
Google 的 Gemini 3 Pro Image Batch API 为所有图片生成请求提供统一的 50% 折扣,2K 图片单价从 $0.134 降至 $0.067,4K 图片从 $0.24 降至 $0.12(Google AI 官方定价,2026 年 2 月)。对于每月需要生成数百甚至数千张图片的团队来说,仅此一项改动就能在不牺牲任何图片质量的前提下节省数千美元。本指南将详细讲解 Batch API 折扣的工作原理、如何用 Python 实现,以及如何叠加多种策略将节省比例提升至 80%。
要点速览
Gemini 3 Pro Image Batch API 的核心优势:使用异步批处理模式提交图片生成请求,即可获得 50% 的固定折扣。2K 图片单价从 $0.134 直降至 $0.067,4K 图片从 $0.24 降至 $0.12。结合第三方中转服务和分辨率优化等策略,总节省比例最高可达 80%。处理时间通常为 2-24 小时,图片质量与标准 API 完全一致。
深入了解 Gemini 3 Pro Image Batch API 折扣
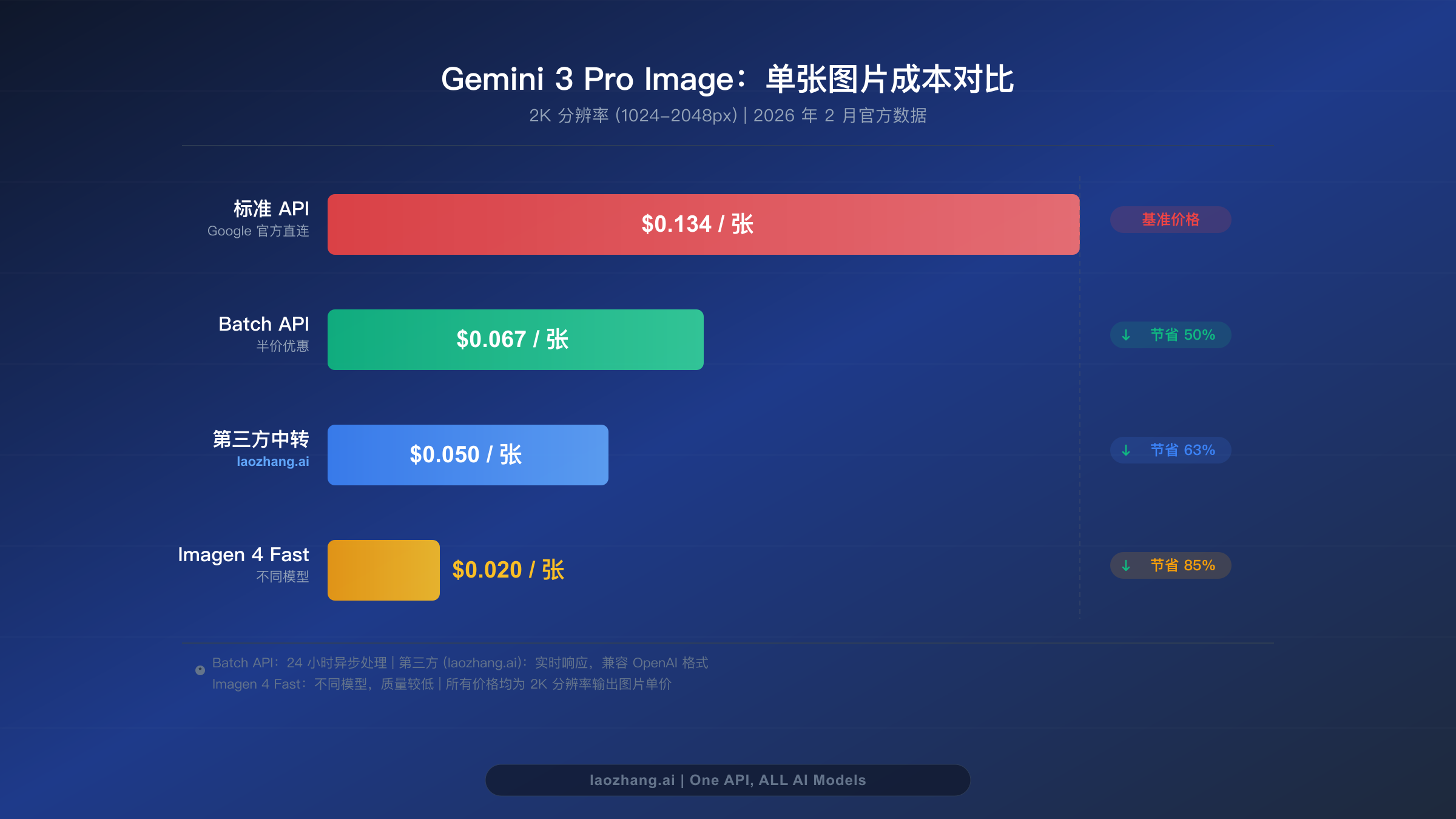
Gemini 3 Pro Image 模型——内部代号为 Nano Banana Pro,通过 gemini-3-pro-image-preview 模型 ID 访问——是截至 2026 年 2 月 Google 最强大的图片生成模型。它在文字渲染准确率方面达到 94%,输出质量达到专业级水准(FID 评分 12.4),并支持最高 4K 的分辨率。然而,标准 API 定价为每张 2K 图片 $0.134,一旦从偶尔使用进入生产级大规模图片生成,成本会迅速累积。这正是 Batch API 折扣发挥变革性作用的地方。
Batch API 对所有定价层级统一提供 50% 的折扣。当你通过批处理端点而非标准同步 API 提交图片生成请求时,Google 仅收取正常费率的一半。这个折扣并非促销活动,也没有时间限制——它是 Batch API 的永久特性,旨在激励异步工作负载,因为这类任务更容易被 Google 调度和高效处理。交换条件很简单:你接受最长 24 小时的处理窗口,换取成本减半。关于 Gemini 3 Pro Image 所有定价层级的详细分析,可以参考我们的 Gemini 3 Pro Image 定价与速度测试完整指南。
以下是各分辨率的具体定价明细:
| 分辨率 | 标准 API 价格 | Batch API 价格 | 节省幅度 |
|---|---|---|---|
| 1K(最高 1024px) | $0.134/张 | $0.067/张 | 50% |
| 2K(1024-2048px) | $0.134/张 | $0.067/张 | 50% |
| 4K(最高 4096px) | $0.240/张 | $0.120/张 | 50% |
值得注意的一个细节是,提示词的文本输入费用也减半了——从每百万 token $2.00 降至 $1.00。不过,对于一个典型的 100-150 token 的图片生成提示词来说,这大约相当于每次请求 $0.0001,与图片输出成本相比完全可以忽略不计。真正的节省完全来自输出定价的降低。
Batch API 图片生成的实际工作原理

在决定 Batch API 是否适合你的工作流程之前,有必要深入了解批处理的运作机制。Batch API 并非一个独立的模型或降级服务——它使用与标准 API 完全相同的 Gemini 3 Pro Image 模型,具备相同的质量、分辨率能力和功能支持。唯一的区别在于交付时间:你不再是在 8-12 秒内收到生成的图片,而是提交一批请求,在最长 24 小时的处理窗口内获取完成的结果(实际通常更快)。
批处理管线分为四个阶段运行。首先,你通过创建内联请求列表(适合 20MB 以下的较小批次)或 JSONL 文件(每行包含一个完整的请求对象,推荐用于最大 2GB 的较大工作负载)来准备请求。批次中的每个单独请求都支持 Gemini 3 Pro Image 的全部功能——你可以指定分辨率(使用大写标记的 1K、2K 或 4K)、十种支持格式(从 1:1 到 21:9)的宽高比、用于风格一致性的参考图片,甚至启用 Google Search 数据接地以实现实时数据可视化。模型独立处理批次中的每个请求,这意味着一个请求的失败不会影响其他请求。
其次,你通过 Batch API 端点提交批处理任务,指定模型和请求来源。Google 分配一个唯一的批处理任务 ID,并开始调度你的请求进行处理。系统自动管理速率限制、重试逻辑和请求分发——消除了你在使用同步 API 时通常需要在客户端处理的复杂逻辑。这是除成本节省之外的一个显著运维优势,尤其对于那些已经构建了自定义队列系统来管理大规模生成工作负载的团队而言。
第三,在处理过程中,Google 以比标准 API 更高的速率限制执行你的请求。标准同步 API 会强制实施每分钟和每日速率限制,这在高流量操作中可能造成节流瓶颈,而 Batch API 是专门为高吞吐量设计的。根据 Gemini API 速率限制文档,批处理任务可以在单次提交中处理数十万个请求。处理通常在 24 小时窗口内远远提前完成——许多用户报告中等批次的处理时间为 2-6 小时。
最后,你通过轮询批处理任务状态或设置回调来获取结果。每个完成的请求都包含生成的图片数据以及文本响应和元数据。系统还提供一个 batchStats 对象,包含成功和失败请求的计数,让你可以编程方式识别并重试失败的请求。保持在待处理或运行状态超过 48 小时的任务会自动过期,不过这是在实际操作中极少发生的边缘情况。
真实成本计算器——各规模下的费用明细
单张图片的价格差异在乘以实际生产规模后会变得极其可观。大多数关于 Batch API 折扣的文章止步于展示单张图片价格,但对预算规划真正有意义的是你实际运营规模下的月度和年度成本。下表展示了在四种定价方案下、各常见生产规模的精确费用,所有数据均按 2K 分辨率图片计算。
| 月用量 | 标准 API | Batch API | 第三方 (laozhang.ai) | Imagen 4 Fast |
|---|---|---|---|---|
| 100 张 | $13.40 | $6.70 | $5.00 | $2.00 |
| 500 张 | $67.00 | $33.50 | $25.00 | $10.00 |
| 1,000 张 | $134.00 | $67.00 | $50.00 | $20.00 |
| 5,000 张 | $670.00 | $335.00 | $250.00 | $100.00 |
| 10,000 张 | $1,340.00 | $670.00 | $500.00 | $200.00 |
| 50,000 张 | $6,700.00 | $3,350.00 | $2,500.00 | $1,000.00 |
年度节省对比(以月用量 5,000 张为例):
| 定价方案 | 月费用 | 年费用 | 相比标准 API 年节省 |
|---|---|---|---|
| 标准 API | $670.00 | $8,040.00 | — |
| Batch API | $335.00 | $4,020.00 | 节省 $4,020(50%) |
| 第三方中转 | $250.00 | $3,000.00 | 节省 $5,040(63%) |
| Imagen 4 Fast | $100.00 | $1,200.00 | 节省 $6,840(85%) |
Imagen 4 Fast 的数据需要一个重要说明:虽然它以 $0.02/张的价格成为最便宜的选项,但它是一个根本不同的模型,文字渲染准确率较低(约 85%,而 Gemini 3 Pro Image 为 94%),支持的分辨率更少,且不支持参考图片或多轮编辑。如果你的使用场景要求最高质量的文字嵌入渲染、角色一致性或 4K 输出,Gemini 3 Pro Image 仍然是合适的选择——而 Batch API 是降低其成本的最直接方式。
对于每月处理 10,000 张以上图片的团队,仅切换到 Batch API 一项,与标准定价相比,年度节省就超过 $8,000。如果结合第三方服务商处理对延迟敏感的工作负载(详见下方优化章节),节省潜力还会进一步增长。
分步实战:批量图片生成指南
如果你已经在使用 Gemini API,实现批量图片生成只需最少的代码改动。核心工作流程包括打包请求、作为批次提交、然后获取结果。开始之前,请确保你拥有有效的 API 密钥——如果需要获取密钥,请参考我们的 Nano Banana Pro API 密钥获取指南。
环境配置非常简单。使用 pip install -U google-genai 安装或更新 Google Generative AI Python SDK,然后就可以开始创建批处理任务了。
使用内联请求创建批处理任务
对于较小的批次(总大小不超过 20MB),你可以直接嵌入请求。这种方式适合生成几百张以内的图片:
pythonfrom google import genai from google.genai import types import base64 import time client = genai.Client(api_key="YOUR_API_KEY") image_prompts = [ "A professional product photo of a minimalist ceramic vase on a marble surface", "An isometric illustration of a modern home office workspace", "A watercolor painting of a coastal sunset with sailboats", "A flat design infographic showing quarterly revenue growth", ] # Build inline requests with resolution and aspect ratio settings inline_requests = [] for prompt in image_prompts: inline_requests.append({ "contents": [{"parts": [{"text": prompt}], "role": "user"}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "imageSize": "2K", "aspectRatio": "16:9" } } }) # Submit the batch job batch_job = client.batches.create( model="gemini-3-pro-image-preview", src=inline_requests, config={"display_name": "product-images-batch-001"} ) print(f"Batch job created: {batch_job.name}") print(f"State: {batch_job.state}")
使用 JSONL 文件创建批处理任务
对于更大规模的生产工作负载,JSONL 文件方式支持最大 2GB 的请求数据,是处理数千张图片时推荐的方法:
pythonimport json import tempfile # Generate JSONL file with image requests prompts = [f"Product photo variation {i} of a leather backpack" for i in range(1000)] with tempfile.NamedTemporaryFile(mode='w', suffix='.jsonl', delete=False) as f: for prompt in prompts: request = { "contents": [{"parts": [{"text": prompt}], "role": "user"}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "imageSize": "2K", "aspectRatio": "1:1" } } } f.write(json.dumps(request) + "\n") jsonl_path = f.name # Upload the JSONL file uploaded_file = client.files.upload(file=jsonl_path) # Submit batch job using the uploaded file batch_job = client.batches.create( model="gemini-3-pro-image-preview", src=uploaded_file, config={"display_name": "backpack-variations-1000"} ) print(f"Batch job created: {batch_job.name}")
监控与获取结果
提交后,你需要轮询任务状态,并在处理完成时下载结果:
pythonimport time from PIL import Image from io import BytesIO # Poll for completion while True: job = client.batches.get(name=batch_job.name) print(f"State: {job.state} | Progress: {getattr(job, 'batch_stats', 'N/A')}") if job.state == "JOB_STATE_SUCCEEDED": break elif job.state in ("JOB_STATE_FAILED", "JOB_STATE_CANCELLED"): print(f"Job ended with state: {job.state}") break time.sleep(60) # Check every minute # Retrieve and save generated images if job.state == "JOB_STATE_SUCCEEDED": for i, result in enumerate(job.results): if hasattr(result, 'response'): for part in result.response.candidates[0].content.parts: if hasattr(part, 'inline_data') and part.inline_data: img_data = base64.b64decode(part.inline_data.data) img = Image.open(BytesIO(img_data)) img.save(f"output_image_{i:04d}.png") print(f"Saved image {i}") # Check for failures stats = job.batch_stats print(f"\nCompleted: {stats.success_count} succeeded, {stats.failed_count} failed")
以上完整实现覆盖了批处理的整个生命周期——从请求准备到结果获取。相比自建队列系统,核心优势在于 Google 自动处理所有重试逻辑、速率限制和调度,而你同时享受 50% 的成本降低和更高的吞吐量限制。
高级批处理技巧——监控、错误处理与优化
超越基础实现,生产环境的批处理需要健壮的错误处理和优化策略。理解批处理任务的生命周期及其边缘情况,有助于构建无需人工干预就能处理数千张图片的可靠流水线。
处理部分失败
批处理任务可能整体成功,但其中个别请求失败。这种情况发生在特定提示词触发了内容安全过滤器、超出 token 限制或遇到临时处理错误时。已完成任务上的 batchStats 对象会告诉你有多少请求成功、多少失败,但你需要检查每个结果来确定哪些需要重试:
python# Identify and collect failed requests for retry failed_requests = [] for i, result in enumerate(job.results): if hasattr(result, 'error'): failed_requests.append({ "index": i, "error": result.error, "original_prompt": image_prompts[i] }) if failed_requests: print(f"{len(failed_requests)} requests failed. Resubmitting...") retry_requests = [ {"contents": [{"parts": [{"text": fr["original_prompt"]}], "role": "user"}], "generationConfig": {"responseModalities": ["TEXT", "IMAGE"], "imageConfig": {"imageSize": "2K"}}} for fr in failed_requests ] retry_job = client.batches.create( model="gemini-3-pro-image-preview", src=retry_requests, config={"display_name": "retry-failed-images"} )
优化批次大小与结构
Google 的文档建议将较小的请求合并为较大的批处理任务以获得更好的吞吐量。提交一个包含 10,000 个请求的批处理任务,其性能远优于提交 100 个各含 100 个请求的任务,因为每个任务都会产生调度开销。然而,极大的任务也承担更多风险——如果系统问题导致任务失败,你会丢失整个批次的进度。一个务实的平衡点是每个任务包含 1,000 到 5,000 个请求,这既能提供高效的处理,又能限制单次失败的影响范围。
对于企业级规模处理图片的组织,建议实现一个任务编排层,将总工作量拆分为可管理的批处理任务,在数据库中跟踪其完成状态,并自动将失败的单个请求重新分配到新批次中重试。这种模式既能享受批处理的成本优势,又能获得细粒度请求跟踪的可靠性。
取消与超时管理
已提交但尚未完成的任务可以通过 API 取消。当你发现批次中包含错误或业务需求发生变化时,这非常有用。保持在待处理或运行状态超过 48 小时的任务会被 Google 的系统自动过期,不过这个超时值足够宽裕,在正常情况下极少触发。如果你需要更严格的处理时间控制,可以实现客户端超时机制,在超过可接受窗口时取消任务:
pythonimport datetime # Submit job and track start time start_time = datetime.datetime.now() max_wait_hours = 12 # Cancel if not done in 12 hours while True: job = client.batches.get(name=batch_job.name) elapsed = (datetime.datetime.now() - start_time).total_seconds() / 3600 if job.state == "JOB_STATE_SUCCEEDED": print(f"Completed in {elapsed:.1f} hours") break elif elapsed > max_wait_hours: client.batches.cancel(name=batch_job.name) print(f"Cancelled after {elapsed:.1f} hours") break time.sleep(300) # Check every 5 minutes
Batch API、标准 API 还是第三方中转——哪个最适合你?
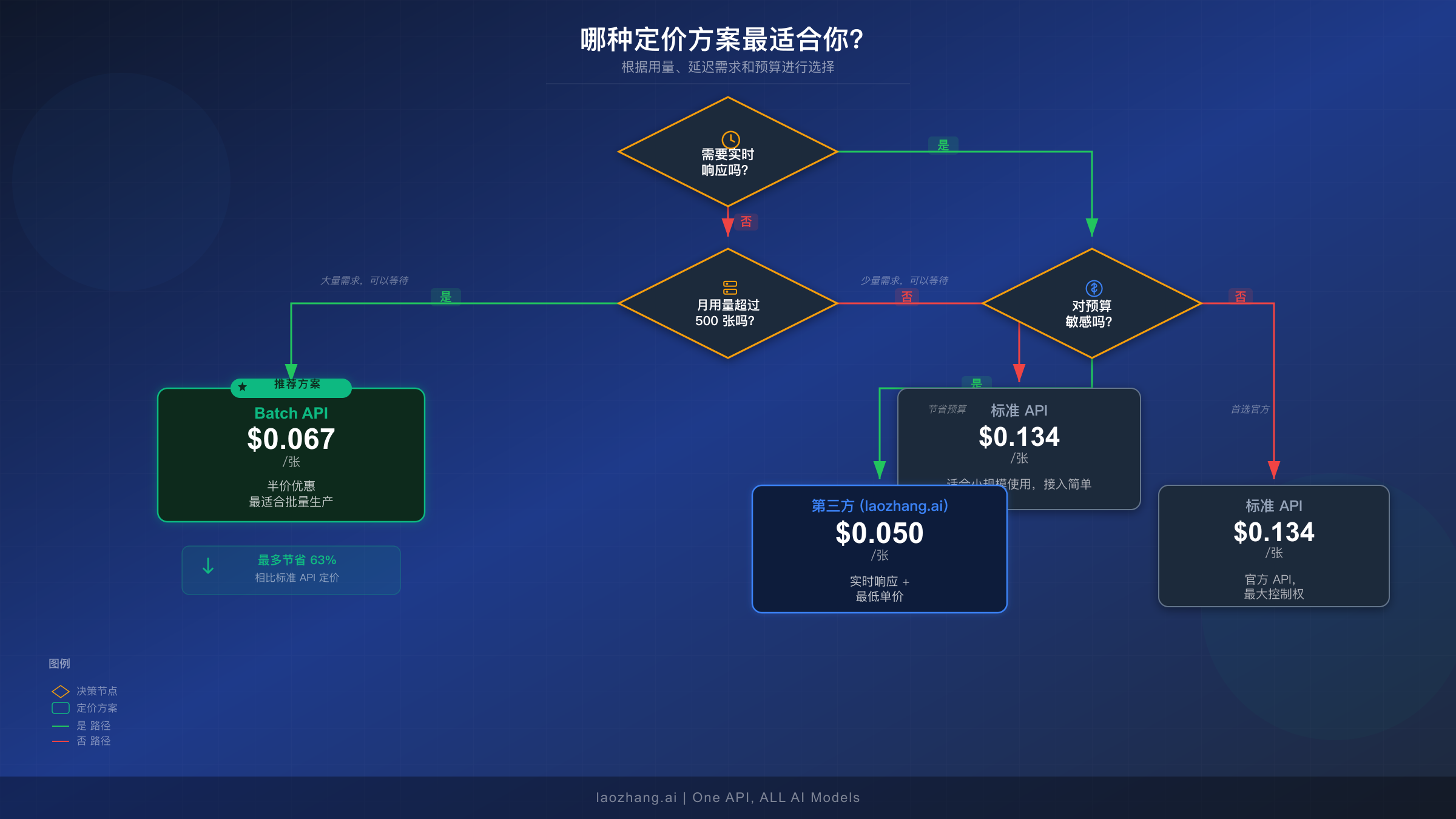
选择合适的定价方案取决于三个因素:你的延迟要求、月度用量和预算敏感度。每种方案服务于不同的使用场景,根据你的具体情况,最佳选择会有显著差异。要了解所有 AI 图片生成 API 的更全面比较,可以参考我们的 2026 年 AI 图片生成 API 对比指南。
标准 API($0.134/张)适用场景: 你需要 8-12 秒内的实时图片生成响应,月用量低于 500 张,或者需要对生成管线进行最大控制并获得直接同步反馈。典型使用场景包括聊天机器人图片生成、交互式设计工具,以及用户正在等待结果的实时内容创作应用。标准 API 提供最简单的集成路径,具备即时响应处理能力,无需任务管理开销。
Batch API($0.067/张)的明确优势场景: 你可以接受 2-24 小时的处理延迟,月生成量在 500 张以上,且降低成本是优先事项。这是以下场景的理想选择——电商产品图片目录(夜间生成图片,次日更新商品列表)、营销团队制作定时发布的社交媒体批量活动视觉素材、内容平台生成插图素材库,以及任何提前准备图片而非按需生成的工作流程。50% 的节省在规模化运营中累积效果惊人——一个每月生成 5,000 张图片的团队,从标准 API 切换到批处理后,每年可节省超过 $4,000。
像 laozhang.ai 这样的第三方中转服务商($0.05/张)在以下场景极具吸引力: 你既需要实时响应,又希望获得比 Google 标准 API 更低的价格。这些平台通过自有基础设施提供对相同 Gemini 3 Pro Image 模型的访问,通常价格比官方定价低 60-80%。需要权衡的是,你的请求会经过第三方服务路由,这对敏感工作负载可能需要考量。关于第三方选项的详细对比,我们的最便宜 Gemini 图片 API 完整指南涵盖了主要服务商。第三方中转服务商特别适合大批量、对延迟敏感的工作负载——Batch API 的 24 小时窗口太慢,但标准 API 定价又太贵。
对于很多生产环境来说,最优策略其实是混合方案:将 Batch API 用于计划内的大批量生成任务(如目录更新和活动素材准备),同时将紧急的实时请求通过高性价比的第三方中转服务路由。这种组合既能在批量工作中获得最深折扣,又能在交互式使用场景中保持响应速度。
叠加折扣——如何在图片生成上最高节省 80%
Batch API 的 50% 折扣是基础,但这并非唯一的成本降低策略。通过组合多种优化技术,你可以将每张图片的有效成本从 $0.134 降至最低 $0.027——总计降低 80%。以下策略可以相互叠加,按影响力和实施难度排序。
分辨率优化是最简单且影响最大的第一步。 如果你的输出要求允许,生成 2K 分辨率而非 4K 分辨率的图片,批处理价格从 $0.12 降至 $0.067——在批处理折扣之上再省 44%。许多网页和社交媒体应用以 1024px 或更小尺寸显示图片,使得 4K 生成成为不必要的开销。在默认选择最大分辨率之前,先审视一下你的实际显示尺寸。关于分辨率权衡的更多细节,我们的 Nano Banana Pro 4K 指南有深入探讨。
提示词优化可以降低 token 成本并提升生成一致性。 虽然提示词输入成本微乎其微(每次请求约 $0.0001),但更短、更精确的提示词实际上比冗长的描述产生更好的效果。一个简洁的 50 token 提示词比一个塞满冗余细节的 500 token 提示词生成的图片伪影和误解更少。这虽然不能直接降低单张图片成本,但能提升你的成功率,减少为获得可接受输出而需要的重新生成次数。
上下文缓存功能即使在批处理模式下也可使用,能节省重复提示词元素的费用。 如果你生成的多张图片共享相同的系统指令或风格指南,上下文缓存对已缓存内容仅收取标准输入价格的 10%。对于每个请求都包含相同 1,000 token 风格指南的批处理任务,这将每次请求的提示词成本降低 90%——在超大规模下是一项虽小但可衡量的优化。
将批处理与第三方中转服务结合使用,可以创造最深层的折扣叠加。 对于既有计划内生成又有按需生成需求的组织,将批量工作负载通过 Google 的 Batch API 以 $0.067/张处理,实时请求通过 laozhang.ai 以 $0.05/张处理,产生的混合费率优于任何单一定价方案。一个将 5,000 张月度图片分配为 3,000 张批处理和 2,000 张实时的团队,月费用为(3,000 x $0.067)+(2,000 x $0.05)= $301,而标准定价为 $670——混合节省 55%。
最大节省方案叠加了批处理(50% 折扣)、2K 分辨率选择(省去 4K 溢价)、提示词优化(减少重试)以及策略性利用 Google AI Studio 的每日免费配额(每天约 50 张免费图片,即每月 1,500 张)。对于需要 5,000 张月度图片的团队:1,500 张免费 + 3,500 张批处理 x $0.067 = 月费 $234.50,低于标准定价的 $670——总计降低 65%。愿意将部分量路由到第三方中转的团队可以将总节省推至 80% 以上。
常见问题解答
Batch API 生成的图片质量比标准 API 低吗?
不会。Batch API 使用与标准 API 完全相同的 Gemini 3 Pro Image 模型,具备相同的质量、分辨率支持和功能。50% 的折扣纯粹是异步处理的定价激励——Google 可以更高效地调度批处理任务,并将这些节省传递给用户。你的批处理生成图片与标准 API 输出逐像素一致。
批量图片生成实际需要多长时间?
Google 的目标处理时间为 24 小时,但实际上大多数批处理任务完成得快得多。用户经常报告中等批次(数百到数千张图片)的完成时间为 2-6 小时。实际处理时间取决于系统负载、批次大小和图片生成请求的复杂度。建议在工作流程设计中预留完整的 24 小时窗口,同时预期更快的交付。
一次批处理最多能生成多少张图片?
Batch API 在单个 JSONL 文件中支持最大 2GB 的请求数据,可以包含数十万个单独的图片生成请求。对于内联请求,限制为 20MB。每个任务没有明确的请求数量上限,但 Google 建议每个任务包含 1,000-5,000 个请求以获得最佳吞吐量和可管理性。
Gemini 3 Pro Image 的免费层级可以用于批处理吗?
Gemini 3 Pro Image 模型(gemini-3-pro-image-preview)在标准 API 和 Batch API 访问中都没有免费层级(Google AI 官方定价,2026 年 2 月)。不过,Google AI Studio 通过其网页界面每天提供约 50 次免费图片生成,可以作为付费 API 使用的补充,用于测试和小规模生产。
批处理模式支持参考图片和多轮编辑吗?
Batch API 支持 Gemini 3 Pro Image 的全部功能,包括文生图、参考图片(每次请求最多 14 张:6 张物体图和 5 张人物图)、分辨率控制、宽高比选择和 Google Search 数据接地。但是,批处理模式不直接支持多轮对话编辑,因为批处理请求是无状态的——每个请求独立处理,没有对话上下文。