
Если модель нужна вам сегодня, выбирайте GPT-5.4. Claude Mythos Preview может выглядеть сильнее по опубликованным Anthropic стартовым бенчмаркам, но это все еще закрытый research preview для приглашенных участников, а не обычная публичная модель, на которую можно просто переключиться после чтения этой статьи.
По состоянию на 9 апреля 2026 года OpenAI пишет, что GPT-5.4 уже доступен в ChatGPT, API и Codex, а Anthropic ограничивает Mythos Preview партнерами Project Glasswing и другими приглашенными организациями. Поэтому это прежде всего вопрос маршрута, а уже потом вопрос бенчмарков: большинству читателей стоит продолжать использовать GPT-5.4 сейчас и следить за Mythos только в том случае, если они уже входят в preview-аудиторию или отвечают за future-tier evals.
Краткий ответ
Если заголовок выглядел как обычное сравнение в стиле "кто победил", полезный ответ здесь намного уже.
| Ваш реальный вопрос | Что делать прямо сейчас | Почему |
|---|---|---|
| "Какую модель я могу реально использовать сегодня?" | GPT-5.4 | Она уже доступна в ChatGPT, API и Codex. |
| "Mythos Preview можно купить как обычную публичную альтернативу?" | Нет | Anthropic описывает ее как закрытый research preview для приглашенных участников. |
| "Нужно ли менять текущий план на GPT-5.4 из-за Mythos?" | Обычно нет | Лидерство в бенчмарках не отменяет разрыв в доступе. |
| "Когда за Mythos действительно стоит следить?" | Когда у вас уже есть доступ или вы ведете future-tier evals | Тогда сигнал из бенчмарков становится операционно полезным. |
Здесь особенно важно не спутать "обе стороны публикуют реальные факты" с "обе стороны описывают один и тот же тип контракта". Anthropic действительно публикует доступ, participant pricing и сильные стартовые бенчмарки для Mythos Preview. OpenAI действительно публикует публичную доступность GPT-5.4, публичные цены и рабочий маршрут через ChatGPT, API и Codex. Сравнение не выдумано, но оно асимметрично в самом важном месте: одна сторона закрыта, другая доступна уже сейчас.
Что Claude Mythos Preview представляет собой прямо сейчас

Claude Mythos Preview реален, но это не обычный публичный модельный контракт. Anthropic пишет, что доступ сейчас ограничен партнерами Project Glasswing и еще более чем 40 приглашенными организациями, работающими с критической инфраструктурой и безопасностью. Этого достаточно, чтобы относиться к Mythos серьезно. Но этого недостаточно, чтобы считать Mythos моделью, на которую обычный читатель может просто перейти после прочтения статьи.
Ценовой слой подтверждает ту же границу. Anthropic указывает для участников $25 за миллион входных токенов и $125 за миллион выходных токенов после окончания периода начальных usage credits. Эти цифры важны, если вы уже находитесь внутри preview-программы. Но они не работают как обычная публичная закупочная поверхность в том же смысле, что цены GPT-5.4 в API, потому что сначала нужно пройти сам порог доступа.
Публичная позиция Anthropic сейчас еще уже, чем это часто выглядит в новостных и агрегаторных постах. По состоянию на 9 апреля 2026 года Anthropic пишет, что не планирует делать Claude Mythos Preview общедоступным. Это не означает, что компания никогда не выпустит публичную модель класса Mythos под другим названием или контрактом. Но это означает, что прямо сейчас не стоит вести себя так, будто Mythos Preview уже находится в одном клике от обычного пользователя.
Надежная модель мышления здесь проста: Mythos Preview является сигналом о верхнем пределе возможностей, а не стандартным маршрутом по умолчанию. Он показывает, что Anthropic, возможно, снова поднял потолок на frontier-уровне. Но сам по себе этот факт не говорит большинству пользователей прекращать выбирать среди моделей, которые они действительно могут развернуть сегодня.
Что GPT-5.4 дает вам сегодня
GPT-5.4 относится к совершенно другому типу объекта. OpenAI запустил его 5 марта 2026 года и пишет, что модель уже доступна в ChatGPT, API и Codex. В рамках этой статьи это не второстепенная деталь, а часть самого ответа. Для большинства читателей главный вопрос не в том, какая лаборатория выглядит эффектнее, а в том, какой маршрут можно реально запустить, протестировать и включить в рабочий процесс уже сейчас.
OpenAI также публикует прямой и понятный прайсинг: $2.50 за миллион входных токенов, $0.25 за миллион кешированных входных токенов и $15 за миллион выходных токенов. Для длинных рабочих цепочек OpenAI отдельно пишет, что GPT-5.4 поддерживает до 1M токенов контекста в API и Codex. Иными словами, текущий контракт GPT-5.4 дает модель, для которой уже можно считать бюджет, строить тесты, писать документацию и отправлять реальные задачи в продакшен без особого preview-статуса.
Именно поэтому GPT-5.4 остается практическим маршрутом по умолчанию даже в том случае, если вы принимаете бенчмарки Anthropic всерьез. Маршрут по умолчанию определяется не заголовком о будущей мощи, а тем, куда вы можете отправить работу на этой неделе. Если следующим вашим вопросом становится доступ к GPT-5.4 и текущие ценовые развилки, полезнее перейти к нашему разбору GPT-5.4 free API. Если ваш рабочий контур завязан именно на агентную автоматизацию через Codex, практичнее открыть мартовский обзор обновления OpenAI Codex.
По этой причине сравнение не должно схлопываться в абстрактный разговор о "качестве модели". Для большинства читателей поверхность решения выглядит не как "какая лаборатория впечатляет сильнее", а как "какой маршрут я могу использовать сегодня, не притворяясь, что у меня уже есть доступ к закрытому preview".
Что официальные пересекающиеся бенчмарки доказывают и чего они не доказывают
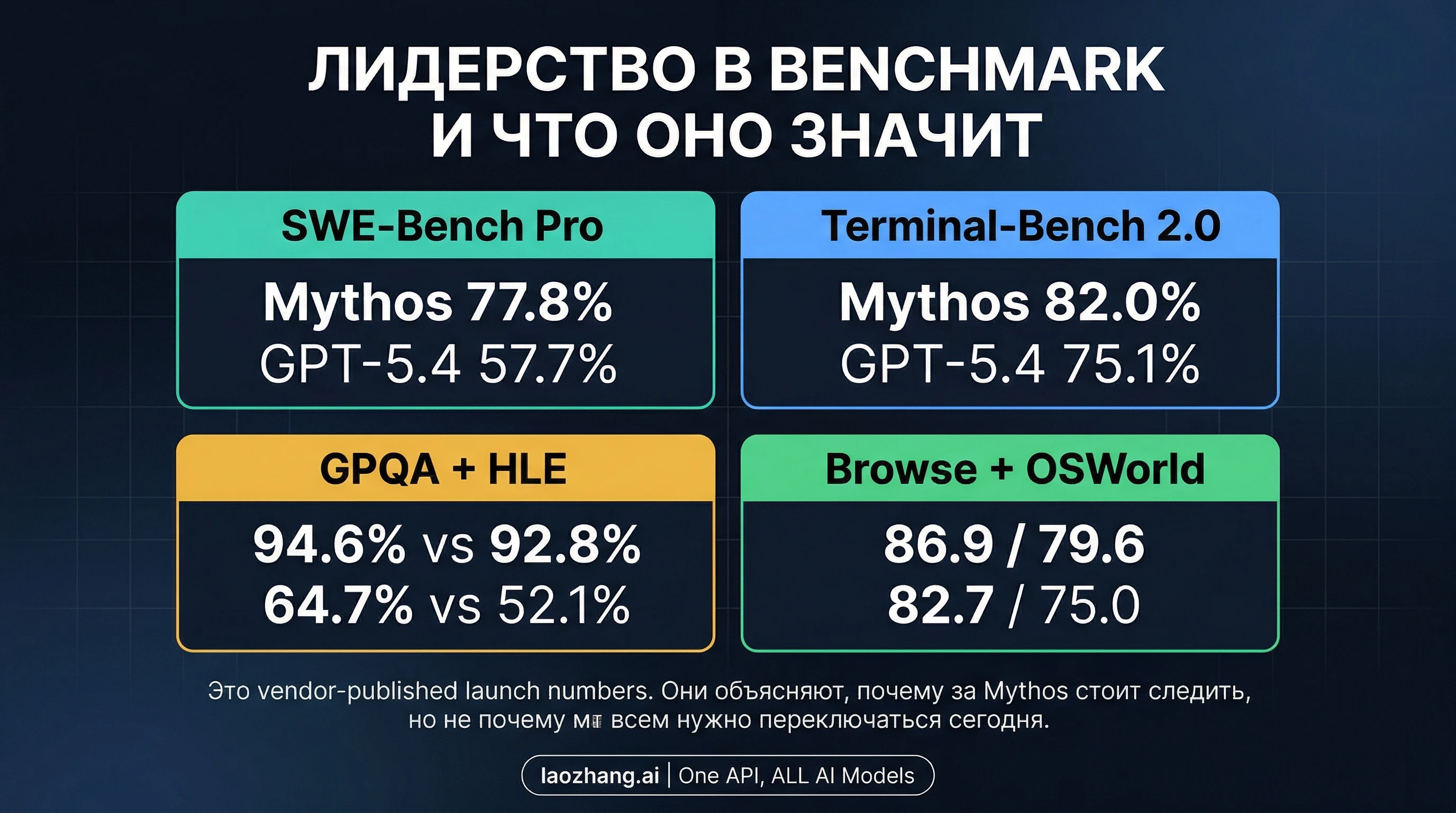
У Mythos Preview действительно есть заметное официальное преимущество на нескольких пересекающихся названиях evals. На странице Project Glasswing Anthropic публикует для Mythos Preview 77.8% на SWE-Bench Pro, 82.0% на Terminal-Bench 2.0, 93.9% на SWE-Bench Verified, 94.6% на GPQA Diamond, 64.7% на Humanity's Last Exam with tools, 86.9% на BrowseComp и 79.6% на OSWorld-Verified. На странице запуска GPT-5.4 OpenAI публикует 57.7% на SWE-Bench Pro, 75.1% на Terminal-Bench 2.0, 92.8% на GPQA Diamond, 52.1% на Humanity's Last Exam with tools, 82.7% на BrowseComp и 75.0% на OSWorld-Verified.
Эти цифры делают Mythos важным объектом наблюдения. Именно поэтому эта страница вообще заслуживает существования. Если бы Anthropic вывел закрытый preview без заметного публичного преимущества хотя бы на части известных evals, практический совет почти не изменился бы и теме не стоило бы отдавать столько экранного времени.
Но таблица бенчмарков по-прежнему не дает вам нейтрального, универсального и окончательного победителя. Anthropic и OpenAI публикуют свои стартовые цифры на собственных официальных площадках. Совпадения в названиях evals полезны, но это все еще vendor-published launch numbers, а не единое лабораторно-нейтральное табло с идентичными инструментами, настройками и бюджетами. Правильное чтение звучит так: "преимущество Mythos достаточно реально, чтобы учитывать его", а не "Mythos уже полностью заменил GPT-5.4 для любого текущего решения".
Это замечание не является риторической страховкой. Оно меняет сам маршрут выбора. Преимущество в бенчмарках означает, что Mythos должен находиться в зоне внимания у тех, кто следит за верхнеуровневыми coding, reasoning и security-adjacent evals. Но оно не заставляет обычного пользователя бросать модель, которую он может реально получить, оплатить и использовать уже сегодня.
Когда Mythos действительно должен менять ваш план

Для большинства читателей Mythos не должен менять текущий план. Если модель нужна сейчас, ответом остается GPT-5.4, потому что он уже прошел пороги доступа, цены и развертывания, которые действительно важны для сегодняшнего решения. Нет большого смысла превращать рабочий маршрут настоящего времени в режим ожидания preview-контракта, к которому вы, возможно, никогда не получите доступ.
Раньше Mythos становится важным для более узкой аудитории. Если вы уже внутри preview-программы, тогда сравнение перестает быть абстрактным. В этот момент у вас появляется реальный eval-вопрос: дает ли Mythos достаточно улучшений на ваших нагрузках, чтобы оправдать тестирование, адаптацию процессов или подготовку к будущей миграции? То же верно для команд, которые ведут frontier-model watchlists, security harnesses или escalation paths для top-end coding systems. Для них Mythos - это уже не просто громкий запуск, а ранний сигнал о том, что будущий верхний уровень Anthropic может потребовать подготовки.
Для всех остальных Mythos стоит считать сигналом для наблюдения, а не текущим пунктом назначения. Это означает: продолжать реальную работу на GPT-5.4, сохранять чистую базу для сравнения и тратить дополнительное время на Mythos только если изменится граница доступа или если ваша организация напрямую получит preview-статус. Такая позиция обычно намного полезнее, чем замораживать текущую работу из-за того, что будущая модель выглядит сильнее в стартовых таблицах.
Здесь есть и отдельная граница темы. Если ваш настоящий вопрос шире, чем Mythos против GPT-5.4, не стоит пытаться заставить эту страницу отвечать за все сразу. Значительная часть такого поискового трафика на самом деле хочет либо публичное public-vs-public сравнение, либо решение внутри экосистемы Anthropic. Это уже другие задачи читателя.
Если ваш настоящий вопрос шире, чем эта страница
Используйте эту страницу только в том случае, если ваш вопрос звучит примерно так: "Должно ли лидерство Mythos в бенчмарках менять то, что я использую прямо сейчас, если GPT-5.4 уже доступен мне сегодня?"
Если на самом деле вы решаете более широкий вопрос "Какой публичный ассистент выбрать в целом: ChatGPT или Claude?", лучше сразу перейти к нашему полному сравнению ChatGPT vs Claude. Эта статья построена вокруг public-vs-public выбора и глубже разбирает код, письмо, цены и общий продуктовый контур.
Если ваш настоящий вопрос другой: "Внутри Anthropic мне стоит использовать текущую shipping-модель или пока просто следить за preview-tier?", тогда полезнее открыть Claude Capybara vs Opus 4.6. Там фокус именно на внутренней границе Anthropic, а не на cross-vendor смешанном контракте.
Маршрутизация наружу здесь не является уходом от темы. Наоборот, именно она сохраняет странице полезность. Эта статья сильнее всего тогда, когда держит узкий фокус: преимущество Mythos в бенчмарках реально, но GPT-5.4 остается deployable default, если вы не находитесь внутри preview-аудитории.
FAQ
"Claude Mythos" и Claude Mythos Preview - это одно и то же?
В текущем публичном употреблении "Claude Mythos" обычно является короткой формой официального имени Claude Mythos Preview. Важнее не разница между коротким и полным названием, а то, что Anthropic описывает Mythos как закрытый preview, а не как публичный self-serve продукт.
Делает ли participant pricing Mythos нормальной альтернативой GPT-5.4?
Нет. У Anthropic действительно есть participant pricing для Mythos Preview, но он привязан к закрытой preview-поверхности. Прайсинг GPT-5.4 привязан к публичному маршруту, который можно реально купить и развернуть уже сегодня. Это неэквивалентные условия закупки.
Значит ли это, что Mythos уже "в целом лучше" GPT-5.4?
Точнее сказать, что Mythos лидирует на нескольких пересекающихся vendor-published launch benchmarks. Это не то же самое, что доказать универсального победителя для любых рабочих процессов, инструментальных конфигураций, задержек и условий доступа.
Может быть, вместо Mythos вообще стоит сравнивать GPT-5.4 с Opus?
Да, если ваш реальный выбор происходит между моделями, которые можно использовать публично прямо сейчас. В таком случае лучше идти в ChatGPT vs Claude для cross-platform выбора или в Claude Capybara vs Opus 4.6 для Anthropic-only маршрута.
Какой итог в одной фразе?
Преимущество в бенчмарках делает Mythos достойным наблюдения. Но этого недостаточно, чтобы вытеснить GPT-5.4 с позиции текущего маршрута по умолчанию для большинства пользователей. Если модель нужна сегодня, используйте GPT-5.4 сейчас. Если у вас уже есть preview-доступ или вы ведете future-tier evals, держите Mythos в активном списке наблюдения и тестируйте его в этом более узком контексте.