
Claude Sonnet 4.6 в некоторых сценариях самоидентификации действительно может отвечать, что он DeepSeek, особенно когда prompt-оболочка слабо закрепляет его идентичность и вопрос задается в короткой форме на китайском. Самый полезный способ читать это поведение — видеть в нем сбой самоидентификации при слабом prompt boundary, а не готовое доказательство того, что Anthropic тайно подменила Sonnet на DeepSeek или что один скриншот уже закрывает вопрос о дистилляции.
“Основа статьи: публичные страницы Anthropic — models overview, обзор Claude 4.6, system prompts, release notes, а также пост Anthropic от 23 февраля 2026 года о distillation attacks, документация OpenRouter по provider routing и публичные обсуждения, где зафиксирован сам наблюдаемый ответ.
TL;DR
- Да, самоописание как DeepSeek достаточно правдоподобно, чтобы его разбирать. В публичных тредах есть несколько примеров, где Claude Sonnet 4.6 отвечает, что он DeepSeek, особенно при китайском self-ID prompt и слабом system prompt.
- Нет, из этого не следует, что Sonnet 4.6 на самом деле и есть DeepSeek. Публичная документация Anthropic по-прежнему перечисляет Sonnet 4.6 как текущую модель Claude с alias
claude-sonnet-4-6. - Самое сильное текущее объяснение — слабый prompt/surface-контур, а не публичная подмена модели. Anthropic сама пишет, что claude.ai и мобильные клиенты используют system prompt, а Claude API эти обновления не наследует.
- Публичное обвинение Anthropic в адрес DeepSeek важно для оптики, но не меняет стандарт доказательств. Именно поэтому скриншот так разошелся, но он все равно не превращается в надежный тест происхождения модели.
- Если вам важна идентичность модели, доверяйте маршруту, а не самоописанию. Смотрите на model ID, фиксируйте provider path, добавляйте identity anchor и сравнивайте поведение на app / API / gateway.
Что подтверждено на самом деле
Главная ошибка вокруг этой темы — смешение наблюдаемого ответа и публичного модельного контракта. Первое — это то, что модель сгенерировала в одном или нескольких диалогах. Второе — это то, какую модель Anthropic публично говорит, что поставляет. Эти уровни могут конфликтовать, но конфликт сам по себе еще не означает, что скриншот автоматически сильнее официального контракта.
По состоянию на 1 апреля 2026 года Anthropic в своем models overview продолжает перечислять Claude Sonnet 4.6 как текущую публичную модель и дает ей alias claude-sonnet-4-6. В release notes указано, что Sonnet 4.6 была запущена 17 февраля 2026 года. То есть Sonnet 4.6 — не слух и не странное название от роутера, а часть открытого модельного стека Anthropic.
Подтверждено и другое: 23 февраля 2026 года Anthropic публично обвинила DeepSeek в масштабной экстракции возможностей Claude. В своем посте о distillation attacks компания прямо упомянула DeepSeek и написала о более чем 150,000 exchanges, нацеленных на reasoning и связанные способности. Этот фон важен, потому что объясняет, почему ответ I am DeepSeek воспринимается не как обычный баг, а как удар по уже существующему публичному нарративу.
А вот чего нет, так это публичной статьи Anthropic, которая бы объясняла корень именно этого self-identification поведения. Нет release note в духе мы исправили identity bug Sonnet 4.6. Поэтому самый безопасный формат статьи здесь — не официальный баг-репорт, а официальный контракт модели + наблюдаемое поведение + дисциплинированная inference-часть.
Именно этот порядок и нужен читателю. Публичный контракт говорит, какую модель Anthropic утверждает, что поставляет. Скриншот показывает, как модель ответила на один вопрос внутри одной prompt-оболочки. Оба слоя важны, но они не эквивалентны.
Если вас больше интересует реальная публичная линейка Anthropic, а не этот конкретный сбой, стоит отдельно посмотреть наш разбор Claude Capybara, где используется та же дисциплина public contract vs rumor.
Почему Sonnet 4.6 может отвечать, что она DeepSeek

Самое правдоподобное объяснение — не один скрытый факт, а несколько факторов, которые вместе делают странный ответ намного менее мистическим.
Первый слой — prompt anchoring. На странице Anthropic о system prompts прямо сказано, что веб-интерфейс Claude и мобильные приложения используют system prompt в начале разговора, а эти обновления не применяются к Claude API. То есть одна и та же фраза что ты за модель? попадает в разные identity-конверты в зависимости от поверхности. На одной поверхности модель сильнее закреплена в собственной роли. На другой вы ближе к более сырому self-ID поведению.
Это не объясняет автоматически каждый скриншот, но хорошо объясняет, почему самоидентификация нестабильна между поверхностями. Если модель не получает сильный identity anchor и вы задаете короткий вопрос о том, кто она, вы на деле проверяете слабое место. Модель не считывает защищенный внутренний бейдж. Она завершает ответ так, как это кажется ей наиболее вероятным в данном контексте.
Второй слой — multilingual completion. Публичные примеры концентрируются вокруг коротких китайских prompt вроде 你是什么模型?, а не вокруг длинного англоязычного контекста, где уже явно прописано Claude Sonnet 4.6. На основании доступных источников самое сильное объяснение такое: при слабом закреплении собственной идентичности модель может завершать знакомый паттерн самоописания модели. Точный механизм публично не подтвержден, поэтому корректнее называть это inference, а не фактом. Но это все равно намного сильнее, чем скачок к выводу значит, модель буквально DeepSeek.
Третий слой — routing и wrapper-логика. Документация OpenRouter по provider routing пишет, что дефолтная стратегия использует price-based load balancing и допускает fallbacks. Это значит, что gateway-путь по определению не всегда является простой схемой одна модель -> один provider -> без промежуточной логики. В некоторых кейсах это вполне может усиливать путаницу. Это не полноценное объяснение всех случаев, потому что в публичных обсуждениях есть утверждения и о воспроизведении на официальном Anthropic API с пустым system prompt. Но как часть общей картины этот слой игнорировать нельзя.
Поэтому самый полезный вывод здесь очень простой: модель может ошибаться в самоидентификации и при этом оставаться той моделью, которую вы вызвали. Большие языковые модели сильны во многом, но они не являются надежным источником собственного происхождения, если задавать им минимальный вопрос без хорошего identity anchor. Их ответ формируется prompt-оболочкой, языком и маршрутом вызова.
Это объяснение менее драматично, чем вирусная интерпретация, но намного лучше согласуется с тем, что реально подтверждается источниками.
Чего этот ответ не доказывает

Из этого поведения постоянно пытаются вытащить три слишком сильных вывода.
Первый: Claude Sonnet 4.6 на самом деле является DeepSeek. Это слишком сильный тезис. Публичная документация Anthropic по-прежнему показывает Sonnet 4.6 как текущую модель Claude со своим alias, датой запуска, контекстным окном и ценовым позиционированием. Ошибочный self-ID ответ не отменяет публичный контракт.
Второй: Anthropic тайно подсовывает вам модель другого провайдера. Это тоже слишком сильный вывод, особенно когда сообщения приходят с разных поверхностей и доказательная база сама по себе неоднородна. Если конкретный скриншот пришел через gateway с нефиксированным routing, provider-level ambiguity может быть частью объяснения. Но из публичных тредов следует, что похожее поведение, по словам пользователей, иногда наблюдается и на официальном API. Поэтому одинаково безответственно и сводить все к gateway fraud, и перескакивать к Anthropic вообще не отдает Claude.
Третий: это доказывает, что Anthropic обучала Sonnet 4.6 на выходах DeepSeek ровно в том смысле, в каком сама обвиняет DeepSeek в distillation. Этот вывод особенно соблазнителен из-за сильной оптики. Но неловкое противоречие — не то же самое, что доказанный training pipeline. Максимум, что пока можно сказать аккуратно: identity-паттерны конкурента способны всплывать в поведении модели при слабом identity anchor. Это важно и интересно. Но этого все еще недостаточно, чтобы по одному скриншоту реконструировать реальную схему обучения Anthropic.
Что было бы более сильным доказательством? Нужен чистый воспроизводимый тест на официальном API, под жестко контролируемыми prompt-условиями, плюс более жесткие признаки происхождения, чем самоописание модели. Это уже ближе к model-card уровню или к прямым сведениям о training recipe. Один короткий prompt и один ответ этот порог не проходят.
Поэтому правильная реакция здесь — не отрицание и не уверенность, а повышение планки доказательств. Поведение достаточно реально, чтобы его разбирать. Но оно недостаточно сильно, чтобы автоматически поддержать любой вывод, который хочется из него извлечь.
Как проверять идентичность модели правильно
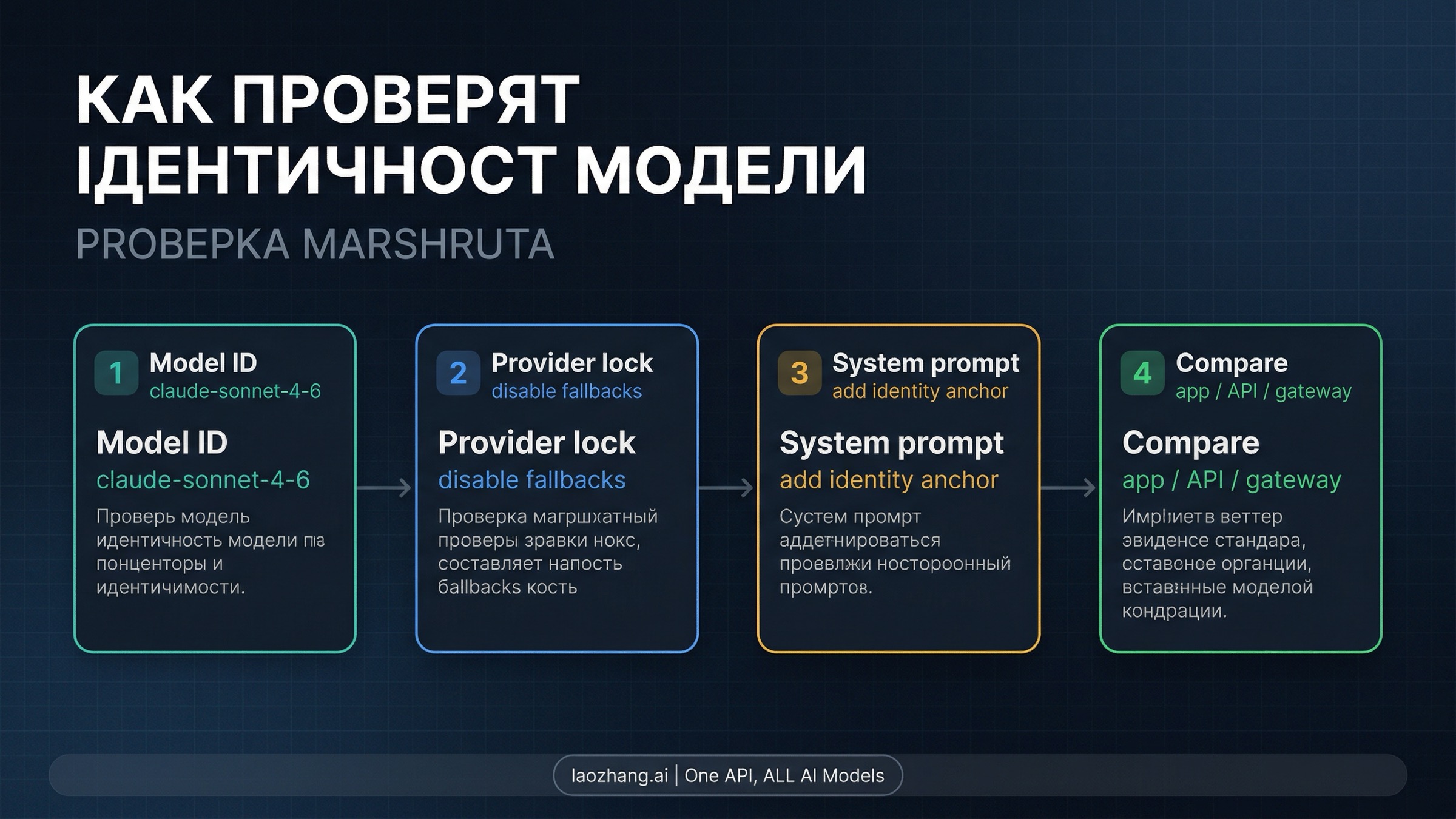
Если ваша реальная задача — понять, какой model path вы действительно вызываете, то вопрос кто ты? к самой модели — самый слабый тест во всей цепочке. Намного полезнее следующий workflow:
- Сначала проверьте model ID в конфигурации. Для текущего публичного Sonnet 4.6 у Anthropic это
claude-sonnet-4-6. Прежде чем интерпретировать prose-ответ модели о самой себе, проверьте, что вы вообще отправили. - Если используете gateway, зафиксируйте provider path. При identity-sensitive тестах нужно по возможности отключать fallbacks или явно выбирать provider, чтобы сократить routing-неопределенность.
- Добавьте явный identity anchor в system prompt. Речь не о том, чтобы заставить модель
соврать, а о том, чтобы не тестировать слишком недоопределенный сценарий. Если модель отвечает корректно только при явном anchor, это само по себе ценный сигнал. - Сравнивайте поверхности, а не верьте одному ответу. Прогоните один и тот же вопрос через claude.ai, официальный Anthropic API и тот gateway-путь, которым реально пользуетесь. Anthropic сама пишет, что эти поверхности не делят один и тот же prompt envelope.
- Логируйте важные условия. Request model, provider choice, fallback settings, состояние system prompt, язык запроса — без этих деталей вы не занимаетесь проверкой идентичности модели, вы просто копите анекдоты.
Смысл этого workflow не в том, чтобы magically убрать glitch. Смысл в том, чтобы перейти от ответ выглядел жутко к эта конкретная route при этих условиях дала такой ответ. На этом уровне уже появляется инженерный смысл и возможность нормального сравнения.
Это также меняет способ чтения уже разошедшихся скриншотов. Скриншот без route-деталей и prompt-состояния не бесполезен, но он заметно слабее, чем его часто подают. Как только вы начинаете смотреть на provider lock, identity anchor и surface difference, спор резко становится менее мистическим и гораздо более проверяемым.
Почему слой Anthropic vs DeepSeek все равно важен
Скриншот взлетел не случайно. Он попадает в уже существующий публичный конфликт: Anthropic говорит, что DeepSeek делала масштабную capability extraction из Claude, а затем модель Claude на некоторых prompt отвечает, что она DeepSeek. Даже если корень проблемы — только prompt weakness, multilingual completion drift или routing ambiguity, для Anthropic это очень плохая оптика.
Эту часть нельзя просто отмахнуть. Anthropic сама создала рамку, внутри которой такой скриншот получает политический и репутационный вес. В своем посте от 23 февраля компания не просто вскользь упомянула DeepSeek, а публично вынесла обвинение и дала количественное описание. Поэтому естественно, что читатели воспринимают self-ID glitch именно через эту рамку.
Но лучший вывод из этого — не значит, Anthropic автоматически неправа насчет дистилляции. Гораздо полезнее и точнее более узкое утверждение: identity-паттерн конкурента может всплывать в ответах модели, не становясь при этом полным доказательством ее weights, происхождения или training method. Скриншот силен риторически, потому что он яркий, наглядный и унизительный. Но этого все еще недостаточно, чтобы превратить его в окончательное доказательство.
Именно поэтому тема важнее, чем просто любопытный баг. Она показывает, насколько многие пользователи по-прежнему принимают self-description модели за надежный системный факт. В эпоху LLM это слишком слабое основание. Конфликт Anthropic и DeepSeek просто сделал эту слабость особенно заметной.
FAQ
Claude Sonnet 4.6 правда может говорить, что она DeepSeek?
Да. Публичных обсуждений уже достаточно, чтобы считать явление реальным настолько, чтобы его анализировать. Но публичного root-cause note от Anthropic на сегодня нет.
Это значит, что Sonnet 4.6 на самом деле DeepSeek?
Нет. Публичная документация Anthropic по-прежнему перечисляет Sonnet 4.6 как действующую модель Claude. Самый безопасный вывод — self-identification может ломаться при слабом prompt-контуре.
Это только проблема OpenRouter?
Не обязательно. Gateway routing действительно может быть частью причины в некоторых случаях, но публичные сообщения указывают и на возможное воспроизведение через официальный Anthropic API при пустом system prompt. Значит, формула только OpenRouter слишком упрощает ситуацию.
Это доказывает, что Anthropic обучала Sonnet на DeepSeek?
Нет. Это может говорить о всплывающих identity-паттернах конкурента, но этого недостаточно, чтобы доказать конкретную training pipeline или illicit distillation.
Почему проблема сильнее заметна в китайском?
Потому что именно вокруг коротких китайских self-ID prompt сосредоточены публичные примеры. Самое разумное текущее объяснение — там больше пространства для шаблонного completion-перехода, если собственная идентичность модели закреплена слабо.
Итоговый вывод
Claude Sonnet 4.6 говорит DeepSeek в некоторых self-identification prompt не потому, что это автоматически вскрывает тайную подмену модели, а потому, что идентичность модели зависит от prompt boundary и поверхности сильнее, чем многим кажется. Anthropic сама дает одну из ключевых подсказок: у claude.ai и мобильных клиентов есть system prompt, а API эту надстройку не наследует. Если добавить сюда multilingual completion-поведение и в некоторых случаях routing-слой gateway, DeepSeek-ответ становится похож не на магическое признание, а на сбой identity-layer.
Это не делает скриншот бессмысленным. Для Anthropic это действительно плохая оптика на фоне собственного публичного конфликта с DeepSeek. Но самый ответственный вывод все равно уже: self-introduction модели — плохой provenance test. Если вам важно, что именно вы вызываете, доверяйте model contract, provider path и prompt envelope больше, чем слабо закрепленному самоописанию самой модели.