
Если под «Gemini 3.1 Flash Live API» вы имеете в виду новый realtime-голосовой модельный слой Google, то точное имя модели — gemini-3.1-flash-live-preview, а корректная API-поверхность — Gemini Live API. Это не придирка к формулировкам. Google разнес полезную информацию по нескольким официальным страницам: страница модели, обзор Live API, capabilities guide, pricing, ephemeral tokens guide и официальный анонс от 26 марта 2026 года.
Короткий вывод такой: если вы сегодня начинаете новый low-latency voice-agent, начинайте с Gemini 3.1 Flash Live. Но не относитесь к этому как к прозрачной замене gemini-2.5-flash-native-audio-preview-12-2025. Google улучшил голосовое качество, естественность диалога и общий operational ceiling, но одновременно поменял thinking-конфигурацию, структуру server events, схему инкрементального ввода и поведение tool use. Если ваш текущий стек на 2.5 опирается на async function calling, proactive audio или affective dialog, слепая миграция может сначала ухудшить продукт.
“Источники: статья основана только на официальной документации Google и официальном анонсе, перепроверенных 28 марта 2026 года. Там, где публичные страницы Google противоречат друг другу или не дают точного числа, я сохраняю эту неопределенность прямо в тексте.
TL;DR
| Что нужно понять сразу | Текущий ответ |
|---|---|
| Точный model ID | gemini-3.1-flash-live-preview |
| Точная API-поверхность | Gemini Live API поверх stateful WebSocket-сессии |
| Дата запуска | 26 марта 2026 года |
| Лучший стартовый сценарий | realtime-голосовые агенты с низкой задержкой, мультимодальностью и более естественным аудио |
| Базовая рекомендация | для новых проектов начинайте с 3.1 |
| Главная причина остаться на 2.5 | вам все еще нужны async tools, proactive audio или affective dialog |
| Ключевые изменения миграции | thinkingBudget заменен на thinkingLevel, один server event теперь может содержать несколько parts, realtime-обновления нужно слать через send_realtime_input, а tool calls сейчас только синхронные |
| Форма цены | text input $0.75 / 1M tokens, audio input $3 / 1M tokens или $0.005 / мин, image/video input $1 / 1M tokens или $0.002 / мин, text output $4.50 / 1M tokens, audio output $12 / 1M tokens или $0.018 / мин |
| Безопасный browser path | выпускать ephemeral tokens на бэкенде и уже ими подключать клиент |
| Скрытая ловушка | default turn coverage теперь включает все video frames |
Что Google реально выпустил 26 марта 2026 года
В официальном анонсе Gemini 3.1 Flash Live описан как новый высококачественный realtime-аудиомодельный слой. Для разработчиков он доступен в preview через Gemini Live API внутри Google AI Studio. Страница модели добавляет техническую конкретику: код модели — gemini-3.1-flash-live-preview, входы — text, images, audio, video, а сама модель оптимизирована под low-latency dialogue с acoustic nuance detection, numeric precision и multimodal awareness.
Важно правильно читать архитектуру. Не существует отдельного продукта под названием «Gemini 3.1 Flash Live API». Есть Gemini Live API как realtime-интерфейс, и есть Gemini 3.1 Flash Live как модель, запускаемая через этот интерфейс. Live API — это stateful WebSocket, рассчитанный на потоковое взаимодействие, прерывания, мультимодальные turn-ы и голосовой ответ, а не обычный цикл request-response.
Отсюда и практическое следствие: это не просто «еще один voice model». В документации явно указаны function calling и Google Search grounding. Значит, реальный целевой сценарий — не только озвучивание текста, а голосовой агент, который слушает, понимает, вызывает инструменты и отвечает в той же сессии. Там же указан knowledge cutoff — январь 2025 года, поэтому если агенту нужна актуальная информация, grounding или собственный retrieval-слой нужно планировать явно.
Есть и два важных нюанса. Во-первых, страница модели пишет про text and audio output, а capabilities guide говорит, что native audio models используют только AUDIO response modality. Самое безопасное инженерное чтение здесь такое: если вам нужен читаемый текст, закладывайтесь на output audio transcription, а не на поведение «обычного текстового ответа». Во-вторых, в анонсе Google прямо сказано, что весь звук, сгенерированный 3.1 Flash Live, водяной знакомится через SynthID.
Начинать с 3.1 или оставаться на 2.5
Для новых сборок Gemini 3.1 Flash Live — правильная точка старта. Google сам позиционирует его как новый флагманский realtime-голосовой вариант, а миграционные заметки написаны так, будто переход с gemini-2.5-flash-native-audio-preview-12-2025 уже ожидается. Но это не значит, что 3.1 — полный superset 2.5.
Правильный вопрос звучит так: зависит ли ваш текущий продукт от возможностей 2.5, которых в 3.1 пока нет? Именно поэтому следующая таблица важнее большинства анонсных формулировок.
| Практическая разница | Gemini 3.1 Flash Live | Gemini 2.5 Flash Live |
|---|---|---|
| Model ID | gemini-3.1-flash-live-preview | gemini-2.5-flash-native-audio-preview-12-2025 |
| Запуск / последнее обновление | запуск 26.03.2026 | обновление в сентябре 2025 |
| Лимит output tokens | 65,536 | 8,192 |
| Управление thinking | thinkingLevel | thinkingBudget |
| Server events | один event может содержать несколько parts | один event — одна part |
| Инкрементальный text input | realtime через send_realtime_input | можно продолжать использовать send_client_content |
| Default turn coverage | TURN_INCLUDES_AUDIO_ACTIVITY_AND_ALL_VIDEO | TURN_INCLUDES_ONLY_ACTIVITY |
| Async function calling | не поддерживается | поддерживается |
| Proactive audio | не поддерживается | поддерживается |
| Affective dialog | не поддерживается | поддерживается |
| Лучший fit сейчас | новые voice-agent сборки | существующие 2.5-системы, которым нужны старые возможности |
Из этой таблицы стоит вынести две вещи.
Во-первых, 3.1 действительно сильнее там, где важна quality of live conversation.
Google говорит о лучшем понимании тона, большей надежности на сложных задачах и лучшем поведении в аудиобенчмарках. Плюс лимит output tokens вырос с 8,192 до 65,536, а это уже заметная operational difference.
Во-вторых, не для каждой production-системы на 2.5 переход выгоден уже сейчас.
Если ваша архитектура использовала behavior: NON_BLOCKING, чтобы модель продолжала говорить, пока инструменты работают в фоне, этот паттерн в 3.1 сейчас отсутствует. Google прямо пишет: Gemini 3.1 Flash Live работает только с synchronous function calling. То же относится к proactive audio и affective dialog.
Итого:
- строите с нуля — стартуйте на 3.1
- уже живете на 2.5 — переходите только после проверки, что синхронные tools и отсутствие 2.5-only функций вас не ломают

Цену здесь удобнее считать минутами, а не только токенами
Pricing-страница Google хороша тем, что дает не только token-based, но и minute-based ставку. Для голосового продукта это гораздо практичнее.
| Метрика | Текущая цена |
|---|---|
| Text input | $0.75 / 1M tokens |
| Audio input | $3.00 / 1M tokens или $0.005 / мин |
| Image/video input | $1.00 / 1M tokens или $0.002 / мин |
| Text output | $4.50 / 1M tokens |
| Audio output | $12.00 / 1M tokens или $0.018 / мин |
| Search grounding | 5,000 бесплатных shared prompts в месяц на Gemini 3, затем $14 / 1,000 queries |
Это позволяет быстро перейти от “кажется, недорого” к нормальной операционной оценке. Если в голосовой сессии звук идет в обе стороны непрерывно, то опубликованные ставки дают примерно $0.023 в минуту только за аудио. Десятиминутный звонок — это около $0.23 без учета grounding, video и вашей инфраструктуры. Это не цитата Google, а прямой расчет из $0.005 / мин на audio input и $0.018 / мин на audio output.
Grounding с Search — вторая строчка, которую часто недооценивают. После бесплатного shared-пула одна поисковая операция стоит примерно $0.014. Пять поисков внутри одной сессии — это еще около $0.07 сверху.
Но самый неприятный скрытый риск — video. Миграционные заметки Google объясняют, что default turn coverage теперь включает all video. Если ваш старый 2.5-клиент постоянно отправлял видеопоток, хотя реальная задача была голосовой, в 3.1 стоимость может вырасти почти незаметно.
Отдельно важно помнить про лимиты. Google не публикует точные RPM / RPD для Gemini 3.1 Flash Live на публичной странице, а отправляет разработчиков смотреть active rate limits в AI Studio. Значит, pricing-страница нужна для понимания формы стоимости, а реальную емкость проекта надо проверять уже внутри AI Studio.
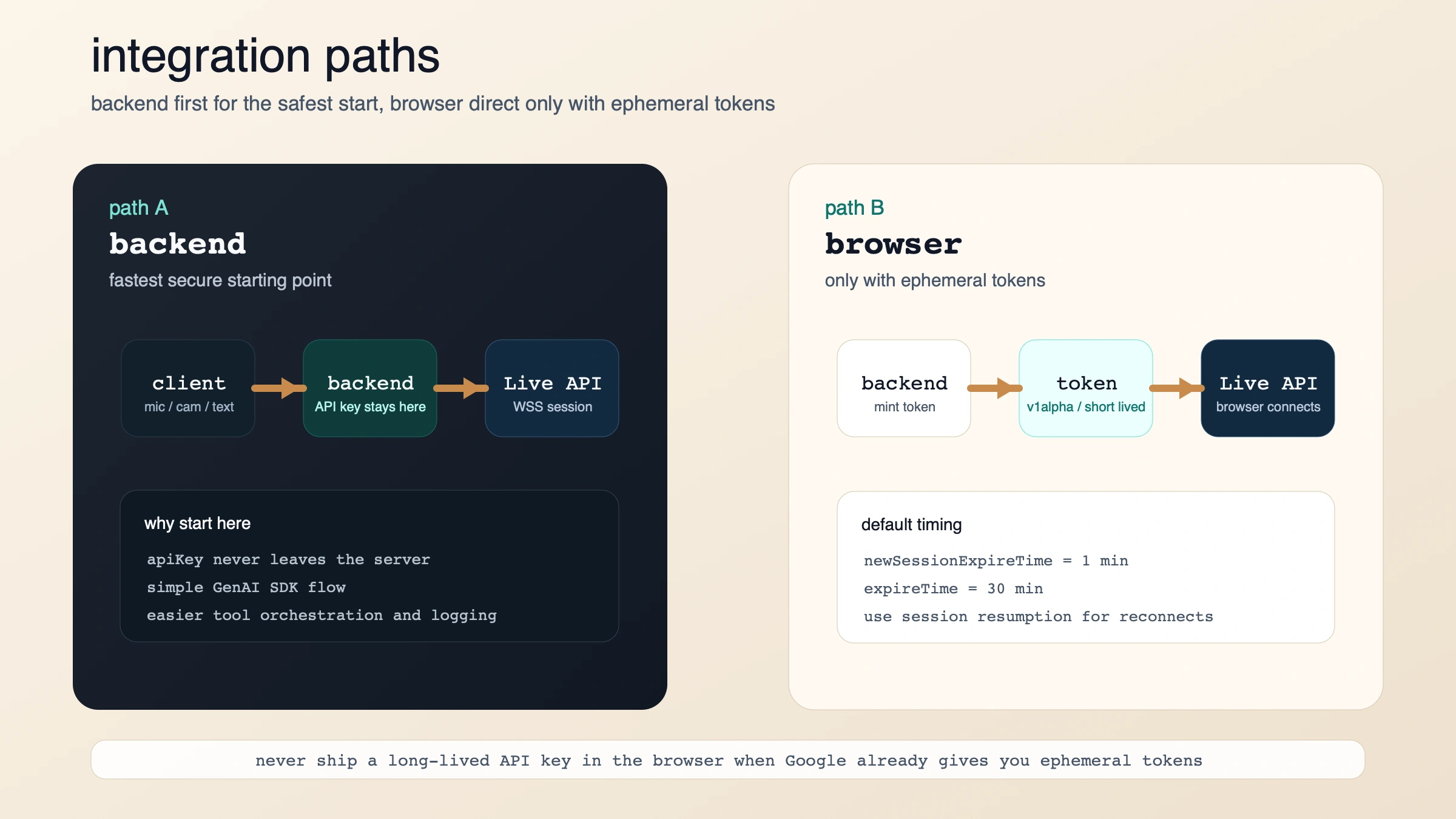
Самый быстрый рабочий путь: сначала бэкенд, потом браузер
Если ваша цель — как можно быстрее получить рабочую интеграцию, начинайте с server-to-server. Overview Live API и capabilities guide показывают именно этот базовый маршрут: открыть Live-сессию, запросить AUDIO и далее отправлять send_realtime_input по мере прихода audio, text или video.
pythonimport asyncio from google import genai client = genai.Client() MODEL = "gemini-3.1-flash-live-preview" async def main(): config = {"response_modalities": ["AUDIO"]} async with client.aio.live.connect(model=MODEL, config=config) as session: await session.send_realtime_input( text="Say hello and introduce yourself in one sentence." ) async for response in session.receive(): if response.server_content and response.server_content.model_turn: for part in response.server_content.model_turn.parts: if part.inline_data: audio_bytes = part.inline_data.data # Проигрывайте или пересылайте audio_bytes здесь. if response.text: print(response.text) if response.server_content and response.server_content.turn_complete: break asyncio.run(main())
На пути к production нужно учитывать и формат сигнала. Документация Google требует 16-bit PCM / 16kHz / little-endian на входе, с MIME-типом вроде audio/pcm;rate=16000. На выходе вы получаете 24kHz PCM. Там же указано ограничение по длительности: 15 минут для audio-only и 2 минуты для audio+video, если вы не внедрили session management / resumption.
Если же нужен browser-direct сценарий, Google предлагает не “положить API key во фронтенд”, а использовать ephemeral tokens. Смысл в том, чтобы снизить latency и не светить долгоживущим ключом.
Базовые значения такие:
- обычно есть 1 минута, чтобы открыть новую сессию этим токеном
- после этого обычно есть 30 минут, чтобы отправлять сообщения по соединению
- на клиенте токен используется как API key
- для переподключения нужен session resumption
Из этого следует простое правило:
- backend only — самый понятный старт
- browser direct — только если ваш бэкенд уже умеет безопасно выдавать ephemeral tokens
Миграционные ошибки, которые чаще всего съедают первый день
Проблема миграции с 2.5 на 3.1 не в том, что все падает громко. Гораздо хуже то, что некоторые вещи продолжают “как будто работать”, но уже неправильно.
1. Перестаньте слать thinkingBudget.
В 3.1 используется thinkingLevel, а значение по умолчанию — minimal.
2. Обрабатывайте все parts в каждом server event.
В 3.1 один event может принести и audio chunks, и transcript. Старый парсер тихо потеряет часть данных.
3. Для realtime-обновлений используйте send_realtime_input.
В 2.5 можно было дольше жить на send_client_content, в 3.1 — нет.
4. Рассматривайте tool use как блокирующий.
Самая заметная operational-потеря по сравнению с 2.5: модель ждет ответа инструмента, прежде чем продолжить.
5. Уберите proactive audio и affective dialog из конфигурации.
В 3.1 они сейчас не поддерживаются.
6. Отправляйте video только там, где оно действительно нужно.
Когда all video входит в default coverage, постоянная камера — это уже не UX-деталь, а решение о расходах.
7. Если вам нужен текст, проектируйте это как transcription.
Это самый безопасный способ обойти расхождение между модельной страницей и capability-документом.
Когда Gemini 3.1 Flash Live — не лучший выбор
Если вы не строите realtime voice product, Live API может быть избыточен.
WebSocket, PCM, interruptions и ephemeral tokens имеют смысл только там, где голос — основной интерфейс.
Если текущая система на 2.5 сильно опирается на async tools, 3.1 пока может быть хуже.
Лучшее voice quality не всегда означает лучший продукт целиком.
Если вы не можете безопасно выпускать ephemeral tokens, не форсируйте browser-direct.
В этом случае разумнее оставить Live-сессию на сервере.
Если вам нужен только TTS, а не диалоговый агент, берите speech-модель, а не Live-модель.
Gemini 3.1 Flash Live — это более толстый контракт: диалог, инструменты, мультимодальность, interruptions.

FAQ
Какой точный model ID?
gemini-3.1-flash-live-preview.
Это уже GA?
Нет. По состоянию на март 2026 это preview.
Поддерживаются ли tools и Google Search?
Да. Но function calling сейчас только синхронный.
Можно ли подключать модель прямо из браузера?
Можно, но рекомендуемый путь — через ephemeral tokens, выпущенные вашим бэкендом.
Сколько может длиться сессия?
15 минут для audio-only и 2 минуты для audio+video. Для большего нужна session management-логика.
Модель возвращает текст или только аудио?
Публичные страницы формулируют это не идеально одинаково, но с инженерной точки зрения безопаснее считать, что AUDIO — базовая response modality, а читаемый текст нужно получать через transcription.
Есть ли watermark на выходном аудио?
Да. Google указывает SynthID watermark для всего аудио, сгенерированного 3.1 Flash Live.
Если сформулировать правило миграции в одной фразе?
Для новых voice-agent проектов стартуйте на Gemini 3.1 Flash Live, а существующие 2.5-системы переносите только после проверки, что вам не критичны async tools, proactive audio и affective dialog.