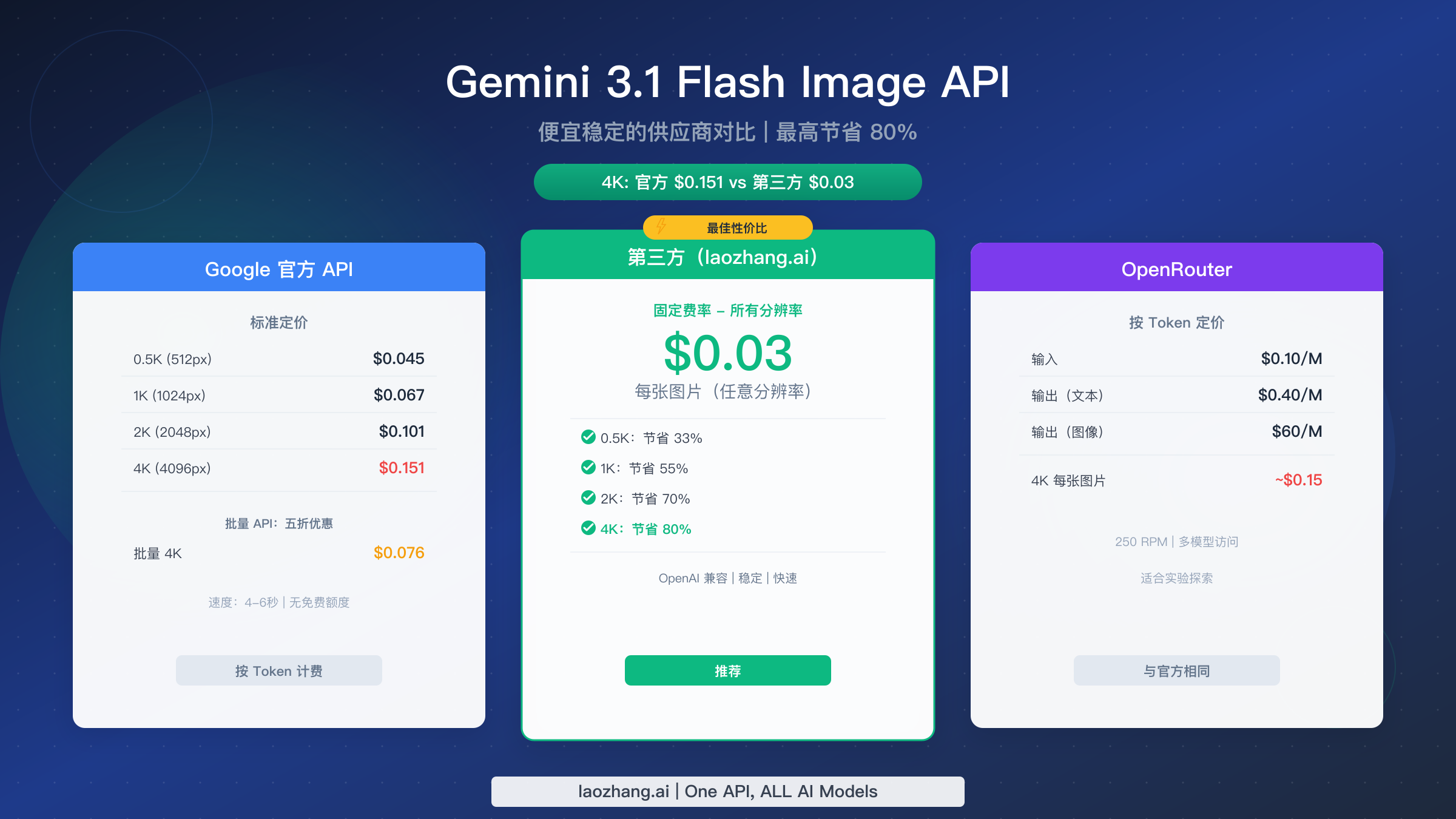
正在寻找最便宜、最稳定的 Gemini 3.1 Flash Image Preview API(Nano Banana 2)使用方式?截至 2026 年 2 月,Google 官方定价从 0.5K 分辨率的每张 $0.045 到 4K 分辨率的 $0.151 不等,而 laozhang.ai 等第三方供应商提供任意分辨率仅 $0.03 每张的固定费率,4K 生成最高可节省 80%。本指南将全面对比各定价层级、分析供应商稳定性,并手把手教你在 5 分钟内完成最低成本方案的集成。
要点速览
Gemini 3.1 Flash Image Preview API(gemini-3.1-flash-image-preview),即 Nano Banana 2,提供出色的图像生成质量,文字渲染准确率约 90%,生成速度在 4-6 秒之间。然而,不同的访问方式在定价上差异巨大。Google 官方标准定价根据输出分辨率收取每张 $0.045 至 $0.151 的费用,而且该模型完全没有免费额度。Batch API 可将成本降低 50%,使 4K 图像降至每张 $0.076,但会引入延迟,不适合实时应用。
第三方 API 供应商提供了最具吸引力的价值方案。像 laozhang.ai 这样的服务无论分辨率如何,都只收取每张 $0.03 的固定费用——这意味着通过 Google 官方 API 需要 $0.151 的 4K 图像,在这里只需 $0.03,节省高达 80%。这些供应商使用 OpenAI 兼容端点,如果你已经在使用 OpenAI SDK,集成起来非常简单。对于大多数需要批量生成图像的开发者和团队来说,第三方供应商在成本节省和稳定性方面提供了最佳组合。
完整定价对比:官方 vs 第三方 API 渠道
要全面了解 Gemini 3.1 Flash Image Preview 的定价体系,需要深入了解按 Token 计费的背后逻辑,而不仅仅是看标题上的每 Token 费率。Google 官方定价页面(ai.google.dev/pricing,2026 年 2 月)将图像生成成本按输出 Token 消耗来计算,而 Token 消耗随分辨率提升而增加。一张 0.5K 的图像大约消耗 747 个输出 Token,而一张 4K 图像则需要约 2,520 个 Token。这种基于 Token 的计价方式意味着,当你追求更高分辨率时,实际每张图像的成本会大幅增加——这个细节让许多开发者在第一次看到账单时措手不及。
官方标准定价层级适用于通过 Google AI Studio 或 Gemini API 发起的所有同步 API 调用,这是基准成本。在最低的 0.5K 分辨率(长边约 512 像素)下,每张图像约 $0.045。提升到 1K 分辨率(1024 像素)后价格升至 $0.067,而 2K 分辨率(2048 像素)达到 $0.101。最高支持的 4K 分辨率(4096x4096)每张高达 $0.151。如果你想了解 Gemini 全系列模型及其定价对比,我们的 Gemini API 定价详细解析涵盖了每一个层级。
Google 还提供 Batch API,所有 Token 费用享有 50% 折扣。这意味着 Batch API 价格分别降至 0.5K $0.022、1K $0.034、2K $0.050 和 4K $0.076。代价是批量请求以异步方式处理——你提交作业后稍后获取结果,这种方式不适合交互式应用,但非常适合批量生成工作流,比如电商目录创建或营销素材流水线。
第三方 API 供应商代表了一种根本不同的定价模式。像 laozhang.ai 这样的供应商不按 Token 收费,而是按每张图像固定费率收费,与输出分辨率无关。只需 $0.03 每张,无论你生成的是 0.5K 缩略图还是完整的 4K 高质量图像。这种固定费率模式在更高分辨率时创造出越来越显著的节省。要全面了解 Gemini 3.1 Flash Image Preview 模型本身——它的能力、限制以及 Nano Banana 2 与早期版本的区别——请参阅我们的 Gemini 3.1 Flash Image Preview 完整指南。
以下是所有供应商和分辨率的完整定价矩阵:
| 分辨率 | Token 数 | 官方标准 | 官方批量 | 第三方(laozhang.ai) | 相比标准节省 |
|---|---|---|---|---|---|
| 0.5K (512px) | ~747 | $0.045 | $0.022 | $0.03 | 33% |
| 1K (1024px) | ~1,120 | $0.067 | $0.034 | $0.03 | 55% |
| 2K (2048px) | ~1,680 | $0.101 | $0.050 | $0.03 | 70% |
| 4K (4096px) | ~2,520 | $0.151 | $0.076 | $0.03 | 80% |
节省规律一目了然:分辨率越高,固定费率第三方定价的优势越大。在 0.5K 时,第三方价格实际上略低于官方标准价格但高于批量价格。然而到了 4K,第三方选项的成本甚至低于打了五折的批量价格,在所有真正用于生产的层级上都提供了最优价值。
值得注意的是,OpenRouter 这一热门多模型 API 聚合器使用与 Google 官方类似的按 Token 定价结构——文本输入 $0.10/百万 Token,文本输出 $0.40/百万 Token,图像输出 Token 按 $60/百万 Token 收费(openrouter.ai,2026 年 2 月)。这意味着通过 OpenRouter 生成一张 4K 图像的成本约为 $0.15,几乎与 Google 官方价格相同。OpenRouter 的价值在于其多模型访问和统一 API,而非 Gemini 图像生成方面的成本节省。250 RPM 的速率限制可以很好地处理中等工作量,但无法从根本上解决高分辨率的成本问题。
在定价讨论中经常被忽略的一个因素是生成失败的成本。Google 官方 API 对所有输出 Token 收费,包括生成结果不理想需要重新生成的请求。如果你的工作流涉及生成多个候选图像并选择最佳的——这在创意应用中很常见——你的实际每张图像成本可能是标价的 2-3 倍。按成功生成次数而非按 Token 收费的第三方供应商在这些场景下可以提供更好的实际定价,不过各供应商的政策有所不同。在 laozhang.ai,每次 API 调用算作一次生成,无论输出是否满足你的质量标准,这提供了成本可预测性。
4K 成本问题(及解决方案)
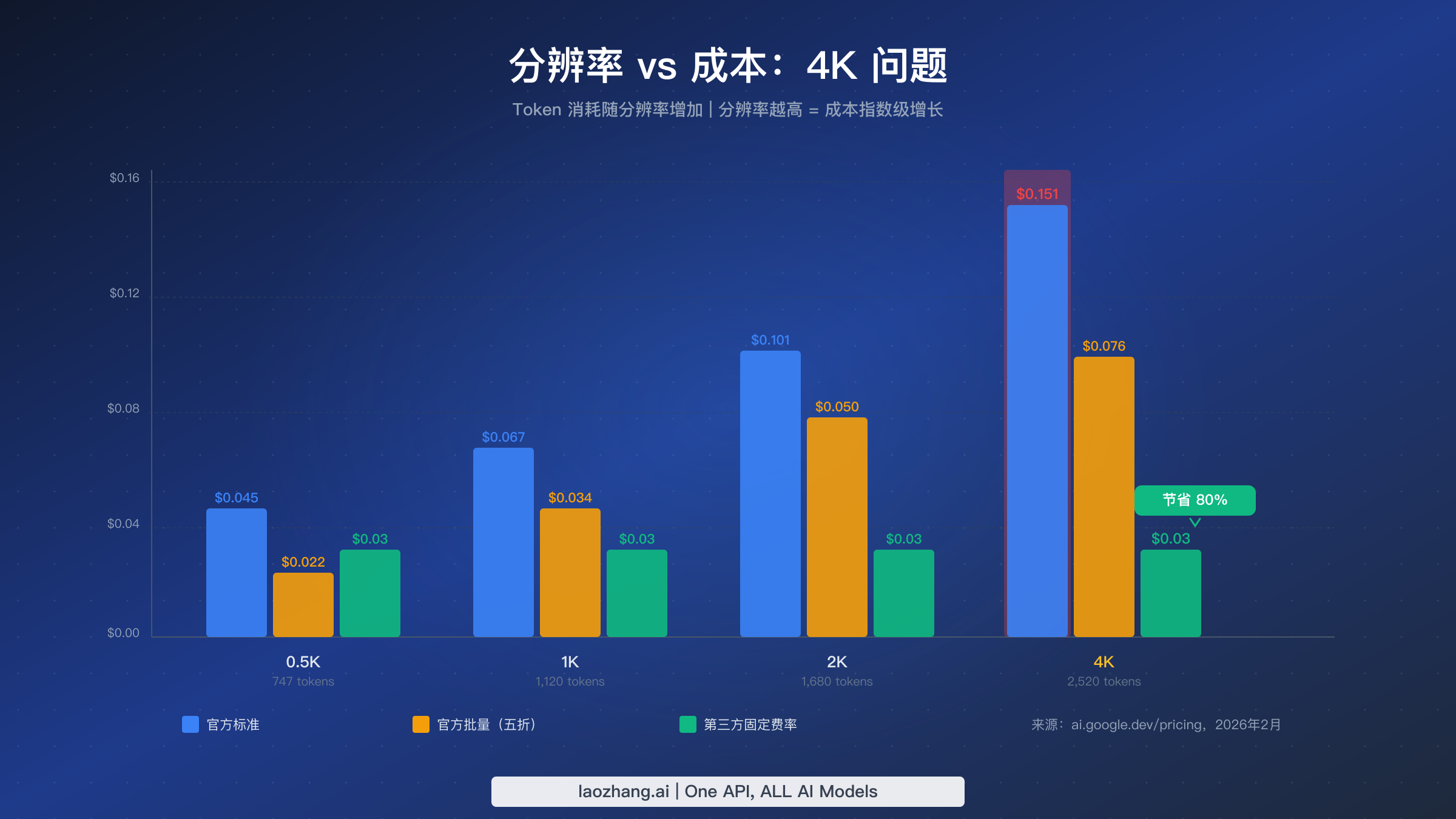
Google 基于 Token 定价中分辨率与成本之间的关系创造了我们所说的"4K 成本问题"。当分辨率翻倍时,Token 消耗并不是简单地翻倍——它以更陡峭的速率增长,因为图像数据随分辨率的平方而增长。一张 4K 图像消耗 2,520 个 Token,是一张 0.5K 图像 747 个 Token 的 3.4 倍,尽管线性尺寸只增加了 8 倍。这种指数级增长意味着需要高分辨率输出的开发者通过官方渠道面临不成比例的高成本。
来看一个实际场景:一个电商平台需要为高 DPI 显示屏生成 4K 分辨率的产品图片。通过官方标准 API 每天生成 1,000 张图片,日成本达到 $151。一个月下来,仅图像生成就要花费 $4,530。通过第三方供应商以 $0.03 每张的价格,同样的量级每天只需 $30,或每月 $900——每月差额达 $3,630。对于处理数万张图像的团队,这些节省等比例增长,可以占据基础设施成本的相当大份额。
有效解决 4K 成本问题主要有三种策略。第一种策略是对非时间敏感的工作负载使用 Google 的 Batch API。如果你的应用生成的是几小时延迟可以接受的营销材料、社交媒体内容或目录图像,Batch API 的 50% 折扣将 4K 成本降至每张 $0.076。这非常适合隔夜批处理,即在工作日结束时提交生成请求,次日早上获取结果。不过,Batch API 无法通过第三方供应商使用——它需要直接访问 Google 的 API。
第二种也是最具影响力的策略是将所有分辨率层级都切换到第三方供应商。以 $0.03 每张的固定费率,第三方方式完全消除了分辨率溢价。你的 4K 图像成本与 0.5K 图像完全相同。这种可预测的定价模式还简化了预算编制,消除了为控制成本而实现分辨率降级逻辑的需要。关于更多降低 Gemini 图像生成成本的策略,我们的 Gemini 图像 API 低价方案指南涵盖了更多优化技巧。
第三种策略是混合方案,将官方 API 用于低分辨率生成,第三方供应商用于高分辨率工作。因为在 0.5K 时成本差异相对较小(官方 $0.045 vs 第三方 $0.03),你可能更倾向于将官方 API 的直连用于缩略图和预览,同时将所有 1K 以上的生成路由到第三方供应商。这种混合模式让你维持与 Google API 的直接关系,同时获取大部分可用的节省。实际上,大多数团队发现通过单一第三方供应商路由一切的简便性超过了这种混合方案的边际收益,但对于有严格供应商要求的组织来说,这仍然是一个有效选项。
为了更直观地展示节省效果,以下是不同月度量级在各定价层级下的 4K 生成成本:
| 月度量 | 官方标准 | 官方批量 | 第三方($0.03) | 月度节省 |
|---|---|---|---|---|
| 1,000 张 | $151 | $76 | $30 | $121 (80%) |
| 5,000 张 | $755 | $380 | $150 | $605 (80%) |
| 10,000 张 | $1,510 | $760 | $300 | $1,210 (80%) |
| 50,000 张 | $7,550 | $3,800 | $1,500 | $6,050 (80%) |
在大规模使用时,节省的金额足以资助其他基础设施改进或增聘团队成员。一家每月生成 50,000 张 4K 图像的公司,仅仅通过从官方标准 API 切换到第三方供应商,每月就能节省超过 $6,000——年节省达 $72,000。即使与 Batch API 相比(需要接受异步处理),第三方选项仍能每月节省 $2,300,同时提供实时响应。
稳定性深度分析:"便宜"不等于"不稳定"

当开发者听到"第三方 API 供应商"时,他们的第一个顾虑通常是可靠性。毕竟,你在应用程序和 Google 基础设施之间增加了一个中间层。但 Gemini 3.1 Flash Image Preview 的稳定性现状比你想象的更加微妙——而且在几个重要方面,第三方供应商实际上可以提供比官方 API 更好的稳定性。
Google 官方 Gemini API 在高峰使用期间有大量记录在案的 503"过载"错误。这些错误源于 Google 对图像生成管道的容量管理,该管道在数百万 API 消费者之间共享资源。当需求激增时——例如新模型发布后或多个时区的工作时间重叠——API 会以 503 响应限流请求。Nano Banana 2 模型也不例外。使用过早期 Gemini 图像模型的开发者会立即认出这种模式。如果你自己也遇到过这些问题,我们关于修复 Gemini 503 过载错误的专门指南提供了详细的故障排除步骤和变通方案。
第三方供应商通过几个架构优势来解决这一稳定性挑战。首先,像 laozhang.ai 这样的成熟供应商维护着不与公众共享的专用容量池。你的请求不是与数百万免费层和按量付费用户竞争同一基础设施,而是通过供应商独立管理的预留容量进行路由。这种隔离显著降低了在高峰期遇到过载状况的可能性。
其次,成熟的第三方供应商实施了多区域路由和自动故障转移。当某个 Google Cloud 区域出现错误率上升时,供应商的负载均衡器会透明地将你的请求重定向到更健康的区域。你不需要自己实现这种故障转移逻辑——供应商在基础设施层面处理这一切。这种多区域方式特别有价值,因为 Google 的 503 错误通常是区域性而非全局性的,这意味着即使你的默认区域过载,其他地方仍有可用容量。
第三,优质的第三方供应商提供内置的重试逻辑和指数退避机制,在错误到达你的应用程序之前就会触发。如果一个生成请求在内部失败,供应商会自动重试(通常 2-3 次,延迟逐渐增加),然后才向你的客户端返回错误。这个透明的重试层吸收了瞬时故障,否则你需要自己实现重试逻辑来处理。
三个主要访问渠道的稳定性对比揭示了实践中的显著差异。Google 官方 API 提供无中间商的直接访问,这意味着在正常条件下延迟更低(生成通常需要 4-6 秒)。然而,它不提供针对 503 过载的内置保护,需要你自行实现重试逻辑。Nano Banana 2 的官方 API 没有免费额度,计费严格按使用量计算,默认没有支出上限。
OpenRouter 提供了一个折中方案,具有 250 RPM 速率限制和多供应商路由能力。它通过单个 API 密钥支持多种 AI 模型,对想要在不同供应商之间试验的开发者很有吸引力。不过,其定价遵循与 Google 官方 API 相同的按 Token 结构,所以并不能解决 4K 成本问题。
像 laozhang.ai 这样的第三方供应商通常为持续的生产工作负载提供最稳定的体验。凭借专用容量、自动故障转移和透明的重试逻辑,它们处理了开发者本来需要自己构建的基础设施复杂性。固定费率定价模式还消除了因更高分辨率按 Token 计费带来的账单惊喜。主要考虑因素是你将 API 流量委托给第三方——虽然信誉良好的供应商使用 OpenAI 兼容端点和标准 HTTPS 加密,但你应该根据自己的合规要求评估它们的数据处理实践。
在实际评估稳定性时,请考虑各供应商的以下关键指标。响应时间一致性比平均响应时间更重要——一个始终提供 5 秒响应的供应商比一个平均 4 秒但偶尔飙升到 30 秒或完全超时的供应商更有价值。高峰时段(通常是北美和欧洲时区的上午 9 点到下午 5 点)的错误率是另一个关键指标,因为许多应用在工作时间生成最多的图像。监控仪表板或状态页面的可用性也是供应商对透明度承诺的信号——你希望在用户注意到之前就了解故障情况。
对于构建关键业务应用的开发者,实施多供应商故障转移策略可以提供最高级别的可靠性。方法很简单:配置你的主要供应商(通常是最便宜的选项)和一个作为备份的次要供应商。如果主要供应商返回错误或超过你的超时阈值,自动通过次要供应商重试。因为两个供应商都使用 OpenAI 兼容端点,你的请求唯一的区别是基础 URL 和 API 密钥。这种模式增加的代码复杂度很小,同时保护了免受单一供应商故障的影响,成本影响也可以忽略不计,因为你只在主要供应商失败时才使用备用供应商。
快速集成指南:5 分钟上手
与第三方 Gemini 3.1 Flash Image Preview API 供应商集成非常简单,因为大多数供应商使用 OpenAI 兼容端点。如果你曾经使用过 OpenAI API,你已经知道请求格式了。唯一的区别是基础 URL、你的 API 密钥和模型名称。以下是使用 laozhang.ai 作为供应商的入门方法——同样的模式适用于任何 OpenAI 兼容端点。
Python(OpenAI SDK)
最快的图像生成入门方式是使用官方 OpenAI Python SDK。如果还没安装,先用 pip install openai 安装,然后使用以下代码:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ { "role": "user", "content": "Generate a photorealistic image of a golden retriever " "playing in autumn leaves, 4K resolution, warm lighting" } ], max_tokens=4096 ) print(response.choices[0].message.content)
这段代码发送一个文本提示并在响应消息中以 base64 编码数据的形式接收生成的图像。max_tokens 参数控制输出大小——更高的值允许更大(更高分辨率)的图像。要获取 4K 输出,请将其设置为至少 4096。
cURL(直接 API 调用)
对于快速测试或 Shell 脚本集成,直接使用 cURL 请求无需安装任何 SDK:
bashcurl -X POST https://api.laozhang.ai/v1/chat/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer your-laozhang-api-key" \ -d '{ "model": "gemini-3.1-flash-image-preview", "messages": [ { "role": "user", "content": "A minimalist logo design for a coffee shop called Sunrise Brew" } ], "max_tokens": 4096 }'
生产级错误处理
对于生产部署,使用适当的错误处理和重试逻辑包装你的 API 调用。虽然第三方供应商在内部处理了大多数瞬时错误,但你的应用程序仍然应该优雅地处理网络超时和速率限制:
pythonimport time from openai import OpenAI, APIError, RateLimitError client = OpenAI( api_key="your-laozhang-api-key", base_url="https://api.laozhang.ai/v1" ) def generate_image(prompt, max_retries=3): for attempt in range(max_retries): try: response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[{"role": "user", "content": prompt}], max_tokens=4096, timeout=30 ) return response.choices[0].message.content except RateLimitError: wait_time = 2 ** attempt time.sleep(wait_time) except APIError as e: if attempt == max_retries - 1: raise time.sleep(1) raise Exception("Max retries exceeded")
要获取你的 API 密钥并查阅完整文档,请访问 docs.laozhang.ai。你也可以在 images.laozhang.ai 上交互式测试图像生成,然后再进行任何集成工作。
对话式图像编辑
Nano Banana 2 最强大的功能之一是对话式图像编辑——你可以将之前生成的图像连同修改指令一起发送回模型。这通过多轮对话格式实现:
python# First turn: generate the initial image response1 = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ {"role": "user", "content": "A modern office workspace with a standing desk"} ], max_tokens=4096 ) # Second turn: edit the image response2 = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[ {"role": "user", "content": "A modern office workspace with a standing desk"}, {"role": "assistant", "content": response1.choices[0].message.content}, {"role": "user", "content": "Add a large window with a city view behind the desk"} ], max_tokens=4096 )
每次编辑都算作一次独立的 API 调用,因此如果你的工作流涉及迭代优化,请将此纳入成本计算。通过第三方供应商每次调用 $0.03,即使是五轮编辑会话也只需 $0.15——仍然低于通过官方标准 API 生成一张 4K 图像的费用。这使得对话式编辑在受益于迭代改进的创意工作流中在经济上变得可行。
Nano Banana 2 与 GPT Image 1 和 Imagen 4 的对比
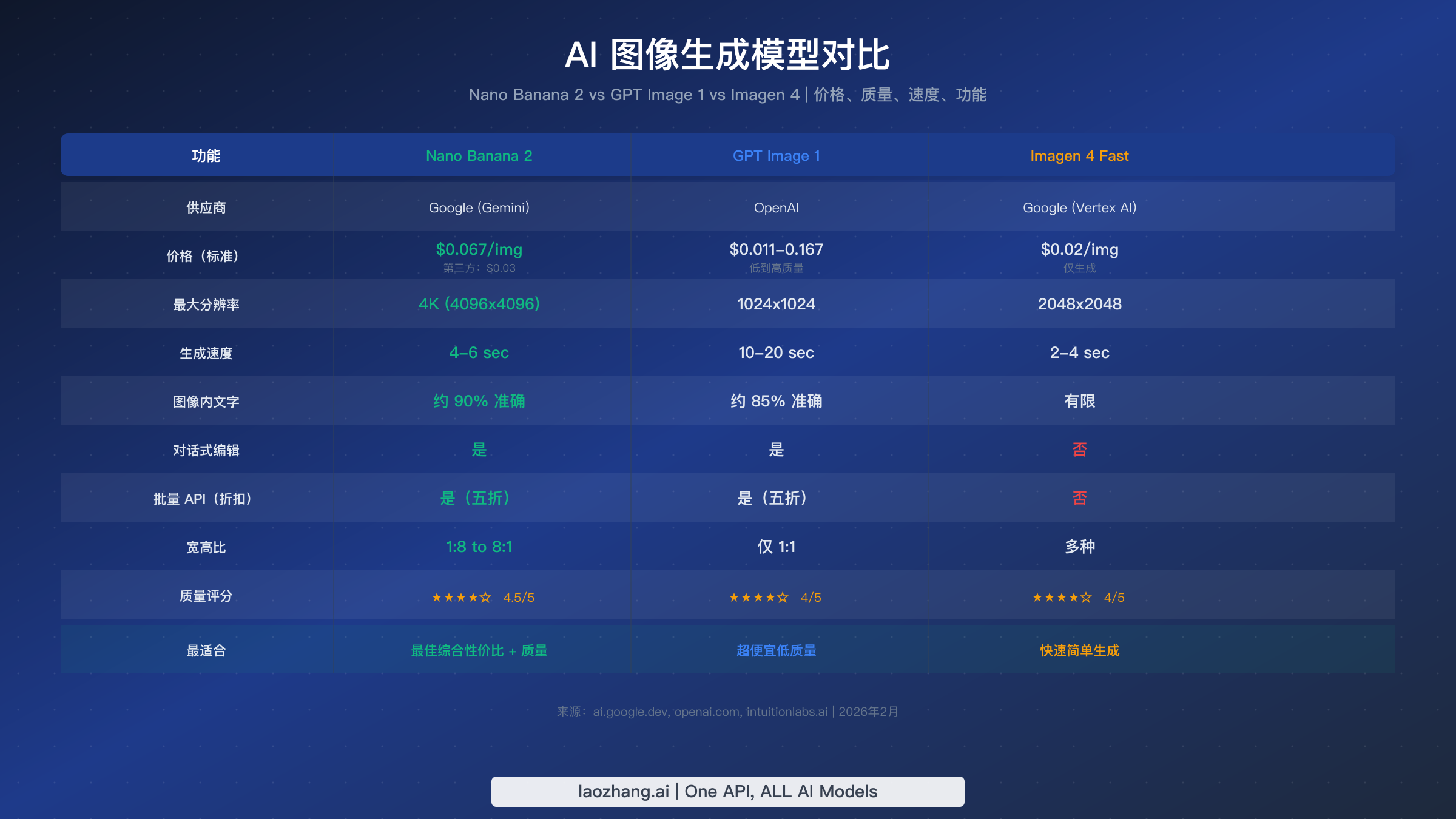
选择 AI 图像生成模型不仅仅是价格问题——质量、速度、功能和生态系统兼容性都是决策因素。Nano Banana 2(Gemini 3.1 Flash Image Preview)与 OpenAI 的 GPT Image 1 和 Google 自家的 Imagen 4 直接竞争,每个都有各自独特的优势。想要了解更广泛的对比,包括 DALL-E 3、Midjourney 和 Stable Diffusion 等模型,请查看我们的 2026 年 AI 图像生成 API 对比。
Nano Banana 2 以最宽的分辨率范围脱颖而出——最高可达 4K(4096x4096)——以及最灵活的宽高比支持,从 1:8 到 8:1。其文字渲染准确率约为 90%,是本文对比的三个模型中最高的,这对于社交媒体图形、信息图表或任何包含可读文字的图像应用来说非常重要。该模型还支持对话式编辑,意味着你可以通过多轮对话迭代优化图像,而不是每次都从头生成。在官方标准定价下,1K 图像每张 $0.067 处于中等水平,但通过第三方以 $0.03 访问使其成为大多数用例中最具性价比的选项。
OpenAI 的 GPT Image 1 提供最宽的价格区间,从低质量每张 $0.011 到高质量 $0.167。低质量层级使其成为图像保真度不太关键的应用的最便宜选项——想想占位图像、快速原型设计或内部工具。然而,GPT Image 1 分辨率限制为 1024x1024,仅支持 1:1 宽高比,这限制了其在许多生产场景中的实用性。10-20 秒的生成速度明显慢于两个 Google 替代方案。与 Nano Banana 2 一样,它支持对话式编辑和 50% 折扣的 Batch API。
Imagen 4 Fast 通过 Google 的 Vertex AI 提供,是速度冠军,每张图像 2-4 秒,定价为每张 $0.02(ai.google.dev,2026 年 2 月)。它支持最高 2048x2048 的分辨率和多种宽高比。然而,Imagen 4 是一个纯图像生成模型——它不支持对话式编辑,这意味着每次修改都需要全新生成。它也没有 Batch API 支持,与 Nano Banana 2 相比文字渲染能力更有限。Imagen 4 最适合需要快速、简单图像生成而无需迭代优化的应用。
另一个值得考虑的维度是生态系统成熟度。Nano Banana 2 受益于 Google 快速扩展的 Gemini 生态系统,这意味着持续的模型改进、最近新增的极端宽高比(1:8、8:1)等新功能,以及与其他 Google Cloud 服务的集成。GPT Image 1 位于 OpenAI 成熟的生态系统中,与 DALL-E 工作流和 ChatGPT 集成无缝兼容。Imagen 4 虽然在纯生成方面很强大,但主要在 Google Cloud Vertex AI 环境中运行,社区较小,第三方集成也较少。
对于大多数开发者来说,最终结论是:通过第三方供应商以 $0.03 每张使用 Nano Banana 2 提供了最佳综合价值。你获得了最高的分辨率上限、最好的文字渲染、对话式编辑支持和具有竞争力的生成速度——所有这些的价格在考虑分辨率优势后甚至低于 Imagen 4 已经很实惠的 $0.02。GPT Image 1 的低质量层级 $0.011 仍然是最便宜的绝对选项,但分辨率和质量的权衡使其仅适用于视觉保真度次于成本的特定用例。
哪个供应商适合你?场景化选择指南
与其给出一刀切的建议,不如根据你的具体使用模式来选择正确的供应商。以下是最常见的场景及对应的最优供应商选择。
低用量,标准分辨率(每天不到 100 张,1K 或以下)。 对于业余项目、原型开发或内部工具等生成少量图像的场景,Google 官方 API 是一个合理的选择。以 1K 图像每张 $0.067 的价格,你的日成本不超过 $7。你获得无中间商的直接访问、最简单的设置,并避免了建立第三方账户的额外开销。在低用量时 Batch API 不太可能有帮助,因为批处理作业的设置开销超过了 50% 的节省。
中等用量,混合分辨率(每天 100-1,000 张)。 这是第三方供应商开始提供显著价值的地方。以每天 500 张平均 2K 分辨率的图像为例,官方 API 成本约为每天 $50.50($0.101 x 500)。第三方供应商以 $0.03 每张的价格将其降至每天 $15——每天节省 $35.50,每月超过 $1,000。固定费率定价还消除了优化分辨率设置以控制成本的需要,简化了你的应用逻辑。这个场景涵盖了大多数中小型 SaaS 应用、内容平台和营销团队。
高用量,4K 分辨率(每天 1,000 张以上,最高质量)。 这个场景代表了第三方供应商最强有力的使用案例。以每天 2,000 张 4K 分辨率图像为例,官方 API 收取每天 $302($0.151 x 2,000)。即使使用 Batch API 打五折,你仍然每天支付 $152。第三方供应商只需每天 $60($0.03 x 2,000)——比标准定价每天节省 $242,每月超过 $7,000。对于电商平台、按需印刷服务或任何需要大规模高分辨率输出的应用,第三方供应商是明确的选择。
无时间敏感性的批处理(隔夜批量作业可接受)。 如果你的工作流允许异步处理——生成大量图像集并在数小时后提取——Google 官方 Batch API 提供 50% 折扣,在不需要第三方关系的情况下提供强大的价值。以批量模式每张 4K 图像 $0.076 的价格,你获得官方 Google 基础设施和有保障的处理。这非常适合目录生成、数据集创建和营销活动准备,这些场景中图像在早上之前需要但不需要实时交付。
有合规要求的企业。 有严格数据处理政策的组织可能出于合规原因需要使用 Google 官方 API,即使成本更高。官方 API 将请求直接路由到 Google 基础设施,遵循 Google 的数据处理条款。如果你的合规框架允许,具有透明数据处理实践的信誉良好的第三方供应商(例如 laozhang.ai,使用标准 HTTPS 加密和 OpenAI 兼容端点)仍然可以满足大多数安全要求,同时提供显著的成本节省。你可以在 images.laozhang.ai 上测试他们的服务,然后再做出承诺。
多模型工作流(使用多种 AI 图像模型)。 如果你的应用需要根据任务在 Nano Banana 2、GPT Image 1 和其他模型之间路由,有两个选择。OpenRouter 通过单个 API 密钥提供按 Token 定价的多模型访问。或者,像 laozhang.ai 这样通过 OpenAI 兼容端点支持多种模型的第三方聚合器,以更低的每张图像成本提供同样的多模型灵活性。选择取决于你更看重定价(第三方聚合器)还是最广泛的模型选择(OpenRouter)。
对于大多数开发者和团队,建议很简单:从第三方供应商开始,因为它综合了最低成本、固定费率定价、内置稳定性功能和简单集成。将官方 API 保留给特定的合规场景或用量极低的原型开发,在这些情况下单一 Google 账户的便利性超过了成本差异。以下决策矩阵总结了每个场景的最优选择:
| 场景 | 用量 | 分辨率 | 最佳供应商 | 估算月费 |
|---|---|---|---|---|
| 业余/原型 | < 100/天 | 1K | 官方 API | < $200 |
| 小型 SaaS | 100-500/天 | 混合 | 第三方 | $90-$450 |
| 内容平台 | 500-2,000/天 | 2K-4K | 第三方 | $450-$1,800 |
| 电商 | 2,000+/天 | 4K | 第三方 | $1,800+ |
| 批量处理 | 5,000+/批 | 任意 | Batch API 或第三方 | 视情况 |
| 企业合规 | 任意 | 任意 | 官方 API | 较高 |
常见问题
Gemini 3.1 Flash Image Preview API 每张图像多少钱?
Google 官方 Nano Banana 2(gemini-3.1-flash-image-preview)的标准定价从 0.5K 分辨率的 $0.045 到 4K 分辨率的 $0.151 不等(ai.google.dev,2026 年 2 月)。成本随输出 Token 消耗增加——更高的分辨率产生更多 Token,成本更高。Batch API 提供 50% 折扣,将 4K 价格降至 $0.076。像 laozhang.ai 这样的第三方供应商提供每张 $0.03 的固定费率,不区分分辨率,是 0.5K 以上所有输出的最便宜选项。
Gemini 3.1 Flash Image Preview API 是否免费?
不是。与其他一些 Gemini 模型不同,Nano Banana 2 图像生成模型没有免费额度(ai.google.dev,2026 年 2 月)。每张生成的图像都会根据消耗的输出 Token 产生费用。官方最便宜的选项是 0.5K 分辨率的 Batch API,每张 $0.022。如果你需要最低的成本门槛,第三方供应商以 $0.03 每张且无最低消费承诺提供了最接近低门槛入口的选择。
Gemini Flash Image API 的响应时间是多少?
Gemini 3.1 Flash Image Preview API 通过官方和第三方渠道通常在 4-6 秒内生成图像。这个速度在各分辨率间保持一致——4K 图像不会比 1K 图像明显慢。作为对比,GPT Image 1 需要 10-20 秒,而 Imagen 4 Fast 在 2-4 秒内生成。Batch API 以异步方式处理图像,完成时间不固定,通常根据队列深度在几分钟到几小时内返回结果。
我可以用 OpenAI SDK 使用 Gemini 图像 API 吗?
可以,通过提供 OpenAI 兼容端点的第三方供应商。像 laozhang.ai 这样的服务接受与 OpenAI Chat Completions API 完全相同格式的请求。你只需在 OpenAI 客户端配置中更改 base_url 和 api_key,将模型设置为 gemini-3.1-flash-image-preview,你现有的代码无需修改即可运行。Google 的官方 API 使用不同的请求格式(Gemini API 格式),需要单独的集成代码。
Nano Banana 2 支持的最大分辨率是多少?
Nano Banana 2 支持最高 4K(4096x4096 像素)的输出分辨率,是目前通过 API 提供的 AI 图像生成模型中最高的(ai.google.dev,2026 年 2 月)。它支持从 1:8 到 8:1 的宽高比,为不同的输出格式提供了极大的灵活性——从竖版手机壁纸到超宽横幅图像。分辨率通过 API 请求中的 max_tokens 参数控制,更高的 Token 限制产生更高分辨率的输出。作为对比,GPT Image 1 最高 1024x1024,Imagen 4 支持到 2048x2048。
Nano Banana 2 有哪些其他模型没有的功能?
Nano Banana 2(Gemini 3.1 Flash Image Preview)支持几个使其脱颖而出的功能。对话式图像编辑允许你通过多轮对话迭代优化生成的图像,无需每次修改都从头重新生成。该模型支持搜索接地和思考模式,用于更具上下文感知的生成。它还提供 50% 成本折扣的 Batch API 用于异步处理。该模型支持从 1:8 到 8:1 的宽高比——远超 GPT Image 1 固定的 1:1 比例。不过,它不支持缓存、函数调用或 Live API(ai.google.dev,2026 年 2 月)。对于信息图表或社交媒体图形等文字密集型图像,其约 90% 的文字渲染准确率明显优于竞争模型,使其成为图像中可读文字至关重要的应用的首选。