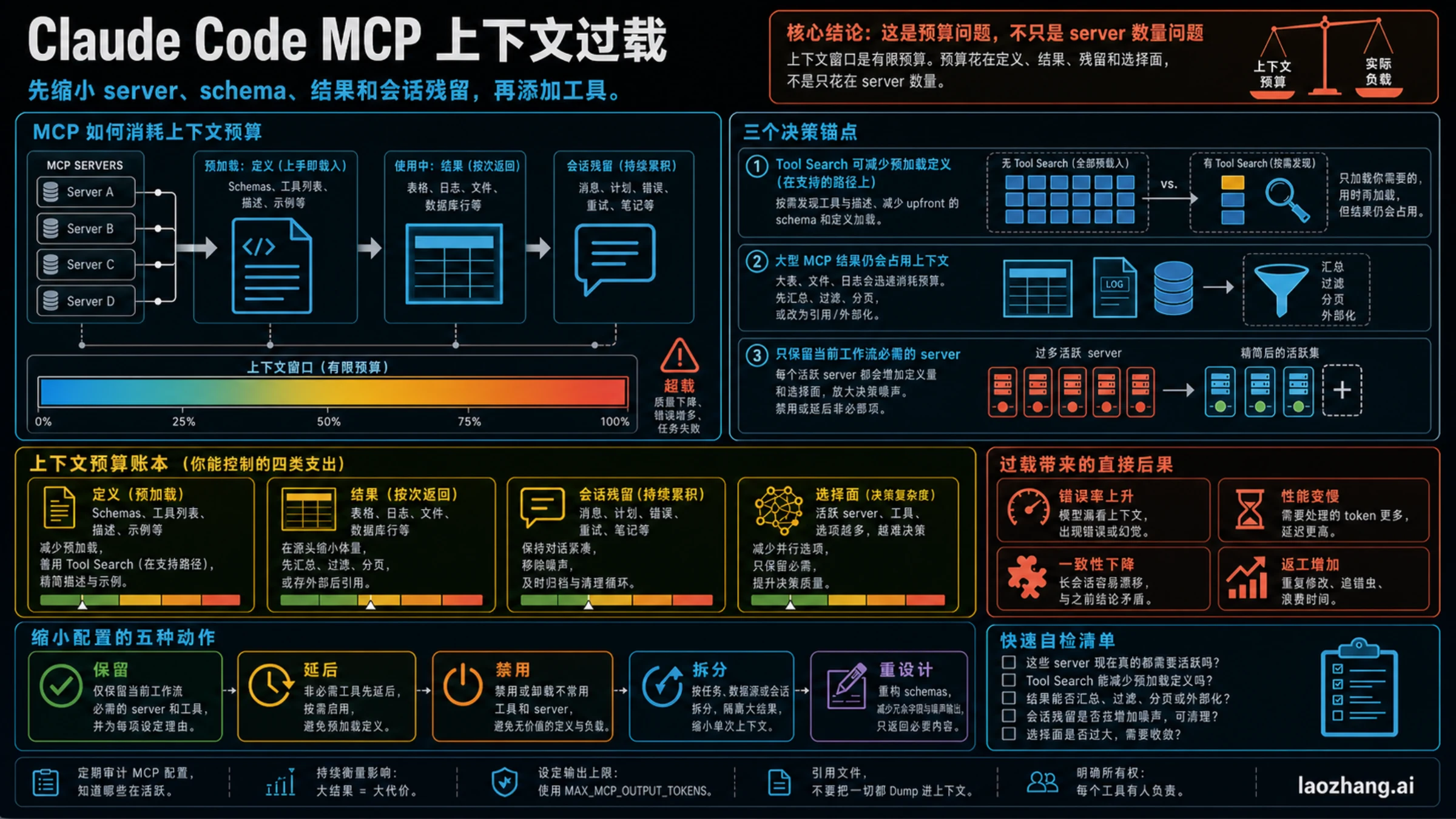
Claude Code 接太多 MCP server 之后变慢、提前 compact、或者一调用工具就开始丢重点,通常不是“Claude 变笨”这么简单。每个连接都会带来一类上下文成本:工具名称、说明和 schema 可能提前进入可见范围;工具调用后的日志、表格、文件和数据库行会继续占用窗口;一次长会话里的失败分支、旧计划和重复尝试也会留下残留。Tool Search 能缓解一部分工具定义负担,但它不会让无关 server、超大返回结果、代理路径差异或旧会话免费。
截至 2026 年 5 月 23 日,Claude Code 文档已经说明 MCP 控制、Tool Search 以及输出超过 10,000 tokens 时的警告;如果你走的是代理、兼容网关、自定义模型或非默认 provider,先在自己的环境里验证,不要把别人的截图当成当前事实。
先用一张预算表判断问题来自哪里:
| 成本 | 现场表现 | 第一修复动作 |
|---|---|---|
| 工具定义 | 还没调用外部工具,模型已经面对一堆名称、描述和参数。 | 确认 Tool Search 是否生效;把当前任务不需要的 server 延后或关掉。 |
| 工具返回 | 一次日志、表格、issue、搜索或数据库调用后,窗口迅速变重。 | 在源头做摘要、过滤、分页、limit、cursor 或返回文件句柄。 |
| 会话残留 | 多次修 bug、重试、撤回方案之后,Claude 开始混淆新旧判断。 | 总结当前决策,关闭旧分支,必要时开新线程。 |
| 决策面 | 多个 server 都叫 search、read、list,Claude 不确定该用哪个。 | 每个工作流只留一个 owner;把过宽的自建 server 拆开或重做。 |
马上可以做的动作很窄:在 Claude Code 里跑 /mcp,列出本次任务真的需要的 server,然后给每个 server 标记 keep、defer、disable、split 或 redesign。缺的是固定方法,就用 skill;缺的是外部数据或动作面,才保留 MCP,并压缩它返回给对话的内容。
先把问题拆成上下文预算
MCP server 不是 settings.json 里的一行名字。一个 MCP tool 至少会有名称、描述、输入 schema,可能还有输出 schema 和返回内容。客户端什么时候把这些信息暴露给模型,取决于 Claude Code 的加载路径、Tool Search 状态和具体 provider 行为;但无论怎样,工具定义本身都不是零成本。
更容易被忽略的是第二类成本:工具调用结果。你可以只启用一个数据库 MCP,但如果它默认吐出 8,000 行、完整 trace、整份文档或所有匹配文件,窗口照样被吃满。相反,三个清晰、安静、只返回小摘要的 server 往往不会造成同样的压力。
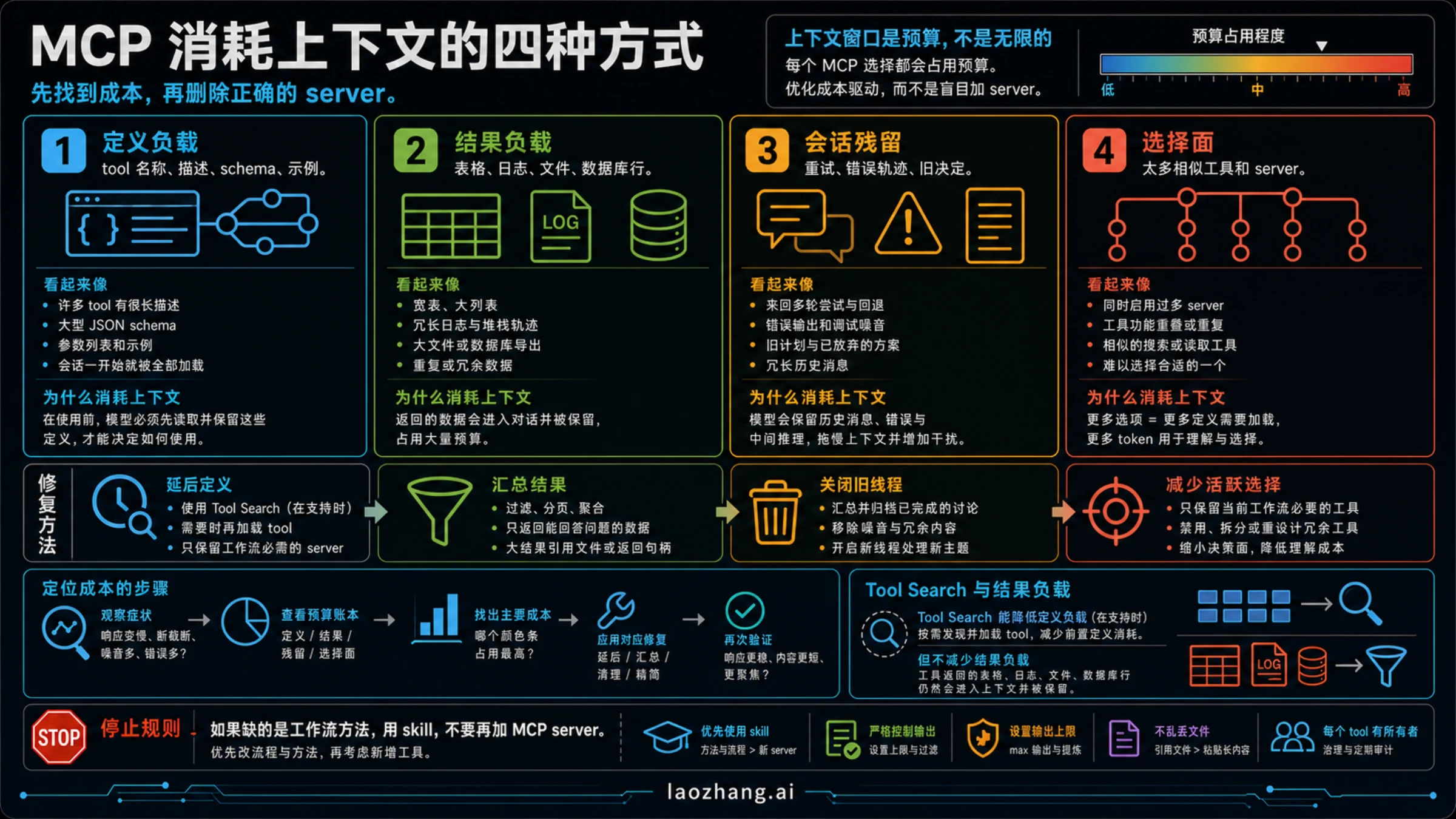
因此,排查时不要只问“我装了几个 MCP server”。要问“这次任务中,有多少内容被放进了当前工作窗口”。如果痛点发生在任何 tool call 之前,重点看工具定义、重复命名和 server 选择面;如果痛点发生在某次调用之后,重点看返回体大小;如果痛点发生在长时间反复修复之后,重点看会话残留。
| 你看到的症状 | 更可能的成本 | 检查位置 |
|---|---|---|
| 刚开始就慢或犹豫 | 工具定义、决策面 | /mcp、server 列表、重复工具名、过长描述 |
| 调用一次后开始乱 | 工具返回 | 日志、表格、文件、数据库行、检索返回数量 |
| 修几轮后判断倒退 | 会话残留 | 旧错误、旧计划、未关闭分支、重复输出 |
| 总选错工具 | 决策面 | 多个 server 暴露相似 read/search/list 动作 |
这个预算模型比“全部删掉”更稳定。你要的是更少的当前选择、更小的返回内容、更清楚的 owner,而不是把所有外部能力都关掉以后再从头猜。
Tool Search 只处理一部分成本
Tool Search 的价值在于延后工具发现和工具定义加载。以前很多建议会说“接入 MCP 就一定把 schema 全塞进上下文”;现在这个说法需要加条件:在 Claude Code 支持的路径上,Tool Search 可以减少 upfront 的定义负担。
但它不是免税卡。Claude 一旦真的调用工具,返回结果仍然进入当前对话,仍然会消耗 context window。Anthropic 对 context window 的解释很直接:这是当前交互的工作记忆,历史轮次和工具结果都会累积。Tool Search 主要改变“什么时候看到工具定义”,不是“工具可以返回多少数据”。
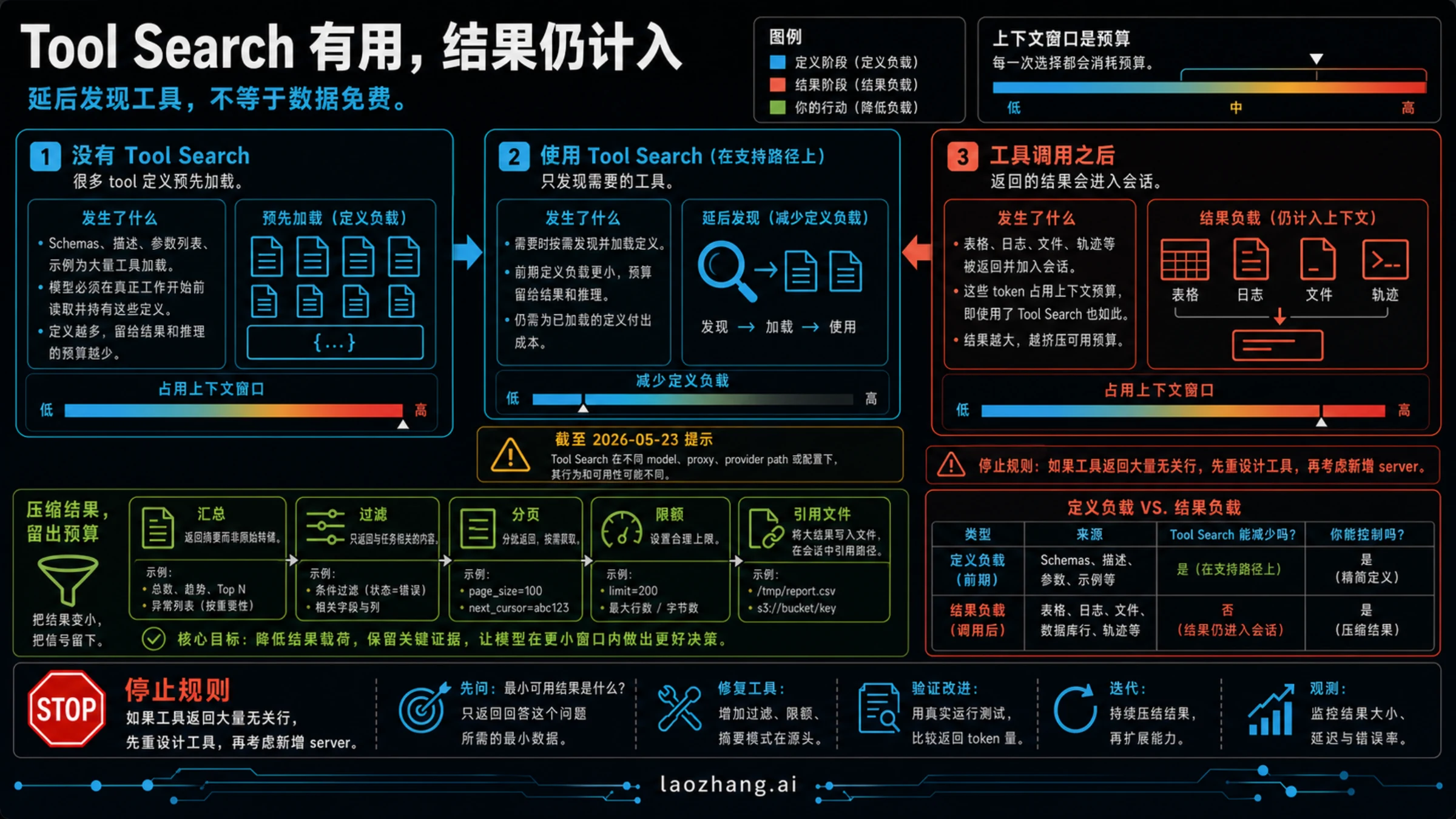
三个边界要分开看:
| 边界 | Tool Search 能帮什么 | 它不解决什么 |
|---|---|---|
| 前置工具定义 | 支持路径上延后发现和加载工具 | 工具名太泛、描述太长、多个 server 争同一件事 |
| 工具返回 | 本身不压缩返回体 | 大表、日志、trace、文件、API 原始 payload |
| 会话残留 | 本身不清理旧轮次 | 长线程、失败分支、重复尝试、过期判断 |
如果你使用 ANTHROPIC_BASE_URL、兼容 provider、代理网关或自定义模型路径,不要只看“Tool Search 已经发布”这个结论。实际做一次任务,看模型在 /mcp 之后是否仍然加载了过多工具,或者是否在工具返回后才开始变差。前者是定义问题,后者是输出压缩问题。
Keep、Defer、Disable、Split、Redesign
清理 MCP 的关键不是追求最小数量,而是让当前激活列表有解释力。每个 server 都必须能填上这句话:“这次任务里,它负责 ____。”如果空格里只能写“可能有用”,它就不该默认待在主会话里。
| 动作 | 什么时候用 | 例子 |
|---|---|---|
| Keep | 它确实拥有当前 workflow,且本地文件、memory、skill 都替代不了。 | PR review 时保留 GitHub MCP,查框架迁移时保留 docs MCP。 |
| Defer | 它有价值,但只在后续阶段或少数分支使用。 | UI 还没改完之前,先不启用浏览器 QA server。 |
| Disable | 它不服务当前任务,或和另一个 active owner 重复。 | 两个 docs server 都回答同一个库。 |
| Split | 一个自建 server 打包了互不相关的读写动作。 | 把只读 issue 搜索和部署写操作拆成不同 server。 |
| Redesign | server 是你写的,工具形状太宽、太吵、默认返回太多。 | 把 dump_database 改成 search_errors(service, time_range, limit)。 |
/mcp 适合在 Claude Code 里快速看 active server;claude mcp list、claude mcp get、claude mcp remove 适合在终端层做配置清点。做这件事时不要只数数量。要看每个工具名是否能让 Claude 做出稳定选择,描述是否短而有区分度,默认输出是否足够小。
如果你其实还在决定“第一批 MCP server 应该装哪些”,先看 Claude Code MCP Server 推荐。本文解决的是另一个阶段:配置已经长胖,现在要把它缩回适合当前工作的形状。
在工具输出进入对话前压缩
Tool Search 生效以后,真正伤窗口的常常是 tool output。一次 Playwright snapshot、GitHub issue 列表、数据库查询、日志拉取或全文搜索,比几个安静 server 更容易把上下文压爆。
Claude Code 的 10,000 token 输出警告和 MAX_MCP_OUTPUT_TOKENS 是护栏,不是设计目标。好的 MCP 返回不是“刚好没超过上限”,而是“足够让 Claude 做下一步判断”。如果下一步只需要三条错误样例,就不要返回整份日志;如果下一步只需要 owner、状态和数量,就不要返回每一行原始记录。
| 规则 | 坏返回 | 更好的返回 |
|---|---|---|
| 先摘要 | 完整日志流 | 异常类型、计数、3 条样例 |
| 源头过滤 | 所有行 | 服务、时间、状态、owner 命中的行 |
| 分页 | 一个巨大响应 | 第一页加 next_cursor |
| 默认上限 | 无限制文件或匹配 | limit: 20,需要时显式放大 |
| 返回句柄 | 完整文件或数据集 | file path、object id、job id、stored result |
| 预览和深挖分开 | 直接原始 payload | 摘要先返回,raw fetch 另开参数 |
用户侧也能做压缩。不要问“读一下数据库”,而是问“按 service 汇总过去 24 小时 top 20 error,每类给 count 和一条 sample trace”。不要问“看日志”,而是问“只看部署失败后的错误行,健康检查和重复 warning 忽略”。问题越窄,工具越不容易把无关内容塞进窗口。
设计紧凑的 MCP server
如果你能改 server,最高杠杆不是开关它,而是重做工具形状。一个紧凑的 MCP server 应该让 Claude 很容易走 compact path:少量工具、清楚 owner、短描述、默认安全、默认摘要、需要时再取更多。
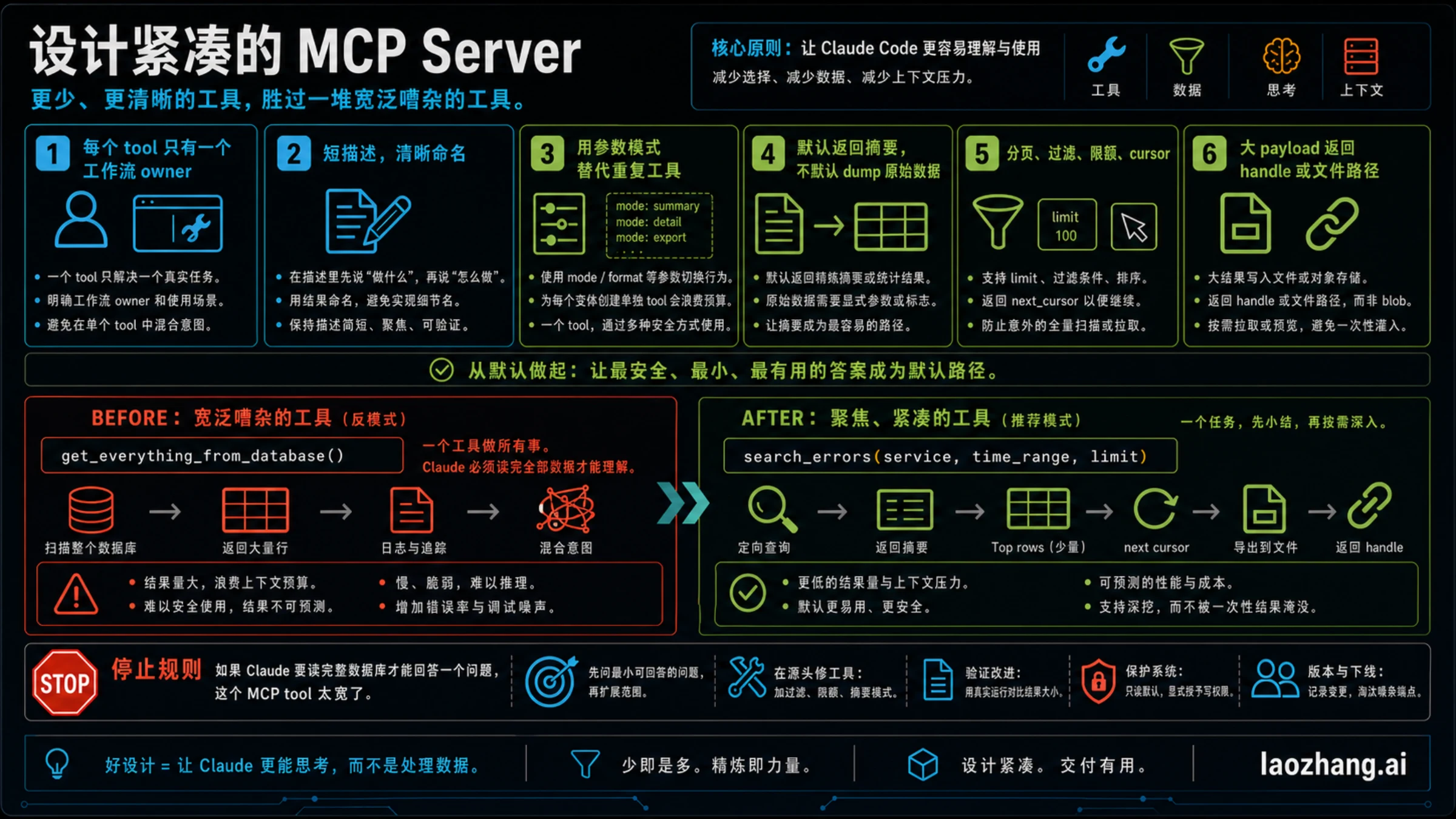
设计时按这个清单过一遍:
- 一个 tool 只做一件事,不要同时读 issue、日志、指标、文件和部署。
- 工具名写结果,不写实现。search_recent_errors 比 query_system 更好。
- 描述要帮 Claude 选择工具,不要把整个后端文档塞进去。
- 相似模式尽量参数化,例如 mode: summary/detail/export,而不是三组重叠工具。
- 默认返回 summary,raw output 必须显式请求。
- 高频、大数据工具必须支持 filter、limit、pagination 或 cursor。
- 超大 payload 返回 path、id、handle,让后续步骤按需打开。
- 读写分开,昂贵或破坏性动作要在名称和描述里清楚标出。
一个坏工具是 get_everything_from_database(),返回 rows、logs、traces 和 unrelated metadata;一个紧凑工具是 search_errors(service, time_range, limit),先返回摘要、top rows 和 next_cursor。区别不只是 token 数。后者让 Claude 知道下一步该问什么,前者会把模型推回“先读完再说”的坏习惯。
把重活移出主线程
有些时候,正确答案不是“少用 MCP”,而是“不要在主线程里做所有 MCP 探索”。Claude Code subagents 可以把噪声调查隔离出去:让一个窄工具集的 subagent 查日志、整理候选、返回摘要,主线程只保留决策。
但 subagent 不是天然压缩边界。工具继承如果太宽,它可能拿到和主会话一样多的 server,最后只是把噪声复制到另一个地方。给探索型 agent 只开它需要的工具,并要求它返回 findings、counts、paths、next actions,而不是 raw payload。
Skill 也是压缩路线,但它解决的是“方法”而不是“外部访问”。缺一套固定检查步骤,写 skill;缺 GitHub、Sentry、数据库或浏览器动作面,用 MCP;两者都缺时,让 MCP 提供触达,让 skill 提供操作方法。可复用方法可以看 Claude Code Skills 推荐,长期规则则适合放到 Claude Code Memory。
20 分钟清理流程
当 Claude Code 因为 MCP 太多而提前 compact、回答变慢或工具选择变差时,用这个流程:
- 在当前任务里运行 /mcp,列出 active server。
- 给每个 server 标记 keep、defer、disable、split 或 redesign。
- 关掉没有当前 workflow owner 的项,不要因为“未来可能用”保留。
- 重跑同一个小任务,观察痛点发生在 tool call 前还是 tool call 后。
- 如果发生在 tool call 前,检查 Tool Search、工具名、描述、重复 owner。
- 如果发生在 tool call 后,检查返回体,改 summary、filter、limit、cursor、handle。
- 如果发生在多轮修复后,总结当前决策并开新线程。
- 如果缺的是方法而不是访问,写 skill,不要再加 server。
好指标不是总共配置了几个 server,而是当前任务中 Claude 需要考虑多少 active choice,以及每个 tool call 会把多少数据带回对话。最小有用配置通常不是最酷的配置,而是 Claude 能稳定推理的配置。
一个常见排查例子是:你同时开了 GitHub、Sentry、数据库、浏览器、文档和内部后台 MCP,但当前任务只是修一个 API 500。此时 GitHub 可能只需要读 issue,Sentry 可能负责错误样本,数据库可能只负责最近 24 小时的失败计数。浏览器 QA、通用文档、后台写操作都可以先 defer。这样 Claude 面前的 active owner 会少很多,问题也更容易被拆成“错误样本、影响范围、修复验证”三步。
另一个例子是自建日志 MCP。坏设计会默认返回整段日志、所有 request headers、完整 stack trace 和周边 debug 行;好设计会先返回错误类型、count、时间范围、代表 trace、受影响 route 和 next_cursor。只有当 Claude 明确需要原始证据时,才通过 handle 打开对应片段。这样做不会降低可追溯性,反而让主线程保留更多空间来判断修复方向。
常见问题
Tool Search 能解决 Claude Code MCP 上下文爆掉吗?
不能完全解决。它能在支持路径上减少前置工具定义负担,但不能压缩工具返回、清理旧会话、消除重复 server,也不能修复过宽的自建工具。
Claude Code 应该启用多少 MCP server?
没有通用数字。只启用当前 workflow 的 owner,其余延后或关闭。一个会返回巨大数据库结果的 server 也能吃爆窗口,几个安静、职责清楚的 server 反而可能没问题。
MCP tool output 很大怎么办?
在源头压缩。让工具返回 summary、filter、limit、pagination、cursor、file path、object id 或 handle。能不把 raw data 塞进对话,就不要塞。
什么时候用 skill 替代 MCP?
缺的是可重复方法、检查清单、参考包或脚本顺序时,用 skill。缺的是外部数据、外部系统或动作面时,用 MCP。两者同时需要时,把访问和方法分开设计。
怎么设计紧凑 MCP server?
少工具、清楚 owner、短描述、默认摘要、可过滤、可分页、有 limit 和 cursor,超大数据返回句柄。避免一个工具为了方便而返回所有东西。
把所有 MCP server 都关掉是不是最安全?
不是。全关只适合诊断。长期方案是一个紧凑 active set:保留当前任务必须的外部访问,延后非必要项,并重做那些默认返回太多数据的工具。
Claude Code MCP 上下文爆掉是可以修的。把窗口当预算,不要把每个集成都放进主线程。留下当前任务真正需要的 server,把大结果在源头压缩,把固定方法交给 skill,把噪声探索放进受限上下文。Claude 能推理得好的 MCP 设置,通常也是最小但够用的设置。