Когда Google возвращает сообщение «серверные мощности исчерпаны», на самом деле речь идёт об одной из трёх совершенно разных ситуаций, и решение полностью зависит от того, какой именно тип ошибки вы получили. По состоянию на февраль 2026 года Gemini API от Google обслуживает миллионы разработчиков по всему миру, однако количество ошибок, связанных с мощностями, резко возросло с декабря 2025 года, когда Google значительно сократил квоты бесплатного тарифа. Это руководство охватывает все три типа ошибок с проверенными данными и конкретными решениями, чтобы вы могли вернуться к разработке за считанные минуты.
Краткое содержание
Ошибки мощностей Google делятся на три категории: HTTP 429 лимит запросов (вы превысили квоту — решение: уменьшить количество запросов или повысить тариф), HTTP 429 мощности исчерпаны (серверы Google перегружены — переключитесь на другую модель или используйте прокси), и HTTP 503 нет мощностей (модель полностью недоступна — подождите или используйте альтернативного провайдера). Большинство статей смешивают все три типа, из-за чего разработчики применяют неправильные решения. Самый быстрый способ исправить ошибки лимита запросов — включить Cloud Billing, что мгновенно повышает вас с 5 RPM до 150+ RPM без каких-либо предварительных затрат.
Что на самом деле означает «Серверные мощности Google исчерпаны»
Сообщение об ошибке «серверные мощности Google исчерпаны» стало одной из самых частых проблем с Gemini API в начале 2026 года, и не без причины. Тема на Reddit, опубликованная 21 февраля 2026 года в разделе r/Bard, набрала более 50 комментариев за 24 часа, причём разработчики сообщали, что не могут использовать даже базовые функции Gemini. Но это сообщение об ошибке крайне расплывчато, поскольку объединяет несколько принципиально разных проблем в одну фразу, которая почти ничего не говорит о том, что именно пошло не так и как это исправить.
Чтобы понять, что происходит, нужно знать, что Gemini API от Google работает на основе многоуровневой системы квот, где каждому проекту разработчика выделяется определённое количество запросов в минуту (RPM), токенов в минуту (TPM) и запросов в день (RPD). Когда вы превышаете любой из этих лимитов, Google возвращает ошибку HTTP 429. Однако совершенно другая проблема возникает, когда серверы самого Google не располагают достаточными вычислительными мощностями для обработки общего спроса от всех пользователей. В этом случае вы можете получить ошибку 429 или даже 503, несмотря на то что находитесь в рамках своей персональной квоты. Эти два сценария требуют совершенно разных решений, и применение неправильного подхода тратит ваше время, пока приложение остаётся неработоспособным.
Путаница усилилась после 7 декабря 2025 года, когда Google значительно снизил квоты бесплатного тарифа. До этой даты модель Gemini Flash предлагала примерно 250 запросов в день на бесплатном тарифе. После изменения некоторые конфигурации получили снижение до 20-50 RPD. Тысячи автоматизаций, чат-ботов и проектов разработки, которые прекрасно работали, сломались за одну ночь, заполнив форумы и трекеры ошибок жалобами. Ситуацию усугубило то, что Google заранее не сообщил об изменениях, и разработчикам пришлось узнавать о них по собственным логам ошибок.
Хронология инцидентов выявляет устойчивую закономерность, а не единичные случаи. В ноябре 2025 года несколько разработчиков на официальном форуме Google AI сообщили о получении ошибок 429 на аккаунтах Tier 1, хотя их потребление составляло менее 1% от заявленной квоты. Представитель Google по работе с разработчиками по имени Chunduri V признал проблему и заявил, что команда «выпустила исправление» 18 декабря 2025 года. Тем не менее к февралю 2026 года аналогичная картина повторилась: появились сообщения о «No capacity available for model gemini-2.5-pro» в виде issue на GitHub-репозитории google-gemini. Эта закономерность указывает на то, что инфраструктура Gemini от Google переживает трудности роста, поскольку спрос опережает скорость развёртывания новых кластеров GPU.
Последствия затрагивают не только отдельных разработчиков. Целые компании, построившие свои продукты на основе Gemini API от Google, оказались в кризисной ситуации, когда в декабре изменились квоты. Стартапы, запустившиеся на бесплатном доступе в период бета-тестирования, были вынуждены либо оплачивать доступ Tier 1, либо перепроектировать свои приложения для работы в рамках значительно сниженных лимитов. Эта ситуация подчёркивает более широкую проблему экосистемы AI API: разрыв между тем, что обещают бесплатные тарифы при регистрации, и тем, что они предоставляют при масштабировании, зачастую гораздо больше, чем ожидают разработчики, а изменения могут происходить без должного уведомления.
Понимание этого контекста критически важно, потому что это означает, что ошибка, которую вы видите прямо сейчас, может быть вообще не вашей виной. Первый шаг в её устранении — правильно диагностировать, какой из трёх типов ошибок вы получили, что и описано в следующем разделе.
3 типа ошибок мощностей Google (и как их отличить)

Большинство руководств по устранению неполадок рассматривают все ошибки мощностей Google как одну и ту же проблему, что равносильно ремонту спущенного колеса и сломанного двигателя по одной и той же инструкции. Сообщение об ошибке в ваших логах содержит конкретные ключевые слова, которые точно указывают на тип проблемы, и каждый тип имеет принципиально разную причину и решение. Вот как диагностировать свою ошибку менее чем за 30 секунд, проверив HTTP-код состояния и тело сообщения об ошибке.
Тип A: ошибка лимита запросов (HTTP 429 — RESOURCE_EXHAUSTED) является наиболее распространённым типом и означает, что ваш конкретный проект превысил одну из выделенных квот. Тело ответа об ошибке будет содержать фразу «Resource has been exhausted» или упоминание «quota exceeded». Это происходит, когда ваше приложение отправляет больше запросов в минуту, чем позволяет ваш тариф, когда вы превышаете дневной лимит запросов или когда вы достигаете потолка токенов в минуту при больших промптах. Критически важно понимать, что ошибки Типа A полностью под вашим контролем. Вы можете снизить частоту запросов, оптимизировать промпты для использования меньшего количества токенов или перейти на более высокий тариф с большими квотами.
Тип B: ошибка исчерпания мощностей (HTTP 429 — MODEL_CAPACITY_EXHAUSTED) на первый взгляд похожа на Тип A, поскольку также возвращает код состояния HTTP 429. Однако тело сообщения об ошибке отличается и будет содержать «MODEL_CAPACITY_EXHAUSTED» или «You have exhausted your capacity on this model». Эта ошибка означает, что серверы Google для данной конкретной модели находятся под высокой нагрузкой и не могут принимать новые запросы ни от кого, независимо от тарифа или оставшейся квоты. Даже платные пользователи Tier 1 и Tier 2 сталкиваются с ошибками Типа B в периоды пикового спроса. Вы не можете исправить это, снизив частоту запросов, потому что проблема на стороне Google, а не на вашей.
Тип C: ошибка недоступности сервера (HTTP 503 — No Capacity Available) является наиболее серьёзной и означает, что модель полностью недоступна на серверах Google. Сообщение об ошибке будет содержать «No capacity available for model {model_name} on the server». В отличие от Типа B, где мощности ограничены, Тип C означает полное отсутствие мощностей. Это обычно происходит во время крупных сбоев, обслуживания инфраструктуры или когда определённая версия модели устарела или обновляется. Показательный пример произошёл 16 февраля 2026 года, когда несколько пользователей сообщили об ошибках 503 для gemini-2.5-pro, которые длились несколько часов.
Процесс диагностики прост. Сначала проверьте HTTP-код состояния: если это 429, у вас Тип A или Тип B. Если это 503, у вас Тип C. Чтобы отличить Тип A от Типа B при ответе 429, изучите тело сообщения об ошибке. Если в нём упоминается «quota» или «RESOURCE_EXHAUSTED», это Тип A. Если упоминается «MODEL_CAPACITY_EXHAUSTED» или «capacity», это Тип B. Это различие чрезвычайно важно, потому что решения совершенно разные. Применение решения Типа A, такого как снижение частоты запросов, к проблеме Типа B ничего не даст, потому что вы изначально не превышали свою квоту. Для детального сравнения того, как разные модели Gemini обрабатывают эти лимиты, ознакомьтесь с нашим сравнением новейших моделей Gemini 3, которое охватывает последние варианты моделей и их характеристики мощностей.
| Тип ошибки | HTTP-код | Ключевое сообщение | Чья проблема? | Основное решение |
|---|---|---|---|---|
| Тип A: лимит запросов | 429 | «RESOURCE_EXHAUSTED» | Ваша | Уменьшить запросы или повысить тариф |
| Тип B: мощности | 429 | «MODEL_CAPACITY_EXHAUSTED» | Сменить модель или использовать прокси | |
| Тип C: сервер недоступен | 503 | «No capacity available» | Подождать или использовать альтернативного провайдера |
Быстрые решения для ошибок лимита запросов (HTTP 429 RESOURCE_EXHAUSTED)
Если вы диагностировали ошибку лимита запросов Типа A, хорошая новость в том, что она полностью устранима с вашей стороны. Следующие решения расположены от самых быстрых до наиболее комплексных, чтобы вы могли начать с немедленных исправлений и внедрять более надёжные решения по мере развития вашего приложения. Все примеры кода ниже протестированы с Gemini API по состоянию на февраль 2026 года.
Реализуйте экспоненциальную задержку с джиттером. Наиболее эффективное немедленное решение для ошибок лимита запросов — добавление механизма повторных попыток, который последовательно увеличивает время ожидания между попытками с добавлением рандомизации для предотвращения эффекта «стада». Когда ваше приложение получает ответ 429, вместо немедленного повтора или отказа оно ожидает базовую задержку, которая удваивается с каждой последующей неудачей, плюс случайное смещение. Этот подход работает, потому что окна лимитов обычно измеряются 60-секундными интервалами, и краткая пауза часто достаточна для обновления вашей квоты.
pythonimport time import random import google.generativeai as genai def call_with_backoff(prompt, max_retries=5): for attempt in range(max_retries): try: model = genai.GenerativeModel("gemini-2.5-flash") response = model.generate_content(prompt) return response except Exception as e: if "429" in str(e) and attempt < max_retries - 1: delay = (2 ** attempt) + random.uniform(0, 1) print(f"Rate limited. Waiting {delay:.1f}s...") time.sleep(delay) else: raise e
Оптимизируйте использование токенов. Каждый запрос потребляет токены из вашей квоты TPM (токенов в минуту), и большие промпты могут исчерпать этот лимит быстрее, чем ваш лимит RPM. Пересмотрите свои промпты и удалите ненужный контекст, инструкции, которые модель уже выполняет по умолчанию, и многословные системные сообщения. Для приложений, включающих историю разговора, реализуйте скользящее окно, которое хранит только последние обмены, а не отправляет весь разговор каждый раз. Сокращение среднего промпта с 2000 токенов до 500 фактически увеличивает вашу пропускную способность в четыре раза в рамках той же квоты TPM.
Группируйте и ставьте в очередь ваши запросы. Если ваше приложение выполняет множество мелких независимых вызовов API, рассмотрите возможность их объединения. Вместо отправки 20 отдельных запросов на резюмирование 20 параграфов объедините их в один промпт, который обрабатывает все 20 сразу. Для приложений, которые не могут группировать запросы, реализуйте очередь запросов с ограничителем скорости, который применяет лимит RPM вашего тарифа на стороне клиента. Это предотвращает всплески запросов, которые вызывают срабатывание лимита, и сглаживает использование API на протяжении всего минутного окна.
Повысьте тариф, включив Cloud Billing. Это наиболее значительное изменение для разработчиков, использовавших бесплатный тариф. Согласно официальной документации Google по лимитам запросов (проверено в феврале 2026 года), простое включение Cloud Billing в вашем проекте Google Cloud мгновенно повышает вас с бесплатного тарифа до Tier 1 без минимальных затрат. Улучшение впечатляющее: ваш RPM увеличивается с 5 (для Gemini 2.5 Pro) до 150-300, TPM возрастает с 250 000 до 1 000 000, а RPD — со 100 до 1000-1500. Вы платите только за фактическое использование, и для многих рабочих нагрузок разработки стоимость минимальна. Для детального разбора лимитов запросов Gemini API по тарифам, включая инструкции по включению биллинга и стоимости каждого тарифа, ознакомьтесь с нашим специальным руководством по лимитам.
Переключитесь на более лёгкую модель. Если вы используете Gemini 2.5 Pro и сталкиваетесь с лимитами, рассмотрите, подойдёт ли для вашего сценария Gemini 2.5 Flash или Flash-Lite. На бесплатном тарифе Flash предлагает 10 RPM (вдвое больше, чем 5 RPM у Pro) и 250 RPD (в 2,5 раза больше 100 RPD у Pro), а Flash-Lite — 15 RPM и 1000 RPD. Для многих задач, таких как резюмирование, классификация и простые вопросы-ответы, модели Flash обеспечивают сопоставимое качество при значительно большей пропускной способности и меньшей стоимости.
Система квот Google: бесплатный тариф vs платные тарифы в 2026 году

Понимание многоуровневой системы квот Google необходимо для планирования использования API и предотвращения неожиданных ошибок мощностей. Система существенно изменилась в конце 2025 — начале 2026 года, и многие статьи в интернете по-прежнему ссылаются на устаревшие данные. Приведённые ниже данные проверены на основе официальной документации Google AI Studio по состоянию на 19 февраля 2026 года.
Google организует доступ к Gemini API в четыре тарифа: Free (бесплатный), Tier 1, Tier 2 и Tier 3. Каждый тариф предоставляет прогрессивно более высокие лимиты запросов, а деньги взимаются только по модели оплаты за использование после бесплатного тарифа. Переход между тарифами предусматривает автоматическое повышение лимитов по мере увеличения ваших расходов, но этот переход не всегда мгновенный и зависит от вашей истории платежей за скользящий 30-дневный период.
Бесплатный тариф не требует настройки биллинга вообще и доступен в поддерживаемых странах. По состоянию на февраль 2026 года он предоставляет Gemini 2.5 Pro с 5 RPM и 100 RPD, Gemini 2.5 Flash с 10 RPM и 250 RPD, а также Gemini 2.5 Flash-Lite с 15 RPM и 1000 RPD. Все модели бесплатного тарифа имеют общий лимит 250 000 TPM. Эти цифры представляют собой существенное снижение по сравнению с уровнями до декабря 2025 года, когда одна только модель Flash предлагала примерно 250 RPD в некоторых конфигурациях. Это снижение застало многих разработчиков врасплох и является главной причиной всплеска сообщений об ошибках мощностей в начале 2026 года.
Tier 1 доступен любому с активным Cloud Billing в проекте Google Cloud без требований к минимальным расходам. Этот тариф предоставляет 150-300 RPM в зависимости от модели, 1 000 000 TPM и 1000-1500 RPD. Скачок с бесплатного тарифа на Tier 1 представляет собой 30-60-кратное увеличение квоты RPM, что делает его самым значительным изменением, которое вы можете внести при возникновении ошибок лимита запросов на бесплатном тарифе. Ценообразование следует стандартной модели Google с оплатой за использование: например, Gemini 2.5 Flash стоит $0,30 за миллион входных токенов и $2,50 за миллион выходных токенов (ai.google.dev/pricing, февраль 2026). Для типичного чат-бота, отправляющего промпты из 500 токенов и получающего ответы из 1000 токенов, это составляет примерно $0,0028 за один обмен, что означает, что за доллар вы получаете около 350 взаимодействий.
Tier 2 требует совокупных расходов более $250 за 30-дневный период и предоставляет 1000+ RPM с индивидуальными лимитами TPM и RPD. Tier 3 требует более $1000 расходов за 30 дней и предлагает максимально доступные лимиты. Оба высших тарифа актуальны в первую очередь для продуктивных приложений со значительным трафиком, и Google работает с такими клиентами над индивидуальным планированием мощностей. Для полного руководства по лимитам бесплатного тарифа Gemini API, включая доступность по странам и инструкции по настройке биллинга, ознакомьтесь с нашим специальным руководством по бесплатному тарифу.
| Тариф | Требование | RPM | TPM | RPD | Стоимость |
|---|---|---|---|---|---|
| Free | Без биллинга | 5-15 | 250K | 100-1 000 | Бесплатно |
| Tier 1 | Cloud Billing включён | 150-300 | 1M | 1 000-1 500 | Оплата за использование |
| Tier 2 | $250+ расходов / 30 дней | 1 000+ | Индивидуально | Индивидуально | Оплата за использование |
| Tier 3 | $1 000+ расходов / 30 дней | Максимальный | Индивидуально | Индивидуально | Оплата за использование |
Часто упускаемая деталь заключается в том, что лимиты запросов применяются к проекту, а не к API-ключу. Это означает, что если у вас несколько приложений используют один проект Google Cloud, все они расходуют квоту из одного пула. Создание отдельных проектов для отдельных приложений гарантирует, что всплеск трафика от одного приложения не лишит другие их выделенных ресурсов. Это простое организационное изменение может предотвратить множество неожиданных ошибок лимита запросов.
Устранение ошибок «No Capacity Available» (HTTP 503)
Ошибки Типа B (429 MODEL_CAPACITY_EXHAUSTED) и Типа C (503 No Capacity Available) принципиально отличаются от ошибок лимита запросов, поскольку указывают на проблему в инфраструктуре Google, а не в вашем использовании. Когда серверы Google не справляются с общим спросом от всех пользователей на конкретную модель, даже разработчики с достаточным запасом квоты будут получать такие ошибки. Этот раздел описывает, что делать, когда проблема на стороне Google — сценарий, который большинство руководств по устранению неполадок либо полностью игнорируют, либо смешивают с лимитами запросов.
Первое, что нужно понять о серверных ошибках мощностей — они, как правило, временные и региональные. Инфраструктура Gemini от Google распределена по нескольким дата-центрам, и ограничения мощностей часто затрагивают конкретные регионы или версии моделей, а не весь сервис глобально. Ошибка 503 для gemini-2.5-pro может разрешиться в течение нескольких минут, если она вызвана временным всплеском спроса, или сохраняться в течение нескольких часов при более масштабной проблеме инфраструктуры. Инцидент 16 февраля 2026 года, зарегистрированный на GitHub-репозитории google-gemini, является хорошим примером последнего случая, когда модель gemini-2.5-pro была недоступна в течение нескольких часов, прежде чем Google устранил основную проблему инфраструктуры.
Когда вы сталкиваетесь с ошибкой Типа B или Типа C, ваш немедленный ответ должен заключаться в проверке страницы статуса Google AI Studio и панели статуса Google Cloud. Эти страницы сообщают об известных сбоях и ожидаемом времени их устранения. Если отчёта о сбое нет, проблема, вероятно, заключается в локальном давлении на мощности, которое разрешится само. В любом случае реализация интеллектуальной стратегии повторных попыток, различающей пользовательские лимиты запросов и серверные ошибки мощностей, имеет решающее значение. Для лимитов запросов (Тип A) хорошо работают короткие повторы с экспоненциальной задержкой, потому что лимит быстро обновляется. Для проблем с мощностями (Типы B и C) более подходящи длительные интервалы повтора в 30-60 секунд, поскольку ограничение связано с физической доступностью серверов, а не со счётчиком квот.
Переключитесь на другой вариант модели. Наиболее эффективное немедленное решение для ошибок мощностей — попробовать более лёгкую модель. Если gemini-2.5-pro возвращает ошибку мощностей, попробуйте вместо неё gemini-2.5-flash. Google выделяет значительно больше вычислительных мощностей для моделей Flash, поскольку они требуют меньше ресурсов на запрос, так что Flash редко испытывает те же ограничения мощностей, что и Pro. Для многих приложений разница в качестве между Pro и Flash меньше, чем ожидают разработчики, особенно для простых задач вроде классификации текста, резюмирования и извлечения структурированных данных.
Попробуйте другое поколение модели. Google одновременно обслуживает несколько поколений моделей Gemini. Если мощности 2.5 Pro исчерпаны, попробуйте 2.0 Flash или даже более новый 3.0 Flash Preview. Выделение мощностей для каждого поколения модели независимо, поэтому ограничение одной версии не обязательно влияет на другие. Этот подход особенно хорошо работает, если ваше приложение не зависит от функций, уникальных для конкретной версии модели.
Реализуйте проверку работоспособности и автоматическое переключение. Для продуктивных приложений, которые не могут допустить простоя, реализуйте периодическую проверку работоспособности, отправляющую минимальный тестовый запрос к основной модели каждые 30-60 секунд. Когда проверка завершается ошибкой мощностей, автоматически перенаправляйте новые запросы к резервному провайдеру или модели. Когда проверка снова проходит успешно, постепенно возвращайте трафик на основную модель. Этот паттерн обеспечивает практически нулевой простой даже при длительных проблемах мощностей Google и особенно важен для клиентских приложений, где ошибки API напрямую превращаются в потерю дохода или ухудшение пользовательского опыта.
Стоит также отметить, что ошибки мощностей иногда содержат подсказки о предполагаемом времени восстановления. Некоторые ответы 429 включают заголовок Retry-After, который указывает, сколько секунд ждать перед следующей попыткой. Хотя этот заголовок присутствует не всегда, когда он есть, его соблюдение вместо более ранних повторов даст вам наибольшие шансы на успешный ответ при следующей попытке. Парсинг этого заголовка и встраивание его в логику повторов — небольшое улучшение, которое существенно влияет на время восстановления при событиях ограничения мощностей.
Альтернативные решения при перегрузке серверов Google
Когда серверы Google действительно перегружены и ни одно из стандартных решений не помогает, вам нужны альтернативные способы поддержания работоспособности вашего приложения. Этот раздел охватывает практические альтернативы, которые используют опытные разработчики, когда не могут допустить простоя, — от прокси-сервисов API, обеспечивающих альтернативный путь доступа к моделям Google, до мультипровайдерных архитектур, полностью устраняющих единые точки отказа.
Прокси-сервисы API предлагают принципиально иной подход к проблеме мощностей. Вместо прямого подключения к конечным точкам API Google вы направляете свои запросы через посредника, который поддерживает собственный пул учётных данных API, балансирует нагрузку между регионами и обрабатывает повторные попытки за вас. Сервисы вроде laozhang.ai агрегируют доступ через множество аккаунтов и регионов, что означает, что когда одна конечная точка достигает лимита мощностей, прокси автоматически направляет ваш запрос на другую конечную точку с доступными мощностями. Ключевое преимущество в том, что вы получаете стабильный, бесперебойный доступ к моделям Google без необходимости самостоятельно строить и поддерживать мультирегиональную инфраструктуру. Компромисс — небольшая дополнительная стоимость за запрос по сравнению с прямым доступом к API, но для приложений, где надёжность важнее минимизации каждой доли цента в расходах на API, этот компромисс оправдан. Вы можете ознакомиться с документацией API на docs.laozhang.ai, чтобы понять процесс интеграции, который обычно требует изменения только базового URL в конфигурации вашего API-клиента.
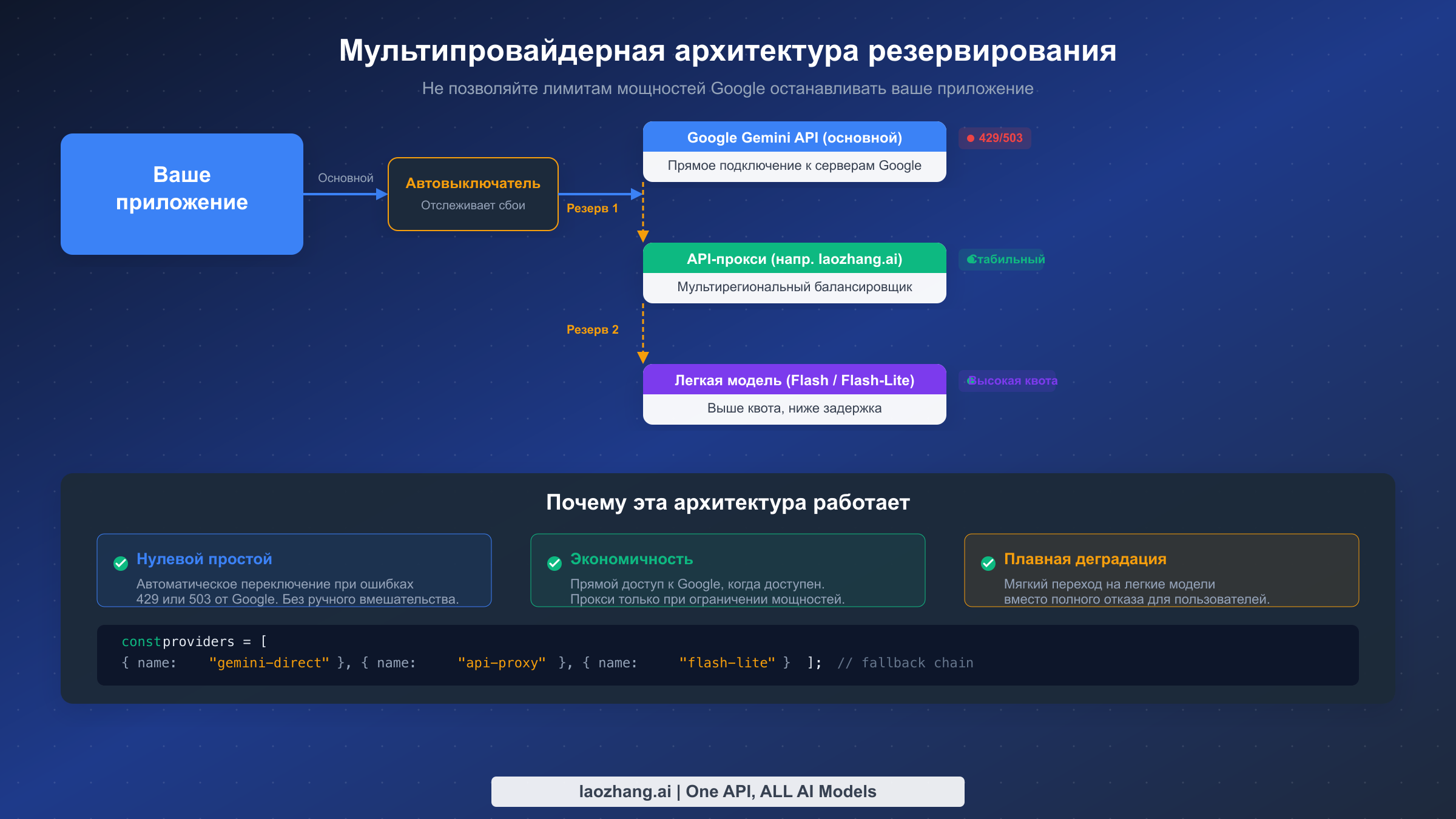
Мультипровайдерная архитектура резервирования — наиболее надёжный подход, который всё чаще применяют корпоративные команды. Вместо зависимости исключительно от моделей Gemini от Google проектируйте своё приложение для работы с несколькими провайдерами LLM и автоматического переключения между ними. Типичная цепочка резервирования может выглядеть так: сначала попробовать Gemini Pro (наименьшая стоимость, лучшее качество для вашего сценария), при ошибке мощностей попробовать прокси-сервис API, а если и он не сработает — переключиться на более лёгкую модель вроде Gemini Flash-Lite с максимально доступными мощностями. Этот подход требует определения интерфейса провайдера, абстрагирующего различия между API, но единовременные затраты на настройку окупаются в первый же раз, когда сбой мощностей в противном случае вывел бы ваше приложение из строя.
javascript// Simple multi-provider fallback implementation const providers = [ { name: "gemini-direct", model: "gemini-2.5-pro", baseUrl: "https://generativelanguage.googleapis.com" }, { name: "api-proxy", model: "gemini-2.5-pro", baseUrl: "https://api.laozhang.ai" }, { name: "flash-fallback", model: "gemini-2.5-flash-lite", baseUrl: "https://generativelanguage.googleapis.com" } ]; async function generateWithFallback(prompt) { for (const provider of providers) { try { const response = await callProvider(provider, prompt); return { response, provider: provider.name }; } catch (error) { if (error.status === 429 || error.status === 503) { console.log(`${provider.name} failed (${error.status}), trying next...`); continue; } throw error; // Non-capacity errors should not trigger fallback } } throw new Error("All providers exhausted"); }
Региональное распределение запросов — ещё одна техника, которая особенно хорошо работает для приложений с глобальной базой пользователей. Мощности Gemini API от Google распределяются по регионам, поэтому ограничения мощностей в регионе US West могут не затрагивать регионы Europe или Asia Pacific. Развёртывая своё приложение в нескольких регионах и направляя запросы API через ближайшую региональную конечную точку, вы снижаете вероятность достижения регионального потолка мощностей и одновременно улучшаете задержку для ваших пользователей.
Построение отказоустойчивых приложений, выдерживающих ограничения мощностей
Выходя за рамки реактивных исправлений, этот раздел описывает архитектурные паттерны, которые продуктивные приложения используют для преодоления ограничений мощностей Google без какого-либо заметного для пользователей воздействия. Эти паттерны требуют больших начальных инженерных усилий, но обеспечивают принципиально более надёжную основу для приложений, которые не могут допустить периодических сбоев.
Паттерн «автоматический выключатель» (circuit breaker) — наиболее важный архитектурный паттерн для отказоустойчивости API. Автоматический выключатель отслеживает частоту отказов ваших API-вызовов и, когда количество сбоев превышает порог, «размыкает» цепь, прекращая отправку запросов к неработающей конечной точке. Это предотвращает трату времени вашим приложением на запросы, которые неизбежно завершатся неудачей, и даёт вышестоящему сервису время на восстановление. После настраиваемого тайм-аута автоматический выключатель переходит в состояние «полуоткрытый», позволяя пройти одному тестовому запросу. Если этот запрос успешен, цепь замыкается и нормальная работа возобновляется. Если он терпит неудачу, цепь остаётся разомкнутой ещё на один период тайм-аута. Этот паттерн особенно эффективен для обработки ошибок мощностей Типов B и C, поскольку автоматически обнаруживает, когда серверы Google находятся под давлением, и перенаправляет трафик без необходимости ручного вмешательства.
pythonimport time from enum import Enum class CircuitState(Enum): CLOSED = "closed" # Normal operation OPEN = "open" # Failing, skip requests HALF_OPEN = "half_open" # Testing if service recovered class CircuitBreaker: def __init__(self, failure_threshold=3, recovery_timeout=60): self.state = CircuitState.CLOSED self.failure_count = 0 self.failure_threshold = failure_threshold self.recovery_timeout = recovery_timeout self.last_failure_time = 0 def can_execute(self): if self.state == CircuitState.CLOSED: return True if self.state == CircuitState.OPEN: if time.time() - self.last_failure_time > self.recovery_timeout: self.state = CircuitState.HALF_OPEN return True return False return True # HALF_OPEN allows one test request def record_success(self): self.failure_count = 0 self.state = CircuitState.CLOSED def record_failure(self): self.failure_count += 1 self.last_failure_time = time.time() if self.failure_count >= self.failure_threshold: self.state = CircuitState.OPEN
Очередь запросов с уровнями приоритета гарантирует, что при ограничении мощностей ваши наиболее важные запросы обслуживаются в первую очередь. Реализуйте приоритетную очередь, которая распределяет входящие запросы по срочности: взаимодействия с пользователями в реальном времени получают высокий приоритет, фоновая пакетная обработка — низкий, а мониторинг или аналитические запросы — самый низкий. Когда автоматический выключатель обнаруживает давление на мощности, очередь автоматически начинает отбрасывать запросы с низким приоритетом, продолжая обслуживать высокоприоритетные. Такая деградация плавная и незаметна для конечных пользователей, которые продолжают получать ответы, пока менее критичные фоновые задачи откладываются.
Мониторинг и оповещения должны отслеживать три различных метрики: утилизацию вашей собственной квоты (процент потреблённых RPM, TPM и RPD), доступность сервиса Google (процент успешных API-вызовов) и задержку ответов (которая часто увеличивается перед возникновением ошибок мощностей). Настройте оповещения, которые срабатывают до достижения жёстких лимитов, а не после. Например, оповещение при использовании RPM более 80% от квоты даёт вам время для масштабирования, оптимизации или активации резервных провайдеров до того, как ваше приложение начнёт отказывать. Встроенные инструменты мониторинга Google Cloud могут отслеживать утилизацию квот, а сервисы вроде Prometheus или Datadog могут агрегировать более широкие метрики в операционные дашборды.
Планирование мощностей — это проактивный аналог реактивной обработки ошибок. Анализируйте исторические паттерны использования API для выявления часов пик, тенденций роста и сезонных всплесков. Если трафик вашего приложения растёт на 20% в месяц, рассчитайте, когда вы превысите лимиты текущего тарифа, и запланируйте повышение соответственно. Для приложений с предсказуемыми пиковыми часами, например утренними часами в определённом часовом поясе, рассмотрите возможность сглаживания запросов — предварительную загрузку или кеширование часто запрашиваемого контента до начала пикового периода для снижения нагрузки на API в реальном времени.
Кеширование ответов — часто недооцениваемая стратегия, которая может значительно сократить использование API без потери качества. Многие приложения отправляют идентичные или почти идентичные промпты повторно: классификация похожих документов, генерация стандартных ответов на типичные вопросы или извлечение структурированных данных из шаблонов одного формата. Реализовав слой кеша, который хранит ответы API по хешу промпта и параметров модели, вы можете обслуживать повторные запросы мгновенно из кеша, а не обращаться к API. Даже простой кеш в памяти с TTL 15 минут может сократить количество API-вызовов на 20-40% для многих рабочих нагрузок, а персистентный кеш на основе Redis или аналогичного хранилища может достичь ещё более высокого процента попаданий. Ключевое — кешировать на правильном уровне детализации: кешировать полный ответ для идентичных промптов, но корректно инвалидировать при изменении системного промпта или версии модели.
Информирование о плавной деградации гарантирует, что даже когда все стратегии резервирования исчерпаны, ваши конечные пользователи получают полезный опыт, а не загадочную страницу ошибки. Спроектируйте ваше приложение так, чтобы оно отображало чёткое, нетехническое сообщение о временной недоступности функции ИИ с автоматическим повтором. Включите видимый индикатор, показывающий, что система работает над восстановлением, и, если уместно, предложите кнопку ручного повтора. Такой ориентированный на пользователя подход к обработке ошибок превращает потенциально разочаровывающий тупик в кратковременную паузу, сохраняя доверие пользователей и предотвращая отток при событиях ограничения мощностей.
Часто задаваемые вопросы
Почему Google ограничивает серверные мощности для Gemini?
Модели Gemini от Google работают на специализированном оборудовании TPU (Tensor Processing Unit) и GPU, которое дорого в развёртывании и требует месяцев на установку. Каждый запрос к крупной модели, такой как Gemini 2.5 Pro, требует значительных вычислительных ресурсов, а общая доступная мощность конечна. Google использует лимиты запросов и многоуровневый доступ для обеспечения справедливого распределения этого конечного ресурса среди миллионов разработчиков. Ограничения мощностей, с которыми вы сталкиваетесь, отражают реальность: спрос на модели Gemini в настоящее время превышает доступную инфраструктуру Google, особенно для моделей уровня Pro, которые требуют больше вычислений на запрос. По мере того как Google продолжает расширять свою инфраструктуру ИИ в новых дата-центрах по всему миру, ожидается постепенное ослабление этих ограничений, но они остаются серьёзной проблемой для разработчиков, создающих продуктивные приложения в начале 2026 года.
Как долго обычно длятся ошибки мощностей?
Ошибки Типа A (лимит запросов) разрешаются, как только ваша квота обновляется — каждую минуту для RPM и каждые 24 часа для RPD. Ошибки Типа B (мощности исчерпаны) более изменчивы и могут длиться от 30 секунд до нескольких часов в зависимости от общего спроса. Ошибки Типа C (503, нет мощностей) во время подтверждённого сбоя обычно разрешаются в течение 1-4 часов на основе исторических инцидентов. Например, проблемы с мощностями в ноябре 2025 года на официальном форуме разработчиков сохранялись периодически в течение нескольких недель, прежде чем Google «выпустил исправление» 18 декабря 2025 года. Лучшая стратегия — никогда не рассчитывать на конкретное время восстановления, а вместо этого проектировать своё приложение для обработки длительных ограничений мощностей с помощью паттернов резервирования, описанных в этом руководстве.
Гарантирует ли переход на платный тариф отсутствие ошибок мощностей?
Нет. Переход на Tier 1 или выше устраняет ошибки Типа A (лимит запросов), предоставляя значительно более высокие квоты, но не защищает от ошибок Типа B (мощности исчерпаны) или Типа C (503), поскольку это серверные проблемы, затрагивающие всех пользователей независимо от тарифа. Тем не менее пользователи платных тарифов получают приоритетный доступ при ограничениях мощностей, что означает меньшую вероятность столкнуться с ошибками Типа B по сравнению с пользователями бесплатного тарифа. Несколько разработчиков на форуме Google AI подтвердили, что аккаунты Tier 1 получали ошибки 429 в ноябре 2025 года, несмотря на то что их использование составляло менее 1% от заявленной квоты, что демонстрирует: проблемы мощностей могут затрагивать даже платных клиентов. Для критически важных продуктивных нагрузок сочетание платного тарифа с мультипровайдерной архитектурой резервирования, описанной ранее в этом руководстве, обеспечивает наиболее надёжное решение, доступное на сегодняшний день.
Есть ли способ проверить текущий статус мощностей Google API?
Google не предоставляет панель мониторинга мощностей в реальном времени специально для Gemini API. Лучшие источники информации о статусе: панель статуса Google Cloud для официальных отчётов о сбоях, форум разработчиков Google AI для отчётов сообщества и раздел issues GitHub-репозитория google-gemini для проблем с доступностью конкретных моделей. Для мониторинга в реальном времени опыта вашего собственного приложения реализуйте паттерн проверки работоспособности, описанный в этом руководстве, который отправляет минимальный тестовый запрос каждые 30-60 секунд для обнаружения проблем мощностей до того, как они повлияют на ваших пользователей. Многие команды также отслеживают каналы в социальных сетях, такие как субреддиты Reddit r/Bard и r/GoogleGemini, где разработчики часто сообщают о проблемах мощностей в реальном времени, иногда за несколько часов до официального признания.
Какой самый дешёвый способ избежать ошибок мощностей?
Самый экономичный подход сочетает три стратегии, работающие вместе. Во-первых, включите Cloud Billing для получения доступа Tier 1 — это ничего не стоит авансом и взимает плату только за фактическое использование по стандартным тарифам Google с оплатой за использование. Во-вторых, используйте Gemini 2.5 Flash вместо Pro для любых задач, где допустима разница в качестве, поскольку Flash имеет более высокие квоты и меньшую стоимость за запрос ($0,30 против $2,00-$4,00 за миллион входных токенов, ai.google.dev/pricing, февраль 2026). В-третьих, реализуйте экспоненциальную задержку с джиттером в клиентском коде для плавной обработки случайных срабатываний лимита вместо немедленного отказа. Эта комбинация обеспечивает большинству разработчиков надёжную работу при минимальных затратах, и для подавляющего большинства рабочих нагрузок разработки и небольших продуктивных проектов ежемесячный счёт за API остаётся значительно ниже $10.