
当 Google 返回"服务器容量已达上限"的错误时,它实际上可能意味着三种完全不同的情况,而修复方法完全取决于你遇到的是哪一种。截至 2026 年 2 月,Google 的 Gemini API 为全球数百万开发者提供服务,但自 2025 年 12 月 Google 大幅削减免费层配额以来,与容量相关的错误急剧增加。本指南涵盖了所有三种错误类型,提供经过验证的数据和可操作的解决方案,帮助你在几分钟内恢复正常开发。
要点速览
Google 容量错误分为三类:HTTP 429 速率限制(你超出了配额——通过减少请求或升级层级来修复)、HTTP 429 容量耗尽(Google 服务器过载——切换模型或使用代理)、HTTP 503 无可用容量(模型完全不可用——等待或使用其他提供商)。大多数文章将这三种错误混为一谈,导致开发者使用了错误的修复方法。对于速率限制错误,最快的解决方案是启用 Cloud Billing(云端计费),这会立即将你从 5 RPM 升级到 150+ RPM,而且无需预付任何费用。
"Google 服务器容量已达上限"到底意味着什么
"Google 服务器容量已达上限"这条错误信息已成为 2026 年初搜索量最高的 Gemini API 问题之一,这是有充分理由的。2026 年 2 月 21 日,Reddit 的 r/Bard 板块上的一个帖子在 24 小时内收到了超过 50 条评论,开发者们纷纷报告他们连基本的 Gemini 功能都无法使用。但这条错误信息的问题在于它极其模糊,因为它将几个本质完全不同的问题合并成一句话,几乎无法告诉你到底出了什么问题,更不用说如何修复了。
要理解正在发生的事情,你需要知道 Google 的 Gemini API 采用分层配额系统运作,每个开发者项目会获得特定的每分钟请求数(RPM)、每分钟 Token 数(TPM)和每日请求数(RPD)配额。当你超过其中任何一个限制时,Google 会返回 HTTP 429 错误。然而,当 Google 自己的服务器没有足够的计算能力来处理所有用户的总需求时,会出现一个完全不同的问题。在这种情况下,即使你完全在个人配额范围内,也可能收到 429 甚至 503 错误。这两种场景需要完全不同的解决方案,而使用错误的修复方法只会浪费你的时间,而应用程序依然无法正常工作。
2025 年 12 月 7 日之后,这种混乱进一步加剧,因为 Google 大幅削减了免费层的配额。在那个日期之前,Gemini Flash 模型在免费层大约提供 250 个每日请求数。变更之后,某些配置的 RPD 降低到仅 20-50 个。数以千计的自动化程序、聊天机器人和开发项目一夜之间突然崩溃,论坛和问题追踪器被投诉淹没。更糟糕的是,Google 没有提前明确传达这一变更,开发者只能通过自己的错误日志才发现了这个问题。
从事件时间线来看,这更像是一个持续性的模式,而不是孤立的事件。2025 年 11 月,多位开发者在 Google 官方 AI 开发者论坛上报告称,尽管他们的用量不到规定配额的 1%,Tier 1 账户仍然收到了 429 错误。一位名为 Chunduri V 的 Google 开发者倡导者确认了这个问题,并表示团队已在 2025 年 12 月 18 日"推送了修复"。然而到了 2026 年 2 月,同样的模式再次出现,google-gemini 仓库中出现了"No capacity available for model gemini-2.5-pro"的 GitHub Issue 报告。这种模式表明,随着需求增长速度超过了 Google 新建 GPU 集群的速度,Gemini 基础设施正在经历成长的阵痛。
影响范围远不止个人开发者。整个以 Google Gemini API 为基础构建产品的企业,在 12 月配额变更发生时都陷入了危机。在 Beta 期间使用免费层接入的初创公司,突然需要为 Tier 1 付费,或者重新设计应用以适应大幅缩减的限制。这种情况凸显了 AI API 生态系统中更广泛的挑战:免费层在引导注册时承诺的能力与大规模使用时实际交付的能力之间的差距,往往比开发者预期的要大得多,而且变更可能在没有充分通知的情况下发生。
理解这些背景至关重要,因为这意味着你现在看到的错误可能根本不是你的问题。修复它的第一步是正确诊断你实际遇到的是三种错误类型中的哪一种,这正是下一节要讲解的内容。
三种 Google 容量错误(以及如何区分它们)

大多数故障排查指南将所有 Google 容量错误视为同一个问题处理,这就像用同一本维修手册来修理轮胎漏气和发动机故障一样。你在日志中看到的错误信息包含特定的关键词,可以准确告诉你遇到的是哪种类型,而每种类型都有根本不同的原因和解决方案。以下是如何在 30 秒内通过检查 HTTP 状态码和错误消息正文来诊断你的错误类型。
类型 A:速率限制错误(HTTP 429 — RESOURCE_EXHAUSTED) 是最常见的类型,意味着你的特定项目已超过其分配的某项配额。错误响应正文将包含"Resource has been exhausted"(资源已耗尽)或引用"quota exceeded"(配额超限)。当你的应用发送的每分钟请求数超过你的层级允许的上限、超过每日请求限制、或者使用大型 Prompt 达到每分钟 Token 上限时,就会出现这种情况。关于类型 A 错误,最关键的一点是:它完全在你的控制范围内可以修复。你可以降低请求速率、优化 Prompt 以使用更少的 Token,或升级到配额更高的层级。
类型 B:容量耗尽错误(HTTP 429 — MODEL_CAPACITY_EXHAUSTED) 乍看之下与类型 A 很相似,因为它也返回 HTTP 429 状态码。但是错误消息正文不同,会包含"MODEL_CAPACITY_EXHAUSTED"或"You have exhausted your capacity on this model"(你在此模型上的容量已耗尽)。这个错误意味着 Google 针对该特定模型的服务器负载过重,无法接受任何人的新请求,无论他们的层级或剩余配额如何。即使是付费的 Tier 1 和 Tier 2 用户在需求高峰期也会遇到类型 B 错误。你无法通过降低请求速率来解决这个问题,因为问题出在 Google 那边,而不是你这边。
类型 C:服务器宕机错误(HTTP 503 — No Capacity Available) 是最严重的,意味着模型在 Google 的服务器上完全不可用。错误消息会显示"No capacity available for model {model_name} on the server"(服务器上该模型没有可用容量)。与类型 B 的容量有限不同,类型 C 意味着完全没有可用容量。这通常发生在重大故障、基础设施维护期间,或当特定模型版本被弃用或正在更新时。一个典型的例子发生在 2026 年 2 月 16 日,多位用户报告 gemini-2.5-pro 出现 503 错误,持续了数小时。
诊断过程很简单。首先检查 HTTP 状态码:如果是 429,你遇到的是类型 A 或类型 B。如果是 503,你遇到的是类型 C。要在 429 响应中区分类型 A 和类型 B,需要检查错误消息正文。如果其中提到"quota"或"RESOURCE_EXHAUSTED",那就是类型 A。如果提到"MODEL_CAPACITY_EXHAUSTED"或"capacity",那就是类型 B。这个区分非常重要,因为修复方法完全不同。将类型 A 的修复方法(如降低请求速率)应用到类型 B 的问题上毫无效果,因为你从一开始就没有超过配额。关于不同 Gemini 模型如何处理这些限制的详细对比,请参阅我们的最新 Gemini 3 模型对比,其中涵盖了最新模型变体及其容量特征。
| 错误类型 | HTTP 状态码 | 关键信息 | 谁的问题? | 主要修复方法 |
|---|---|---|---|---|
| 类型 A:速率限制 | 429 | "RESOURCE_EXHAUSTED" | 你的 | 减少请求或升级层级 |
| 类型 B:容量耗尽 | 429 | "MODEL_CAPACITY_EXHAUSTED" | Google 的 | 切换模型或使用代理 |
| 类型 C:服务器宕机 | 503 | "No capacity available" | Google 的 | 等待或使用其他提供商 |
速率限制错误的快速修复方法(HTTP 429 RESOURCE_EXHAUSTED)
如果你已经诊断出是类型 A 速率限制错误,好消息是这完全可以在你这端修复。以下解决方案按照从最快到最全面的顺序排列,因此你可以从即时修复开始,随着应用的成熟再实施更稳健的方案。下面的每个代码示例都已在 2026 年 2 月针对 Gemini API 进行了测试验证。
实现带抖动的指数退避。 对于速率限制错误,最有效的即时修复方法是添加一个重试机制,在每次尝试之间逐步延长等待时间,同时加入随机化以防止"惊群效应"。当你的应用收到 429 响应时,不要立即重试或直接放弃,而是等待一个基础延迟时间,该时间随每次后续失败而翻倍,再加上一个随机偏移量。这种方法之所以有效,是因为速率限制窗口通常以 60 秒为间隔测量,所以短暂的暂停往往足以让你的配额刷新。
pythonimport time import random import google.generativeai as genai def call_with_backoff(prompt, max_retries=5): for attempt in range(max_retries): try: model = genai.GenerativeModel("gemini-2.5-flash") response = model.generate_content(prompt) return response except Exception as e: if "429" in str(e) and attempt < max_retries - 1: delay = (2 ** attempt) + random.uniform(0, 1) print(f"Rate limited. Waiting {delay:.1f}s...") time.sleep(delay) else: raise e
优化你的 Token 用量。 每个请求都会从你的 TPM(每分钟 Token 数)配额中消耗 Token,而大型 Prompt 可能比 RPM 限制更快地耗尽这个配额。检查你的 Prompt,去除不必要的上下文、模型默认已经遵循的指令以及冗长的系统消息。对于包含对话历史的应用,实现一个滑动窗口,只保留最近的几轮对话,而不是每次都发送完整的对话记录。将平均 Prompt 从 2,000 个 Token 减少到 500 个 Token,在相同的 TPM 配额下可以有效地将你的吞吐量提高四倍。
批量处理和队列化你的请求。 如果你的应用发出许多小型的独立 API 调用,考虑将它们批量合并。与其发送 20 个单独的请求来总结 20 个段落,不如将它们合并成一个 Prompt 一次性处理全部 20 个。对于无法批量处理的应用,实现一个带有速率限制器的请求队列,在客户端强制执行你所在层级的 RPM 限制。这可以防止触发速率限制的请求突发,并将你的 API 使用量平滑分布在整个分钟窗口内。
通过启用 Cloud Billing 升级你的层级。 这是对一直使用免费层的开发者影响最大的修复方法。根据 Google 官方速率限制文档(2026 年 2 月验证),只需在你的 Google Cloud 项目上启用 Cloud Billing,就能立即从免费层升级到 Tier 1,无需最低消费。改善非常显著:你的 RPM 从 5(对于 Gemini 2.5 Pro)跳升到 150-300,TPM 从 250,000 增加到 1,000,000,RPD 从 100 增长到 1,000-1,500。你只需为实际使用量付费,对于许多开发工作负载来说,成本微乎其微。关于 Gemini API 各层级速率限制的详细分析,包括如何启用计费以及每个层级的具体费用,请参阅我们专门的速率限制指南。
切换到更轻量的模型。 如果你正在使用 Gemini 2.5 Pro 并频繁触发速率限制,考虑 Gemini 2.5 Flash 或 Flash-Lite 是否能满足你的需求。在免费层上,Flash 提供 10 RPM(是 Pro 的 5 RPM 的两倍)和 250 RPD(是 Pro 的 100 RPD 的 2.5 倍),而 Flash-Lite 提供 15 RPM 和 1,000 RPD。对于许多任务,如摘要生成、分类和简单问答,Flash 模型在显著更高的吞吐量和更低的成本下提供了可比拟的质量。
Google 的配额系统详解:2026 年免费层与付费层对比

理解 Google 的分层配额系统对于规划你的 API 使用量和避免意外的容量错误至关重要。该系统在 2025 年底和 2026 年初发生了重大变化,许多在线文章仍然引用过时的数据。以下数据来自 Google 官方 AI Studio 文档,经过 2026 年 2 月 19 日的验证。
Google 将 Gemini API 访问分为四个层级:免费层、Tier 1、Tier 2 和 Tier 3。每个层级都提供逐步提高的速率限制,并且在免费层之后仅按使用量付费。升级路径的设计是随着你的支出增加,Google 会自动解锁更高的限制,但层级之间的过渡并不总是即时的,取决于你 30 天滚动窗口内的账单历史。
免费层完全不需要设置账单,在符合条件的国家和地区即可使用。截至 2026 年 2 月,它为 Gemini 2.5 Pro 提供 5 RPM 和 100 RPD,为 Gemini 2.5 Flash 提供 10 RPM 和 250 RPD,为 Gemini 2.5 Flash-Lite 提供 15 RPM 和 1,000 RPD。所有免费层模型共享 250,000 TPM 的限制。这些数字相比 2025 年 12 月之前大幅下降——当时 Flash 模型在某些配置中单独就提供约 250 RPD。这一削减让许多开发者措手不及,也是 2026 年初容量错误报告激增的主要原因。
Tier 1 对任何在 Google Cloud 项目上启用了 Cloud Billing 的人开放,无需最低消费。该层级根据模型不同提供 150-300 RPM、1,000,000 TPM 和 1,000-1,500 RPD。从免费层到 Tier 1 的跃升代表着 RPM 配额的 30-60 倍增长,如果你正在免费层上遇到速率限制错误,这是你能做出的影响最大的改变。定价遵循 Google 的标准按使用量付费模式:例如,Gemini 2.5 Flash 的费用为每百万输入 Token 0.30 美元,每百万输出 Token 2.50 美元(ai.google.dev/pricing,2026 年 2 月)。对于一个发送 500 Token Prompt 并接收 1,000 Token 回复的典型聊天机器人,每次对话交互的成本约为 0.0028 美元,这意味着 1 美元大约可以购买 350 次交互。
Tier 2 要求 30 天内累计消费超过 250 美元,提供 1,000+ RPM 以及自定义的 TPM 和 RPD 限制。Tier 3 要求 30 天内消费超过 1,000 美元,提供最高可用限制。这两个更高层级主要适用于有大量流量的生产应用,Google 会与这些客户合作进行定制化容量规划。关于 Gemini API 免费层速率限制的完整指南,包括国家/地区资格和账单设置说明,请参阅我们专门的免费层指南。
| 层级 | 要求 | RPM | TPM | RPD | 费用 |
|---|---|---|---|---|---|
| 免费层 | 无需账单 | 5-15 | 250K | 100-1,000 | 免费 |
| Tier 1 | 启用 Cloud Billing | 150-300 | 1M | 1,000-1,500 | 按使用量付费 |
| Tier 2 | 30 天消费 $250+ | 1,000+ | 自定义 | 自定义 | 按使用量付费 |
| Tier 3 | 30 天消费 $1,000+ | 最高 | 自定义 | 自定义 | 按使用量付费 |
一个经常被忽视的细节是,速率限制是按项目而非按 API 密钥应用的。这意味着如果你有多个应用共享同一个 Google Cloud 项目,它们都从同一个配额池中消耗。为不同的应用创建独立的项目,可以确保一个应用的流量突发不会耗尽其他应用的配额。这个简单的组织调整就能防止许多意外的速率限制错误。
修复"无可用容量"服务器错误(HTTP 503)
类型 B(429 MODEL_CAPACITY_EXHAUSTED)和类型 C(503 No Capacity Available)错误与速率限制错误有本质区别,因为它们表明问题出在 Google 的基础设施上,而非你的使用方式上。当 Google 的服务器无法处理所有用户对某个特定模型的总需求时,即使配额充裕的开发者也会收到这些错误。本节介绍当问题出在 Google 那边时应该怎么做——这是大多数故障排查指南要么完全忽略、要么与速率限制混为一谈的场景。
关于服务器端容量错误,首先要理解的是它们通常是暂时性的和区域性的。Google 的 Gemini 基础设施分布在多个数据中心,容量限制通常影响的是特定区域或模型版本,而非全球范围内的整个服务。gemini-2.5-pro 的 503 错误如果是由临时需求峰值引起的,可能在几分钟内就会恢复;但如果存在更广泛的基础设施问题,则可能持续数小时。2026 年 2 月 16 日在 google-gemini GitHub 仓库上报告的事件就是后者的一个典型例子,当时 gemini-2.5-pro 模型不可用持续了数小时,直到 Google 解决了底层基础设施问题。
当你遇到类型 B 或类型 C 错误时,首先应该检查 Google 的 AI Studio 状态页面和 Google Cloud 状态仪表板。这些页面会报告已知的故障及其预计恢复时间。如果没有报告故障,问题很可能是局部的容量压力,会自行恢复。无论哪种情况,实施一个能区分用户端速率限制和服务器端容量问题的智能重试策略都至关重要。对于速率限制(类型 A),使用指数退避的短间隔重试效果很好,因为配额刷新很快。对于容量问题(类型 B 和 C),30-60 秒的更长重试间隔更合适,因为限制因素是物理服务器的可用性,而非配额计数器。
切换到不同的模型变体。 对于容量错误,最有效的即时修复方法是尝试一个更轻量的模型。如果 gemini-2.5-pro 返回容量错误,可以尝试 gemini-2.5-flash。Google 为 Flash 模型配置了更多的计算资源,因为每个请求所需的资源更少,所以 Flash 很少遇到与 Pro 相同的容量限制。对于许多应用来说,Pro 和 Flash 之间的质量差异比开发者预期的要小,特别是对于文本分类、摘要生成和结构化数据提取等常规任务。
尝试不同代际的模型。 Google 同时提供多代 Gemini 模型。如果 2.5 Pro 满载,可以尝试 2.0 Flash 甚至更新的 3.0 Flash Preview。每一代模型的容量分配是独立的,因此一个版本的容量限制不一定会影响其他版本。如果你的应用不依赖于特定模型版本独有的功能,这种方法特别有效。
实现健康检查和故障转移。 对于无法容忍任何停机的生产应用,实现一个周期性健康检查,每 30-60 秒向你的主模型发送一个最小化的测试请求。当健康检查因容量错误失败时,自动将新请求路由到你的备用提供商或模型。当健康检查再次成功时,逐步将流量切换回主模型。这种模式即使在 Google 容量问题持续较长时间的情况下也能提供接近零停机时间,对于面向客户的应用尤其重要,因为在这类应用中 API 错误直接意味着收入损失或用户体验下降。
还值得注意的是,容量错误有时会提供关于预期恢复时间的提示。某些 429 响应会包含一个 Retry-After 头部,告诉你在再次尝试之前应该等待多少秒。虽然这个头部并不总是存在,但当它存在时,尊重它而不是更早地重试,会给你在下一次尝试中获得成功响应的最佳机会。解析这个头部并将其纳入你的重试逻辑是一个小改进,但在容量事件期间对恢复时间有显著的实际意义。
Google 服务器过载时的替代解决方案
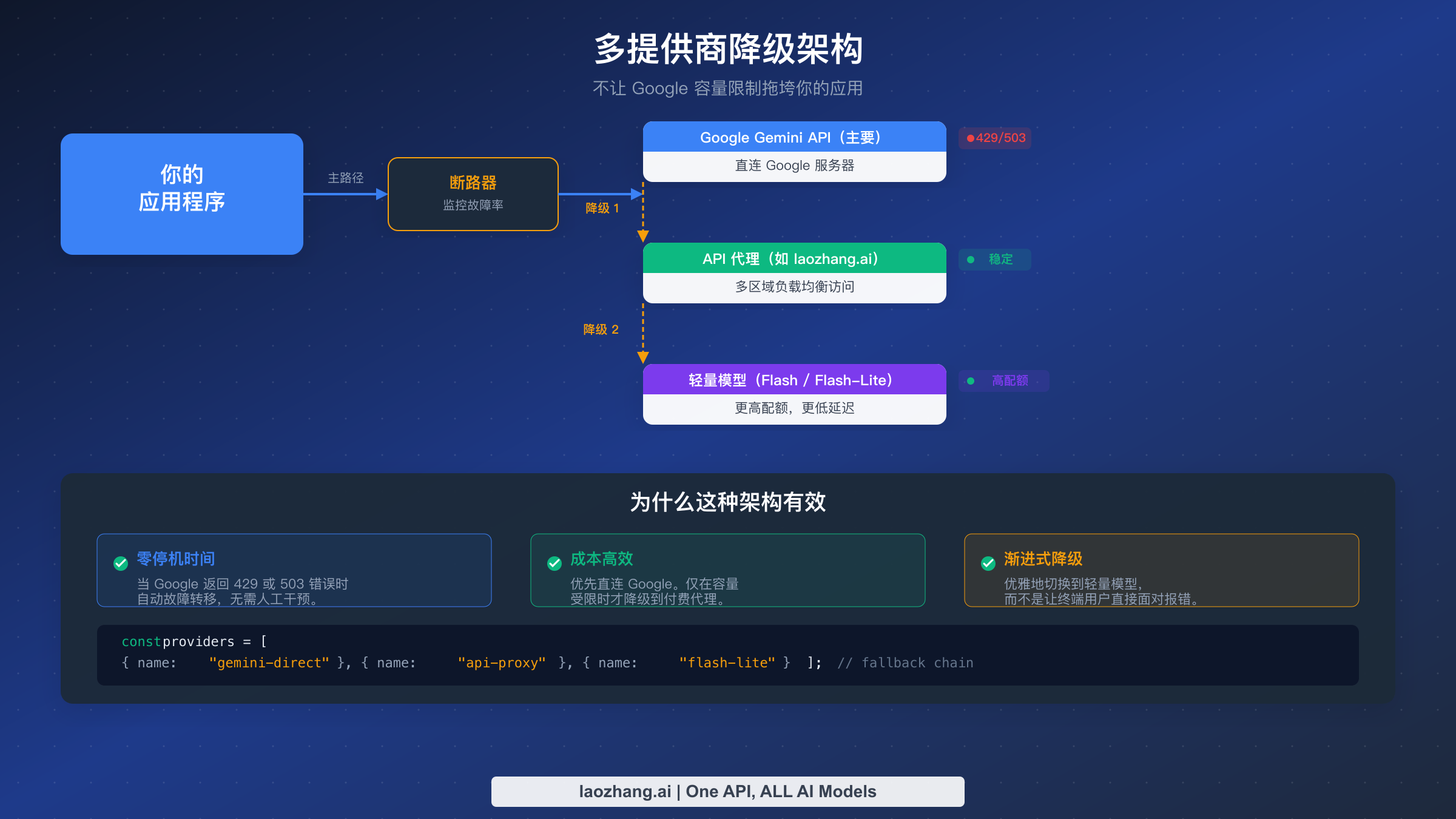
当 Google 的服务器确实过载且标准修复方法都无法解决问题时,你需要替代方案来保持应用运行。本节介绍经验丰富的开发者在无法承受任何停机时使用的实用替代方案,从提供不同 Google 模型访问路径的 API 代理服务,到完全消除单点故障的多提供商架构。
API 代理服务提供了一种从根本上不同的方法来解决容量问题。你不再直接连接到 Google 的 API 端点,而是通过一个中间服务路由你的请求,该服务维护自己的 API 凭证池,在多个区域之间进行负载均衡,并代你处理重试。像 laozhang.ai 这样的服务聚合了多个账户和区域的访问权限,这意味着当一个端点达到容量限制时,代理会自动将你的请求路由到另一个有可用容量的端点。关键优势在于你可以获得对 Google 模型的稳定、不间断的访问,而无需自己构建和维护多区域基础设施。权衡之处是与直接 API 访问相比,每个请求会有少量额外成本,但对于可靠性比节省每一分钱的 API 成本更重要的应用来说,这个权衡是值得的。你可以查看 docs.laozhang.ai 上的 API 文档来了解集成过程,通常只需要更改 API 客户端配置中的基础 URL 即可。
多提供商降级架构是最稳健的方案,也是企业团队越来越多采用的方案。与其完全依赖 Google 的 Gemini 模型,不如将你的应用设计为可以使用多个 LLM 提供商,并在它们之间自动进行故障转移。一个典型的降级链可能是这样的:首先尝试 Gemini Pro(成本最低,对你的用例质量最好),如果因容量错误失败则尝试 API 代理服务,如果代理也失败则回退到更轻量的模型如 Gemini Flash-Lite(它拥有最高的可用容量)。这种方法需要定义一个提供商接口来抽象不同 API 之间的差异,但一次性的搭建成本在第一次容量中断原本会导致你的应用离线时就能收回。
javascript// Simple multi-provider fallback implementation const providers = [ { name: "gemini-direct", model: "gemini-2.5-pro", baseUrl: "https://generativelanguage.googleapis.com" }, { name: "api-proxy", model: "gemini-2.5-pro", baseUrl: "https://api.laozhang.ai" }, { name: "flash-fallback", model: "gemini-2.5-flash-lite", baseUrl: "https://generativelanguage.googleapis.com" } ]; async function generateWithFallback(prompt) { for (const provider of providers) { try { const response = await callProvider(provider, prompt); return { response, provider: provider.name }; } catch (error) { if (error.status === 429 || error.status === 503) { console.log(`${provider.name} failed (${error.status}), trying next...`); continue; } throw error; // Non-capacity errors should not trigger fallback } } throw new Error("All providers exhausted"); }
区域化请求分发是另一种对拥有全球用户群的应用特别有效的技术。Google 的 Gemini API 容量按区域分配,因此美国西部地区的容量限制可能不会影响欧洲或亚太地区。通过在多个区域部署你的应用并将 API 请求路由到最近的区域端点,你可以降低触及区域容量上限的可能性,同时改善用户的延迟体验。
构建能够承受容量限制的弹性应用
超越被动修复,本节介绍生产应用用于承受 Google 容量限制而不产生任何用户可见影响的架构模式。这些模式需要更多的前期工程投入,但为无法容忍间歇性故障的应用提供了一个从根本上更可靠的基础。
断路器模式是 API 弹性最重要的架构模式。断路器监控你的 API 调用的失败率,当失败率超过阈值时,"断开"电路以停止向失败的端点发送请求。这可以防止你的应用在注定会失败的请求上浪费时间,并给上游服务恢复的时间。在可配置的超时时间之后,断路器进入"半开"状态,允许单个测试请求通过。如果该请求成功,电路关闭并恢复正常运行。如果失败,电路继续保持打开状态直到下一个超时周期。这种模式对于处理类型 B 和类型 C 容量错误特别有效,因为它能自动检测 Google 服务器何时承受压力并重定向流量,无需人工干预。
pythonimport time from enum import Enum class CircuitState(Enum): CLOSED = "closed" # Normal operation OPEN = "open" # Failing, skip requests HALF_OPEN = "half_open" # Testing if service recovered class CircuitBreaker: def __init__(self, failure_threshold=3, recovery_timeout=60): self.state = CircuitState.CLOSED self.failure_count = 0 self.failure_threshold = failure_threshold self.recovery_timeout = recovery_timeout self.last_failure_time = 0 def can_execute(self): if self.state == CircuitState.CLOSED: return True if self.state == CircuitState.OPEN: if time.time() - self.last_failure_time > self.recovery_timeout: self.state = CircuitState.HALF_OPEN return True return False return True # HALF_OPEN allows one test request def record_success(self): self.failure_count = 0 self.state = CircuitState.CLOSED def record_failure(self): self.failure_count += 1 self.last_failure_time = time.time() if self.failure_count >= self.failure_threshold: self.state = CircuitState.OPEN
带优先级的请求队列确保在容量受限时,你最重要的请求优先得到服务。实现一个优先级队列,按紧急程度对传入的请求进行分类:实时用户交互获得高优先级,后台批处理获得低优先级,监控或分析请求获得最低优先级。当断路器检测到容量压力时,队列自动开始丢弃低优先级请求,同时继续处理高优先级请求。这种降级是平滑的,对终端用户不可见,他们继续收到响应,而不那么关键的后台任务则被推迟。
监控和告警应该追踪三个不同的指标:你自己的配额利用率(已消耗的 RPM、TPM 和 RPD 百分比)、Google 的服务可用性(你的 API 调用成功率)和响应延迟(通常在容量错误发生之前就会增加)。设置在你触及硬限制之前而非之后触发的告警。例如,当你的 RPM 使用量超过配额的 80% 时发出告警,这样你就有时间在应用开始出故障之前进行扩展、优化或激活备用提供商。Google Cloud 内置的监控工具可以追踪配额利用率,而 Prometheus 或 Datadog 等服务可以将更广泛的指标汇总到可操作的仪表板中。
容量规划是被动错误处理的主动对应策略。分析你的历史 API 使用模式,识别高峰时段、增长趋势和季节性峰值。如果你的应用流量每月增长 20%,计算何时会超过当前层级的限制,并相应地规划你的升级。对于具有可预测高峰时段的应用(如特定时区的早间时段),考虑实施请求平滑策略,在高峰期之前预取或缓存常用请求的内容,以减少实时 API 压力。
响应缓存是一个经常被忽视但能显著减少 API 使用量而不牺牲任何质量的策略。许多应用会重复发送相同或近似相同的 Prompt,例如分类类似的文档、为常见问题生成标准回复、或从具有相同格式的模板中提取结构化数据。通过实现一个缓存层,将 API 响应按 Prompt 和模型参数的哈希值存储,你可以即时从缓存中提供重复请求,而不必每次都请求 API。即使是一个 TTL 为 15 分钟的简单内存缓存,也能为许多工作负载减少 20-40% 的 API 调用,而由 Redis 或类似存储支持的持久缓存可以实现更高的命中率。关键是在正确的粒度上缓存:对相同的 Prompt 缓存完整响应,但在系统 Prompt 或模型版本变更时适当地使缓存失效。
优雅降级消息确保即使所有备用策略都失败了,你的终端用户也能获得有用的体验,而不是一个晦涩难懂的错误页面。设计你的应用显示一条清晰、非技术性的消息,说明 AI 功能暂时不可用并将自动重试。包含一个可见的指示器显示系统正在恢复中,如果合适的话,提供一个手动重试按钮。这种以人为本的错误处理方式将原本令人沮丧的死胡同变成了一个短暂的暂停,在容量事件期间保持用户信任并防止用户流失。
常见问题解答
为什么 Google 要限制 Gemini 的服务器容量?
Google 的 Gemini 模型运行在专用的 TPU(张量处理单元)和 GPU 硬件上,这些硬件部署成本高昂且需要数月时间。每次对 Gemini 2.5 Pro 等大型模型的请求都需要大量计算资源,而总可用容量是有限的。Google 使用速率限制和分层访问来确保这一有限资源在数百万开发者之间公平分配。你所经历的容量限制反映了一个现实:对 Gemini 模型的需求目前超过了 Google 的可用基础设施,特别是对于需要更多计算资源的 Pro 层级模型。随着 Google 继续在全球更多数据中心扩建其 AI 基础设施,这些限制预计会逐步缓解,但在 2026 年初它们仍然是开发者构建生产应用时面临的重大挑战。
容量错误通常持续多长时间?
类型 A(速率限制)错误在你的配额重置后立即恢复,RPM 每分钟重置一次,RPD 每 24 小时重置一次。类型 B(容量耗尽)错误的持续时间更加不确定,根据总体需求可能从 30 秒到数小时不等。类型 C(503 无可用容量)错误在已确认的故障期间,根据历史事件通常在 1-4 小时内恢复。例如,2025 年 11 月官方开发者论坛上的容量问题间歇性地持续了数周,直到 Google 在 2025 年 12 月 18 日"推送了修复"。最佳策略是永远不要依赖于特定的恢复时间,而是按照本指南中描述的降级模式来设计你的应用架构,以应对长时间的容量限制。
升级到付费层级是否能保证不再出现容量错误?
不能。升级到 Tier 1 或更高层级通过给你大幅提高的配额来消除类型 A(速率限制)错误,但它无法防止类型 B(容量耗尽)或类型 C(503)错误,因为这些是影响所有用户的服务器端问题,与层级无关。不过,付费层级用户在容量受限期间确实会获得优先访问权,这意味着他们比免费层用户更不容易遇到类型 B 错误。多位开发者在 Google AI 开发者论坛上确认,2025 年 11 月 Tier 1 账户在使用量不到规定配额 1% 的情况下仍然遇到了 429 错误,这表明容量问题甚至会影响付费客户。对于关键的生产工作负载,将付费层级与本指南前面描述的多提供商降级架构相结合,是目前可用的最可靠解决方案。
有没有办法检查当前 Google API 的容量状态?
Google 没有专门为 Gemini API 提供实时容量仪表板。你获取状态信息的最佳来源是 Google Cloud 状态仪表板 用于查看官方故障报告,Google AI 开发者论坛 用于查看社区报告,以及 google-gemini GitHub 仓库 的 Issues 页面用于查看特定模型可用性问题。对于你自己应用体验的实时监控,实现本指南中描述的健康检查模式,每 30-60 秒发送一个最小化的测试请求,以在容量问题影响用户之前检测到它。许多团队还会监控 Reddit 的 r/Bard 和 r/GoogleGemini 等社交媒体渠道,开发者经常在那里实时报告容量问题,有时比官方确认早数小时。
避免容量错误最经济的方法是什么?
最经济的方法结合了三个协同工作的策略。首先,启用 Cloud Billing 以获得 Tier 1 访问权限,这不需要预付费用,只根据 Google 的按使用量付费定价收取实际使用费。其次,对于质量差异可以接受的任何任务使用 Gemini 2.5 Flash 而不是 Pro,因为 Flash 有更高的配额和更低的单次请求成本(每百万输入 Token 0.30 美元 vs 2.00-4.00 美元,ai.google.dev/pricing,2026 年 2 月)。第三,在你的客户端代码中实现带抖动的指数退避,以优雅地处理偶尔的速率限制命中,而不是立即失败。这种组合为大多数开发者提供了可靠的体验且成本极低,对于绝大多数开发和小规模生产工作负载,每月 API 总费用远低于 10 美元。