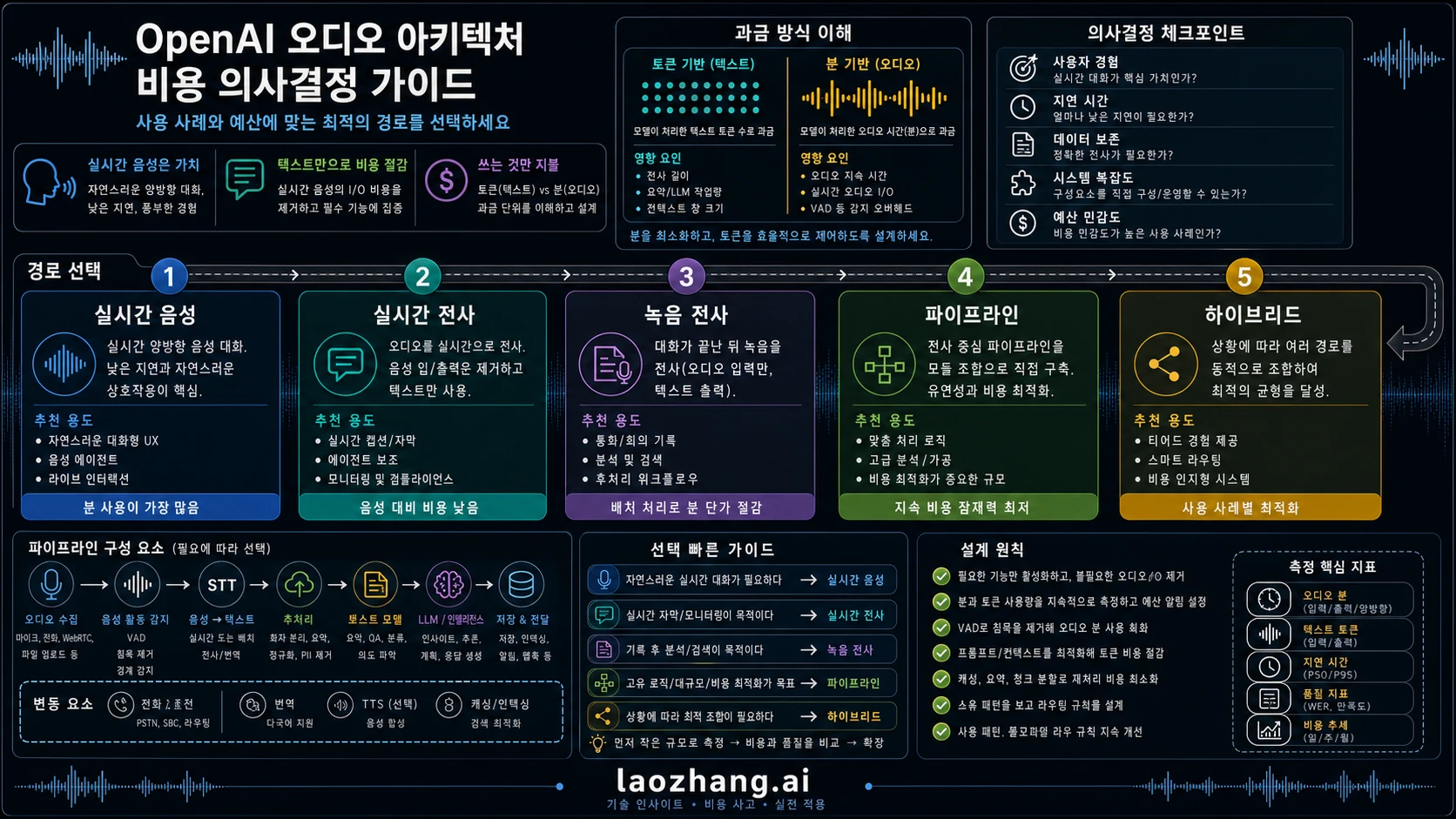
Realtime API와 전사 파이프라인을 비교할 때 먼저 볼 것은 분당 가격이 아니다. 제품이 통화 중 사용자의 말을 이해하고, 끼어들기를 처리하고, tool을 호출하고, 자연스러운 음성으로 바로 답해야 하는지를 먼저 봐야 한다. 그 실시간 음성 상호작용이 제품 가치라면 gpt-realtime-2 비용은 검토할 만하다. 결과물이 transcript, summary, archive, QA review, compliance trail, analytics feed라면 전사 우선 경로부터 모델링하는 편이 맞다.
가격표보다 먼저 경로를 고른다.
- 실시간 음성 에이전트: 음성 품질, interruption, turn-taking, 낮은 지연, 통화 중 tool use가 가치일 때
gpt-realtime-2를 사용한다. - 실시간 텍스트 전사: 사람이 말하는 동안 텍스트만 필요하고 음성으로 답하는 assistant가 필요 없으면
gpt-realtime-whisper를 본다. - 녹음 또는 파일 전사: 오디오를 업로드하거나 녹음 후 request로 처리할 수 있으면
gpt-4o-transcribe와gpt-4o-mini-transcribe를 비교한다. - 자체 파이프라인: STT, text model, optional TTS, telephony, storage, monitoring, QA는 실제 workflow가 요구할 때만 추가한다.
- 하이브리드: Realtime은 고가치 live moment에만 쓰고 archive, review, summaries, analytics는 전사 우선으로 보낸다.
2026년 6월 14일 기준 OpenAI는 gpt-realtime-whisper를 $0.017/minute, gpt-4o-transcribe를 estimated $0.006/minute, gpt-4o-mini-transcribe를 estimated $0.003/minute로 표시한다. 단순 환산하면 각각 $1.02/hour, $0.36/hour, $0.18/hour다. gpt-realtime-2 음성 에이전트는 다르다. audio input과 audio output이 token으로 과금되고, 사용자 음성 1시간과 assistant 음성 출력 1시간이 모두 잡히면 text tokens, tool calls, 반복되는 conversation history, optional input transcription, telephony, pipeline components를 빼고도 $5.76/hour의 media-token floor가 생긴다.
중단 규칙은 간단하다. 텍스트로 충분하면 spoken assistant output에 돈을 내지 않는다. 아래에서는 low-latency speech가 추가 비용을 정당화하는 경우, Realtime 비용이 커지는 이유, 전사 파이프라인에서 계속 변수로 남겨야 할 비용을 worksheet로 정리한다.
먼저 제품 작업으로 경로를 고른다
“Realtime API vs 전사 파이프라인 비용”은 추상적인 가격 비교가 아니다. 제품 작업을 먼저 정하고, OpenAI 경로를 고른 뒤, billing unit과 주변 component를 계산해야 한다. 순서가 바뀌면 실시간 전사와 음성 에이전트를 같은 Realtime으로 묶어 잘못된 시간 단가를 비교하게 된다.
| 제품 작업 | 먼저 견적 낼 경로 | 모델링할 비용 단위 | 쓸 때 | 중단 규칙 |
|---|---|---|---|---|
| 실시간 음성 에이전트 | gpt-realtime-2 | Response마다 audio와 text tokens | 사용자가 interruption, turn-taking, tool use, spoken output을 세션 중 필요로 할 때 | text output으로 충분하면 여기서 시작하지 않는다 |
| 실시간 전사만 | gpt-realtime-whisper | live audio minutes | 말하는 동안 텍스트가 필요할 때 | 오디오가 기다릴 수 있으면 bounded transcription을 먼저 본다 |
| 녹음 오디오를 텍스트로 | gpt-4o-transcribe 또는 gpt-4o-mini-transcribe | submitted audio minutes | files, recordings, post-call review, summaries, QA, compliance | live deltas가 필요하면 realtime transcription으로 간다 |
| Custom pipeline | STT -> text model -> optional TTS -> operations layer | component별 meter | control, vendor mix, telephony fit, auditability, optimization이 필요할 때 | TTS, telephony, text model을 이유 없이 넣지 않는다 |
| Hybrid | live moment는 Realtime, back office는 transcription-first | combined meters | live help는 가치가 있지만 archive와 analytics는 음성이 필요 없을 때 | live session 끝과 back-office 시작을 측정한다 |
이 표는 음성 제품을 하나의 가격표로 뭉개는 실수를 막는다. 음성 에이전트는 interactive spoken loop를 사는 것이고, 전사 파이프라인은 텍스트와 downstream processing을 사는 것이다. 둘 다 오디오에서 시작할 수 있지만 결과물은 다르다.
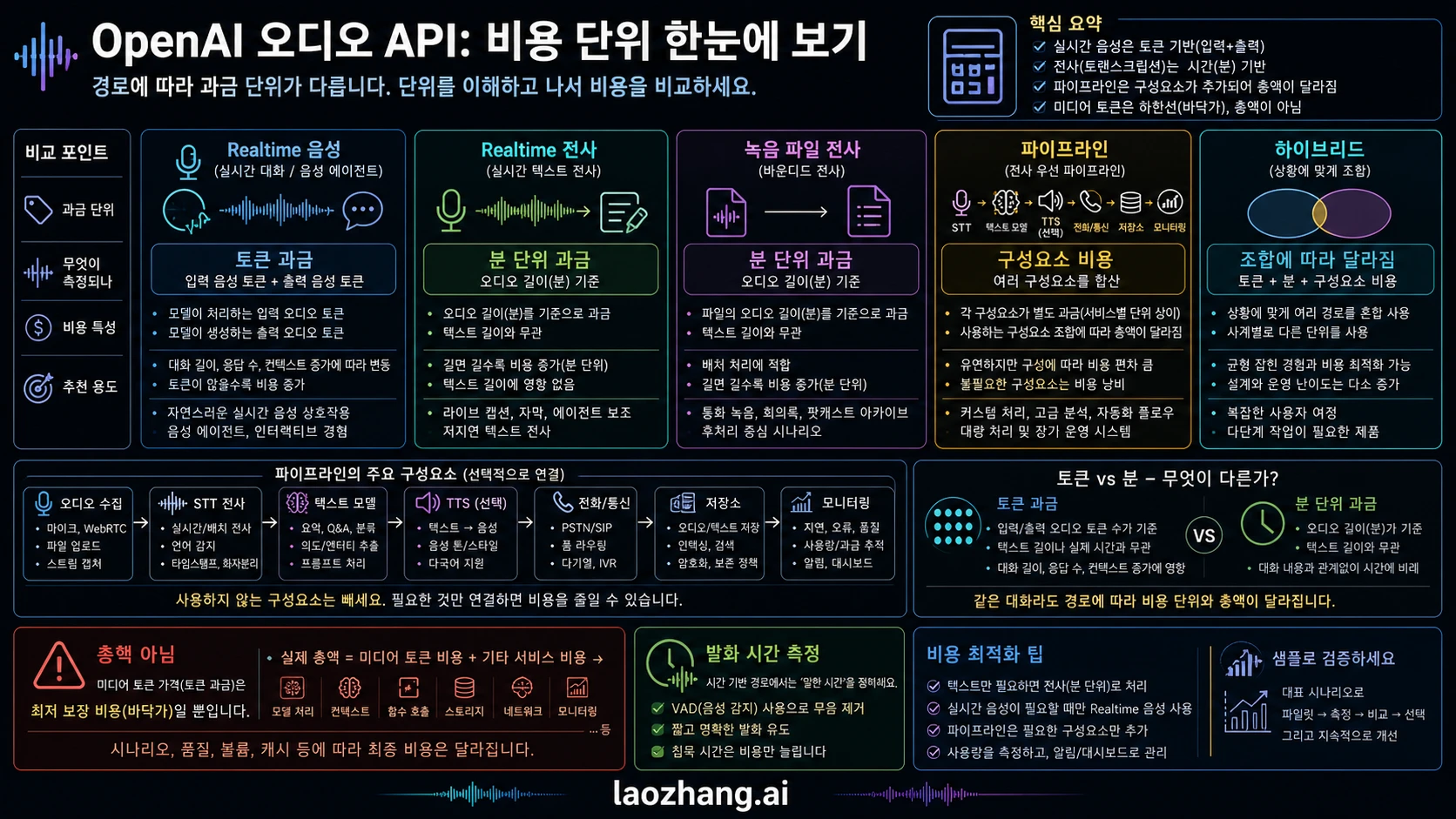
지금 기준으로 잡아야 할 OpenAI 공식 가격
OpenAI의 현재 price row를 anchor로 삼고, 그다음 실제 workload를 더한다. 2026년 6월 14일 OpenAI pricing page에서 확인한 이 결정에 필요한 rows는 다음과 같다.
| 경로 | Current OpenAI price row | 시간당 감각 | 포함하지 않는 것 |
|---|---|---|---|
gpt-realtime-whisper | $0.017/minute | 직접 환산 $1.02/hour | text model work, storage, monitoring, telephony, non-OpenAI components |
gpt-4o-transcribe | estimated $0.006/minute | 직접 환산 $0.36/hour | post-processing, summaries, classification, storage, orchestration |
gpt-4o-mini-transcribe | estimated $0.003/minute | 직접 환산 $0.18/hour | accuracy review, domain tuning, retries, operations work |
gpt-realtime-2 audio input | $32.00/1M audio input tokens | user audio 1 token/100 ms 기준 $1.152/hour | assistant audio, text, tools, history growth, optional transcription, pipeline components |
gpt-realtime-2 audio output | $64.00/1M audio output tokens | assistant audio 1 token/50 ms 기준 $4.608/hour | user audio, text, tools, history growth, optional transcription, pipeline components |
분 단위 전사는 바로 계산된다.
textgpt-realtime-whisper: 60 minutes * $0.017 = $1.02/hour gpt-4o-transcribe: 60 minutes * $0.006 = $0.36/hour gpt-4o-mini-transcribe: 60 minutes * $0.003 = $0.18/hour
gpt-realtime-2의 media-token floor도 계산할 수 있지만, 이것은 floor일 뿐 견적서가 아니다.
textUser audio input: 36,000 tokens/hour * $32 / 1,000,000 = $1.152/hour Assistant audio output: 72,000 tokens/hour * $64 / 1,000,000 = $4.608/hour Media-token floor: $1.152 + $4.608 = $5.76/hour
$5.76/hour를 Realtime의 최종 시간 단가로 쓰면 안 된다. 이 숫자는 사용자 음성 1시간과 assistant 음성 출력 1시간만 놓은 바닥값이다. text tokens, repeated conversation context, tool schemas, tool results, optional input transcription, special tokens, telephony, storage, monitoring, Realtime 밖의 pipeline은 빠져 있다.
Realtime 음성 에이전트 비용이 커지는 이유
Realtime cost guide는 voice-agent session이 단순 audio file과 다른 이유를 설명한다. 비용은 Response가 생성될 때 발생하고 input/output tokens를 기준으로 한다. input transcription을 켜면 별도 transcription model 비용이 붙는다. OpenAI는 connection과 network bandwidth가 현재 별도 과금되지 않는다고 설명하지만, 세션이 열려 있다고 해서 생성 비용이 사라지는 것은 아니다.
실무의 cost drivers는 다음과 같다.
- User audio: 1 token per 100 ms.
- Assistant audio: 1 token per 50 ms. 긴 답변은 media floor를 크게 밀어 올린다.
- Response count: 각 Response는 새로운 generation event다.
- Conversation history: 이전 대화가 다시 context로 들어가므로 후반 turn이 비싸질 수 있다.
- Empty audio control: VAD가 silence를 거를 수 있지만 client가 수동 추가하면 낭비된다.
- Text and tool work: instructions, tool schemas, tool results, text output도 token을 쓴다.
- Optional input transcription: 세션 안에서 transcript가 필요하면 별도 transcription cost가 생긴다.
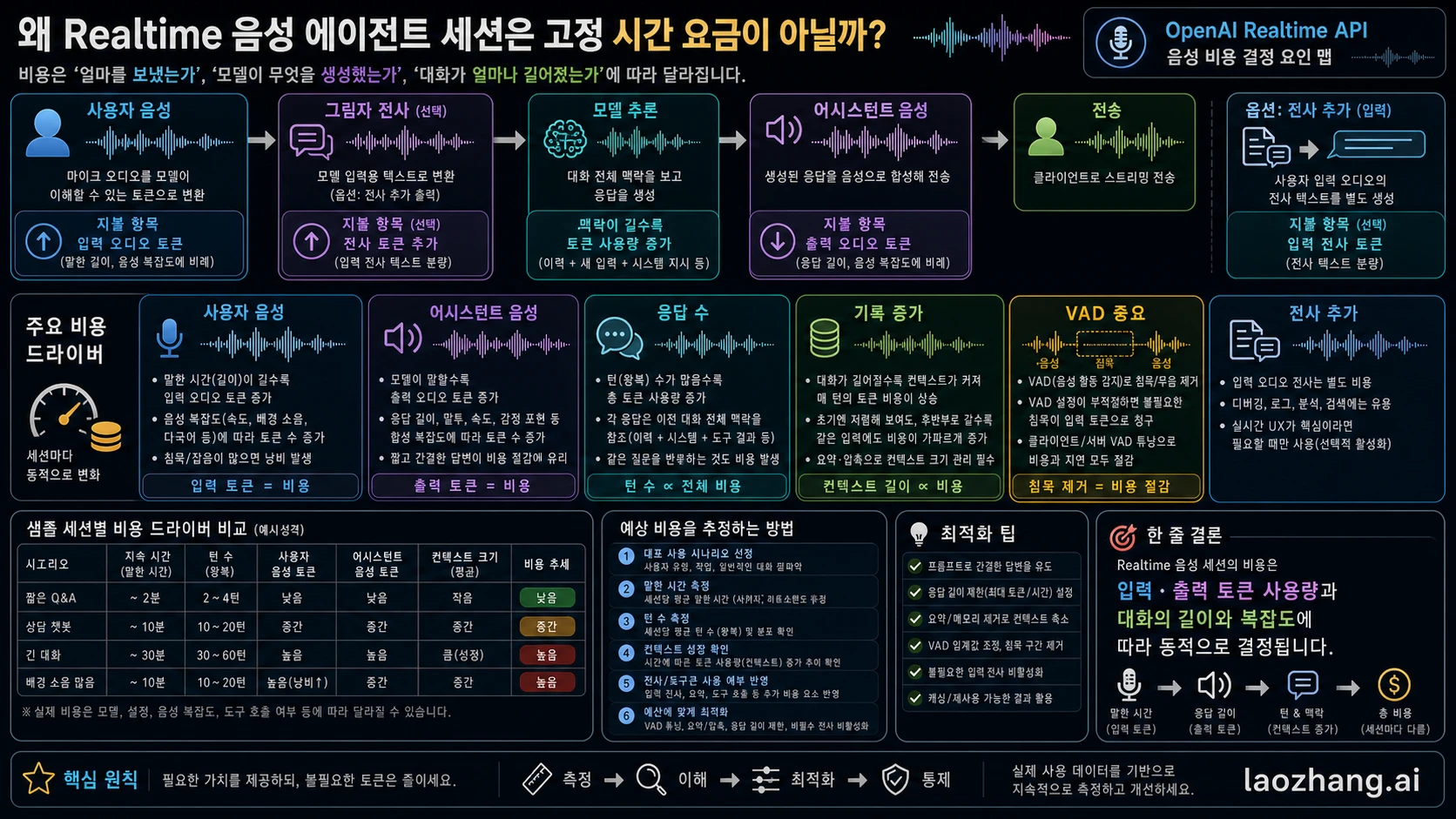
그래서 “Realtime은 시간당 얼마”라는 답은 launch planning에 부족하다. assistant가 짧게 답하는 60분 support call과, assistant가 자주 말하고 tools를 쓰며 긴 context를 유지하는 20분 tutoring session은 전혀 다른 bill을 만들 수 있다.
절약은 경로 변경보다 세션 설계에서 시작한다. VAD를 유지해 silence가 input에 들어가지 않게 한다. old history가 다음 답을 개선하지 않으면 세션을 끝내거나 summarize한다. tool schemas와 system instructions를 줄인다. 짧은 답으로 충분하면 assistant monologue를 피한다. input transcription은 세션 안의 transcript가 제품에 필요할 때만 켠다. pilot에서는 Response count, assistant speech duration, late-turn history size를 실제로 측정한다.
Realtime의 장점도 분명하다. gpt-realtime-2는 low latency, interruption handling, voice response quality, tool use during conversation을 하나의 native spoken interaction loop로 제공한다. 이 특성이 conversion, containment, accessibility, task completion을 올린다면 추가 비용은 낭비가 아니라 제품 비용이다.
전사 우선 파이프라인 비용 모델
전사 우선 파이프라인은 첫 paid step을 plain speech-to-text로 둘 수 있어 저렴하게 시작한다. Files와 bounded audio에 대해 Speech to text guide는 gpt-4o-transcribe, gpt-4o-mini-transcribe, gpt-4o-transcribe-diarize 같은 route를 제시한다. file uploads는 25 MB cap이 있고 live transcript deltas와 모양이 다르다. spoken assistant 없이 live text만 필요하면 Realtime transcription guide의 gpt-realtime-whisper가 맞다.
제품이 텍스트만 만들지 않는다면 STT에서 멈추면 안 된다. summaries, extraction, routing, QA, coaching, moderation, analytics, compliance가 있다면 stack 전체를 센다.
| Component | Count as | Price treatment |
|---|---|---|
| Audio capture and transport | app, browser, WebRTC, telephony, recording infrastructure | stack과 region에 따라 variable |
| STT | gpt-realtime-whisper, gpt-4o-transcribe, gpt-4o-mini-transcribe | OpenAI minute rows가 estimate anchor |
| Text model | summarization, extraction, routing, QA, coaching, moderation, agent logic | model, tokens, cache, retries에 따라 variable |
| Optional TTS | text processing 뒤 speech output | launch route에서 검증 전까지 variable |
| Telephony | PSTN, SIP, call recording, phone numbers, compliance features | provider와 region별 확인 |
| Storage and retrieval | audio files, transcripts, embeddings, logs, retention policy | privacy와 retention policy에 따라 variable |
| Monitoring and QA | human review, audits, metrics, failure replay, alerting | regulated workflow에서는 STT row보다 클 수 있음 |
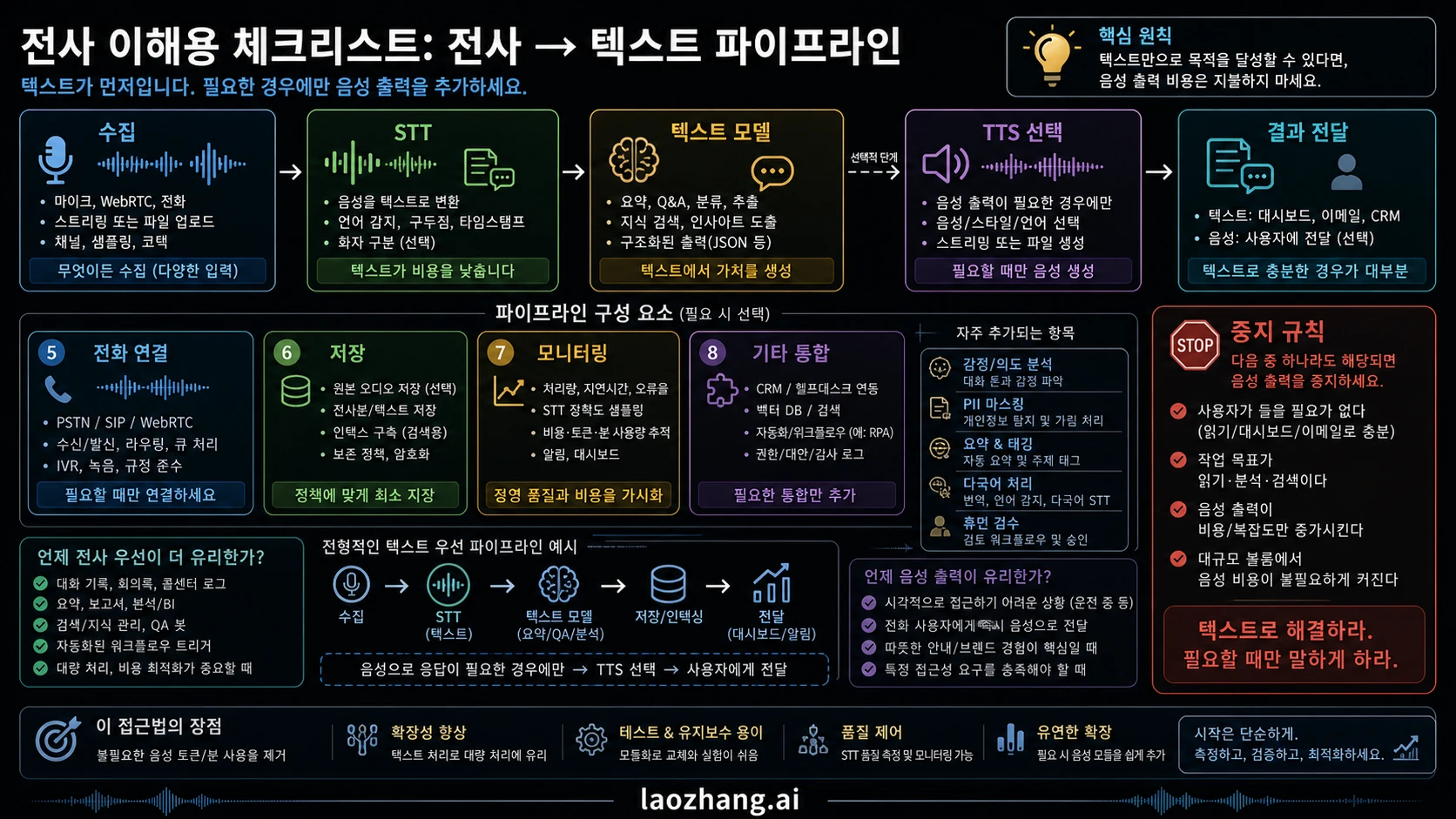
이 pipeline은 spoken output이 필요 없는 제품에서 Realtime voice-agent session보다 예측 가능하고 저렴할 수 있다. 디버깅도 쉽다. audio, transcript, text-model output, summary, classification, audit log 같은 artifact가 남기 때문이다.
대가는 latency와 integration load다. STT -> text model -> TTS를 stream으로 묶어도 native spoken session과 같아지지는 않는다. workflow가 text-centered이거나 component control이 중요하기 때문에 고르는 것이지, STT row가 싸 보인다고 전체가 항상 싸다고 말하면 안 된다.
실시간 음성에 돈을 쓸 가치가 있는 경우
gpt-realtime-2에 비용을 쓰는 것은 spoken interaction이 session 중 user behavior를 바꿀 때다. sales나 onboarding call, interruption이 중요한 tutoring/coaching, accessibility flow, 사용자가 있는 동안 tools를 호출하는 voice agent, speech quality가 interface인 consumer voice UX, human escalation을 줄이는 support containment가 후보가 된다.
pilot question은 “Realtime이 STT보다 비싼가”가 아니다. “live speech가 추가 meter를 정당화할 value를 만드는가”다. 다음을 측정한다.
| Metric | Why it matters |
|---|---|
| real user talk time | counted user audio를 결정한다 |
| assistant speech time | audio output을 결정하고 media-token floor를 지배하기 쉽다 |
| Responses per session | generation event 수를 통제한다 |
| average history size by turn | late-session cost growth를 보여준다 |
| tool calls per session | hidden text와 tool context를 포착한다 |
| completion or containment lift | voice loop가 비용을 회수하는지 알려준다 |
| human fallback rate | 전사 route로 충분한 케이스를 찾는다 |
이 metrics가 business outcome이나 user outcome을 개선한다면 Realtime은 raw hourly row가 높아도 맞는 지출이 될 수 있다. 개선이 없다면 모든 audio workflow를 Realtime으로 확대하지 않는다.
전사 우선이 이기는 경우
text가 최종 artifact라면 transcription-first로 시작한다. meeting summaries, call QA, compliance review, searchable archives, support analytics, coaching notes, review가 필요한 medical/legal intake drafts, asynchronous voice notes, post-call classification이 대표적이다.
중단 규칙은 실제적이다. 사용자가 assistant의 목소리를 필요로 하지 않으면 assistant audio output 비용을 내지 않는다. transcript가 오디오 종료 뒤에 와도 되면 bounded transcription을 먼저 비교한다. live captions만 필요하면 gpt-realtime-whisper를 gpt-realtime-2보다 먼저 가격 산정한다. summaries와 classifications가 capture 후 실행되면 STT row 밖의 text-model work로 예산화한다. compliance trail이 필요하면 pipeline artifacts가 live spoken loop보다 검토하기 쉬운 경우가 많다.
이 경로는 quality gate도 만들기 쉽다. original audio를 보관하고, transcription을 rerun하고, model outputs를 비교하고, prompt changes를 검사하고, non-urgent work를 batch 처리하고, high-risk samples만 human review로 보낼 수 있다. 운영팀에는 몇 초의 latency보다 이런 control이 더 중요할 때가 많다.
하이브리드: Realtime은 가치가 있는 실시간 구간에만 쓴다
production에서는 hybrid가 가장 현실적일 때가 많다. speech가 결과를 바꾸는 live segment에는 Realtime을 쓰고, spoken output이 필요 없는 archive, review, compliance, analytics는 transcription-first processing으로 보낸다.
간단한 hybrid sequence는 다음과 같다.
- interruption, turn-taking, speech가 필요한 live interaction에만
gpt-realtime-2session을 시작한다. - user audio duration, assistant audio duration, Response count, tool calls, input transcription 여부를 기록한다.
- product와 privacy policy가 필요로 할 때만 transcript artifact를 저장하거나 export한다.
- post-call summaries, QA, compliance classification, analytics, search indexing은 text 또는 transcription-first route로 실행한다.
- live boundary와 back-office boundary가 안정될 때까지 sample sessions를 매주 review한다.
이렇게 하면 가장 비싼 route가 실제로 필요한 구간에 붙어 있다. onboarding agent는 통화 중 Realtime을 쓰고 CRM notes와 QA는 나중에 처리할 수 있다. call-center monitor는 supervisor visibility를 위해 live transcription을 쓰되 voice agent가 전 시간을 말하게 하지 않을 수 있다. voice note app은 정확한 text와 clean summary만 필요하다면 Realtime을 쓰지 않아도 된다.
하이브리드의 핵심은 live value가 끝나는 지점을 정하는 것이다. 그 이후의 각 step은 왜 realtime speech가 필요한지 다시 증명해야 한다.
예산 워크시트
최소 세 가지 estimate를 만든다. transcription-only, Realtime media floor, full pipeline이다. 먼저 공식 row를 넣고 pilot data로 placeholder를 바꾼다.
| Worksheet line | Formula |
|---|---|
| Live transcript-only cost | live_audio_minutes * $0.017 for gpt-realtime-whisper |
| Bounded high-accuracy transcription cost | audio_minutes * $0.006 for gpt-4o-transcribe |
| Bounded low-cost transcription cost | audio_minutes * $0.003 for gpt-4o-mini-transcribe |
| Realtime user-audio floor | user_audio_hours * $1.152 for gpt-realtime-2 audio input |
| Realtime assistant-audio floor | assistant_audio_hours * $4.608 for gpt-realtime-2 audio output |
| Realtime media-token floor | user_audio_floor + assistant_audio_floor |
| Realtime session estimate | media floor + text tokens + tool tokens + history growth + optional input transcription |
| Pipeline estimate | STT + text model + optional TTS + telephony + storage + monitoring + QA |
low, typical, high usage로 돌린다. Realtime에서는 user talk time보다 assistant speech time과 Response count를 먼저 바꿔 본다. 이 둘이 margin risk를 빨리 드러낸다. transcription-first에서는 audio duration, text-model output length, retry rate, storage retention, human-review load를 바꾼다.
launch 전 실제 pilot sessions에서 evidence를 수집한다. median과 p95 user audio duration, median과 p95 assistant audio duration, Response count, late turn의 average history size, input transcription usage and model, tools와 follow-up processing의 text tokens, failed/retried sessions, transcript당 human review minutes, launch date의 current OpenAI price rows가 필요하다.
deploy 당일 가격을 다시 확인한다. model IDs, availability, minute rows, token rows, account-specific access는 바뀔 수 있고 오래된 calculator는 빨리 낡는다.
자주 묻는 질문
Realtime API가 항상 전사 파이프라인보다 비싼가요?
항상은 아니다. Realtime voice-agent session은 plain transcription보다 floor가 높을 수 있지만 중요한 질문은 live spoken interaction이 value를 만드는가다. interruption, low latency, tool use during call, spoken output이 필요하면 Realtime은 비용을 낼 만하다. text artifact가 목적이면 transcription-first가 더 예산화하기 쉽다.
gpt-realtime-whisper와 gpt-realtime-2는 같은가요?
아니다. gpt-realtime-whisper는 spoken assistant output 없이 transcript deltas가 필요한 live transcription-only workflow용이다. gpt-realtime-2는 live spoken assistant session을 위한 Realtime voice-agent route다.
왜 $5.76/hour를 Realtime 시간당 가격이라고 부르면 안 되나요?
그 숫자는 current gpt-realtime-2 audio token rows에서 나온 media-token floor다. text tokens, repeated history, tools, optional input transcription, special tokens, telephony, pipeline components가 빠져 있다.
실시간 자막에는 어떤 route를 써야 하나요?
먼저 realtime transcription-only를 본다. spoken assistant 없이 live transcript deltas만 필요하면 gpt-realtime-whisper가 가격 산정 route다. 녹음 후 처리가 가능하면 gpt-4o-transcribe와 gpt-4o-mini-transcribe를 비교한다.
자체 STT -> LLM -> TTS pipeline이 항상 Realtime보다 나은가요?
아니다. pipeline은 text-centered work, compliance, telephony, debugging, vendor mix에 좋을 수 있지만 integration work와 component latency가 늘어난다. natural interruption과 spoken response quality가 경험의 중심이면 native Realtime session이 더 맞을 수 있다.
가장 안전한 production rule은 무엇인가요?
먼저 route를 고르고, OpenAI가 직접 가격을 제시하는 부분은 current official rows로 anchor한다. 나머지는 variable로 두고 실제 pilot sessions로 검증한다. text로 충분할 때 spoken assistant output에 돈을 내지 말고 media-token floor를 final bill이라고 부르지 않는다.