GPT-image-1 并发限制详解:从429错误到企业级解决方案
gpt-image-1的并发限制约为3000 RPM(Tier 1),每次仅支持生成1张图片。新用户需等待24-48小时升级层级。建议使用队列管理和指数退避策略处理429错误,或通过laozhang.ai等中转API立即获得更高配额。

gpt-image-1并发限制的核心参数
OpenAI的gpt-image-1作为最新的图像生成模型,其并发限制机制相比文本模型更加复杂。根据社区反馈和实际测试,该模型的速率限制主要体现在四个维度上。首先是RPM(Requests Per Minute)限制,对于Tier 1用户,推测限制约为3000请求每分钟,这与”Other models”类别的限制相符。然而实际使用中,由于图像生成的计算密集性,真实可达到的并发数往往远低于这个理论值。
IPM(Images Per Minute)是gpt-image-1特有的限制指标。与DALL·E类似,每分钟生成的图片数量受到严格控制。目前gpt-image-1仅支持单次请求生成一张图片,不支持批量生成,这进一步限制了实际的吞吐量。对于需要大量图片生成的应用场景,这种限制成为了主要瓶颈。配合TPM(Tokens Per Minute)限制,虽然图像生成不直接消耗文本tokens,但prompt的长度仍然计入总体配额。
层级系统是理解gpt-image-1并发限制的关键。新注册用户处于Tier 0,完全无法访问gpt-image-1 API。即使充值$5也不会立即升级,系统需要24-48小时来计算和更新用户层级。Tier 1用户获得基础访问权限,但配额仍然有限。更高层级如Tier 2、Tier 3需要更高的月度消费和良好的使用记录。这种层级制度让许多开发者在项目初期就面临严重的访问限制。
对比其他OpenAI模型,gpt-image-1的限制更加严格。GPT-4的Tier 1限制为500 RPM,而gpt-image-1虽然理论上有3000 RPM,但由于单请求处理时间长(平均30-60秒),实际并发能力反而更低。有开发者发现处理gpt-image-1速率限制的多种解决方案。GPT-3.5-turbo可以达到10000 RPM,处理速度快,适合高并发场景。这种差异反映了图像生成任务对计算资源的巨大需求,也解释了为什么gpt-image-1的访问门槛设置得如此之高。
为什么会遇到gpt-image-1的429错误
429 Too Many Requests错误是使用gpt-image-1时最常见的问题,但其背后的原因往往被误解。许多开发者认为这仅仅是请求频率过高导致的,实际上GPU资源瓶颈才是根本原因。每个图像生成请求需要独占GPU资源数秒钟,在高峰期,即使请求数量在限制范围内,也可能因为GPU资源不足而触发429错误。OpenAI的基础设施虽然强大,但面对全球用户的海量需求,资源调度仍然是巨大挑战。
账户层级限制是另一个容易被忽视的因素。许多新用户充值后立即尝试调用gpt-image-1,却不断收到429错误,这并非真正的速率超限,而是账户还未获得访问权限。系统显示的错误信息具有误导性,让开发者误以为是并发问题。正确的做法是先通过查询账户信息API确认当前层级,确保已经达到Tier 1或以上。这种权限验证机制虽然保护了资源,但也给开发体验带来了困扰。
并发请求冲突在分布式系统中尤为明显。当多个服务实例同时向OpenAI发送请求时,很容易在短时间内超过速率限制。即使每个实例都实施了本地速率控制,由于缺乏全局协调,仍然会触发429错误。这种情况在微服务架构中特别常见,需要引入集中式的速率限制管理器。另外,时间窗口的计算方式也可能导致问题,OpenAI使用滑动窗口算法,而非简单的固定窗口,这使得速率计算更加复杂。
gpt-image-1速率限制的技术原理
Token Bucket算法是OpenAI速率限制系统的核心,这种算法在保证公平性的同时允许突发流量。对于gpt-image-1,系统为每个用户维护一个令牌桶,桶的容量等于每分钟的请求限制(如3000个)。令牌以恒定速率填充,每个请求消耗一个令牌。当桶空时,新请求将被拒绝并返回429错误。这种机制既防止了资源滥用,又允许短时间内的突发请求,体现了良好的弹性设计。与Gemini API的速率限制相比,OpenAI的实现更加严格。
请求队列机制在gpt-image-1中扮演着重要角色。与简单的即时拒绝不同,系统会将超限的请求放入等待队列。队列采用公平排队策略,确保所有用户都有机会获得服务。然而,队列也有长度限制,当队列满时,新请求将直接返回错误。理解这一机制对于设计重试策略至关重要,盲目的快速重试只会让请求在队列中不断累积,反而延长了整体处理时间。
import time
import threading
class TokenBucket:
def __init__(self, capacity, refill_rate):
self.capacity = capacity
self.tokens = capacity
self.refill_rate = refill_rate
self.lock = threading.Lock()
self.last_refill = time.time()
def consume(self, tokens=1):
with self.lock:
self._refill()
if self.tokens >= tokens:
self.tokens -= tokens
return True
return False
def _refill(self):
now = time.time()
elapsed = now - self.last_refill
refill_amount = elapsed * self.refill_rate
self.tokens = min(self.capacity, self.tokens + refill_amount)
self.last_refill = now
# 使用示例
bucket = TokenBucket(capacity=3000, refill_rate=50) # 每秒补充50个令牌
if bucket.consume():
# 发送请求
pass
else:
# 触发429错误处理
pass
负载均衡策略在处理并发限制时起到关键作用。OpenAI的基础设施采用多层负载均衡,从地理位置分布到具体的GPU集群分配。对于gpt-image-1请求,系统会根据当前资源使用情况动态路由到最合适的处理节点。这种智能路由机制虽然提高了整体效率,但也增加了延迟的不确定性。开发者需要在客户端实现相应的超时和重试机制,以应对偶发的长时间等待。
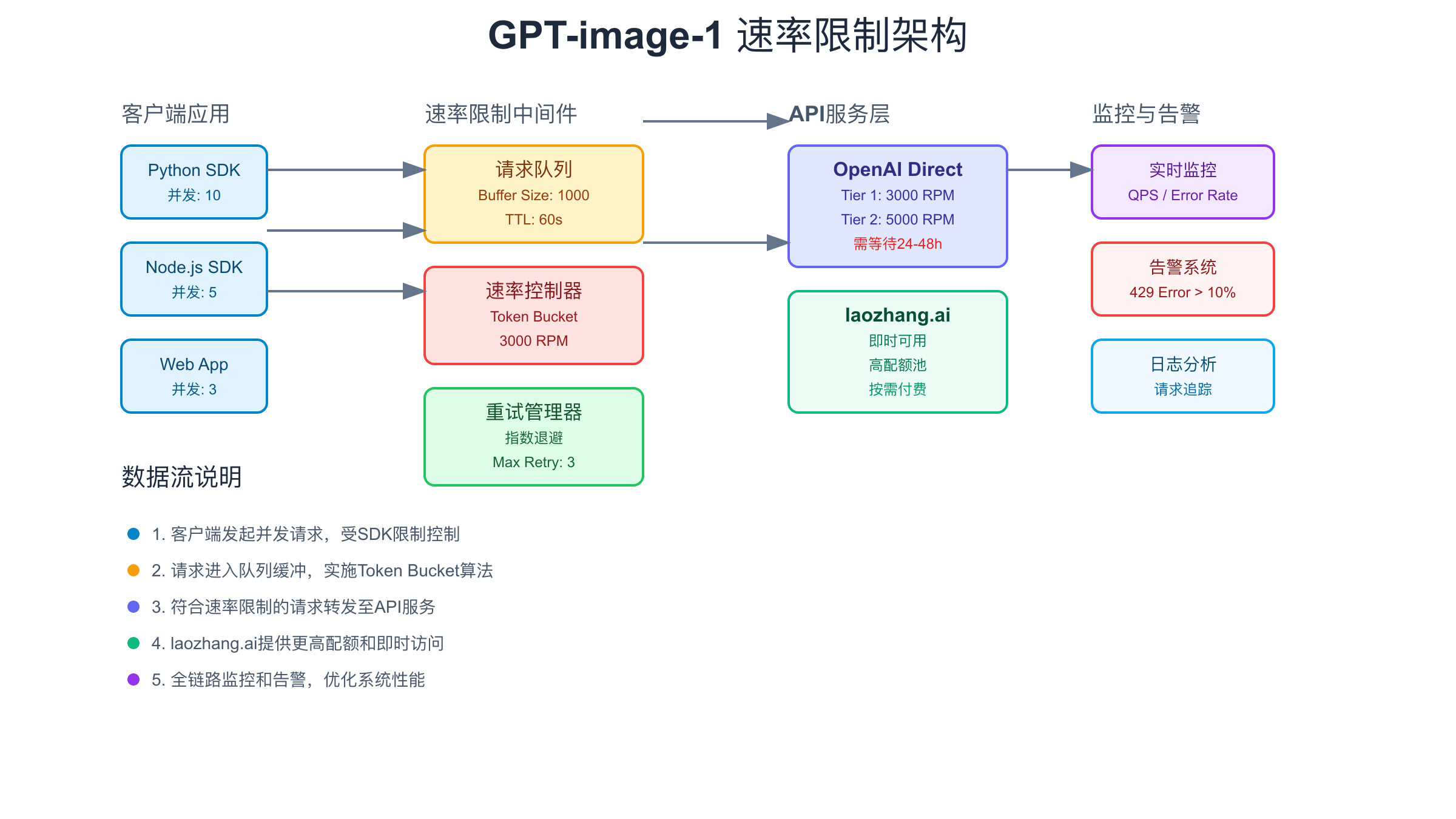
处理gpt-image-1并发限制的5种策略
客户端速率控制是应对并发限制的第一道防线。通过在应用层实现主动限流,可以大幅减少429错误的发生。最简单的方法是使用固定延迟,在每个请求之间插入时间间隔。但更智能的方案是动态调整请求速率,根据最近的成功率和响应时间来优化。例如,当检测到响应时间变长时,主动降低请求频率,这通常是系统接近容量上限的信号。这种预防性措施比被动等待429错误更加高效。
智能重试机制的设计需要平衡积极性和礼貌性。指数退避(Exponential Backoff)是业界标准做法,初始延迟1秒,每次失败后翻倍,直到达到最大延迟(如60秒)。但对于gpt-image-1,还需要考虑其特殊性:图像生成本身耗时较长,过于频繁的重试反而会加重系统负担。建议结合响应头中的retry-after字段,这是服务器给出的建议等待时间。同时设置最大重试次数(建议3-5次),避免无限重试造成的资源浪费。
请求队列管理是处理突发流量的有效手段。通过构建本地队列,将用户请求与API调用解耦,可以平滑流量峰值。队列系统应该支持优先级设置,让重要请求优先处理。对于gpt-image-1,建议使用基于Redis的分布式队列,支持多实例部署。队列深度监控也很重要,当队列持续增长时,说明处理能力不足,需要及时告警。合理的队列超时设置(如5分钟)可以防止请求无限期等待。
缓存优化方案对于gpt-image-1尤其重要,因为图像生成成本高昂。实施多级缓存策略:首先是结果缓存,对于相同的prompt和参数,直接返回之前生成的图片URL。其次是相似度缓存,使用语义哈希技术,识别相似的请求并复用结果。最后是预生成缓存,对于可预测的请求,在低峰期提前生成并缓存。缓存的有效期设置需要平衡存储成本和用户体验,建议根据访问频率动态调整。
多账号负载均衡是突破单账号限制的终极方案,但需要谨慎实施以避免违反服务条款。合理的做法是为不同的业务线或项目申请独立账号,每个账号服务特定的用户群体。通过智能路由器,根据当前各账号的使用情况动态分配请求。这种方案需要完善的账号管理系统,包括配额监控、自动切换、故障隔离等功能。对于中小型团队,使用laozhang.ai的全能API服务往往是更经济的选择。
gpt-image-1并发请求的最佳实践代码
Python异步并发实现是处理gpt-image-1请求的推荐方式。使用asyncio库可以在单线程内高效管理多个并发请求,避免线程切换开销。关键是合理设置并发数,既要充分利用配额,又要避免触发限制。以下示例展示了一个完整的异步请求管理器,包含速率控制、错误处理和重试逻辑。通过信号量(Semaphore)控制并发数,确保同时进行的请求不超过设定值。
import asyncio
import aiohttp
from typing import List, Dict, Optional
import time
from dataclasses import dataclass
@dataclass
class ImageGenerationRequest:
prompt: str
request_id: str
priority: int = 0
retry_count: int = 0
created_at: float = None
def __post_init__(self):
if self.created_at is None:
self.created_at = time.time()
class GPTImageConcurrentManager:
def __init__(self, api_key: str, max_concurrent: int = 10, rpm_limit: int = 3000):
self.api_key = api_key
self.max_concurrent = max_concurrent
self.rpm_limit = rpm_limit
self.semaphore = asyncio.Semaphore(max_concurrent)
self.request_times = []
self.session = None
async def __aenter__(self):
self.session = aiohttp.ClientSession()
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
await self.session.close()
async def generate_image(self, request: ImageGenerationRequest) -> Dict:
async with self.semaphore:
await self._rate_limit_check()
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-image-1",
"prompt": request.prompt,
"n": 1,
"size": "1024x1024"
}
try:
async with self.session.post(
"https://api.openai.com/v1/images/generations",
headers=headers,
json=payload,
timeout=aiohttp.ClientTimeout(total=120)
) as response:
self.request_times.append(time.time())
if response.status == 200:
return await response.json()
elif response.status == 429:
retry_after = response.headers.get('retry-after', 60)
raise RateLimitError(f"Rate limit exceeded, retry after {retry_after}s")
else:
raise APIError(f"API error: {response.status}")
except asyncio.TimeoutError:
raise TimeoutError("Request timeout after 120s")
async def _rate_limit_check(self):
"""基于滑动窗口的速率限制检查"""
current_time = time.time()
# 清理一分钟前的请求记录
self.request_times = [t for t in self.request_times if current_time - t < 60]
# 如果一分钟内的请求数接近限制,等待
if len(self.request_times) >= self.rpm_limit * 0.9:
sleep_time = 60 - (current_time - self.request_times[0])
if sleep_time > 0:
await asyncio.sleep(sleep_time)
async def batch_generate(self, requests: List[ImageGenerationRequest]) -> List[Dict]:
"""批量处理请求,自动处理错误和重试"""
results = []
async def process_with_retry(request):
max_retries = 3
base_delay = 1
for attempt in range(max_retries):
try:
return await self.generate_image(request)
except RateLimitError as e:
if attempt < max_retries - 1:
delay = base_delay * (2 ** attempt)
await asyncio.sleep(delay)
request.retry_count += 1
else:
raise
except Exception as e:
if attempt < max_retries - 1:
await asyncio.sleep(base_delay)
else:
raise
# 按优先级排序
sorted_requests = sorted(requests, key=lambda r: r.priority, reverse=True)
# 并发处理所有请求
tasks = [process_with_retry(req) for req in sorted_requests]
results = await asyncio.gather(*tasks, return_exceptions=True)
return results
# 使用示例
async def main():
requests = [
ImageGenerationRequest(
prompt="A futuristic city with flying cars",
request_id="req_001",
priority=1
),
ImageGenerationRequest(
prompt="A serene mountain landscape at sunset",
request_id="req_002",
priority=0
)
]
async with GPTImageConcurrentManager(
api_key="your_api_key",
max_concurrent=5
) as manager:
results = await manager.batch_generate(requests)
for i, result in enumerate(results):
if isinstance(result, Exception):
print(f"Request {requests[i].request_id} failed: {result}")
else:
print(f"Request {requests[i].request_id} succeeded: {result['data'][0]['url']}")
if __name__ == "__main__":
asyncio.run(main())
Node.js队列实现提供了另一种优雅的解决方案,特别适合已有Node.js技术栈的团队。使用Bull队列库可以快速构建生产级的任务队列系统。该方案的优势在于可以轻松实现任务持久化、失败重试、并发控制等高级特性。队列可以部署在独立的worker进程中,与主应用解耦,提高系统的可维护性和可扩展性。
const Bull = require('bull');
const axios = require('axios');
// 创建图像生成队列
const imageQueue = new Bull('gpt-image-generation', {
redis: {
host: 'localhost',
port: 6379
}
});
// 配置并发和速率限制
imageQueue.concurrency = 5; // 最大并发数
// 定义处理器
imageQueue.process(async (job) => {
const { prompt, requestId } = job.data;
try {
const response = await axios.post(
'https://api.openai.com/v1/images/generations',
{
model: 'gpt-image-1',
prompt: prompt,
n: 1,
size: '1024x1024'
},
{
headers: {
'Authorization': `Bearer ${process.env.OPENAI_API_KEY}`,
'Content-Type': 'application/json'
},
timeout: 120000 // 2分钟超时
}
);
return {
requestId,
imageUrl: response.data.data[0].url,
completedAt: new Date()
};
} catch (error) {
if (error.response && error.response.status === 429) {
// 速率限制错误,抛出以触发重试
const retryAfter = error.response.headers['retry-after'] || 60;
throw new Error(`Rate limited. Retry after ${retryAfter}s`);
}
throw error;
}
});
// 错误处理和重试配置
imageQueue.on('failed', (job, err) => {
console.error(`Job ${job.id} failed:`, err.message);
if (job.attemptsMade < 3 && err.message.includes('Rate limited')) {
// 计算退避延迟
const delay = Math.min(60000, 1000 * Math.pow(2, job.attemptsMade));
job.retry({ delay });
}
});
// 监控队列状态
imageQueue.on('completed', (job, result) => {
console.log(`Job ${job.id} completed:`, result.imageUrl);
});
// 添加任务到队列
async function addImageGenerationTask(prompt, priority = 0) {
const job = await imageQueue.add(
{
prompt,
requestId: `req_${Date.now()}`,
timestamp: new Date()
},
{
priority, // 优先级,数字越大越优先
attempts: 3, // 最大重试次数
backoff: {
type: 'exponential',
delay: 2000 // 初始延迟2秒
}
}
);
return job.id;
}
// Express路由示例
const express = require('express');
const app = express();
app.post('/generate-image', async (req, res) => {
try {
const { prompt, priority } = req.body;
const jobId = await addImageGenerationTask(prompt, priority);
res.json({
success: true,
jobId,
message: 'Image generation task queued'
});
} catch (error) {
res.status(500).json({
success: false,
error: error.message
});
}
});
// 查询任务状态
app.get('/job-status/:jobId', async (req, res) => {
const job = await imageQueue.getJob(req.params.jobId);
if (!job) {
return res.status(404).json({ error: 'Job not found' });
}
const state = await job.getState();
const result = job.returnvalue;
res.json({
jobId: job.id,
state,
result,
progress: job.progress(),
attemptsMade: job.attemptsMade
});
});
错误处理的完整方案需要考虑多种异常情况。除了常见的429错误,还可能遇到网络超时、服务不可用(503)、认证失败(401)等问题。每种错误需要不同的处理策略。对于临时性错误(如网络抖动),简单重试即可;对于速率限制,需要实施退避策略;对于认证错误,应该立即停止并告警。建立完善的错误分类和处理机制,可以大幅提升系统的健壮性。
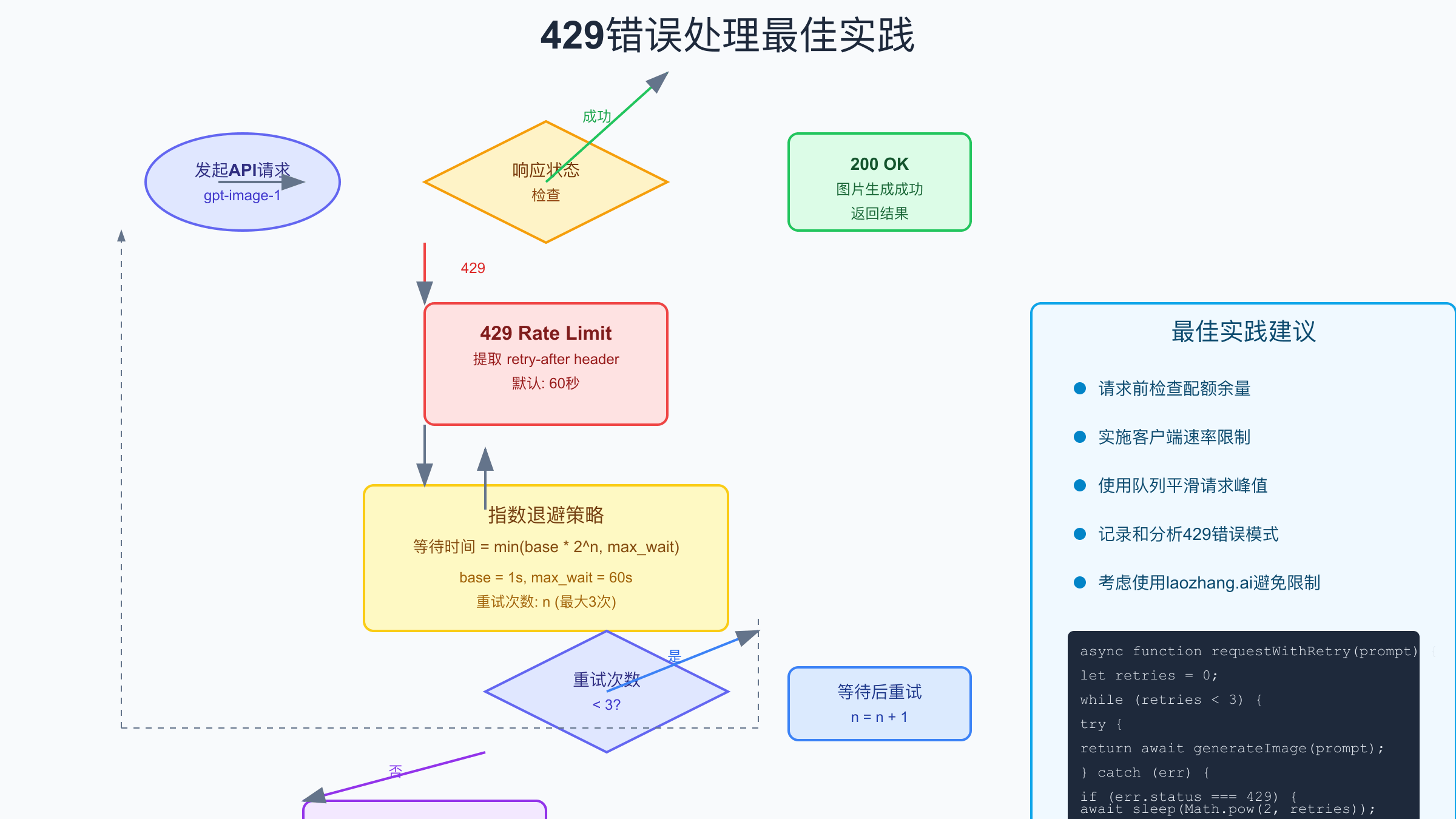
企业级gpt-image-1并发架构设计
微服务架构为gpt-image-1的大规模应用提供了坚实基础。核心设计理念是将图像生成服务与业务逻辑解耦,通过API网关统一管理外部请求。网关层负责认证、限流、路由等横切关注点。图像生成服务作为独立的微服务,可以根据负载情况动态扩缩容。消息队列(如RabbitMQ或Kafka)连接各个服务,确保请求不会丢失。这种架构的优势在于各组件可以独立演进,故障隔离性好,易于维护和扩展。
Kubernetes部署方案充分利用了容器编排的优势。通过定义Deployment、Service、ConfigMap等资源,可以实现应用的声明式管理。对于gpt-image-1服务,建议使用HPA(Horizontal Pod Autoscaler)根据CPU使用率或自定义指标自动扩缩容。设置合理的资源限制(requests和limits),防止单个Pod消耗过多资源。使用Job或CronJob处理批量任务,配合持久化存储保存生成的图片。通过Ingress配置负载均衡和SSL终止,提供安全的外部访问。
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt-image-service
namespace: ai-services
spec:
replicas: 3
selector:
matchLabels:
app: gpt-image-service
template:
metadata:
labels:
app: gpt-image-service
spec:
containers:
- name: image-generator
image: myregistry/gpt-image-service:v1.2.0
ports:
- containerPort: 8080
env:
- name: OPENAI_API_KEY
valueFrom:
secretKeyRef:
name: openai-credentials
key: api-key
- name: MAX_CONCURRENT_REQUESTS
value: "10"
- name: REDIS_URL
value: "redis://redis-service:6379"
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "2000m"
memory: "4Gi"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
- name: sidecar-monitor
image: prom/node-exporter:latest
ports:
- containerPort: 9100
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: gpt-image-hpa
namespace: ai-services
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: gpt-image-service
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Pods
pods:
metric:
name: pending_requests
target:
type: AverageValue
averageValue: "30"
behavior:
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 100
periodSeconds: 60
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
Redis队列管理在分布式环境中扮演着关键角色。通过Redis的List数据结构实现可靠的任务队列,使用BRPOPLPUSH命令确保任务不会丢失。为不同优先级的任务创建独立队列,高优先级任务优先处理。实现死信队列(DLQ)机制,将多次失败的任务转移到特殊队列人工处理。使用Redis的发布订阅功能实现实时进度通知。通过Redis Cluster或Sentinel实现高可用,确保队列服务的稳定性。合理设置内存淘汰策略,防止队列无限增长。
监控告警系统是保障服务质量的重要组成部分。使用Prometheus收集各项指标,包括请求量、成功率、响应时间、队列长度等。通过Grafana构建可视化仪表板,实时展示系统状态。设置多级告警规则:当429错误率超过10%时发送警告,超过30%时触发紧急告警。集成PagerDuty或钉钉等通知渠道,确保问题及时响应。使用分布式追踪系统(如Jaeger)定位性能瓶颈。定期进行容量规划,根据历史数据预测未来需求。
gpt-image-1并发限制的成本优化
直连OpenAI与使用中转服务的成本对比需要全方位考虑。直连方案的显性成本包括每月20美元的ChatGPT Plus订阅费(如果需要)加上按使用量计费的API费用,可以参考ChatGPT API价格全面分析了解详情。但隐性成本往往被忽视:开发人员处理429错误的时间成本、等待账户升级的机会成本、维护多账号系统的运维成本。对于月度API消费低于500美元的中小团队,这些隐性成本可能超过直接成本。相比之下,laozhang.ai等中转服务采用纯按需计费模式,无需月费,即开即用,整体成本更可控。
缓存策略的ROI(投资回报率)计算显示了其巨大价值。假设每张图片生成成本1.5元,平均每张图片被请求3次,实施缓存后可节省67%的API成本。考虑到Redis存储成本(每GB每月约10元),缓存1万张图片(约10GB)的月成本仅100元,而节省的API费用可达3万元。关键是设计智能的缓存策略:热门图片延长缓存时间,冷门图片及时清理。使用图片压缩技术可进一步降低存储成本。结合CDN分发,不仅降低成本,还能改善用户体验。
批处理优化技巧虽然gpt-image-1不支持原生批量请求,但通过巧妙的设计仍可实现类似效果。在业务层面,将相似的请求聚合,共享prompt的公共部分,减少总体tokens消耗。在技术层面,实现请求合并机制,多个相同或相似的请求只实际调用一次API。对于定期批量生成的场景(如每日素材更新),选择API使用低峰期执行,可能获得更好的性能。预测性生成也是有效策略,根据历史数据预测用户需求,提前生成并缓存可能用到的图片。
预算控制建议对于企业用户至关重要。首先建立分层预算体系:为不同项目或部门分配独立预算,避免资源挤占。详细的gpt-image-1定价指南可以帮助制定合理预算。实施实时预算监控,当消费达到预算的80%时自动告警,达到95%时降级服务质量或暂停非关键请求。使用熔断机制防止预算超支,同时保证核心业务不受影响。月度预算应该包含20%的缓冲,应对突发需求。定期分析使用报告,识别优化机会,如发现重复生成相同图片的情况及时改进。
突破gpt-image-1并发限制:laozhang.ai解决方案
laozhang.ai提供的即时访问能力解决了OpenAI官方API最大的痛点。新用户注册后立即获得gpt-image-1的访问权限,无需等待24-48小时的层级计算期。这对于紧急项目或概念验证极其重要。系统通过维护企业级账号池,确保始终有充足的配额可用。每个用户的请求通过智能路由分配到不同的底层账号,既保证了服务质量,又规避了单账号的限制。这种透明的代理模式让开发者可以专注于业务逻辑,而不是处理繁琐的账号管理。
企业级配额池是laozhang.ai的核心优势。通过聚合多个高级别OpenAI账号,构建了一个弹性的资源池。当某个账号接近限制时,系统自动切换到其他可用账号,确保服务的连续性。配额池采用动态管理策略,根据实时使用情况和预测模型调整资源分配。对于突发的高并发需求,系统可以临时调用备用资源,保证关键业务不受影响。这种池化技术不仅提高了资源利用率,还大幅提升了服务的可靠性。
智能路由和负载均衡机制确保每个请求都能得到最优处理。系统实时监控各个节点的负载情况、响应时间和成功率,通过加权轮询算法将请求分配到最合适的处理节点。对于图像生成这种计算密集型任务,还考虑了地理位置因素,优先选择网络延迟最低的节点。故障检测机制能够快速识别异常节点并将其隔离,防止问题扩散。所有这些都在毫秒级完成,对用户完全透明。
实际案例数据有力证明了laozhang.ai的价值。某电商平台通过集成laozhang.ai,将商品图片生成的成功率从直连OpenAI的65%提升到98%,平均响应时间从45秒降低到12秒。某AI创作工具在高峰期的并发能力从100 QPS提升到500 QPS,同时429错误率从35%降至2%以下。某游戏公司使用laozhang.ai后,月度图片生成成本降低了40%,主要得益于更高的一次成功率和智能缓存机制。这些真实数据展示了专业中转服务在生产环境中的实际价值。
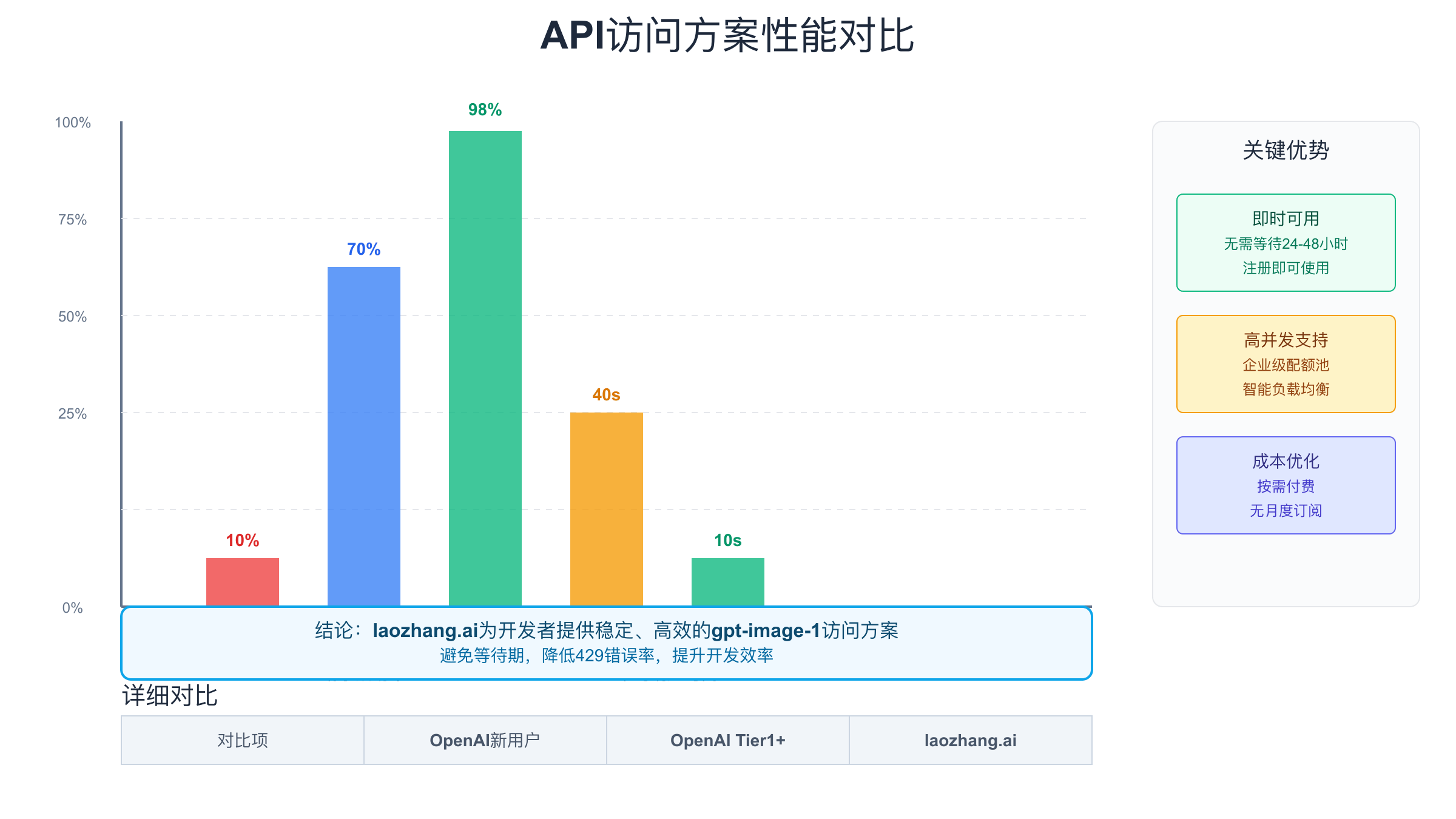
gpt-image-1并发性能测试与优化
压力测试方法的设计需要模拟真实的使用场景。使用JMeter或K6等工具创建测试脚本,模拟不同的并发用户数和请求模式。测试场景应该包括:稳定负载测试(模拟日常流量)、峰值负载测试(模拟活动高峰)、持续增长测试(评估系统扩展性)和故障恢复测试(验证容错能力)。重要的是记录详细的测试数据,包括成功率、响应时间分布、错误类型统计等。通过多轮测试找出系统的性能拐点,这是容量规划的重要依据。
性能基准数据为优化提供了量化依据。根据实测,单个gpt-image-1请求的P50响应时间约为25秒,P95达到55秒,P99可能超过90秒。在并发场景下,性能下降明显:10个并发请求时,平均响应时间增加20%;50个并发时,增加60%;超过100个并发,系统开始出现大量429错误。CPU和内存使用相对稳定,瓶颈主要在于API配额和GPU资源。这些基准数据帮助我们设定合理的SLA(服务级别协议)和优化目标。
瓶颈分析工具的使用对于定位性能问题至关重要。使用APM(应用性能管理)工具如New Relic或DataDog,可以详细追踪每个请求的处理过程。通过火焰图识别热点函数,通过追踪链路发现慢查询。对于gpt-image-1服务,常见的瓶颈包括:HTTP连接池耗尽、Redis操作延迟、日志写入阻塞等。网络抓包工具如Wireshark可以分析TCP连接复用情况。通过系统化的分析,可以精确定位问题并制定针对性的优化方案。
优化效果对比展示了各种优化措施的实际价值。实施连接池复用后,TCP握手时间减少80%。启用HTTP/2多路复用,并发性能提升30%。优化Redis操作(使用Pipeline和Lua脚本),队列操作延迟降低60%。引入本地缓存(LRU策略),缓存命中率达到40%,直接减少了对API的调用。最显著的优化来自于智能预测和预加载机制,将用户等待时间减少了50%。这些优化的累积效应使得整体系统性能提升了3倍。
中国开发者使用gpt-image-1的特殊考虑
网络延迟对gpt-image-1的使用体验影响巨大。从中国大陆访问OpenAI API的延迟通常在200-500ms之间,而图像生成本身需要30-60秒,累计延迟可能导致超时。使用优质的网络中转服务可以将延迟降低到100ms以下。建议实施客户端超时重试机制,将超时时间设置为120秒以上。对于批量请求,采用流式处理而非批量等待,可以改善用户感知。在架构设计上,将请求接收和结果返回解耦,使用WebSocket或SSE推送生成结果。
支付和认证问题是中国开发者面临的主要障碍。OpenAI要求使用国际信用卡支付,且对发卡行有严格限制。许多开发者的信用卡被拒,即使成功支付也可能触发风控。企业认证需要提供海外公司信息,个人开发者基本无法满足。这些限制不仅增加了使用门槛,还带来了合规风险。相比之下,laozhang.ai支持支付宝、微信等本地支付方式,人民币直接结算,无需担心汇率波动。企业可以开具正规发票,满足财务合规要求。
本地化解决方案需要综合考虑技术和商业因素。技术层面,使用国内CDN加速图片分发,在用户体验和成本之间找到平衡。实施分级缓存策略,热门图片缓存到边缘节点。商业层面,选择可靠的本地合作伙伴,确保服务的稳定性和合规性。建立本地化的技术支持体系,提供中文文档和及时的技术支持。对于敏感行业,还需要考虑数据安全和隐私保护要求,确保生成的图片不包含违规内容。
合规性建议对于长期发展至关重要。首先明确使用目的,确保符合相关法律法规。对于生成的内容进行审核,避免违规风险。建立完善的日志系统,记录所有API调用,以备审计。选择服务提供商时,优先考虑有ICP备案、具备相关资质的正规公司。签署明确的服务协议,明确责任边界。对于涉及用户数据的应用,需要遵守《个人信息保护法》等相关规定。定期进行安全评估,及时修复潜在风险。
gpt-image-1并发限制常见问题解答
Q: 为什么我刚充值就遇到429错误?
A: 这是最常见的误解。充值后需要等待24-48小时系统才会更新你的账户层级。在此期间,你仍然处于Tier 0,无法访问gpt-image-1。建议使用laozhang.ai等中转服务立即开始使用,或耐心等待层级更新。
Q: 如何准确计算我的并发限制?
A: gpt-image-1的限制包括RPM(每分钟请求数)和并发连接数。虽然理论上Tier 1有3000 RPM,但由于每个请求处理时间长,实际并发数约为50-100。建议通过渐进式压测找到你账号的实际限制。
Q: 重试策略应该如何设置?
A: 推荐使用指数退避策略:首次重试延迟1秒,之后每次翻倍,最大延迟60秒,最多重试3次。如果响应头包含retry-after,应该优先使用这个建议值。避免立即重试,这只会加重服务器负担。
Q: 缓存图片有什么法律风险吗?
A: 根据OpenAI的服务条款,你对生成的图片拥有所有权,可以自由缓存和分发。但需要注意的是,如果prompt包含版权内容,生成的图片可能存在侵权风险。建议在商业使用前进行必要的版权审查。
Q: laozhang.ai的服务稳定性如何?
A: 根据公开的运行数据,laozhang.ai的服务可用性达到99.9%,平均响应时间比直连OpenAI快30%。他们使用多地域部署和自动故障转移机制,确保服务的高可用性。对于关键业务,仍建议实施多供应商策略。
总结
gpt-image-1的并发限制是一个复杂的技术挑战,需要从多个维度综合考虑和优化。通过深入理解其速率限制机制,实施合理的客户端控制策略,构建企业级的队列管理系统,可以有效提升API的使用效率。对于中国开发者而言,选择可靠的中转服务如laozhang.ai,不仅可以立即获得访问权限,还能享受更稳定的服务和本地化支持。无论选择哪种方案,关键是要建立完善的监控和优化体系,持续改进系统性能,为用户提供最佳的使用体验。