Claude Code 让人觉得“贵”,往往不是因为你发了很多提示词,而是因为它会把上下文、文件、工具结果和模型输出一起卷进代理式循环里。你只觉得自己在终端里发了一条请求,但 Claude Code 可能已经读了代码、跑了命令、检查了结果,再把这些内容重新带进下一轮。更容易让人混淆的是,“用量”现在并不是一个简单数字。如果你登录的是 Pro 或 Max,Claude Code 用的是和 Claude 网页端、桌面端、移动端共享的套餐额度,主要看 5 小时会话与每周限制;如果环境里存在 ANTHROPIC_API_KEY,或者你主动切到按量计费,它就不再像订阅功能,而是变成 API 流量,受 RPM、输入 TPM、输出 TPM 和支出限制约束。把这两套系统分开之后,大多数“Claude Code 为什么这么烧 Token”的问题都会清楚很多。
这篇文章基于 2026 年 4 月 2 日前公开可验证的信息,解释 Claude Code 当前到底怎样计算用量、为什么它会比普通聊天更快吃掉额度、怎样用 Settings > Usage、/status 和 /cost 看懂当前状态,以及在 Anthropic 最近更新帮助中心和文档之后,哪些优化依然真正有效。目标不是再给你一张很快过时的“每周大概能用多少小时”表,而是帮你建立一个可持续的判断框架:你现在到底应该缩小上下文、换模型、开启 extra usage,还是干脆把这次重负载冲刺切到 API 计费上。
快速结论
- Claude Code 没有一条统一的“Token 进度条”。在 Pro 和 Max 上,它主要看与 Claude 共享的 5 小时会话和每周限制;在 API 模式下,它主要看 RPM、输入 TPM、输出 TPM 和支出上限。
- 真正决定用量的往往不是提示词条数,而是上下文大小。代码库范围、长会话、频繁工具调用、MCP 开销和更贵的模型都会叠加。
- 最值得养成的监控习惯是:在套餐路径下看
Settings > Usage与/status,在会话级成本判断时看/cost。个人 Pro 或 Max 用户目前没有完整的 Claude Code analytics 仪表盘。 - Sonnet 4.6 和 Opus 4.6 在 Claude Code 中可以走到 1M 上下文,但在付费 Claude 套餐里,这和 extra usage 的访问条件相关。更大的上下文窗口确实有用,但上下文卫生差的时候,它同样会让成本更快放大。
- 最有效的节省方法通常不是“少发几句”,而是清掉陈旧会话、及时 compact、默认使用 Sonnet 或 Haiku,并减少 Claude 在动手前必须重新读取的内容。
- 如果你明明感觉自己没做什么却很快见底,先确认你到底走的是套餐路径还是 API 路径,再检查当前模型、上下文大小,以及是否处在更容易被收紧的高峰时段。
Claude Code 的“用量”现在到底指什么

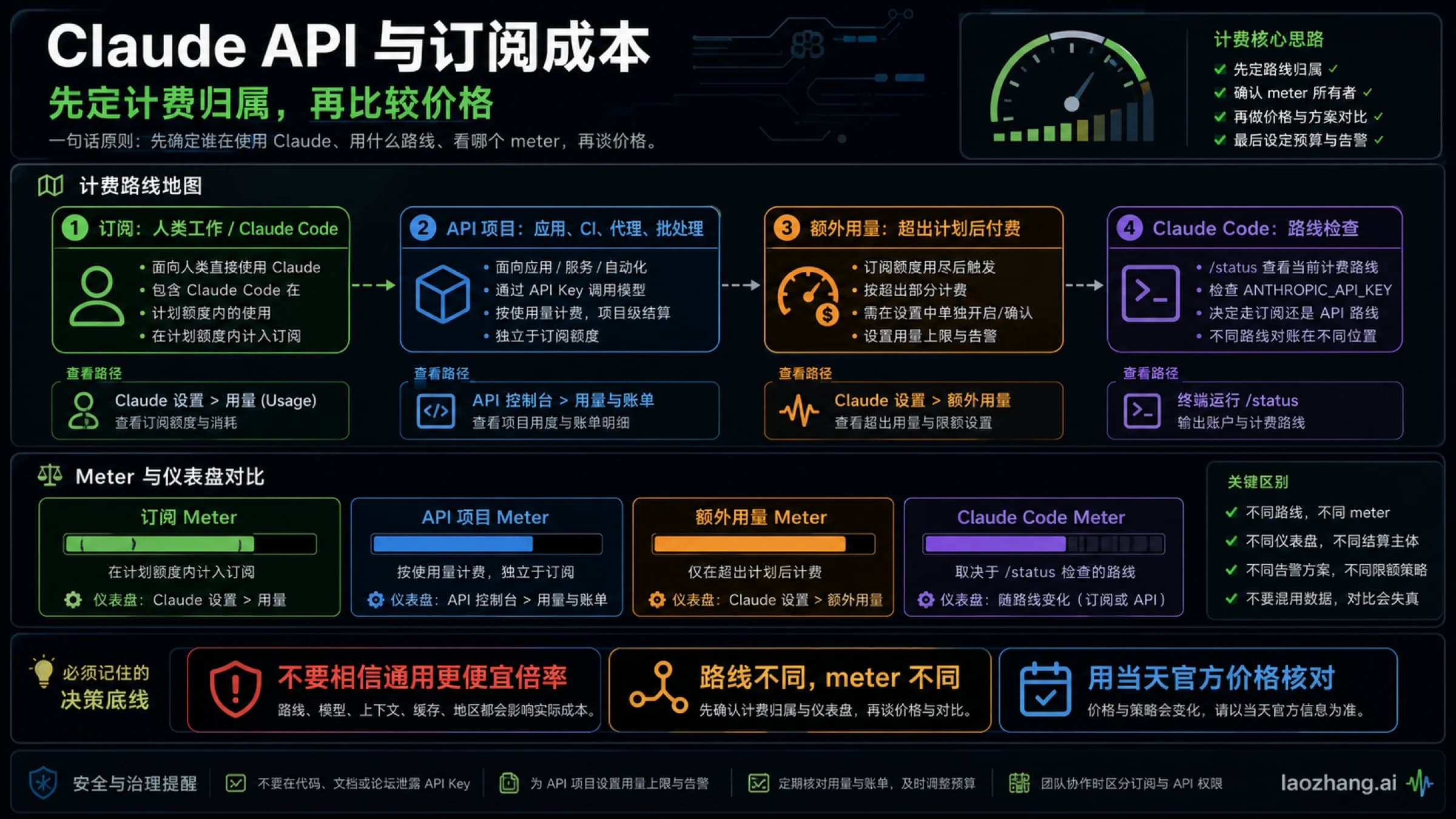
很多人一上来就把 Claude Code 的用量理解成同一套额度,这是最容易出错的地方。Anthropic 现在实际上给了两套不同的计量系统,而 Claude Code 会根据你的认证方式在这两套系统之间切换。
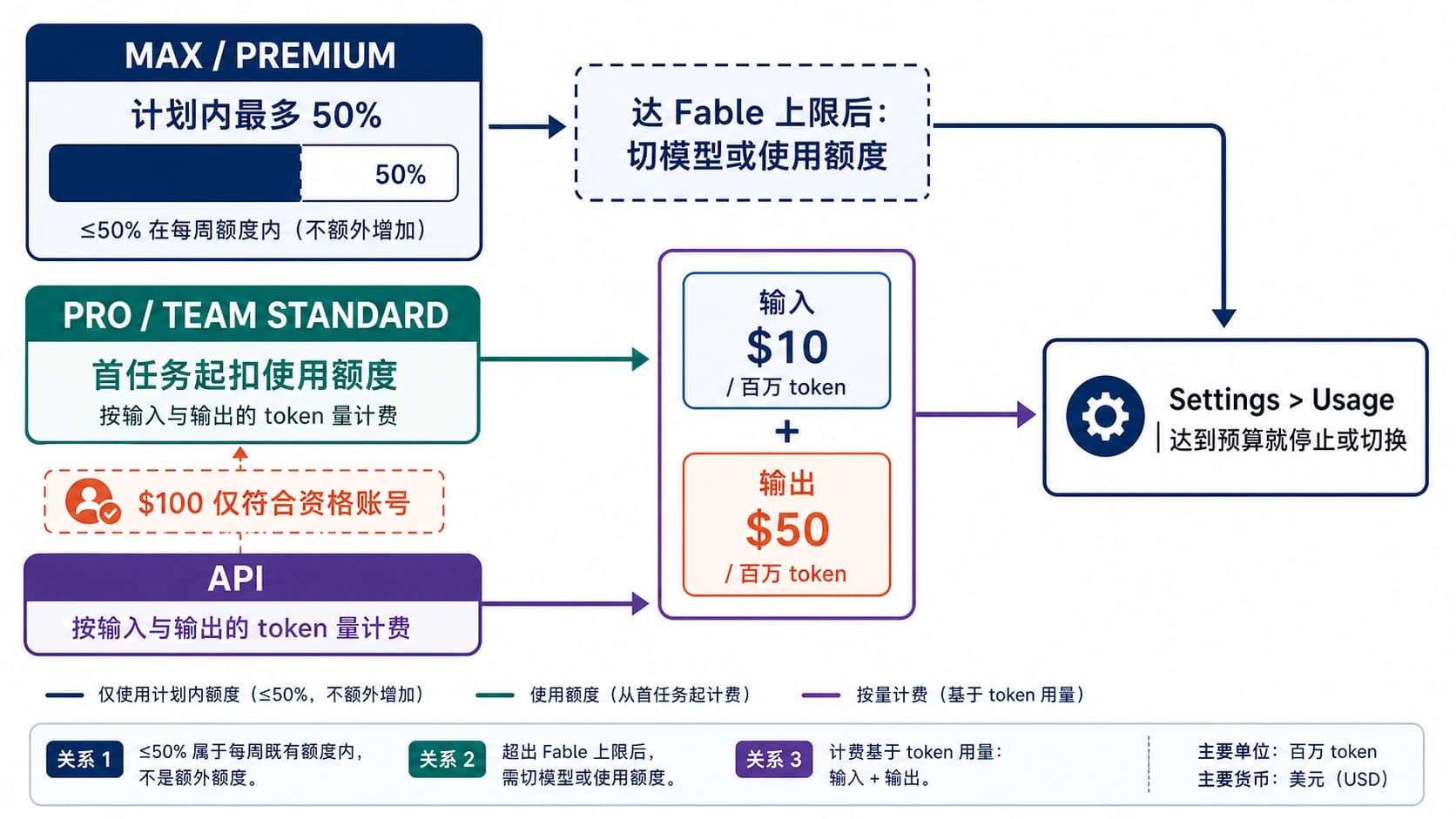
如果你使用的是 Pro 或 Max 订阅,Claude Code 会从和 Claude 网页端、桌面端、移动端共享的套餐额度里扣减。Anthropic 当前的帮助中心会明确引导你去看 Settings > Usage,那里会显示你当前的 5 小时会话限制 和 每周限制。这才是个人订阅用户当前应该采用的官方框架。旧文章里常见的“每日配额”“固定提示词次数”“每周大概多少小时”这种说法,现在都比看起来更容易过时。帮助页面还明确写了两件过去很多人靠猜的事:第一,Claude 和 Claude Code 共享用量;第二,包含额度用尽后,你可以等待重置、开启 extra usage,或者切到按量付费的 API 模式。
如果你使用的是 带 API key 的 Claude Code,计量方式就完全换了。Anthropic 的 API 文档会按 每分钟请求数、每分钟输入 Token、每分钟输出 Token 来算,再叠加不同层级的支出上限。对于 API 用户,关键问题不再是“我的套餐还剩多少”,而是“我撞到了哪一档 rate bucket”。你可能 Console 里还有余额,但已经因为 ITPM 或 RPM 被挡住了。
还有一个经常让人误判的细节:如果环境变量里设置了 ANTHROPIC_API_KEY,Anthropic 的帮助页面明确说 Claude Code 会优先使用这个 key,而不是你的 Pro 或 Max 订阅。于是你以为自己在“烧套餐额度”,实际上已经在走 API 计费。很多人说“Claude Code 一下子把 Token 用完了”,第一件要确认的事情不是具体用了多少 Token,而是当前到底走的是哪条计费路径。
更稳妥的理解方式是:Pro 和 Max 用户主要管理 5 小时和每周额度,API 用户主要管理吞吐和支出。两条路径给人的体感可能相似,因为最后都会把你拦下来,但背后的杠杆完全不同。套餐用户要考虑的是会话窗口、weekly limit、extra usage 和时段影响;API 用户要考虑的是 RPM、ITPM、OTPM、缓存命中和支出上限。把这两件事混在一起,Claude Code 才会显得像个谜。
为什么 Claude Code 比普通聊天更容易烧掉 Token

Claude Code 看起来比聊天更“费”,原因很简单:它不是一个披着终端外壳的单轮聊天工具,而是一个会不断读取上下文、调用工具、修改文件、运行命令、检查结果并继续迭代的代理式编码系统。
最主要的驱动因素是 上下文累积。Anthropic 当前的 Claude Code cost 指南把核心原则写得很直白:成本和上下文大小直接相关。这个道理放到编码工作流里会更明显,因为每多读一个文件、每多带一段对话历史、每多保留一个 MCP 工具定义,下一轮都更重。一个看似“高效”的长线程,往往会在后半段变成最贵的工作方式,因为每次后续请求都要拖着更多历史往前走。
第二个因素是 工具密集型工作。Claude Code 的价值恰恰来自它不只是“回答你”,而是会去搜索、读取、编辑、执行和验证。所以,同一句“帮我修这个 Bug”,如果只在网页聊天里讨论,和让 Claude Code 真的进仓库动手,成本会完全不是一个级别。你看到的只是一个请求,但 Claude Code 可能已经做了多次工具调用,而每次调用又会重新带上系统提示、上下文和新产出的结果。
第三个因素是 模型路线和上下文窗口本身。Anthropic 当前帮助页面说,付费 Claude 套餐一般是 200K 上下文,但 Sonnet 4.6 和 Opus 4.6 在 Claude Code 里可以走到 1M 上下文;API 文档也分别说明 Sonnet 4.6 和 Opus 4.6 支持 1M。更大的窗口确实对大型仓库、跨模块设计和长链路任务很有帮助,但它不是“免费理解力”。它只是让你能够带更多内容。带得越多,成本也会越高。
第四个因素是 你感觉不到的后台开销。Claude Code 文档现在会明确提到:prompt caching 有助于复用重复内容,auto-compaction 会在上下文增长后压缩历史,而且即使工具空闲,一些后台功能也会消耗少量 Token。官方把这部分描述为很小的成本,通常每个会话低于 $0.04,但关键不是这个绝对数字,而是它提醒你:Claude Code 的用量从来不只对应“我打了多少字”。
这也是为什么“我明明没发几条 prompt”是一个很差的成本指标。真正要看的,是这次任务把多大范围的代码带进了上下文、调用了多少工具、会话保持了多久、当前用的是哪条模型路线,以及 Claude 是否一遍又一遍重读了本可以提前缩小的内容。
不靠感觉,应该怎么查看当前用量
如果一篇“用量指南”最后还是让你靠体感去猜,那基本没什么价值。Anthropic 现在确实给了几种可用的查看方法,只是它们分散在不同表层。
对于 Pro 和 Max 订阅用户,最关键的外部入口是 Settings > Usage。当前帮助页面说明那里会显示 当前 5 小时会话的使用情况、每周限制 和重置时间。回到 Claude Code 终端里,Anthropic 也明确建议个人订阅用户用 /status 来看剩余分配。如果你的目标是尽量留在套餐内、不让工作流意外掉到 API 计费,/status 应该是每次大任务前先看的地方。
如果你想判断 这一个会话为什么突然变贵,更关键的是 /cost。Anthropic 的成本文档明确把它作为 Claude Code 内部查看 Token 用量的主要命令。你要回答的不是“我的套餐还剩多少”而是“为什么这个线程开始失控”,那就应该优先看 /cost,而不是猜。文档还提到可以把成本展示放进状态栏。如果你几乎天天用 Claude Code,这个设置很值得开。
对于 Team、Enterprise 或 Console 用户,Anthropic 现在已经提供了更完整的 Claude Code analytics,可以看活动、建议采纳率、被接受的代码行数和花费等信息。但 Anthropic 的帮助页同样写得很清楚:个人 Pro 和 Max 用户目前没有这套 Claude Code usage analytics。所以论坛里那种“去看看你没打开的隐藏 dashboard”式建议,对个人订阅用户并不成立。
可以把当前工具栈粗略理解成这样:
| 你想回答的问题 | 最合适的查看方式 |
|---|---|
| 我的 Pro / Max 套餐还剩多少? | Settings > Usage 和 /status |
| 为什么这个 Claude Code 会话突然很贵? | /cost 与状态栏成本显示 |
| 团队整体怎样使用 Claude Code? | Claude Code analytics(Team / Enterprise / Console) |
| 我到底撞到了哪一档 API 限制? | 429 响应头、retry-after 和 Console 限制页 |
如果只保留一个新习惯,我会建议你保留这个:不要再用感觉判断 Claude Code 的用量。在开始重任务前先看 /status,会话中间看 /cost。这比互联网上大多数“每周大概能用多久”的估算表都更可靠。
现在真正重要的定价与限制模型

Anthropic 在 2026 年 4 月的公开价格页面,对订阅价格说得很明确,但对“每个套餐到底等于多少精确容量”说得更保守。所以写这部分时,最好把 公开价格合同 和 未公开的有效容量 分开。
在 个人订阅套餐 这边,Anthropic 当前价格页写明 Pro 为 $20/月,年付折合 $17/月,并且明确写着包含 Claude Code 与 Claude Cowork。Max 从 $100/月起,提供相当于 Pro 的 5 倍或 20 倍使用量,同时有更高输出限制和高峰期优先权。这些是当前稳定、公开、可验证的合同信息。比起第三方文章里那些“Pro 每周大概能跑多少小时”之类的估算,直接锚定官方对价格和相对容量的表述更稳妥。如果你主要想解决“Pro 够不够、Max 到底值不值”,可以继续看我们已有的 Claude Code Pro vs Max 对比 和 Claude Code 定价指南。
在 API 计费 这边,Anthropic 则给出了明确的 Token 价格。到 2026 年 4 月 2 日为止,价格页显示 Sonnet 4.6 为每百万输入 Token $3、输出 Token $15,Opus 4.6 为 $5 / $25,Haiku 4.5 为 $1 / $5。Prompt caching 会单独计价,Batch 处理依然写着 50% 折扣。如果你的工作方式本来就是短时间、高强度、多轮自动化,那 API 路线往往比订阅营销文案更容易精确算账。
API 层级表 同样非常关键,因为它告诉你“为什么速度出问题”到底是预算问题还是桶限制问题:
| API 层级 | 充值门槛 | RPM | Sonnet 输入 TPM | Sonnet 输出 TPM |
|---|---|---|---|---|
| Tier 1 | $5 | 50 | 30,000 | 8,000 |
| Tier 2 | $40 | 1,000 | 450,000 | 90,000 |
| Tier 3 | $200 | 2,000 | 800,000 | 160,000 |
| Tier 4 | $400 | 4,000 | 2,000,000 | 400,000 |
这些数值都来自 Anthropic 当前 API rate-limit 文档。文档还特别强调了一点:对于多数 Claude 模型,缓存读取不会计入 ITPM。这就是为什么上下文复用做得好,会让 API 路径看起来像“白赚了一档层级”。
上下文窗口这件事也比旧文章里写得更复杂。Anthropic 当前帮助页说付费 Claude 套餐一般是 200K 上下文,但 Sonnet 4.6 和 Opus 4.6 在 Claude Code 中可以走 1M;API 文档则分别说明 Sonnet 4.6 和 Opus 4.6 支持 1M,其余模型通常仍在 200K+。真正有用的结论其实很简单:更大的窗口只在你确实需要时才有价值;上下文选择一旦偷懒,更大的窗口只会让浪费更贵。
所以到底该怎样看套餐选择?如果你想要一个大致可预测的月度支出,而且日常工作负载不至于全天满负荷,Pro 或 Max 加 extra usage 往往是最干净的路径。如果你经常做 burst automation、代理式批处理、团队工作流,或者你就是希望成本能按单次任务拆清楚,API 计费通常更容易管理。真正错误的习惯,是一遇到用量焦虑就默认“我该升更大的套餐”。有时候你需要的只是更干净的会话。
七个不拖慢效率的 Claude Code 降耗方法
最好的优化,不是让你少用 Claude Code,而是让 Claude 少做不必要的工作。
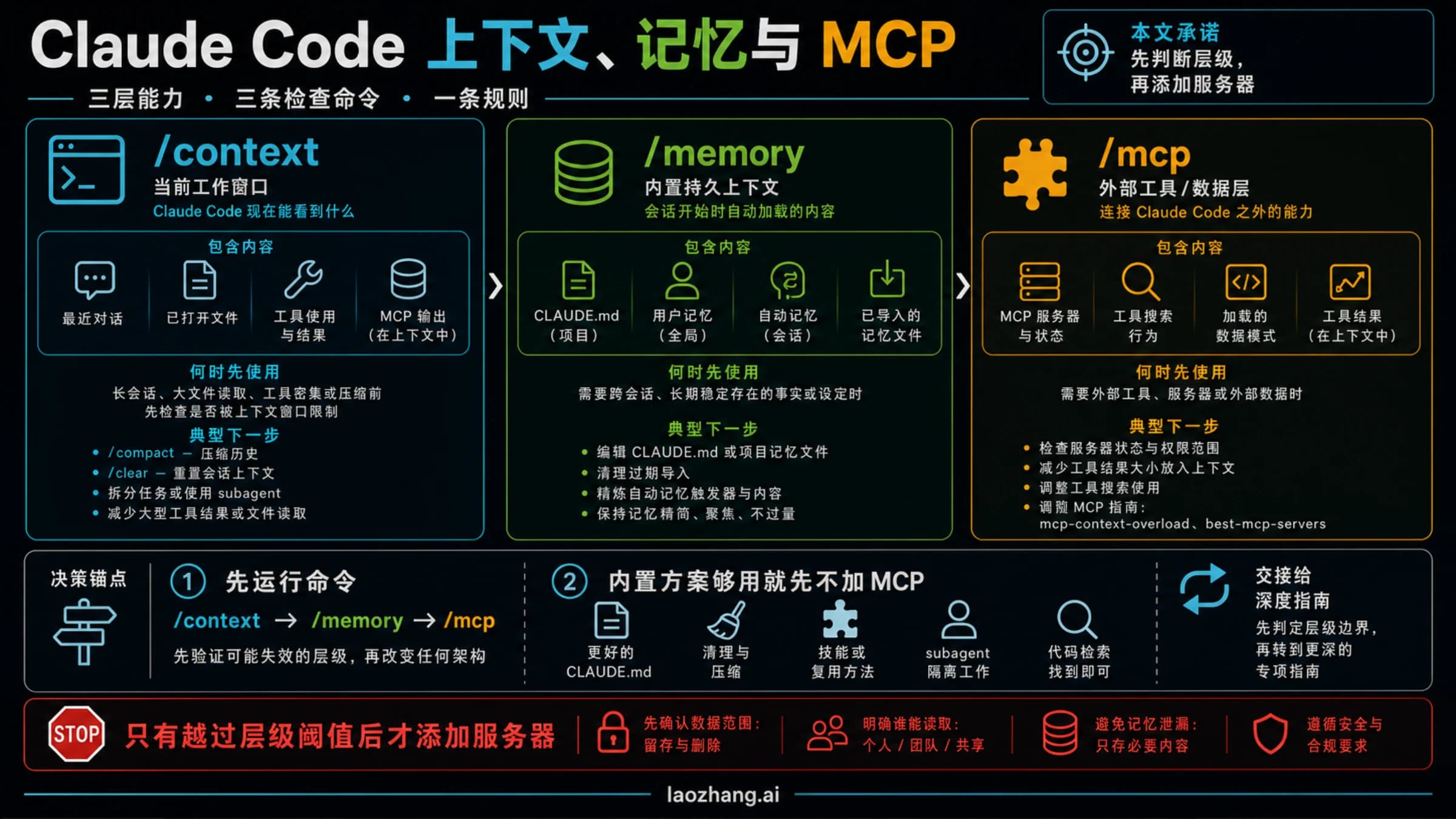
1. 不相关任务之间及时清理旧上下文。 Anthropic 的成本文档会明确建议在切到不相关任务时使用 /clear,因为陈旧上下文会浪费每一轮的 Token。这几乎是重度用户杠杆最高的习惯。如果你还想保留线程,可以先给它改名,之后再 /resume 回来。真正昂贵的不是“多开几个会话”,而是把完全不同的任务硬塞进同一条长线程里。
2. 线程变胖之前就做 compact。 Anthropic 也明确推荐 /compact,甚至允许你在 CLAUDE.md 里补充压缩指令。这适合“任务仍然相关,但对话已经变得很臃肿”的场景。好的 compact 指令应该足够具体,例如保留当前 Bug 假设、改过的文件和剩余测试失败点,不要让 Claude 自己猜该留下什么。
3. 看 /cost,不要只靠直觉。 如果你总是在“已经不爽了”之后才去看成本,那通常已经太晚。会话中间主动跑 /cost,或者把成本显示放进状态栏,问题会在变严重之前暴露出来。
4. 默认从 Sonnet 开始,简单任务更频繁地交给 Haiku。 Anthropic 的成本文档明确说 Sonnet 足够覆盖大多数编码任务,价格又明显低于 Opus;同时也提到 Haiku 适合更简单的子任务。现实里,这意味着格式整理、说明文案、小改动、简单重构不应一律走最贵路线。把 Opus 留给真正复杂的架构判断、难调试、多步推理。
5. 降低 MCP 和探索性开销。 Anthropic 现在会说明 MCP 工具定义默认延迟加载,而 /context 可以帮助你看清哪些内容在吃上下文。文档还建议,只要有成熟 CLI,就优先走 CLI,因为很多场景下它比把一整个 MCP 服务器定义带进会话更省。git、gh、rg、云平台 CLI 往往都比“漂亮但厚重的上下文层”更划算。
6. 让 Claude 在动手前少读一点。 Anthropic 现在推荐在强类型语言里使用 code intelligence 插件,因为更准确的符号导航能减少无意义的文件读取。文档也提到 hooks 和 skills 可以帮助你在 Claude 真正载入上下文前,先过滤或预处理输入。这类优化的价值常被低估。如果你的流程总是先把大日志、完整测试输出或同一套架构发现过程重复喂进去,问题通常不在套餐,而在预处理做得不够。
7. 为当前这一周选对付款模式。 Anthropic 当前的 Pro / Max 帮助页已经把两条官方逃生路线写得很明确:额度不够时,可以开启 extra usage,或者直接切到 pay-as-you-go。对于一次性的迁移冲刺、代理大量跑任务的一周、或者明显高于平常的重构周期,这通常比“死守订阅额度”更理性。有时候最省钱的做法并不是继续压榨现有套餐,而是暂时切到更适合突发负载的表层。
这七条背后的共同逻辑其实只有一句话:缩小上下文、明确模型路线、别让 Claude 一遍遍重新理解你已经知道的东西。
如果你还是觉得用量不对劲
一篇靠谱的用量文章,也应该告诉你什么时候问题可能不完全在你自己。至少有三种情况,会让 Claude Code 的体感和你的预期明显错位。
第一种是 认证路径搞错了。如果环境里有 API key,Claude Code 可能直接走 API 计费,而不是你的订阅。用户体感上会说“Claude Code 怎么突然这么烧 Token”,但真正发生的可能是你不知不觉换了一条计费路线。
第二种是 限制行为本身会波动。2026 年 3 月下旬,GitHub issue、Reddit 讨论和科技媒体都出现过“5 小时额度掉得特别快”“高峰期更容易被收紧”的反馈。Anthropic 的帮助页已经承认 5 小时和每周限制存在,但并不会公开一套永远不变的动态调度表。比较稳妥的结论不是“所有抱怨都是真的”,而是:任何静态估算都不如当前产品里的实时指标更可靠。当你的体验和老文章冲突时,优先相信当下的 Settings > Usage、/status 和 /cost。
第三种是 默认走了过大的上下文路线。最近围绕 1M 上下文的讨论就很容易让人误解,以为“更大的窗口一定更划算”。Anthropic 的官方页面确实确认了 Sonnet 4.6 和 Opus 4.6 在 Claude Code 中能走到 1M,但并没有承诺在所有时间窗口、所有认证路径下,体感都完全一致。如果你最近突然觉得掉得特别快,先按最简单的顺序排查:更小的模型、更小的上下文、新会话、确认没有意外走 API key,再考虑是不是高峰时段问题。
如果你碰到的是明确的报错提示,而不是单纯想理解用量模型,可以继续看我们的 Claude Code “Rate limit reached” 修复指南。这篇文章解决的是“它为什么会这样”;那篇文章解决的是“我现在该怎么恢复工作”。
常见问题
Claude Code 和 Claude 网页端是分开的额度吗?
对于个人 Pro 和 Max 用户,不是。Anthropic 当前帮助中心明确说明,Claude 与 Claude Code 共用同一套套餐分配。如果你走的是 API 计费,那又是完全独立的一套系统,有自己的速率限制和支出逻辑。
Claude Code 里的 1M 上下文是默认都有的吗?
不是。Anthropic 当前帮助页面说明,付费 Claude 套餐一般是 200K,上到 Sonnet 4.6 和 Opus 4.6 的 1M 能力则与 Claude Code 新规则和 extra usage 条件相关。API 路径下,Anthropic 也明确写了 Sonnet 4.6 与 Opus 4.6 支持 1M。不要把“模型支持 1M”理解成“任何路径下都应该默认开最大上下文”。
个人 Pro 或 Max 可以看到 Claude Code analytics 吗?
目前不行。Anthropic 的 usage analytics 帮助页明确写了,这套分析能力面向 Team、Enterprise 和 API Console 用户,不对个人 Pro 或 Max 开放。个人用户应该用 Settings > Usage、/status 和 /cost。
Prompt caching 对 Claude Code 用量真的有帮助吗?
有,但不同路径的帮助方式不一样。Anthropic 的 API 文档明确说明,多数模型的 cache reads 不计入 ITPM,这会直接改善 API 吞吐。更广义地说,Anthropic 也一直把缓存和重复内容复用视为“让额度走得更远”的关键方法。实操上,你只需要记住:稳定重复的上下文,永远比让 Claude 每次都从头读一遍更省。
我应该继续用 Pro、升级到 Max,还是切到 API 计费?
如果 Claude Code 对你有帮助,但还不是全天候主力,先从 Pro 开始通常最合理。平时工作里经常在完成任务前被打断,再考虑 Max。遇到一次性的重负载冲刺、自动化链路、或者你就是需要把成本和吞吐分开管理时,切到 API 计费通常更容易算清楚。
为什么 Claude Code 一开始还好,过一会儿突然就变贵了?
因为会话会越来越重。对话历史、载入的文件、工具结果和模型路线都会持续累积。问题通常不在“你又发了几条 prompt”,而在于你让后续每一轮都拖着更多旧内容往前走。最常见的修复不是少问几句,而是重开会话、及时 compact,或者缩小这次任务真正需要的上下文范围。