Нет универсального ответа, какая платформа дешевле: Claude API или OpenAI API. Для коротких массовых задач, где достаточно GPT-5.4 mini, OpenAI обычно начинает с более низкой строки цены. Для длинного контекста, coding agents, сложного reasoning и высокой повторяемости контекста Claude может дать меньшую итоговую стоимость, даже если одна базовая строка кажется дороже.
Проверка выполнена 2 мая 2026 года. Страница OpenAI API Pricing показывает GPT-5.5: $5 за 1M input tokens, $0.50 за cached input и $30 за output; GPT-5.4: $2.50 / $0.25 / $15; GPT-5.4 mini: $0.75 / $0.075 / $4.50. Заметка OpenAI о GPT-5.5 была обновлена 24 апреля 2026 года: GPT-5.5 и GPT-5.5 Pro теперь доступны в API, но перед production-расчетом все равно надо проверить, включен ли он в вашем аккаунте. Страница Anthropic Pricing показывает Claude Opus 4.7: $5 input и $25 output, Sonnet 4.6: $3 / $15, Haiku 4.5: $1 / $5 за 1M tokens, плюс отдельные правила для cache, batch, data residency, long context и tools.
Быстрый ответ: сначала workload, потом provider
| Сценарий | Что тестировать первым | Почему |
|---|---|---|
| Классификация, extraction, короткие summary | OpenAI GPT-5.4 mini | Базовая строка ниже Claude Haiku 4.5. |
| Сложное кодирование или professional reasoning | GPT-5.5 и Claude Opus 4.7 на одном наборе задач | Цена input похожа, output у Opus ниже, но retries и качество меняют картину. |
| Длинные документы и multi-file analysis | Claude Opus 4.7 или Sonnet 4.6 | Anthropic явно описывает 1M context для этих моделей на standard pricing. |
| Большие offline jobs | Batch на обеих платформах | У обеих сторон есть 50% batch discount, если latency допустима. |
| Повторяемый system prompt или RAG context | Считать cache hit rate | Cached input может стать важнее базовой цены. |
Строки цены являются якорем, а не решением
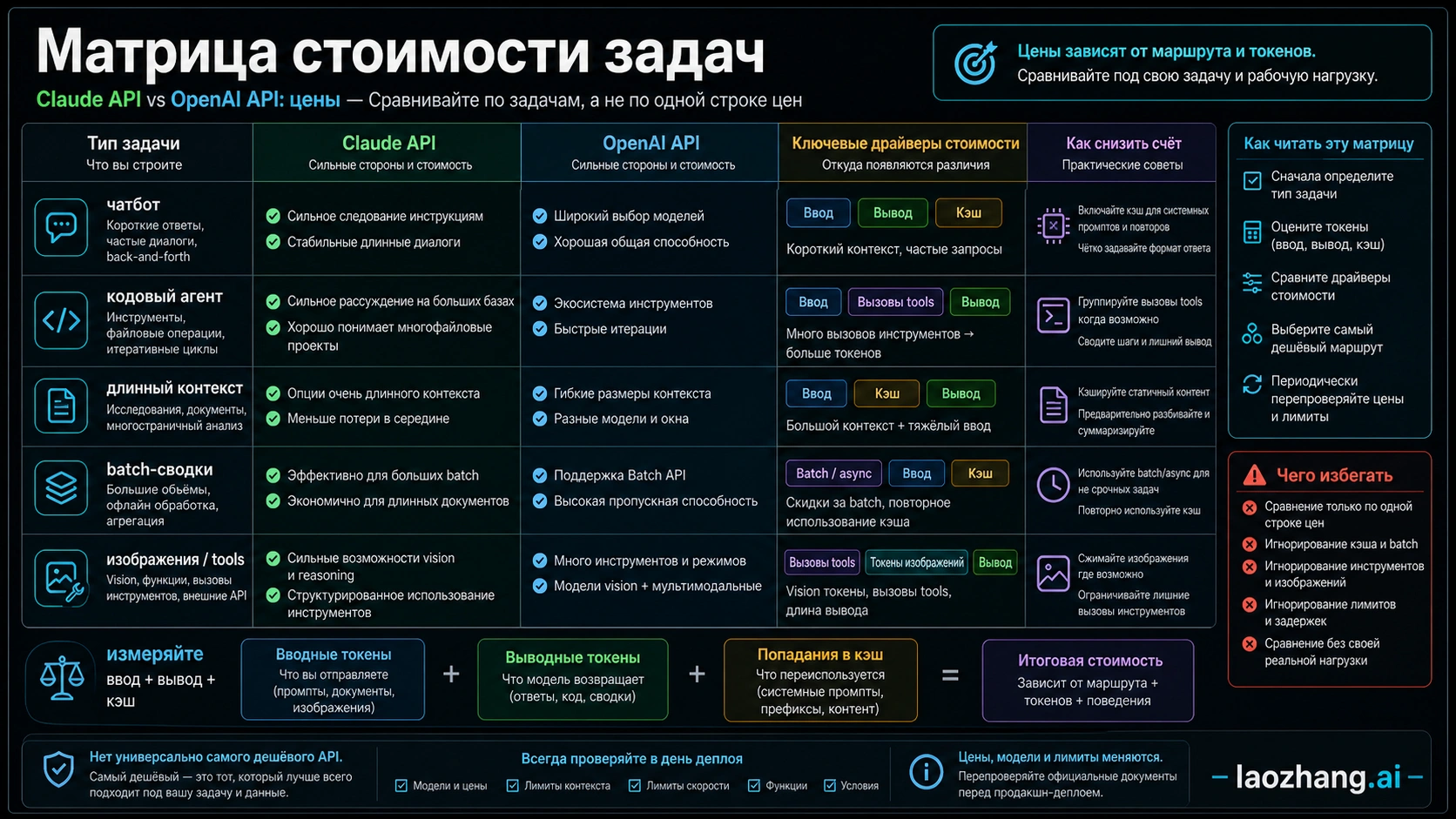
Если сравнивать только таблицы, GPT-5.4 mini дешевле Haiku 4.5, а GPT-5.4 дешевле Sonnet 4.6 по input и равен по output. Сравнение GPT-5.5 и Opus 4.7 уже не такое простое: input одинаковый, output у Claude ниже, но доступность GPT-5.5 в API надо проверять отдельно.
Реальная цена считается не за токен, а за успешную задачу. Если модель дает длиннее ответы, чаще ошибается, требует больше tool calls или хуже держит контекст, дешевая строка быстро теряет преимущество. Если Claude снижает retries в long-context или coding-agent workflow, он может оказаться дешевле по конечному результату.
Cache и batch часто переворачивают выбор
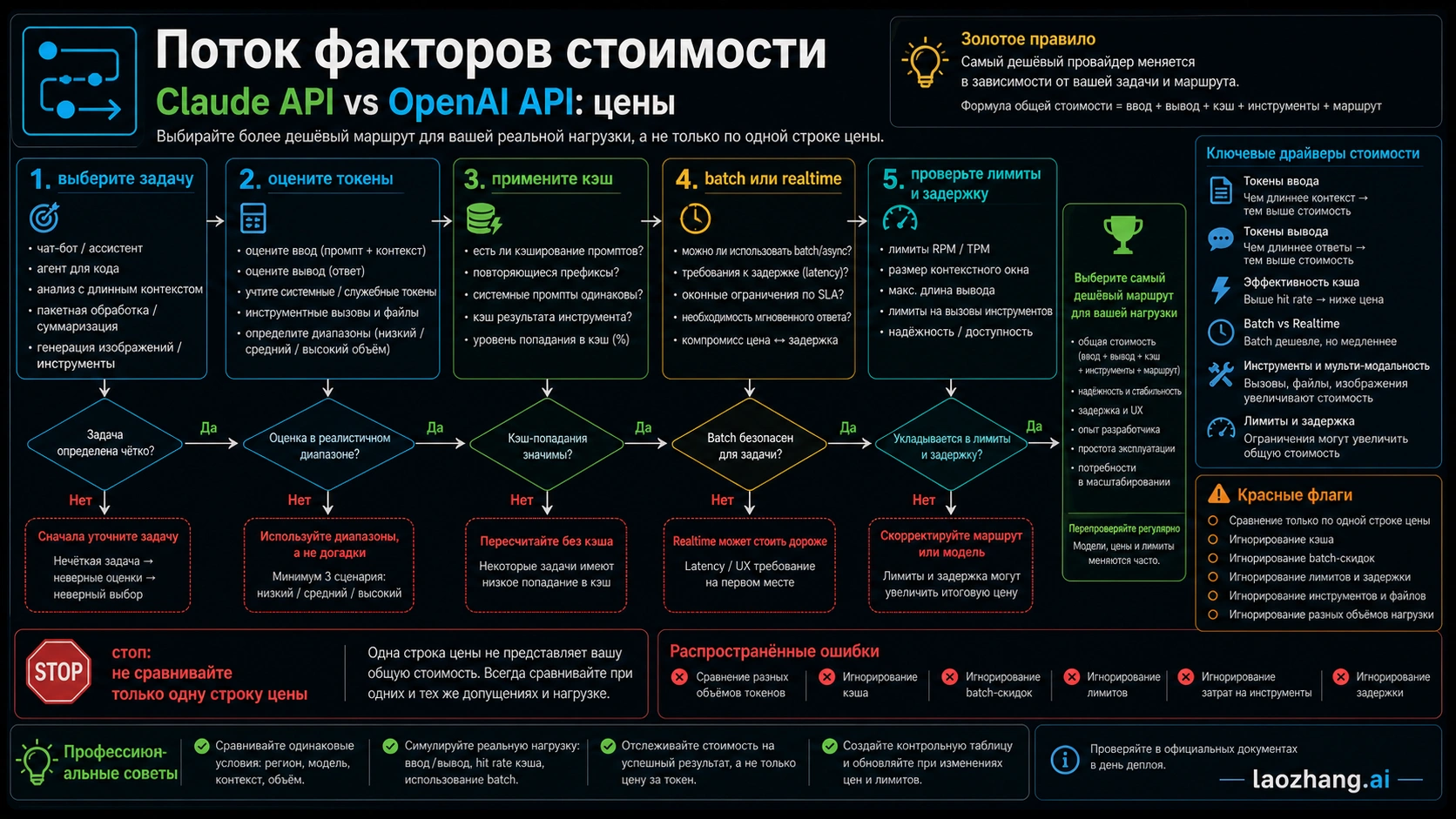
Prompt caching особенно важен для больших system prompts, policy packs, tool schemas и RAG documents. Anthropic указывает 1.25x base input для 5-minute cache write, 2x для 1-hour write и 0.1x для cache hit. OpenAI публикует отдельные cached input строки. Поэтому считайте первый запрос и повторные cache-hit запросы отдельно.
Batch нужен там, где работа не realtime. OpenAI говорит о 50% экономии input и output через Batch API, Anthropic также указывает 50% discount для batch. Для offline summarization, evaluation, classification и migration QA вопрос "batch или realtime" может быть важнее вопроса "Claude или OpenAI".
Когда OpenAI дешевле по умолчанию
OpenAI стоит тестировать первым для больших простых потоков: classification, extraction, JSON transformation, короткие support drafts, title generation и краткие summary. Если GPT-5.4 mini проходит quality bar, нет смысла начинать с frontier-модели.
OpenAI также удобен, когда cached input и batch совпадают с вашим traffic pattern. Если prompts короткие, output короткий, context небольшой, а качество стабильно, нижняя строка mini-модели дает сильную экономию. Если GPT-5.5 еще не доступен в вашем API account, используйте GPT-5.4 family как текущий production comparator.
Когда Claude оправдывает цену
Claude надо считать отдельно для long-context research, multi-file coding, agent loops, contract review, support knowledge bases и workflows, где одна ошибка стоит дорого. В таких задачах дешевый токен не гарантирует дешевый результат.
Anthropic также отмечает, что новый tokenizer Opus 4.7 может использовать до 35% больше tokens для того же fixed text. Это прямое предупреждение: нельзя сравнивать word count как cost count. Берите реальные samples, прогоняйте tokenizer и сравнивайте low, typical и high output cases.
Мини-калькулятор для команды
| Cost unit | Что измерить |
|---|---|
| Input tokens | system prompt, user text, RAG, tools, files, image-related input |
| Output tokens | final answer, code, JSON, explanations, summaries |
| Cache | write size, read size, hit rate, TTL |
| Batch | можно ли ждать и поддерживает ли route нужную feature |
| Tools | web search, code execution, image generation, server-side tools |
| Retries | failed calls, truncation, manual reruns, poor quality |
| Route premium | data residency, regional endpoints, priority or fast modes |
Проверка перед деплоем
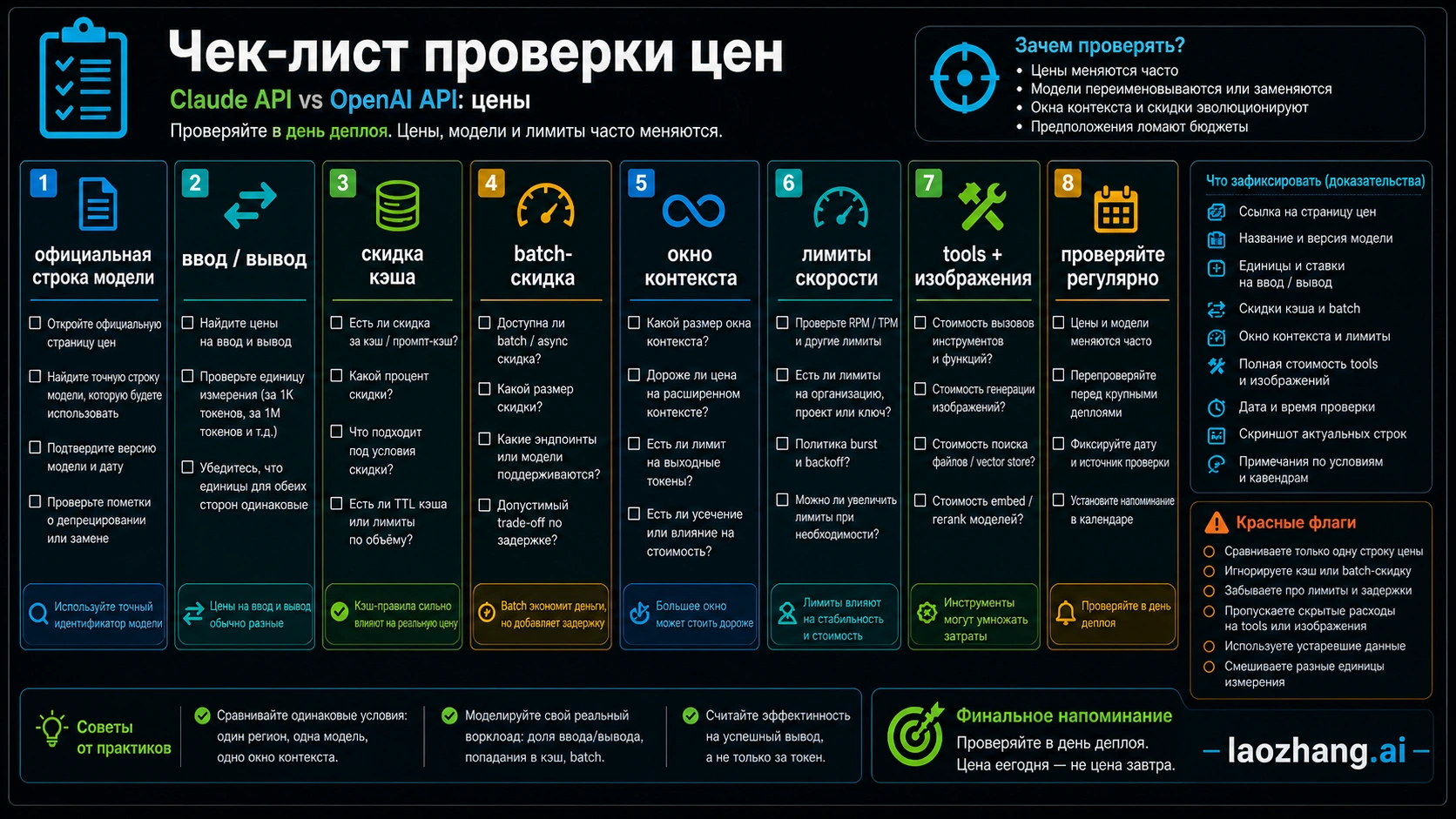
В день деплоя откройте OpenAI API pricing, GPT-5.5 availability note и Anthropic pricing. Проверьте точную модель, доступ в аккаунте, input/output, cache, batch, context, rate limits, tool charges и route premiums. Калькуляторы и форумы полезны для сценариев, но не являются источником цены.
Еще две проверки на реальных данных
Не считайте только один средний запрос. Возьмите минимум три набора: короткий input и короткий output, длинный input и короткий output, длинный input и длинный output. Для каждого набора запишите input tokens, output tokens, повторяемый контекст, batch-возможность, cache hit rate и число retries. После этого станет видно, что один provider может выигрывать в коротких задачах, а другой — в long-context или agentic сценариях.
Отдельно проверьте крайние случаи: самый большой документ, самый тяжелый tool schema, самый длинный agent loop и самый строгий ответ с фактами. Сравните не только цену, но и truncation, formatting errors, manual repair time и долю задач, которые прошли quality bar с первой попытки. Для production команды дорогой маршрут часто появляется не в строке pricing, а в retries, очередях, исправлениях и задержках.
FAQ
Claude API или OpenAI API дешевле?
OpenAI чаще дешевле для простых массовых задач. Claude надо тестировать для long context, agents, cache-heavy workflows и задач, где меньше retries важнее низкой строки цены.
Можно ли сравнивать GPT-5.5 и Claude Opus 4.7?
Да, но укажите дату и доступность API. OpenAI публикует цену GPT-5.5 и обновила заметку 24 апреля 2026 года: GPT-5.5 доступен в API; Anthropic уже показывает Opus 4.7 как текущую API модель.
Cache всегда экономит?
Нет. Cache write без последующих reads может стоить дороже. Экономия появляется при повторном использовании большого стабильного контекста.
Batch всегда лучше?
Нет. Batch подходит для offline jobs. Realtime UX, interactive agents и low-latency coding не должны жертвовать задержкой ради скидки.