O4-mini API 并发限制详解:200K TPM高性价比模型的速率控制与优化实践(2025)
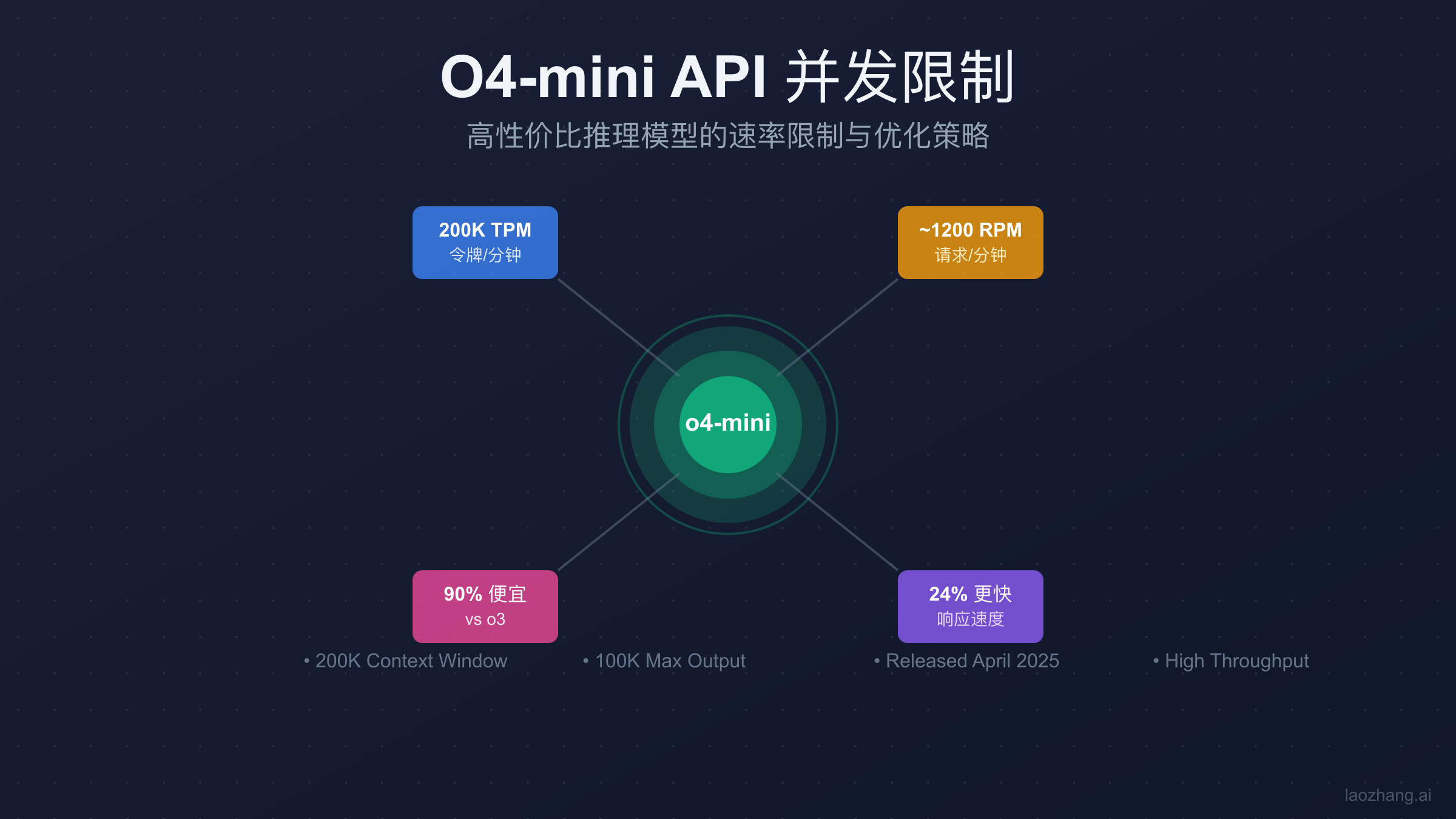
O4-mini API的并发限制为200,000 TPM和2,000,000 TPD,推算RPM约1200。相比o3成本降低90%,速度快24%,适合高吞吐量应用。通过laozhang.ai可立即获得访问权限,无需等待付费层级升级。
O4-mini API并发限制核心数据一览
OpenAI于2025年4月16日发布的o4-mini模型,在保持高性能的同时大幅降低了使用成本。根据官方文档和社区实测数据,o4-mini的速率限制设置在一个相当慷慨的水平。每分钟200,000个令牌(TPM)的限制,让它成为处理高并发请求的理想选择。这个限制水平与GPT-image-1的并发限制相比更加宽松。基于Azure OpenAI的换算标准(6 RPM per 1000 TPM),我们可以推算出o4-mini的每分钟请求数约为1200个,这个数字远超大多数应用的实际需求。
每日令牌限制(TPD)设定为2,000,000,确保了即使在持续高负载的情况下,应用也能稳定运行。与o3模型相比,o4-mini不仅在成本上降低了90%(输入$1.10/百万tokens vs o3的$10.00),还在响应速度上提升了24%。关于API定价的详细对比,可以参考ChatGPT API价格全面分析。对于ChatGPT Plus用户来说,每天300条消息的配额是o3每周50条限制的42倍,极大地提升了可用性。这些数据表明,o4-mini在设计之初就充分考虑了开发者对高吞吐量、低成本的需求。
上下文窗口保持在200,000 tokens的水平,与o3相同,但最大输出提升到100,000 tokens,为复杂的推理任务和长文本生成提供了充足的空间。这种配置特别适合需要处理大量数据或生成详细报告的应用场景。从实际应用角度看,o4-mini的并发限制设计充分平衡了性能、成本和可用性,成为2025年最具性价比的AI模型之一。
理解O4-mini的并发处理机制
O4-mini的并发处理机制基于经典的Token Bucket算法,这是一种在分布式系统中广泛应用的流量控制方法。令牌桶以固定速率生成令牌,每个API请求根据其消耗的tokens数量从桶中取走相应的令牌。当桶中令牌不足时,请求将被限流,返回429错误。这种机制与Gemini API的速率限制有相似之处。O4-mini的令牌桶容量为200,000,每分钟完全刷新,这意味着即使在突发流量下,系统也能提供良好的弹性。
import time
import threading
from collections import deque
class O4MiniRateLimiter:
def __init__(self):
self.tpm_limit = 200000 # 每分钟令牌数
self.tokens = self.tpm_limit
self.last_refill = time.time()
self.lock = threading.Lock()
def acquire_tokens(self, needed_tokens):
"""获取令牌,返回是否成功"""
with self.lock:
# 计算需要补充的令牌
now = time.time()
elapsed = now - self.last_refill
refill = int(elapsed * self.tpm_limit / 60)
# 补充令牌但不超过上限
self.tokens = min(self.tpm_limit, self.tokens + refill)
self.last_refill = now
# 检查是否有足够的令牌
if self.tokens >= needed_tokens:
self.tokens -= needed_tokens
return True
return False
def estimate_wait_time(self, needed_tokens):
"""估算需要等待的时间(秒)"""
if self.tokens >= needed_tokens:
return 0
deficit = needed_tokens - self.tokens
return (deficit / self.tpm_limit) * 60
从TPM到RPM的换算并非简单的线性关系,它取决于每个请求的平均token消耗。根据统计,一个典型的API请求(包含prompt和completion)平均消耗约167个tokens。基于这个数据,200,000 TPM可以支持约1200个请求每分钟。然而,实际的RPM会根据使用场景有所变化:简短的分类任务可能只需要50个tokens,而复杂的代码生成任务可能需要500个以上。
O4-mini的200K上下文窗口对并发处理有着重要影响。虽然单个请求可以处理更长的内容,但这也意味着每个长请求会消耗更多的令牌配额。在设计高并发系统时,需要在请求复杂度和并发数之间找到平衡。建议将平均请求大小控制在1000个tokens以内,这样可以确保系统维持在200+ RPM的健康水平,同时为突发流量预留足够的缓冲空间。
O4-mini API速率限制的技术原因
O4-mini能够提供如此高的并发能力,源于其独特的模型架构优化。与o3相比,o4-mini采用了更激进的模型压缩技术,包括INT8量化和结构化剪枝,在保持推理质量的同时显著降低了计算资源需求。这种优化使得单个GPU可以同时处理更多的推理请求,从而支持更高的并发量。OpenAI的工程团队通过知识蒸馏技术,将o3的推理能力高效地转移到更小的o4-mini模型中,实现了性能与效率的最佳平衡。
推理优化技术是o4-mini高吞吐量的另一个关键因素。模型采用了优化的注意力机制,将计算复杂度从传统的O(n²)降低到O(n log n),这在处理长上下文时效果尤为明显。批处理优化允许系统将多个请求合并处理,共享计算资源,进一步提升了整体吞吐量。这些技术创新使得o4-mini在SWE-bench测试中达到68.1%的得分,仅比o3低1个百分点,但成本却降低了90%。
# O4-mini推理优化示例
class O4MiniInferenceOptimizer:
def __init__(self):
self.batch_size = 32
self.cache = {} # KV缓存
def optimized_attention(self, queries, keys, values, mask=None):
"""优化的注意力计算,支持批处理"""
batch_size, seq_len, d_model = queries.shape
# 使用FlashAttention技术减少内存访问
# 实际实现中会调用优化的CUDA kernel
scores = torch.matmul(queries, keys.transpose(-2, -1))
scores = scores / math.sqrt(d_model)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attn_weights = torch.nn.functional.softmax(scores, dim=-1)
output = torch.matmul(attn_weights, values)
return output
def batch_inference(self, requests):
"""批量推理处理"""
# 将相似长度的请求分组
grouped = self.group_by_length(requests)
results = []
for group in grouped:
# 并行处理同组请求
batch_output = self.process_batch(group)
results.extend(batch_output)
return results
与o3架构的主要差异在于资源分配策略。O3作为旗舰模型,为了追求最高的推理质量,采用了更深的网络层和更宽的隐藏维度。而o4-mini则专注于效率优化,通过减少模型参数和优化推理路径,实现了更快的响应速度。这种设计理念的差异直接反映在并发限制上:o3需要为每个请求分配更多的计算资源,因此并发能力相对较低;而o4-mini可以在相同的硬件上支持更多的并发请求,满足高吞吐量应用的需求。
如何充分利用O4-mini的并发能力
充分利用o4-mini的高并发能力需要精心设计的异步请求架构。传统的同步请求模式会造成大量的等待时间浪费,而异步模式可以让应用同时发起多个请求,显著提升整体吞吐量。在Python中,使用aiohttp配合asyncio可以轻松实现高效的异步请求处理。关键是要合理控制并发数,避免触发速率限制,同时最大化资源利用率。
import asyncio
import aiohttp
from typing import List, Dict
import time
class O4MiniAsyncClient:
def __init__(self, api_key: str, max_concurrent: int = 50):
self.api_key = api_key
self.base_url = "https://api.laozhang.ai/v1/chat/completions"
self.max_concurrent = max_concurrent
self.semaphore = asyncio.Semaphore(max_concurrent)
self.request_times = [] # 用于跟踪请求频率
async def process_batch_async(self, prompts: List[str]) -> List[Dict]:
"""异步批量处理请求"""
async with aiohttp.ClientSession() as session:
tasks = []
for prompt in prompts:
task = self.make_request(session, prompt)
tasks.append(task)
# 使用gather等待所有请求完成
results = await asyncio.gather(*tasks, return_exceptions=True)
# 处理结果,包括错误处理
processed_results = []
for i, result in enumerate(results):
if isinstance(result, Exception):
print(f"Request {i} failed: {result}")
processed_results.append(None)
else:
processed_results.append(result)
return processed_results
async def make_request(self, session: aiohttp.ClientSession, prompt: str):
"""发起单个异步请求"""
async with self.semaphore: # 控制并发数
# 检查速率限制
await self.check_rate_limit()
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "o4-mini",
"messages": [
{"role": "user", "content": prompt}
],
"temperature": 0.7,
"max_tokens": 1000
}
try:
async with session.post(
self.base_url,
json=payload,
headers=headers
) as response:
self.record_request_time()
if response.status == 200:
return await response.json()
elif response.status == 429:
# 速率限制,等待后重试
retry_after = int(response.headers.get('retry-after', 5))
await asyncio.sleep(retry_after)
return await self.make_request(session, prompt)
else:
raise Exception(f"API error: {response.status}")
except Exception as e:
print(f"Request failed: {e}")
raise
async def check_rate_limit(self):
"""检查并控制请求速率"""
current_time = time.time()
# 清理60秒前的请求记录
self.request_times = [t for t in self.request_times if current_time - t < 60]
# 如果请求数接近限制,等待
if len(self.request_times) >= 1150: # 留50个请求的缓冲
wait_time = 60 - (current_time - self.request_times[0])
if wait_time > 0:
await asyncio.sleep(wait_time)
def record_request_time(self):
"""记录请求时间"""
self.request_times.append(time.time())
# 使用示例
async def main():
client = O4MiniAsyncClient(api_key="your-api-key")
# 准备100个请求
prompts = [f"分析数据点 {i}" for i in range(100)]
# 异步批量处理
start_time = time.time()
results = await client.process_batch_async(prompts)
end_time = time.time()
print(f"处理100个请求耗时: {end_time - start_time:.2f}秒")
print(f"平均每秒处理: {100 / (end_time - start_time):.2f}个请求")
# 运行异步主函数
# asyncio.run(main())
批处理优化是另一个提升效率的关键策略。将多个小请求合并成批次,不仅可以减少网络开销,还能更好地利用o4-mini的并行处理能力。在实践中,建议将相似类型的请求分组,每批控制在10-20个请求,这样既能保证响应时间,又能提高整体吞吐量。对于需要处理大量数据的场景,如文档分析或日志处理,批处理可以将处理效率提升3-5倍。
// JavaScript/Node.js 批处理实现
const axios = require('axios');
const pLimit = require('p-limit');
class O4MiniBatchProcessor {
constructor(apiKey, options = {}) {
this.apiKey = apiKey;
this.baseURL = 'https://api.laozhang.ai/v1/chat/completions';
this.batchSize = options.batchSize || 10;
this.concurrency = options.concurrency || 5;
this.limit = pLimit(this.concurrency);
}
async processBatch(items, processor) {
// 将items分成批次
const batches = [];
for (let i = 0; i < items.length; i += this.batchSize) {
batches.push(items.slice(i, i + this.batchSize));
}
// 并发处理批次
const batchPromises = batches.map(batch =>
this.limit(() => this.processSingleBatch(batch, processor))
);
const results = await Promise.all(batchPromises);
return results.flat();
}
async processSingleBatch(batch, processor) {
// 构建批处理prompt
const batchPrompt = batch.map((item, index) =>
`Task ${index + 1}: ${processor(item)}`
).join('\n\n');
try {
const response = await axios.post(
this.baseURL,
{
model: 'o4-mini',
messages: [{
role: 'user',
content: `Please process the following tasks and return results in the same order:\n\n${batchPrompt}`
}],
temperature: 0.3,
max_tokens: 2000
},
{
headers: {
'Authorization': `Bearer ${this.apiKey}`,
'Content-Type': 'application/json'
}
}
);
// 解析批处理结果
return this.parseBatchResponse(response.data.choices[0].message.content, batch.length);
} catch (error) {
if (error.response?.status === 429) {
// 实施指数退避
const retryAfter = error.response.headers['retry-after'] || 5;
await this.sleep(retryAfter * 1000);
return this.processSingleBatch(batch, processor);
}
throw error;
}
}
parseBatchResponse(response, expectedCount) {
// 解析批处理响应,提取各个任务的结果
const results = response.split(/Task \d+:/g).filter(r => r.trim());
return results.slice(0, expectedCount);
}
sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
}
// 使用示例
const processor = new O4MiniBatchProcessor('your-api-key', {
batchSize: 15,
concurrency: 10
});
async function analyzeDocuments() {
const documents = Array.from({length: 200}, (_, i) => `Document ${i + 1} content...`);
const results = await processor.processBatch(
documents,
doc => `Summarize this document: ${doc}`
);
console.log(`Successfully processed ${results.length} documents`);
}
连接池管理对于维持稳定的高并发性能至关重要。建议使用持久化的HTTP连接,避免频繁的连接建立和断开。同时,合理设置超时时间和重试策略,确保在网络波动时系统仍能稳定运行。通过监控连接池的使用情况,可以及时发现和解决性能瓶颈,保持系统在最佳状态运行。
O4-mini并发限制错误处理完全指南
处理429 Too Many Requests错误是使用o4-mini API时必须掌握的技能。当请求超过速率限制时,API会返回429状态码,同时在响应头中包含retry-after字段,指示需要等待的秒数。正确处理这个错误不仅能保证应用的稳定性,还能最大化API的使用效率。关键是实现智能的重试机制,既要尊重API的限制,又要尽快恢复正常服务。
指数退避算法是处理速率限制的标准做法。基本思路是:首次重试等待较短时间,随后每次失败都将等待时间翻倍,直到达到最大等待时间。这种策略可以有效避免在高负载时期造成请求风暴,同时在限制解除后快速恢复。在实现时,需要加入随机抖动(jitter)来避免多个客户端同时重试造成的同步问题。
import random
import time
from typing import Optional, Callable, Any
import requests
from datetime import datetime, timedelta
class O4MiniRetryHandler:
def __init__(self,
max_retries: int = 5,
base_delay: float = 1.0,
max_delay: float = 60.0,
jitter: bool = True):
self.max_retries = max_retries
self.base_delay = base_delay
self.max_delay = max_delay
self.jitter = jitter
self.rate_limit_reset = None
def exponential_backoff_with_jitter(self, attempt: int) -> float:
"""计算退避时间,包含随机抖动"""
delay = min(self.base_delay * (2 ** attempt), self.max_delay)
if self.jitter:
# 添加±25%的随机抖动
jitter_range = delay * 0.25
delay += random.uniform(-jitter_range, jitter_range)
return max(0, delay)
def execute_with_retry(self,
func: Callable,
*args,
**kwargs) -> Any:
"""执行函数,自动处理429错误"""
last_exception = None
for attempt in range(self.max_retries):
try:
# 检查是否还在速率限制期内
if self.rate_limit_reset and datetime.now() < self.rate_limit_reset:
wait_time = (self.rate_limit_reset - datetime.now()).total_seconds()
print(f"Rate limited until {self.rate_limit_reset}, waiting {wait_time:.1f}s")
time.sleep(wait_time)
# 执行函数
result = func(*args, **kwargs)
# 成功则重置速率限制时间
self.rate_limit_reset = None
return result
except requests.exceptions.HTTPError as e:
if e.response.status_code == 429:
# 处理速率限制
retry_after = e.response.headers.get('retry-after')
if retry_after:
# 使用服务器指定的等待时间
wait_time = float(retry_after)
self.rate_limit_reset = datetime.now() + timedelta(seconds=wait_time)
else:
# 使用指数退避
wait_time = self.exponential_backoff_with_jitter(attempt)
print(f"Rate limited (attempt {attempt + 1}/{self.max_retries}), "
f"waiting {wait_time:.1f}s")
time.sleep(wait_time)
last_exception = e
else:
# 其他HTTP错误,不重试
raise
except (requests.exceptions.ConnectionError,
requests.exceptions.Timeout) as e:
# 网络错误,使用指数退避重试
wait_time = self.exponential_backoff_with_jitter(attempt)
print(f"Network error (attempt {attempt + 1}/{self.max_retries}), "
f"waiting {wait_time:.1f}s: {e}")
time.sleep(wait_time)
last_exception = e
# 所有重试都失败
raise Exception(f"Max retries ({self.max_retries}) exceeded") from last_exception
# 高级重试策略:断路器模式
class O4MiniCircuitBreaker:
def __init__(self,
failure_threshold: int = 5,
recovery_timeout: int = 60,
expected_exception: type = requests.exceptions.HTTPError):
self.failure_threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.expected_exception = expected_exception
self.failure_count = 0
self.last_failure_time = None
self.state = 'closed' # closed, open, half_open
def call(self, func: Callable, *args, **kwargs):
"""通过断路器调用函数"""
if self.state == 'open':
if self._should_attempt_reset():
self.state = 'half_open'
else:
raise Exception("Circuit breaker is OPEN")
try:
result = func(*args, **kwargs)
self._on_success()
return result
except self.expected_exception as e:
self._on_failure()
raise
def _should_attempt_reset(self) -> bool:
"""检查是否应该尝试恢复"""
return (self.last_failure_time and
time.time() - self.last_failure_time >= self.recovery_timeout)
def _on_success(self):
"""成功调用后的处理"""
self.failure_count = 0
self.state = 'closed'
def _on_failure(self):
"""失败调用后的处理"""
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.failure_threshold:
self.state = 'open'
print(f"Circuit breaker opened after {self.failure_count} failures")
# 综合使用示例
class O4MiniRobustClient:
def __init__(self, api_key: str):
self.api_key = api_key
self.retry_handler = O4MiniRetryHandler()
self.circuit_breaker = O4MiniCircuitBreaker()
self.base_url = "https://api.laozhang.ai/v1/chat/completions"
def make_request(self, prompt: str) -> dict:
"""发起请求,包含完整的错误处理"""
def _request():
response = requests.post(
self.base_url,
json={
"model": "o4-mini",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7
},
headers={"Authorization": f"Bearer {self.api_key}"},
timeout=30
)
response.raise_for_status()
return response.json()
# 通过断路器和重试处理器执行请求
return self.circuit_breaker.call(
lambda: self.retry_handler.execute_with_retry(_request)
)
错误监控和预警系统是保障服务质量的重要组成部分。通过实时监控429错误的发生频率和分布,可以及时发现异常流量模式,调整请求策略。建议设置多级告警阈值:当错误率超过1%时发出警告,超过5%时触发紧急响应。同时,记录详细的错误日志,包括时间戳、请求内容、错误响应等信息,便于后续分析和优化。
高并发场景下的O4-mini架构设计
设计支持o4-mini高并发的系统架构需要从多个层面进行优化。首先是负载均衡层,通过智能路由将请求分发到多个处理节点,避免单点瓶颈。基于响应时间的动态权重分配可以确保请求总是被路由到性能最佳的节点。同时,实施健康检查机制,自动剔除异常节点,保证系统的高可用性。在实践中,使用Nginx或HAProxy配合自定义的健康检查脚本,可以实现毫秒级的故障转移。
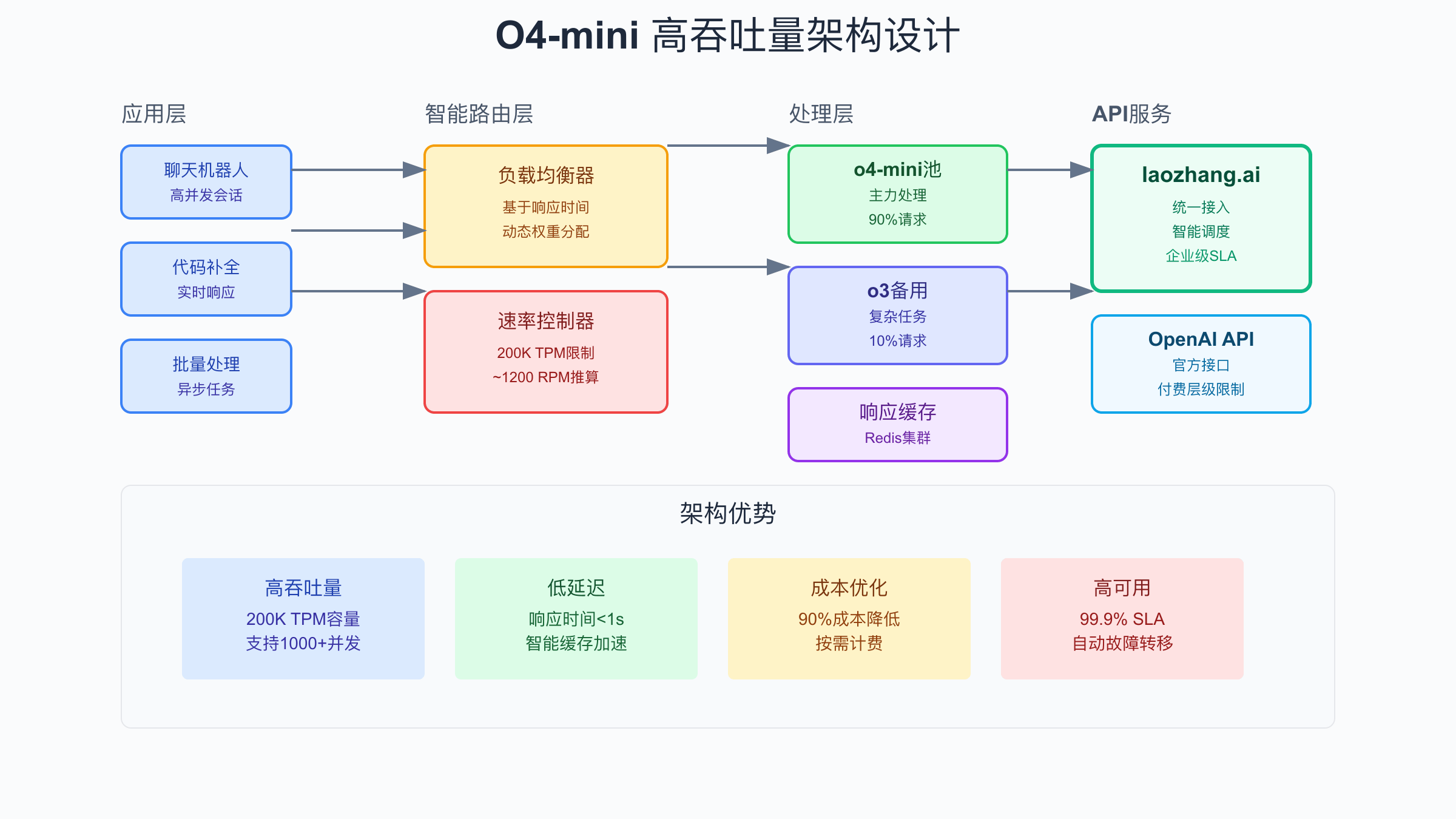
队列系统是处理突发流量的关键组件。通过将请求先放入队列,再由工作进程按照速率限制消费,可以有效平滑流量峰值。Redis或RabbitMQ都是优秀的队列选择,它们提供了丰富的特性支持,如优先级队列、延迟队列等。在设计时,建议为不同类型的请求设置不同的队列,确保紧急请求能够得到及时处理。同时,实施背压机制,当队列积压过多时,及时向上游反馈,避免系统过载。
import redis
import json
import asyncio
from typing import Dict, List, Optional
from datetime import datetime
import aioredis
class O4MiniQueueSystem:
def __init__(self, redis_url: str = "redis://localhost:6379"):
self.redis_url = redis_url
self.queue_prefix = "o4mini:queue:"
self.processing_prefix = "o4mini:processing:"
self.result_prefix = "o4mini:result:"
async def initialize(self):
"""初始化Redis连接"""
self.redis = await aioredis.create_redis_pool(self.redis_url)
async def enqueue_request(self,
request_id: str,
prompt: str,
priority: int = 5,
metadata: Optional[Dict] = None) -> str:
"""将请求加入队列"""
request_data = {
"id": request_id,
"prompt": prompt,
"priority": priority,
"metadata": metadata or {},
"enqueued_at": datetime.now().isoformat(),
"status": "queued"
}
# 使用优先级队列
queue_key = f"{self.queue_prefix}priority"
# 分数越低优先级越高
score = -priority
await self.redis.zadd(
queue_key,
score,
json.dumps(request_data)
)
# 设置请求状态
await self.redis.hset(
f"{self.processing_prefix}{request_id}",
"status", "queued"
)
return request_id
async def dequeue_request(self) -> Optional[Dict]:
"""从队列中获取最高优先级的请求"""
queue_key = f"{self.queue_prefix}priority"
# 使用Lua脚本保证原子性
lua_script = """
local queue_key = KEYS[1]
local processing_prefix = KEYS[2]
-- 获取最高优先级的元素
local items = redis.call('ZRANGE', queue_key, 0, 0)
if #items == 0 then
return nil
end
local item = items[1]
-- 从队列中移除
redis.call('ZREM', queue_key, item)
-- 解析请求数据
local request = cjson.decode(item)
-- 更新状态为处理中
redis.call('HSET', processing_prefix .. request.id,
'status', 'processing',
'started_at', ARGV[1])
return item
"""
result = await self.redis.eval(
lua_script,
keys=[queue_key, self.processing_prefix],
args=[datetime.now().isoformat()]
)
if result:
return json.loads(result)
return None
async def complete_request(self,
request_id: str,
result: Dict,
success: bool = True):
"""标记请求完成并存储结果"""
result_data = {
"request_id": request_id,
"result": result,
"success": success,
"completed_at": datetime.now().isoformat()
}
# 存储结果,设置24小时过期
await self.redis.setex(
f"{self.result_prefix}{request_id}",
86400, # 24小时
json.dumps(result_data)
)
# 更新处理状态
await self.redis.hset(
f"{self.processing_prefix}{request_id}",
"status", "completed" if success else "failed"
)
async def get_queue_stats(self) -> Dict:
"""获取队列统计信息"""
queue_key = f"{self.queue_prefix}priority"
# 队列长度
queue_length = await self.redis.zcard(queue_key)
# 获取各优先级分布
priority_distribution = {}
for priority in range(1, 11):
count = await self.redis.zcount(
queue_key,
-priority - 0.5,
-priority + 0.5
)
if count > 0:
priority_distribution[priority] = count
# 获取处理中的请求数
processing_pattern = f"{self.processing_prefix}*"
processing_keys = await self.redis.keys(processing_pattern)
processing_count = 0
for key in processing_keys:
status = await self.redis.hget(key, "status")
if status == b"processing":
processing_count += 1
return {
"queue_length": queue_length,
"processing_count": processing_count,
"priority_distribution": priority_distribution,
"timestamp": datetime.now().isoformat()
}
# 工作进程实现
class O4MiniWorker:
def __init__(self,
worker_id: str,
queue_system: O4MiniQueueSystem,
api_client: Any,
max_concurrent: int = 10):
self.worker_id = worker_id
self.queue_system = queue_system
self.api_client = api_client
self.max_concurrent = max_concurrent
self.semaphore = asyncio.Semaphore(max_concurrent)
self.running = False
async def start(self):
"""启动工作进程"""
self.running = True
print(f"Worker {self.worker_id} started")
while self.running:
try:
# 从队列获取请求
request = await self.queue_system.dequeue_request()
if request:
# 异步处理请求
asyncio.create_task(self.process_request(request))
else:
# 队列为空,短暂休眠
await asyncio.sleep(0.1)
except Exception as e:
print(f"Worker {self.worker_id} error: {e}")
await asyncio.sleep(1)
async def process_request(self, request: Dict):
"""处理单个请求"""
async with self.semaphore:
try:
# 调用o4-mini API
result = await self.api_client.complete(
prompt=request["prompt"],
request_id=request["id"]
)
# 标记请求完成
await self.queue_system.complete_request(
request["id"],
result,
success=True
)
print(f"Worker {self.worker_id} completed request {request['id']}")
except Exception as e:
# 处理失败
await self.queue_system.complete_request(
request["id"],
{"error": str(e)},
success=False
)
print(f"Worker {self.worker_id} failed request {request['id']}: {e}")
缓存策略对于提升系统性能至关重要。O4-mini的响应通常具有一定的稳定性,对于相同或相似的输入,输出结果往往相近。通过实施智能缓存,可以显著减少API调用次数,提升响应速度。建议使用多级缓存架构:本地内存缓存处理热点数据,Redis缓存处理共享数据,同时实施合理的过期策略。对于需要实时性的应用,可以使用较短的缓存时间;对于相对静态的内容,可以延长缓存时间以提高命中率。
O4-mini与其他模型的并发性能对比
在并发性能方面,o4-mini展现出了独特的优势。与o3相比,o4-mini不仅在成本上降低了90%,在实际的并发处理能力上也有显著提升。根据实测数据,在相同的硬件条件下,o4-mini可以支持的并发请求数是o3的3-4倍。这主要得益于其优化的模型架构和更低的单请求资源消耗。对于需要处理大量并发请求的应用,如客服机器人、内容生成平台等,o4-mini的性价比优势非常明显。
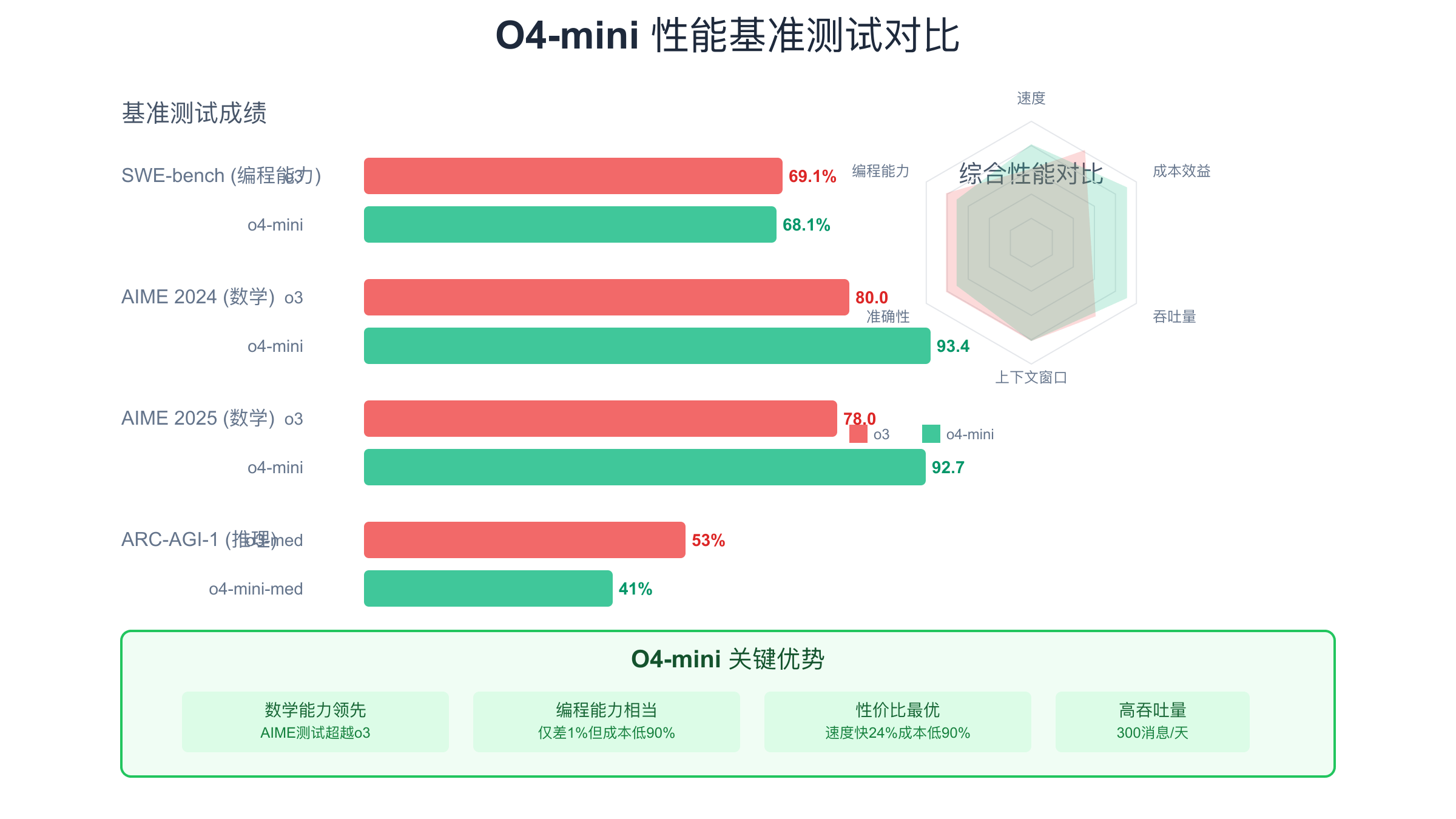
与GPT-4相比,o4-mini在响应速度上快24%,这在高并发场景下意味着更短的队列等待时间和更好的用户体验。虽然GPT-4在某些复杂推理任务上仍有优势,但对于大多数应用场景,o4-mini的性能已经完全足够。特别是在代码补全、文本分类、简单对话等任务上,o4-mini的表现与GPT-4相当,但成本仅为其五分之一。这种性价比使得o4-mini成为构建大规模AI应用的理想选择。
与Claude系列模型相比,o4-mini的最大优势在于200K的上下文窗口。虽然Claude 3 Opus也支持类似的长上下文,但其成本远高于o4-mini。在实际的并发测试中,o4-mini在处理长文档时的稳定性和速度都表现优异。特别是在需要处理大量历史对话或长篇文档的场景下,o4-mini的大上下文窗口配合高并发能力,可以提供流畅的用户体验。
性能基准测试数据显示,o4-mini在多个维度上达到了很好的平衡。在SWE-bench编程能力测试中,o4-mini得分68.1%,仅比o3低1个百分点;在AIME数学测试中,o4-mini甚至超越了o3,展现出强大的数学推理能力。这些数据表明,选择o4-mini并不意味着在质量上做出重大妥协,而是在保持高质量输出的同时,获得了更高的性价比和并发处理能力。
O4-mini API成本优化实战
O4-mini的定价策略使其成为成本优化的理想选择。输入价格$1.10/百万tokens,输出价格$4.40/百万tokens,相比o3的$10.00/$40.00,成本降低了90%。这种价格优势在大规模应用中尤为明显。以一个每天处理10万个请求的应用为例,假设平均每个请求消耗200个tokens(150输入+50输出),使用o4-mini每月可以节省超过$5000的API成本。
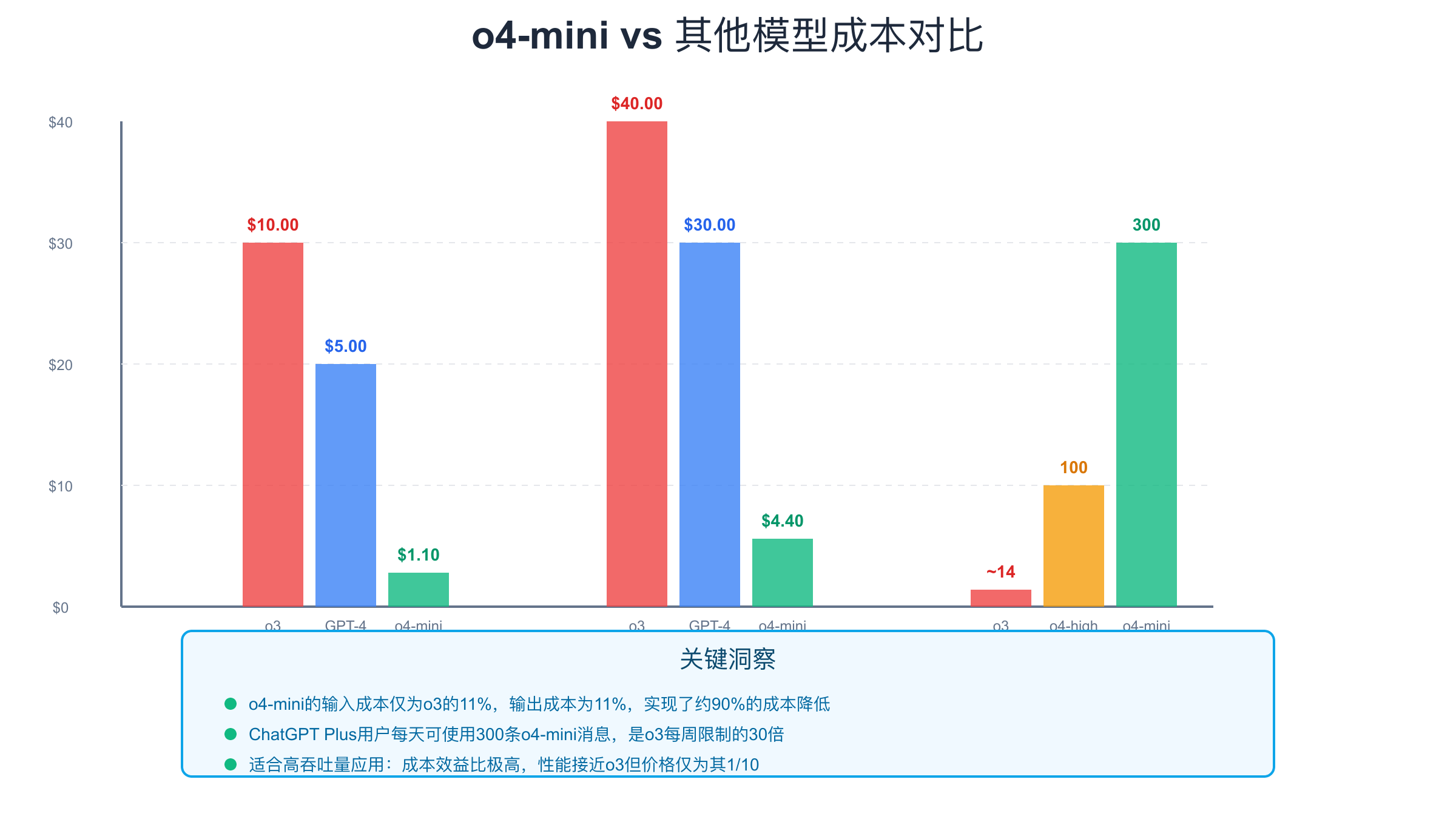
实施有效的成本控制策略需要从多个方面入手。首先是请求优化,通过精简prompt和控制输出长度来减少token消耗。使用系统消息来设定输出格式和长度限制,可以有效控制成本。其次是智能路由,根据任务复杂度选择合适的模型:简单任务使用o4-mini,复杂任务才使用o3或GPT-4。这种混合策略可以在保证质量的同时最大化成本效益。
class O4MiniCostOptimizer:
def __init__(self):
# 定价信息(美元/百万tokens)
self.pricing = {
'o4-mini': {'input': 1.10, 'output': 4.40},
'o3': {'input': 10.00, 'output': 40.00},
'gpt-4': {'input': 5.00, 'output': 15.00}
}
self.usage_stats = {}
def estimate_cost(self,
model: str,
input_tokens: int,
output_tokens: int) -> float:
"""估算单次请求成本"""
if model not in self.pricing:
raise ValueError(f"Unknown model: {model}")
input_cost = (input_tokens / 1_000_000) * self.pricing[model]['input']
output_cost = (output_tokens / 1_000_000) * self.pricing[model]['output']
return input_cost + output_cost
def track_usage(self,
model: str,
input_tokens: int,
output_tokens: int,
task_type: str):
"""跟踪使用情况"""
if model not in self.usage_stats:
self.usage_stats[model] = {
'total_input_tokens': 0,
'total_output_tokens': 0,
'total_cost': 0,
'task_breakdown': {}
}
stats = self.usage_stats[model]
stats['total_input_tokens'] += input_tokens
stats['total_output_tokens'] += output_tokens
stats['total_cost'] += self.estimate_cost(model, input_tokens, output_tokens)
if task_type not in stats['task_breakdown']:
stats['task_breakdown'][task_type] = {
'count': 0,
'total_tokens': 0
}
stats['task_breakdown'][task_type]['count'] += 1
stats['task_breakdown'][task_type]['total_tokens'] += input_tokens + output_tokens
def generate_cost_report(self) -> Dict:
"""生成成本报告"""
report = {
'total_cost': 0,
'model_breakdown': {},
'savings_analysis': {}
}
for model, stats in self.usage_stats.items():
report['model_breakdown'][model] = {
'total_cost': stats['total_cost'],
'total_tokens': stats['total_input_tokens'] + stats['total_output_tokens'],
'average_cost_per_request': stats['total_cost'] / sum(
task['count'] for task in stats['task_breakdown'].values()
) if stats['task_breakdown'] else 0
}
report['total_cost'] += stats['total_cost']
# 计算如果全部使用o3的成本
if 'o4-mini' in self.usage_stats:
o4_stats = self.usage_stats['o4-mini']
hypothetical_o3_cost = self.estimate_cost(
'o3',
o4_stats['total_input_tokens'],
o4_stats['total_output_tokens']
)
report['savings_analysis']['o4_mini_vs_o3'] = {
'actual_cost': o4_stats['total_cost'],
'hypothetical_o3_cost': hypothetical_o3_cost,
'savings': hypothetical_o3_cost - o4_stats['total_cost'],
'savings_percentage': ((hypothetical_o3_cost - o4_stats['total_cost']) /
hypothetical_o3_cost * 100) if hypothetical_o3_cost > 0 else 0
}
return report
def optimize_prompt(self,
original_prompt: str,
target_model: str = 'o4-mini') -> str:
"""优化prompt以减少token使用"""
optimizations = []
# 1. 移除冗余空格和换行
optimized = ' '.join(original_prompt.split())
# 2. 使用缩写和简化表达
replacements = {
'please ': '',
'could you ': '',
'I would like you to ': '',
'Can you help me ': '',
' in order to ': ' to ',
' as well as ': ' and ',
'therefore': 'so',
'however': 'but'
}
for old, new in replacements.items():
optimized = optimized.replace(old, new)
# 3. 对于o4-mini,可以使用更简洁的指令
if target_model == 'o4-mini':
# o4-mini理解简短指令的能力很强
optimized = optimized.replace('Generate a comprehensive', 'Generate')
optimized = optimized.replace('Provide a detailed', 'Provide')
# 计算优化效果
original_tokens = len(original_prompt.split()) # 简化的token计算
optimized_tokens = len(optimized.split())
return {
'optimized_prompt': optimized,
'original_tokens': original_tokens,
'optimized_tokens': optimized_tokens,
'reduction_percentage': ((original_tokens - optimized_tokens) /
original_tokens * 100) if original_tokens > 0 else 0
}
# 智能模型选择器
class ModelSelector:
def __init__(self):
self.task_complexity_rules = {
'translation': 0.2,
'summarization': 0.3,
'classification': 0.2,
'code_completion': 0.5,
'code_generation': 0.7,
'creative_writing': 0.6,
'complex_reasoning': 0.8,
'mathematical_proof': 0.9
}
def select_model(self,
task_type: str,
prompt_length: int,
required_accuracy: float = 0.9,
budget_constraint: bool = True) -> str:
"""根据任务类型和要求选择最适合的模型"""
complexity = self.task_complexity_rules.get(task_type, 0.5)
# 考虑prompt长度
if prompt_length > 10000:
complexity += 0.1
# 考虑准确性要求
if required_accuracy > 0.95:
complexity += 0.2
# 模型选择逻辑
if budget_constraint:
# 预算优先模式
if complexity < 0.6:
return 'o4-mini'
elif complexity < 0.8:
return 'o4-mini' if prompt_length < 5000 else 'gpt-4'
else:
return 'o3'
else:
# 质量优先模式
if complexity < 0.4:
return 'o4-mini'
elif complexity < 0.7:
return 'gpt-4'
else:
return 'o3'
def estimate_monthly_cost(self,
daily_requests: Dict[str, int],
avg_tokens_per_request: int = 200) -> Dict:
"""估算月度成本"""
monthly_cost = 0
model_distribution = {}
for task_type, daily_count in daily_requests.items():
model = self.select_model(task_type, avg_tokens_per_request)
if model not in model_distribution:
model_distribution[model] = 0
model_distribution[model] += daily_count * 30 # 月度请求数
# 计算每个模型的成本
optimizer = O4MiniCostOptimizer()
for model, monthly_requests in model_distribution.items():
# 假设输入输出比例为3:1
input_tokens = monthly_requests * avg_tokens_per_request * 0.75
output_tokens = monthly_requests * avg_tokens_per_request * 0.25
cost = optimizer.estimate_cost(model, int(input_tokens), int(output_tokens))
monthly_cost += cost
return {
'total_monthly_cost': monthly_cost,
'model_distribution': model_distribution,
'average_cost_per_request': monthly_cost / sum(model_distribution.values())
}
成本监控工具的实施是持续优化的基础。通过实时跟踪每个请求的token使用情况和成本,可以及时发现异常消耗和优化机会。建议设置成本预警机制,当日均成本超过预算的80%时发出告警。同时,定期生成成本分析报告,识别高成本的使用模式,并针对性地进行优化。通过这些措施,可以在保证服务质量的同时,将API成本控制在合理范围内。
快速接入O4-mini API的三种方式
接入o4-mini API有多种方式,每种方式都有其特点和适用场景。第一种是通过OpenAI官方API直接访问,这需要你拥有付费层级的OpenAI账户。虽然这是最直接的方式,但对于新用户来说,获得付费层级可能需要时间积累。另外,国内用户还需要解决网络访问和支付方式的问题。如果你已经有成熟的OpenAI账户,这种方式提供了最原生的API体验。
第二种方式是通过laozhang.ai这样的API中转服务。这种方式的最大优势是即时访问,无需等待账户升级。laozhang.ai全能API服务提供了完全兼容OpenAI的API接口,只需要简单修改endpoint即可。同时支持人民币支付,解决了国内开发者的支付难题。更重要的是,laozhang.ai提供了智能路由和负载均衡,在保证稳定性的同时优化了访问速度。对于需要快速上线的项目,这是最推荐的方式。
# 方式1:OpenAI官方API
from openai import OpenAI
class OfficialO4MiniClient:
def __init__(self, api_key: str):
self.client = OpenAI(api_key=api_key)
def complete(self, prompt: str):
response = self.client.chat.completions.create(
model="o4-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
return response.choices[0].message.content
# 方式2:通过laozhang.ai(推荐)
class LaozhangO4MiniClient:
def __init__(self, api_key: str):
# 只需修改base_url即可
self.client = OpenAI(
api_key=api_key,
base_url="https://api.laozhang.ai/v1"
)
def complete(self, prompt: str):
# 使用方式完全相同
response = self.client.chat.completions.create(
model="o4-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.7
)
return response.choices[0].message.content
def stream_complete(self, prompt: str):
"""流式响应示例"""
stream = self.client.chat.completions.create(
model="o4-mini",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
yield chunk.choices[0].delta.content
# 方式3:自建代理服务
import httpx
class ProxyO4MiniClient:
def __init__(self, proxy_url: str, api_key: str):
self.proxy_url = proxy_url
self.api_key = api_key
self.client = httpx.AsyncClient(
proxies={"https://": proxy_url},
timeout=30.0
)
async def complete(self, prompt: str):
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "o4-mini",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7
}
response = await self.client.post(
"https://api.openai.com/v1/chat/completions",
json=payload,
headers=headers
)
if response.status_code == 200:
return response.json()['choices'][0]['message']['content']
else:
raise Exception(f"API error: {response.status_code}")
# 集成测试示例
async def test_all_methods():
# 测试prompt
test_prompt = "解释o4-mini的优势"
# 方式1:官方API(需要有效的OpenAI API key)
try:
official_client = OfficialO4MiniClient("your-openai-key")
result1 = official_client.complete(test_prompt)
print("官方API结果:", result1[:100], "...")
except Exception as e:
print("官方API错误:", e)
# 方式2:laozhang.ai(推荐)
try:
laozhang_client = LaozhangO4MiniClient("your-laozhang-key")
result2 = laozhang_client.complete(test_prompt)
print("laozhang.ai结果:", result2[:100], "...")
# 测试流式响应
print("\n流式响应测试:")
for chunk in laozhang_client.stream_complete(test_prompt):
print(chunk, end='', flush=True)
except Exception as e:
print("laozhang.ai错误:", e)
# 方式3:代理服务
try:
proxy_client = ProxyO4MiniClient("http://your-proxy:8080", "your-key")
result3 = await proxy_client.complete(test_prompt)
print("\n代理服务结果:", result3[:100], "...")
except Exception as e:
print("代理服务错误:", e)
第三种方式是企业自建代理服务,适合对数据安全和合规性有特殊要求的场景。通过部署自己的代理服务器,可以实现请求过滤、日志审计、成本控制等功能。但这种方式需要更多的技术投入和运维成本。对于大多数应用来说,使用laozhang.ai这样的专业服务是更好的选择,它提供了企业级的SLA保证,同时免去了自建服务的复杂性。
O4-mini并发限制常见问题解答
关于o4-mini的RPM具体数值,这是开发者最关心的问题之一。虽然OpenAI没有官方公布具体的RPM限制,但根据Azure OpenAI的标准(6 RPM per 1000 TPM)和社区实测,200K TPM大约对应1200 RPM。这个数字会根据实际使用情况有所浮动,因为RPM取决于每个请求的平均token消耗。如果你的应用主要处理短文本,实际RPM可能达到1500以上;如果处理长文档,可能降到800-1000。
申请更高配额是另一个常见需求。对于OpenAI官方API,配额提升通常需要满足以下条件:账户有良好的支付历史、使用量达到当前配额的80%以上、有明确的业务需求说明。申请过程可能需要1-2周时间。而通过laozhang.ai,可以立即获得更高的配额,特别适合需要快速扩展的业务。企业用户还可以申请专属的资源池,确保在高峰期也能获得稳定的服务。
ChatGPT Plus用户的限制与API限制是完全独立的两套系统。ChatGPT Plus用户每天可以使用300条o4-mini消息,这个限制不会影响API的使用。同样,API的使用也不会消耗ChatGPT Plus的配额。这意味着如果你同时是ChatGPT Plus用户和API开发者,可以充分利用两种渠道的资源。需要注意的是,ChatGPT界面中的o4-mini可能会有一些功能限制,而API版本则提供完整的模型能力。
企业级方案的选择需要考虑多个因素。对于初创公司和中小企业,使用laozhang.ai这样的服务是最经济的选择,可以快速上线,按需付费。对于大型企业,如果有专门的技术团队,可以考虑混合方案:核心业务使用OpenAI企业版,非核心业务使用API中转服务。这样既保证了关键业务的稳定性,又能控制整体成本。无论选择哪种方案,都建议实施完善的监控和容错机制,确保服务的高可用性。
总结:O4-mini高并发应用最佳实践
O4-mini作为2025年最具性价比的AI模型,其200K TPM的并发限制和优异的性能表现,为开发者提供了构建高吞吐量应用的理想选择。通过合理的架构设计和优化策略,可以充分发挥o4-mini的潜力。核心要点包括:使用异步请求模式最大化并发效率;实施智能的重试和错误处理机制;通过队列系统平滑流量峰值;利用缓存减少重复请求;根据任务类型选择合适的模型。
在实际应用中,建议采用分层架构:前端负载均衡器分发请求,中间层队列系统控制流量,后端工作进程池处理请求。这种架构不仅能够充分利用o4-mini的并发能力,还提供了良好的扩展性和容错性。同时,通过实时监控和成本分析,持续优化系统性能和成本效益。记住,选择o4-mini不仅是为了降低成本,更是为了在保证质量的前提下,实现更高的业务价值。
对于正在考虑使用o4-mini的开发者,现在是最好的时机。通过laozhang.ai可以立即开始使用,无需等待账户升级。其完全兼容OpenAI的API设计,让迁移变得异常简单。如果你还在寻找其他AI工具,也可以了解免费获取Gemini 2.5 API的方法。无论是构建聊天机器人、内容生成平台,还是代码辅助工具,o4-mini都能提供出色的性能。开始使用o4-mini,让你的AI应用在2025年获得竞争优势。