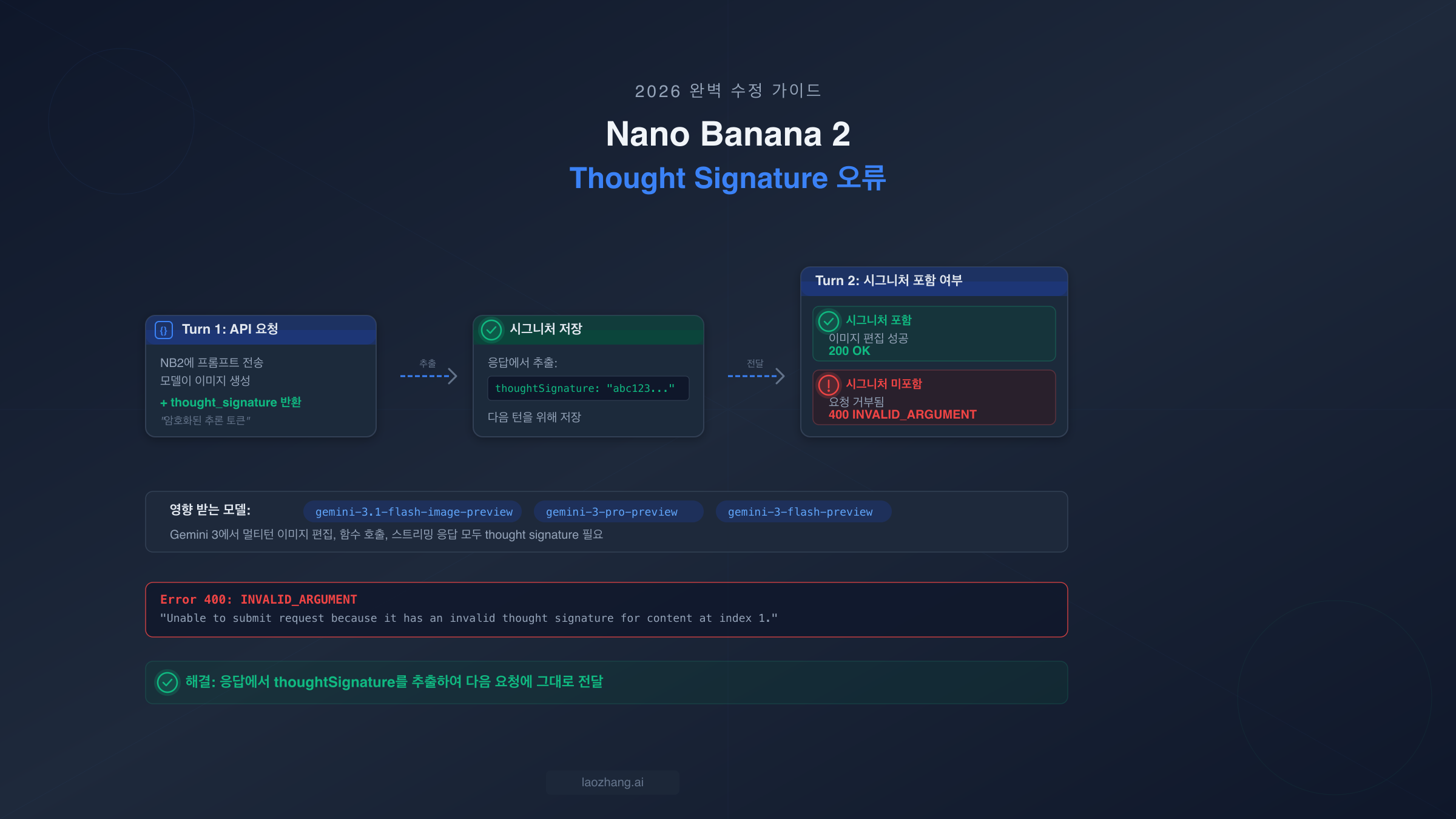
Nano Banana 2 thought_signature 오류(400 INVALID_ARGUMENT)는 멀티턴 API 요청에서 모델이 이전 응답에서 반환한 thought_signature 필드를 누락했을 때 발생합니다. Nano Banana 2(gemini-3.1-flash-image-preview)는 암호화된 추론 토큰을 생성하는 확장 사고(extended thinking)를 사용하며, 동일 대화 내의 모든 후속 요청에는 이 시그니처가 변경 없이 포함되어야 합니다. 해결 방법은 간단합니다. 각 API 응답에서 thoughtSignature 필드를 추출하여 다음 요청의 대화 히스토리에 그대로 전달하면 됩니다. 공식 Google Gen AI SDK의 채팅 기능을 사용하고 있다면 이 과정이 자동으로 처리되지만, REST API를 직접 호출하거나 OpenAI 호환 엔드포인트를 사용하거나 Dify 또는 n8n 같은 플랫폼을 통해 작업하는 경우에는 수동으로 처리해야 합니다.
Thought Signature 오류란 무엇이며 Nano Banana 2에 왜 필요한가?
Nano Banana 2에 멀티턴 요청을 보낼 때 API가 400 INVALID_ARGUMENT: Unable to submit request because it has an invalid thought signature for content at index N으로 응답하면, Gemini 3 모델 계열에서 가장 흔하면서도 가장 까다로운 오류를 만난 것입니다. 이 오류는 API 키가 잘못되었거나 요청 형식이 전통적인 의미에서 잘못되었다는 뜻이 아닙니다. 대화 히스토리에서 필수 컨텍스트가 누락되어 모델의 내부 추론 체인이 끊어졌다는 의미입니다.
이 오류가 발생하는 이유를 이해하려면 Gemini 3 모델이 "사고(thinking)"를 어떻게 처리하는지 알아야 합니다. Nano Banana 2(모델 ID: gemini-3.1-flash-image-preview, Google AI 문서, 2026년 3월)가 요청을 처리할 때, 출력을 생성하기 전에 내부 추론 단계인 확장 사고를 수행합니다. 이 사고 단계에서 thought_signature라는 암호화된 문자열이 생성되는데, 이는 모델의 추론 과정을 압축한 표현입니다. 비디오 게임의 세이브 파일과 비슷하다고 생각하시면 됩니다. 모델이 다음 턴에서 대화를 일관성 있게 이어가려면 이 세이브 상태가 필요합니다. 이것이 없으면 모델은 수신한 대화 히스토리가 실제로 생성한 내용과 일치하는지 검증할 수 없어 400 오류로 요청을 거부합니다.
대부분의 개발자를 곤란하게 만드는 핵심 세부사항은, thinkingConfig: { thinkingBudget: 0 }으로 설정하거나 thinking을 "off"로 설정해도 이 시그니처가 생성된다는 점입니다. 사고 프로세스는 내부적으로 여전히 실행되며, 시그니처도 여전히 생성되고 필수입니다. Google 공식 문서에 따르면 사고 구성에 관계없이 thinking 토큰은 항상 과금됩니다(ai.google.dev/thought-signatures, 2026년 3월). 이로 인해 많은 개발자가 예상치 못한 상황을 겪게 됩니다. thinking을 끄면 시그니처 필드를 무시해도 된다고 가정했다가 두 번째 턴에서 400 오류를 만나게 되는 것입니다. 대화형 이미지 편집 워크플로를 구축하면서 이 오류로 어려움을 겪고 있다면, 혼자가 아닙니다. Dify(#2262), CherryStudio(#11391), n8n, OpenClaw(#5001), Pipecat(#3557)의 GitHub 이슈들이 모두 이 동일한 근본 원인으로 추적됩니다. thought signature 이외의 다른 NB2 오류에 대한 포괄적인 내용은 Nano Banana 2 종합 문제 해결 가이드를 참고하세요.
Thought Signature가 필수인 경우와 선택인 경우
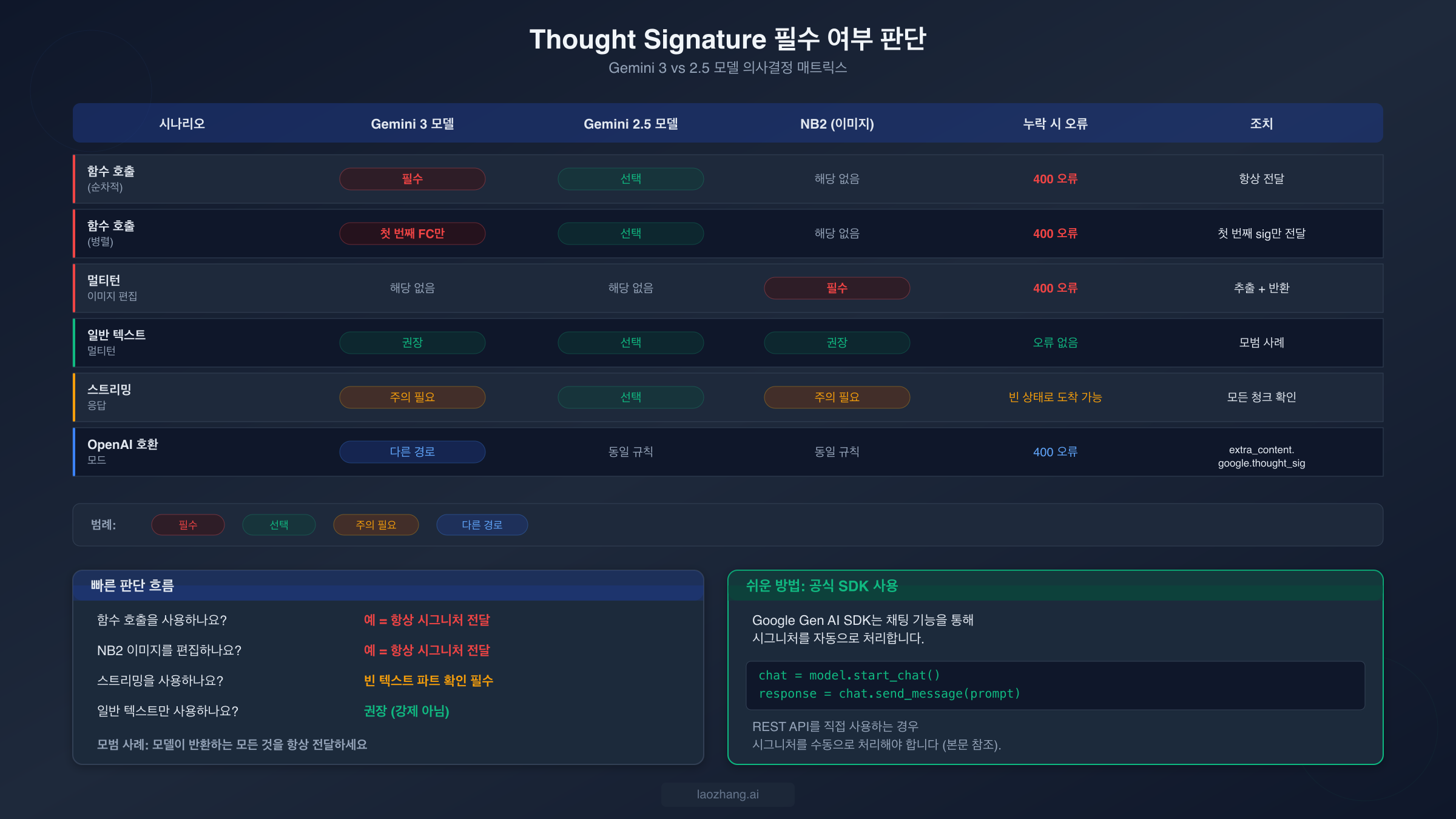
thought signature를 반드시 전달해야 하는 경우와 안전하게 무시할 수 있는 경우를 이해하는 것이 전체 코드베이스에서 이 오류를 방지하는 핵심입니다. 규칙은 Gemini 3과 Gemini 2.5 모델 간에 다르며, Nano Banana 2의 이미지 생성 사용 사례에서도 또 다릅니다. 이 판단을 잘못하면 코드에 불필요한 복잡성이 추가되거나 프로덕션에서 예기치 않은 400 오류가 발생합니다.
Gemini 3 모델(gemini-3-flash-preview, gemini-3-pro-preview)의 경우, 모든 함수 호출 시나리오에서 thought signature가 필수입니다. 즉, 애플리케이션이 Gemini 3에서 도구 사용이나 함수 호출을 사용한다면, 모든 후속 턴에서 thought signature를 추출하여 반환해야 합니다. 예외 없이 말입니다. 순차적 함수 호출은 특히 까다로운데, 시퀀스의 각 단계가 자체 시그니처를 생성하며 함수 결과를 보낼 때 이 모든 시그니처가 포함되어야 하기 때문입니다. 병렬 함수 호출은 다른 패턴을 가집니다. 응답의 첫 번째 functionCall 파트만 시그니처를 가지므로 그것만 캡처하여 반환하면 됩니다. 함수 호출이 없는 일반 텍스트 멀티턴 대화에서는 Gemini 3에서 시그니처가 권장되지만 강제되지는 않습니다. 즉, 생략해도 400 오류가 발생하지는 않지만 Google은 최적의 응답 품질을 위해 포함할 것을 권장합니다.
Gemini 2.5 모델의 경우 규칙이 더 완화됩니다. 함수 호출, 텍스트 대화 등 모든 경우에서 thought signature는 선택 사항입니다. 모델은 시그니처가 있든 없든 요청을 수락합니다. 그러나 Gemini 2.5와 Gemini 3 모델 모두에서 작동해야 하는 코드를 구축하는 경우, 가장 안전한 접근 방식은 시그니처를 포함하여 모델이 반환하는 모든 것을 항상 전달하는 것입니다.
Nano Banana 2(gemini-3.1-flash-image-preview)는 주로 멀티턴 이미지 생성 및 편집에 사용되므로 특수한 범주에 속합니다. 이미지를 생성한 후 후속 턴에서 편집을 요청할 때 thought signature는 필수입니다. 이것이 대부분의 개발자가 이 오류를 처음 만나는 주된 사용 사례이며, 함수 호출 시나리오보다 문서화가 부족합니다. 실용적 규칙은 간단합니다. 이미지를 생성하고 다듬거나, 시각적 콘텐츠에 대해 대화하거나, 이미지 편집을 연결하는 등 NB2로 멀티턴 워크플로를 구축하는 경우 thought signature를 처리해야 합니다. NB2 기능의 다른 모델과의 상세 비교는 Nano Banana Pro vs Nano Banana 2 비교를 참고하세요.
멀티턴 이미지 생성에서 오류 수정하기
멀티턴 이미지 편집은 Nano Banana 2의 주요 사용 사례이며, 대부분의 개발자가 thought signature 오류를 처음 만나는 곳입니다. 워크플로 자체는 간단합니다. 이미지를 생성한 다음 모델에 수정을 요청하는 것이죠. 하지만 시그니처 처리 과정에서 놓치기 쉬운 중요한 단계가 추가됩니다. 다음은 모든 단계에서 시그니처 추출이 강조된 완전한 흐름입니다.
Google Gen AI SDK를 사용한 Python 구현:
pythonimport google.generativeai as genai import base64 genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( "Generate a photo of a golden retriever playing in a park", generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # Step 2: 응답에서 thought signature와 이미지 추출 thought_signature = None image_data = None text_response = "" for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: thought_signature = part.thought_signature if hasattr(part, "inline_data") and part.inline_data: image_data = part.inline_data if hasattr(part, "text") and part.text: text_response += part.text print(f"Signature captured: {thought_signature[:30]}...") # Step 3: 시그니처를 포함하여 멀티턴 히스토리 구성 history = [ # 원래 요청 {"role": "user", "parts": [{"text": "Generate a photo of a golden retriever playing in a park"}]}, # 모델 응답 — thought_signature를 반드시 포함해야 함 {"role": "model", "parts": []} ] # 시그니처를 포함하여 모델 응답 파트 재구성 for part in response.candidates[0].content.parts: part_dict = {} if hasattr(part, "text"): part_dict["text"] = part.text if hasattr(part, "inline_data") and part.inline_data: part_dict["inline_data"] = { "mime_type": part.inline_data.mime_type, "data": part.inline_data.data } if hasattr(part, "thought_signature") and part.thought_signature: part_dict["thought_signature"] = part.thought_signature history[-1]["parts"].append(part_dict) # Step 4: 완전한 히스토리와 함께 편집 요청 전송 edit_response = model.generate_content( contents=history + [ {"role": "user", "parts": [{"text": "Now add a red frisbee in the dog's mouth"}]} ], generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # Step 5: 추가 편집을 위해 새로운 시그니처 추출 new_signature = None for part in edit_response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: new_signature = part.thought_signature print(f"Edit successful! New signature: {new_signature[:30]}...")
핵심 단계는 Step 3에 있습니다. 대화 히스토리를 재구성할 때 모델의 이전 응답에는 반환된 그대로의 thought_signature 필드가 포함되어야 합니다. 이 필드를 제거하거나, 응답을 텍스트와 이미지 데이터만으로 단순화하거나, 모든 파트를 순회하지 않으면 다음 턴에서 400 오류가 발생합니다. NB2의 모든 이미지 생성 응답에는 파트 어딘가에 thought signature가 포함됩니다. 여러분이 해야 할 일은 이를 충실히 보존하는 것입니다.
TypeScript 구현:
typescriptimport { GoogleGenerativeAI } from "@google/generative-ai"; const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); // 가장 쉬운 방법: 채팅 인터페이스 사용 const chat = model.startChat({ generationConfig: { responseModalities: ["TEXT", "IMAGE"] } }); // Turn 1: 이미지 생성 (SDK가 자동으로 시그니처 처리) const result1 = await chat.sendMessage("Generate a photo of a sunset over mountains"); // Turn 2: 이미지 편집 (SDK가 자동으로 시그니처 전달) const result2 = await chat.sendMessage("Add a silhouette of a person hiking"); // Turn 3: 추가 보정 const result3 = await chat.sendMessage("Make the colors more vibrant and add lens flare");
TypeScript 예제는 시그니처 관리를 자동으로 처리하는 SDK의 채팅 인터페이스를 사용합니다. 이 방식을 사용할 수 있다면 thought signature 오류의 전체 클래스가 사라집니다. SDK가 내부적으로 모든 시그니처를 추적하고 수동 개입 없이 후속 요청에 포함시킵니다. 이것이 대부분의 애플리케이션에서 가장 권장되는 방식입니다. NB2 이미지 생성 가격에 대한 자세한 내용은 Nano Banana 2 API 가격 가이드를 참고하세요.
스트리밍, 병렬 호출, OpenAI 호환 모드 처리
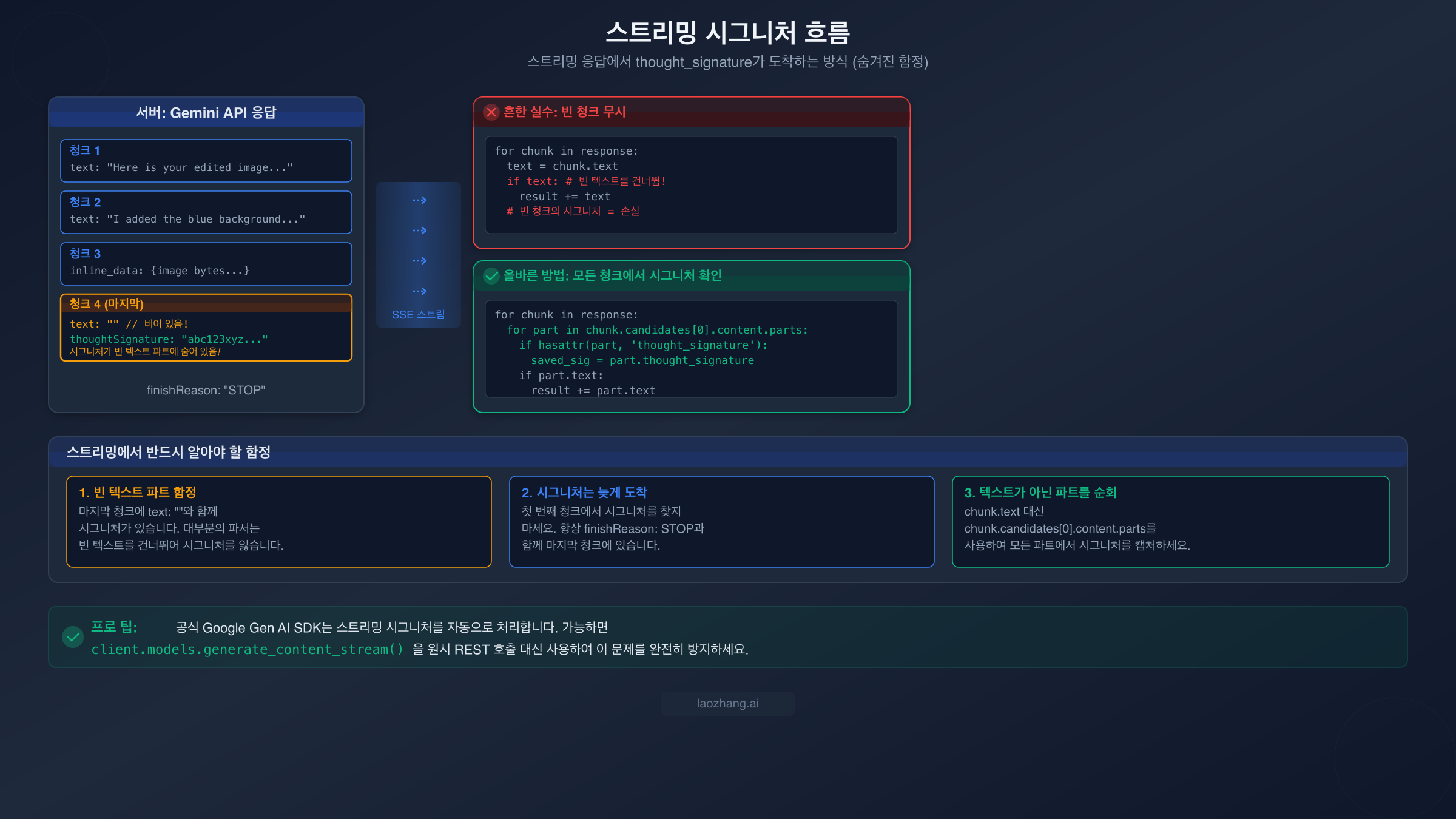
스트리밍 응답, 병렬 함수 호출, OpenAI 호환 모드는 각각 애플리케이션을 조용히 중단시킬 수 있는 고유한 thought signature 엣지 케이스를 도입합니다. 스트리밍의 경우 특히 교활한데, 스트림 파서의 작동 방식과 응답 스트림에서 시그니처가 실제로 나타나는 위치 사이의 미묘한 상호작용이 관련되어 있기 때문입니다.
스트리밍: 빈 텍스트 파트 함정
NB2 또는 Gemini 3 모델에서 스트리밍을 사용할 때, thought signature는 첫 번째 청크나 예측 가능한 중간 청크에서 도착하지 않습니다. 스트림의 마지막 청크에서 도착하며, 여기에 함정이 있습니다. 마지막 청크에는 종종 빈 텍스트 문자열(text: "")과 함께 thought_signature 필드가 포함된 파트가 있습니다. 대부분의 스트리밍 파서는 if chunk.text:로 청크 처리 여부를 결정하는데, 빈 문자열은 대부분의 언어에서 false로 평가됩니다. 이는 파서가 시그니처를 포함하는 바로 그 청크를 조용히 건너뛰게 되어, 다음 턴에서 400 오류가 발생합니다.
해결 방법은 편의 속성에 의존하지 말고 파트를 명시적으로 순회하는 것입니다:
python# 잘못된 방법: 빈 텍스트 청크에서 시그니처 손실 signature = None for chunk in response: if chunk.text: # 빈 문자열 = False = 시그니처 손실! result += chunk.text # 올바른 방법: 모든 청크의 모든 파트를 확인 signature = None full_text = "" for chunk in response: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: signature = part.thought_signature if hasattr(part, "text") and part.text: full_text += part.text
이 패턴은 시그니처가 어떤 청크에 있든, 동반되는 텍스트 파트가 비어 있든 상관없이 시그니처를 캡처합니다. 성능 영향은 무시할 수 있는 수준입니다. 이미 처리하고 있을 파트를 순회하는 것뿐이지만 안정성 향상은 상당합니다.
병렬 함수 호출
Gemini 3이 단일 응답에서 여러 함수 호출을 반환할 때(병렬 함수 호출), 첫 번째 functionCall 파트만 thought signature를 가집니다. 동일 응답의 후속 함수 호출 파트에는 자체 시그니처가 없습니다. 함수 결과를 반환할 때 첫 번째 함수 호출 파트의 시그니처를 응답에 포함해야 합니다. 이것은 Google 공식 문서에 기록되어 있지만 함수 호출 자체를 처리하는 데 집중하고 있을 때 놓치기 쉽습니다. 루프에서 함수 호출을 처리하며 각각에서 시그니처를 추출하면 첫 번째만 값이 있다는 것을 발견하게 됩니다. 그 단일 시그니처가 바로 전달해야 할 것입니다.
OpenAI 호환 모드
OpenAI 호환 엔드포인트를 통해 Gemini 모델에 접근하는 경우(OpenAI에서 마이그레이션하거나 게이트웨이 서비스를 사용할 때 일반적), thought signature는 응답에서 완전히 다른 위치에 있습니다. 파트 수준의 thought_signature 대신 메시지 객체의 extra_content.google.thought_signature 아래에 중첩됩니다. OpenAI 코드를 Gemini에서 작동하도록 마이그레이션하는 많은 개발자를 혼란스럽게 합니다. 네이티브 Gemini API 문서를 기반으로 시그니처 처리를 구현하지만 OpenAI 호환 레이어는 응답을 다르게 구조화하기 때문입니다. 수정 방법은 호환 모드 사용 시 대체 필드 경로를 확인하는 것입니다:
python# 네이티브 Gemini API signature = part.thought_signature # OpenAI 호환 모드 signature = message.get("extra_content", {}).get("google", {}).get("thought_signature")
애플리케이션이 여러 API 모드를 지원하는 경우 두 경로를 모두 처리해야 합니다. 네이티브와 호환 엔드포인트 모두에서 작동해야 하는 프로덕션 애플리케이션의 경우, 두 위치를 모두 확인하는 헬퍼 함수로 시그니처 추출을 추상화하는 것을 권장합니다.
고급 해결 방법 — 더미 시그니처와 모델 마이그레이션
Google 공식 문서에 숨겨져 있지만 다른 어떤 글에서도 눈에 띄게 다루지 않은 해결 방법이 있습니다: 더미 thought signature입니다. Gemini 3에서 생성되지 않은 대화 히스토리가 있는 경우, 예를 들어 다른 모델에서 마이그레이션하거나, 합성 대화 컨텍스트를 주입하거나, 시그니처를 저장하지 않은 데이터베이스에서 히스토리를 재구성하는 경우, 실제 시그니처 대신 특수한 플레이스홀더 문자열을 사용할 수 있습니다.
Google은 시그니처 유효성 검사기를 우회하는 두 가지 공식 더미 시그니처 문자열을 제공합니다(ai.google.dev/thought-signatures FAQ, 2026년 3월):
python# 옵션 1: 권장 더미 시그니처 dummy_signature = "context_engineering_is_the_way_to_go" # 옵션 2: 대체 더미 시그니처 dummy_signature = "skip_thought_signature_validator"
대화 히스토리의 모델 턴에서 이 문자열 중 하나를 thought_signature 값으로 포함하면 API가 검증 없이 수락합니다. 이는 여러 시나리오에서 매우 유용합니다: GPT-4 또는 Claude에서 Gemini 3으로 기존 대화 히스토리를 마이그레이션하거나, thought signature를 저장하도록 설계되지 않은 데이터베이스에서 대화를 복원하거나, 모델을 거치지 않은 시스템 수준 컨텍스트 턴을 주입하거나, 실제 시그니처 없이 멀티턴 워크플로를 테스트하는 경우입니다.
그러나 프로덕션에서 더미 시그니처에 의존하기 전에 이해해야 할 중요한 주의사항이 있습니다. 더미 시그니처는 해당 턴의 사고 컨텍스트를 사용할 수 없다고 모델에 알립니다. 이는 모델이 해당 턴의 추론 일관성을 검증할 수 없다는 의미입니다. Gemini 3의 함수 호출 워크플로에서는 모델이 원래 추론 체인을 참조할 수 없기 때문에 응답 품질이 약간 저하될 수 있습니다. 특히 NB2 이미지 편집의 경우, 이미지 생성 턴에 더미 시그니처를 사용하면 모델이 창작 결정을 완벽하게 "기억"하지 못할 수 있어 후속 편집의 품질에 영향을 줄 수 있습니다. 더미 시그니처 접근 방식은 적절한 시그니처 관리의 영구적 대체가 아니라 마이그레이션 도구나 폴백으로 사용하는 것이 가장 좋습니다.
실용적 의사결정 트리는 명확합니다. 실제 시그니처를 추출하고 저장할 수 있다면 항상 그렇게 하세요. 시그니처 없는 레거시 히스토리가 있다면 모든 대화 히스토리를 처음부터 다시 구축하는 대신 더미 시그니처를 사용하여 마이그레이션을 진행하세요. 프로토타이핑이나 테스트 중이라면 더미 시그니처를 통해 시그니처 배관 걱정 없이 비즈니스 로직에 집중할 수 있습니다.
Dify, CherryStudio, n8n 등 플랫폼별 수정 방법

thought signature 오류는 단순한 원시 API 문제가 아닙니다. AI 개발 플랫폼과 도구 전반에 걸친 광범위한 이슈이기도 합니다. Dify, CherryStudio, n8n 또는 유사한 플랫폼을 통해 Gemini 3 모델을 사용할 때, 플랫폼의 내부 메시지 처리가 대화 턴 관리 과정에서 thought signature를 제거하거나 손실하는 경우가 많습니다. 이는 API 자격 증명과 모델 구성이 완벽히 올바르더라도, 플랫폼이 모르는 필드를 조용히 삭제하기 때문에 400 오류가 발생할 수 있다는 것을 의미합니다.
Dify는 현재 가장 큰 영향을 받는 플랫폼입니다. Dify의 메시지 히스토리 관리는 모델 응답을 저장하기 전에 비표준 필드를 제거하며, thought_signature는 비표준 필드로 취급됩니다. 이로 인해 Gemini 3 모델과의 멀티턴 대화는 첫 번째 턴 이후 지속적으로 실패합니다. 이 문제는 GitHub 이슈 #2262에서 추적되고 있으며, 이를 수정하는 풀 리퀘스트가 리뷰 대기 중입니다. 그동안의 해결 방법은 Dify의 내장 Gemini 통합을 우회하고 HTTP Request 노드를 사용하여 자체 대화 히스토리 관리로 Gemini API를 직접 호출하는 것입니다. 더 많은 설정이 필요하지만 요청과 응답 페이로드를 완전히 제어할 수 있습니다.
CherryStudio는 더 미묘한 문제가 있습니다. 데스크톱 클라이언트는 일반 대화 흐름에서 thought signature를 보존하지만 "재생성" 버튼을 사용할 때 손실합니다. CherryStudio가 응답을 재생성할 때 재생성되는 턴의 원본 시그니처 없이 대화 히스토리를 재구성하여 400 오류를 유발합니다. 해결 방법은 간단합니다. 재생성을 사용하지 말고 새 대화를 시작하거나 메시지를 새 턴으로 다시 작성하세요. 이 문제는 GitHub 이슈 #11391에서 추적됩니다.
n8n은 Dify와 동일한 근본적 문제에 직면합니다. Gemini 노드가 워크플로 실행 간 대화 상태에서 thought signature 필드를 보존하지 않습니다. n8n 사용자에게 권장되는 접근 방식은 Gemini 전용 노드 대신 HTTP Request 노드를 사용하여 API 페이로드를 직접 제어하는 것입니다. n8n의 워크플로 데이터에 전체 응답(시그니처 포함)을 저장하고 후속 턴에서 수동으로 대화 히스토리를 재구성할 수 있습니다.
LangChain은 이 문제를 버전 0.3.x 이후에 이미 수정했습니다. 이전 버전을 사용하고 있다면 최신 릴리스로 업데이트하면 thought signature 처리가 자동으로 해결됩니다. LangChain의 ChatGoogleGenerativeAI 클래스는 이제 대화 히스토리를 구축할 때 thought signature를 포함한 모든 응답 메타데이터를 보존합니다.
OpenClaw 및 Gemini 모델에 대한 OpenAI 호환 엔드포인트를 제공하는 다른 API 게이트웨이 서비스는 다른 문제를 가지고 있습니다. OpenAI 호환 응답에서 extra_content.google.thought_signature 필드를 전달하지 않을 수 있습니다. 해결 방법은 OpenAI 호환 엔드포인트 대신 게이트웨이를 통해 네이티브 Gemini API 엔드포인트를 사용하거나, 모든 응답 필드를 보존하도록 게이트웨이를 구성하는 것입니다.
모든 플랫폼에서 범용 폴백은 이전 섹션에서 설명한 더미 시그니처 해결 방법입니다. 플랫폼이 실제 시그니처를 제거하면 대화 히스토리에 "context_engineering_is_the_way_to_go"를 시그니처 값으로 주입하여 대화를 계속할 수 있습니다. 다만 앞서 언급한 품질 관련 주의사항이 적용됩니다.
프로덕션용 Thought Signature 핸들러
이미지 편집, 함수 호출, 스트리밍, 여러 API 모드 등 모든 시나리오에서 견고한 thought signature 처리가 필요한 프로덕션 애플리케이션을 위해, 이 가이드에서 다룬 모든 엣지 케이스를 캡슐화하는 재사용 가능한 핸들러 클래스를 소개합니다.
pythonclass ThoughtSignatureHandler: """멀티턴 Gemini 대화에서 thought signature를 관리합니다.""" DUMMY_SIGNATURES = [ "context_engineering_is_the_way_to_go", "skip_thought_signature_validator" ] def __init__(self): self.signatures = {} # turn_index -> signature def extract_from_response(self, response, turn_index: int) -> str | None: """Gemini API 응답에서 thought signature를 추출합니다.""" sig = None if hasattr(response, "candidates") and response.candidates: for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature break if sig: self.signatures[turn_index] = sig return sig def extract_from_stream(self, stream, turn_index: int): """스트리밍 응답에서 시그니처를 추출하며 청크를 yield합니다.""" sig = None for chunk in stream: if hasattr(chunk, "candidates") and chunk.candidates: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature yield chunk if sig: self.signatures[turn_index] = sig def extract_from_openai_compat(self, message: dict, turn_index: int) -> str | None: """OpenAI 호환 응답 형식에서 시그니처를 추출합니다.""" sig = (message.get("extra_content", {}) .get("google", {}) .get("thought_signature")) if sig: self.signatures[turn_index] = sig return sig def get_signature(self, turn_index: int, fallback_dummy: bool = False) -> str | None: """턴에 대해 저장된 시그니처를 가져오며, 선택적으로 더미 폴백을 사용합니다.""" sig = self.signatures.get(turn_index) if sig is None and fallback_dummy: return self.DUMMY_SIGNATURES[0] return sig def build_history_part(self, part_data: dict, turn_index: int) -> dict: """모델 응답 파트에 thought signature가 포함되도록 보장합니다.""" sig = self.signatures.get(turn_index) if sig and "thought_signature" not in part_data: part_data["thought_signature"] = sig return part_data
이 핸들러는 세 가지 주요 추출 시나리오(표준 응답, 스트리밍, OpenAI 호환)를 처리하고, 턴 인덱스별로 시그니처를 저장하며, 실제 시그니처를 사용할 수 없을 때 더미 시그니처로의 폴백을 제공합니다. extract_from_stream 메서드는 시그니처를 포함하는 청크에서 시그니처를 캡처하면서 투명하게 청크를 yield하는 제너레이터입니다. 처리 로직을 변경하지 않고 기존 스트리밍 코드에 바로 적용할 수 있습니다.
TypeScript 애플리케이션의 경우 SDK의 채팅 인터페이스를 사용할 수 있기 때문에 동등한 패턴이 더 간단합니다. TypeScript에서 원시 REST 호출을 사용해야 하는 경우 옵셔널 체이닝을 사용하여 동일한 추출 로직을 적용하세요:
typescriptconst extractSignature = (response: any): string | undefined => { return response?.candidates?.[0]?.content?.parts ?.find((p: any) => p.thoughtSignature)?.thoughtSignature; };
프로덕션 시스템을 구축할 때는 시그니처 관리와 함께 속도 제한 처리도 구현하는 것을 고려하세요. NB2는 엄격한 속도 제한이 있어 시그니처 오류와 결합되면 혼란스러운 실패 모드가 만들어질 수 있습니다. 자세한 내용은 Nano Banana 2 완전한 속도 제한 가이드를 참고하세요. NB2 이미지 생성을 위해 더 높은 처리량이나 완화된 속도 제한이 필요한 팀의 경우 laozhang.ai와 같은 서비스가 경쟁력 있는 가격(이미지당 $0.05, 표준 1K 토큰 기준 ~$0.067 대비)으로 대체 API 접근을 제공합니다.
FAQ — Thought Signature 자주 묻는 질문
Nano Banana 2는 응답에 항상 thought_signature를 반환하나요?
네. NB2 및 기타 Gemini 3 모델의 모든 응답에는 thinking이 "off"로 설정되거나 thinkingBudget이 0이더라도 thought signature가 포함됩니다. 사고 프로세스는 항상 내부적으로 실행되며 시그니처는 항상 생성됩니다. 시그니처 생성을 중단할 수는 없으며, 이를 되돌려 전달할지 여부만 선택할 수 있습니다(항상 전달해야 합니다).
잘못된 시그니처나 다른 대화의 시그니처를 사용하면 어떻게 되나요?
API가 동일한 400 INVALID_ARGUMENT 오류로 요청을 거부합니다. 시그니처는 이를 생성한 특정 대화 턴에 암호화적으로 연결되어 있습니다. 대화 간이나 동일 대화 내 턴 간에 시그니처를 교환할 수 없습니다. 각 턴의 시그니처는 생성된 위치에서 정확히 한 번 사용되어야 합니다.
공식 Google Gen AI SDK는 thought signature를 자동으로 처리하나요?
네, SDK의 채팅 인터페이스(TypeScript에서 model.startChat() 또는 Python에서 model.start_chat())를 사용할 때 자동으로 처리됩니다. SDK가 thought signature를 포함한 전체 대화 히스토리를 내부적으로 관리합니다. 수동으로 구성한 대화 히스토리와 함께 model.generate_content()를 직접 사용하는 경우에는 시그니처 관리를 직접 해야 합니다.
thought signature를 데이터베이스에 저장하여 나중에 사용할 수 있나요?
네, 그리고 애플리케이션이 세션 간 대화를 재개해야 하는 경우 반드시 그래야 합니다. 각 턴에 대해 thought signature를 포함한 전체 모델 응답을 저장하세요. 재개할 때는 저장된 모든 시그니처로 대화 히스토리를 재구성합니다. 시그니처가 저장되지 않은 턴이 있는 경우(레거시 데이터) 더미 시그니처 "context_engineering_is_the_way_to_go"를 플레이스홀더로 사용하세요.
thought_signature 필드가 과금되나요? 토큰 사용량에 포함되나요?
시그니처를 생성하는 thinking 토큰은 thinkingBudget 설정에 관계없이 항상 과금됩니다(ai.google.dev, 2026년 3월). 그러나 시그니처 문자열 자체는 컴팩트한 암호화 표현이므로 되돌려 전달할 때 요청 크기를 크게 증가시키지 않습니다. 과금 영향은 초기 thinking 계산에 있지 시그니처 전송에 있지 않습니다.
오류 메시지가 "missing thought signature"가 아니라 "invalid thought signature"인 이유는 무엇인가요?
오류 메시지 Unable to submit request because it has an invalid thought signature for content at index N은 두 가지 경우를 모두 포함합니다: 누락된 시그니처(필드가 완전히 없는 경우)와 손상된 시그니처(필드는 존재하지만 잘못된 데이터를 포함하는 경우). "at index N"은 대화 히스토리에서 문제가 있는 턴을 알려줍니다. 해당 인덱스의 모델 응답에 원본 thought signature가 포함되어 있는지 확인하세요.