Claude no puede generar imágenes rasterizadas como fotos o ilustraciones de forma nativa, a diferencia de ChatGPT con DALL-E o Gemini con Imagen. Sin embargo, Claude ofrece potentes capacidades visuales que muchos usuarios pasan por alto: puede crear gráficos SVG, gráficos interactivos, diagramas y visualizaciones basadas en React a través de Artifacts. Claude también destaca en el análisis y comprensión de imágenes a través de su función Vision, y puede generar imágenes mediante integraciones MCP (Model Context Protocol) con herramientas como FLUX y Stable Diffusion. Esta guía cubre todas las vías visuales disponibles a marzo de 2026.
Resumen rápido
Claude no genera fotos, ilustraciones ni arte IA de forma nativa. Lo que sí puede hacer: crear gráficos SVG profesionales y diagramas, construir visualizaciones interactivas a través de Artifacts, analizar y comprender imágenes con precisión líder en la industria mediante Vision, y generar imágenes rasterizadas a través de integraciones MCP con modelos externos como FLUX y Stable Diffusion XL. Para la mayoría de los casos de uso empresariales y técnicos, el conjunto de herramientas visuales de Claude es más versátil que un simple generador de imágenes; simplemente funciona de manera diferente a lo que podrías esperar.
La respuesta directa — Qué puede y qué no puede hacer Claude con imágenes
La respuesta corta a "¿puede Claude generar imágenes?" es tanto no como sí, dependiendo de lo que entiendas por "imágenes". Si te preguntas si Claude puede crear imágenes fotorrealistas, arte digital o ilustraciones como lo hace DALL-E o Midjourney, la respuesta es no. Anthropic, la empresa detrás de Claude, no ha incorporado un modelo nativo de generación de imágenes en Claude. Cuando le pides a Claude que "dibuje un atardecer" o "cree una foto de un gato", no puede producir una imagen basada en píxeles en formato JPEG o PNG desde cero. Esta es una decisión arquitectónica fundamental: Claude es un modelo de lenguaje grande optimizado para la comprensión y generación de texto, no un sistema de síntesis de imágenes basado en difusión.
Sin embargo, el panorama completo es mucho más matizado que un simple "no". Claude posee varias capacidades visuales potentes que muchos usuarios desconocen o subestiman significativamente. En primer lugar, Claude puede generar código SVG (Scalable Vector Graphics) que se renderiza como diagramas, gráficos, organigramas, logotipos e infografías de calidad profesional directamente en tu navegador. En segundo lugar, a través de la función Artifacts disponible en claude.ai, Claude puede crear visualizaciones interactivas completas basadas en HTML y React, como paneles animados, exploradores de datos y presentaciones interactivas que responden a la entrada del usuario. En tercer lugar, Claude tiene capacidades de comprensión de imágenes líderes en la industria a través de su función Vision, que le permite analizar, describir, extraer texto y responder preguntas sobre imágenes que subas. En cuarto lugar, y quizás lo más emocionante para usuarios que específicamente necesitan generación de imágenes rasterizadas, Claude ahora puede generar imágenes a través de integraciones MCP (Model Context Protocol) que conectan la inteligencia de Claude con modelos dedicados de generación de imágenes como FLUX, Stable Diffusion y otros.
La matriz de capacidades se desglosa de la siguiente manera. Claude no puede crear de forma nativa: fotografías, pinturas digitales, arte IA, archivos de imagen rasterizada (PNG/JPEG) ni contenido de vídeo. Claude sí puede crear de forma nativa: gráficos vectoriales SVG, diseños visuales HTML/CSS, componentes interactivos React vía Artifacts, diagramas Mermaid y arte ASCII. Claude puede hacer mediante integraciones: generar imágenes fotorrealistas vía servidores MCP, editar imágenes existentes usando herramientas externas, y generar imágenes por lotes usando flujos de trabajo conectados por API. Comprender esta distinción es esencial porque determina qué enfoque utilizar para tus necesidades específicas de contenido visual, y como verás a lo largo de esta guía, las capacidades visuales reales de Claude son considerablemente más amplias de lo que la mayoría de los usuarios se imagina.
Lo que Claude SÍ puede crear visualmente (más de lo que crees)

Cuando la mayoría de la gente piensa en generación de imágenes con IA, se imagina herramientas como DALL-E produciendo imágenes fotorrealistas a partir de indicaciones de texto. Claude opera en un espacio visual fundamentalmente diferente, uno que es posiblemente más útil para flujos de trabajo profesionales y técnicos, aunque no pueda pintarte un dragón montando en bicicleta. Las capacidades visuales nativas de Claude se dividen en cuatro categorías distintas, cada una sirviendo diferentes necesidades del usuario y produciendo diferentes tipos de salida visual.
Gráficos y diagramas SVG
La capacidad de Claude para generar código SVG es genuinamente impresionante y a menudo infravalorada. SVG (Scalable Vector Graphics) es un formato estándar web que describe imágenes usando instrucciones matemáticas en lugar de píxeles, lo que significa que el resultado escala perfectamente a cualquier tamaño sin perder calidad. Cuando le pides a Claude crear un diagrama de flujo, organigrama, diagrama de comparación, visualización de datos o incluso un logotipo sencillo, genera código SVG limpio que se renderiza como un gráfico de calidad profesional en cualquier navegador moderno. La calidad del SVG producido por Claude supera consistentemente lo que ChatGPT y Gemini producen en este formato, en gran parte porque las capacidades de generación de código de Claude son las mejores de su clase y el SVG es fundamentalmente un formato basado en código.
Las aplicaciones prácticas de las capacidades SVG de Claude incluyen diagramas de documentación técnica, gráficos para presentaciones, visualizaciones de datos para informes, recursos de marca simples e iconos, y diagramas arquitectónicos para sistemas de software. La ventaja clave aquí es la precisión y la editabilidad: a diferencia de una imagen rasterizada generada por DALL-E, un diagrama SVG de Claude se puede modificar fácilmente editando el código subyacente, y se verá nítido en todo, desde la pantalla de un teléfono hasta el proyector de una sala de conferencias.
Visualizaciones interactivas a través de Artifacts
Quizás la capacidad visual más emocionante y menos conocida es la habilidad de Claude para crear visualizaciones totalmente interactivas a través de la función Artifacts en claude.ai. Artifacts permiten a Claude generar aplicaciones completas en HTML, CSS y JavaScript, incluidos componentes React, que se renderizan en un panel dedicado junto a la conversación. Esto significa que Claude puede crear paneles de datos interactivos donde los usuarios pueden filtrar y ordenar datos, visualizaciones educativas animadas que explican conceptos complejos, calculadoras y herramientas de comparación interactivas, y prototipos de componentes de interfaz con total interactividad. A marzo de 2026, Anthropic ha ampliado las capacidades de Artifacts para admitir visualizaciones interactivas aún más complejas, convirtiendo a Claude en una herramienta legítima de prototipado para diseñadores y desarrolladores.
La diferencia entre una imagen estática de DALL-E y un Artifact interactivo de Claude es la diferencia entre una fotografía de un panel de control y un panel de control funcional. Para presentaciones empresariales, contenido educativo y documentación técnica, las visualizaciones interactivas suelen comunicar información de manera mucho más efectiva que las imágenes estáticas. Los Artifacts de Claude están disponibles en los planes Pro ($20/mes, a marzo de 2026, claude.ai) y Max, con disponibilidad limitada en el nivel gratuito.
Diseños visuales HTML y CSS
Más allá de los Artifacts interactivos, Claude destaca en la generación de diseños HTML y CSS completos que pueden servir como recursos visuales. ¿Necesitas una tarjeta de comparación de precios? ¿Una sección de características destacadas? ¿Una tabla de datos estilizada con efectos hover? Claude genera HTML/CSS de calidad de producción que se puede capturar en pantalla o integrar directamente en proyectos web. Esta capacidad tiende un puente entre "necesito una imagen" y "necesito un elemento visual"; a menudo, lo que los usuarios realmente necesitan es una presentación visual bien diseñada de la información, no necesariamente un archivo de imagen rasterizada.
Comprensión de imágenes de Claude — Potentes capacidades Vision
Si bien Claude no puede generar imágenes rasterizadas, es uno de los sistemas de IA más capaces disponibles para comprenderlas y analizarlas. La función Vision de Claude, disponible en todos los modelos de Claude incluido el nivel gratuito en claude.ai, te permite subir imágenes y pedirle a Claude que las analice, describa, interprete y extraiga información de ellas con una profundidad y precisión notables. Esta es una capacidad claramente diferente de la generación de imágenes, pero para muchos flujos de trabajo profesionales, la comprensión de imágenes es en realidad más valiosa que la creación de imágenes, y es una capacidad donde Claude genuinamente lidera la industria.
Las capacidades Vision de Claude cubren varios casos de uso importantes que demuestran por qué Anthropic eligió invertir fuertemente en la comprensión de imágenes en lugar de la generación de imágenes. El análisis de documentos y OCR representa una de las aplicaciones más sólidas, y es el caso de uso donde Claude supera más claramente a los asistentes de IA competidores. Claude puede leer texto de fotografías de documentos, notas manuscritas, recibos y tarjetas de visita con una precisión notable, superando a menudo a herramientas OCR dedicadas que cuestan cientos de dólares al año. La precisión se extiende a escenarios desafiantes que hacen fallar a otros sistemas: texto parcialmente oscurecido, fuentes inusuales, documentos multilingües y escritura manual con legibilidad variable. Los desarrolladores rutinariamente suben capturas de pantalla de mensajes de error, fragmentos de código o archivos de configuración y le piden a Claude que depure o explique lo que ven, convirtiéndolo en un compañero de desarrollo invaluable que cierra la brecha entre la información visual y la orientación técnica accionable.
La descripción de imágenes y accesibilidad es otra área donde Vision de Claude destaca de maneras que impactan directamente los resultados empresariales. Cuando subes una fotografía, gráfico o diagrama, Claude puede proporcionar descripciones detalladas y precisas que capturan no solo lo que hay en la imagen sino las relaciones entre elementos, el tono de una fotografía o las conclusiones clave de una visualización de datos. Esta capacidad tiene aplicaciones prácticas que van mucho más allá del uso casual. Los propietarios de sitios web usan Claude para generar texto alternativo para miles de imágenes, mejorando tanto el cumplimiento de accesibilidad como el rendimiento SEO. Los equipos de investigación lo utilizan para catalogar y describir archivos de imágenes. Las empresas de medios lo usan para generar automáticamente subtítulos y metadatos para contenido visual. La calidad de las descripciones de Claude es consistentemente lo suficientemente detallada para cumplir con las directrices de accesibilidad WCAG, que requieren texto alternativo que transmita la misma información que un usuario con visión obtendría de la imagen.
El razonamiento visual y la respuesta a preguntas demuestra la comprensión más profunda de Claude sobre las imágenes y representa quizás el aspecto técnicamente más impresionante de su sistema Vision. Puedes subir una infografía compleja y pedirle a Claude que explique las tendencias clave y si los datos respaldan la conclusión que se presenta. Puedes subir una fotografía de una habitación y pedirle a Claude que estime dimensiones, identifique posibles problemas de seguridad o sugiera mejoras de diseño de interiores. Puedes subir un diagrama técnico, ya sea un esquema eléctrico, una topología de red o una estructura química, y pedirle a Claude que identifique posibles errores o sugiera optimizaciones. La capacidad de Claude para razonar sobre contenido visual, no solo describirlo, lo diferencia de herramientas de reconocimiento de imágenes más simples y lo hace genuinamente útil para trabajo a nivel experto.
El flujo de trabajo práctico para muchos usuarios implica una potente combinación de capacidades de Vision y generación trabajando en secuencia: subir una imagen existente para que Claude la analice, luego pedirle a Claude que cree una versión mejorada como diagrama SVG, un Artifact interactivo, o incluso una imagen rasterizada a través de integración MCP. Este flujo de trabajo de analizar y recrear aprovecha las fortalezas de Claude en ambas direcciones y es particularmente valioso para usuarios que necesitan modernizar diagramas heredados, recrear gráficos de pizarras fotografiadas o convertir imágenes estáticas en experiencias visuales interactivas.
Cómo generar imágenes a través de Claude usando MCP
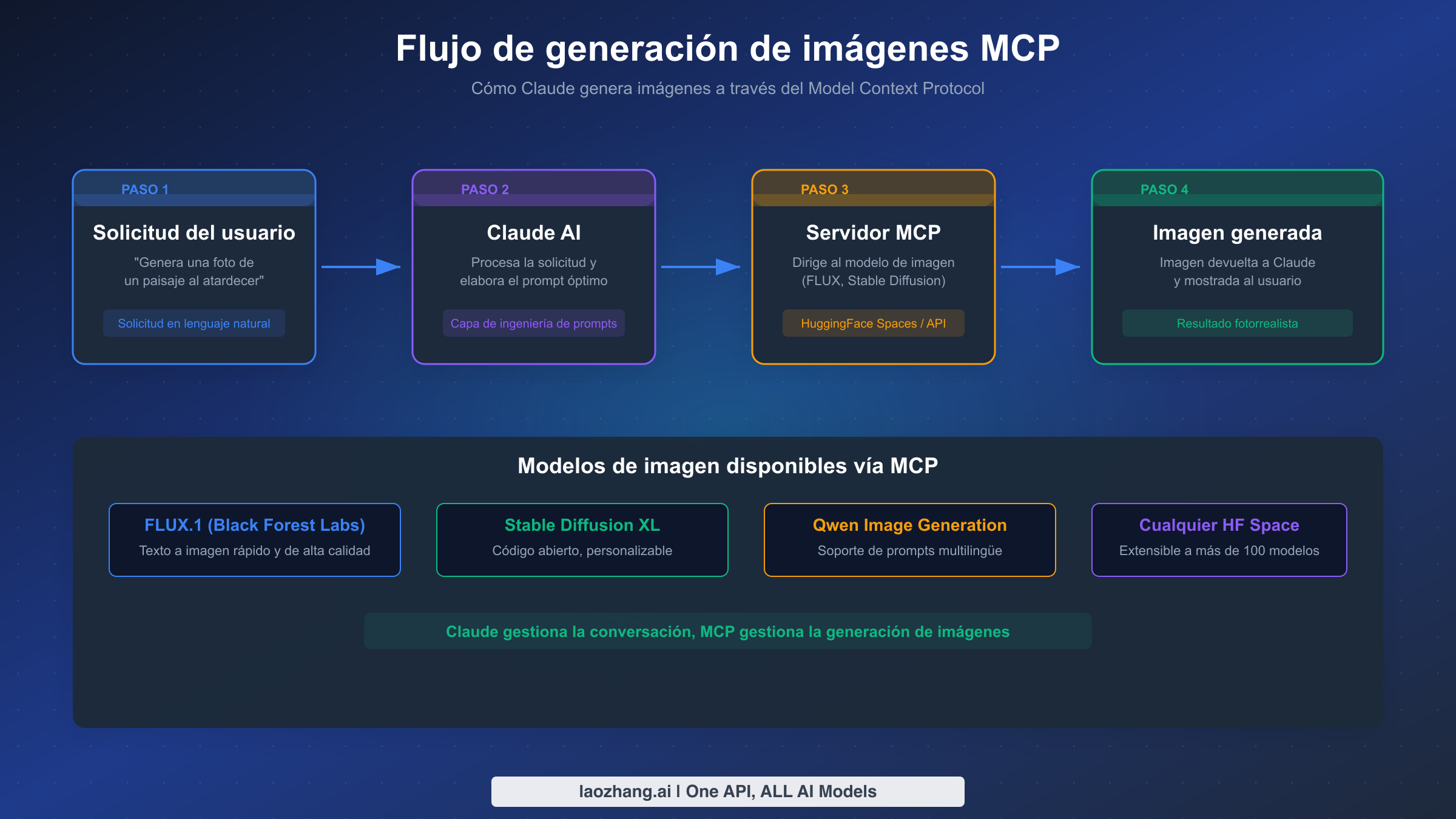
Para usuarios que específicamente necesitan que Claude produzca imágenes rasterizadas (fotografías, ilustraciones, arte digital), el Model Context Protocol (MCP) proporciona un puente potente entre la inteligencia conversacional de Claude y los modelos dedicados de generación de imágenes. MCP es un protocolo abierto desarrollado por Anthropic que permite a Claude interactuar con herramientas y servicios externos, extendiendo efectivamente las capacidades de Claude más allá de lo que el modelo base puede hacer. A través de MCP, Claude puede conectarse a APIs de generación de imágenes como FLUX.1 (de Black Forest Labs), Stable Diffusion XL y prácticamente cualquier modelo alojado en HuggingFace Spaces, habilitando la verdadera generación de texto a imagen dentro del flujo de trabajo de Claude.
Cómo funciona la generación de imágenes con MCP
El flujo de trabajo es sencillo una vez configurado. Envías una solicitud en lenguaje natural a Claude ("Genera una foto profesional de producto de un portátil en un escritorio minimalista"). Claude procesa tu solicitud usando su comprensión del lenguaje para elaborar una indicación optimizada para el modelo de imagen objetivo. El servidor MCP dirige esta indicación al modelo de generación de imágenes seleccionado (FLUX, Stable Diffusion, etc.). La imagen generada se devuelve a través de MCP y se muestra directamente en tu conversación con Claude. La ventaja clave de este enfoque es que Claude actúa como una capa inteligente de ingeniería de indicaciones: entiende el contexto, refina solicitudes vagas y optimiza las indicaciones para el modelo específico que se está utilizando, produciendo a menudo mejores resultados que si le dieras la indicación directamente al modelo de imágenes.
Configuración de MCP para generación de imágenes
Configurar la generación de imágenes MCP con Claude Desktop requiere algunos pasos, pero está al alcance de usuarios con comodidad técnica básica. Necesitas Claude Desktop (la aplicación descargable, no la versión web) y un archivo de configuración que le indique a Claude a qué servidores MCP conectarse. El enfoque más popular utiliza HuggingFace Spaces como backend de generación de imágenes, que proporciona acceso gratuito a modelos como FLUX.1.
Para configurar Claude Desktop para la generación de imágenes, necesitas editar el archivo de configuración MCP ubicado en ~/Library/Application Support/Claude/claude_desktop_config.json en macOS o la ruta equivalente en Windows. Una configuración básica para conectarse a un modelo FLUX en HuggingFace se ve así:
json{ "mcpServers": { "image-generator": { "command": "npx", "args": [ "-y", "@anthropic/mcp-server-huggingface", "--space", "black-forest-labs/FLUX.1-schnell" ] } } }
Después de guardar esta configuración y reiniciar Claude Desktop, verás un nuevo icono de herramienta en la interfaz de chat indicando que el servidor MCP está conectado. A partir de ese momento, simplemente puedes pedirle a Claude que genere imágenes en lenguaje natural y utilizará el modelo conectado para producirlas.
Para desarrolladores y equipos que necesitan más flexibilidad, puedes configurar múltiples modelos de generación de imágenes simultáneamente y dejar que Claude elija el más apropiado según la solicitud. Por ejemplo, podrías configurar FLUX.1 para arte conceptual rápido, Stable Diffusion XL para imágenes fotorrealistas, y un modelo especializado para estilos específicos. Para un análisis más detallado de los precios de las API de generación de imágenes, consulta nuestra comparativa de precios de API de generación de imágenes IA.
Modelos de imagen disponibles vía MCP
El ecosistema MCP admite un número creciente de modelos de generación de imágenes, cada uno con diferentes fortalezas. FLUX.1 de Black Forest Labs es actualmente la opción más popular para la generación de imágenes MCP debido a su equilibrio entre velocidad y calidad: la variante "schnell" genera imágenes en menos de dos segundos manteniendo una buena calidad visual. Stable Diffusion XL sigue siendo popular entre usuarios que desean máxima personalización a través de modelos LoRA y ajuste fino. Qwen Image Generation ofrece un sólido soporte para indicaciones multilingües, lo que lo hace ideal para trabajo creativo en idiomas distintos al inglés. Y dado que MCP se conecta a HuggingFace Spaces, cualquiera de los cientos de modelos de generación de imágenes alojados allí puede potencialmente integrarse con Claude.
Claude vs ChatGPT vs Gemini — Comparativa de generación de imágenes
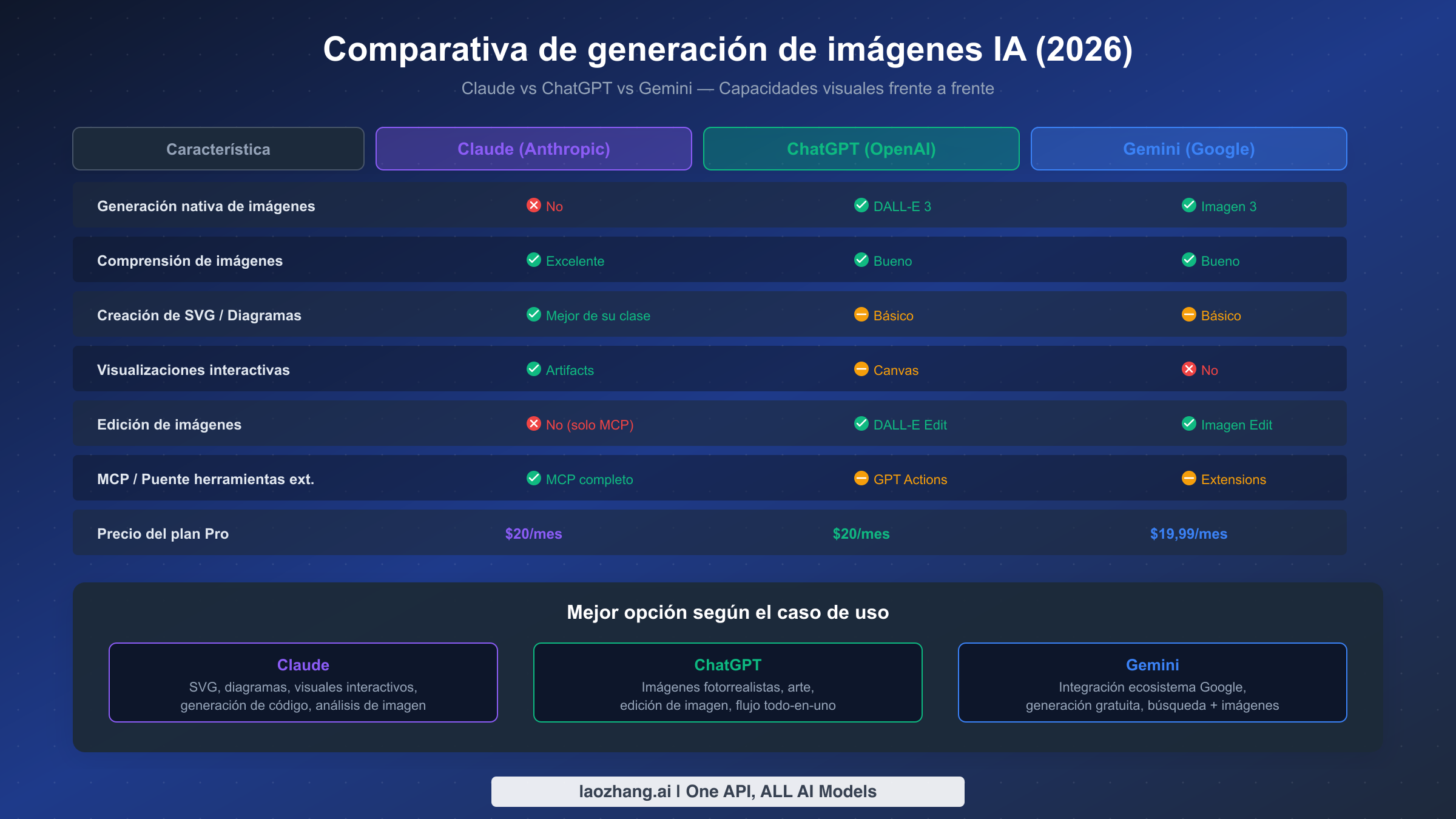
Comprender cómo se comparan las capacidades visuales de Claude con sus principales competidores, ChatGPT (OpenAI) y Gemini (Google), requiere mirar más allá de la simple pregunta "¿puede generar imágenes?". Cada plataforma ha adoptado una estrategia fundamentalmente diferente para manejar contenido visual, y la mejor opción depende completamente de las necesidades específicas de tu flujo de trabajo. La comparativa a continuación utiliza datos verificados de precios y características a marzo de 2026.
La generación nativa de imágenes es el área donde la brecha de Claude es más visible. ChatGPT integra DALL-E 3 directamente en su interfaz de conversación, permitiendo a los usuarios generar imágenes fotorrealistas, ilustraciones y arte creativo sin ninguna configuración adicional; esta es la experiencia de generación de imágenes más fluida entre las tres plataformas. Gemini integra de manera similar el modelo Imagen 3 de Google, ofreciendo generación nativa de imágenes con fortalezas particulares en fotorrealismo y renderizado de texto dentro de las imágenes. Claude no ofrece generación nativa de imágenes rasterizadas, y esta sigue siendo su brecha más significativa respecto a la competencia. Sin embargo, el enfoque de Claude a través de la integración MCP ofrece mayor flexibilidad de modelos, ya que los usuarios pueden conectarse a cualquier modelo de generación de imágenes en lugar de estar limitados al estilo de salida de un único proveedor. La compensación es clara: ChatGPT y Gemini priorizan la conveniencia con modelos integrados, mientras que Claude prioriza la flexibilidad y la elección a través de su arquitectura de protocolo abierto.
La creación visual más allá de las fotos es donde la posición competitiva de Claude cambia drásticamente a su favor. La calidad de generación SVG de Claude supera consistentemente a ChatGPT y Gemini, produciendo código más limpio, diseños más precisos y diagramas mejor diseñados. Esta ventaja proviene de las capacidades de generación de código mejores de su clase de Claude: dado que SVG es fundamentalmente un formato de código, una mejor generación de código se traduce directamente en mejor salida visual. La función Artifacts de Claude para visualizaciones interactivas no tiene equivalente directo en ChatGPT o Gemini. Mientras que ChatGPT ofrece Canvas para edición colaborativa y Gemini puede generar algo de contenido visual, ninguno iguala la sofisticación de los Artifacts interactivos basados en React de Claude, que pueden producir paneles de control, calculadoras y exploradores de datos totalmente funcionales. Para usuarios cuyas necesidades de "generación de imágenes" realmente se refieren a crear diagramas profesionales, visualizaciones de datos o contenido visual interactivo, Claude es posiblemente la plataforma más potente disponible actualmente.
Comprensión y análisis de imágenes
Las tres plataformas ofrecen sólidas capacidades de comprensión de imágenes, pero Vision de Claude es ampliamente considerado como el más preciso para análisis detallado de imágenes, OCR de documentos y tareas de razonamiento visual. Benchmarks independientes sitúan consistentemente a Claude en o cerca de la cima en precisión de comprensión de imágenes, particularmente para imágenes complejas con múltiples elementos e interpretación visual matizada. La ventaja de Claude es especialmente pronunciada en escenarios de análisis de documentos: extraer datos de tablas en fotografías, leer notas manuscritas e interpretar diagramas técnicos complejos. La comprensión de imágenes de ChatGPT es fuerte y mejora con cada actualización del modelo, mientras que Gemini se beneficia de la extensa investigación en visión computacional de Google, lo que lo hace particularmente bueno identificando objetos, ubicaciones y puntos de referencia en fotografías.
Comparativa de precios y valor
Las tres plataformas ofrecen sus funciones principales a precios notablemente similares: Claude Pro a $20/mes, ChatGPT Plus a $20/mes y Gemini Advanced a $19,99/mes (todos los precios verificados en marzo de 2026, páginas de precios oficiales respectivas). El cálculo de valor depende de qué capacidades te importan más. Si la generación nativa de imágenes es esencial, ChatGPT y Gemini ofrecen mejor valor ya que esa capacidad está incluida en la suscripción. Si necesitas principalmente gráficos SVG, visualizaciones interactivas y análisis de imágenes superior, Claude Pro proporciona el mejor retorno de inversión. Para un desglose detallado de cómo Claude se compara con ChatGPT en todas las dimensiones, consulta nuestra comparativa detallada ChatGPT vs Claude.
¿Qué plataforma para cada necesidad?
El marco de decisión es sencillo una vez que identificas tu caso de uso principal. Elige ChatGPT si tu necesidad principal es generar imágenes fotorrealistas, arte creativo o ilustraciones dentro de una conversación: la integración con DALL-E es inigualable en facilidad de uso, y la calidad de las imágenes generadas sigue mejorando con cada actualización del modelo. Elige Gemini si necesitas generación de imágenes estrechamente integrada con el ecosistema de Google (Search, Docs, Slides) o quieres la mejor opción de generación de imágenes en el nivel gratuito, ya que Google ofrece acceso gratuito generoso a Imagen a través de Gemini. Elige Claude si tus necesidades visuales se centran en diagramas profesionales, visualizaciones interactivas, análisis de imágenes, o si deseas máxima flexibilidad a través de MCP para conectarte a cualquier modelo de generación de imágenes disponible en el ecosistema. Muchos usuarios avanzados mantienen suscripciones a múltiples plataformas, usando cada una por sus fortalezas: Claude para análisis y diagramas, ChatGPT para generación rápida de imágenes y Gemini para la integración con Google Workspace. Este enfoque multiplataforma se está volviendo cada vez más común a medida que cada asistente de IA establece áreas distintas de excelencia.
Flujos de trabajo prácticos — Usando Claude para creación de contenido visual
Comprender las capacidades de Claude en teoría es útil, pero ver cómo se combinan en flujos de trabajo reales demuestra su valor práctico. Los siguientes escenarios ilustran cómo diferentes tipos de usuarios aprovechan el conjunto de herramientas visuales de Claude para realizar tareas que inicialmente podrían parecer requerir un generador de imágenes dedicado.
Creadores de contenido y especialistas en marketing utilizan frecuentemente Claude para producir recursos visuales para publicaciones de blog, redes sociales y presentaciones. Un flujo de trabajo típico consiste en pedirle a Claude que cree una infografía comparativa como diagrama SVG, y luego solicitar una versión interactiva como Artifact para la versión web del contenido. Por ejemplo, un especialista en marketing de contenido que escribe sobre opciones de almacenamiento en la nube podría pedirle a Claude generar un gráfico de comparación de precios en SVG, crear una calculadora interactiva en Artifacts que permita a los lectores introducir sus necesidades de almacenamiento y ver proyecciones de costes, y luego usar Vision de Claude para analizar infografías de la competencia para inspiración. Todo el flujo de contenido visual ocurre dentro de una sola conversación con Claude, con cada elemento visual construyendo sobre el contexto de los anteriores.
Desarrolladores de software y redactores técnicos representan quizás el grupo más grande de usuarios que se benefician del enfoque visual de Claude. Al documentar una arquitectura de microservicios, un desarrollador puede pedirle a Claude generar un diagrama del sistema en SVG, crear un explorador de arquitectura interactivo como Artifact donde los usuarios puedan hacer clic en los servicios para ver sus conexiones, y producir diagramas de secuencia para flujos de API. Dado que Claude comprende profundamente el contexto del código, sus diagramas técnicos son a menudo más precisos e informativos que lo que produciría un generador de imágenes genérico; Claude sabe lo que un diagrama de arquitectura bien estructurado debería comunicar, no solo cómo debería verse.
Educadores y formadores aprovechan extensamente los Artifacts interactivos de Claude. Un instructor que enseña estadística puede pedirle a Claude crear un visualizador interactivo de distribución normal donde los estudiantes puedan ajustar los valores de media y desviación estándar y ver cómo cambia la curva en tiempo real. Un profesor de idiomas podría solicitar un sistema interactivo de tarjetas de vocabulario con repetición espaciada. Estas herramientas educativas interactivas van mucho más allá de lo que una imagen estática podría lograr, y la capacidad de Claude para generarlas conversacionalmente las hace accesibles incluso para educadores sin experiencia en programación.
Analistas de datos e investigadores utilizan las capacidades combinadas de Vision y SVG de Claude para flujos de trabajo rápidos de visualización de datos. Sube una captura de pantalla de una tabla de datos de un informe PDF, y Claude puede extraer los datos usando Vision, luego generar inmediatamente un gráfico SVG de calidad de publicación que visualice las tendencias clave. Este flujo de trabajo de analizar y visualizar condensa lo que tradicionalmente requeriría múltiples herramientas (software OCR, programa de hojas de cálculo, herramienta de gráficos) en una sola interacción conversacional. Los investigadores han encontrado esto particularmente valioso para revisiones de literatura, donde necesitan visualizar rápidamente datos de múltiples artículos: subir los gráficos de cada artículo, pedirle a Claude que extraiga los puntos de datos clave, y luego generar una visualización comparativa unificada que sintetice los hallazgos de todos los estudios.
Gerentes de producto y diseñadores UX están descubriendo cada vez más a Claude como un compañero de prototipado rápido. En lugar de pasar horas en Figma creando maquetas para revisiones de las partes interesadas, pueden describir un concepto de interfaz de usuario a Claude y recibir un prototipo Artifact interactivo en minutos. El prototipo no es perfecto a nivel de píxel, pero es funcional: los botones hacen clic, los formularios aceptan entrada y los datos fluyen entre componentes. Esto permite a los equipos de producto probar conceptos de interacción y recopilar comentarios de las partes interesadas a una fracción del coste y tiempo de prototipado tradicional. Combinado con la capacidad de Claude para analizar capturas de pantalla de aplicaciones existentes (vía Vision), esto crea un flujo de trabajo potente: fotografiar el estado actual, describir los cambios deseados y recibir un prototipo funcional de la versión mejorada.
Preguntas frecuentes sobre Claude e imágenes
¿Puede Claude generar fotos como DALL-E o Midjourney?
No, Claude no puede generar de forma nativa imágenes fotorrealistas, arte digital o ilustraciones. A diferencia de ChatGPT que integra DALL-E 3 o Midjourney que está diseñado específicamente para la creación de imágenes, Claude no tiene un modelo interno de síntesis de imágenes. Sin embargo, Claude puede generar fotos a través de integraciones MCP con modelos como FLUX.1 y Stable Diffusion, lo que requiere Claude Desktop y algo de configuración inicial. Una vez configurado, la experiencia es conversacional: describes lo que quieres y Claude usa el modelo conectado para producirlo.
¿Qué tipo de elementos visuales PUEDE crear Claude sin integraciones?
Sin necesidad de configuración adicional, Claude puede crear gráficos SVG (diagramas, organigramas, infografías, logotipos, iconos), visualizaciones interactivas HTML/React a través de Artifacts, diagramas Mermaid y diseños HTML/CSS estilizados. Estas capacidades están disponibles en todos los planes incluido el nivel gratuito, aunque la funcionalidad de Artifacts es más limitada en cuentas gratuitas. Para muchos casos de uso profesional (documentación técnica, presentaciones, visualización de datos), estas capacidades nativas son en realidad más útiles que la generación de imágenes rasterizadas.
¿Puede Claude analizar y comprender imágenes que subo?
Sí. La función Vision de Claude es uno de los sistemas de comprensión de imágenes más capaces disponibles. Puedes subir fotos, capturas de pantalla, documentos, gráficos, diagramas y otras imágenes, y Claude las analizará en detalle. Puede extraer texto (OCR), describir contenido visual, responder preguntas sobre imágenes, identificar objetos y patrones, y razonar sobre relaciones espaciales. Vision está disponible en todos los planes de Claude incluido el gratuito (claude.ai, marzo de 2026).
¿Es la comprensión de imágenes de Claude mejor que la de ChatGPT?
La comprensión de imágenes de Claude es generalmente considerada líder en la industria, particularmente para análisis detallado, OCR de documentos y razonamiento visual complejo. Los benchmarks independientes sitúan consistentemente a Claude en o cerca de la cima en precisión de comprensión de imágenes. Las capacidades de visión de ChatGPT también son sólidas y continúan mejorando, pero Claude tiende a proporcionar análisis más matizados y detallados, especialmente para imágenes técnicas, composiciones de múltiples elementos y tareas de extracción de documentos.
¿Añadirá Claude generación nativa de imágenes en el futuro?
Anthropic no ha anunciado públicamente planes para añadir generación nativa de imágenes rasterizadas a Claude. La empresa se ha enfocado históricamente en seguridad, razonamiento y capacidades lingüísticas en lugar de competir directamente en el espacio de generación de imágenes. Sin embargo, el ecosistema MCP significa que Claude ya puede acceder a prácticamente cualquier modelo de generación de imágenes a través de integraciones, lo que puede reducir la urgencia para que Anthropic construya el suyo propio. Para la información más actualizada sobre las capacidades de Claude, consulta la documentación oficial de Anthropic y la guía de precios y suscripción de Claude para detalles de planes.
Veredicto final — ¿Es Claude suficiente para tus necesidades visuales?
Si Claude es "suficiente" para tus necesidades de contenido visual depende completamente de cuáles sean esas necesidades. Si necesitas principalmente generación de imágenes fotorrealistas para proyectos creativos, contenido de redes sociales o materiales de marketing, Claude por sí solo no es la herramienta adecuada: querrás ChatGPT con DALL-E, Midjourney o un generador de imágenes dedicado. Claude puede cerrar esta brecha a través de integraciones MCP, pero la configuración requiere esfuerzo técnico y el flujo de trabajo es menos fluido que la generación nativa de imágenes en plataformas competidoras.
Sin embargo, si tus necesidades visuales se centran en diagramas profesionales, documentación técnica, visualización de datos, presentaciones interactivas o análisis de imágenes, Claude no es solo "suficiente", sino posiblemente la mejor plataforma de IA disponible. Su calidad de generación SVG, sus capacidades de Artifacts interactivos y su Vision líder en la industria lo hacen especialmente adecuado para trabajo del conocimiento que requiere contenido visual preciso, editable e interactivo en lugar de creación de imágenes artísticas.
El enfoque más pragmático para usuarios con necesidades visuales diversas es usar Claude como el asistente de IA principal por sus superiores capacidades de razonamiento, codificación y análisis, mientras se aprovechan las integraciones MCP para la necesidad ocasional de generación de imágenes rasterizadas. Esto te da la inteligencia de Claude como capa de orquestación, comprendiendo tu intención, refinando indicaciones y eligiendo la herramienta adecuada, mientras accedes al ecosistema completo de modelos de generación de imágenes cuando sea necesario. Para muchos usuarios, esta combinación resulta más potente que las capacidades nativas de cualquier plataforma individual, porque la comprensión de Claude del contexto y la intención se traduce en mejores resultados independientemente de qué modelo de imagen produzca finalmente los píxeles.
Para equipos y organizaciones que evalúan plataformas de IA, la recomendación es auditar tus necesidades reales de contenido visual del último trimestre antes de tomar una decisión. Si más de la mitad de tus solicitudes de "generación de imágenes" fueron en realidad para diagramas, gráficos, documentación gráfica o visualizaciones de datos, Claude es probablemente la mejor inversión. Si la mayoría fueron para imágenes creativas, fotos de marketing o contenido artístico, ChatGPT o una herramienta dedicada como Midjourney te servirá mejor. Y si necesitas ambos, la ruta de integración MCP significa que Claude también puede manejar la generación de imágenes creativas; simplemente requiere un poco más de configuración que la experiencia llave en mano que ofrecen los competidores.
La conclusión: Claude no puede generar fotos de forma nativa, pero sus capacidades visuales son más amplias, más versátiles y, en muchos contextos profesionales, más útiles que la simple generación de imágenes. La pregunta no es si Claude puede crear imágenes, sino si el enfoque de Claude hacia el contenido visual sirve mejor a las necesidades reales de tu flujo de trabajo.