
Claude Code 确实会在会话之间记住项目信息,但它不是靠一个无限扩张的永久记忆库来工作。Anthropic 在 2026 年 4 月 8 日仍公开的文档把这件事讲得很清楚:内置记忆主要分成两层,一层是你主动写进去的 CLAUDE.md,另一层是 Claude 通过重复纠正慢慢学到的 auto memory。
真正容易把人带偏的地方,不是“Claude Code 有没有记忆”,而是把三种不同的事情混成了一个词。有些内容应该写成明确规则,有些内容适合让 Claude 从反复反馈里学会,还有一些需求根本就不属于 Claude Code 内置记忆,而是跨工具、跨机器的外部连续性问题。把这三层分开之后,Claude Code memory 这件事就不再神秘了。
最实用的判断很简单:如果这条规则丢了你会很难受,就把它写进 CLAUDE.md;如果它更像一种会被反复纠正出来的工作习惯,就让 auto memory 去承载;如果你真正需要的是跨工具或跨机器的长期检索,那才是插件层该介入的时候。在怀疑 memory 坏掉之前,先跑 /memory 看看到底加载了什么,再用 /context 看当前上下文预算是怎么分配的。
Claude Code 应该记住什么,又不该记住什么
最有用的问题不是“Claude Code 有没有 memory”,而是“什么该由哪一层来记”。
CLAUDE.md 是显式规则层。仓库结构、测试命令、危险操作边界、代码风格偏好、哪些目录不能乱改,这些都适合写在这里。如果一条规则值得在每次会话开始前就放进上下文,它就应该进 CLAUDE.md。不过这里有一个必须说清的边界:Anthropic 当前文档明确说明,CLAUDE.md 是上下文,不是硬性 enforcement。写得太虚、互相冲突、或者塞得太满,Claude 仍然可能跑偏。
auto memory 是学习层。它更适合承载那种可以通过重复纠正学会的模式,比如“这个项目通常先跑哪条测试命令”“这里的内部缩写是什么意思”“这类 review comment 通常怎么写”。Anthropic 当前文档把它描述成机器本地的记忆目录,这既是优点,也是边界。优点是可检查、可整理、可理解;边界是它不是一个自动跨设备同步的万能记忆库。
插件层是第三类东西。Anthropic 的插件市场已经出现 memory extension 产品,这也是为什么搜索结果里经常把内置 memory 和外部 second-brain 工具混在一起讲。但这不等于插件就是 Claude Code memory 的默认答案。如果你的真实问题只是“让 Claude 在这个项目里稳定记住规则和习惯”,先把内置层用对,比一开始就上插件更重要。
如果你只记一条判断规则,那就是这句:必须显式保留的内容写进去,能从纠正中学会的内容让它学,真正超出本地边界的需求再升级。
启动时到底会加载什么
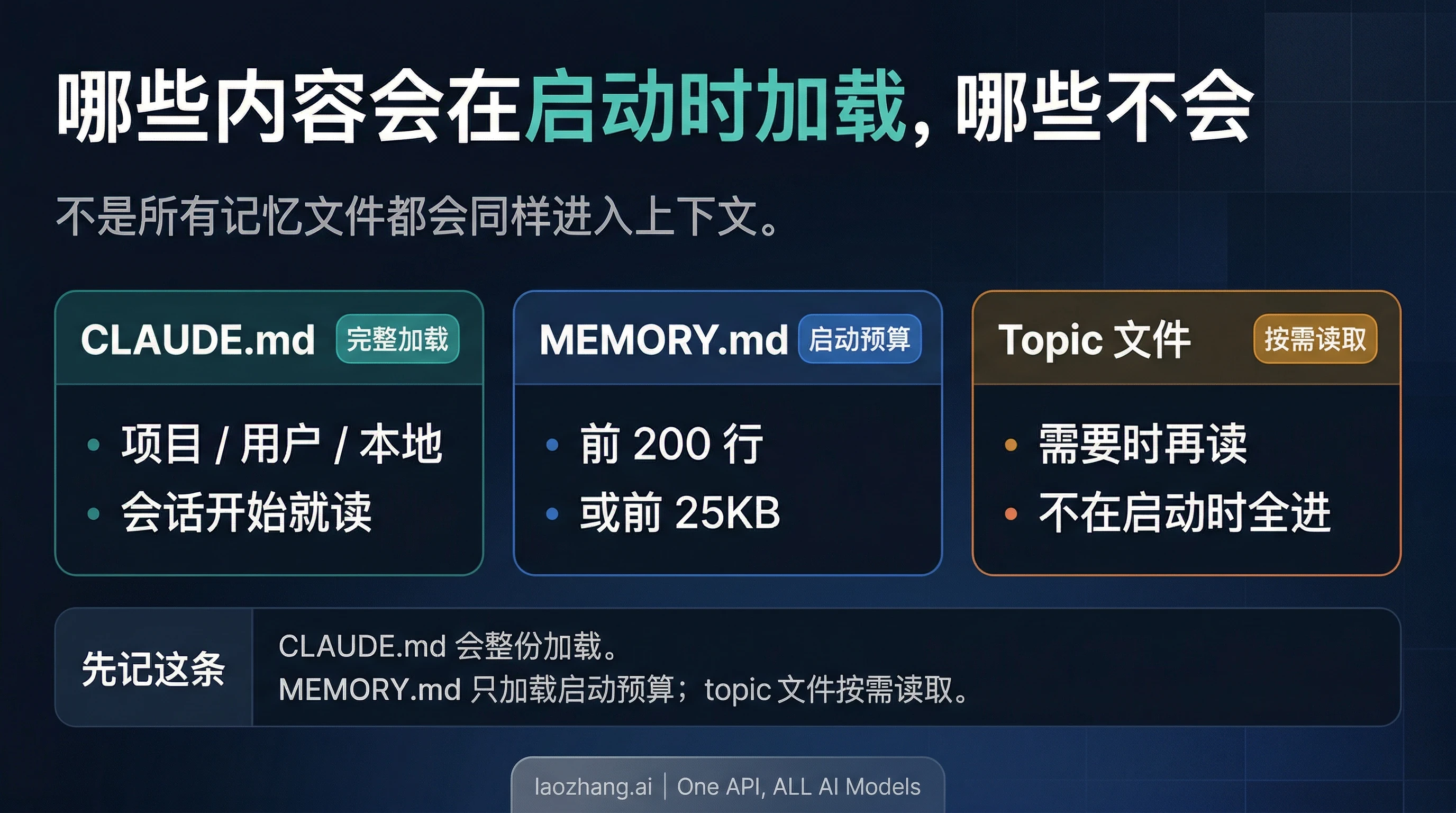
很多“Claude 忘了”的问题,本质上并不是记忆不存在,而是你以为所有 memory 文件都会在启动时同样进入上下文。
Anthropic 当前文档说明,CLAUDE.md 会在每次会话开始时加载。这就是为什么真正重要的规则应该写在 CLAUDE.md,而不是埋在一个你希望 Claude 之后能自己读到的 topic 文件里。
auto memory 的加载方式更克制。默认 memory 目录里会有一个 MEMORY.md 索引文件,以及若干按主题拆开的 topic 文件。官方文档给出的当前规则是:启动时只会加载 MEMORY.md 的前 200 行或前 25KB;topic 文件按需读取,不会在启动时整包塞进来。这个区别非常关键,因为“文件存在”不等于“当前会话已经加载了它”。
这也是为什么 /memory 和 /context 不是可有可无的命令。/memory 能让你直接看到当前会话加载了哪些 CLAUDE.md、CLAUDE.local.md 和 rules 文件,也能把你带到 memory 文件夹本身。/context 则用来检查当前上下文到底被什么占满了。如果你觉得 Claude 忘了,先别急着怪模型,先确认是不是根本没加载。
机器本地边界同样要放到第一屏就讲明白。Anthropic 公开的路径说明把 auto memory 放在主目录下的本地路径里,这意味着它很适合本机上的项目连续性,但不应该被误解成自动跨机器共享的长期记忆。
怎么把 CLAUDE.md 写对,而不是写成一个杂物箱

好的 CLAUDE.md 不是最大的那一个,而是最干净、最有分工的那一个。
项目级 CLAUDE.md 应该承担团队共享的规则:仓库工作流、测试方式、代码组织、哪些目录是生成产物、什么情况下必须先停下来确认。它不该变成一个无限加长的百科全书。Anthropic 当前建议也强调,CLAUDE.md 最好保持相对短小,接近 200 行以内会更利于遵循和上下文效率。
用户级 ~/.claude/CLAUDE.md 更适合放你的跨项目偏好:你喜欢怎样的解释风格、你希望 Claude 在什么情况下先询问、你习惯怎样组织提交说明。这些不是仓库规则,而是你的默认工作方式。
CLAUDE.local.md 则适合本地私有说明,比如只对当前机器有意义的临时约束,或者不适合提交进仓库但又值得保留的项目笔记。它的价值在于精确,而不是成为第二份巨大的 CLAUDE.md。
如果某条规则只对某个路径、目录或局部工作流有效,放进 .claude/rules/ 往往比继续往主文件里堆更好。这样做不是为了好看,而是为了让 Claude 在真正相关的时候读到真正相关的规则。
还有一个经常被忽略的点:如果仓库已经由另一个 agent 系统通过 AGENTS.md 管理规则,Claude Code 不会直接读取 AGENTS.md。Anthropic 当前的推荐做法是从 CLAUDE.md 里 import AGENTS.md。这一步不做,很多人就会误以为“明明仓库里有规则,Claude 为什么没遵守”。
如果你还在处理 Claude Code 本身的安装或认证问题,先看我们的 Claude Code 安装教程。memory 的结构化配置,建立在 CLI 基础已经正常工作的前提上。
auto memory 的实际边界是什么
auto memory 容易被想象成一个“自己会长大的长期记忆层”,但更准确的说法是:它是一个可检查、可整理、可关闭的学习层。
第一,它不是黑箱。Anthropic 当前文档直接给出了默认存储路径、MEMORY.md 索引和 topic 文件结构,这意味着你可以检查它到底学了什么,而不是只能猜。
第二,它不是无限制加载。只有 MEMORY.md 的前一部分会在启动时带进上下文,topic 文件是按需读取的。所以真正必须永远在场的规则,不应该藏在 topic 文件深处,而应该放回正确的 CLAUDE.md。
第三,它不是不可控制。官方文档说明,你可以通过 /memory 检查当前加载情况,也可以在设置里通过 autoMemoryEnabled: false 关闭它,或者使用 CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 禁用它。这个控制面很重要,因为它让你能把“memory 真的不够”与“当前设置本来就不干净”分开看。
真正值得问的问题,不是 auto memory “够不够聪明”,而是你让它承担的任务是不是它该承担的任务。它擅长承载重复纠正出来的习惯,不擅长替代显式规则层,更不应该被误认为跨机器共享知识库。
为什么 Claude 会在 /compact 之后,或下一次会话里把东西忘掉
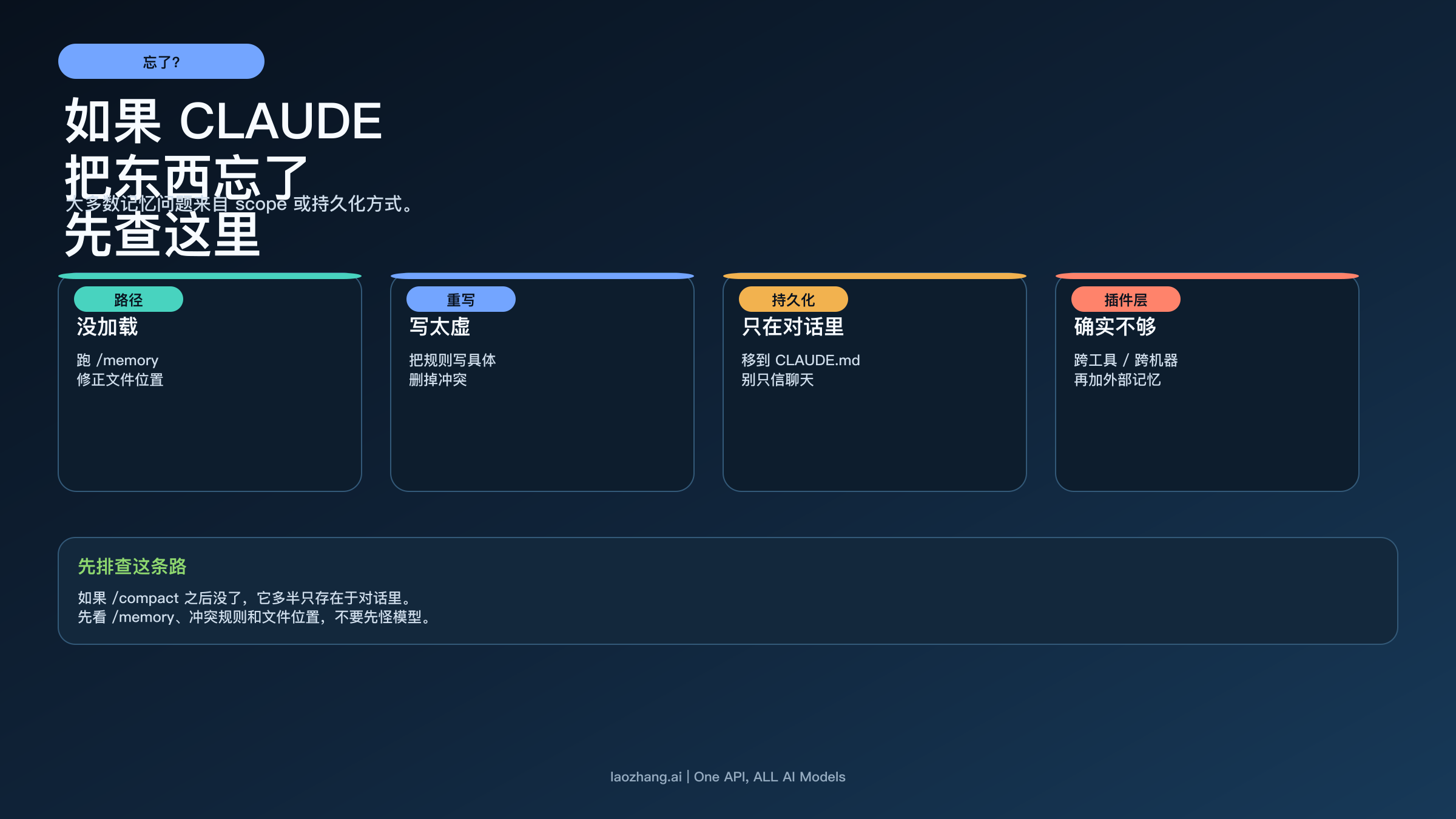
大多数“Claude 忘了”的情况,最后都不是因为 memory 根本不存在,而是因为顺序错了、作用域错了,或者你把只出现在对话里的内容当成了持久记忆。
第一条分支是根本没加载。先跑 /memory。你以为应该生效的 CLAUDE.md,真的进了当前会话吗?你以为某个 topic 文件在启动时就会读进来,但官方规则明明说它是按需读取,这种错觉非常常见。
第二条分支是规则写得太虚或互相打架。Anthropic 当前文档已经把边界说得很清楚:CLAUDE.md 是上下文,不是强制政策。模糊的句子、重复的要求、互相矛盾的规则,会让 Claude 表现得像“忽然失忆”,其实更像“你没有给它一个清楚的优先级”。
第三条分支是东西只活在对话里。官方 troubleshooting 里最重要的一条就是:如果某条信息在 /compact 之后消失了,它很可能从来没有写进 CLAUDE.md。这不是小细节,而是整个 memory 体系里最实用的一条诊断规则。会影响后续会话的内容,尽量不要只停留在聊天里。
第四条分支才是真的碰到了边界。如果你需要跨工具、跨机器、或者比当前内置 memory 更强的检索和长期连续性,那么外部插件层就是合理升级,而不是多余复杂度。但只有在你先排除了加载、写法和持久化错误之后,这个结论才成立。
最稳妥的排查顺序可以固定下来:
- 先用
/memory看实际加载了什么。 - 再判断这条信息本来就该写进
CLAUDE.md,还是应该交给 auto memory。 - 清理模糊、冲突、过长的规则。
- 用
/context看会不会是上下文过载导致表现异常。 - 最后才问自己:这是不是已经超出了内置 memory 的边界。
如果你真正卡住的是长会话带来的上下文和成本压力,而不是 memory 分工本身,可以继续看我们的 Claude Code token usage 指南。很多人主观上觉得是“记忆混乱”,实际却是上下文膨胀和使用量问题。
什么时候插件真的有用,什么时候只是把问题复杂化
Anthropic 的插件生态已经证明了一件事:memory 的确是可以扩展的 surface。但这不等于你每次遇到记忆问题都应该先上插件。
插件真正有用的场景,是你明确知道自己需要超出本地内置模型的连续性:跨工具检索、跨机器共享、团队级长期知识层、或者更复杂的 memory orchestration。到了这个阶段,你设计的已经不是“Claude Code 怎么记住这个项目”,而是“整个工作流怎么管理长期知识”。
插件最容易被滥用的场景,则是你其实还没有把内置层用对。还没分清楚 CLAUDE.md 和 auto memory 的分工、还没看过 /memory、还在把对话内容误当成持久规则,这时引入插件通常只会把原本清晰的问题盖住。
保守一点反而更有效:先把内置系统用到位,再在你能明确说出“卡住我的到底是哪条边界”时,决定是否升级到插件层。
常见问题
Claude Code 会跨会话记住项目吗?
会,但依赖的是分层记忆,而不是一个统一的永久记忆库。CLAUDE.md 承载你写进去的规则,auto memory 承载学习到的模式。
什么内容应该写进 CLAUDE.md?
所有你不希望下次还靠聊天重新解释的规则:测试命令、代码规范、目录边界、危险操作约束,都适合写进去。
MEMORY.md 在哪里?
Anthropic 当前文档给出的默认路径是 ~/.claude/projects/<project>/memory/。它是机器本地目录,不是自动云同步。
为什么 /compact 之后它就忘了?
官方说明很直接:/compact 之后 Claude 会重新读取磁盘上的规则。如果内容没被持久化到 CLAUDE.md,就可能随着会话压缩一起消失。
我需要 memory 插件吗?
大多数情况下不需要。先把内置的规则层、学习层和检查命令用对,再判断你的需求是不是已经超出了机器本地边界。
Claude Code memory 真正好用的前提,不是把它想成一个万能大脑,而是把它当成一个分层系统:明确规则写进去,重复习惯让它学,真正超出边界的连续性再升级。这样比相信一个模糊的“长期记忆”概念靠谱得多。