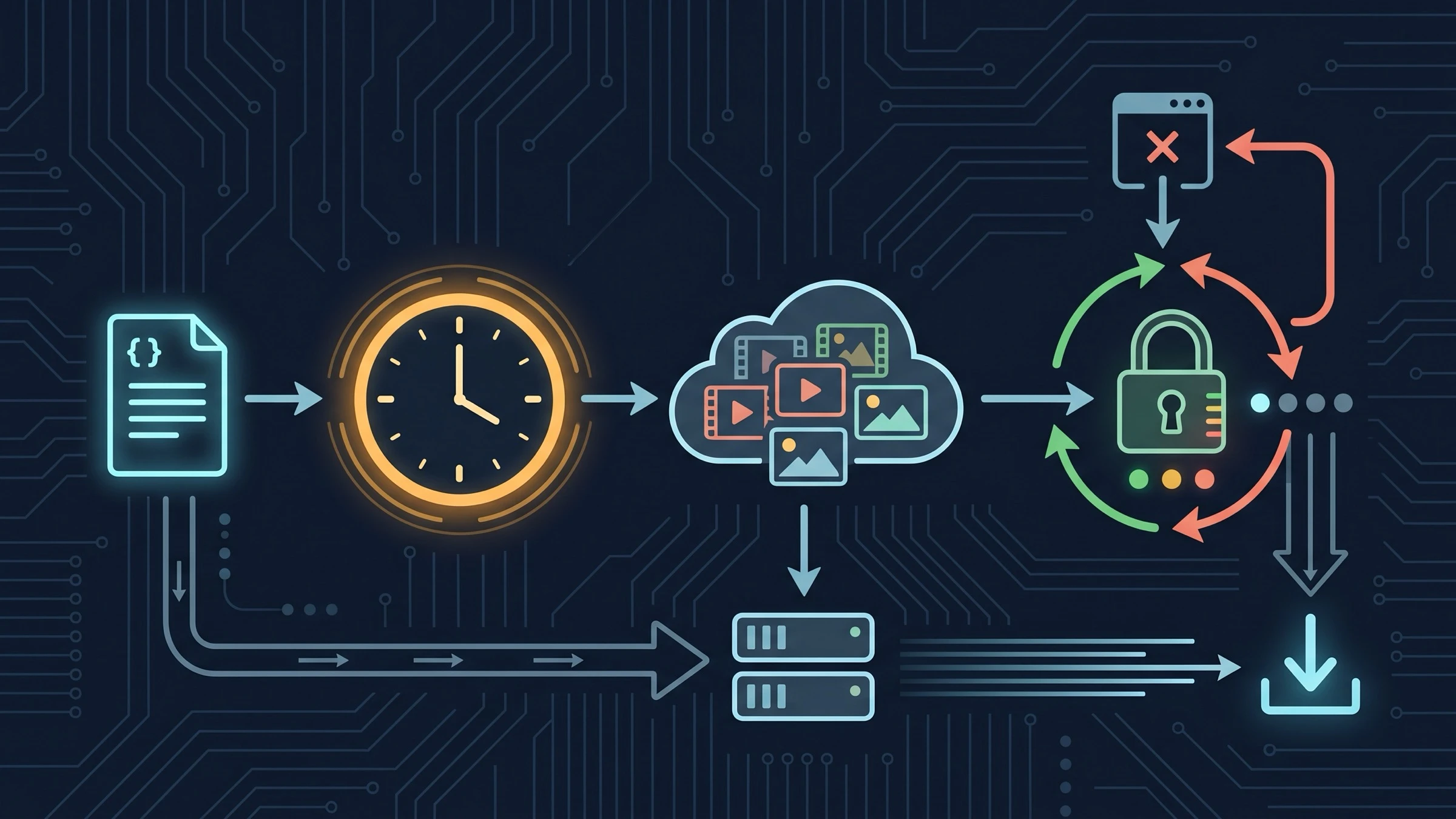
Seedance 2.0 API не возвращает финальное видео сразу. Это асинхронная задача: приложение отправляет запрос на создание, сохраняет provider task ID, проверяет статус или принимает callback, а после succeeded копирует content.video_url в собственное хранилище.
Для международного маршрута BytePlus ModelArk endpoint создания задачи выглядит так: https://ark.ap-southeast.bytepluses.com/api/v3/contents/generations/tasks. Модели Seedance 2.0: dreamina-seedance-2-0-260128 и dreamina-seedance-2-0-fast-260128. Для китайского Volcengine Ark используйте региональный endpoint и doubao-* model IDs; эти маршруты нельзя смешивать в одной конфигурации.
Отправьте одну задачу
Create call должен быть единственным местом, где реально запускается генерация. До отправки проверьте prompt, модель, references, ratio, resolution, duration, audio и callback URL. После ответа сохраните provider task ID вместе с локальным job ID, request hash, пользователем и параметрами результата.
bashcurl -X POST "https://ark.ap-southeast.bytepluses.com/api/v3/contents/generations/tasks" \ -H "Authorization: Bearer $ARK_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "dreamina-seedance-2-0-260128", "content": [ { "type": "text", "text": "A quiet product demo shot, slow camera move, clean studio light" } ], "ratio": "16:9", "resolution": "720p", "duration": 5, "generate_audio": false, "return_last_frame": true, "callback_url": "https://example.com/webhooks/seedance" }'
Если HTTP-запрос оборвался после отправки, не создавайте новую задачу вслепую. Сначала найдите локальный job по request hash. Если task ID уже сохранён, продолжайте проверку статуса; если ID точно нет, повторите создание в рамках того же job.
Проверяйте статус или принимайте callback
Статусы Seedance лучше хранить как state machine:
| Status | Что означает | Что делать |
|---|---|---|
queued | Задача принята | Ждать с backoff |
running | Видео генерируется | Продолжать проверку статуса |
succeeded | Результат готов | Скопировать content.video_url |
failed | Ошибка провайдера | Сохранить code и message |
expired | Время выполнения истекло | Решить, можно ли перезапустить |
cancelled | Задача отменена | Остановить проверку статуса |
bashcurl -X GET \ "https://ark.ap-southeast.bytepluses.com/api/v3/contents/generations/tasks/$TASK_ID" \ -H "Authorization: Bearer $ARK_API_KEY"
Callback даёт быстрые обновления, но резервная проверка статуса всё равно нужна как путь восстановления. Она закрывает пропущенные webhooks, деплои и временные ошибки валидации callback.
Скачайте и сохраните результат
После успеха content.video_url указывает на временный MP4. Не делайте его постоянной ссылкой для пользователя. Официальный контракт ответа говорит, что сгенерированное видео очищается через 24 часа, поэтому копируйте файл в своё object storage сразу.
tsasync function saveSeedanceVideo(job, task) { const url = task.content?.video_url; if (!url) throw new Error("Seedance succeeded without video_url"); const res = await fetch(url); if (!res.ok) throw new Error(`download failed: ${res.status}`); await storage.putObject({ key: `seedance/${job.id}/output.mp4`, body: res.body, contentType: "video/mp4", }); }
Сохраняйте provider payload: model, status, seed, ratio, resolution, duration, generate_audio и usage.total_tokens. Это помогает в поддержке, биллинге и воспроизведении результата.
Передавайте references через content
References в Seedance 2.0 не являются произвольными вложениями. Массив content определяет режим генерации. Для first-frame используйте first_frame; для first-and-last-frame используйте first_frame и last_frame; для multimodal references используйте reference_image, reference_video и reference_audio.
json{ "model": "dreamina-seedance-2-0-260128", "content": [ { "type": "text", "text": "Use [image 1] as the product reference and keep the motion minimal." }, { "type": "image_url", "image_url": { "url": "https://cdn.example.com/reference-product.webp" }, "role": "reference_image" } ], "ratio": "16:9", "duration": 5, "generate_audio": false }
До отправки проверяйте формат, размер, длительность и права на media. Audio нельзя отправлять отдельно; нужен хотя бы один image или video reference. Если в workflow есть реальные люди, проверку согласия нужно делать до API-вызова.
Делайте повторы идемпотентными
Самая дорогая ошибка - создать две платные генерации для одного job. Соберите request hash из маршрута, model ID, нормализованного prompt, reference URLs или asset IDs, выходных параметров и user ID. Если job с таким hash уже есть, верните его вместо нового create call.
| Операция | Правило retry |
|---|---|
| Create без task ID | Повторять только после проверки job и hash |
| Create с сохранённым task ID | Не отправлять снова; продолжать проверку статуса |
| Polling | Повторять с backoff |
| Callback | Обработка должна быть идемпотентной |
| Download | Повторять до истечения временной ссылки |
| Failed task | Сначала классифицировать ошибку |
FAQ
API синхронный?
Нет. Create возвращает task ID; MP4 появляется позже в content.video_url.
Что лучше: проверка статуса или callback?
Используйте callback для скорости и проверку статуса для восстановления. Система только на callback легко теряет задачи во время deploy или сетевых сбоев.
Можно ли хранить video_url как постоянную ссылку?
Нет. Это временная ссылка, и видео очищается через 24 часа. Скопируйте файл в своё хранилище.
Что делать при timeout на create?
Найдите локальный job по request hash. Если provider task ID уже есть, продолжайте проверку статуса; если ID нет, повторите create в рамках того же job.