
Начинайте с GPT-5.3-Codex, если на первом этапе вам нужно подешевле прогнать цикл агентной работы с кодом, завязанный на терминал и частые вызовы инструментов. Начинайте с Claude Opus 4.6, если главная цена ошибки возникает не из-за стоимости токенов, а из-за длинных многошаговых задач, очень большого контекста репозитория или такого объема ответа, где слабый первый проход приводит к дорогой ручной переделке. Это и есть практический ответ по состоянию на 3 апреля 2026 года.
Но перед таблицей нужно сделать одно важное уточнение. GPT-5.3-Codex все еще является реальной и актуальной моделью OpenAI, однако уже не может служить сокращением для всего сегодняшнего Codex как продукта. OpenAI ввела GPT-5.4 в Codex 5 марта 2026 года, а 17 марта 2026 года описала подход, где более крупная модель отвечает за планирование и финальное решение, а GPT-5.4 mini берет более узкие подзадачи. Поэтому здесь мы сравниваем Claude Opus 4.6 и GPT-5.3-Codex именно как модели, а не весь актуальный продукт Codex. Если вам нужен ответ на уровне продукта или рабочего процесса, переходите к гайду по OpenAI Codex за март 2026 и к сравнению Claude Code vs Codex.
| Если у вас такой тип узкого места | Кого проверять первым | Почему |
|---|---|---|
| Более дешевые циклы кодинга через терминал и инструменты | GPT-5.3-Codex | Ниже официальная API-цена и более ясная собственная benchmark-база у OpenAI |
| Длинные задачи на уровне репозитория | Claude Opus 4.6 | 1M контекста, 128k вывода и более убедительная логика для задач, где дорого обходятся повторы |
| В вашем стеке есть оба этапа | Использовать обе модели | Пусть GPT-5.3-Codex берет дешевый первый проход, а Opus 4.6 вступает, когда растут глубина контекста и цена переделки |
Примечание по источникам: материал перепроверен по текущим официальным страницам OpenAI и Anthropic на 3 апреля 2026 года. Публичная база бенчмарков асимметрична: OpenAI публикует более богатое приложение для GPT-5.3-Codex, Anthropic дает более компактный, но все еще полезный набор публичных агентных бенчмарков для Opus 4.6. Поэтому выводы ниже нужно читать как аргументы для выбора первой модели, а не как идеально симметричную таблицу очков.
Сначала нужно точно определить объект сравнения
Это сравнение полезно только при одном условии: мы точно держим объект сравнения. GPT-5.3-Codex вышла 5 февраля 2026 года, и текущие API-документы OpenAI по-прежнему описывают ее как действующую модель для кодинга с явной ценой, режимами reasoning, endpoint-ами, окном контекста 400,000 токенов и максимальным выводом 128,000 токенов. Значит, имя модели актуально и его вполне имеет смысл напрямую сопоставлять с Claude Opus 4.6.
Изменился контекст вокруг самого продукта. Текущий каталог моделей OpenAI уже ставит GPT-5.4 на роль основного семейства для агентной, coding и профессиональной работы, а публикация от 17 марта 2026 года про GPT-5.4 mini прямо описывает Codex как систему, где большая модель берет на себя планирование и финальное решение, а меньшие модели забирают более узкие вспомогательные задачи. Это не означает, что GPT-5.3-Codex исчезла. Это означает, что многие люди, говоря "Codex", уже задают не совсем вопрос про одну конкретную модель.
Почему это важно? Потому что выбор модели и выбор продукта отвечают на разные вопросы. Сравнение моделей должно отвечать на вопрос, какую модель разумнее проверять первой. Сравнение продуктов должно отвечать, какой инструмент, какой способ работы и какой путь внедрения стоит выбрать. Эти вопросы связаны, но они не совпадают. Эта статья остается на уровне моделей именно затем, чтобы дать более острый ответ: какую модель стоит выводить на первую проверку прямо сейчас?
Быстрый снимок: где на самом деле проходит разделение
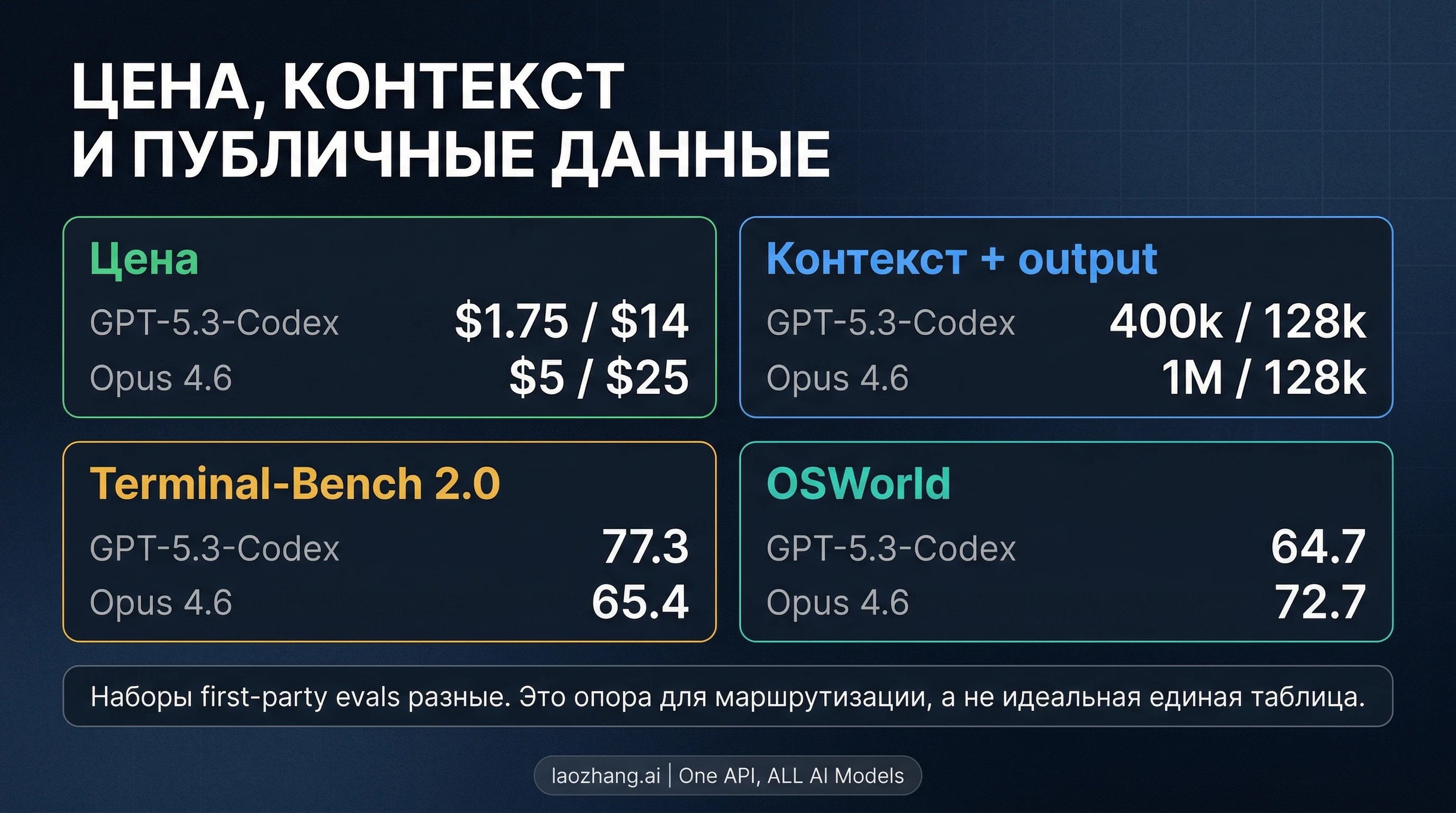
Полезнее всего читать не "кто победил в большем числе строк", а какой тип ошибки указывает каждая строка. GPT-5.3-Codex выглядит как модель, которую можно агрессивно гонять в оценочных циклах. Claude Opus 4.6 выглядит как модель, которая должна спасать от более дорогих ошибок.
| Параметр | GPT-5.3-Codex | Claude Opus 4.6 | Что это реально значит |
|---|---|---|---|
| Официальная API-цена | $1.75 input / $14 output за 1M tokens | $5 input / $25 output за 1M tokens | GPT-5.3-Codex значительно проще тестировать в большом числе повторов |
| Cached input | $0.175 за 1M tokens | Anthropic публикует цену и кэширование отдельно | OpenAI удобнее для повторяющихся оценочных прогонов |
| Context window | 400k | 1M | Opus держит заметно больший репозиторий или набор спецификаций за один проход |
| Max output | 128k | 128k | Размер вывода здесь не главный разделитель |
| Public Terminal-Bench 2.0 | 77.3 | 65.4 | У OpenAI сильнее публичный аргумент в пользу более дешевой оценки coding-agent сценариев |
| Public OSWorld | 64.7 | 72.7 | У Anthropic сильнее публичный аргумент в пользу длинного выполнения в окружении |
Уже отсюда виден главный вывод. GPT-5.3-Codex проще оправдать как дешевый первый тест, особенно если ваш вопрос звучит как "насколько далеко я могу продвинуть агент для программирования, прежде чем мне понадобятся тарифы уровня Opus". Claude Opus 4.6 легче оправдать там, где глубина контекста и цена неудачи важнее счета за токены, потому что модель может удерживать заметно больше рабочего состояния без потери запаса по выводу.
Опасность в другом: нельзя делать вид, будто эти строки складываются в один идеальный и симметричный рассказ про бенчмарки. Это не так. Цифры OpenAI идут из приложения от 5 февраля 2026 года и запускались с xhigh reasoning effort. Публичный кейс Anthropic по Opus 4.6 уже, но полезен: страницы продукта и модели подчеркивают 65.4% на Terminal-Bench 2.0, 72.7% на OSWorld, публичный 1M context и высокий приоритет для агентных задач. Этого достаточно, чтобы выбрать, с чего начинать. Этого недостаточно, чтобы честно объявить любую из сторон универсальным победителем.
Когда GPT-5.3-Codex заслуживает первой пробы
Вывод: если ваш ближайший вопрос звучит как "сколько агентной работы с кодом можно получить за меньшие деньги", то GPT-5.3-Codex логичнее проверять первой.
Основание: OpenAI показывает для нее $1.75 / $14 за миллион токенов, $0.175 cached input, 400k контекста, 128k вывода и регулируемый reasoning effort. Приложение также дает ей более полный публичный кейс для кодинга: 77.3% на Terminal-Bench 2.0 и 64.7% на OSWorld-Verified.
Практический смысл: если вы еще исследуете пределы агента для программирования и ожидаете много итераций, повторных попыток и оценочных прогонов, начинайте с GPT-5.3-Codex.
Причина здесь не в поклонении рейтингам, а в экономике. Стек разработки, который живет в повторяющихся циклах в терминале, попытках патчей, вызовах инструментов и самокоррекции, сначала тратит деньги на повторение, а уже потом на гигантский контекст. В такой системе GPT-5.3-Codex дает вам более дешевый способ понять, что вашей задаче действительно нужно. Если модель проваливается, вы уже чему-то научились без оплаты Opus-ставок на каждом шаге. Если она справляется достаточно хорошо, возможно, вам и не нужно тянуть премиальную модель через весь конвейер.
Есть и еще одна практичная причина: у OpenAI именно для такого типа задач сейчас лучше оформлен публичный пакет доказательств. Это не просто обещание "подходит для кодинга", а связка из цены, контекста и открытых тестов. Для первого этапа оценки это очень удобная отправная точка.
Когда Claude Opus 4.6 стоит пробовать первой
Вывод: если главная проблема не в цене токенов, а в длинных задачах, большой глубине контекста и дорогой цене неудачного первого прохода, то Claude Opus 4.6 имеет смысл пробовать раньше.
Основание: Anthropic показывает для Opus 4.6 $5 / $25 за миллион токенов, 1M контекста и 128k максимального вывода. Публичные страницы также подчеркивают 65.4% на Terminal-Bench 2.0, 72.7% на OSWorld и общее позиционирование модели как варианта для более длинной и тяжелой агентной работы.
Практический смысл: если вы работаете с крупными репозиториями, длинными многошаговыми задачами или такими deliverable, где неудачный первый проход потом дорого исправлять вручную, логичнее начинать с Claude Opus 4.6.

В пользу Opus работает не абстрактное "она умнее", а другая вещь: некоторые типы задач очень дорого наказывают за слабый первый проход. Если модель должна держать большой репозиторий, длинные проектные документы, длинные материалы по инцидентам или сразу выдавать крупный артефакт, то контекст 1M и вывод 128k меняют саму форму задачи.
Здесь цена токена уже не равна всей стоимости работы. Более дорогая модель может оказаться дешевле по факту, если она уменьшает число повторных запусков, время на ревью и количество правок после "почти правильного" первого ответа. Публичная история Anthropic как раз строится вокруг такого типа работы. Даже если их benchmark-набор не так симметричен, как у OpenAI, этого достаточно, чтобы считать Opus 4.6 более подходящей первой пробой для длинных и дорогих задач.
Двухмодельная схема, которую стоит проверить большинству команд
Для многих команд самый честный ответ 2026 года — не один победитель навсегда, а понятное правило переключения.
Поставьте GPT-5.3-Codex на дешевый первый проход: терминальные циклы, широкие оценочные батчи, раннюю автоматизацию, где вы только учитесь понимать форму ошибки. А когда задача перерастает в большой репозиторий, длинное многошаговое выполнение или артефакт, где неудачный первый проход дает дорогую цену переделки, переводите работу на Claude Opus 4.6. Это не вежливое "оба хороши". Это вполне конкретная двухэтапная схема.

Ключ здесь в правиле эскалации. Если запрос все еще относительно узкий, а вас прежде всего волнует цена оценочных циклов, задача должна оставаться на GPT-5.3-Codex. Если контекст разрастается, множатся повторные попытки, а сам результат становится ценным артефактом, переводите работу на Opus. И мерить этот переход нужно по цене повторных запусков и переделки, а не только по стоимости токенов. Команды, которые сравнивают только официальные тарифы, почти всегда пропускают реальную цену посредственного первого прохода.
Именно здесь упоминание продукта становится практичным, а не декоративным. Если вы заранее знаете, что хотите держать обе ветки, единый шлюз вроде laozhang.ai может уменьшить трение, связанное с отдельной оплатой, авторизацией и переключением между моделями. Причина упоминания проста: лучший практический ответ этой статьи для многих случаев — это использование обеих моделей по ролям, а такая схема проще в эксплуатации, когда интеграционный слой тоньше.
Более общий вывод такой: выбор модели должен следовать за этапом работы. Дешевая модель для первого прохода и дорогая модель для сложного выполнения могут спокойно жить внутри одной системы разработки. В 2026 году это часто оказывается более сильным инженерным решением, чем попытка заставить одну флагманскую модель делать все.
Если ваш настоящий вопрос — что такое Codex сегодня
Многие читатели, которые вводят "GPT-5.3-Codex", на самом деле частично спрашивают о другом: что такое Codex сегодня как продукт? На этот вопрос статья не должна отвечать слишком широко. Текущее продуктовое описание OpenAI уже явно сдвинулось к Codex эпохи GPT-5.4: app, CLI, IDE, cloud и более явное разделение между большими моделями для планирования и меньшими моделями для поддержки. Поэтому GPT-5.3-Codex остается здесь валидным объектом сравнения, но уже не является полным ответом о продукте.
Практический переход отсюда очень простой. Если вы выбираете модели, оставайтесь здесь и используйте правило выше. Если вы выбираете продукт или способ работы, следующим шагом должен стать гайд по OpenAI Codex за март 2026. Если ваш настоящий вопрос состоит в том, брать ли инструмент Anthropic или инструмент OpenAI, переходите к Claude Code vs Codex. А если дальнейший вопрос на стороне Anthropic больше касается разделения ролей и цены премиального сценария, тогда точнее помогут гайд по Claude 4.6 Agent Teams и руководство по цене Opus.
Итог
Если сжать все в одну короткую, но честную формулу, она будет такой. Начинайте с GPT-5.3-Codex, когда задача — это более дешевый цикл агентной работы с кодом и смысл первого раунда в том, чтобы понять, сколько полезной автоматизации можно получить без премиальных тарифов. Начинайте с Claude Opus 4.6, когда работа уже настолько длинная, что глубина контекста, стабильность выполнения и размер вывода стоят дороже, чем цена за токены. А если в вашем стеке явно живут оба этапа, перестаньте искать фальшивого универсального победителя и используйте обе модели осознанно.