
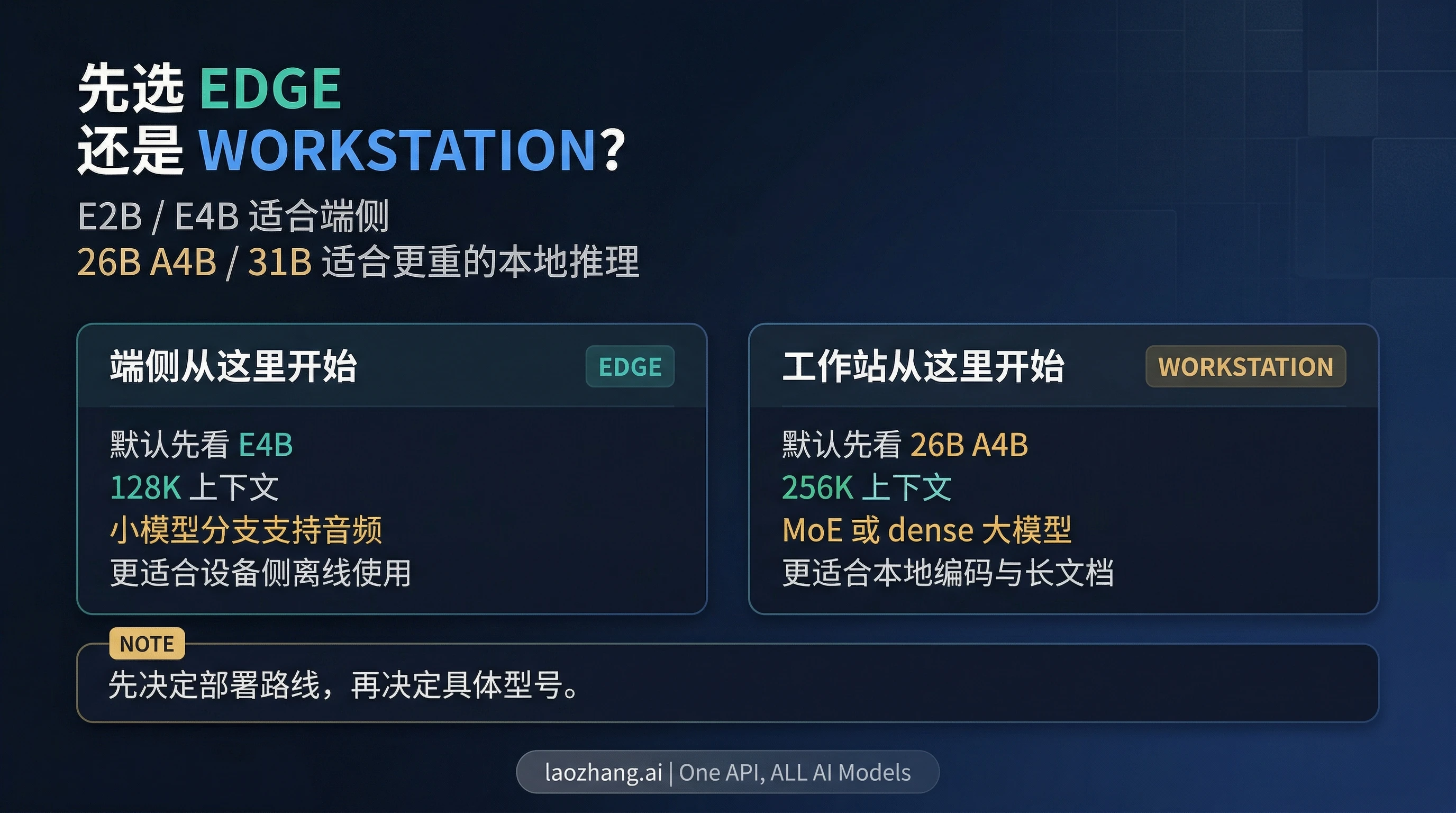
Gemma 4 不是一个模型。如果你只记住一件事,那就记住这个分法:E2B 和 E4B 更偏端侧,26B A4B 和 31B 更偏工作站。 截至 2026 年 4 月 3 日,这个分法比任何单独的 benchmark 截图都更重要,因为它决定了你应该从手机、笔记本、工作站,还是官方的在线试用入口开始。
这也是 Gemma 4 和很多“新模型发布”看起来不一样的地方。它不是抽象意义上 Google 又发了一个开放模型,而是一个在 Apache 2.0 许可下发布的四型号家族:小模型分支强调高效、本地、移动端;大模型分支强调更长上下文和开发者硬件上的更重推理。如果你只看发布页,会觉得产品面很多;真正有用的动作是先把问题收敛成一句话:你需要的是端侧模型,还是工作站模型?
本文核心信息已于 2026 年 4 月 3 日对照 Google 的 Gemma release log、发布博客、Gemma 4 model card、Gemini Developer API 定价页与 Android Developers Blog 进行核对。
先判断:你该从哪一条开始?
| 你的真实目标是…… | 应该先看…… | 原因 | 主要代价 |
|---|---|---|---|
| 离线、低延迟、端侧、移动端或更小的本地设备 | E4B | 最稳妥的端侧默认项,能力明显强于 E2B,同时仍面向本地高效运行 | 上下文上限低于大模型分支,不适合最重的工作站推理 |
| 想要 Gemma 4 里最轻的选择,同时保留新家族优势 | E2B | 当内存、电池、延迟才是真实瓶颈时,它是最合理的效率优先方案 | 上限低于 E4B,难任务余量更少 |
| 想要一款适合工作站本地运行、同时比 dense 大模型更务实的默认项 | 26B A4B | MoE 结构只激活 3.8B 参数,往往是工作站这条线的第一评估点 | 产品叙事比“一个大 dense 模型”更复杂 |
| 明确想要 Gemma 4 家族里密度最高的大模型 | 31B | 当你最看重 dense 大模型的原始质量或后续微调底座时更合适 | 硬件负担比 26B A4B 更重 |
| 先在线试一下大模型,再决定要不要自托管 | AI Studio 里的 26B A4B 或 31B | 这是官方最快的“大分支试用入口” | 当前定价页并没有给出一个标准的 Gemma 4 付费 SKU 叙事 |
| 端侧语音 / 音频理解 | E4B 或 E2B | 小模型分支原生支持 audio | 大模型分支没有同样的音频定位 |
一句话默认建议可以非常直接:如果你从端侧硬件出发,先看 E4B;如果你从工作站出发,先看 26B A4B。 除非你很清楚自己要追求最小 footprint,或者明确要 dense 31B,否则这两个入口最值得先评估。
Gemma 4 到底是什么
Gemma 4 是 Google 最新一代开放模型家族。官方 release log 将其记录在 2026 年 3 月 31 日,公开发布博客日期为 2026 年 4 月 2 日。Google 把它放在 Gemini 3 之后的开放模型脉络里,但这并不意味着 Gemma 4 只是“便宜版 Gemini”。真正重要的区分是部署边界:Gemma 是你可以自行运行、适配、部署的开放权重家族;Gemini 则是 Google 托管的模型线。
这个边界会直接改变决策方式。选择 Gemini,多数时候是在做托管 API 方案和价格决策;选择 Gemma 4,首先是在做部署决策。你要决定自己要的是本地端侧模型、工作站级本地模型,还是一个帮助你先评估开放模型的在线试用入口。
Google 这次也把产品边界说得比很多发布周期更清楚。官方 model card 把 Gemma 4 定义为一个 multimodal open model family:支持 text 和 image 输入,小模型分支还支持 native audio 输入,而全线输出仍是 text。这一点值得说得更直接些,因为发布周最容易产生误解:Gemma 4 不是 图像生成模型,也不是视频生成模型。它是一个以文本输出为中心、适合 reasoning、coding、OCR 式理解以及相关流程的开放多模态模型家族。
真正的分野:edge 模型 vs workstation 模型

理解 Gemma 4 最有用的方式,不是抽象地问“哪个模型最好”,而是问它的每个分支在解决什么部署问题。
edge 分支是 E2B 和 E4B。按照官方 model card,这两个型号都支持 128K context、text 与 image 输入,并且原生支持 audio 输入。Google 的 Android 公告也明确把这一支和未来设备上的 Gemini Nano 4 / AICore 路线绑在一起。这意味着它们不是简单意义上的“小模型”,而是专门为了端侧执行、设备级延迟、能耗和受限硬件而存在的那一支。
在这条 edge 分支里,E4B 是大多数读者更应该先看的默认项。它比 E2B 余量更大,同时仍然处在 Google 明确朝 on-device / AI Edge 方向推动的分支上。E2B 更像一个效率优先的专门选择:当 footprint 才是第一限制,你才应该主动往它收缩。
workstation 分支则是 26B A4B 和 31B。这两个型号都把上下文拉到 256K,对长文档、较大代码上下文和更重的本地 reasoning 流来说,这是很实在的提升。它们也把 Gemma 4 从“纯端侧问题”推向了开发者工作站、自托管本地栈和更接近生产式部署的场景。
其中最值得单独指出的是 26B A4B。官方 model card 把它定义为 Mixture-of-Experts 模型,总参数 25.2B,但推理时只激活 3.8B。翻译成更实用的话,就是:它很可能是很多本地开发者真正该先试的大分支默认项。它给你更长上下文和更强推理层级,但又不要求每个人都直接承受最重的 dense 模型成本。
31B 则是 dense 大模型。只有在你明确更看重 dense 大模型的原始质量,或者就是想要更强的 dense fine-tuning 底座时,它才是第一选择。重要的是,不要因为它数字最大,就默认把它当成全家族自动答案。对很多本地开发者来说,26B A4B 才是更务实的第一站。
相比 Gemma 3,Gemma 4 真正变了什么
Gemma 4 相比 Gemma 3 的升级,不应该被简化成一句“分数变高了”。更重要的变化,是 Google 把这个家族做成了一个更容易实际使用的产品体系。
第一,大模型分支把上下文拉到 256K,小模型分支维持 128K。这会直接改变 Gemma 4 在长文档和 repository 级本地工作流中的可用性。第二,发布材料和 model card 都明确强调了 native system role 与 native function-calling posture,这对 agentic / structured workflow 很关键。第三,家族分支变得更清楚了:edge 模型不再像附带的小尾巴,workstation 分支也不再被塞成一个含糊的大型号。
能力提升也不是装饰性的。官方 model card 里,31B 在若干重点 benchmark 上相比 Gemma 3 27B 有明显提升,包括 AIME 风格数学推理和 LiveCodeBench 风格 coding 指标。这里的重点不是让文章沦为 benchmark 崇拜,而是说明这次升级并不是“换名字的发布”。Gemma 4 下面有真实的能力变化,也有真实的产品分工变化。
另一项很重要的变化是部署姿态。Google 明显在把 Gemma 4 讲成一个可以从多个入口使用的家族:AI Studio 提供大模型的在线试用入口;AI Edge / Android 提供小模型的端侧路线;Hugging Face、Ollama、MLX、llama.cpp、vLLM 等 runtime 则给出自托管路径。真正值得记住的,不是“Gemma 4 更聪明了”,而是 Gemma 4 更知道自己该在哪里用。
今天可以去哪里运行 Gemma 4

你应该去哪里运行 Gemma 4,完全取决于你刚才选的是哪条分支。
如果你想 最快试一下大模型分支,Google 的发布博客把 31B 和 26B A4B 指向 AI Studio。这是在不先搭本地栈的情况下,体验 workstation 分支最快的官方入口。但这里有一个边界必须说清楚:当前 Gemini Developer API 的 pricing page 显示,Gemma 4 在公开页面上是 free only,并没有被放进一个标准的 paid tier 叙事里。所以“它可以在线试”是对的;“它现在像普通付费 Gemini 模型那样是标准托管 SKU”则不是当前价格页给出的结论。
如果你关心的是 edge 分支,官方信号会明显不同。Google 的 Android Developers Blog 把 Gemma 4 与 AICore Developer Preview、未来的 Gemini Nano 4 设备路线绑在一起;发布材料也把 E4B / E2B 指向 AI Edge 相关路径。这让小模型分支更像一条真实的端侧路线,而不是一个象征性发布。
如果你想要 自托管本地控制权,Google 的发布材料也明确点名了 Hugging Face、Kaggle、Ollama、Transformers、MLX、llama.cpp、vLLM 等常见开放模型生态。这才是你要把 Gemma 4 放进本地编码工作流、工作站栈或私有部署环境时应该走的路。若你下一步就是做本地 provider 配置,那么后续更值得读的是我们的 OpenClaw LLM 配置指南,而不是继续看一篇停留在发布层面的新闻总结。
如果你已经在考虑 更大规模的生产部署,Google 正在把这条叙事推向 Google Cloud,而不是把 Gemma 4 当成 Gemini API 定价表上的一个普通按量付费条目。这是很重要的产品边界。“Gemma 4 可以在 Google 生态里运行”是真的;“Gemma 4 现在就等同于一个普通的付费 Gemini hosted model”则不是当前价格页支持的说法。
按场景给出最实用的选择
如果你要的是一个 通用的 edge 默认项,从 E4B 开始。它最能平衡 Google 当前对端侧路线的产品投入,以及本地多模态使用时你真正需要的能力余量。
如果你的真实瓶颈是 内存、电池或延迟,从 E2B 开始。它不是全家族默认项,但在 footprint 比 ceiling 更重要的时候,它反而是最诚实的答案。
如果你要的是 工作站级本地 coding / reasoning 模型,从 26B A4B 开始。这是整篇文章里最重要的实践建议。MoE 设计让你进入大模型分支时,不必一上来就把最重的 dense 模型当作第一站。对很多想在本地跑 coding、reasoning 和长上下文任务的开发者来说,26B A4B 就是最合理的首选评估对象。
如果你最在意的是 dense 大模型的原始质量或微调余量,再转向 31B。只有在你的硬件预算足够,而且你明确知道自己为什么需要 dense 31B 的时候,这个选择才成立。
如果你明确需要 端侧音频理解,就待在 E2B / E4B 这条分支上。官方 model card 已经把 audio 的产品边界说清楚了,这比单纯追求更大的参数数字更重要。
如果你只是想先判断 Gemma 4 值不值得花时间,不要一上来先搭本地部署。大分支先去 AI Studio,小分支先看 Android / AI Edge preview 路线。最错误的第一步,就是在还没分清自己属于哪条分支之前,就先花几个小时搭一条可能并不适合你的本地栈。
哪些情况下 Gemma 4 反而不是正确答案
Gemma 4 很容易被过度吹大,因为它同时踩中了几个很吸引人的词:open weights、Apache 2.0、长上下文、强 reasoning 姿态、明确的 edge ambition。但这不代表它对所有用户都是最佳路线。
如果你真正需要的是 一个稳定、清晰、可直接购买的托管 API 方案,Gemma 4 目前并没有 Gemini 托管路线那么直观。当前 pricing page 的价值,恰恰在于它把这个边界暴露得很清楚。在这种情况下,更适合继续看的反而是我们的 Gemini API 定价指南,因为那才是面向托管 API 成本与方案边界的读法。
如果你真正要的是 最强的闭源前沿模型推理栈,并且不想承担任何开放权重或本地部署工作,Gemma 4 也未必是你要找的东西。它的强项在于开放、可部署、可接入本地生态,而不是抹平开放模型与托管 frontier system 之间的差异。
如果你要的是 图像生成或视频生成,Gemma 4 也不是正确家族。官方 model card 已经足够清楚:Gemma 4 是一个接受文本与视觉输入、输出文本的多模态开放模型家族,而不是 Google 的图像 / 视频生成产品线。
最后用一个正确心智模型收束
理解 Gemma 4 最好的方式,不是把它当成“又一个发布周品牌名”,而是把它当成一个 双线并行的开放模型家族。
第一条线是 端侧这条线:E2B 与 E4B,重点是本地执行、多模态端侧使用和设备级实用性。第二条线是 工作站这条线:26B A4B 与 31B,重点是更长上下文和更重的本地推理。只要你先把这条线选对,Gemma 4 其实一点也不复杂;如果跳过这一步,四个型号就会重新糊成一团。
所以最有用的快答也恰好最简单:想走严肃的端侧路线,就先看 E4B;想走严肃的工作站路线,就先看 26B A4B。 只有在效率是真瓶颈时再往更小退,只有在你明确知道自己要 dense 31B 的代价时再往更大走。