
在 Nano Banana 2 里,image safety 不是一个开关,而是三层不同的判定合同。Gemini API 里有一层是可调的 prompt 侧安全设置;还有一层是更硬的响应层,会给出 OTHER、PROHIBITED_CONTENT、IMAGE_SAFETY 这类可见原因;Gemini Apps 之上又有一层产品级的策略移除。很多排障会走偏,不是因为模型完全不可理解,而是因为这三层经常被当成了同一个过滤器。
如果你只记住一句话,那就是:BLOCK_NONE 是一个很窄的控制项,不是总开关。它只能影响 Gemini API 里四个 prompt 侧类别;它不能改写 Google 自带的 core protections,也不能解释为什么某个任务在 Gemini Apps 里能做、到了 API 却走进更硬的拦截路径。
最快的判断方法是先确认到底是哪一层出手了:
- 如果你改
safetySettings之后,结果会跟着变化,那大概率还是可调层。 - 如果 API 暴露出
SAFETY、OTHER、PROHIBITED_CONTENT、IMAGE_SAFETY这类可见原因,把它们当成路由信号,不要当成一个模糊报错。 - 如果同一件事在 Gemini Apps 和 Gemini API 上表现不同,把 Gemini Apps 当成一个独立 surface,而不是 API 的一比一镜像。
证据说明: 本文使用了 2026 年 4 月 3 日核验过的 Gemini API 官方文档、Gemini Apps 帮助页、Gemini 3.1 Flash Image 模型卡,以及当前开发者论坛投诉帖。这个环境下的 Google 直接抓取被阻断,所以文中的搜索观察采用了 fallback 证据,而不是假装拿到了完整的 Google 页面。
Nano Banana 2 里 image safety 到底指什么
Nano Banana 2 对应的 Gemini API 模型是 gemini-3.1-flash-image-preview。Google 对它的定位是 Gemini 家族里更快、吞吐更高的图像模型。这个前提很重要,因为很多页面仍然沿用旧 Nano Banana 或 Nano Banana Pro 的安全叙事,然后把新模型写成“同样一套行为,只是更严格”。这条捷径并不可靠。
更准确的理解方式是:Nano Banana 2 里的 image safety,至少可能指向三份不同合同。
第一份合同,是 Gemini API 里可调的 prompt 侧安全系统。Google 当前公开的可调类别只有四个:harassment、hate speech、sexually explicit content、dangerous content。开发者口中的 safetySettings,通常说的就是这一层。
第二份合同,是 API 自身更硬的 block 与 response 层。公开 schema 里能看到 SAFETY、OTHER、PROHIBITED_CONTENT、IMAGE_SAFETY 这类原因。它们不是同一个拒绝的不同叫法,而是在告诉你:到底应该检查 settings、改写 prompt、把任务改掉,还是接受这件事本来就不属于当前 surface。
第三份合同,是 Gemini Apps 这个产品外壳本身。Google 当前的帮助文档明确写到了图像生成、上传图片后编辑、组合多张图片,以及带有人物的个性化使用场景;但同一份文档也明确提醒,生成图片可能因为策略原因被移除。所以 Gemini Apps 不能简单理解成“只是套了一个更好看的 API 界面”。
一旦把这三层拆开,Nano Banana 2 的安全问题就会清楚很多。你不再会问“这个 safety filter 为什么这么随机”,而会先问唯一真正重要的问题:这次到底是哪一层在做决定?
安全设置能改什么,不能改什么
围绕 Nano Banana 2 的一个最常见误解,是把 BLOCK_NONE 当成模型的关闭开关。当前 Gemini API 官方安全文档并不支持这种理解。
官方支持的说法更窄,但也更有用。Gemini API 里可调的 safety settings 只覆盖四个 prompt 侧类别:
HARASSMENTHATE_SPEECHSEXUALLY_EXPLICITDANGEROUS_CONTENT
这意味着:如果你的请求真的落在这四类阈值里,BLOCK_NONE 是有意义的;但它不是通用答案。
Google 也明确说了,core harms 会继续在这些可调项之外被拦截。所以如果你把可调阈值都放低甚至关掉了,结果还是完全不变,那强信号不是“Google 一定藏了别的秘密开关”,而是你从一开始就不在可调层里。
这也是很多 Nano Banana 2 排障讨论总在打转的原因。有人说“我已经全设成 BLOCK_NONE 了”,另一个人马上接一句“那 Google 肯定还有隐藏过滤器”。更稳妥的结论其实更简单:这个请求大概率已经跨出了可调层,进入了 BLOCK_NONE 本来就不负责的合同。
实际操作时,把 safetySettings 留给真的属于可调 prompt 侧的问题。如果返回层已经在给你别的信号,就不要继续把所有拒绝都当成 settings 问题。
怎么读 SAFETY、OTHER、PROHIBITED_CONTENT 和 IMAGE_SAFETY
把可见原因当成“下一步该做什么”的路由信号,Nano Banana 2 会比看起来容易操作得多。
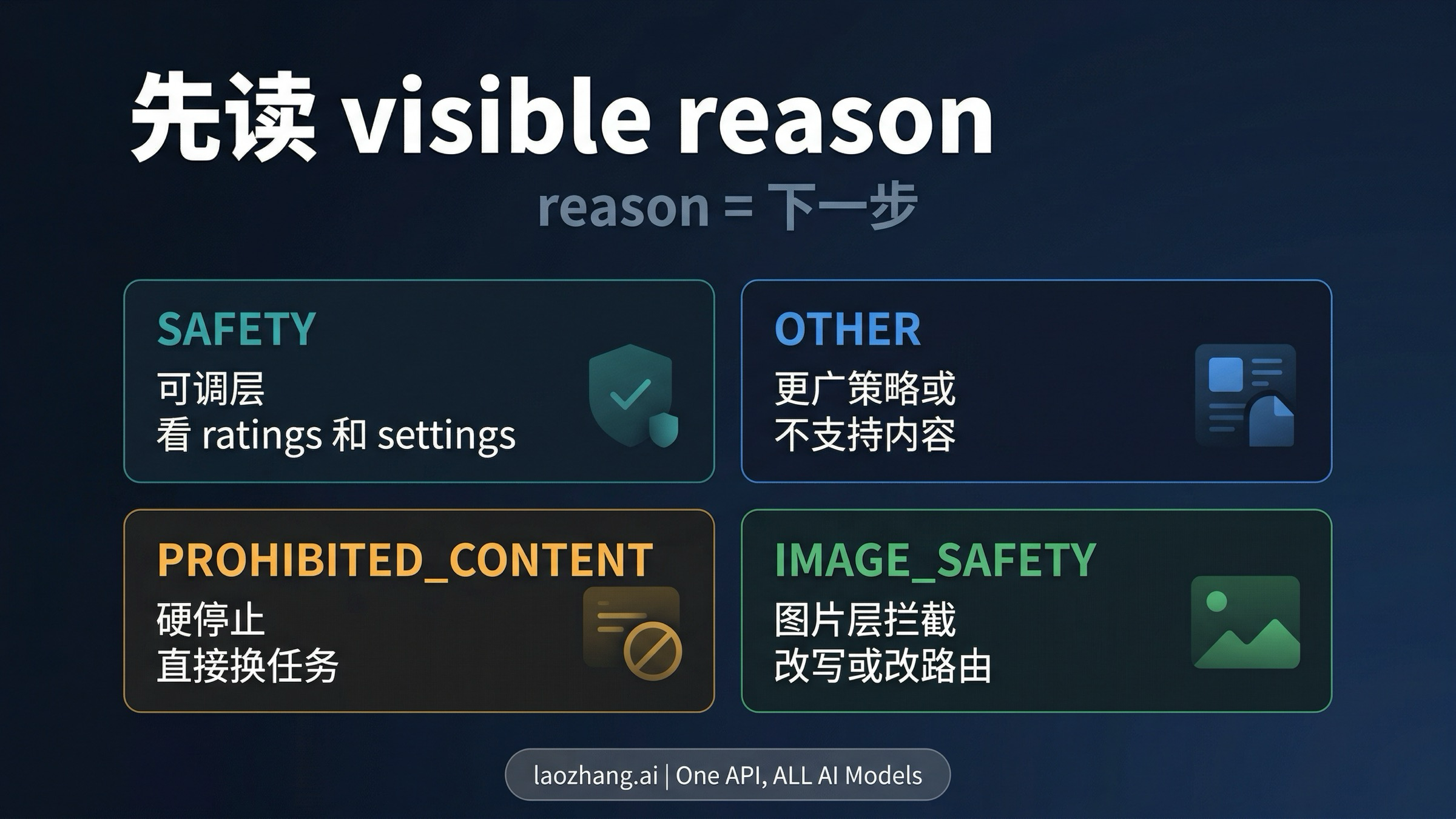
在当前 Gemini API 文档里,Google 明确公开了 SAFETY、OTHER、PROHIBITED_CONTENT、IMAGE_SAFETY 这类 block reasons。实际做图像集成时,你也可能在响应体里看到这些或非常接近的响应层原因。更稳妥的做法,是把这个可见 reason 当成路由说明,而不是把它当成一个泛化拒绝标签。
| 可见 reason | 它通常说明什么 | 下一步该做什么 |
|---|---|---|
SAFETY | 请求落入了可调安全系统。 | 看 safetyRatings,再和当前 safetySettings 对照,确认它是否真的属于那四个可调类别。 |
OTHER | 请求可能踩到了更广的策略边界,或属于不支持内容。Google 的 troubleshooting 文档明确说过,BlockedReason.OTHER 可能对应 ToS 或 unsupported content。 | 不要继续把它当成窄阈值问题。重设任务边界、简化请求,或者接受这件事不属于当前 surface。 |
PROHIBITED_CONTENT | 你已经不在“温和误判”区,而在更硬的策略区。 | 不要继续做细微改写。换任务,或者停止。 |
IMAGE_SAFETY | 图像生成安全层拦住了输出。 | 改写 prompt、改变 framing、改风格,或者转到更窄的排障路径;不要默认 settings 能解决。 |
真正关键的是最后一列。这些原因之所以有价值,是因为它们把你导向不同动作。
如果你看到 SAFETY,官方文档给的是一条 settings 路;如果你看到 OTHER,Google 已经在告诉你问题可能根本不在那四个可调类别里;如果你看到 PROHIBITED_CONTENT,更合适的动作通常是停止强推同一个任务;如果你看到 IMAGE_SAFETY,那更像是图像层拦截,而不是 settings 配错了。
这里仍然有一个边界要记住:Google 并没有公开发布每一种 IMAGE_SAFETY 或 OTHER 的细粒度触发词典。所以不要把这些标签硬解释成一份隐形内部规则书。它们是 route markers,不是完整说明书。
为什么正常 prompt 也会失败
Nano Banana 2 的安全体验之所以让人觉得不透明,一个重要原因是:合法、正常的使用场景也可能遇到摩擦。Google 开发者论坛当前仍然能看到针对时尚、生活方式等非 NSFW prompt 的误杀投诉。Gemini 3.1 Flash Image 模型卡也明确说,Google 仍在继续降低 false positives 和 false negatives,这本身就说明平衡还在调。
更稳妥的解读既不是“模型坏了”,也不是“所有投诉都是用户自己写得差”。更接近事实的说法是:公开合同仍然不完整。
举例说,一个看起来正常的 reference-image edit 也可能失败;一段服装描述可能比用户预期更容易触发安全层;某个现实人像编辑在一个 surface 上看起来合理,到了另一个 surface 却失败。这些现象都不能证明 Google 存在一份隐藏但已经坐实的官方禁止清单。它们只能证明:实际摩擦,确实比公开 taxonomy 更复杂。
这个区别很重要。因为一旦用户开始把论坛传言当成官方策略,排障质量就会迅速变差。大家会对“隐藏规则”讲得越来越肯定,却对真正能核验的文档越来越不在乎;最后做的不是排障,而是围着传闻调 prompt。
更好的流程是:记录这次失败到底是什么,减少歧义,一次只做一个明确变化。把表述从身份或身体特征导向,改成任务或场景导向。涉及人物时,先问清楚自己要的到底是写实生成、社论式插画,还是更安全的 reference transform。如果在做了这些基础清理之后仍然反复失败,诚实答案有时不是“我还没找到神奇措辞”,而是“这个 surface 现在就不支持”。
Gemini Apps 与 Gemini API
很多糟糕的安全建议,都是从把 Gemini Apps 和 Gemini API 硬压成同一种行为开始的。

当前 Gemini Apps 帮助文档并不支持这种简化。Google 现在明确把 Nano Banana 2 在 Gemini Apps 里的能力写成:可以生成图片、编辑上传图片、组合多张图片,也可以做带人物的个性化场景。这已经足够推翻“Nano Banana 2 完全不允许人物图像”的一刀切说法。
但同一份帮助文档也同时提醒:当系统检测到可能的策略问题时,图片可能被移除。关键就在这里。产品层支持某项能力,不等于每个请求都会通过;而 app 里的策略移除,也不等于 API 文档里的某个 response reason。
这就是为什么跨 surface 的经验贴特别容易误导。一个人说“我在 Gemini 里做出来了”,另一个人说“同样概念在 API 里被拦了”,两者完全可能同时成立。外壳、moderation path、面向用户的提示方式,以及最终执行时点,本来就不是同一套东西。
对于真正做集成的人,结论很实际。如果你的任务更像消费级编辑或个性化图像操作,Gemini Apps 可能更适合作为“当前支持到哪里”的参考 surface;如果你的任务是生产级 API 集成,就应该从 API 文档和响应合同出发,而不是从 app 截图和论坛经验出发。两者相关,但不能互相替代。
什么时候该改路由,而不是继续重试
围绕 Nano Banana 2 image safety,最有用的习惯之一,就是知道什么时候“再试一次”其实只是浪费时间。

如果你遇到的是 200 OK 但没有可用图片,或者响应路径里出现了明确的 IMAGE_SAFETY,那就该转到更窄的这篇:Nano Banana 2 返回 200 OK 但没有图片。这是一个很具体的操作性故障,不适合继续在这里泛泛分析。
如果失败组合里混着 quota exhaustion、参数错误、服务不稳定等更广问题,而不是一个明确的 safety block,那更应该走总排障页 Nano Banana 2 不工作怎么办。安全分析并不能修好 429、bad parameter 或临时服务故障。
如果你的真实问题是:Nano Banana 2 到底能不能稳定处理人物、肖像、个性化编辑,那更适合看更窄的 Gemini 图像生成人物限制。那篇文章聚焦的是人物图像这条支线,而不是让当前这页扛下所有限制叙事。
如果你的工作重点不是“理解 Google 的安全合同”,而是“把图像生成能力稳定接到一个统一 app 或 API 层里”,那更相关的路由可能是 Nano Banana AI 图片生成器 这类更宽的工具层。它不会移除 Google 模型内部的策略限制,但可以减少 provider 切换和 fallback 路由上的操作混乱。
更大的结论是:很多时候,正确动作是 route,而不是再 retry 一次。把 Nano Banana 2 image safety 看成“先识别合同,再选动作”的问题之后,很多无效重试都会自然消失。
FAQ
BLOCK_NONE 会关闭 Nano Banana 2 的全部安全过滤吗?
不会。当前 Gemini API 文档支持的是更窄的说法:BLOCK_NONE 只会改变四个 prompt 侧类别的阈值。它不会移除 Google 自带的 core protections,也不会把 app 层策略行为压缩成同一套规则。
image safety 是否意味着 Nano Banana 2 完全做不了人物图像?
不是。当前 Gemini Apps 帮助页明确展示了带人物的个性化图像与图像编辑使用场景。更稳妥的说法是:涉及人物的请求处在更敏感的区域,而且 Gemini Apps 与 Gemini API 的表现不一定一样。
每一个 IMAGE_SAFETY 拦截都会计费吗?
更稳妥的做法,是把已经被处理过的图像生成拦截视为“可能计费”,除非官方 surface 明确说不会。Google 公布了 Nano Banana 2 当前的 token 计价,但在这次研究里,并没有找到一句能覆盖所有 IMAGE_SAFETY 情况的官方统一说法,所以这篇文章刻意避免把计费结论说得比官方文档更绝对。
排查 Nano Banana 2 image safety 最简单的办法是什么?
先识别合同。先问自己:这是 Gemini API 可调的 safety settings 问题,还是更硬的 API 响应原因,还是 Gemini Apps 的产品层策略行为?如果你连层级都没认出来,后面的排障基本就是猜。
Nano Banana 2 并不存在一个统一的 image-safety filter。它存在的是几份共享同一个模糊说法的合同。把这些合同拆开以后,很多无效重试都会少得多。