Gemini API Key: Complete Guide to Google’s AI API in 2025
A Gemini API key is your authentication credential for accessing Google’s advanced AI models through the Gemini API. In 2025, Google offers free access with 1,500 daily requests and paid tiers supporting up to 2,000 requests per minute, making it accessible for both experimentation and production use.

How to Get Your Gemini API Key in 2025
Obtaining a Gemini API key has become remarkably streamlined in 2025, with Google AI Studio providing the fastest path to getting started. The process takes less than two minutes for developers who already have a Google account, and the free tier immediately grants access to powerful AI capabilities without requiring credit card information. This accessibility has made Gemini API adoption surge among developers seeking alternatives to more expensive AI services.
The quickest method involves navigating to Google AI Studio at ai.google.dev and clicking the “Get API key” button in the left sidebar. Upon first access, you’ll be prompted to create a new project or select an existing Google Cloud project. For beginners, creating a new project specifically for Gemini API experimentation is recommended, as it provides clean separation from other Google Cloud resources and simplifies billing tracking if you later upgrade to paid tiers.
Free tier access includes generous limits that accommodate most development and small-scale production needs. With 1,500 requests per day for Gemini 1.5 Flash and additional quotas for other models, developers can thoroughly test applications before committing to paid plans. The free tier supports all core features including multimodal inputs, function calling, and the latest Gemini 2.5 model capabilities, making it genuinely useful for production applications with moderate traffic.
Common setup mistakes often stem from confusion between Google AI Studio and Vertex AI paths. While both provide access to Gemini models, Google AI Studio offers simpler setup and immediate access, whereas Vertex AI requires more complex configuration but provides enterprise features like VPC service controls and advanced monitoring. New developers should start with Google AI Studio and migrate to Vertex AI only when enterprise requirements demand it.
Key generation best practices extend beyond the initial creation process. Always generate separate keys for development, staging, and production environments to prevent accidental usage of production quotas during testing. Name your keys descriptively in the Google Cloud Console to identify their purpose at a glance – for example, “gemini-prod-webapp” or “gemini-dev-testing”. Enable key restrictions to limit usage to specific IP addresses or referrer URLs, adding an extra security layer. Regular key audits should verify that all active keys are still needed and properly secured, revoking any that are obsolete or potentially compromised.
Understanding Gemini API Key Authentication
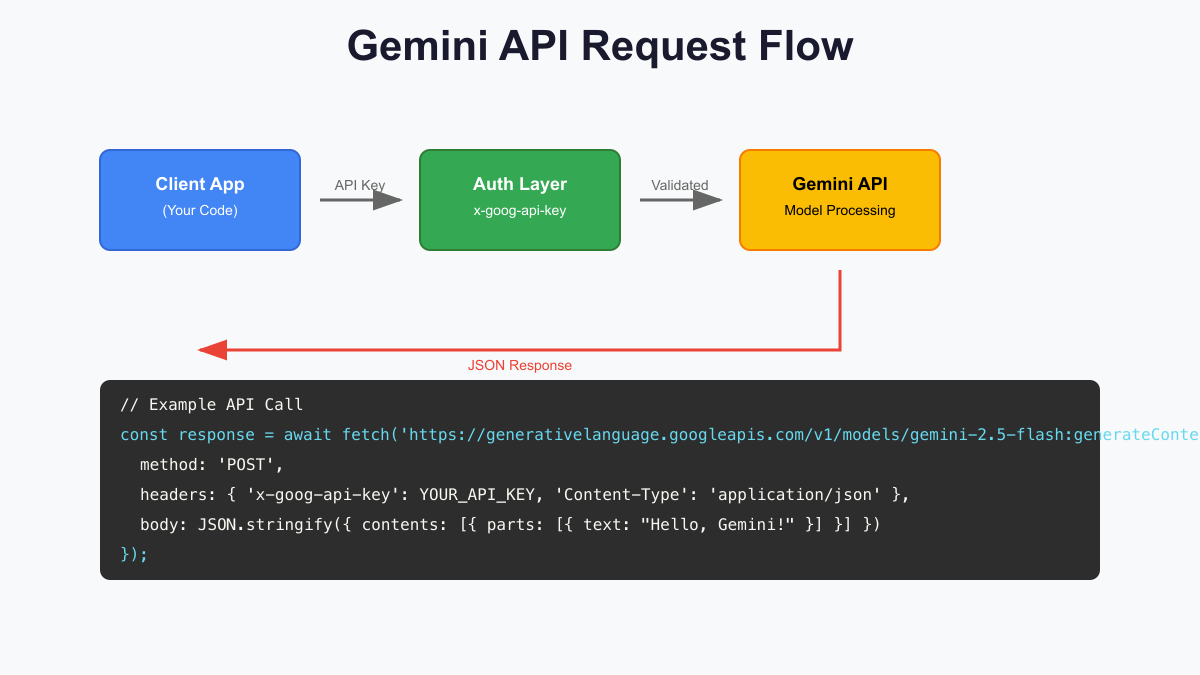
Gemini API authentication relies on a bearer token mechanism where your API key serves as both identification and authorization. Unlike some competing APIs that require complex OAuth flows or multiple credentials, Gemini’s single-key approach simplifies integration while maintaining security through proper implementation practices. The key must be included with every API request, acting as your application’s identity when communicating with Google’s servers.
The correct authentication method uses the x-goog-api-key HTTP header, not URL parameters or request body inclusion. This header-based approach prevents accidental key exposure in server logs, browser history, or debugging tools. When making requests, the header format follows standard HTTP conventions: “x-goog-api-key: YOUR_API_KEY”. This standardization ensures compatibility across different HTTP clients and programming languages while maintaining security best practices.
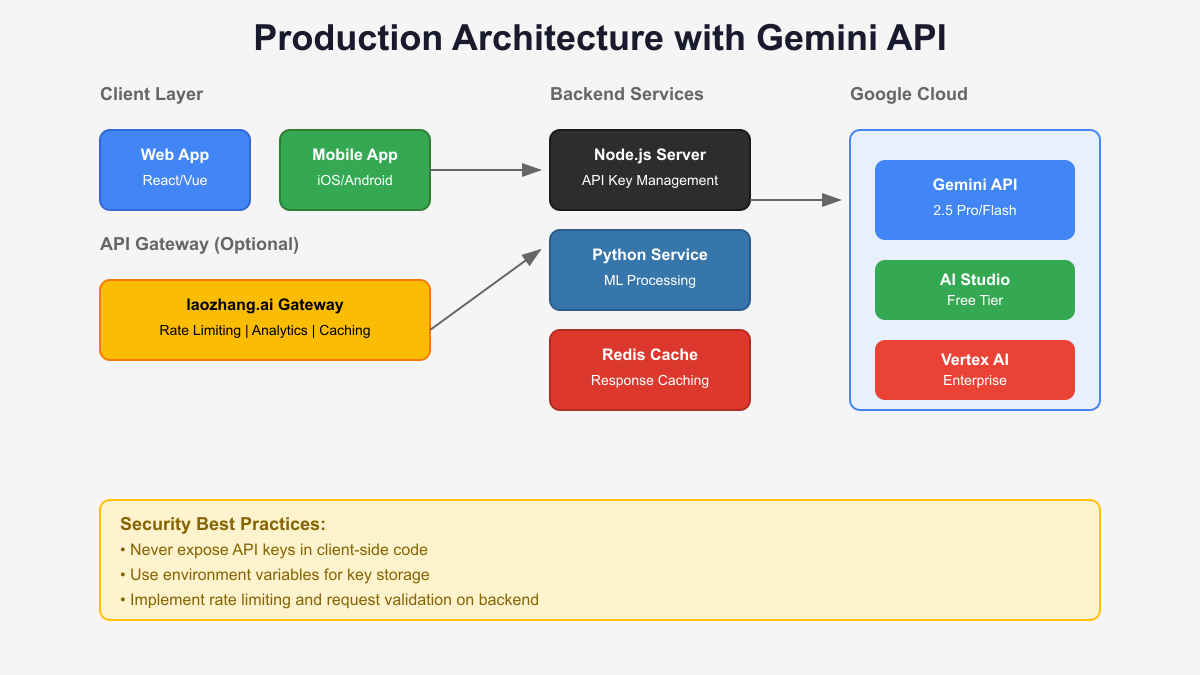
Security considerations extend beyond basic key transmission. Production applications should never embed API keys directly in client-side code, as browser developer tools or mobile app decompilation easily expose them. Instead, implement a backend proxy that stores keys securely and forwards requests to Gemini API. This architecture not only protects your credentials but also enables additional features like request logging, rate limiting, and usage analytics through services like laozhang.ai’s API gateway.
Environment variable configuration represents the standard approach for key management in modern applications. Store your key as GEMINI_API_KEY in environment variables, then reference it in your application code. This pattern works across deployment platforms from local development to cloud services, supports easy key rotation, and prevents accidental commits of sensitive credentials to version control systems.
Gemini API Key Pricing and Cost Optimization
Understanding Gemini API pricing structures enables significant cost savings while maintaining application performance. The 2025 pricing model offers compelling advantages over competitors, with Gemini 2.5 Flash costing only $0.35 per million input tokens compared to GPT-4o’s $2.50, representing an 86% cost reduction for comparable capabilities. This dramatic price difference makes previously cost-prohibitive AI applications suddenly viable for businesses of all sizes.
Free tier limitations provide substantial value for development and low-traffic applications. The daily quota of 1,500 requests for Gemini 1.5 Flash, combined with smaller quotas for Pro models, supports applications serving hundreds of users without incurring costs. Smart quota management, such as implementing user-level rate limiting and caching common responses, can extend free tier coverage to support even moderately popular applications.
Pay-as-you-go pricing scales linearly with usage, but several optimization strategies can reduce costs by 50-80%. Batch processing stands out as the most impactful optimization, offering 50% discounts for non-time-sensitive requests. By accumulating user requests throughout the day and processing them in evening batches, applications can halve their API costs while maintaining acceptable response times for many use cases.
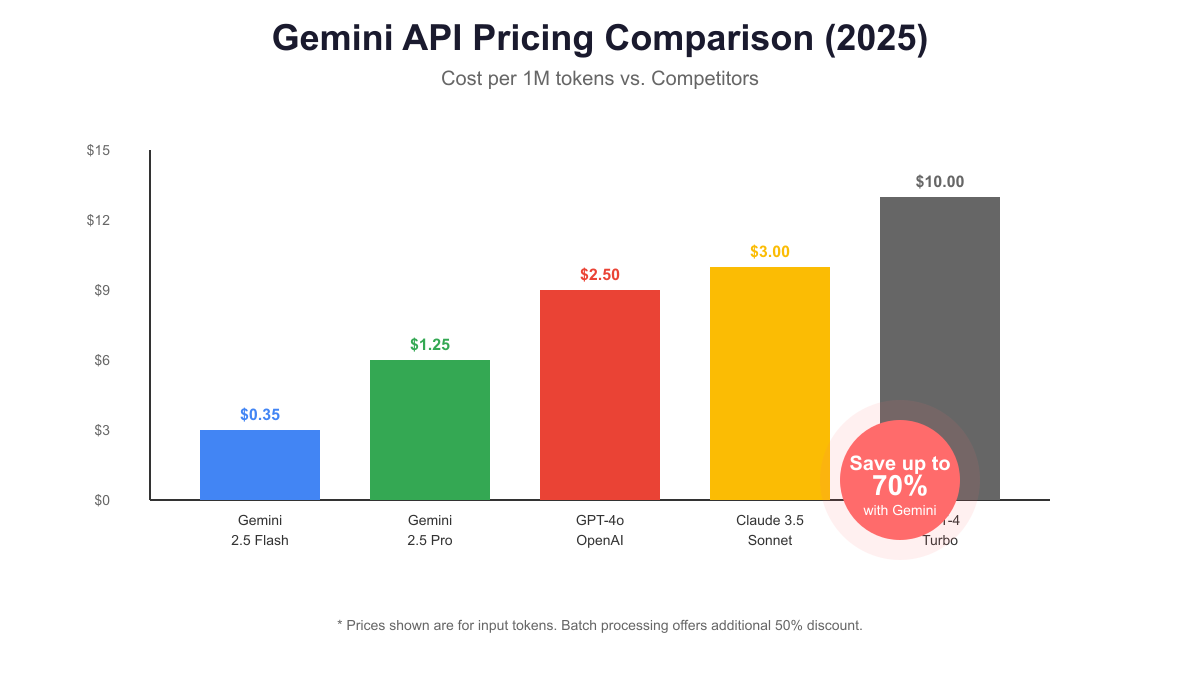
Cost comparison with major competitors reveals Gemini’s strategic pricing advantage. While GPT-4 Turbo costs $10 per million tokens and Claude 3.5 Sonnet charges $3, Gemini 2.5 Pro at $1.25 provides superior performance at a fraction of the cost. For high-volume applications, these differences translate to thousands of dollars in monthly savings. Integration with API gateways like laozhang.ai can further optimize costs through intelligent caching and request routing between different model tiers based on query complexity.
Setting Up Your First Gemini API Key Request
Making your first successful API request marks a crucial milestone in Gemini API integration. The process involves constructing properly formatted HTTP requests with correct headers, payload structure, and endpoint URLs. Modern SDKs simplify this process, but understanding the underlying HTTP mechanics ensures you can debug issues and optimize performance when needed.
Python implementation using the official google-genai library provides the cleanest integration path. After installing the library with pip install google-genai, a minimal working example demonstrates the API’s simplicity. The SDK handles authentication, request formatting, and response parsing automatically, allowing developers to focus on application logic rather than API mechanics.
import google.generativeai as genai
import os
# Configure with your API key
genai.configure(api_key=os.environ['GEMINI_API_KEY'])
# Initialize the model
model = genai.GenerativeModel('gemini-2.5-flash')
# Generate content
response = model.generate_content("Explain quantum computing in simple terms")
print(response.text)
# Handle streaming responses for better UX
for chunk in model.generate_content("Write a story about AI", stream=True):
print(chunk.text, end='')
JavaScript developers benefit from similar simplicity with the @google/genai package. The Node.js implementation supports both CommonJS and ES modules, integrating seamlessly with modern JavaScript frameworks. Async/await syntax makes the code readable while maintaining non-blocking execution essential for web applications.
import { GoogleGenerativeAI } from '@google/genai';
// Initialize with API key
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
const model = genAI.getGenerativeModel({ model: 'gemini-2.5-flash' });
// Generate content with error handling
async function generateContent(prompt) {
try {
const result = await model.generateContent(prompt);
return result.response.text();
} catch (error) {
console.error('API Error:', error);
throw error;
}
}
// Stream responses for real-time display
async function streamContent(prompt) {
const result = await model.generateContentStream(prompt);
for await (const chunk of result.stream) {
process.stdout.write(chunk.text());
}
}
Testing with curl commands provides valuable debugging capabilities and helps understand the raw API interface. Direct HTTP requests reveal exactly what data transmits between your application and Google’s servers, making troubleshooting more straightforward when SDKs behave unexpectedly.
# Basic API test with curl
curl -X POST 'https://generativelanguage.googleapis.com/v1/models/gemini-2.5-flash:generateContent' \
-H 'Content-Type: application/json' \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-d '{
"contents": [{
"parts": [{
"text": "What is the meaning of life?"
}]
}]
}'
Gemini API Key Rate Limits and Quotas
Rate limiting represents a critical consideration for production Gemini API deployments, with dramatically different limits between free and paid tiers. Free tier users face strict constraints of 2 requests per minute for Pro models and 15 RPM for Flash models, necessitating careful request management to avoid service disruptions. These limits reset on a rolling basis, meaning applications must implement sophisticated queuing mechanisms to smooth traffic spikes.
Paid tier capabilities transform the API into a production-ready service supporting up to 2,000 requests per minute. This 100x increase over free tier limits enables real-time applications serving thousands of concurrent users. However, reaching these theoretical limits requires proper architecture, as network latency, response generation time, and client-side processing create practical bottlenecks below maximum RPM values.
Quota management strategies separate successful from failing applications. Implementing exponential backoff for rate limit errors prevents cascade failures while maintaining maximum throughput. A well-designed retry mechanism waits 1 second after the first failure, 2 seconds after the second, and continues doubling up to a maximum delay, ensuring eventual request success without overwhelming the API.
Monitoring usage patterns through comprehensive logging enables proactive quota management. Track metrics including requests per minute, daily usage trends, and per-user consumption to identify optimization opportunities. Services like laozhang.ai provide built-in analytics for API usage, making it easier to visualize patterns and set up alerts before hitting limits. This visibility proves invaluable for capacity planning and cost optimization.
Production Security for Gemini API Keys
Securing Gemini API keys in production environments demands multiple layers of protection beyond basic HTTPS transmission. The financial and reputational risks of exposed keys – from unexpected bills to data breaches – make security architecture a primary concern rather than an afterthought. Modern security practices have evolved to address sophisticated attack vectors while maintaining developer productivity.
Server-side proxy patterns provide the gold standard for API key protection. By routing all Gemini API requests through your backend servers, client applications never possess or transmit API keys. This architecture enables centralized security controls, request validation, and usage monitoring. Implementation typically involves creating dedicated API endpoints that accept user requests, validate permissions, add authentication headers, and forward sanitized requests to Gemini.
// Secure backend proxy example (Node.js/Express)
app.post('/api/gemini/generate', authenticate, async (req, res) => {
// Validate user permissions
if (!req.user.canUseAI) {
return res.status(403).json({ error: 'Insufficient permissions' });
}
// Sanitize and validate input
const prompt = sanitizeInput(req.body.prompt);
if (!isValidPrompt(prompt)) {
return res.status(400).json({ error: 'Invalid prompt' });
}
// Add user context for logging
const requestId = generateRequestId();
logAPIUsage(req.user.id, requestId, prompt);
// Forward to Gemini with server-side key
try {
const response = await model.generateContent(prompt);
res.json({
text: response.text,
requestId: requestId
});
} catch (error) {
handleAPIError(error, res);
}
});
Key rotation strategies minimize damage from potential compromises. Implement quarterly key rotation as a baseline, with automated processes to update keys across all environments simultaneously. Store multiple valid keys during transition periods to ensure zero-downtime rotation. Version control systems should never contain actual keys; instead, use references to secure storage systems that development, staging, and production environments can access appropriately.
Access control implementation extends beyond simple authentication to include role-based permissions, IP allowlisting, and temporal restrictions. Production keys should only be accessible to deployment systems and senior engineers, with all access logged for audit purposes. Implement break-glass procedures for emergency access while maintaining security oversight. Regular security audits should verify that key access patterns match expected usage and that former team members no longer retain access.
Troubleshooting Common Gemini API Key Issues
API key validation problems frequently plague new Gemini implementations, often manifesting as cryptic error messages that don’t immediately indicate the root cause. The absence of a dedicated validation endpoint means developers must infer key validity from API responses, making systematic troubleshooting essential. Understanding common failure patterns accelerates resolution and prevents extended downtime.
The “API key not valid” error typically indicates formatting issues rather than invalid credentials. Verify that your key starts with “AIza” and contains exactly 39 characters. Check for accidental whitespace, especially when copying from web interfaces or loading from configuration files. Environment variable expansion problems often introduce subtle issues – echo your key to confirm it loads correctly, being careful to do this only in secure environments.
Quota exceeded (429) errors require different strategies based on tier and usage patterns. Free tier users hitting limits must implement request queuing and user-level rate limiting. A simple in-memory queue with timestamp tracking can smooth traffic spikes:
from collections import deque
from time import time, sleep
import threading
class RateLimiter:
def __init__(self, requests_per_minute):
self.rpm = requests_per_minute
self.requests = deque()
self.lock = threading.Lock()
def wait_if_needed(self):
with self.lock:
now = time()
# Remove requests older than 1 minute
while self.requests and self.requests[0] < now - 60:
self.requests.popleft()
if len(self.requests) >= self.rpm:
# Calculate wait time
wait_time = 60 - (now - self.requests[0]) + 0.1
sleep(wait_time)
return self.wait_if_needed()
self.requests.append(now)
# Usage with Gemini API
limiter = RateLimiter(15) # Free tier Flash limit
def generate_content_with_limit(prompt):
limiter.wait_if_needed()
return model.generate_content(prompt)
Authentication failures in different environments often stem from environment-specific configuration issues. Development environments might use different key formats or have proxy settings that interfere with API requests. Container deployments frequently fail when environment variables don’t properly propagate through orchestration layers. Systematically verify configuration at each layer: local environment, container runtime, orchestration platform, and cloud provider settings.
Environment-specific solutions require understanding platform quirks. React applications need REACT_APP_ prefixes for environment variables, while Next.js uses NEXT_PUBLIC_ for client-side access. Docker containers must explicitly pass environment variables or use .env files with proper security. Kubernetes deployments should use Secrets for key storage, mounted as environment variables in pod specifications. Each platform’s documentation contains critical details often overlooked during initial implementation.
Advanced Gemini API Key Features
Multimodal capabilities distinguish Gemini from traditional text-only APIs, enabling applications to process images, audio, and video alongside text in unified requests. This functionality opens entirely new application categories, from automated video analysis to real-time visual question answering. The unified API design means your existing API key instantly grants access to these advanced features without additional configuration or costs.
Function calling transforms Gemini from a passive response generator into an active agent capable of interacting with external systems. By defining available functions in your API requests, Gemini can determine when to call them and generate appropriate parameters. This enables building sophisticated automation systems where AI orchestrates complex workflows:
# Define available functions
functions = [
{
"name": "search_database",
"description": "Search product database for items",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"category": {"type": "string"},
"max_price": {"type": "number"}
},
"required": ["query"]
}
},
{
"name": "process_order",
"description": "Process a customer order",
"parameters": {
"type": "object",
"properties": {
"product_id": {"type": "string"},
"quantity": {"type": "integer"}
},
"required": ["product_id", "quantity"]
}
}
]
# Configure model with functions
model = genai.GenerativeModel(
'gemini-2.5-pro',
tools=functions
)
# Gemini will determine which function to call
response = model.generate_content(
"Find me a laptop under $1000 and order 2 units"
)
Grounding with Google Search enhances response accuracy by incorporating real-time information. When enabled, Gemini automatically searches for relevant data to verify or supplement its responses. This feature proves invaluable for applications requiring current information like news summarization, market analysis, or technical documentation that updates frequently. The API only charges for searches that successfully enhance responses, making it cost-effective for accuracy-critical applications.
Code execution capabilities allow Gemini to write and run Python code within sandboxed environments, enabling complex calculations and data analysis without external infrastructure. This feature supports data science workflows where Gemini can load datasets, perform analysis, and generate visualizations. The sandboxed environment includes common libraries like NumPy and Pandas, making it immediately useful for analytical applications.
Gemini API Key Integration Patterns
React and Next.js integration requires careful consideration of client-server boundaries to maintain security while providing responsive user experiences. The recommended pattern involves creating API routes that handle Gemini communication server-side while exposing clean interfaces to React components. This architecture prevents API key exposure while enabling real-time features through WebSocket connections or Server-Sent Events.
Modern React applications benefit from custom hooks that abstract API complexity while providing reactive state management. A well-designed useGemini hook handles loading states, error conditions, and response streaming while maintaining clean component code:
// Custom React hook for Gemini API
import { useState, useCallback } from 'react';
export function useGemini() {
const [loading, setLoading] = useState(false);
const [error, setError] = useState(null);
const [streamedResponse, setStreamedResponse] = useState('');
const generateContent = useCallback(async (prompt, options = {}) => {
setLoading(true);
setError(null);
setStreamedResponse('');
try {
const response = await fetch('/api/gemini/generate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prompt, ...options })
});
if (!response.ok) throw new Error('API request failed');
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
setStreamedResponse(prev => prev + chunk);
}
} catch (err) {
setError(err.message);
} finally {
setLoading(false);
}
}, []);
return { generateContent, loading, error, response: streamedResponse };
}
Node.js backend setup leverages JavaScript’s async capabilities for efficient API communication. Implementing connection pooling, request queuing, and circuit breakers ensures reliability under load. The event-driven architecture of Node.js particularly suits streaming responses, enabling real-time AI features without blocking server threads.
Python async implementation using FastAPI or Sanic provides high-performance API integration suitable for machine learning pipelines. The async/await syntax maintains readable code while handling thousands of concurrent requests. Integration with existing data science workflows becomes straightforward when using familiar Python libraries.
API gateway benefits extend beyond basic request routing to include sophisticated features like automatic failover, usage analytics, and cost allocation. Services like laozhang.ai specialize in AI API management, providing unified interfaces for multiple providers including Gemini. This abstraction layer simplifies multi-model deployments where different queries route to optimal models based on cost, latency, or capability requirements. The gateway handles authentication, rate limiting, and error recovery, allowing developers to focus on application logic rather than infrastructure concerns.
Optimizing Performance with Gemini API Keys
Model selection between Flash and Pro variants significantly impacts both performance and cost, requiring careful analysis of your specific use case requirements. Gemini 2.5 Flash excels at high-volume, straightforward tasks with sub-second response times, making it ideal for chatbots, content moderation, and simple question answering. Pro models justify their higher cost through superior reasoning capabilities, making them essential for complex analysis, code generation, and multi-step problem solving.
Response streaming techniques dramatically improve perceived performance by displaying partial results as they generate. Users begin reading initial paragraphs while the API continues generating subsequent content, creating a responsive experience despite total generation time. Implementing proper streaming requires handling partial JSON responses and managing UI updates efficiently:
// Streaming implementation for better UX
async function streamGeminiResponse(prompt, onChunk) {
const response = await fetch('/api/gemini/stream', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prompt })
});
const reader = response.body.pipeThrough(new TextDecoderStream()).getReader();
while (true) {
const { value, done } = await reader.read();
if (done) break;
// Parse streaming JSON chunks
const lines = value.split('\n').filter(line => line.trim());
for (const line of lines) {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.slice(6));
onChunk(data.text);
}
}
}
}
Caching strategies reduce both costs and latency by storing frequently requested responses. Implement semantic similarity matching to identify cacheable content even when prompts aren’t identical. A production caching system combines multiple layers: browser cache for static responses, CDN for geographic distribution, application cache for dynamic content, and database storage for long-term persistence.
Latency optimization involves multiple techniques working together. Geographic deployment close to users reduces network round-trip time. Connection pooling eliminates handshake overhead. Request batching amortizes latency across multiple queries. Predictive prefetching loads likely responses before users request them. Combined properly, these optimizations can reduce perceived latency by 60-80% compared to naive implementations.
Gemini API Key vs Competitors
Performance benchmarks reveal Gemini’s competitive advantages across multiple dimensions. In standardized testing, Gemini 2.5 Pro achieves 92% accuracy on mathematical reasoning tasks (AIME 2024) compared to GPT-4.5’s scores in the 70% range. Code generation benchmarks show similar advantages, with Gemini scoring 74% on Aider Polyglot versus 44.9% for GPT-4.5. These performance differences become critical for applications requiring high accuracy or complex reasoning.
Cost comparison strongly favors Gemini for most use cases. At $0.35 per million tokens for Flash and $1.25 for Pro, Gemini undercuts OpenAI by 70-86% while delivering comparable or superior results. This pricing advantage compounds for high-volume applications where API costs can reach thousands of dollars monthly. A typical chatbot application serving 10,000 daily users might spend $50/month with Gemini Flash versus $350 with GPT-4o.
Feature differences highlight unique Gemini capabilities. Native multimodal support processes images, audio, and video without separate APIs or additional costs. The 1 million token context window dwarfs competitors’ limits, enabling analysis of entire codebases or lengthy documents. Function calling and code execution features come standard without premium pricing tiers. Grounding with Google Search provides unique access to real-time information.
Migration considerations from other providers focus on API compatibility and feature parity. While Gemini’s API differs from OpenAI’s format, the conceptual similarity makes migration straightforward. Most applications require only updating endpoint URLs, adjusting request formats, and modifying response parsing. The official migration guides provide detailed mappings between different providers’ APIs. Services like laozhang.ai can abstract these differences, allowing gradual migration while maintaining backward compatibility.
Future-Proofing Your Gemini API Key Implementation
Staying updated with Gemini API changes requires proactive monitoring of official channels and community resources. Google’s aggressive development pace introduces new features monthly, with major model updates quarterly. Subscribe to the official Gemini developer newsletter, follow the GitHub repository for SDK updates, and participate in community forums where early adopters share experiences with new features.
Version management strategies protect applications from breaking changes while enabling adoption of new capabilities. Pin SDK versions in production while testing updates in staging environments. Implement feature flags to gradually roll out new model versions to user segments. Maintain compatibility layers that can fallback to previous API versions if issues arise. This defensive approach ensures stability while remaining positioned to leverage improvements.
Scaling strategies must consider both technical and financial dimensions as usage grows. Implement horizontal scaling with load balancers distributing requests across multiple API keys to avoid rate limits. Use queue-based architectures to handle traffic spikes gracefully. Monitor cost trends and adjust model selection dynamically based on query complexity. Plan for 10x growth by designing systems that scale linearly rather than requiring architectural changes.
Enterprise considerations extend beyond technical implementation to include compliance, support, and service level agreements. Large organizations should evaluate Vertex AI for advanced features like VPC service controls, private endpoints, and enterprise support. Establish relationships with Google Cloud representatives who can provide guidance on optimal configurations and early access to new features. Document architectural decisions and maintain runbooks for operational scenarios. These preparations ensure smooth scaling from prototype to enterprise deployment.
Integration with existing enterprise systems requires careful planning around authentication, monitoring, and compliance requirements. Single Sign-On (SSO) integration ensures consistent access control across all systems accessing Gemini APIs. Implement comprehensive audit logging that captures not just API usage but also the business context of each request. This might include user identities, department codes, project identifiers, and cost centers for accurate billing allocation. Many enterprises find that API gateway solutions like laozhang.ai simplify these enterprise requirements by providing built-in support for SSO, detailed analytics, and compliance reporting.
Disaster recovery and business continuity planning become critical as AI features become core to business operations. Implement multi-region deployments with automatic failover capabilities. Maintain cached responses for critical queries that can serve users during API outages. Design graceful degradation strategies where applications remain functional even without AI features. Regular disaster recovery drills should test these scenarios, ensuring teams understand recovery procedures and systems behave as expected under failure conditions.
Cost governance at enterprise scale requires sophisticated monitoring and control mechanisms. Implement departmental quotas with automatic notifications as teams approach limits. Use tagging strategies to track costs by project, team, and business unit. Set up automated reports that highlight unusual usage patterns or cost spikes. Consider negotiating enterprise agreements with Google for volume discounts and dedicated support. The combination of technical controls and business processes ensures AI costs remain predictable and aligned with business value.