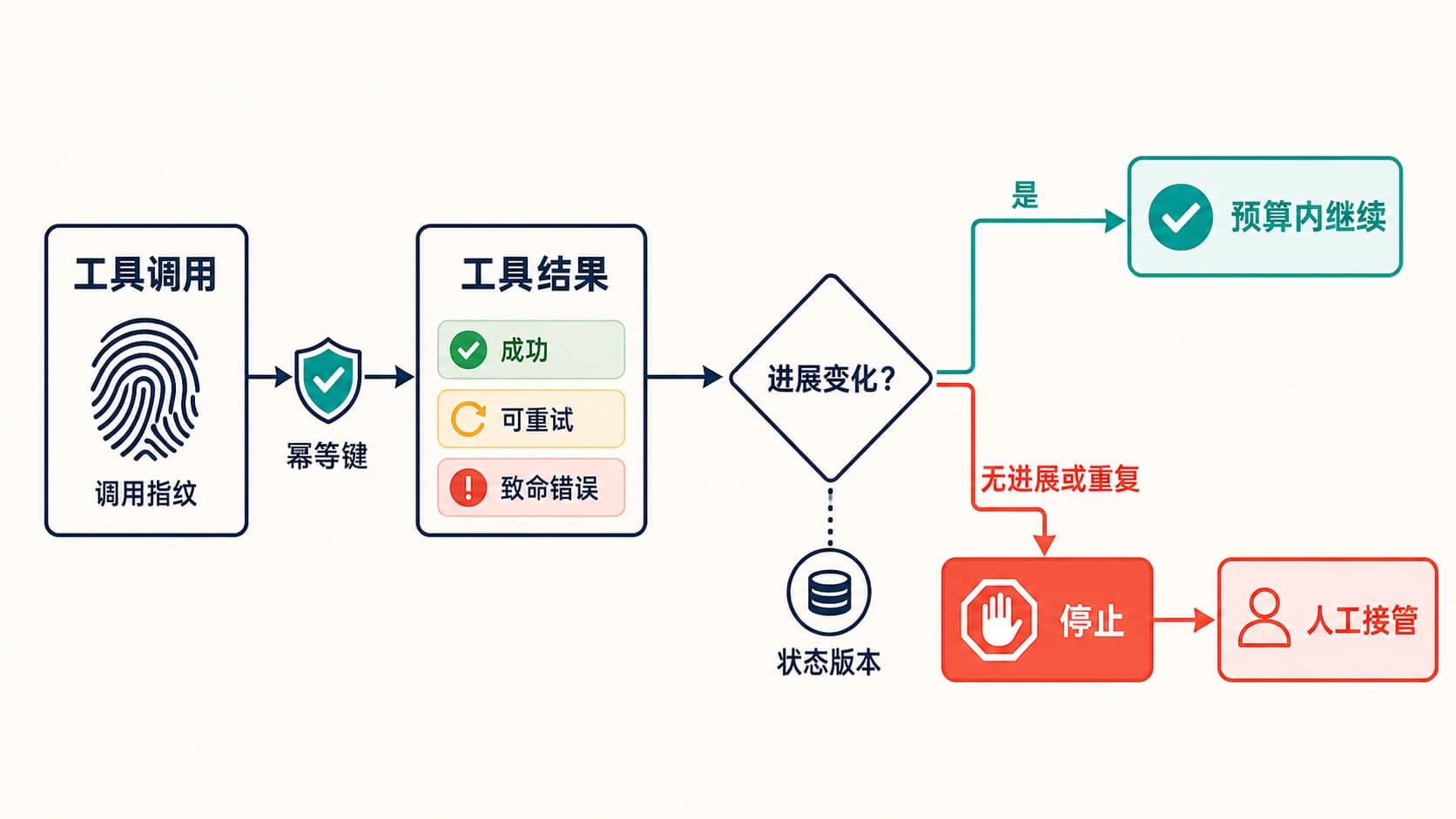
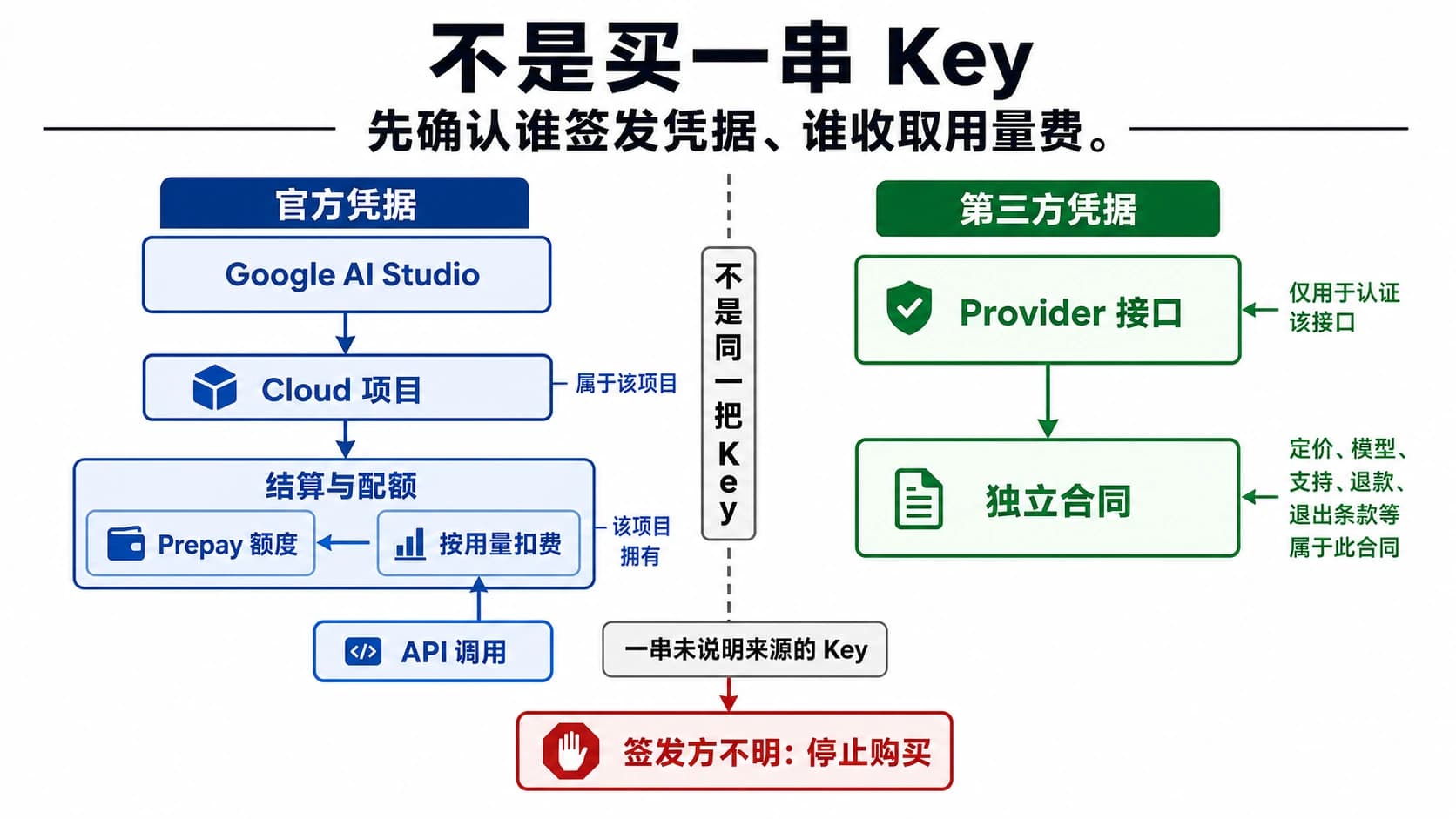
LLM Agent 的 API 花费熔断开关必须在供应商调用离开你的系统之前运行。只在后台设置月度预算、邮件提醒或用量看板,不能阻止一个正在循环、重试、调用工具或拉起子 Agent 的任务继续消耗余额。
最低可用设计是:先按本次请求允许产生的最大成本做估算,再在共享账本里原子预留这笔额度;只有预留成功,才允许请求进入 OpenAI、Anthropic、网关或其他付费模型路径;响应结束后用真实 usage 对账并释放多余预留。一旦预算会被打穿,Agent 收到的是不可重试的 over_budget,而不是普通 429、timeout 或可绕行错误。
| 控制项 | 能阻止什么 | 在花费熔断里的角色 |
|---|---|---|
| 预算提醒或邮件 | 人没及时看到账单变化 | 软提醒;请求通常还能继续 |
| 供应商或项目额度 | 供应商侧的账户治理 | 有价值的后备,不是 Agent 的第一道闸 |
| AI 网关预算 | 所有流量都经过同一网关时的统一拦截 | 可以变成硬停,但必须关闭绕行路由 |
| 请求前预算闸门 | 下一次付费模型请求 | 自主 Agent 的主熔断点 |
停止规则很简单:一旦预算闸门返回 over_budget,主 Agent 不能重试,不能拉起助手,不能切到另一把付费 key,也不能让工具函数继续发起模型请求。除非有人显式改预算、改策略并记录覆盖理由,否则这个 run 到此停止。
真正的花费熔断是什么
花费熔断不是一个漂亮的用量图,也不是账单接近上限时发给管理员的邮件。对 LLM Agent 来说,真正的熔断点必须有权拒绝下一次付费模型调用。这个控制点可以在 Agent runtime、内部 OpenAI 兼容代理、共享 AI 网关、供应商 wrapper 或边车服务里,但它必须控制 Agent 实际使用的 credential path。
常见事故不是团队不知道要控成本,而是控错了层。主 planner 走了预算检查,检索工具却直接拿 provider key;文本模型走了代理,评估器或图片工具却使用了 emergency fallback key;主 Agent 收到错误后停止,子 Agent 队列还在消费任务。这些都不是熔断,只是部分观察。
如果 Agent 已经在重复调用工具,先用 AI Agent 工具循环排障指南判断属于原样重试、短周期还是无进展循环,并在下一次危险调用前阻断,不要只把它当作花费问题。
运行手册里要把四个词分开:
| 词 | 应该表示 | 不应该表示 |
|---|---|---|
| 花费上限 | 美元、人民币或账户币种里的成本 ceiling | 每分钟 token 吞吐 |
| 速率限制 | 单位时间的请求数、token 数或图片数 | 月度总成本 |
| 软预算 | 提醒、报表、阈值和人工治理 | 调用前硬拦截 |
| 硬停止 | 付费工作开始前被拒绝的请求 | 调用之后才出现的邮件或看板 |
这套词表会改变排障顺序。处理失控 Agent 时,第一问不是哪个后台有 budget 字段,而是哪一个组件能拦下下一次付费请求。
选择控制层
生产环境最稳的方案是分层:请求路径里的预算闸门做主控,供应商、平台和看板做后备。不要把所有控制都叫做 kill switch,它们负责的失败模式并不一样。

| 层 | 擅长 | 弱点 | 建议定位 |
|---|---|---|---|
| Agent 循环上限 | 防止无限 plan、过多 tool step、过长 wall-clock | 不知道最终供应商账单 | 本地安全护栏 |
| 单次 token 上限 | 限制单次请求最坏成本 | 挡不住很多小请求累积 | 调用形状护栏 |
| 请求前花费闸门 | 在请求出站前阻止下一次付费工作 | 需要共享账本和统一路由 | 主熔断点 |
| 网关预算 | 跨 key、团队、供应商或模型做统一控制 | 绕过网关的流量会漏掉,并发一致性要测试 | 共享控制面 |
| 供应商或项目额度 | 账户级治理和供应商侧策略 | 可能是软阈值、延迟执行,且不懂 Agent 重试语义 | 后备 |
| 提醒与审计日志 | 发现、通知、复盘 | 不一定能阻止下一次调用 | 可观测性 |
如果你已经有 OpenAI 兼容代理,把预算检查放在代理层通常最省力,因为 SDK 只要换 base URL 就能复用。若 Agent runtime 是唯一知道所有模型调用和工具调用的地方,就先在 runtime 放闸门,并要求所有子 Agent 通过同一预算 scope。若你同时接多家供应商,网关或内部代理比在每个 worker 里复制预算逻辑更容易审计。
错误设计是半截闸门。主 planner 受控,retrieval evaluator、image generator、fallback key 或批处理 worker 不受控,事故时账单仍会从旁路流出。熔断图上每条能花钱的边都必须指向同一类预算决策。
实现预留、调用、对账
可落地的模式是一个保守的预飞行预留账本。你在调用前不知道最终费用,所以预算闸门先按最坏合理情况锁住额度,再在响应回来后按真实 usage 对账。
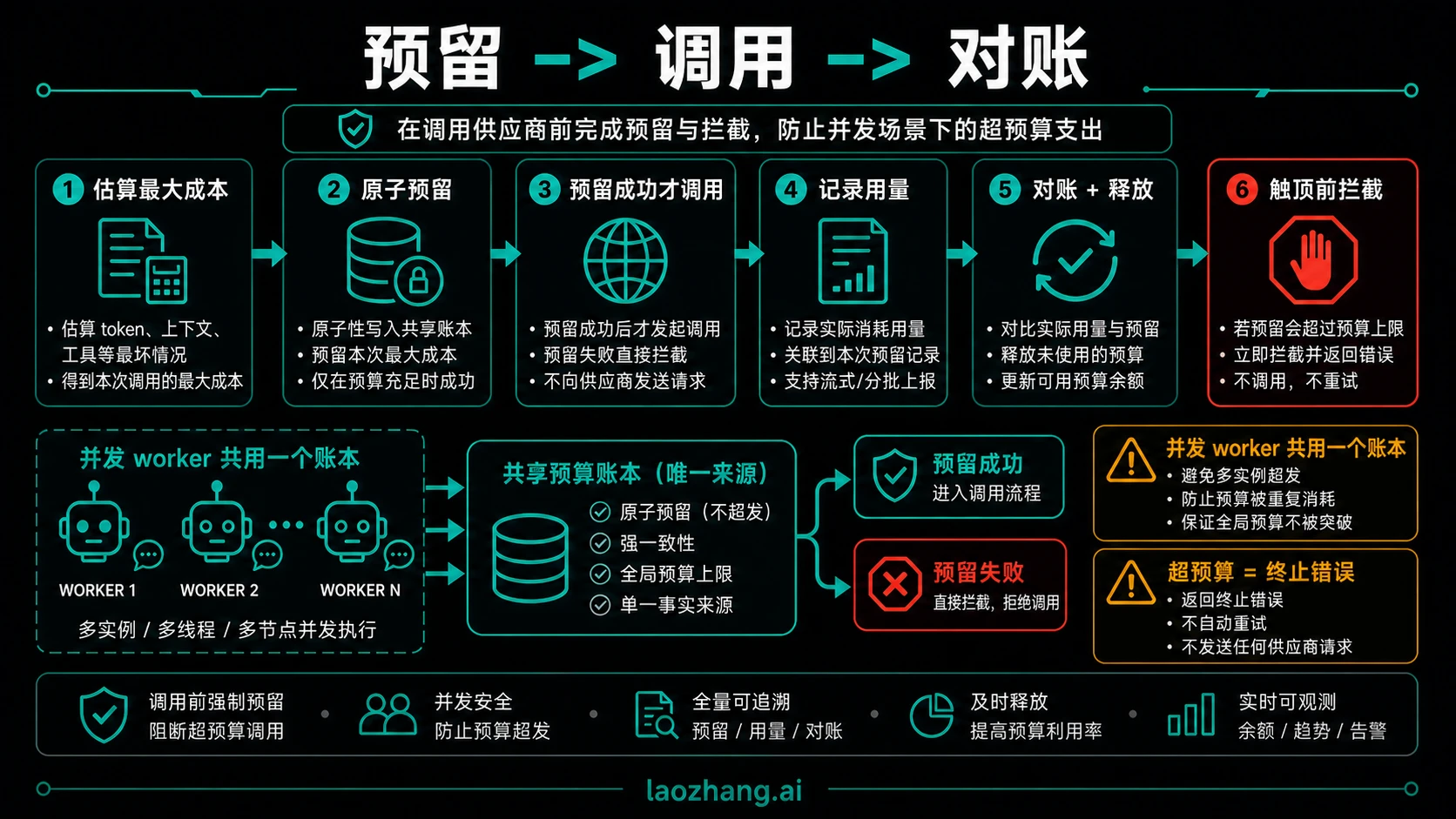
最小账本字段如下:
| 字段 | 用途 |
|---|---|
| budget_id | 拥有上限的团队、用户、项目、Agent 或 run |
| limit_amount | 这个周期或任务允许的最大花费 |
| reserved_amount | 已经被在途请求预留的金额 |
| actual_amount | 已完成请求按 usage 对账后的真实花费 |
| period_start / period_end | 日、月或 run 级预算窗口 |
| request_id | 关联预算决策和供应商日志 |
| agent_run_id | 把 planner、worker、子 Agent、工具调用归到同一任务 |
| decision | allowed、blocked、reconciled 或 released |
| reason | 触顶、缺少估算、未知模型、人工覆盖或策略阻断 |
调用前流程不复杂:
tsasync function guardedModelCall(request) { const estimate = estimateWorstCaseCost(request); const reservation = await ledger.reserveAtomically({ budgetId: request.budgetId, requestId: request.requestId, agentRunId: request.agentRunId, amount: estimate, }); if (!reservation.allowed) { return { error: "over_budget", retryable: false }; } const response = await provider.responses.create(request.payload); await ledger.reconcile({ reservationId: reservation.id, actualAmount: costFromUsage(response.usage), usage: response.usage, }); return response; }
关键词是原子预留。五个 worker 同时读取剩余额度、都认为自己能发请求,最终 usage 日志回来时就已经晚了。预留必须是数据库事务、Redis 脚本、durable workflow step 或网关侧不可交错的操作,同一个 budget_id 不能出现两个并发请求都以旧余额放行。
流式响应要更保守。初始预留按你允许的最大输出估算;如果 usage 只在流结束时出现,就在 stream close 后对账;如果客户端中途断开而 usage 未知,不要立刻释放全部预留。可以保留保守占用、标记 unknown,或用后续供应商日志补对账。断流不等于没有花费。
让 Agent 真停下
预算错误必须成为 Agent 语义的一部分,而不是一个普通异常。timeout、网络错误和某些 429 可以重试,超预算不应该重试。
建议返回结构化错误:
json{ "error": "over_budget", "retryable": false, "budget_id": "team-alpha-agent-run", "next_allowed_action": "ask_for_human_budget_override" }
然后执行三条传播规则:
| 规则 | 原因 |
|---|---|
| planner 不再调度付费工作 | 否则根循环会继续创建被阻断任务 |
| 子 Agent 继承父级预算 scope | 否则 helper 会在父任务停止后继续花钱 |
| 会触发模型调用的工具也走同一闸门 | 否则工具函数变成隐藏模型消费 |
还要给重试策略单独写 stop list。over_budget、policy_blocked、missing_budget_scope 都应被视作不可重试。日志要记录,操作者要看见,run 要停止。不要让 Agent 把预算错误解释成供应商暂时繁忙,更不要让它切模型、切 key、切网关来绕开本来应该停止的预算决策。
核对供应商和网关边界
供应商控制有用,但不能混成同一种熔断。发布内部手册前要重查,因为预算、配额、dashboard 行为会变。
| Surface | 当前应核对的证据 | 实用边界 |
|---|---|---|
| OpenAI 项目预算 | 本次证据里 OpenAI Help Center 把项目月预算描述为软花费阈值,超过后 API 请求仍可能继续;OpenAI rate limits 文档也把吞吐限制和 usage/spend limits 分开。 | 不要只靠项目预算挡失控 Agent,把它当治理和提醒。 |
| OpenAI Responses usage | Responses 对象有 usage 字段,能帮助按真实 token 对账。 | 用于调用后记录和成本核算,不足以在调用前阻断。 |
| Anthropic Console 限制 | Anthropic 文档区分 spend limits 与 rate limits。 | 适合供应商侧治理,直连 Agent 仍要过自己的闸门。 |
| LiteLLM proxy | LiteLLM 文档说明预算、rate limit、agent/session cap 和 spend tracking。 | 所有付费路径都走代理时可以作为实现选项。 |
| Cloudflare AI Gateway | 文档说明 spend limit 达到累计成本后可用 HTTP 429 阻断后续请求,同时有最终一致性提醒。 | 网关方案有力,但并发突刺和绕行路由必须测试。 |
| Vercel Spend Management / Gateway | 文档说明预算 key、通知、webhook 和 pause 之类平台级动作。 | 是平台花费刹车,不替代每个 Agent 请求前的预算 gate。 |
如果用户报的是 OpenAI rate limit 或 quota exceeded,那是另一条排障线。rate limit 解决吞吐被拒,spend kill switch 解决你自己的预算策略应该在下一次付费请求前拒绝。不要把两个错误码写成同一件事。
用零供应商调用来测试
花费熔断没有通过测试之前,不要接昂贵模型或长时间 Agent 任务。最关键的测试不是看日志里有 blocked,而是证明 blocked 后供应商计数器为零。
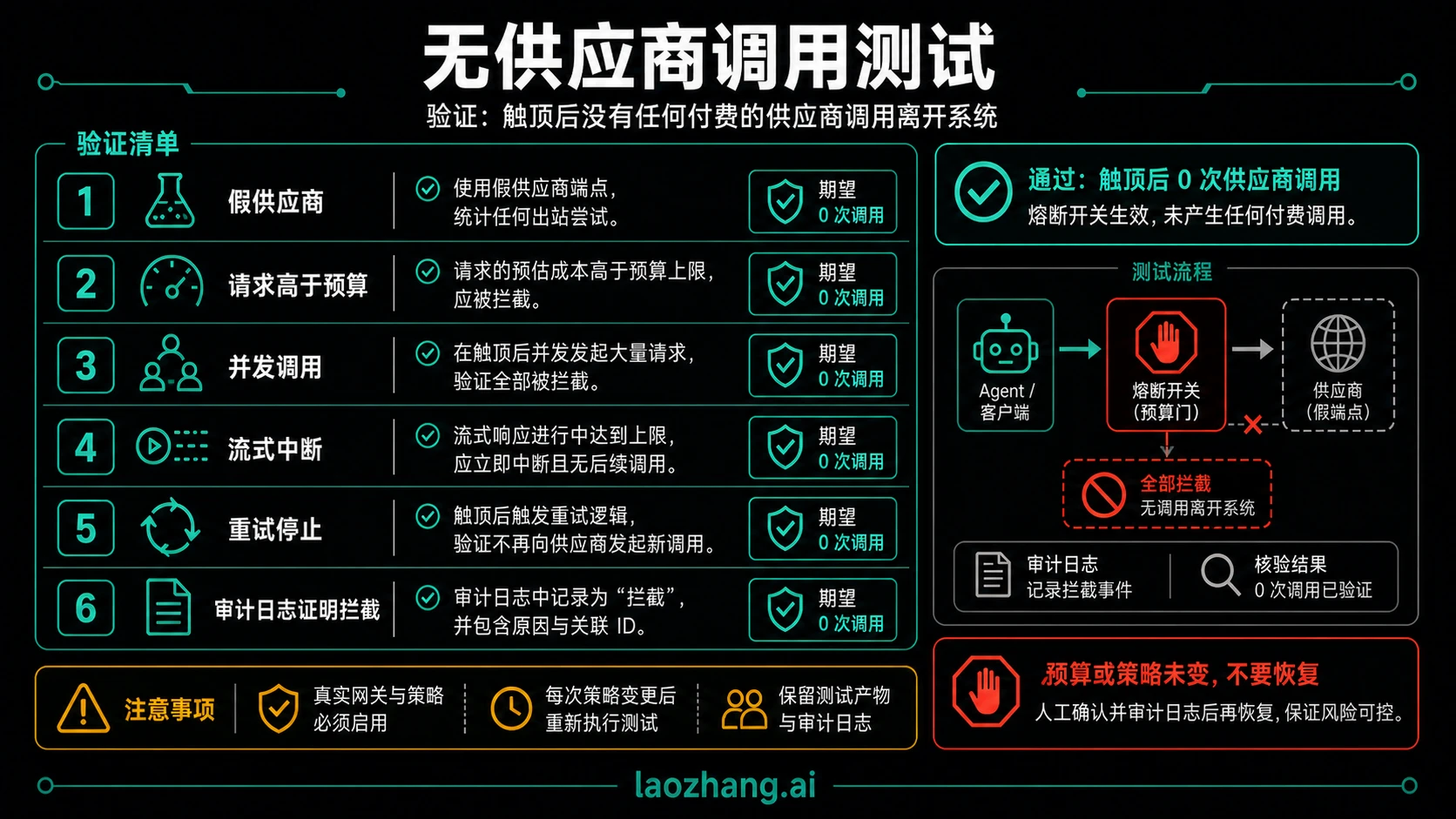
| 测试 | 设置 | 通过条件 |
|---|---|---|
| 假供应商 | 用本地 counter service 替代真实 provider endpoint | 预算耗尽后 counter 保持 0 |
| 请求大于余额 | 剩余额度低于本次估算 | gate 在网络调用前返回 over_budget |
| 并发 worker | 同时发起足够多请求,如果预留竞争会超额 | 只有预留成功的请求通过,其他请求不碰 provider |
| 流式中断 | 开始 stream 后强制断开 | 账本保留保守预留直到 usage 对账 |
| 重试策略 | 模拟 timeout、429、over_budget | 只有可重试错误会重试,over_budget 直接停 |
| 审计包 | 检查 ledger、request_id、agent_run_id、reason | 操作者能解释为什么拦截 |
每次改模型价格表、路由规则、重试策略、网关或账本存储,都要重跑这组测试。只要假供应商在 cap 后还能收到请求,这个系统还只是成本监控,不是熔断。
生产运行手册
事故中可执行的手册要足够短:
- 冻结直连供应商凭证,确认 Agent worker 没有绕过 gate 的 key。
- 确认预算 scope:用户、团队、项目、Agent run,还是月度账户上限。
- 查看账本:actual spend、reserved spend、in-flight calls、unknown reconciliation items。
- 确认 Agent 收到的是终止性的 over_budget。
- 停止重试、子 Agent 调度和工具链里隐藏的模型调用。
- 用供应商日志对账 request_id 和 ledger 记录。
- 决定是提高 cap、缩小任务,还是关闭 run。
- 如需人工覆盖,记录批准人、新 cap、失效时间和原因。
最高风险覆盖是“换条路再试”。它会把原预算 scope 隐藏掉,创造新的可计费路径。必须切供应商、模型、网关或 key 时,把它当成新的预算决策,而不是同一次失败的重试。
常见问题
OpenAI 项目预算足够当 LLM Agent API 花费熔断吗?
不够。本次核对到的 OpenAI Help Center 文案把项目预算描述为软阈值,适合治理和提醒,但不应作为失控 Agent 的唯一停止机制。你的请求路径里仍需要一个调用前预算 gate。
熔断该返回 HTTP 402、429 还是别的状态?
状态码要看客户端生态,Agent 看到的 payload 更重要。它必须写明预算会被打穿,并且 retryable 为 false。某些网关用 429 表示 limit-style block,内部 Agent runtime 可以用 over_budget 这样的领域错误。
响应还没回来,怎么估算成本?
用本次请求被允许产生的最大输入、输出、工具、图片或流式成本。估算可以保守,调用后再用 usage 字段或网关 cost log 对账,释放没用掉的预留。
provider usage 很晚才到怎么办?
保持预留直到对账结束,或把它标成 unknown 并保守计费。中断 stream 后立刻释放全部预算,会在真实花费未确认前重新打开预算窗口。
子 Agent 要单独预算吗?
可以有子预算,但必须继承父 run 的总 cap。helper 不能在父任务停止后继续使用另一条付费路由。
已经有 AI 网关,从哪里开始?
先确认每一条付费模型路径都走网关。再用假供应商、低 cap 和并发请求测试网关预算行为。只有关闭绕行路由且被阻断请求不触达 provider 时,网关预算才是主熔断。