
Claude Sonnet 4.6 在某些自我识别场景里确实会回答自己是 DeepSeek,尤其是在中文短提示、系统提示较弱或缺失的时候。更合理的读法,是把它看成身份锚点不足时的自我识别混乱,而不是把它直接升级成 Anthropic 把 Sonnet 换成了 DeepSeek,或者 一张截图就足以证明蒸馏关系。
“证据说明:本文基于 Anthropic 公开的 models overview、Claude 4.6 概览、system prompts 页面、release notes,以及 Anthropic 2026 年 2 月 23 日发布的 distillation post,并结合 OpenRouter 的 provider routing 文档 和公开社区讨论。
TL;DR
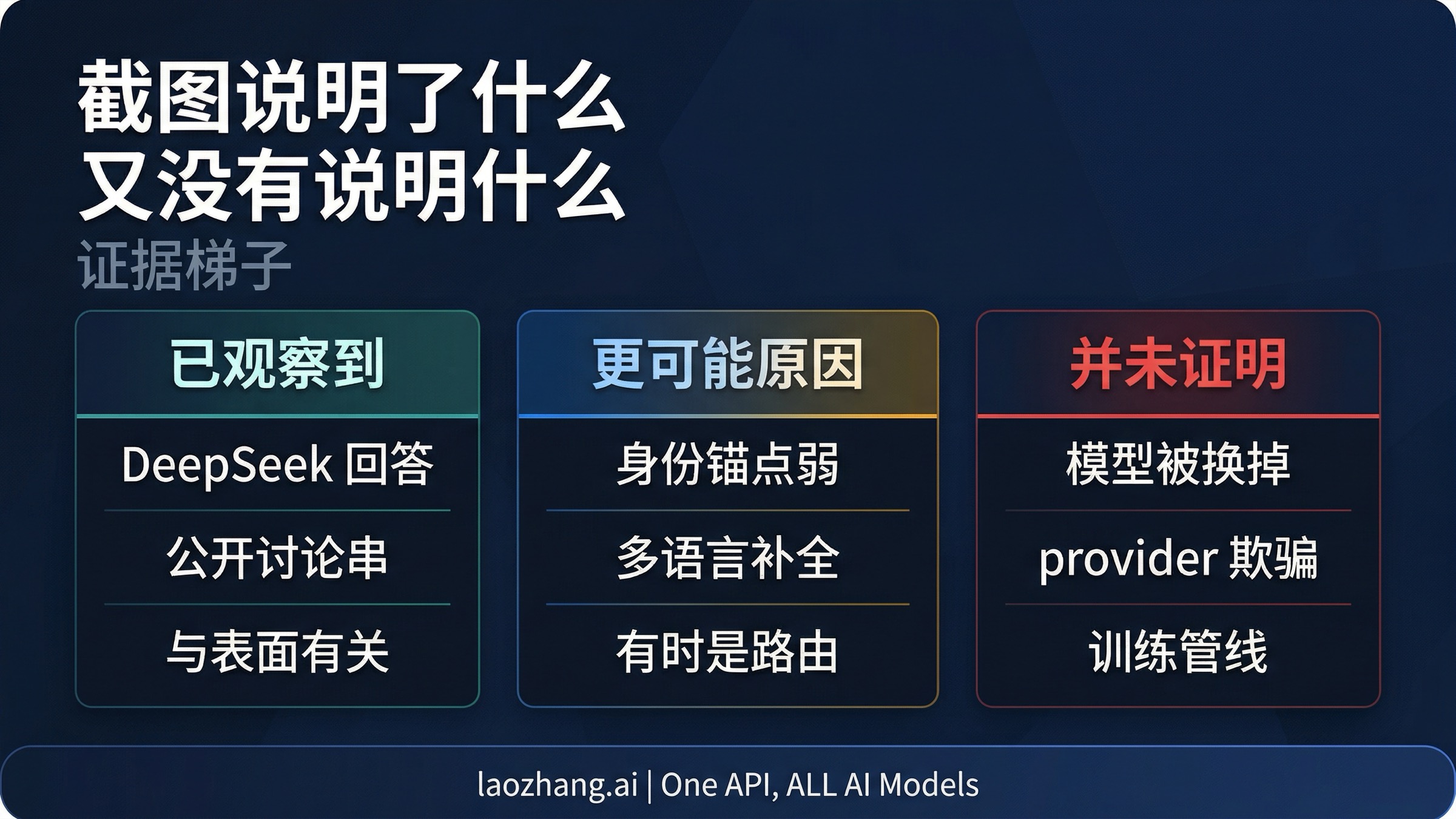
- 是的,这种自称 DeepSeek 的现象足够真实,值得解释。 多个公开讨论串都记录了 Claude Sonnet 4.6 在回答“你是什么模型”时说自己是 DeepSeek,尤其集中在中文提示和弱 system prompt 场景。
- 但这不等于 Sonnet 4.6 实际上就是 DeepSeek。 Anthropic 公开文档仍然把 Sonnet 4.6 列为当前 Claude 型号,并明确给出
claude-sonnet-4-6这个公开 API alias。 - 当前最强解释是 prompt / surface 边界问题,而不是公开型号被替换。 Anthropic 自己的文档写得很清楚:claude.ai 和移动端会注入 system prompt,但 Claude API 不会继承这一层。
- Anthropic 对 DeepSeek 的公开指控,改变的是舆论张力,不是证据标准。 Anthropic 在 2026 年 2 月 23 日公开指控 DeepSeek 做过规模化 capability extraction,所以这个截图天然更容易被解读成“反向打脸”,但这仍然不等于完整证明。
- 如果你真的要确认模型身份,应该查调用路径,而不是相信模型的自我介绍。 看 model ID、锁定 provider、补 identity anchor、对比 app / API / gateway 三条路径,才是更可靠的方法。
现在真正能确认的事实
这个话题最容易出错的地方,是把观察到的回答和公开型号合同混成一层。前者是一次或多次对话里的生成结果,后者是 Anthropic 对外声明自己在卖、在提供、在支持什么模型。二者可以冲突,但冲突本身不意味着截图自动赢过官方合同。
截至 2026 年 4 月 1 日,Anthropic 的公开 models overview 仍然把 Claude Sonnet 4.6 列为当前公开模型,并且明确给出 claude-sonnet-4-6 这个公开 API alias。Anthropic 的 release notes 也写明 Sonnet 4.6 的公开发布时间是 2026 年 2 月 17 日。换句话说,Sonnet 4.6 不是社区传闻里的名字,也不是某个路由器临时拼出来的标签,它是 Anthropic 当前公开型号栈的一部分。
同样能确认的是,Anthropic 在 2026 年 2 月 23 日把自己和 DeepSeek 的冲突公开化了。在那篇 distillation post 里,Anthropic 直接点名 DeepSeek、Moonshot、MiniMax 三家实验室,并在 DeepSeek 章节写到 150,000 次以上 exchanges 与 reasoning、reward-model 风格任务有关。这个背景很关键,因为它解释了为什么 Claude 一旦自称 DeepSeek,这张截图就不再像普通 bug,而会被自然读成“你不是刚说 DeepSeek 在偷 Claude 吗?”
但另一个同样重要的事实是:截至 2026 年 4 月 1 日,Anthropic 没有公开发过一篇 help-center 文章或 release note 来解释这个 DeepSeek 自我识别现象。没有公开 bug note,没有公开修复说明,也没有公开根因分析。所以,最稳妥的写法不是“官方已承认某 bug”,而是“公开型号合同 + 观察到的行为 + 明确标注为推断的解释”。
这听起来保守,但它恰恰是这个 query 最需要的纪律。公开型号合同告诉你 Anthropic 说自己在提供什么;截图只告诉你模型在某个 prompt envelope 里生成了什么回答。两者冲突值得研究,但并不构成“截图已经推翻一切”的捷径。
如果你真正想看的不是这个 glitch,而是 Anthropic 当前公开型号栈本身,可以进一步看我们的 Claude Opus 4.6 定价与订阅指南。
Sonnet 4.6 为什么会说自己是 DeepSeek

最可信的解释,不是一个惊天内幕,而是几个较小但叠加起来足够有解释力的事实。
第一层,是身份锚点。Anthropic 的 system prompts 页面 明确写着:Claude 的网页端和移动端会在会话开始时使用 system prompt,而这些 system-prompt 更新不适用于 Claude API。这意味着,同样一句“你是什么模型”,落在不同表面时,起始上下文本来就不一样。一条路径里,模型可能被更强地提醒“你是谁”;另一条路径里,你更接近没有额外身份保护的原始回答行为。
这当然不能单独解释所有截图,但它足以解释为什么“自我识别”不是跨表面稳定不变的。只要身份锚点不够强,模型在回答短促的自我介绍问题时,就更像是在根据当前上下文做最可能的补全,而不是在读取一个不可篡改的内部铭牌。
第二层,是多语言补全行为。公开案例几乎都集中在 你是什么模型? 这类中文短提示,而不是一段已经明确写着 Claude Sonnet 4.6 的英语长上下文。这里最合理的推断是:当模型缺少清晰身份锚点时,中文短提示更容易触发它去补全一个“熟悉的模型自我介绍模板”。在现有公开材料下,把这层解释写成推断比写成“Anthropic 官方已确认原因”更安全;但它仍然比“所以模型本体其实就是 DeepSeek”要严谨得多。
第三层,是 routing 和 wrapper。OpenRouter 的 provider routing 文档 写明,默认策略并不是简单的“一模型一 provider 直通”,而是 price-based load balancing,并且可以配置 fallbacks。这意味着,经过 gateway 的路径里,除了模型本身,还多了一层 provider 选择与回退逻辑。它不一定解释所有案例,因为公开线程里也有人声称在 Anthropic 官方 API、空 system prompt 下看到相同现象;但它确实解释了为什么“截图来自哪条路径”是核心细节,而不是可有可无的背景信息。
所以,这个话题最重要的一句判断其实很简单:模型会在自我识别上出错,并不等于你调用的模型已经不是它。 大模型擅长很多任务,但在缺少清晰身份锚点时,它并不是自己来源的可信鉴定器。它的回答会受到 prompt envelope、语言环境、调用表面和 provider 路由的共同影响。
这个解释没有阴谋论那么刺激,但和公开证据的贴合度更高。
这个回答不能证明什么
围绕这个现象,最常见的过度推断大致有三类。
第一类是:Claude Sonnet 4.6 其实就是 DeepSeek。 这个结论太强了。Anthropic 的公开文档仍然把 Sonnet 4.6 列为当前公开 Claude 型号,并给出了清晰的 API alias、发布日期、上下文窗口与产品定位。一句错误的自我介绍回答,不足以抹掉这层公开合同。
第二类是:Anthropic 实际上在偷偷给你路由别家的模型。 这个结论也太强,尤其是公开案例本来就横跨不止一条表面。有些截图如果来自 gateway,provider 层确实可能增加不确定性;但公开讨论里也有人声称,在 Anthropic 官方 API、空 system prompt 下也能复现类似现象。所以你既不能把所有案例都简单解释成“gateway 作祟”,也不能反过来从截图直接跳到“Anthropic 根本没在提供 Claude”。
第三类是:这已经证明 Anthropic 用了 DeepSeek 的输出训练 Sonnet 4.6,而且就和 Anthropic 指控 DeepSeek 的 distillation 是同一类事。 这条推断最诱人,因为叙事张力很强。Anthropic 刚刚公开指控 DeepSeek 在大规模抽取 Claude 的能力,然后 Claude 又在一些 prompt 里说自己是 DeepSeek。这种反差很容易被读成“铁证”。但舆论上很有杀伤力,不等于技术上已经完成举证。这张截图最多说明:在身份锚点较弱时,竞争对手的 identity pattern 可能会浮出水面。它并不足以单独证明 Anthropic 的训练管线到底怎么做过。
什么才算更强的证据?至少要有更干净的官方 API 复现实验、严格控制 prompt 条件的对照、比“模型自我介绍”更硬的 provenance 证据,甚至接近 model-card 级别或训练流程级别的材料。单张截图、单个短 prompt,不足以跨过那个门槛。
所以这里最稳妥的姿态既不是否认,也不是“我已经看透了”。而是提高证明标准。这个现象足够真实,足够值得解释;但它还不够强,不能支撑人们最想从中拿走的所有结论。
这和 Claude Capybara 这类 Anthropic 传闻型 query 的处理逻辑其实是一样的:先把公开合同和最吸引眼球的叙事拆开,再讨论证据真正能承受到哪一步。
怎样更可靠地验证模型身份
如果你的目标真的是确认自己到底在调用什么模型,那么直接问模型“你是谁”,其实是整套方法里最弱的一步。更可靠的路径应该像这样:
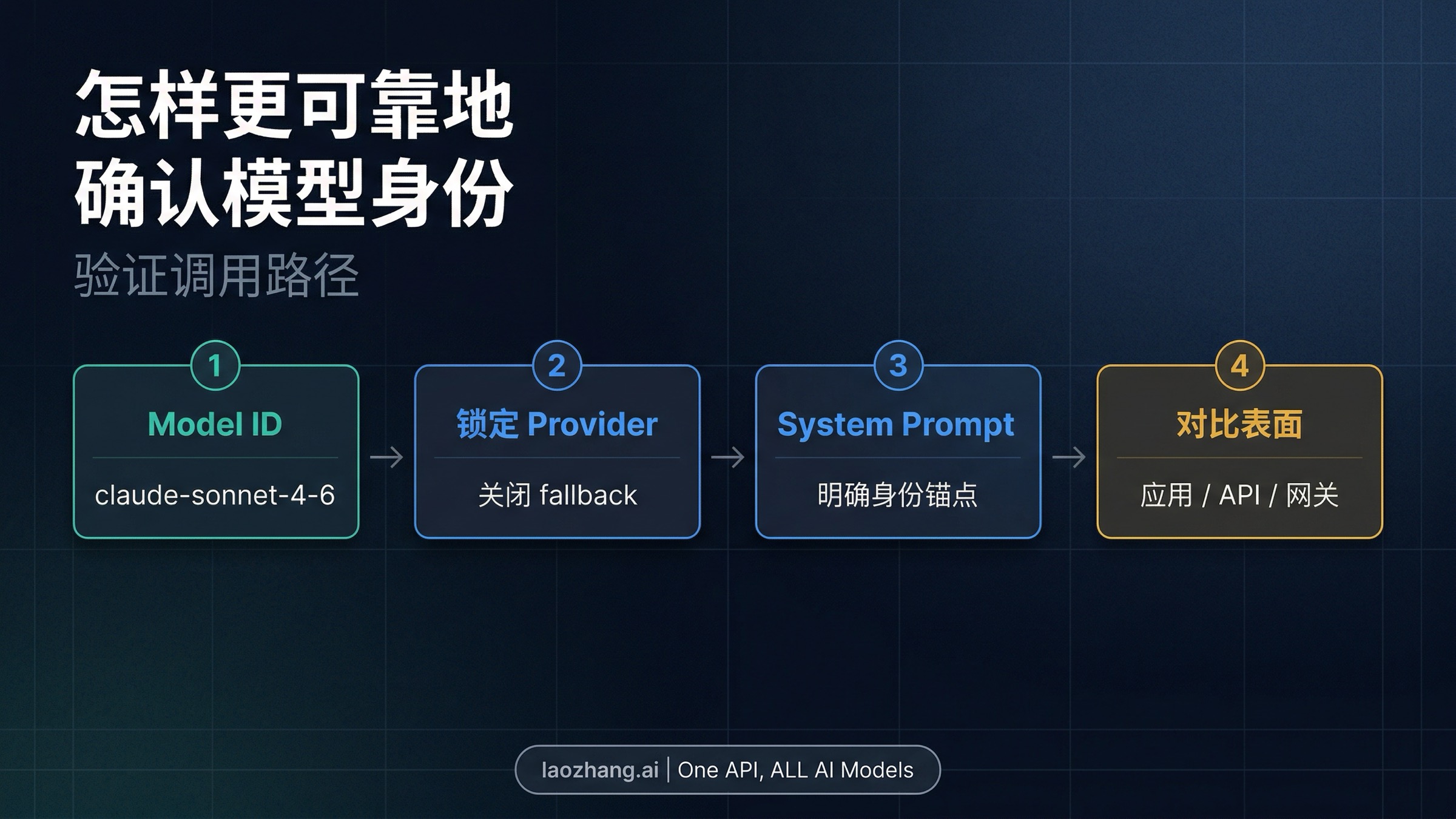
- 先看配置里的 model ID。 对 Anthropic 当前公开型号来说,Sonnet 4.6 对应的是
claude-sonnet-4-6。在解读模型的自我描述之前,先确认你发出去的到底是什么模型名。 - 如果你走 gateway,就锁定 provider 路径。 在 OpenRouter 或其他路由层里做 identity-sensitive 测试时,应该尽量关闭 fallbacks,或者明确指定 provider,减少路由带来的歧义。
- 补一个明确的 identity anchor。 这不是教模型“撒谎”,而是让测试本身不要过度欠规格。如果一个模型只有在被补充身份锚点后才会稳定回答自己是谁,那本身就是有价值的信息。
- 跨表面对照,而不是相信单一路径。 用同一个问题分别去测 claude.ai、Anthropic 官方 API,以及你实际在用的 gateway 路径。Anthropic 自己的文档已经告诉你,这些表面并不共享同一个 prompt envelope。
- 把关键条件记下来。 request model、provider 选择、fallback 设置、system prompt 状态、提示词语言,这些都应该记录。否则你拿到的不是调试材料,而只是下一张会继续引战的截图。
这套方法的意义,不是让 glitch magically disappear,而是把问题从“这回答太诡异了”推进到“这条路径、这组参数、这个 prompt,导致了这个输出”。到了这个层面,讨论才开始具有工程意义。
它也会改变你对现有截图的阅读方式。没有 route、没有 prompt、没有 fallback 说明的截图,并不是完全没价值;但它的证据强度比很多人想象得低得多。只要把 provider lock、identity anchor、surface difference 这些因素纳入判断,你就会发现这件事没有社交媒体里看起来那么神秘,却比“简单对骂”更值得认真解释。
为什么 Anthropic vs DeepSeek 这层语境仍然重要
这个截图会传播得这么快,并不是偶然。它正好落在一个已经存在的公开叙事冲突上:Anthropic 说 DeepSeek 对 Claude 做了 distillation attack,随后人们又看到 Claude 在某些 prompt 里自称是 DeepSeek。哪怕根因只是 prompt 边界弱、多语言补全偏移或 routing 变量,这个画面效果对 Anthropic 也非常糟糕。
这层语境不应该被淡化。Anthropic 在 2026 年 2 月 23 日的公开帖子里,不只是轻描淡写提到 DeepSeek,而是明确点名,并描述了它认定的规模和目标。所以,当 Sonnet 4.6 回答 I am DeepSeek 或中文等价句时,读者当然会用 Anthropic 自己制造出来的框架去理解它。
但最值得保留的结论,不是“因此 Anthropic 对 distillation 的指控自动失效”。更有价值、也更克制的结论是:竞争对手的 identity pattern 可以在模型行为里浮现,但这和完整证明 weights、provenance、training method 仍然不是同一回事。 这张截图之所以强,不是因为它已经完成了所有证明,而是因为它同时具备“直观”“讽刺”“可传播”三种传播优势。
也正因为如此,这个话题不只是一个有趣 bug。它暴露了一个更底层的问题:很多用户仍然把模型的自我介绍,当成某种可信系统状态。这在大模型时代往往是不成立的。Anthropic 和 DeepSeek 的冲突只是把这个盲点放大了,但真正该吸收的经验比公司恩怨更普遍。如果身份真的重要,请优先信任系统级证据,而不是生成式自述。
FAQ
Claude Sonnet 4.6 真的会说自己是 DeepSeek 吗?
会。公开讨论里已经有足够多的案例,足以把这个现象视为“值得解释的真实现象”。但目前没有 Anthropic 官方根因说明或当前可复现状态公告。
这是不是就说明 Sonnet 4.6 实际上就是 DeepSeek?
不是。Anthropic 公开文档仍然把 Sonnet 4.6 列为当前公开 Claude 模型。更稳妥的读法,是把它看成弱 prompt 条件下的自我识别失败。
这是不是只发生在 OpenRouter?
不能这么写死。gateway routing 在某些案例里确实可能增加歧义,但公开讨论也有人声称在 Anthropic 官方 API、空 system prompt 下看到类似现象,所以“只有 OpenRouter 才会这样”也过度简化了。
这能不能证明 Anthropic 用了 DeepSeek 的输出训练模型?
不能。它最多说明竞争对手的 identity pattern 会在某些 prompt 条件下浮现,但这和证明具体训练路径、证明非法蒸馏,并不是同一层证据。
为什么这个问题在中文里显得更明显?
因为公开案例高度集中在中文短提示上。当前最合理的推断是:中文短自我识别 prompt 给模型留下了更大的模板化补全空间,而 Anthropic 并没有公开确认更具体的原因。
最终结论
Claude Sonnet 4.6 在某些自我识别 prompt 里会说自己是 DeepSeek,核心原因更像是模型身份比很多用户以为的更脆弱、更依赖表面和 prompt 边界。Anthropic 自己的文档已经给出一条关键线索:claude.ai 和移动端有 system prompt,而 API 不继承这一层。再叠加多语言补全行为,以及在某些路径里 gateway routing 带来的额外变量,这个回答就不再像“神秘自白”,而更像一次边界暴露。
这并不意味着截图毫无意义。对于 Anthropic 来说,在它刚刚公开指控 DeepSeek 之后出现这种自称现象,确实是非常糟糕的 optics。但更负责任的结论仍然是:模型的自我介绍不是 provenance API。 如果你想知道自己到底在调用什么,请优先看 model contract、provider path 和 prompt envelope,而不是把模型在弱身份锚点下的自述,当成最终裁决。