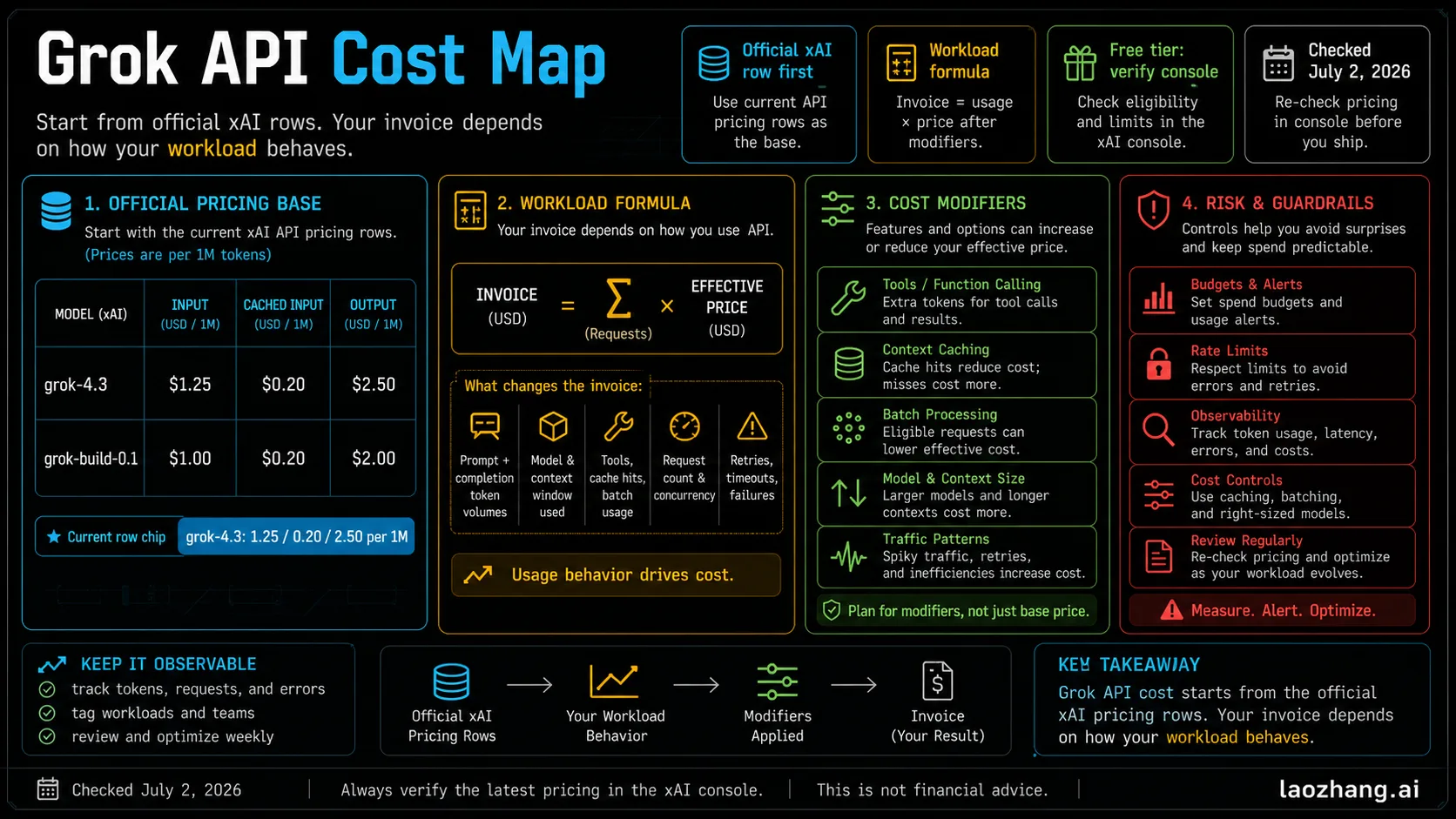
As checked against xAI Docs on July 2, 2026, Grok API pricing for grok-4.3 is listed at $1.25 input, $0.20 cached input, and $2.50 output per 1M tokens. Public xAI docs do not guarantee a permanent official free API tier; the safe assumption is that credits, eligibility, limits, and billing mode must be verified in your own xAI console before you scale.
Treat the official token row as the base, not the budget. A useful estimate is: input tokens plus cached input plus output and reasoning tokens, plus server-side tools, storage, batch or priority mode, retries, and the spending limits on your team account. That is why the practical question is not just "what is the Grok API price?" but "what will this workload cost when it succeeds?"
Keep the contracts separate: xAI API pricing is not the same thing as Grok app or X subscription access, and third-party free or provider routes are not official xAI pricing rows. Start with a small prepaid test, log token and tool usage, compare it with the worksheet below, then decide whether the workload is safe to scale.
Quick Worksheet Before You Spend
Use this first when you need a fast budget answer.
| Question | Current answer | Budget action |
|---|---|---|
| What is the main Grok API price row? | xAI Docs list grok-4.3 at $1.25 input, $0.20 cached input, and $2.50 output per 1M tokens. | Use this as the base row for general Grok API work, then recheck the pricing page before publishing a number. |
| Is there a free Grok API tier? | Public docs do not guarantee a permanent official free API tier. The quickstart tells users to load credits before using the API. | Check your console for account-specific credits or promotions; do not assume another account's credit state applies to you. |
| What changes the invoice most? | Token mix, cached input, output length, tool calls, batch eligibility, priority service, storage, retries, and rate-limit tier. | Build a per-workload worksheet instead of copying one sticker price. |
| What is the safest test route? | Small prepaid usage with postpaid limit set low or to zero, plus token and tool logging. | Stop if the console, logs, or model row does not match the worksheet. |
The worksheet uses xAI documentation as the source of record for official prices and treats third-party "free" routes only as separate provider contracts.
Current Official Grok API Price Rows
The official price table lives in xAI's pricing documentation, not in search snippets or provider calculators. On July 2, 2026, the relevant Chat API rows visible in that page were:
| Model row | Context listed | Input per 1M | Cached input per 1M | Output per 1M | Practical use |
|---|---|---|---|---|---|
grok-4.3 | 1M | $1.25 | $0.20 | $2.50 | Default current Grok API row for most text and image-input work. |
grok-build-0.1 | 256k | $1.00 | $0.20 | $2.00 | Lower listed row for build-oriented work where it is available and fits quality needs. |
grok-4.20-multi-agent-0309 | 1M | $1.25 | $0.20 | $2.50 | Specialized row; verify availability and intended use before routing traffic. |
grok-4.20-0309-reasoning | 1M | $1.25 | $0.20 | $2.50 | Reasoning row; budget from measured output and reasoning behavior, not name alone. |
grok-4.20-0309-non-reasoning | 1M | $1.25 | $0.20 | $2.50 | Non-reasoning row; test quality and output length before choosing it for cost. |
The Grok 4.3 model page lists grok-4.3, aliases such as grok-4.3-latest and grok-latest, text and image input, text output, a 1M-token context window, and the same $1.25 / $0.20 / $2.50 per-1M price row. It also says requests exceeding the 200K context window can use different rates, so very long-context tests should be measured separately.
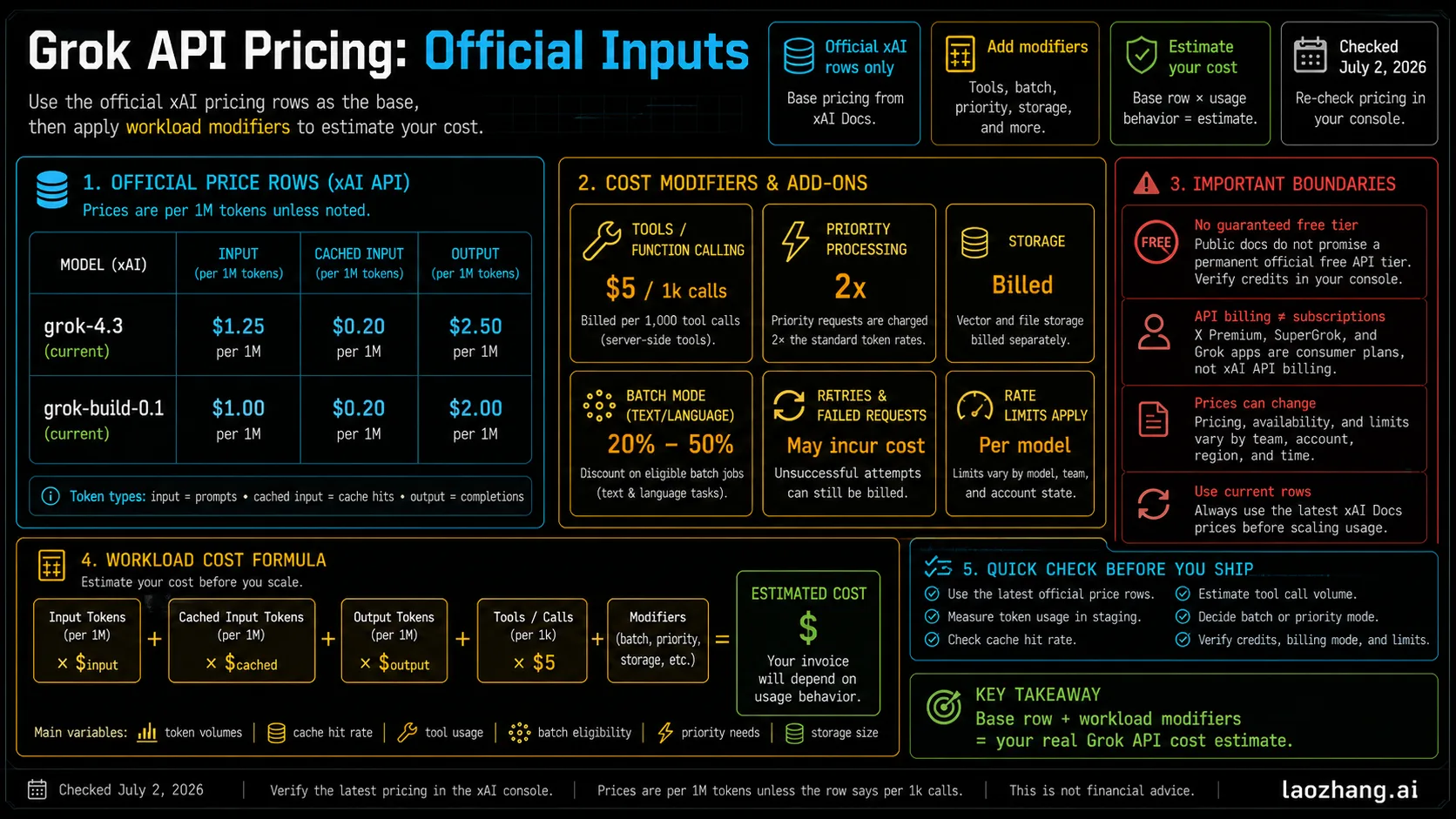
Do not freeze these rows as timeless. xAI can change pricing, available models, rate limits, regions, or console access. For production documentation, copy the date, the exact model ID, and the docs URL into your release note or internal budget sheet.
Tool, Batch, Priority, and Storage Costs
Most bad Grok API budgets fail because they price tokens only. xAI's pricing page also lists add-on costs and modifiers that can matter as much as the model row.
| Cost surface | Listed price or rule checked July 2, 2026 | When it matters |
|---|---|---|
| Web Search | $5 per 1k calls | Agents that need current web evidence. |
| X Search | $5 per 1k calls | Social or real-time X evidence workflows. |
| Code Execution | $5 per 1k calls | Coding, data, or sandboxed execution agents. |
| File Attachments search | $10 per 1k calls | Large document workflows using uploaded files. |
| Collections Search / RAG | $2.50 per 1k calls | Retrieval-heavy knowledge-base work. |
| Batch API | 20%-50% off standard text/language token rates, usually within 24 hours | Non-urgent bulk jobs where latency is flexible. |
| Priority Processing | 2x standard token rates after prompt caching discounts | Latency-sensitive work where priority service is explicitly used. |
| File storage | $0.025/GiB/day | Uploaded files retained across jobs. |
| Collection storage | $0.10/GiB/day | Stored retrieval collections. |
| Downloads | $0.20/GiB downloaded | File or collection export workflows. |
This table is why "Grok API pricing" should be written as a formula. A research agent with web search can spend more on tool calls than a simple support draft spends on tokens. A repeated support prompt can be much cheaper if cached input actually hits. A batch summarization job can be cheaper than synchronous traffic if the job can wait.
Does Grok API Have a Free Tier?
The safe public answer is no durable official free API tier is guaranteed by the xAI docs checked on July 2, 2026. The quickstart says to sign up, then load the account with credits to start using the API. That is not the same as a permanent free tier.
Use this split:
| Route | What it can mean | How to describe it safely |
|---|---|---|
| Official xAI API | Usage billed or credited inside your xAI team/account. | "Verify credits, eligibility, and billing mode in your xAI console." |
| Console credits or promotions | Account-specific credit state that can change. | "Credits may exist for your account, but public docs do not make them universal." |
| Third-party free route | A provider absorbs, sponsors, proxies, or limits usage under its own contract. | "This is a provider route, not the official xAI price row." |
| Grok app or X subscription | Consumer access to Grok through an app or subscription. | "This is separate from API billing." |
The difference matters. If your budget sheet says "free" because one tutorial showed a provider route, your production API plan may be wrong on day one. If your account has promotional credits, record the credit balance and expiration behavior separately from model pricing. If your billing mode changes from prepaid-only to postpaid, update the stop rule.
The Grok API Cost Formula
Use this formula before you compare workloads:
textestimated cost = input_tokens / 1,000,000 * input_price + cached_input_tokens / 1,000,000 * cached_input_price + output_tokens / 1,000,000 * output_price + tool_calls / 1,000 * tool_call_price + storage_gib_days * storage_price + downloads_gib * download_price + retry_cost + priority_multiplier_or_batch_discount
That formula is intentionally explicit. It prevents three common mistakes:
- Treating cached input as automatic savings before cache hits are measured.
- Treating server-side tools as free because they are hidden behind an agent flow.
- Treating the base row as final even when retry, priority, or storage behavior changes the effective cost.
A practical worksheet should track these columns for each workload:
| Worksheet column | Why it belongs |
|---|---|
| Model ID | Aliases can move; a pinned row is easier to audit. |
| Input tokens per task | Long context, policies, examples, and retrieved text can dominate. |
| Cached input tokens per task | Repeated prefixes can reduce cost only when cache behavior is real. |
| Output tokens per task | Long answers, JSON, and repair loops inflate output spend. |
| Tool calls per task | Search, code, file, and RAG tools have their own price surfaces. |
| Retry rate | A cheap first attempt is expensive if the third attempt is the accepted result. |
| Batch eligible | Non-urgent work may earn token discounts. |
| Priority required | Priority mode can double token rates. |
| Storage retained | File and collection storage becomes a daily cost. |
| Console limit | Spending limits decide whether mistakes stop early or run into postpaid usage. |
Four Use-Case Cost Examples
These examples are worksheets, not universal monthly quotes. Replace the assumptions with your own logs before you scale.
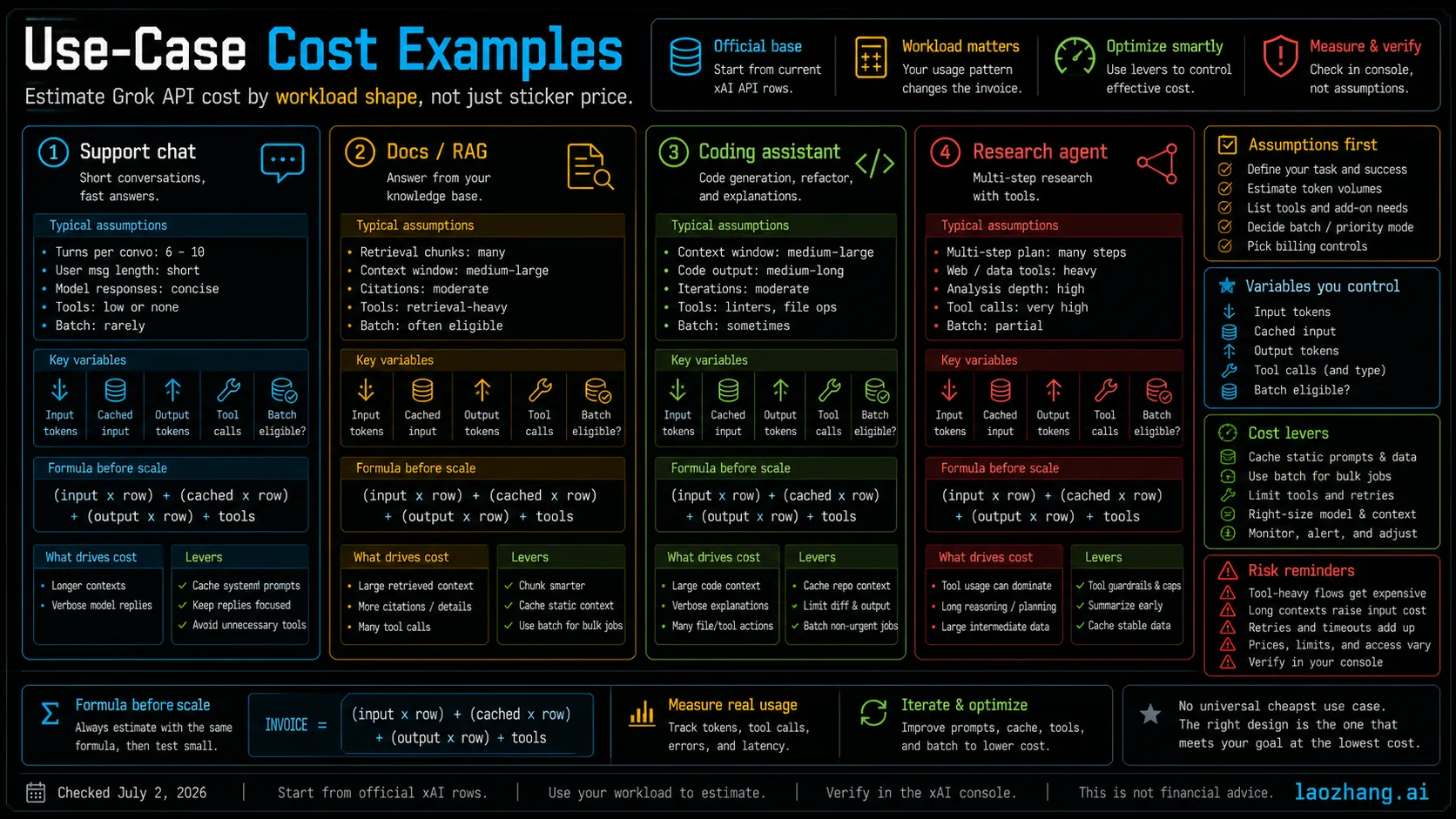
Support Chat
A support bot is usually output-sensitive and cache-sensitive. The repeated system prompt, policy block, tone rules, and tool instructions may be good cached-input candidates. The expensive part often becomes accepted answer length, handoff summaries, and retries after a poor answer.
| Assumption | Example value | Cost implication |
|---|---|---|
| Requests | 100,000 replies/month | High volume makes small per-task differences visible. |
| Input | 800 fresh tokens/reply | Base input is usually manageable. |
| Cached input | 1,200 repeated tokens/reply | Cache hit rate can materially reduce cost. |
| Output | 350 tokens/reply | Output price matters more than many teams expect. |
| Tools | 0 to 1 retrieval/search call/reply | Tool calls can overtake token savings if used on every reply. |
The control rule: cache stable instructions, cap answer length, log accepted vs retried replies, and sample quality before routing all tickets.
Documents and RAG
Document workflows are input-heavy. A single answer can include retrieved passages, file search, user query, policy text, and a long output. The token row may look cheap until the retrieval layer adds file search or collections calls.
| Assumption | Example value | Cost implication |
|---|---|---|
| Requests | 20,000 answers/month | Medium volume with large context can still be expensive. |
| Input | 6,000 fresh tokens/answer | Retrieval size is the main lever. |
| Cached input | 1,000 repeated tokens/answer | Stable instructions help, but retrieved chunks are usually fresh. |
| Output | 700 tokens/answer | Citations and summaries increase output. |
| Tools | Collections Search or File Attachments search | Tool rows must be counted separately. |
The control rule: retrieve fewer, better chunks; keep citations compact; set a maximum context budget; and compare answer quality before widening retrieval.
Coding Assistant
Coding work can be cheap for short suggestions and expensive for agentic loops. The cost driver is not just tokens; it is the number of attempts, tool calls, code execution, and review time before a change is accepted.
| Assumption | Example value | Cost implication |
|---|---|---|
| Tasks | 5,000 coding turns/month | Turn count can hide multi-attempt work. |
| Input | 2,500 tokens/turn | Files, diffs, tests, and instructions add up. |
| Cached input | 500 tokens/turn | Reused repo instructions may help. |
| Output | 900 tokens/turn | Patch explanations and structured responses can be long. |
| Tools | Code Execution when enabled | Tool fees and retry loops need their own line. |
The control rule: log accepted changes, failed test runs, retries, and human review minutes. Successful-task cost matters more than first-response token cost.
Research Agent
A research agent can look cheap in tokens and expensive in tools. Web Search, X Search, file search, and long evidence summaries can dominate. This is also the workload where stale or unsupported facts are most costly.
| Assumption | Example value | Cost implication |
|---|---|---|
| Reports | 1,000 reports/month | Lower volume can still be expensive per task. |
| Input | 4,000 tokens/report | Query plan, evidence, and instructions are substantial. |
| Cached input | 800 tokens/report | Reusable report scaffolds may cache. |
| Output | 1,500 tokens/report | Evidence packets and summaries are output-heavy. |
| Tools | Multiple Web Search or X Search calls | Tool calls can dominate the total. |
The control rule: cap tool calls, require source quality, batch non-urgent research, and stop if the agent cannot show which facts came from current official sources.
Rate Limits and Billing Controls
xAI's rate-limit documentation says each API team has per-model RPS and TPM limits, and that tiers are based on cumulative API spend since January 1, 2026. It also says all consumed tokens count toward TPM: prompt, completion, reasoning, cached prompt, image, and audio tokens. Treat the model page's rate-limit numbers as useful, but still verify your team console.
The billing management API exposes invoices, payment methods, prepaid credit balance, top-ups, historical usage, postpaid invoice preview, and spending limits. For a first production test, the safest control pattern is:
- Start with prepaid credits.
- Set the postpaid limit low or to zero if you want prepaid-only behavior.
- Log tokens, cached tokens, model ID, tool calls, retries, errors, latency, and accepted result.
- Compare actual spend against the worksheet after a small sample.
- Raise limits only after the estimate and logs match.

Do not wait until the monthly invoice to learn that an agent was calling tools on every retry. Put the stop rule in code: if request volume, tool-call count, retry rate, or output tokens exceed the worksheet by a defined threshold, pause the route.
Watch Old Model Rows After the May 15 Retirement
The May 15 retirement notice is the freshness warning for this topic. xAI says several retired slugs redirect to grok-4.3 after May 15, 2026, and deprecated slugs after that date are billed at grok-4.3 pricing. That means old snippets that still center Grok 4.1 Fast, Grok 3, or pre-retirement rows can be dangerous budget inputs.
Use this rule:
| If you see... | Treat it as... | Safer move |
|---|---|---|
Grok 4.1 Fast as the current cheap default | Stale until proven otherwise in xAI Docs or your console. | Recheck the pricing page and console model list. |
| A blog post promising universal free credits | Account-specific or provider-specific until official docs say otherwise. | Verify your console and credit balance. |
| A provider calculator with "free" usage | Separate provider contract. | Keep it out of the official xAI row. |
| A current model alias | Convenient but movable. | Pin the exact model ID for cost tests. |
This is not pedantry. A retired slug can still work while your cost assumption is wrong. Budget from current official rows and your own console behavior.
A Safe Test Plan
Before scaling Grok API usage, run a small test that matches the workload you actually want.
| Step | What to do | Pass signal |
|---|---|---|
| 1. Pin the model | Start with grok-4.3 or the exact row you intend to test. | Logs show the expected model ID and team/account. |
| 2. Set a spend stop | Use prepaid credits and a low postpaid limit. | A runaway test cannot create a large invoice. |
| 3. Run a representative sample | Use real prompts, retrieval, tools, and output format. | The sample resembles production work. |
| 4. Track successful-task cost | Count accepted outputs, retries, tool calls, and review time. | Cost per accepted result is clear. |
| 5. Compare alternatives | Test a smaller row, batch mode, cache, or fewer tools where quality allows. | The cheaper route still passes quality. |
| 6. Scale gradually | Raise limits only after logs match the worksheet. | Spend, quality, latency, and failure rate remain stable. |
For model-migration decisions rather than budget decisions, use the Grok 4.3 API guide for model IDs, aliases, migration timing, and rollout testing. Keep the pricing worksheet focused on cost and workload behavior.
FAQ
How much does Grok API cost?
As checked on July 2, 2026, xAI Docs list grok-4.3 at $1.25 input, $0.20 cached input, and $2.50 output per 1M tokens. Real cost also depends on output length, cache hits, tool calls, batch or priority mode, storage, retries, and your account limits.
Is Grok API free?
Public xAI docs checked on July 2, 2026 do not guarantee a permanent official free API tier. The quickstart says to load credits to start using the API. Some accounts or providers may have credits or free routes, but those are separate from the official xAI price row and must be verified in your own console or provider contract.
Which Grok model should I budget for first?
For general current Grok API work, start with the official grok-4.3 row unless your console and workload point to another available model. If you test grok-build-0.1 or a specialized grok-4.20 row, keep quality, availability, and output behavior in the worksheet, not just base token price.
Why is cached input cheaper?
Cached input discounts repeated prompt content when cache behavior applies. It is useful for stable system prompts, policy blocks, or repeated instructions, but it is not automatic savings. Measure cache hits before lowering your budget.
Do tools change Grok API pricing?
Yes. xAI lists separate tool-call prices for Web Search, X Search, Code Execution, File Attachments search, and Collections Search/RAG. If a workflow uses those tools, include them in the cost formula.
Should I use Batch API?
Use Batch only when the job is not latency-sensitive. xAI lists 20%-50% token discounts for eligible text/language model batch work, typically within 24 hours, but image and video generation through Batch may still be billed at standard rates.
What is the biggest budget mistake?
The biggest mistake is copying a single token row and calling it the budget. The safer budget is successful-task cost: official row plus workload tokens, cache behavior, output length, tools, retries, storage, batch or priority mode, and the spending limits in your xAI team console.