
As of May 7, 2026, xAI docs list grok-4.3 as an API model, so treat Grok 4.3 as a route-and-test decision before you change a production default.
| If you came here to... | Current answer | Do this next |
|---|---|---|
| Call Grok 4.3 through an API | Use the xAI API contract, not Grok chat or social beta screenshots. | Start with grok-4.3, then verify grok-4.3-latest and grok-latest only if aliases fit your release policy. |
| Estimate price | xAI docs list input, cached input, and output prices per 1M tokens, with higher-context caveats above 200K tokens. | Model successful-task cost, including cache rate, long context, tools, retries, latency, and human review. |
| Migrate older Grok traffic | xAI's migration notice says older Grok API models retire on May 15, 2026 at 12:00pm PT. | Inventory calls, run compatibility checks, pilot Grok 4.3, and keep rollback until quality and cost hold. |
| Decide whether Grok 4.3 is better | Benchmarks and social reactions are useful test signals, not deployment proof. | Run the same prompts, files, tools, budget, and scoring against your current default before switching. |
The official contract sources for this first pass are xAI's Grok 4.3 model page, xAI's model list, and xAI's May 15 migration note. Those pages own model identifiers, aliases, context, listed price rows, and retirement timing; providers, Reddit, X posts, videos, and press coverage only help decide what to test.
The stop rule is simple: do not promote Grok 4.3 to a default because it is new, cheap on a base price row, or strong in one benchmark. Promote it only after the same-task pilot beats your current route on quality, latency, total cost, failure rate, and review time.
Start With The Official xAI Contract
The useful Grok 4.3 question is not "is the model real?" The useful question is "which contract can I safely build against today?" For API work, that contract is xAI's developer documentation and console behavior. The Grok 4.3 model page is the source of record for the model ID, aliases, context window, regions, and rate-limit surface. The broader models and pricing page is the source to recheck before quoting prices or tool costs. The May 15 migration guide owns the retirement deadline for older Grok API models.
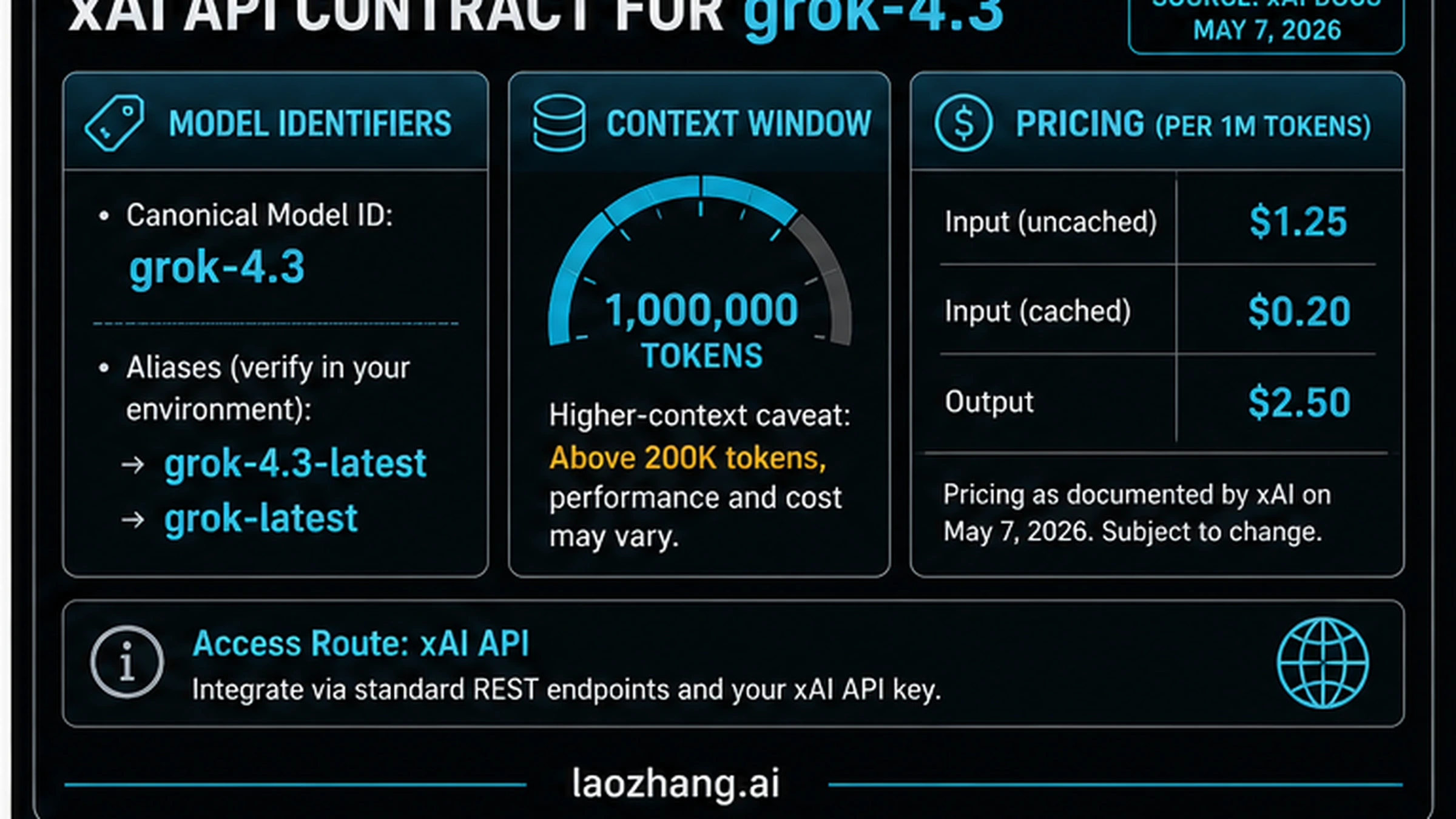
| Contract item | What to use on May 7, 2026 | Why it matters |
|---|---|---|
| Model ID | grok-4.3 | Pin this when reproducibility matters. |
| Aliases | grok-4.3-latest, grok-latest | Useful for experiments, risky for production defaults unless you want automatic movement. |
| API route | xAI API and xAI-compatible OpenAI client configuration | Do not confuse this with Grok chat, X Premium, SuperGrok, OpenRouter, or a provider wrapper. |
| Context window | 1M tokens listed for the model | Long context still needs cost, latency, and quality measurement. |
| Higher-context caveat | pricing and behavior can change above 200K tokens | Long prompts can move the real cost even when the base row looks cheap. |
| Regions and limits | check the model page and console | Account, region, team, and tier can change what your code can actually call. |
This contract-first framing keeps the decision honest. Social cards and forum threads can show that people are discussing Grok 4.3, but they do not decide your endpoint, rate limits, billing surface, or rollout deadline. If you need a universal model comparison, use the sibling guide to Grok 4.3 vs Claude Opus 4.7 vs GPT-5.5. The Grok-specific job is narrower: verify the xAI route before spending engineering time.
Use The Exact Model String Before Aliases
Start production tests with grok-4.3. That gives you the clearest audit trail when you compare outputs, costs, failures, and support evidence. Aliases are convenient for exploration because they can track the current active version, but that same convenience is a liability in a controlled rollout. If an alias moves, the model behavior can move while your code still looks unchanged.
Use this simple policy:
| Environment | Model label policy | Reason |
|---|---|---|
| Local experiment | grok-4.3 or grok-4.3-latest | Fast iteration is acceptable if results are not production evidence. |
| Eval harness | grok-4.3 | You need stable before/after comparisons. |
| Staging rollout | grok-4.3 plus console verification | You need the same ID, account, region, and limits that production will use. |
| Production default | pinned model ID unless a release policy approves aliases | Hidden alias movement can look like a regression in your app rather than a model change. |
Record the model label in logs alongside request ID, region, prompt version, input size, cached-input rate if available, output tokens, tools used, retry count, and latency. If a support case or rollback happens later, that log record is more useful than a broad statement that "Grok 4.3 failed."
API Call Path And Minimal Request
xAI's quickstart shows both native xAI usage and OpenAI-compatible client configuration. If your existing stack is built around OpenAI-style clients, the practical route is to keep the client shape but point it at xAI's base URL and use an xAI key. Recheck the current quickstart before copying code into a production service because SDK snippets and recommended endpoints can change.
A minimal OpenAI-compatible request shape looks like this:
pythonfrom openai import OpenAI import os client = OpenAI( api_key=os.environ["XAI_API_KEY"], base_url="https://api.x.ai/v1", ) response = client.chat.completions.create( model="grok-4.3", messages=[ { "role": "user", "content": "Summarize the migration risk in three bullets.", } ], ) print(response.choices[0].message.content)
Keep the first call boring. Do not combine a new model, a new prompt, a new agent framework, a new tool stack, and a production traffic switch in one move. First prove that your key, endpoint, model string, organization or team, region, quota, timeout, and logging work. Then add your real prompt and tools.
Before you let Grok 4.3 into a service, verify this checklist:
| Check | Pass signal |
|---|---|
| Key and base URL | One request succeeds from the same runtime that will call production. |
| Model ID | Logs show grok-4.3, not an accidental alias or provider remap. |
| Account route | The request is billed and rate-limited by the intended xAI team or project. |
| Timeout and retry | Failures are bounded; retry loops cannot multiply cost silently. |
| Output schema | The model satisfies the format your downstream code expects. |
| Observability | Request ID, tokens, latency, status, and tool use are captured. |
Pricing Is Not The Same As Successful-Task Cost
As of the May 7, 2026 evidence pass, xAI docs list a base Grok 4.3 row of $1.25 input, $0.20 cached input, and $2.50 output per 1M tokens. That row is useful, but it is not enough to decide a migration. A lower base price can lose if the model needs more retries, longer prompts, heavier human review, or paid server-side tools.
Use the price row as the starting point for a ledger:
| Cost variable | What to measure | Why it can change the decision |
|---|---|---|
| Input tokens | prompt, context, retrieved files, logs, policies | Long prompts can dominate repeated tasks. |
| Cached input | repeated prefixes and cache-hit behavior | A model with better cache economics can win high-volume workflows. |
| Output tokens | final answer, tool summaries, JSON, reasoning-visible text if charged | Output-heavy tasks can erase input savings. |
| Long context | whether the request crosses the 200K-token caveat zone | Large evidence packs can change price and latency. |
| Server-side tools | Web Search, X Search, or other xAI tool invocations | Realtime value may depend on tools that are not free text generation. |
| Retries | failed attempts, timeout retries, schema repair attempts | A cheap model is expensive if it needs three attempts. |
| Human review | minutes to accept, repair, or reject the result | For coding and operations, reviewer time often beats token price. |
Successful-task cost is the number to compare. For a support bot, that may be one resolved ticket. For a coding agent, it may be one merged change. For research, it may be one correct evidence packet. If Grok 4.3 costs less per accepted result and keeps quality stable, it deserves more traffic. If it saves tokens but increases review or rollback work, the base row is misleading.
May 15 Migration Plan
The May 15 date matters because it turns Grok 4.3 from a launch-week curiosity into an operations task for teams that already use older Grok API models. xAI's migration notice says older Grok API models retire on May 15, 2026 at 12:00pm PT. Treat that as a deadline to inventory, test, and stage changes rather than a reason to rush a blind default switch.
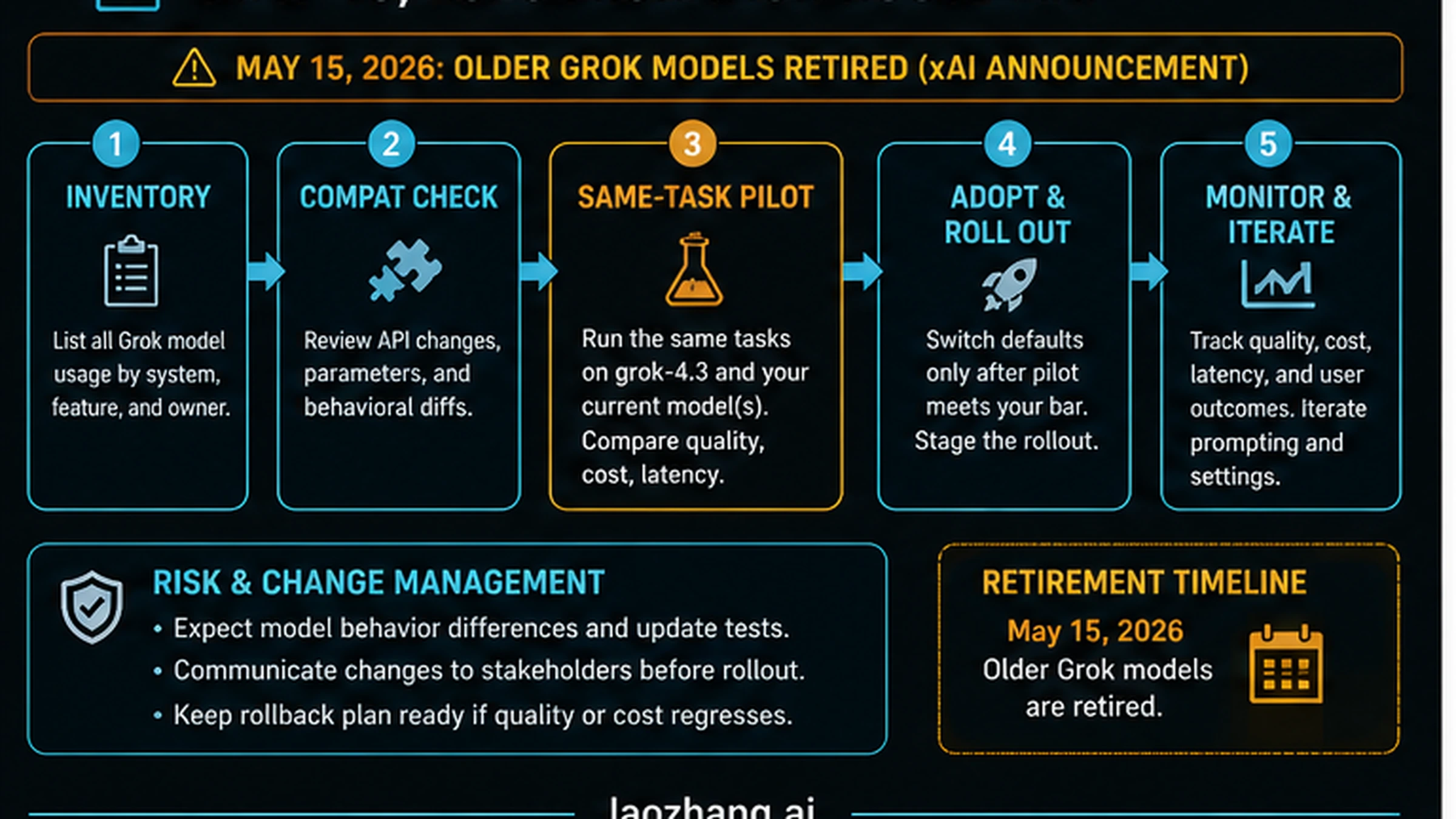
| Migration step | What to do | Evidence to keep |
|---|---|---|
| Inventory | Find every Grok model call by service, owner, model string, alias, prompt, tool use, and traffic class. | A list of call sites and owners. |
| Compatibility check | Run the same prompts through grok-4.3 and compare parameters, response shape, schema behavior, and error handling. | Diff logs and failing examples. |
| Same-task pilot | Test representative production tasks before default routing changes. | Quality scores, latency, cost, and reviewer notes. |
| Staged rollout | Move low-risk traffic first, then increase only when metrics hold. | Traffic percentage, failure rate, and rollback triggers. |
| Monitoring | Watch cost, latency, output quality, user complaints, and support logs after the switch. | A post-change scorecard. |
Do not let the deadline erase rollback discipline. A migration that changes model behavior, prompt handling, tool use, or output format can break downstream systems even when the API call itself succeeds. Keep the old route available for rollback until the new route has survived the tasks that matter.
Benchmarks And Social Claims Are Test Signals
Public discussion around Grok 4.3 already mixes official docs, Reddit API discussion, social clips, video reactions, Artificial Analysis, press coverage, provider pages, and Hacker News. That mix is exactly why a deployment decision should not crown a universal winner. Market chatter shows demand and confusion; it does not replace a same-task pilot.
Use third-party sources this way:
| Source type | Good use | Unsafe use |
|---|---|---|
| xAI docs | model ID, API route, aliases, context, listed price, migration timing | durable claims without a final recheck |
| xAI status | live incident or service availability caveat | uptime guarantee |
| Artificial Analysis and benchmark pages | decide which task types deserve pilot coverage | declare that Grok 4.3 wins your workload |
| VentureBeat and press | understand launch framing and market claims | treat reported price or benchmark claims as the contract |
| Reddit, X, YouTube, Hacker News | identify confusion, common questions, and beta/API mixups | source production facts |
| Provider listings | detect third-party availability options | present provider route as official xAI API truth |
Benchmarks are still useful. If a public test says Grok 4.3 is strong at reasoning, include reasoning tasks in your pilot. If a discussion says it is cheaper, include total cost. If a video claims it is better at fresh web questions, include a search-tool task and measure citation quality. The mistake is not reading benchmarks; the mistake is treating them as your deployment proof.
Same-Task Pilot Before You Switch
A fair pilot keeps everything constant except the model route. Use the same prompt, same input files, same retrieval set, same tools, same output schema, same timeout, same retry rule, and same scoring. Otherwise you are testing the surrounding system more than Grok 4.3.

| Pilot lane | Minimum test | Stop rule |
|---|---|---|
| Quality | Compare accepted answers, factual errors, reasoning gaps, and missing constraints. | Do not switch if reviewers repair more Grok outputs than the incumbent. |
| Tool use | Test function calls, JSON mode, retrieval, search, and failure recovery. | Do not switch if tool errors are harder to detect or recover. |
| Long context | Include tasks near normal, high, and above-200K context sizes if applicable. | Do not switch if recall or latency collapses in the context band you need. |
| Cost | Count input, cached input, output, tools, retries, and review minutes. | Do not switch from base token price alone. |
| Latency | Record median, p95, and timeout behavior under realistic load. | Do not switch if slow tails harm the product experience. |
| Stability | Run the same task multiple times and across traffic windows. | Do not switch if variance is worse than your product can tolerate. |
The pilot result should produce one of three decisions:
- Adopt Grok 4.3 for a narrow route where it clearly wins.
- Keep the incumbent default and use Grok 4.3 only for a measured fallback or special workload.
- Continue testing because the data is promising but not safe enough for production.
That is a stronger outcome than a yes/no answer. It tells the team where Grok 4.3 belongs, which risks remain, and what evidence would justify more traffic later.
When To Use A Comparison Page Instead
The Grok-specific decision is intentionally not a broad model ranking. Use this route when your task is xAI API availability, model IDs, listed pricing, migration, and Grok-specific pilot design. If your real question is "which frontier model should I try first across vendors," read the route-first comparison of Grok 4.3, Claude Opus 4.7, and GPT-5.5.
The split matters. A Grok-only page can go deep on xAI aliases, migration timing, higher-context caveats, and server-side search cost. A comparison page should decide first-test routes across OpenAI, Anthropic, and xAI. Mixing both jobs into one article would make the opening slower and the recommendation less useful.
FAQ
Is the model available through the xAI API?
Yes, xAI docs list grok-4.3 as an API model as of May 7, 2026. Recheck the model page and console before production because model availability, aliases, regions, limits, and account access can change.
Which model string should I use?
Use grok-4.3 when reproducibility matters. Treat grok-4.3-latest and grok-latest as aliases that require a release policy because they may move to a newer active model.
Is API access free?
For the xAI API contract, do not treat Grok chat or consumer subscriptions as the same surface. The API docs list token prices, so do not assume API use is free. If you are asking about Grok app access, SuperGrok, or X Premium, verify that separate product surface.
What is the listed API price?
The May 7 evidence pass found xAI docs listing $1.25 input, $0.20 cached input, and $2.50 output per 1M tokens for the base Grok 4.3 row, with higher-context caveats above 200K tokens. Recheck xAI docs before quoting this in a budget because pricing is volatile.
Does the model support a 1M context window?
xAI docs list a 1M-token context window for Grok 4.3. That does not mean every long-context job is cheap or stable. Measure quality, latency, and price when your workload crosses large context sizes, especially above the 200K caveat zone.
Should older Grok API traffic move here?
If your system uses older Grok API models affected by the May 15, 2026 retirement notice, you need a migration plan. Inventory call sites, test compatibility, run a same-task pilot, stage rollout, and keep rollback until metrics hold.
Is it better than GPT-5.5 or Claude Opus 4.7?
Not universally. Grok 4.3 is the xAI route to test for API access, realtime/X freshness, lower listed price pilots, and long-context experiments. GPT-5.5 and Claude Opus 4.7 have different route strengths. Use the sibling comparison when cross-vendor first-test choice is the real job.
What should I verify before switching production defaults?
Verify the model ID, endpoint, key, account, region, quota, price, context size, tool cost, retry behavior, output schema, latency, and reviewer acceptance rate. Then switch only if Grok 4.3 wins the same-task pilot against your current default.