Claude Code 自动模式是 Anthropic 新推出的 research preview 权限模式,目标用户不是第一次接触 Claude Code 的新手,而是那些已经在用它、却被一连串低风险确认弹窗拖慢节奏的开发者。根据 2026 年 3 月 28 日我核对的官方文档,Anthropic 目前将它描述为 Team 方案上的功能:它会用一个独立的 Sonnet 4.6 安全分类器,自动放行低风险的仓库内操作,同时拦截或质疑爆炸半径更大的动作,比如下载并执行外部代码、生产部署,以及对 main 强推。你的问题如果是“长时间会话里确认太多”,那自动模式很值得理解;如果你的任务涉及生产基础设施、破坏性数据操作,或者边界本来就不清楚,那自动模式不是你该追求的捷径。
“证据说明:本文基于 Anthropic 官方 Auto mode 公告、permission modes 文档、Claude Code 产品页 和 Claude Code changelog,核对时间为 2026 年 3 月 28 日。
TL;DR
- Auto mode 于 2026 年 3 月 24 日发布,被 Anthropic 定位为比
--dangerously-skip-permissions更安全的长期任务模式。 - 当前官方文档把它写成 Team 功能,Enterprise 和 API 仍在 rollout 中。如果你只有个人 Pro 或 Max,不要默认自己已经能用。
- 自动模式最适合长时间、仓库内、边界明确的工作:多文件重构、依赖更新、测试循环、分支内清理。
- 它比很多人想象得更保守。Anthropic 明确写了会阻止
curl | bash、生产部署、共享基础设施破坏性修改、直接或强推main等操作。 - 如果你只是想少一点“确认编辑”弹窗,
acceptEdits往往就够了。如果你真正需要的是先看方案再执行,用plan。如果你想完全无人值守,那应该去做隔离环境,而不是在真实机器上直接跳到bypassPermissions。
Claude Code 自动模式到底改变了什么
Anthropic 推出自动模式,本质上是在填补两个极端之间的空白。普通 default 模式下,Claude 在编辑文件和执行命令前都会征求确认。这对陌生仓库、敏感工作、或者需要全程掌控的人来说很合理,但一旦 Claude 正在做一个一小时的例行重构,会话体验就会被大量重复确认打碎。另一端的 --dangerously-skip-permissions 又太激进了,它适合一次性容器、隔离很强的 CI 或实验环境,却不适合带着真实密钥和真实生产入口的日常工作机。
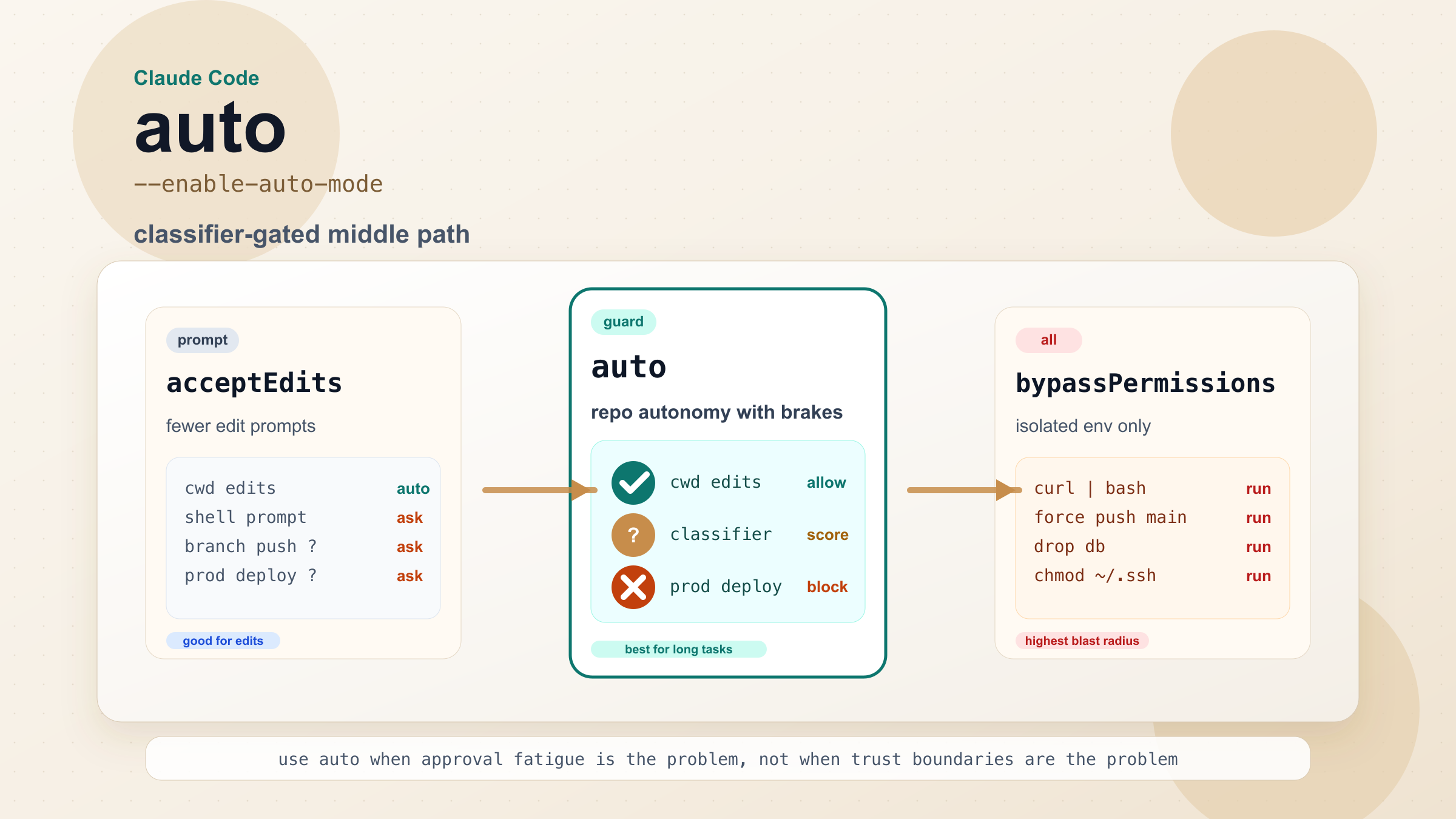
自动模式夹在中间,但它不是“现在 Claude 什么都能自动做”这么简单。更准确的理解是:只要任务还落在一个受信任的本地仓库边界里,它就会尽量让 Claude 连续工作;一旦动作看起来模糊、外扩或者高风险,就会让独立的安全层介入。这个区别非常重要,因为它既解释了为什么自动模式确实有价值,也解释了为什么它在很多人第一次尝试时会显得“比想象中更严格”。
Anthropic 想自动化的,不是所有审批,而是那些重复、低风险、可预测的审批。当前工作目录里的文件编辑,和“下载远程脚本再执行”,完全不是一个风险等级。只读 HTTP 请求,和“直接上生产环境改基础设施”,也完全不是一类动作。自动模式就是围绕这种差异建立的:让仓库内、可理解、低外扩的工作顺畅通过,对可能扩大作用范围的动作维持怀疑。
所以,这个功能最适合的不是“我想完全放手”的开发者,而是“我已经信任 Claude 做这件事,只是不想再确认三十次同类操作”的开发者。比如你已经确定要让 Claude 跨三十个文件改一个抽象名、更新测试、跑本地套件,自动模式就能把这类会话做得更顺。但如果你连任务本身都不信任 Claude,自动模式帮不了你,它只是改变了你在执行过程中被打断的频率。
官方文档里还有一个很重要、但很容易被忽略的细节:Anthropic 说明 Auto mode 的 classifier 看到的是用户消息和工具调用,而不是 Claude 自己生成的解释文本或完整工具结果。换句话说,这个安全层判断的是“请求的动作”和“动作意图”,而不是对整段推理过程做全知审查。这也意味着,你应该把自动模式当成一个边界更窄的护栏,而不是“现在这个会话已经被证明安全”的总开关。
现在到底能不能用,以及怎么开启
大多数人真正要的不是抽象解释,而是资格判断。Anthropic 当前文档对自动模式的呈现,营销层面看起来比现实覆盖面更宽,所以最简单的判断方式是:先看 plan、管理员开关、模型、以及使用界面,再决定是不是出问题了。
先看方案。 目前 permission modes 文档把 Auto mode 写成 Team 方案可用,Enterprise 和 API 还在 rollout 中。这意味着个人 Claude Pro 或 Max 订阅,不等于你已经拿到了 Auto mode 访问权。如果你在个人账号里怎么都看不到这个模式,问题很可能不是安装失败,而是计划本身还不支持。想系统看 Claude Code 各方案差异,可以读我们的 Claude Code 定价指南。
再看管理员权限。 在 Team 和 Enterprise 环境里,Anthropic 要求管理员先开启 Auto mode,用户侧才能切换。这一点说明它不是普通的个人偏好开关,而是一个组织层面的工作流决策。如果你所在团队本来就统一管理 Claude 权限,那你在本地怎么折腾 CLI,都不一定比先问管理员更有效。
模型支持也更窄。 官方当前写的是 Claude Sonnet 4.6 和 Claude Opus 4.6 可用;Haiku、Claude 3,以及 Bedrock、Vertex、Foundry 这类第三方提供商路径都不支持。这是另一类常见误区:Claude Code 本身能用,不代表 Auto mode 也一定能用。它依赖的是更具体的模型和托管条件。
界面也有差别。 自动模式优先按本地 CLI 来理解。Anthropic 文档明确写了 claude.ai/code 的云端会话没有 Auto mode;Remote Control 界面提供的是 Ask permissions、Auto accept edits 和 Plan mode,而不是完整的 Auto mode。所以如果你是在云端页面或 Remote Control 里找不到 Auto,问题可能不是你配置错了,而是你拿错了入口。
如果前面的条件都满足,CLI 里的开启路径其实不复杂:
- 先确认团队管理员已经打开 Auto mode。
- 用
--enable-auto-mode启动本地 Claude Code 会话。 - 进入会话后按
Shift+Tab,在权限模式之间切换,直到出现auto。 - 如果还是没有,再回头检查 plan、模型和使用界面,不要一开始就浪费时间排查不存在的 bug。
Anthropic 文档特别提醒:如果启动时没有带 --enable-auto-mode,那 auto 根本不会出现在模式轮换里。很多第一次尝试失败,其实就卡在这里。如果你还没把 Claude Code 本身装好或更新好,先读我们的 Claude Code 安装教程。
文档里还提到一个 VS Code 扩展层面的细节:更高权限的模式只有在设置项 “Allow dangerously skip permissions” 打开后才会显示。这不是说你必须用 bypassPermissions,而是 Anthropic 故意把更激进的权限控制藏在一个显式风险设置后面,避免用户无意中误用。
最后还有一个很实际的 changelog 细节值得提前说清。2026 年 3 月 27 日,Claude Code 2.1.86 把提示文案从 “temporarily unavailable” 改成了 “unavailable for your plan”。这个改动虽然小,但非常说明问题:真正的高频困惑,不是“功能暂时没滚到你这里”,而是“你的计划本来就没有这个功能”。如果你看到的还是旧文案,先升级。
自动模式会放行什么、拦什么,以及为什么会回退
这部分才是真正决定自动模式对你有没有用的核心。
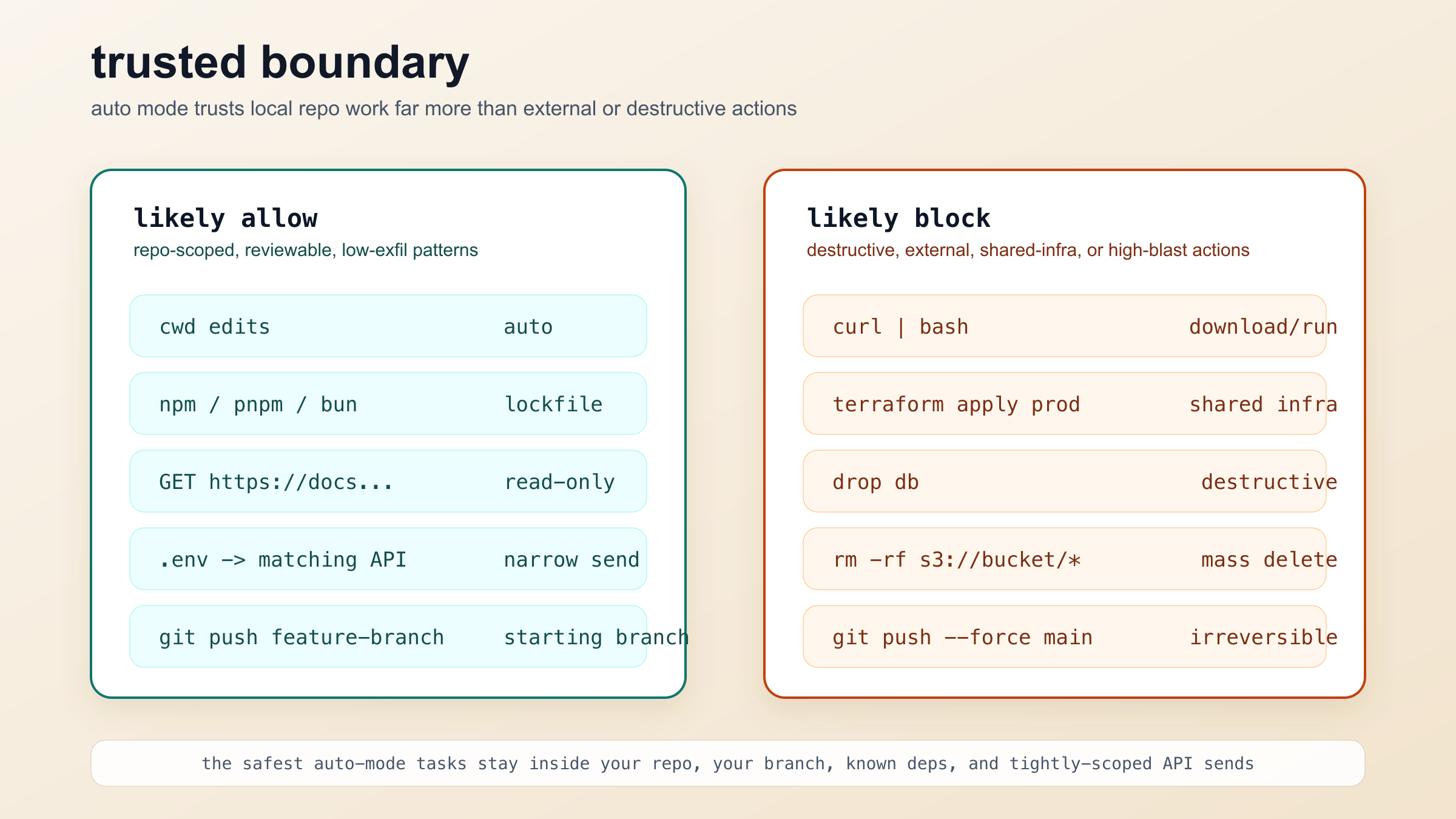
Anthropic 文档把 Auto mode 里的动作分成两条路径。第一条是明显低风险的快通道,有些动作根本不用 classifier 就能自动放行。最典型的例子就是当前工作目录内的文件编辑。这很好理解:Claude Code 的大量工作,本来就是读文件、改文件、在一个已知仓库里移动。如果连这种动作都要当成高风险,自动模式就失去意义了。除此之外,Anthropic 还明确写了:只读 HTTP 请求可以放行;和 lockfile 一致的依赖安装可以放行;读取 .env 并只把密钥发送到对应 API 的窄范围请求也可以放行。
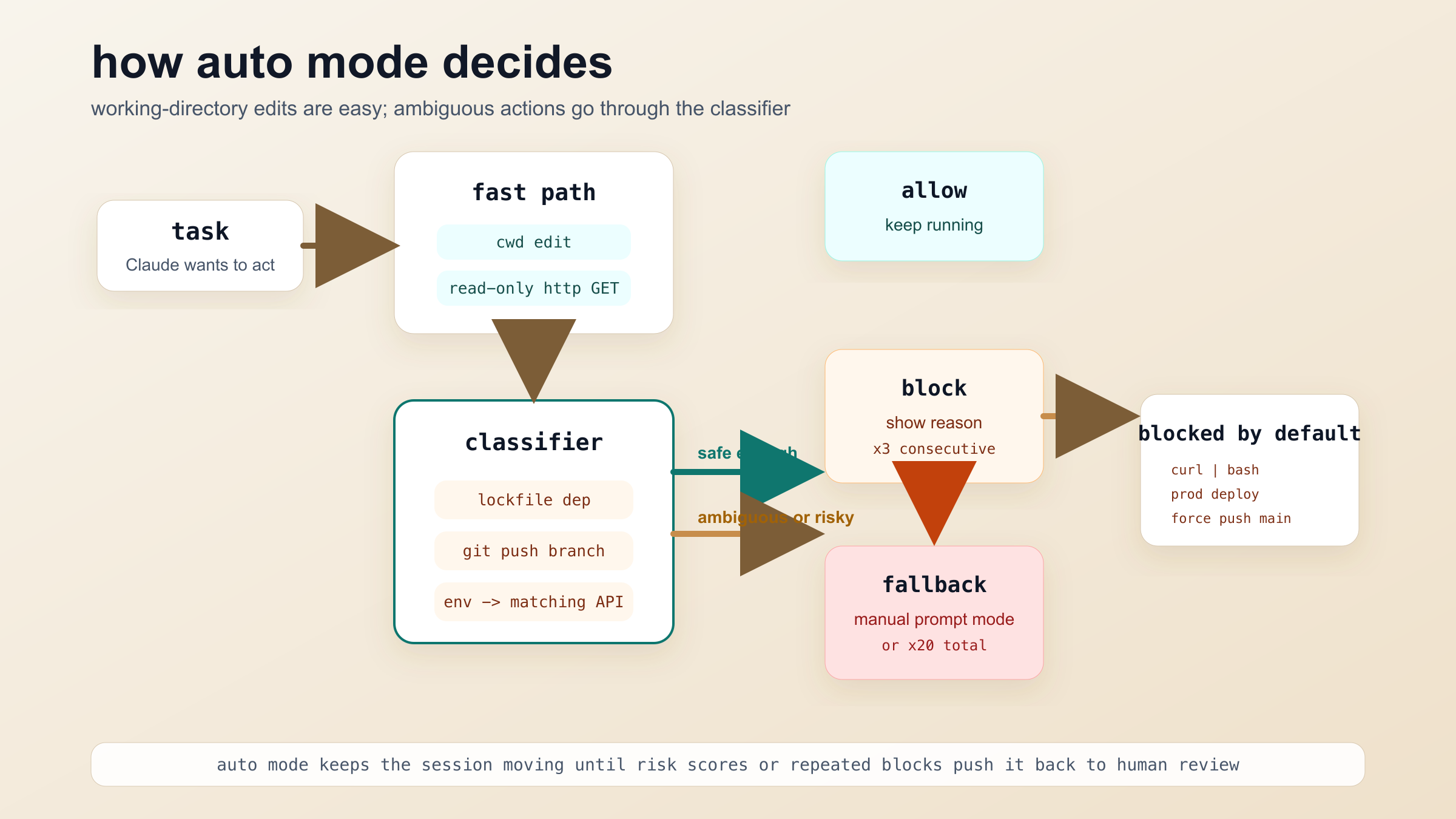
第二条路径就是 classifier 真正发挥作用的地方。Anthropic 说明 Auto mode 会调用一个运行在 Sonnet 4.6 上的分类器,对那些不是明显低风险的动作做判断。这意味着会有额外延迟,也会增加一些 token 成本,因为你实际上在主会话之外又多了一层模型调用。如果它能帮你省掉几十次重复确认,这个成本通常值得;如果你的会话本来就很短、很简单、很容易人工监督,那这个额外层未必有意义。
比“有个分类器”更关键的,是 Anthropic 明确写出来的默认拦截边界。文档里点名了几类动作:
- 从互联网下载代码并执行
- 服务部署或生产数据库迁移
- 对共享基础设施做高风险修改,比如 Terraform 或 CloudFormation
- 云存储里的批量删除
- IAM 或仓库权限变更
- 对现有文件做不可逆的破坏性操作
- 强推或直接推送到
main
这些例子很重要,因为它们直接说明了 Anthropic 的设计目标。Auto mode 对“留在仓库里做软件工作”更友好;对“扩大作用范围、增加不可逆性、碰外部系统”则更怀疑。你把它理解成“仓库内自治,基础设施怀疑”,会比把它理解成“自动批准更多操作”更准确。
这也是很多人第一次试自动模式时会失望的原因。如果你期待的是“比 --dangerously-skip-permissions 稍微保守一点的 YOLO 模式”,那它一定显得太严格。如果你期待的是“在仓库内长任务里少被烦,但遇到明显危险动作时继续踩刹车”,那它就会显得设计得很克制。这里的摩擦不是随机的,而是 Anthropic 明确选择的边界。
官方文档里另一个非常有价值的行为说明是回退逻辑:如果 classifier 连续拦了三次,或者一个会话里总共拦了二十次,Claude Code 会退回人工确认模式。这个设计很合理。因为一个不断撞护栏的会话,通常只说明两件事:要么任务本来就不适合 Auto mode,要么 Claude 正在探索一条风险明显更高的执行路径。两种情况里,正确响应都不是继续硬顶,而是换模式,或者先把任务边界缩小。
Anthropic 还写到,进入 Auto mode 后,Claude Code 会丢掉像 Bash(*) 和 Agent 这样的宽泛 allow rules。这一点尤其能说明它不是 acceptEdits 换个名字那么简单。Anthropic 明确不允许你先留下一组“几乎什么都能放行”的规则,再把自动模式当装饰层盖在上面。Auto mode 的安全层是真正参与决策的,不是摆设。
Auto、acceptEdits、plan、bypassPermissions 到底怎么选
围绕这个功能最容易犯的错,就是把它当成所有人的新默认值。实际上,对很多开发者来说,acceptEdits 依旧是最舒服的平衡点。它去掉了最频繁的文件编辑确认,但依然让 shell 命令处于更明显的人类审查之下。如果你的大部分会话都是“改代码 + 偶尔跑几个你还想亲眼过一遍的命令”,acceptEdits 已经能解决大半体验问题,而且不会改变太多信任模型。

plan 又是另一回事。它不是 Auto mode 的轻量版,也不是重度版,而是解决另一类需求:你真正需要的不是“让 Claude 连续执行”,而是“先把方案、顺序、风险和取舍讲清楚”。陌生仓库、复杂迁移、边界模糊的大任务,都更适合先用 plan。很多人以为自己要的是自动模式,其实他们要的是先降不确定性。
default 仍然是很多场景下的正确答案。新仓库、线上事故、敏感清理、权限收敛,或者任何你就是想一手过每一步的场景,都应该继续留在普通确认模式里。它慢,但慢得有价值。
bypassPermissions 则不是 Auto mode 的“进阶版”。它的契约完全不同。你等于是在说:“我接受这个环境已经足够隔离、足够可丢弃、足够有边界,所以我愿意去掉提示层。”如果你的环境不满足这句话,那就不该去那里。Anthropic 自己之所以推出 Auto mode,本来就是因为很多开发者想要比默认模式更多的连续性,但又不想承担完全跳过权限的全部风险。
可以把决策压缩成下面这张表:
| 你的下一个任务是... | 最合适的模式 | 原因 |
|---|---|---|
| 新仓库、敏感修复、风险较高的清理 | default | 你要的是最高可见性,不是速度 |
| 本地实现工作,但 shell 还想单独看 | acceptEdits | 去掉编辑弹窗,不隐藏命令判断 |
| 架构梳理、迁移规划、范围确认 | plan | 真正需要的是先思考 |
| 长时间、仓库内、分支内的重构或测试循环 | auto | 这正是 Auto mode 想解决的审批疲劳问题 |
| 一次性容器或高隔离沙盒 | bypassPermissions | 只有环境能吸收错误时,完全无人值守才成立 |
我自己的建议很简单:选能解决真正瓶颈的最轻模式,不要因为“更高级”就用 Auto mode。如果你真正卡住的是反复确认,那它很有价值;如果不是,它很可能不是最优解。
什么任务最适合自动模式,什么任务最好不要碰它
Auto mode 最出彩的场景,是 Claude 在一个你已经愿意让它修改的仓库里,做大量正确但琐碎的工作。多文件重构就是典型例子。比如重命名一个核心抽象、更新导入、修测试、清理分支,这类任务里真正痛苦的往往不是“Claude 会不会改”,而是“为什么我要确认这么多次”。依赖维护也是好例子,尤其是修改和 lockfile 结构一致的时候。测试循环同样很适合,因为它常常意味着很多小编辑和很多重复命令。
这些任务的共同点,不只是“都算写代码”。更关键的是:作用域窄、效果本地化、结果容易事后审查。工作留在分支里,改动能 review,出错后果基本也被限制在当前仓库或当前任务里。这才是 classifier-gated 模式真正能成立的前提。
一旦“写代码”开始混进“操作权力”,自动模式就会迅速变弱。生产部署、基础设施修改、破坏性数据库命令、权限调整、批量删数据,不应该出现在“我只是想少点确认”的优化目标里。Anthropic 确实把很多这类动作默认拦住了,这很好,但更重要的是,你自己也不该把这种工作交给“低打断工作流”来定义。
还有一类中间地带,也需要你对环境保持诚实。假设 Claude 正在一个仓库里改代码,但这个仓库同时连着真实密钥、部署脚本和跨服务管理工具。即使你下的自然语言任务只是“重构这个模块”,整个环境的作用范围也可能已经大到让 acceptEdits 或 plan 更合适。自动模式最安全的时候,是环境本身就窄,而不只是任务描述听起来无害。
这里也顺便把 Claude Code 速率限制指南 放进上下文里。Auto mode 能让长会话更顺,但它并不会让会话变免费。Anthropic 明确写了 classifier 会引入额外成本和延迟。如果你本来就容易撞上 Claude Code 的长期使用上限,那自动模式更像是体验优化,而不是绕过限制的捷径。
一个很实用的经验法则是:把 Auto mode 用在“你愿意交给一个足够细心的初级工程师在仓库内处理”的工作上,而不是“只有拿着生产权限的资深值班工程师才应该碰”的工作上。这个标准不完美,但足够实用。
为什么它会显示 unavailable,或者为什么它比你想象中更严格
最常见的问题其实就是不可用。如果 auto 根本不出现,先做最无聊但最有效的检查:你的 plan 对吗?管理员开了吗?模型是不是 Sonnet 4.6 或 Opus 4.6?你是在本地 CLI,而不是 claude.ai/code 的云端会话里吗?启动时真的带了 --enable-auto-mode 吗?大部分“功能坏了”的报告,最后都落在这几件事上。
第二类高频挫败是:会话不断撞 block,最后退回人工确认。遇到这种情况,最合理的解释通常不是“classifier 太蠢”,而是“这个任务已经超出 Auto mode 的信任边界”。可能 Claude 正在尝试下载并执行什么东西;可能任务已经漂移到了基础设施修改;也可能你原来依赖的宽泛 allow rules 在进入 Auto mode 后已经被丢弃。无论是哪种,回退本身都不是噪音,而是在提醒你:该换模式,或者先缩任务。
第三类常见感受是:明明听起来更先进,为什么 Auto mode 反而比 acceptEdits 更“有主见”?答案其实很直接。acceptEdits 的放宽范围更窄,它主要是让文件编辑少一点确认;Auto mode 想放开的,是更长、更 shell-heavy 的连续执行,所以 Anthropic 必须给它配一个更明确的安全层和默认 block list。结果就是,它在更大范围上更自动,但也在更关键的边界上更严格。这不是矛盾,而是设计代价。
还要记住,Anthropic 当前文档已经明确说明:不同 Claude Code 界面的权限模式并不完全一致。如果你在本地 CLI、VS Code 扩展、Remote Control、云端会话之间切换,不要默认自己看到的模式列表、开关入口和限制条件完全相同。
最后,别忘了它现在仍然是 research preview。这个标签不是让你害怕,而是提醒你别把它当成已经完全稳定下来的长期契约。Anthropic 之后可能会放宽支持范围,也可能会微调 classifier 和 UI 呈现方式。所以每次你发现“这跟我上次记得的不一样”,第一步都应该是回看最新官方文档,而不是假设行为永远不变。
那你到底该不该开
如果下面四句话都成立,答案通常是“可以”:
- 你今天就有这个功能的访问权
- 任务足够长,反复确认本身已经成了主要摩擦
- 工作留在一个受信任的仓库、分支和工具边界里
- 你仍然会像工程师一样审查结果,而不是把功能当成保证
如果下面任意一句成立,答案通常是“不,至少现在不该”:
- 你用的是当前还不支持 Auto mode 的个人方案
- 任务会碰到生产、共享基础设施或破坏性操作
- 环境本身太宽,仓库边界根本不足以代表真实风险
- 你真正需要的只是少一点编辑确认,那
acceptEdits往往已经够了
理解 Claude Code 自动模式,最有用的方式不是“Anthropic 终于让代理完全自治了”,而是更窄、更实战的版本:Anthropic 为那个尴尬但高频的中间地带做了一个权限模式。你已经信任 Claude 做这件事,但不想付出手动确认的全部成本,也不想承担完全跳过权限的全部风险。如果你正处在这个中间地带,Auto mode 很聪明;如果你不在,它要么显得 unavailable,要么显得太严,要么显得太冒险。这三种反应都不是坏事,它们恰恰说明了这个功能的真实适用边界。