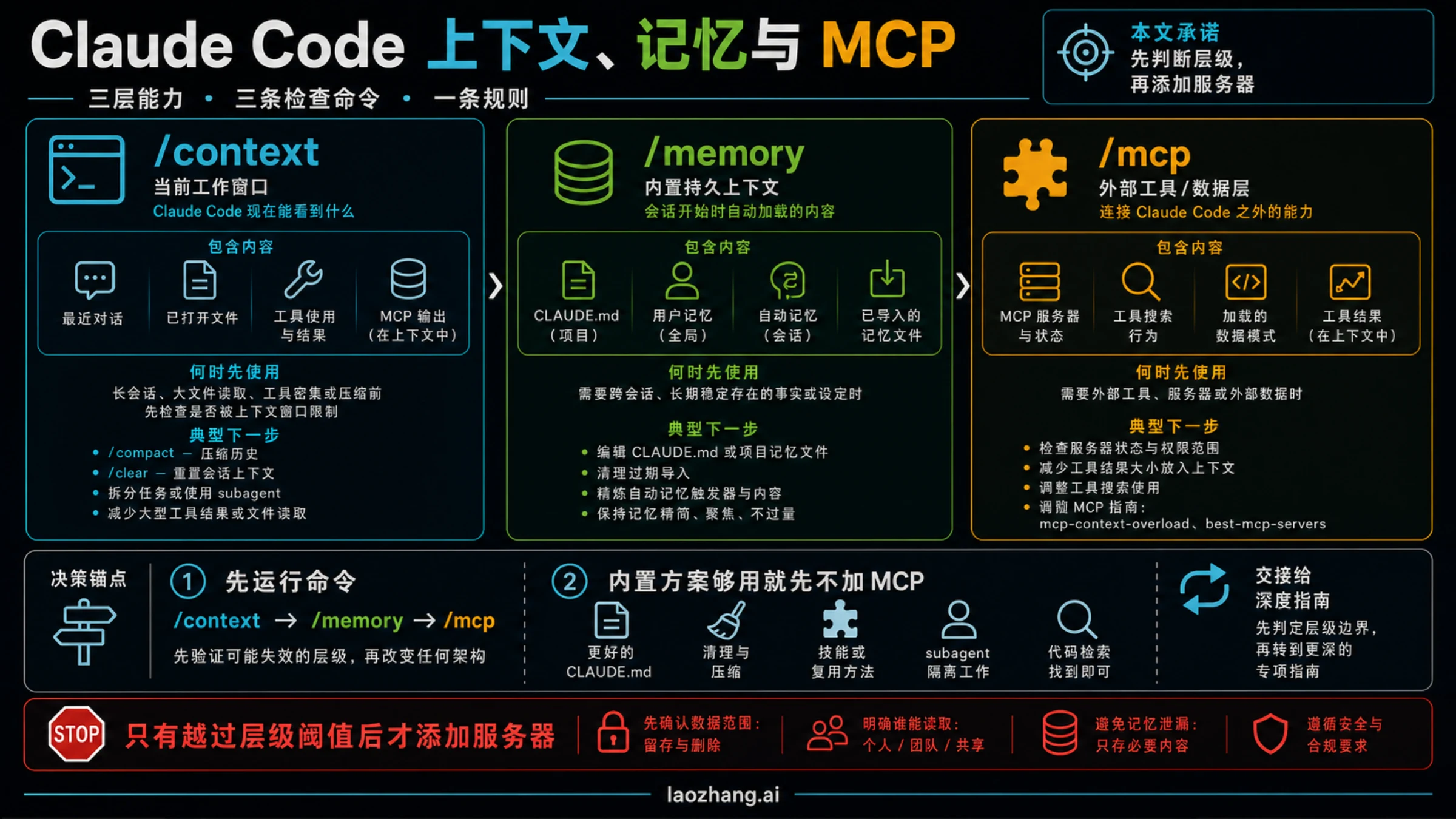
Claude Code 的上下文、记忆和 MCP 不是同一个开关。遇到“它忘了”“会话变乱”“工具输出太吵”时,先证明问题发生在哪一层:当前工作窗口、启动时加载的内置记忆,还是外部工具层。只有这个判断清楚,memory MCP 才可能是正确答案。
快速路线可以这样走:
| 症状 | 先运行 | 它证明什么 | 服务器之前的较小修复 |
|---|---|---|---|
| 长会话后回答开始漂移 | /context | 当前窗口是否被对话、文件、工具结果或 MCP 输出挤满 | 在边界处压缩、清空残留、拆任务、减少工具输出 |
| 新会话里项目规则没被带上 | /memory | 哪些 CLAUDE.md、导入记忆或 auto memory 已加载 | 修改正确层级的记忆文件,而不是新接服务器 |
| 工具太多、连接异常或外部结果可疑 | /mcp | 当前连接了哪些 MCP server,以及外部层是否在制造噪声 | 缩小 server 范围、禁用噪声工具、修复连接 |
| 重复流程总要重新解释 | /skills 或子代理 | 问题是否属于可复用方法或隔离探索 | 写成 skill,或者把大范围读取交给子代理 |
停止规则也很直接:如果更干净的 CLAUDE.md、/compact、/clear、skill、子代理或代码检索已经能解决问题,就不要急着接 memory MCP。只有你确实需要跨机器连续性、团队共享回忆、跨工具检索,或者内置记忆放不下的动态工作状态时,外部记忆服务器才进入候选名单。接入之前还要问清楚数据保留、删除、谁能读取、是否会存入密钥或客户资料。
快速判断:到底是哪一层失效?
把 Claude Code 的连续性看成层,而不是一个“记忆强度”旋钮。当前对话是 Claude 现在能看到的工作窗口;内置记忆是启动时加载进窗口的项目或用户背景;MCP 是连接外部工具、数据和动作的通道;skill 保存可复用方法;子代理把可能污染主线程的大范围探索隔离出去。这个分层一旦被忽略,你很容易把一个上下文膨胀问题误判成“需要更强记忆”。
很多团队的第一反应是“接入 memory MCP 后就有长期记忆”。这只说中了一个场景,却跳过了诊断。如果问题其实是当前窗口被长日志、文件读取、网页快照或 MCP 返回结果塞满,外部记忆服务器可能只会增加更多工具描述和检索结果。真正的第一步不是安装,而是确认失效的所有者。
| 失败模式 | 更可能的所有者 | 证明面 | 下一步 |
|---|---|---|---|
| 同一会话后半段反复引用旧分支 | 当前 context window | /context | 在决策点压缩,或开新会话并重新加载项目记忆 |
| 新会话不记得仓库规则 | 内置 memory | /memory | 把规则写到正确的 CLAUDE.md 或导入文件 |
| 工具结果巨大、重复或权限异常 | MCP | /mcp | 关掉噪声 server,限制输出字段,修连接 |
| 每次都要解释同一套流程 | skill | /skills | 把流程写成技能或清单 |
| 需要读很多旁支文件但主线不能乱 | 子代理 | 任务交接记录 | 把探索交给隔离上下文,只带结论回来 |
| 多机器、多工具、团队都要共享动态状态 | 外部 memory MCP | server 文档和数据治理 | 通过保留/删除/权限检查后再接入 |
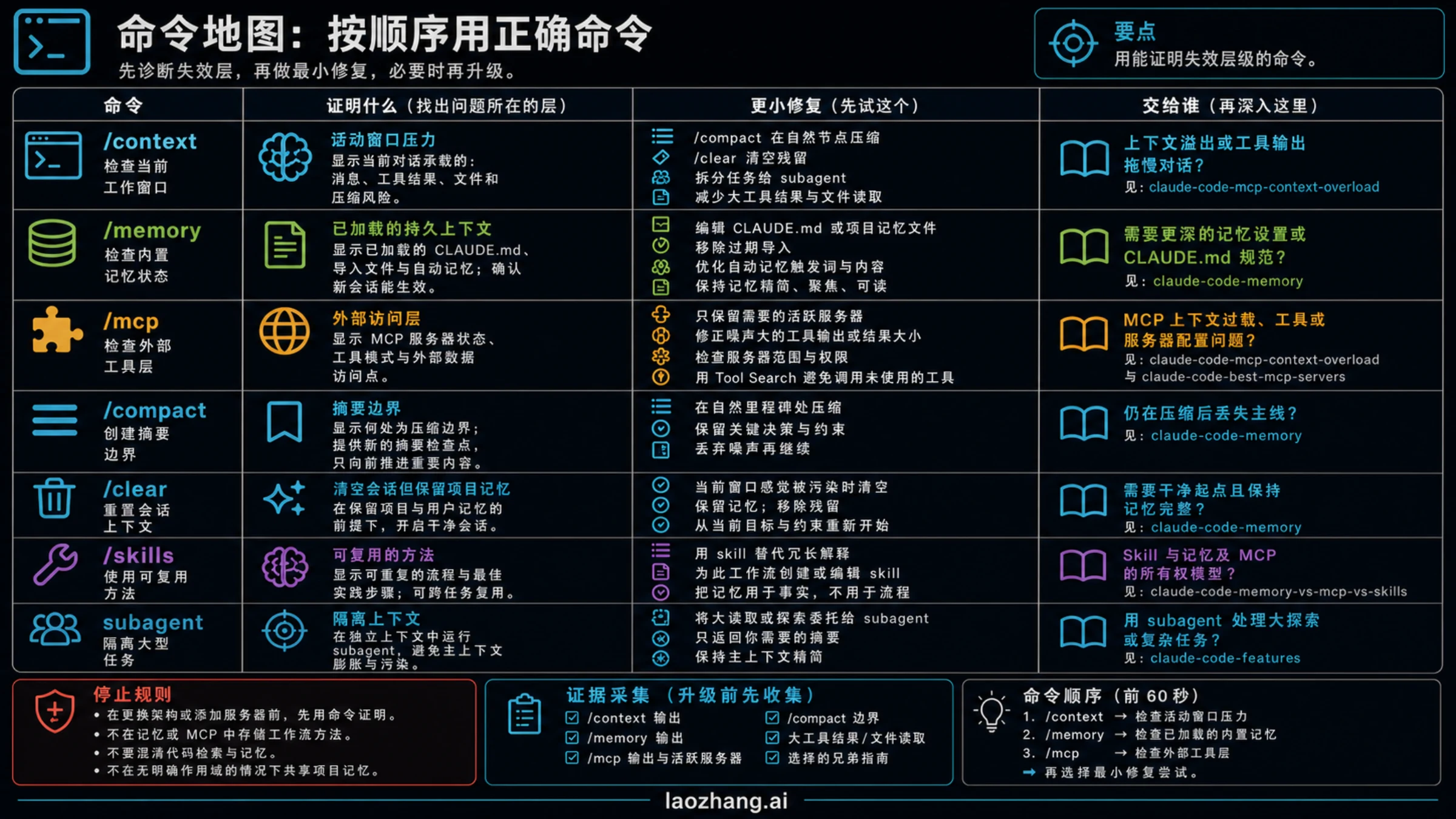
这个表的作用,是把模糊的连续性抱怨变成可以执行的排查顺序。如果答案落到内置记忆,就继续维护 CLAUDE.md;如果落到 MCP,就先清理 server;如果落到外部记忆,再去评估具体 memory MCP。同一个症状跨越多层时,按“先证明、再缩小、最后升级”的顺序做记录,后续协作才知道为什么没有直接安装服务器,也能复查当时的命令证据和数据边界。
/context 证明什么
/context 证明的是当前工作窗口,而不是长期记忆能力。它让你看到会话里正在占空间的类别:用户指令、项目记忆、工具定义、工具结果、文件片段、模型回答、压缩摘要和其他加载材料。只要问题出现在同一会话越来越长之后,/context 就应该排在第一位。
典型信号包括:Claude 开始把已经废弃的方案当成当前计划;一次长日志读取后后续回答质量下降;MCP server 返回了很大的 JSON 或网页快照;压缩后上下文只留下宽泛摘要,丢了关键边界;或者一个线程里同时混入研究、实现、审稿和发布动作。这里的修复不是“记住更多”,而是“让当前窗口更干净”。
可以按这个顺序处理。先在自然边界压缩,让压缩摘要只保留决策、路径和未完成事项。再把无关探索移到新线程或子代理。然后限制工具输出,要求 server 返回摘要、句柄、分页或明确字段。最后,如果当前窗口已经有太多错误分支,直接 /clear 或开新会话,让项目记忆重新加载。memory MCP 在这一步通常不是解药,因为它可能继续向同一个拥挤窗口注入更多材料。
内置记忆负责什么
内置记忆负责那些新会话一开始就应该知道的稳定背景,例如仓库约定、命名规则、测试命令、发布边界、用户偏好和长期项目原则。它通过 CLAUDE.md、导入文件和自动记忆进入 Claude Code 的启动上下文,所以它仍然占用 context window;它不是一个无限数据库,也不是权限系统。
这意味着两类材料要分开放。短而稳定的规则可以进记忆:例如“这个仓库文章必须用 data/posts/{lang}/{slug}/{slug}.mdx”“先跑哪个检查器”“不要推荐某个旧品牌”。但大段日志、完整调研记录、一次性证据、长表格、会议纪要和全部历史对话不应该塞进记忆。它们应该放在文件、issue、数据库或外部文档里,再用短记忆指向位置。
使用 /memory 的场景,是 Claude 在新会话中漏掉了一个本该持续存在的规则。命令能帮助你区分三件事:规则从未保存;规则保存到了错误作用域;规则已经加载,但当前窗口太乱导致模型没有稳定使用它。只有第三种才回到 /context;前两种都应该修内置记忆,而不是新增外部 server。
MCP 负责什么
MCP 负责外部访问:工具、数据源、服务、数据库、检索、issue 系统、浏览器、内部平台和动作接口。它很适合把 Claude Code 连接到默认看不见的系统,但不等于所有“记忆”都应该外置。一个 memory MCP 也是 MCP server,首先要接受 MCP 层的约束:连接是否可靠、工具描述是否克制、输出是否可控、权限和数据保留是否透明。
运行 /mcp 的目的,是确认外部层本身有没有问题。server 是否断连?工具是否重复?同一类能力是否暴露了太多入口?工具描述是否在每次会话中占据过多上下文?一次调用是否返回了过大的原始结果?如果这些问题存在,继续增加 memory MCP 只会让架构更重。
另一个常见误区,是把代码检索、项目记忆和长期工作状态混在一起。代码检索回答“文件和符号在哪里”;内置记忆回答“这个项目长期应该怎么做”;memory MCP 只有在需要跨会话、跨工具、跨机器或团队共享动态事实时才合适。如果你只是想让 Claude 找到代码,优先用代码检索或更好的文件读取策略,而不是把代码库变成记忆库。
接外部 memory MCP 之前的更小修复
很多连续性问题其实是工作流形状问题。重复方法应该交给 skill。skill 可以保存步骤、参考资料、检查器和约束,但不会把全部细节默认塞进每个会话。记忆负责“应该知道什么”,skill 负责“该怎么执行”。这两个边界分清后,很多所谓记忆问题会消失。
大范围探索应该交给子代理或单独线程。主线程只需要结论、证据路径、剩余风险和下一步,不需要承载所有读取过程。对于文章、代码迁移、依赖排查、日志分析这类任务,这个隔离比长期记忆更能保护主会话质量。因为问题往往不是“模型不记得”,而是“模型记了太多无关过程”。
还有两个简单命令经常被低估。/compact 适合在已知边界把已完成探索压缩成摘要;/clear 适合彻底摆脱当前会话残留,同时让项目记忆重新加载。如果你已经能用这两个动作恢复质量,说明问题属于当前上下文治理,而不是外部记忆治理。
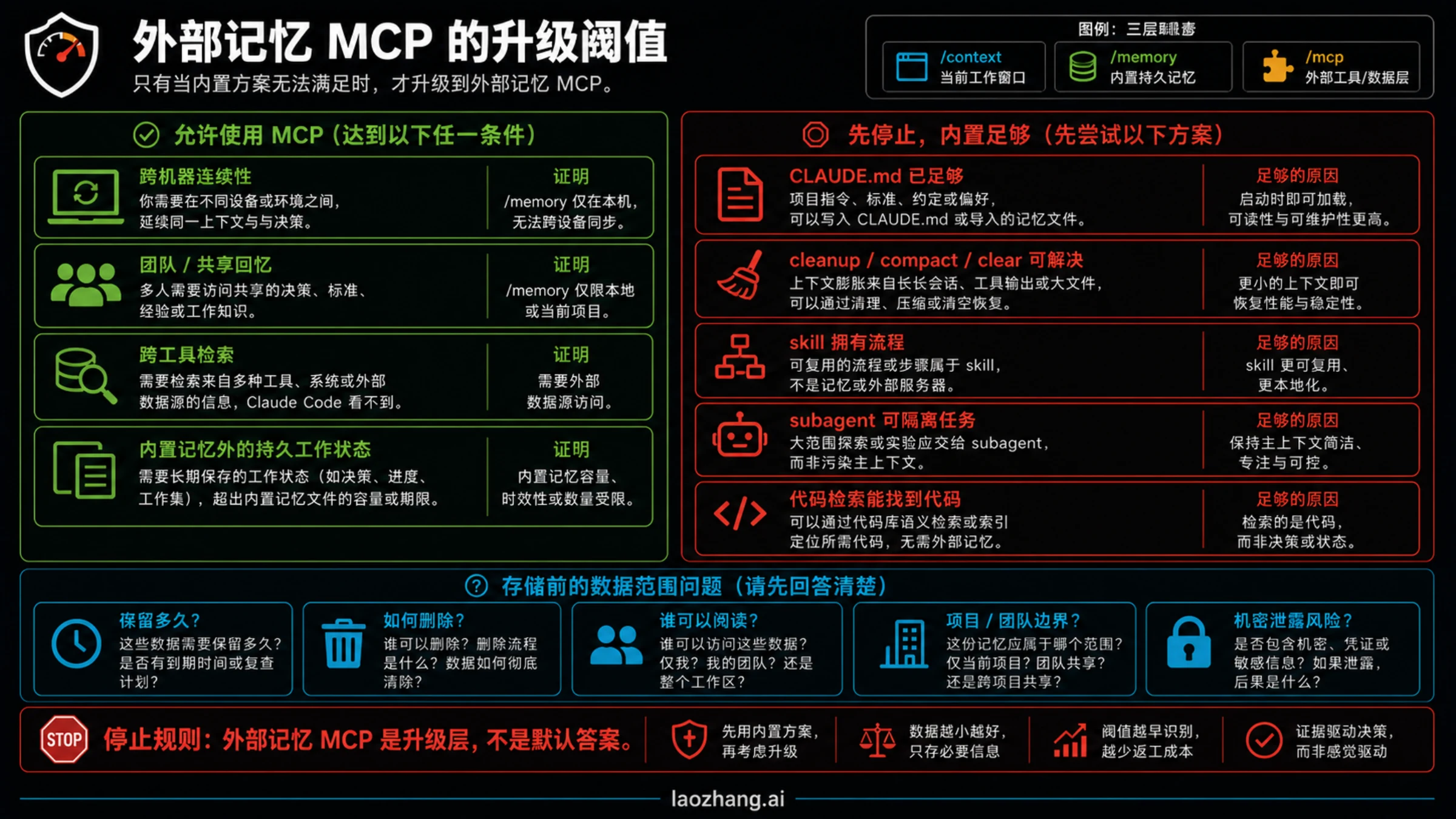
什么时候外部 memory MCP 才值得
外部 memory MCP 的价值在真实阈值之后才出现。第一类阈值是跨机器或跨环境连续性:同一项目在多台机器、多个 IDE 或多个 Claude Code 环境间切换,内置本地文件无法自然同步。第二类阈值是团队共享回忆:某些项目事实、决策和偏好需要被多人和多个代理读取。第三类阈值是跨工具检索:你需要把 issue、文档、聊天、代码事件或运行记录放进同一个可查询层。第四类阈值是动态工作状态太大或太频繁,不适合写进 CLAUDE.md。
即便跨过这些阈值,也要先做数据检查。服务器在哪里运行?谁能读取?怎样删除?是否保存原始对话、摘要、向量或用户手写事实?能否阻止密钥、客户数据、付款信息和内部账号进入记忆?团队能否接受它的保留策略?如果这些问题没有答案,就不要把 server 升级成默认工作流。
正确的接入方式,是小范围试点。先限定一个项目或一类事实,写清楚允许保存和禁止保存的内容,准备回滚路径,并在几次真实任务后检查它是否真的减少重复说明和上下文膨胀。如果只是“感觉更智能”,但证据包里看不到更少的错误、更清楚的检索或更低的重复成本,那它还不值得进入默认链路。
修复矩阵与证据包

在改变架构之前,先留下足够证据,让下一步不是猜测。
| 要捕获什么 | 为什么重要 | 决策用途 |
|---|---|---|
| 症状和发生时间 | 区分新会话失败和长会话漂移 | 决定先看 /memory 还是 /context |
| /context 输出 | 看到当前窗口压力和材料来源 | 判断是否需要压缩、清理或拆线程 |
| /memory 输出 | 看到哪些记忆文件真正加载 | 判断规则是否保存到正确作用域 |
| /mcp 状态 | 看到外部 server 和工具层 | 判断是否要禁用、缩小或修复 server |
| 大型工具结果 | 找出上下文膨胀来源 | 要求摘要、分页、句柄或字段过滤 |
| 压缩边界 | 说明哪些判断应该留下 | 防止压缩后丢失关键决策 |
| 数据保留要求 | 确认外部记忆是否合规 | 决定 memory MCP 是否可用 |
证据包不需要华丽,但必须能回答“为什么不是更小修复”。如果证据指向内置记忆,就修 CLAUDE.md 或导入文件;如果指向上下文压力,就减少活跃材料;如果指向 MCP 噪声,就缩小 server;如果指向重复流程,就写 skill;如果确实指向跨机器或团队共享回忆,再进入 memory MCP 评估。
常见问题
Claude Code 的 context 和 memory 是一回事吗?
不是。context 是当前会话的工作窗口,memory 是启动时加载进这个窗口的持久背景。memory 会成为 context 的一部分,但 context 本身不会自动变成长期存储。很多“忘记”问题,其实是当前窗口太满或压缩摘要太粗,而不是没有长期记忆。
我应该直接安装 Claude Code memory MCP 吗?
通常不应该。先运行 /context、/memory 和 /mcp,证明问题属于哪一层。只有内置记忆、清理命令、skill、子代理和代码检索都解决不了跨会话或跨工具连续性时,memory MCP 才是合理选项。
Tool Search 会不会让 MCP 没有上下文成本?
不会。Tool Search 可以减少一开始加载的工具定义压力,但已经调用的工具和返回结果仍会进入模型需要处理的材料。MCP server 仍然需要紧凑描述、受控输出、分页、摘要和句柄。
项目规则应该放在 CLAUDE.md 还是 MCP server?
大多数稳定项目规则应该放在 CLAUDE.md 或它导入的内置记忆文件里。MCP 更适合外部访问和动作,不适合只保存“每次都要知道”的短规则。把短规则外置,反而会让每次读取都变成工具调用。
什么时候用 skill 而不是 memory?
当问题是可重复方法时,用 skill。比如审稿流程、发布检查、数据清洗步骤、文章生产工作流、故障排查路径。memory 适合保存长期事实和偏好;skill 适合保存执行方法。
代码检索算 memory 吗?
不算。代码检索帮助 Claude 找到文件、符号和相关片段。memory 负责项目决策和偏好。把二者混在一起,会让记忆库变成难维护的代码索引,也会让代码检索背上不该承担的长期决策责任。