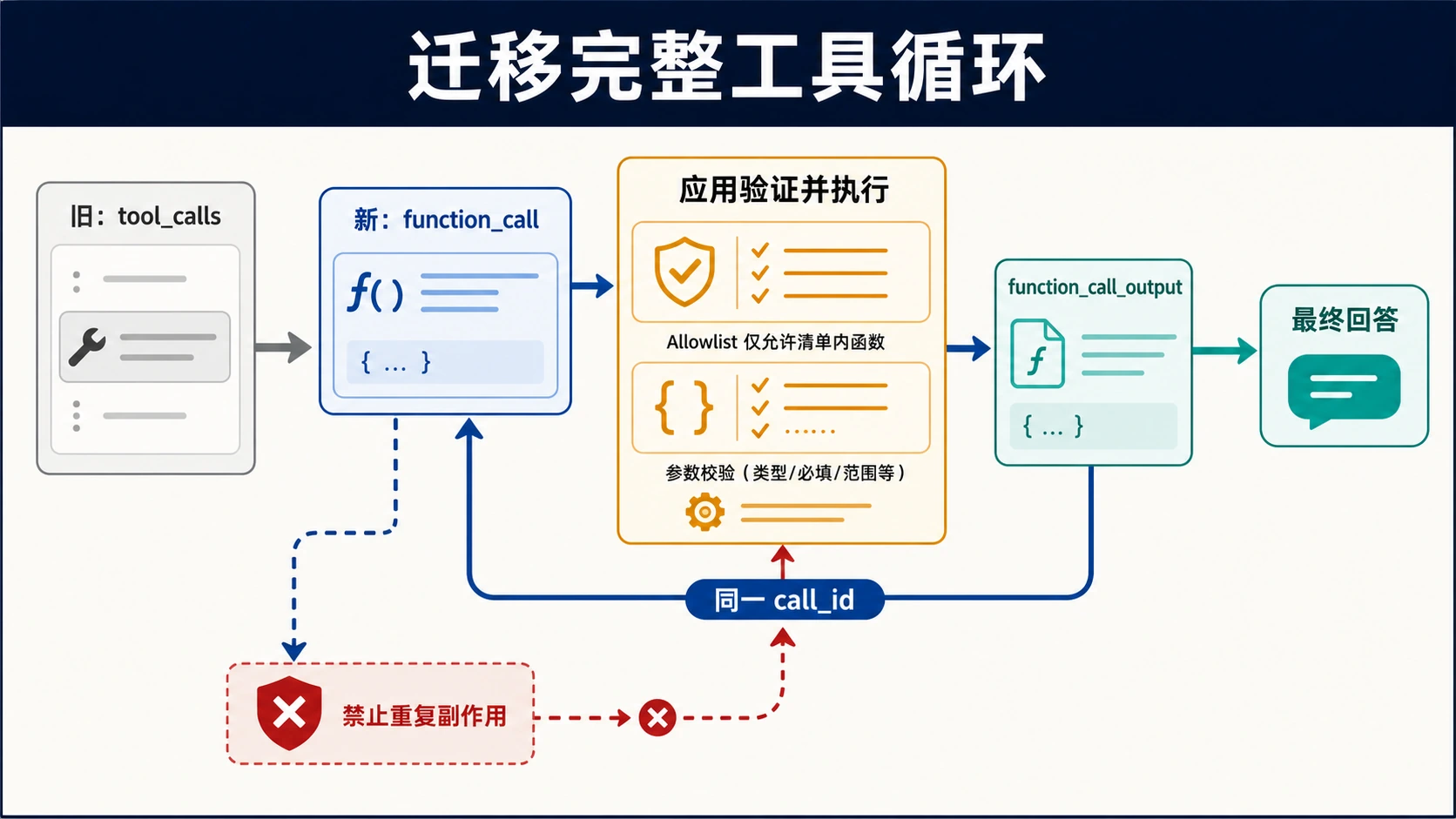
Claude Fable 5 和 GLM-5.2 现在不是两条同等可运行的选择。按 2026 年 6 月 14 日复核到的官方材料,Anthropic 已说明 Fable/Mythos 访问被停用,所以 Fable 5 只能作为等待复核的分支;Z.AI 文档把 GLM-5.2 放在 GLM Coding Plan 里,因此 GLM-5.2 是可以先做小范围 Coding Agent 测试的分支。
这不等于 GLM-5.2 自动替代 Fable 5。你不能因为一边暂时跑不了,另一边在文档里可见,就把生产默认模型改掉。正确顺序是:先确认当前可用性,再用同一个 repo、同一个 issue、同一个 prompt、同一组工具权限和同一条验收测试来测,最后才讨论谁更适合你的工作流。
| 分支 | 什么时候走 | 第一动作 | 停止规则 |
|---|---|---|---|
| 等 Fable 5 | 你必须评估 Anthropic 自有模型行为、账单、策略或 fallback。 | 重新检查 Anthropic access statement、model docs 和 pricing docs。 | 如果当前不能运行 Fable 5,就不要给它的实时任务表现打分。 |
| 小测 GLM-5.2 | 你需要本周能跑的 Coding Agent 路线。 | 在 Z.AI Coding Plan 里确认 GLM-5.2 或 GLM-5.2[1m],再跑一个边界清晰的小任务。 | 任务没有通过、延迟和配额没有记录、回滚成本不可控时,不叫替代。 |
| 保留双跑包 | 你正在考虑团队默认模型或生产路由变更。 | 保存同一任务包,等 Fable 恢复后再跑同一组输入。 | 没有两边都可运行的同一任务证据,就没有胜负结论。 |
证据提示: 本文使用的 Anthropic Fable 发布页、访问状态、模型与价格文档,以及 Z.AI GLM Coding Plan 文档,复核时间是 2026 年 6 月 14 日。模型可用性、配额、价格和路由随时可能变,发布或改默认路由前要回到官方文档重新确认。
快速结论:先问能不能跑
如果你的问题是“今天该先测试谁”,答案不是按模型名排强弱,而是按路线排。Fable 5 当前不是一个适合开始 live Coding Agent 评测的分支,因为 Anthropic 的访问说明写明 Fable 5 和 Mythos 5 已对所有客户停用。它的上下文、输出上限、价格行和模型 ID 仍然有参考价值,但在不可访问期间不能拿来跑同一任务。
GLM-5.2 则是可以先验证的分支。Z.AI 最新模型文档列出了 GLM Coding Plan 对 GLM-5.2 的支持,工具集成文档也给出 OpenAI-compatible 的 coding provider 路径和 GLM-5.2 / GLM-5.2[1m] 这类标签。这个证据足够让你做 smoke test,但还不足以让你写“GLM-5.2 全面胜出”。
把“先测谁”和“谁更好”分开,会少很多误判。前者是可用性问题,后者是同一任务证据问题。现在可以先测 GLM-5.2;如果 Fable 恢复访问,再把保存好的任务包拿去双跑,而不是拿新任务去对比旧印象。
本地讨论容易把问题讲成一场戏
中文讨论里很容易把这件事包装成“Fable 全面封禁、GLM-5.2 全面放开”的戏剧化叙事。这个叙事抓住了时间线,但容易漏掉两个关键边界:第一,Fable 不可用时不能公平参与 live task;第二,GLM-5.2 可见并不等于它已经通过你的代码库、测试、延迟和回滚标准。
所以不能只写“国产替代”或“全面开放”。真正要做的是把信息分层:官方访问状态归 Anthropic,GLM Coding Plan 归 Z.AI,生产默认模型归自己的任务验收,视频或论坛实测只能作为线索,不能代替你自己的同一任务包。
更稳的处理方式是不要把封禁新闻和模型能力揉成一个结论,而是回到操作层。你要先确认哪条路线能跑,再确认单位怎么计费,最后确认这条路线是否能在你的 repo 里交出可审查的 diff。
本周真正改变的是可用性
Anthropic 在 2026 年 6 月 9 日宣布 Claude Fable 5。几天后,独立的 Fable/Mythos access statement 说明 Fable 5 和 Mythos 5 因美国政府指令需要对所有客户停用。这个变化让任何“Fable vs GLM”的静态表格都不完整,因为表格如果不先写可用性,就会暗示两边都能被同样测试。
Z.AI 的证据层不同。GLM-5.2 不是在本文证据里以一个通用 API 发布页出现,而是作为 GLM Coding Plan 的文档化路线出现。文档提到 GLM-5.2 支持,并在工具路径里展示了 GLM-5.2 与 1M context 相关配置。正确读法是:这里有一条需要你验证的路线,而不是所有 wrapper、旧 GLM 对比页、社交媒体截图都自动适用。
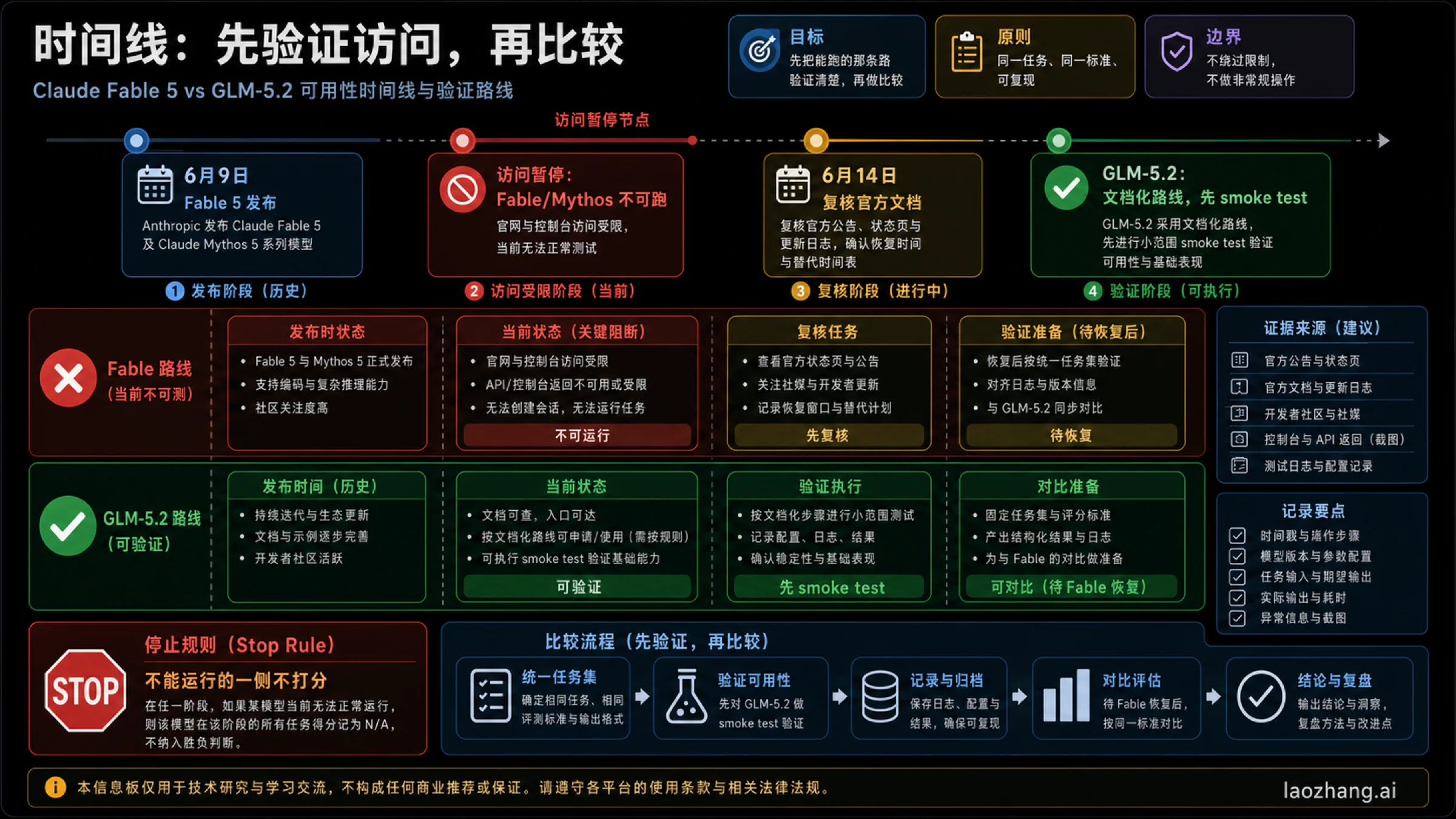
如果你无法运行 Fable,就不要给 Fable 的同一任务表现打分。如果你能运行 GLM-5.2,也不要因为它能跑就直接升级为默认。可用性只决定测试顺序,不决定生产信任。
官方合同表:谁拥有哪条说法
| 合同点 | Claude Fable 5 | GLM-5.2 |
|---|---|---|
| 先找谁确认 | Anthropic | Z.AI |
| 2026-06-14 当前状态 | Fable/Mythos 访问说明显示不可用。 | GLM Coding Plan 文档中可见。 |
| 需要盯的模型标签 | claude-fable-5 | glm-5.2 与 glm-5.2[1m] |
| 上下文边界 | Anthropic 文档列出 1M context 与 128k output,但当前不可运行。 | Z.AI coding route 记录 1M context 类路线。 |
| 成本单位 | Anthropic 是 per-million-token 价格行。 | Coding Plan 是配额或倍率消耗规则。 |
| 对 Coding Agent 的含义 | 规格强,但当前只能等待复核。 | 可先做小范围任务验证。 |
| 不能证明什么 | 不能证明今天能跑 Fable。 | 不能证明 GLM-5.2 更强或可替代所有默认模型。 |
这个表的作用不是颁冠军,而是让你知道每条说法应该回到哪个系统复核。Anthropic 负责 Fable 访问、模型文档和价格行;Z.AI 负责 GLM Coding Plan 路线;你自己的 repo、测试和日志负责生产可用性。
如果你的真实工作流是 Claude Code,还要额外分清配置归属。使用第三方 provider/base URL 是路由配置问题,不是模型能力问题。Claude Code 的配置边界可以参考 Claude Code API 配置,凭证和账单归属可以参考 Claude Code API Key 与订阅账单。
成本不能直接用一行价格比出来
Fable 5 和 GLM-5.2 的成本单位不一样。Fable 有官方 token 价格行;本文证据里的 GLM-5.2 主要是 Coding Plan 路线,使用配额和倍率规则。把“每百万 token 多少钱”和“一个计划里扣多少配额”直接相除,得到的往往不是可执行结论。
一个 Coding Agent 任务的真实成本还包括工具调用、长上下文、失败重试、人工 review、CI 时间和回滚。便宜的失败尝试并不便宜;昂贵但一次通过的任务也可能更划算。你需要用同一任务测这些变量,而不是拿营销表格或视频标题决定。
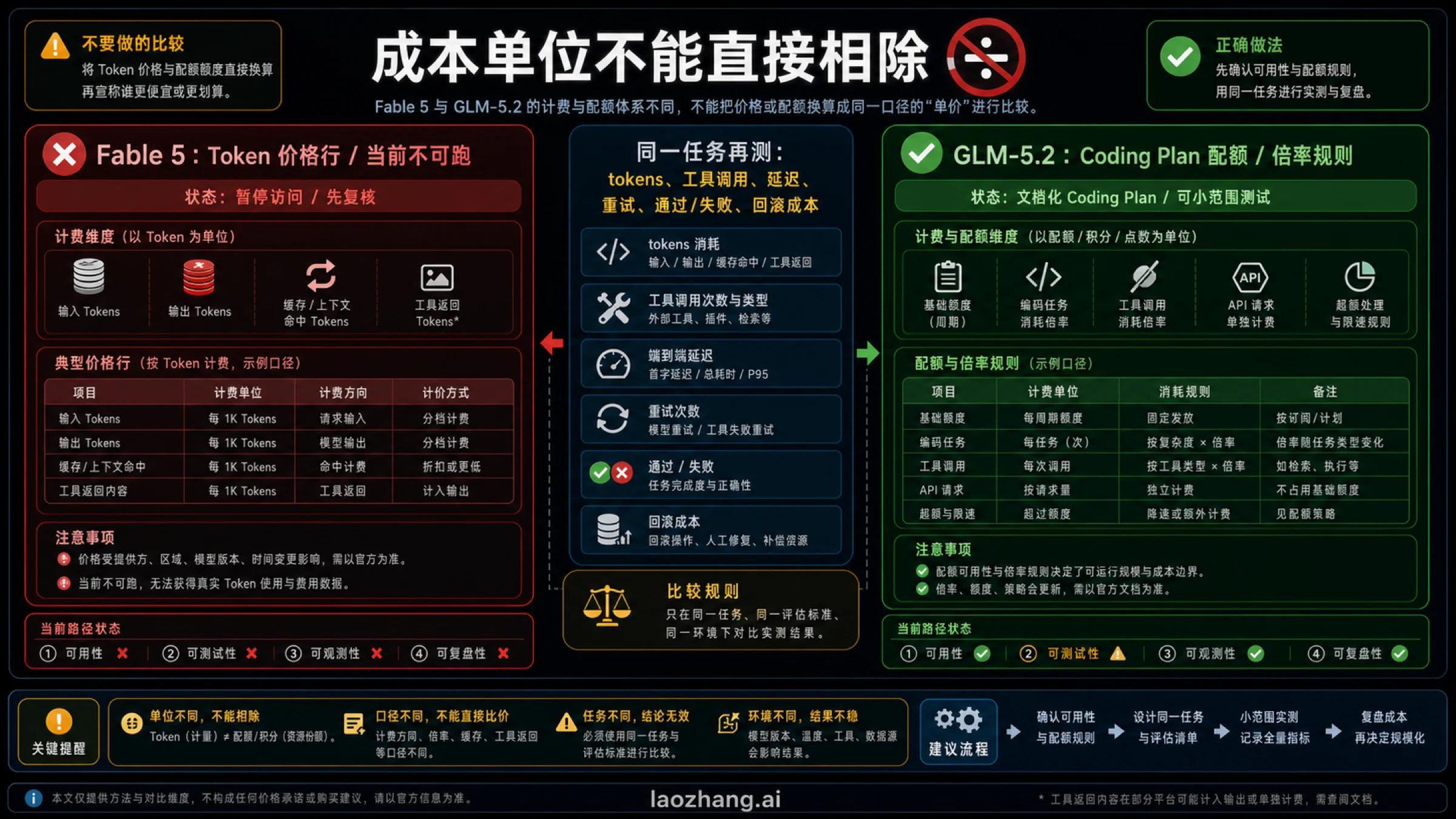
| 需要记录的单位 | 为什么必须记录 |
|---|---|
| prompt tokens | 复制整个 repo 上下文时,输入成本或配额消耗会放大。 |
| output tokens | patch 说明、日志和长回答可能让输出成为主要成本。 |
| 工具调用 | Coding Agent 路线常被工具使用模式影响。 |
| 延迟 | 便宜但卡住 review 或 CI 的路线未必便宜。 |
| 通过/失败 | 失败任务会转化成人工修复成本。 |
| 重试次数 | 重试会同时烧配额、时间和信任。 |
| 回滚成本 | 错 patch 的真实成本经常不在账单里。 |
如果这些行还没有数据,就应该说“单位暂不可比”。这句话比一个看似自信但不能复现的价格胜负更有用。
什么时候值得先测 GLM-5.2
当你的问题是“Fable 暂停期间,我本周还能把哪个 Coding Agent 路线拿来试一下”,GLM-5.2 值得优先小测。适合的任务包括边界清楚的仓库修复、可复现的测试失败、迁移清单、文档生成、低风险重构和能快速 review 的补丁。
不适合先测 GLM-5.2 的情况也要写清楚。如果你必须评估 Anthropic 特有策略、账单、fallback 语义、Claude Code 原生行为,或者你要做真正的 Fable 对照实验,那就应该等待 Fable 可运行再开始。安全敏感、合规敏感、回滚困难或需要深入业务上下文的任务,也不应该把一次 smoke test 结果当默认模型依据。
测试 GLM-5.2 时,先把范围缩小。不要让模型同时改架构、改测试、改 lint、改部署脚本。一个任务只验证一个能力:能不能理解 issue、给出可 review 的 diff、通过指定测试、保持日志可追踪、失败时容易回滚。
不要现在就更换默认模型
默认模型是生产决策,不是新闻判断。Fable 暂停访问可以决定测试顺序,但不能替你决定生产信任。GLM-5.2 即使在一个小任务上表现不错,也只说明它通过了这一类任务的初步验证。
更换默认前,至少要满足这些条件:任务包完全相同,验收条款完全相同,日志和 diff 能保存,延迟和配额可接受,失败原因可解释,回滚路径清楚,团队知道何时退回原路线。
| 更换前要求 | 通过条件 |
|---|---|
| 同一任务包 | repo、issue、prompt、文件范围、工具权限和时间预算一致。 |
| 同一验收条款 | 测试、review 清单和失败预算一致。 |
| 同一证据包 | 保存命令日志、diff、测试输出、延迟、配额和失败原因。 |
| 同一回滚计划 | 知道如何 revert、隔离或重跑。 |
| 同一决策阈值 | 事先定义“足够好”和“必须回退”。 |
如果 Fable 恢复访问,应该用保存的同一任务包重跑。不要拿 GLM-5.2 的新任务去对比 Fable 的旧印象,也不要拿 Fable 的发布规格去对比 GLM-5.2 的真实执行日志。
同一任务评估清单
最干净的测试应该刻意变小。选一个 repo、一个 issue、一条验收测试。任务要足够真实,能暴露模型行为;也要足够小,让 review 不靠猜。

- 锁定输入:prompt、branch、文件范围、issue 描述、工具权限、时间预算。
- 通过 Z.AI 文档化 coding route 运行 GLM-5.2。
- 保存模型标签、provider route、命令日志、diff、测试输出、延迟、配额备注和失败原因。
- 只看可观察结果:patch 质量、测试是否通过、重试次数、review 负担、回滚成本。
- Fable 恢复后,使用同一任务包重跑,不改 prompt 和验收标准。
- 两边都可运行后,再比较被验收任务的成本和失败模式,而不是比较名称热度。
这样得到的结论才可防守。可以说“GLM-5.2 在我们的迁移任务里一次重试后通过,配额消耗可接受”。不能说“GLM-5.2 赢了,因为 Fable 现在跑不了”。
常见问题
Claude Fable 5 现在能用吗?
按 2026 年 6 月 14 日复核到的 Anthropic access statement,Fable 5 和 Mythos 5 访问已对所有客户停用。计划任何 Fable 测试前,都要重新检查 Anthropic 当前访问状态、模型文档和价格页。
GLM-5.2 比 Claude Fable 5 更好吗?
现在不能给公平的 live 结论,因为 Fable 5 当前不可运行。GLM-5.2 是可以先测试的路线,但“更好”需要两边都用同一任务、同一输入和同一验收标准跑出可观察结果。
应该看哪个模型字符串?
Fable 侧看 Anthropic 文档中的 claude-fable-5 和当前访问状态。GLM 侧看 Z.AI 文档中的 glm-5.2 与 glm-5.2[1m],特别是 Coding Plan 和 1M context 路线是否在你的工具里可选。
GLM-5.2 一定更便宜吗?
不能简单说一定更便宜。Fable 是 token 价格行,GLM-5.2 在本文证据里是 Coding Plan 配额和倍率规则。只有同一任务的 tokens、工具调用、重试、延迟和通过率被记录后,才能讨论真实成本。
可以把 GLM-5.2 当 Fable 替代吗?
可以把 GLM-5.2 当作当前可测试路线,不要直接当作 Fable 替代。等 Fable 恢复后再用同一任务包双跑;在此之前,GLM-5.2 最多是你当前工作流里的候选分支。
结论
这篇比较真正要解决的不是“哪个名字更强”,而是“哪条路线现在能被诚实测试”。截至 2026 年 6 月 14 日,Fable 5 有官方规格但访问暂停,GLM-5.2 有 Z.AI Coding Plan 文档化路线并可先做小范围验证。
所以顺序应该是:先复核 Fable 状态;再验证 GLM-5.2 路由;用同一任务测成本、质量、延迟、重试和回滚;最后才讨论默认模型。只要少了同一任务证据,就不要把可用性差异写成模型胜负。