As of Apr 24, 2026, this is not a symmetric four-model API contest. Test Kimi K2.6 first when you need low-cost coding-agent pilots, use the current DeepSeek V4 Flash or V4 Pro API lane when the job is cheap callable DeepSeek work, keep GPT-5.5 inside ChatGPT or Codex until OpenAI publishes a production API contract, and use Claude Opus 4.7 first when correctness and long-context reliability cost more than tokens.
The stop rule is simple: do not replace your default model from a price row or a benchmark screenshot. Run the same task through the candidate route and your current production route, keep the same repo snapshot, prompt, tools, and tests, then compare defects, reviewer time, latency, retry cost, and rollback risk.
| Route | Test first when | Official boundary | Do not do this |
|---|---|---|---|
| Kimi K2.6 | Cost-sensitive coding-agent pilots or high-volume experiments need a serious cheap route. | Moonshot lists kimi-k2.6, 262,144 context, and RMB token pricing. | Do not call it the production default until it survives the same workflow. |
| Current DeepSeek API | You want cheap callable DeepSeek work today. | DeepSeek's current public API docs point to deepseek-v4-flash and deepseek-v4-pro; V2 is stale bridge language. | Do not build a 2026 deployment decision around the V2 label. |
| GPT-5.5 | You work inside ChatGPT or Codex and want OpenAI-native behavior. | OpenAI developer docs still keep the current API examples on GPT-5.4 and say GPT-5.5 API availability is coming. | Do not invent a GPT-5.5 API model ID or price row. |
| Claude Opus 4.7 | Correctness, long context, review cost, or production rollback risk matters more than the token bill. | Anthropic lists claude-opus-4-7, 1M context, and Opus pricing. | Do not switch away without a same-task dual-run. |
The Fast Answer
The useful first choice is a route, not a universal winner. Kimi K2.6 is the first cheap pilot route. The current DeepSeek API lane is the first DeepSeek route to test if you need a low-cost callable endpoint. GPT-5.5 is the first OpenAI-native route to try inside ChatGPT or Codex. Claude Opus 4.7 remains the first production API route when hidden defects, long context, and rollback risk are more expensive than the model bill.
That split matters because the four names do not represent the same kind of deployable surface. Kimi and DeepSeek can be evaluated as API cost routes, but DeepSeek V2 is not the current public API lane. GPT-5.5 can be evaluated in OpenAI surfaces, but the callable production API contract must be rechecked before server-side traffic moves. Opus 4.7 is already a premium Anthropic API and cloud route.
Use this working order:
| Need | First route | Why |
|---|---|---|
| More cheap coding-agent attempts | Kimi K2.6 | The Kimi contract makes high-volume pilots economically plausible. |
| Cheap DeepSeek API work | DeepSeek V4 Flash or V4 Pro | That is the current official API lane, while V2 is a stale label for 2026 deployment. |
| OpenAI-native coding and research | GPT-5.5 in ChatGPT or Codex | The live value is inside OpenAI surfaces until the API contract is public. |
| Production correctness and long-context reliability | Claude Opus 4.7 | The API route, model ID, context, and pricing are documented today. |
The ranking changes if your workflow changes. A team writing low-risk scaffolding may prefer Kimi first. A team running an enterprise agent against sensitive repositories may keep Opus first. A team already invested in Codex should test GPT-5.5 inside that surface before planning an API migration. A team asking for DeepSeek should compare against current V4 API rows, not the V2 label.
Official Contract Lanes
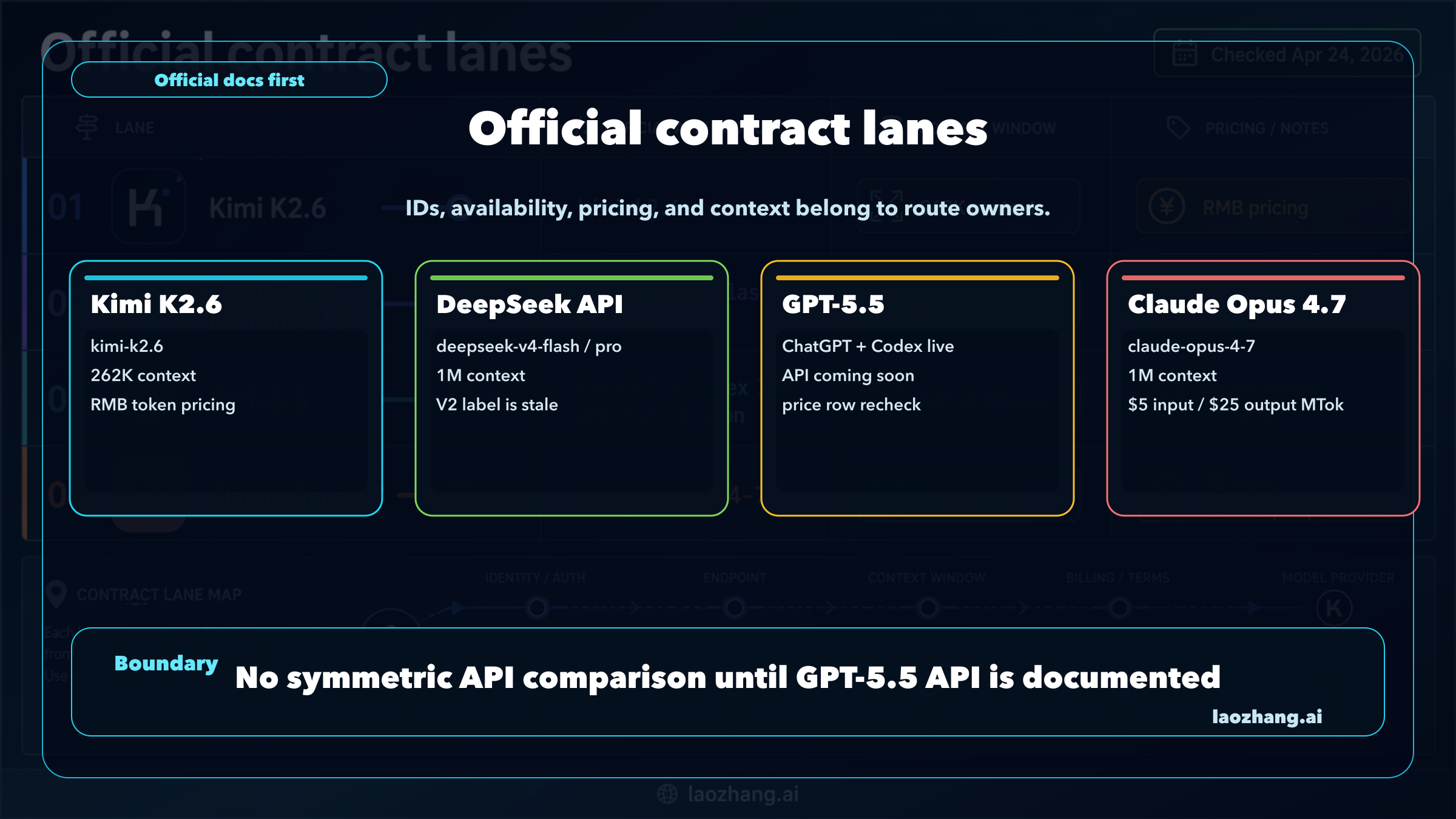
Official contract rows are the cleanest way to avoid a false comparison. Model names, context windows, price rows, and API availability belong to their owners, not to social summaries.
| Contract item | Kimi K2.6 | Current DeepSeek API | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|---|---|
| Owner route | Moonshot / Kimi platform | DeepSeek API | OpenAI ChatGPT and Codex first | Anthropic API and Claude/cloud routes |
| Current deploy label | kimi-k2.6 | deepseek-v4-flash or deepseek-v4-pro | Recheck API model ID when OpenAI publishes it | claude-opus-4-7 |
| Availability boundary checked Apr 24, 2026 | API route documented by Kimi | API route documented by DeepSeek | ChatGPT/Codex available; API availability coming | API and cloud route documented by Anthropic |
| Context route | 262,144 tokens on Kimi pricing docs | 1M context and 384K max output in current DeepSeek API docs | API context should be rechecked when live | 1M context at standard Opus 4.7 pricing |
| Pricing owner | Kimi platform lists RMB token prices | DeepSeek docs list USD token prices | OpenAI developer docs do not expose a production GPT-5.5 API row in the current model guide | Anthropic pricing docs list Opus pricing |
Kimi's platform page for kimi-k2.6 lists cache-hit input at RMB 1.10 per million tokens, cache-miss input at RMB 6.50, output at RMB 27.00, and a 262,144-token context window. Those rows make Kimi a serious candidate for cheap pilots, but they do not prove replacement quality.
DeepSeek's current API pricing docs point to deepseek-v4-flash and deepseek-v4-pro, with OpenAI-compatible and Anthropic-compatible base URLs. The same docs note that older compatibility labels such as deepseek-chat and deepseek-reasoner map into newer V4 Flash modes. That is why "DeepSeek V2" should remain bridge language, not the route name for a current deployment.
OpenAI's developer model guide currently shows GPT-5.4 API examples, while OpenAI's GPT-5.5 status in the run evidence is ChatGPT and Codex first with API availability coming. That makes GPT-5.5 worth testing in OpenAI-native work, but it makes API claims fail-closed until official API docs expose the production model row.
Anthropic's model overview lists claude-opus-4-7, and Anthropic's pricing docs list Opus 4.7 at $5 input and $25 output per million tokens with 1M context at standard pricing. Opus is not the cheapest option, but it has the cleanest production-contract story among the four routes.
Why DeepSeek V2 Is The Wrong Current API Label

DeepSeek V2 still appears in market phrasing because people remember the older model family and use the label as shorthand for "cheap DeepSeek." The deployment question in 2026 should be different: which DeepSeek route is callable, priced, and documented now?
For API work, that answer is DeepSeek V4 Flash or DeepSeek V4 Pro. V4 Flash is the cheaper general lane, while V4 Pro is the heavier route. DeepSeek's docs list 1M context and 384K maximum output for the current API rows, plus low cache-hit and cache-miss pricing. Those are the rows a buyer or developer can actually put into a pilot plan.
Keeping "DeepSeek V2" in the title is still useful because it matches the comparison language readers use. Letting it own the body would be a mistake. A clean article should translate the label once, then evaluate the current API route. That prevents two bad decisions:
- Choosing against DeepSeek because an old label looks outdated.
- Choosing DeepSeek because an old benchmark or old price row looks cheaper than the current contract.
The same boundary applies to GPT-5.5, but in the opposite direction. GPT-5.5 is current as an OpenAI product surface, yet it should not be treated as a production API route until the API model ID, price row, limits, and tool behavior are official for your account.
Price Is A Pilot Signal, Not A Replacement Verdict
Kimi and DeepSeek look attractive because cheap attempts matter in agentic work. A coding agent that can run more trials, generate more variants, and recover from more low-risk mistakes can be useful even when it is not the safest default for high-stakes work.
That is the best case for Kimi K2.6. Its official RMB pricing is low enough to justify broad pilots where attempt volume is part of the product. It also has a large enough context window for many repository and analysis tasks. If your team has many medium-risk tasks waiting behind a premium-model budget, Kimi deserves an early test.
DeepSeek's best case is current cheap API work. V4 Flash can be the first DeepSeek route when the task needs a low-cost endpoint, familiar API compatibility, and enough context to handle long inputs. V4 Pro can be tested when the job needs a stronger DeepSeek lane without jumping directly to premium Opus economics.
The trap is treating token price as total workflow cost. A cheap run is expensive if it creates hidden defects, reruns, manual review, tool loops, or rollback work. A premium run is wasteful if the task is low risk and the cheaper route passes the same tests. The real unit is not "one million tokens." It is "one accepted task after review."
Use a four-column cost log:
| Cost area | What to record | Why it matters |
|---|---|---|
| Token cost | input, cached input, output, retries, and tool calls | Separates price-list advantage from real invoice shape. |
| Quality cost | blocker defects, major defects, minor issues, and format misses | Prevents a low price from hiding review burden. |
| Time cost | wall-clock time, queue time, reviewer minutes, and reruns | Captures the operational cost of slow or unstable routes. |
| Integration cost | model ID changes, auth, context behavior, tool support, and rollback work | Stops "it worked once" from becoming a default change. |
Which Route Fits Coding Agents
For coding agents, start with the model whose route matches the task's failure cost.
Use Kimi first for low-risk batch edits, scaffolding, draft implementations, test generation, and cost-sensitive agent experiments. The goal is not to prove that Kimi beats every premium model. The goal is to find the task class where cheaper repeated attempts produce more accepted work per dollar.
Use DeepSeek V4 Flash or Pro when you want a current DeepSeek API route with explicit pricing and compatibility. It is a better test target than a stale V2 label because it represents what a developer can actually call and measure today. If the result is good, keep the DeepSeek route in the candidate pool. If the result fails on your harness, the failure is about the current route rather than an old name.
Use GPT-5.5 first inside ChatGPT and Codex when the operator experience is part of the value. Codex work often includes repository navigation, iterative edits, and review loops where the surface matters as much as the model string. GPT-5.5 can be a strong first pilot there without becoming a server-side API decision.
Use Claude Opus 4.7 first for migrations, deep refactors, security-sensitive changes, long-context reasoning, and tasks where review time dominates token spend. Opus is the premium default candidate when a hidden bug can erase the savings from a cheaper run.
The most common team policy is not one model forever. It is a router:
| Workload | Start route | Promote only if |
|---|---|---|
| Low-risk bulk changes | Kimi K2.6 | It passes tests and keeps reviewer time low across repeated runs. |
| Cheap API experiments | DeepSeek V4 Flash or Pro | It is stable on the exact endpoint, context length, and output shape needed. |
| OpenAI-native coding flow | GPT-5.5 in Codex | It reduces review time or fixes failure modes better than the current OpenAI route. |
| High-risk production changes | Claude Opus 4.7 | A cheaper route matches quality under the same harness and rollback thresholds. |
Same-Task Dual-Run Checklist

A default model switch is a production change. Treat it like one.
Build a small but unforgiving harness before changing routing. Pick five to ten tasks that already cost review time. Use the same repo snapshot, same spec, same tools, same timeout, same test command, and same reviewer. Save all model outputs and patches. Score the result by accepted diff, defect severity, tool recovery, format stability, latency, token cost, and reviewer minutes.
Then set loss thresholds before the run starts:
| Stop condition | What it means |
|---|---|
| One blocker defect | The candidate route is not safe as a default for that workload. |
| Three major defects | Keep the route in pilot mode or narrow it to lower-risk tasks. |
| Reviewer time above 2x | Token savings are probably being moved to human labor. |
| Tool or format instability | The route may work in chat but fail as an agent default. |
| Unclear API contract | Do not deploy until model ID, limits, pricing, and billing behavior are official. |
Promotion should require repeated wins. If Kimi or DeepSeek is cheaper but needs more retries, it may still win for low-risk tasks and lose for production code. If GPT-5.5 is excellent inside Codex but lacks a public API row, it can win the operator workflow and still wait for server deployment. If Opus is expensive but produces fewer hidden failures, it may remain the right premium default.
How Existing Users Should Decide
If you already use Kimi for coding-agent experiments, add DeepSeek V4 Flash and GPT-5.5-in-Codex to the pilot pool, but keep Opus as the comparator for high-risk work. The focused Kimi K2.6 vs Claude Opus 4.7 guide is better when the decision is only cheap Kimi pilot versus premium Opus default.
If you already use DeepSeek, update the evaluation language first. Compare current V4 Flash or V4 Pro against Kimi, GPT-5.5 surface tests, and Opus. Do not let an old V2 label decide the route.
If you already use OpenAI API models, keep the production baseline on the documented OpenAI API route until GPT-5.5 API access, model ID, and pricing are official. Use GPT-5.5 in ChatGPT and Codex for operator-side learning now, then move the same harness server-side later.
If you already use Claude Opus 4.7, treat Kimi, DeepSeek, and GPT-5.5 as pilot routes by workload class. Opus should keep production traffic when correctness, long context, and review cost are the reason it was chosen. The narrower GPT-5.5 vs Claude Opus 4.7 comparison is better when the only question is OpenAI surface versus Anthropic production route.
FAQ
Is Kimi K2.6 cheaper than Claude Opus 4.7?
Yes on the official token rows checked on Apr 24, 2026, but currency and route ownership matter. Kimi lists RMB token pricing for kimi-k2.6; Anthropic lists Opus 4.7 in USD per million tokens. The useful conclusion is that Kimi is worth a low-cost pilot, not that it is automatically a production replacement.
Is DeepSeek V2 still the model to compare?
Not for current API deployment. Treat "DeepSeek V2" as a market-visible bridge label and evaluate DeepSeek through the current V4 Flash or V4 Pro API route.
Is GPT-5.5 available in the API?
Use GPT-5.5 in ChatGPT and Codex where it is live, but recheck OpenAI developer docs before using it as a production API route. Do not invent a GPT-5.5 model ID or price row.
Which model should a coding-agent team test first?
Test Kimi first for cheap low-risk volume, DeepSeek V4 for cheap callable DeepSeek work, GPT-5.5 inside Codex for OpenAI-native workflows, and Opus 4.7 for high-risk production correctness. Use the same-task harness before changing defaults.
Can one model replace all the others?
No. The safer policy is route-based: cheap pilot routes for low-risk work, OpenAI-native routes for Codex and ChatGPT workflows, and premium Opus routing for workloads where hidden defects cost more than tokens.