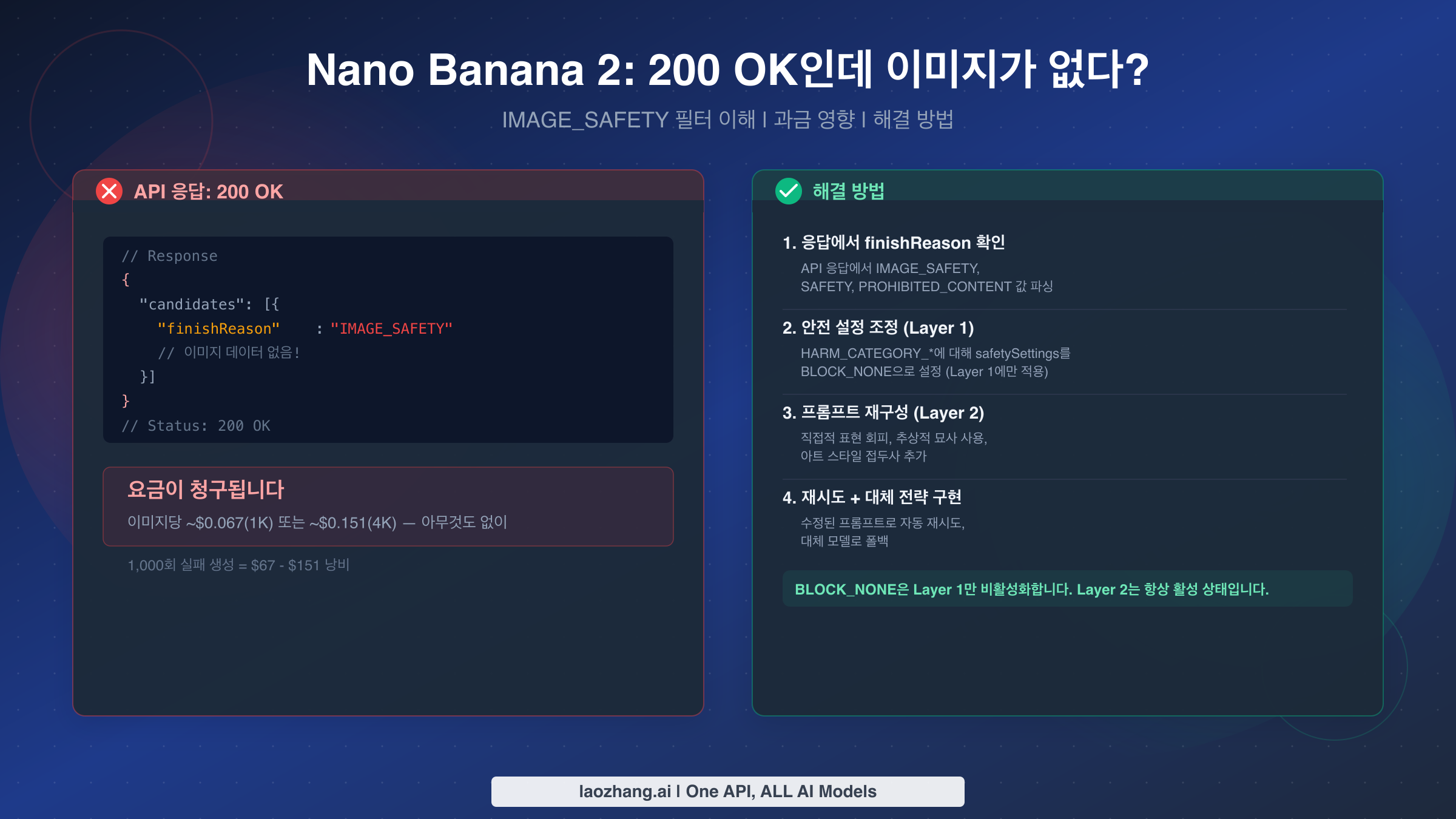
Nano Banana 2의 가장 혼란스러운 동작은 범용 성공 코드인 HTTP 200 OK를 반환하면서 실제로는 이미지를 전혀 전달하지 않는 것입니다. 그 원인은 Google의 Layer 2 IMAGE_SAFETY 필터로, BLOCK_NONE이나 어떤 안전 설정으로도 비활성화할 수 없는 하드코딩된 콘텐츠 차단 메커니즘입니다. 더 나쁜 것은, Google이 이 빈 응답에 대해서도 전체 토큰 처리 비용을 청구한다는 점입니다. 1K 이미지당 약 $0.067, 4K 이미지당 약 $0.151에 달합니다(ai.google.dev/pricing, 2026년 3월 기준). 이 가이드에서는 이 문제가 발생하는 정확한 이유, 코드에서 이를 감지하는 방법, 그리고 API 예산이 소진되는 것을 방지하는 7가지 검증된 전략을 설명합니다.
핵심 요약
200 OK 이미지 없음 문제는 한 가지로 귀결됩니다. Nano Banana 2(gemini-3.1-flash-image-preview)는 이중 레이어 안전 아키텍처를 사용합니다. Layer 1은 safetySettings를 통해 구성할 수 있으며 BLOCK_NONE에 반응합니다. Layer 2는 IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM 필터를 포함하며 항상 활성 상태이고 비활성화할 수 없습니다. Layer 2가 이미지를 차단하면 API는 여전히 이미지 데이터 대신 finishReason: "IMAGE_SAFETY"와 함께 HTTP 200을 반환하며, 토큰 처리 비용이 과금됩니다. 해결책은 설정 변경이 아닙니다. 바로 프롬프트 엔지니어링입니다. 아래에 문서화된 트리거 카테고리를 피하도록 프롬프트를 재구성하고, 코드에서 finishReason 검사를 구현하며, 낭비되는 비용을 최소화하기 위해 프롬프트 변형을 적용한 재시도 로직을 추가하는 것이 핵심입니다.
API가 이미지 없이 200 OK를 반환하는 이유

"성공적인" HTTP 응답에 이미지가 포함되지 않는 이유를 이해하려면 Nano Banana 2 파이프라인 내부에서 Google의 안전 시스템이 실제로 어떻게 작동하는지 알아야 합니다. 혼란이 존재하는 이유는 Google이 특이한 설계 결정을 내렸기 때문입니다. 콘텐츠 필터링이 이미지를 차단할 때 4xx 오류를 반환하는 대신, finishReason 필드를 설정하여 차단을 표시하면서 200 OK를 반환합니다. 이는 표준 HTTP 오류 처리로는 절대 이를 포착할 수 없다는 것을 의미합니다. 요청이 조용히 거부되었다는 사실을 발견하려면 응답 본문을 파싱해야 합니다.
Nano Banana 2 안전 시스템은 근본적으로 다른 동작을 하는 두 개의 별개 레이어로 운영됩니다. Layer 1은 HARASSMENT, HATE_SPEECH, SEXUALLY_EXPLICIT, DANGEROUS_CONTENT의 네 가지 피해 카테고리에 대해 프롬프트를 평가하는 구성 가능한 확률적 필터입니다. 각 카테고리는 확률 점수를 사용하며, API 요청의 safetySettings 파라미터를 통해 임계값을 제어할 수 있습니다. 카테고리를 BLOCK_NONE으로 설정하면 해당 레이어에서 해당 특정 카테고리에 대한 차단이 사실상 비활성화됩니다. Layer 1이 요청을 차단하면 응답에 finishReason: "SAFETY"가 포함됩니다. Layer 2가 생성하는 값과는 다른 고유한 값임을 주목하세요.
Layer 2는 대부분의 개발자에게 혼란이 시작되는 지점입니다. 이 레이어에는 Google이 협상 불가능한 정책 시행으로 유지하는 하드코딩된 안전 필터가 포함되어 있습니다. IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM, SPII(민감한 개인 식별 정보)의 네 가지 Layer 2 필터는 구성 가능한 임계값이 없는 이진 차단기로 작동합니다. BLOCK_NONE을 포함한 어떤 API 파라미터로도 비활성화할 수 없습니다. Layer 2가 요청을 가로채면 응답에 finishReason: "IMAGE_SAFETY" 또는 finishReason: "PROHIBITED_CONTENT"가 포함됩니다(Google Cloud 문서, 2026년 3월 기준 검증). 대부분의 문서에서 묻어두는 핵심적인 세부 사항은 이러한 Layer 2 응답이 여전히 HTTP 200을 반환한다는 것이며, 상태 코드만 확인하는 코드에게 성공의 환상을 만들어냅니다.
실질적인 의미는 큽니다. 네 가지 Layer 1 카테고리 모두에 BLOCK_NONE을 설정했는데도 이미지가 생성되지 않는다면, 아무것도 잘못 구성한 것이 아닙니다. 프롬프트가 단순히 어떤 구성 변경으로도 우회할 수 없는 Layer 2 필터를 트리거한 것입니다. 유일한 해결 방법은 프롬프트를 수정하는 것이며, 이는 아래 프롬프트 엔지니어링 섹션에서 자세히 다룹니다. 200 OK 시나리오 외의 모든 오류 유형에 대한 포괄적인 개요를 원하는 개발자라면, Nano Banana 2 완벽 문제 해결 가이드에서 429 속도 제한, 서버 과부하 오류, API 파라미터 문제를 다루고 있습니다.
Layer 2를 가장 자주 트리거하는 요인
2026년 2월 27일 Nano Banana 2가 출시된 이후, Google은 원래 Nano Banana 모델에 비해 Layer 2 필터를 크게 강화했습니다. 개발자 보고서와 커뮤니티 논의를 기반으로 한 가장 일반적인 트리거는 여섯 가지 뚜렷한 카테고리에 해당합니다. 유명인이나 실존 인물 얼굴 생성은 아마도 가장 엄격한 카테고리입니다. 묘사적 표현을 통한 간접적인 언급조차 종종 필터를 트리거합니다. 선정적이거나 노출이 있는 의상 묘사는 "패션쇼의 모델"이나 "해변의 수영선수"처럼 의도가 분명히 비성적인 경우에도 차단됩니다. 사실적인 폭력이나 무기 묘사는 광범위하게 해석되어, 군사 역사 일러스트레이션과 액션 영화 장면 재현도 포착합니다. 실제 화폐나 금융 문서 재현은 명백히 허구적이거나 양식화된 버전에서도 일관되게 트리거됩니다. 브랜드 콘텐츠나 로고 재현은 특정 브랜드 이름을 참조하거나 상표가 등록된 시각적 요소를 근접하게 묘사하는 모든 프롬프트를 포착합니다. 마지막으로, 해부학적 또는 의료 이미지는 사실적 스타일로 요청되면 차단되지만, 교육 다이어그램으로 프레이밍하면 동일한 콘텐츠가 통과하는 경우가 많습니다.
원래 Nano Banana 모델과 비교하면 엄격도가 눈에 띄게 증가했습니다. 원래 모델에서 성공적으로 이미지를 생성했던 프롬프트가 프롬프트 텍스트를 전혀 변경하지 않았는데도 Nano Banana 2에서 IMAGE_SAFETY를 트리거하는 경우가 빈번합니다. Reddit과 GitHub Discussions의 커뮤니티 테스트에 따르면, 원래 모델에서 작동했던 프롬프트의 약 15-25%가 현재 NB2에서 실패하며, 이것이 많은 개발자들이 포럼 게시물에서 이 모델을 "너프됐다"고 표현하는 이유입니다. 이러한 트리거 카테고리를 이해하는 것은 신뢰할 수 있는 애플리케이션을 구축하는 데 필수적입니다. 각 카테고리마다 우회하기 위한 다른 프롬프트 엔지니어링 접근 방식이 필요하기 때문입니다.
중요한 finishReason 값들
모든 필터 차단이 동일한 것은 아닙니다. API 응답의 finishReason 필드는 어떤 레이어가 요청을 포착했는지 정확히 알려주며, 이에 따라 수정 전략이 결정됩니다. "SAFETY" 값은 Layer 1이 차단했음을 의미합니다. 이는 safetySettings로 수정 가능합니다. "IMAGE_SAFETY" 값은 Layer 2가 포착했음을 의미합니다. 프롬프트를 재구성해야 합니다. "PROHIBITED_CONTENT" 값은 프롬프트가 Google의 핵심 콘텐츠 정책을 위반했음을 의미하며 주제를 완전히 변경해야 합니다. "STOP" 값은 생성이 성공적으로 완료되었으며 응답에 이미지 데이터가 있어야 함을 의미합니다. 모든 Nano Banana 오류 코드에 대한 완전한 참조는 오류 코드 참조 가이드를 확인하세요.
과금 함정 — 빈 응답에 대해 비용을 지불하고 있습니다
200 OK 이미지 없음 문제에서 재정적으로 가장 고통스러운 측면은 Google이 필터링된 모든 요청에 대해 전체 토큰 처리 요금을 청구한다는 것입니다. 429(속도 제한 초과), 500(내부 서버 오류) 또는 503(서비스 불가) 응답과 달리 — 이들은 과금되지 않습니다 — IMAGE_SAFETY가 포함된 200 OK 응답은 Google이 프롬프트를 처리하고, 안전 파이프라인을 통해 실행하고, 차단을 결정한 후 관련된 연산 작업에 대해 비용을 청구한다는 것을 의미합니다. 이미지를 받지 못했다는 사실은 과금 계산과 무관합니다.
비용 영향은 실패율과 해상도 설정에 따라 달라집니다. 1K 해상도 이미지당 약 $0.067, 4K 해상도 이미지당 약 $0.151의 표준 NB2 가격(ai.google.dev/pricing, 2026년 3월 기준)에서, 적당한 필터 비율이라도 대규모에서는 비용이 커집니다. 하루에 1K 해상도로 10,000개의 이미지를 생성하는 프로덕션 애플리케이션을 생각해 보세요. 그 중 20%가 IMAGE_SAFETY를 트리거한다면, 받지도 못한 이미지에 대해 하루 약 $134, 월간 약 $4,000을 지불하게 됩니다. 동일한 20% 실패율의 4K 해상도에서는 낭비 비용이 하루 약 $302, 월간 $9,000 이상으로 올라갑니다.
이 과금 구조는 역설적인 인센티브를 만듭니다. 안전 경계에 가까운 프롬프트에 더 많은 비용을 지불하게 되는데, 이는 전체 평가 파이프라인을 통해 토큰을 소비한 후에야 거부되기 때문입니다. 명백히 무해한 프롬프트는 빠르게 통과합니다. Layer 2에서 차단되기 전에 광범위한 안전 분석이 필요한 프롬프트는 실제로 성공적인 생성보다 더 많은 토큰을 소비할 수 있습니다. 이것이 바로 무작정 재시도 전략 — 단순히 동일한 프롬프트를 재제출하는 것 — 이 최악의 접근 방식인 이유입니다. 각 재시도마다 동일한 비용이 발생하면서 동일한 결과를 얻게 됩니다.
가장 효과적인 비용 완화 전략은 세 가지 요소를 결합합니다. 첫째, 애플리케이션 코드에서 finishReason 검사를 구현하여 필터링된 응답이 조용히 소비되는 대신 즉시 감지되도록 합니다. 둘째, 텍스트 전용 Gemini 호출(이미지 생성 호출의 극히 일부 비용)을 사용하여 프롬프트가 안전 필터를 트리거할 가능성이 있는지 전체 이미지 생성 비용을 투입하기 전에 테스트하는 프롬프트 사전 스크리닝을 활용합니다. 셋째, IMAGE_SAFETY 필터에 대해 검증된 알려진 양호한 프롬프트 템플릿 라이브러리를 유지하여 새로운 콘텐츠 요청이 테스트되지 않은 표현 대신 검증된 기준에서 시작되도록 합니다. 전체 이미지 생성 사용에서 API 비용을 최소화하려는 개발자라면, NB2 API 가격 상세 분석에서 배치 할인과 비용 최적화 전략을 자세히 다루고 있습니다.
IMAGE_SAFETY 실패 비용이 감당할 수 없는 수준이라면, laozhang.ai와 같은 API 통합 플랫폼이 이미지당 약 $0.05로 Nano Banana 2 접근을 제공합니다. 이는 Google 직접 가격보다 약 25% 낮은 수준으로, 동일한 모델 품질을 제공하면서 실패한 생성 비용을 부분적으로 상쇄할 수 있습니다.
코드에서 200 OK 이미지 없음을 감지하고 처리하는 방법

대부분의 개발자가 저지르는 근본적인 실수는 HTTP 200을 응답에 이미지 데이터가 존재한다는 확인으로 취급하는 것입니다. Nano Banana 2에서는 이미지 데이터를 추출하기 전에 반드시 응답 본문의 finishReason 필드를 확인해야 합니다. 다음은 모든 가능한 응답 상태를 올바르게 처리하는 Python과 Node.js의 프로덕션 수준 오류 처리 코드입니다.
Python 구현
pythonimport google.generativeai as genai import base64 import time def generate_image_safe(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=3, resolution="1024x1024"): """IMAGE_SAFETY 감지 및 재시도 로직이 포함된 이미지 생성 함수.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE"]}, safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", } ) # Check finishReason BEFORE accessing image data if not response.candidates: return {"success": False, "reason": "NO_CANDIDATES", "charged": True, "attempt": attempt + 1} candidate = response.candidates[0] finish_reason = candidate.finish_reason.name if finish_reason == "STOP": # Success - extract image for part in candidate.content.parts: if hasattr(part, 'inline_data'): return {"success": True, "image_data": part.inline_data.data, "mime_type": part.inline_data.mime_type, "attempt": attempt + 1} elif finish_reason == "SAFETY": # Layer 1 block - safetySettings should prevent this return {"success": False, "reason": "SAFETY_LAYER1", "charged": True, "fixable": True, "fix": "Check safetySettings configuration"} elif finish_reason == "IMAGE_SAFETY": # Layer 2 block - must rephrase prompt if attempt < max_retries - 1: prompt = soften_prompt(prompt) # Retry with modified prompt time.sleep(1) continue return {"success": False, "reason": "IMAGE_SAFETY_LAYER2", "charged": True, "fixable": False, "fix": "Rephrase prompt to avoid safety triggers"} elif finish_reason == "PROHIBITED_CONTENT": # Hard policy violation - do not retry return {"success": False, "reason": "PROHIBITED_CONTENT", "charged": True, "fixable": False, "fix": "Change content entirely"} except Exception as e: if "429" in str(e): return {"success": False, "reason": "RATE_LIMITED", "charged": False} raise return {"success": False, "reason": "MAX_RETRIES_EXCEEDED", "charged": True} def soften_prompt(prompt): """재시도를 위한 자동 프롬프트 완화 함수.""" prefixes = ["watercolor style illustration of ", "minimalist digital art depicting ", "flat vector illustration showing "] # Cycle through style prefixes on each retry import random return random.choice(prefixes) + prompt
Node.js 구현
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageSafe(prompt, options = {}) { const { maxRetries = 3, modelName = "gemini-3.1-flash-image-preview" } = options; const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseModalities: ["IMAGE"] }, safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], }); const candidate = result.response.candidates?.[0]; if (!candidate) { return { success: false, reason: "NO_CANDIDATES", charged: true }; } const finishReason = candidate.finishReason; if (finishReason === "STOP") { const imagePart = candidate.content.parts.find(p => p.inlineData); if (imagePart) { return { success: true, imageData: imagePart.inlineData.data, mimeType: imagePart.inlineData.mimeType, attempt: attempt + 1 }; } } if (finishReason === "IMAGE_SAFETY" && attempt < maxRetries - 1) { prompt = softenPrompt(prompt); await new Promise(r => setTimeout(r, 1000)); continue; } return { success: false, reason: finishReason, charged: true, attempt: attempt + 1 }; } catch (error) { if (error.status === 429) { return { success: false, reason: "RATE_LIMITED", charged: false }; } throw error; } } return { success: false, reason: "MAX_RETRIES_EXCEEDED", charged: true }; }
두 구현의 핵심 패턴은 동일합니다. HTTP 상태 코드만 신뢰하지 말고, 이미지 데이터를 추출하기 전에 항상 finishReason을 검사하며, 재시도 가능한 차단(완화된 프롬프트로 IMAGE_SAFETY)과 최종 차단(PROHIBITED_CONTENT)을 구분해야 합니다. 재시도 로직은 동일한 거부에 대해 반복적으로 비용을 지불하는 것을 방지하기 위해 무작정 재제출이 아닌 프롬프트 완화를 사용합니다. 반환 객체의 charged 필드는 과금 상태를 명시적으로 추적합니다. 이를 통해 모니터링 시스템이 실패한 생성에 얼마나 지출하고 있는지 수량화할 수 있으며, 이는 이전 섹션에서 다룬 비용 분석에 직접 반영됩니다.
IMAGE_SAFETY 비율 모니터링
프로덕션 배포에서는 표준 API 모니터링과 함께 IMAGE_SAFETY 거부율을 핵심 지표로 추적해야 합니다. 우려 임계값은 애플리케이션 유형에 따라 다릅니다. 마케팅 및 비즈니스 그래픽 애플리케이션은 5% 미만을 유지해야 하고, 크리에이티브 및 예술적 애플리케이션은 10-15%가 허용될 수 있으며, 사용자 생성 프롬프트 애플리케이션은 불가피하게 더 높을 수 있습니다. 이러한 기준을 초과한다면 프롬프트 템플릿을 다음 섹션에 문서화된 전략을 사용하여 체계적으로 수정해야 할 가능성이 높습니다.
프롬프트 로직 변경 없이 거부율이 갑자기 급증하는지 주의하세요. Google은 2026년 2월 27일 NB2 출시 이후 Layer 2 필터를 최소 두 번 강화했으며, 매번 이전에 성공적으로 생성된 프롬프트를 포착했습니다. 이 지표에 대한 자동화된 알림을 설정하세요. 이상적으로는 프롬프트 카테고리별 거부율을 보여주는 일일 대시보드를 구축하여 청구서 대시보드에서 몇 주간의 낭비된 지출을 발견하는 대신 필터 변경에 몇 시간 내에 대응할 수 있도록 해야 합니다. 잘 설계된 로깅 시스템은 거부된 모든 요청에 대해 finishReason과 함께 전체 프롬프트 텍스트를 캡처하여, 어떤 특정 문구나 콘텐츠 패턴이 필터를 트리거하는지 식별하는 데 도움이 되는 검색 가능한 데이터베이스를 만들어야 합니다. 이 데이터는 프롬프트 템플릿을 개선하고 Google이 필터 동작을 업데이트할 때 빠르게 적응하는 데 매우 유용합니다.
IMAGE_SAFETY 차단을 피하는 7가지 프롬프트 엔지니어링 전략

Layer 2 필터는 API 설정으로 비활성화할 수 없으므로, 프롬프트 엔지니어링이 IMAGE_SAFETY 차단을 줄이는 유일한 도구입니다. 수백 건의 개발자 보고서를 분석하고 gemini-3.1-flash-image-preview 모델로 광범위하게 테스트한 결과, 다음 일곱 가지 전략이 대부분의 콘텐츠 카테고리에서 필터 트리거율을 60-80% 일관되게 감소시킵니다.
전략 1: 아트 스타일 접두사를 붙이세요. 가장 효과적인 단일 기법은 모든 프롬프트의 시작 부분에 명시적인 아트 스타일을 추가하는 것입니다. "watercolor illustration of," "flat vector art depicting," 또는 "minimalist digital artwork showing"과 같은 문구는 안전 분류기에 사실적 이미지가 아닌 예술적 콘텐츠를 요청하고 있다는 신호를 보냅니다. 분류기가 양식화된 콘텐츠를 사실적 콘텐츠보다 낮은 위험 점수로 처리하기 때문에, 경계선에 있는 프롬프트에 대한 트리거를 극적으로 줄입니다. "a warrior in battle"이라는 프롬프트는 IMAGE_SAFETY를 자주 트리거하지만, "watercolor illustration of a warrior in battle, peaceful composition"은 거의 트리거하지 않습니다.
전략 2: 외모 묘사를 역할 묘사로 대체하세요. 이미지에 사람이 포함될 때, 외모보다는 역할, 직업 또는 원형으로 묘사하세요. 의상, 체형 또는 구체적인 신체적 특징을 묘사하는 대신, "a professional chef in a kitchen"이나 "an engineer examining blueprints"라고 작성하세요. 이 접근 방식은 대상화하거나 선정적으로 해석될 수 있는 신체 묘사에 대한 분류기의 민감도를 우회합니다. 핵심 통찰은 NB2의 안전 필터가 원래 Nano Banana 모델과 비교하여 사람에 대한 묘사에 특히 공격적이라는 것이며, 이는 2026년 2월 출시 이후 의도적인 정책 변경으로 보입니다.
전략 3: 교육 콘텐츠에는 "illustration" 또는 "diagram"을 사용하세요. 의학, 해부학, 과학 이미지는 사진으로 요청하면 IMAGE_SAFETY를 자주 트리거하지만, 다이어그램이나 교육 일러스트레이션으로 요청하면 통과하는 경우가 많습니다. 애플리케이션이 교육 콘텐츠를 생성한다면, 항상 요청을 "medical textbook diagram," "scientific illustration," 또는 "educational schematic"으로 프레이밍하세요. 이는 분류기가 교육적 콘텐츠와 잠재적으로 유해한 시각적 콘텐츠를 구분하도록 훈련된 방식에 매핑됩니다. 안전 필터 경계를 다루는 콘텐츠를 작업하는 개발자에게 이 재프레이밍 기법은 필수적입니다.
전략 4: 모든 실명과 브랜드 콘텐츠를 피하세요. Nano Banana 2는 실존 인물, 유명인, 공인, 인식 가능한 브랜드 이름이나 로고가 포함된 요청에 특히 엄격한 필터링을 적용합니다. 이미지 생성 프롬프트에 실제 사람의 이름을 절대 포함하지 마세요. 대신 원형이나 역할을 묘사하세요. 마찬가지로, 특정 브랜드 이름, 제품명 또는 상표가 등록된 시각적 요소를 참조하지 마세요. 특정 브랜드의 미학과 유사한 것이 필요하다면, 시각적 스타일을 추상적으로 묘사하세요. 특정 회사를 참조하는 대신 "a minimalist tech company logo with geometric shapes"라고 작성하세요. 이는 이전 모델과의 큰 변화이며, NB2로 마이그레이션하는 많은 개발자들이 당황하게 됩니다.
전략 5: 부정적 안전 한정어를 추가하세요. "no violence," "peaceful scene," "fully clothed," 또는 "family-friendly"와 같은 문구를 프롬프트에 명시적으로 추가하면 안전 분류기에 추가적인 신호로 작용합니다. 폭력적인 콘텐츠를 요청하지 않았으므로 이것이 불필요해 보일 수 있지만, 분류기는 이러한 명시적 신호를 사용하여 신뢰도 점수를 조정합니다. 부정적 신호의 부재에 의존하는 것이 아니라 의도에 대한 긍정적 증거를 분류기에 제공하는 것으로 생각하세요.
전략 6: 복잡한 장면을 구성 요소로 분리하세요. 여러 요소를 묘사하는 하나의 복잡한 프롬프트 — "a crowded nightclub with people dancing and drinks flowing, neon lights, realistic photo" — 는 개별적으로는 통과할 수 있지만 집합적으로는 필터를 트리거하는 여러 경계선 요소를 결합합니다. 안전 분류기는 누적 위험 채점 방식을 사용하는 것으로 보이며, 각 잠재적으로 민감한 요소가 단독으로는 차단을 트리거하지 않더라도 전체 위험 점수에 추가되어 임계값을 초과합니다. 대신, 배경 장면과 캐릭터 요소를 별도로 생성하거나, 요청당 잠재적으로 트리거되는 요소의 수를 줄이도록 구성을 단순화하세요. 예를 들어, 위의 나이트클럽 프롬프트 대신 "a modern interior with neon lighting and geometric decor, digital art"로 생성할 수 있습니다. 사람과 특정 활동을 완전히 제거하는 것입니다. 이 접근 방식은 프롬프트 효율성을 신뢰성과 교환하며, 실제로 더 단순한 구성이 모델이 더 적은 요소에 품질을 집중할 수 있기 때문에 더 나은 시각적 결과를 생성하는 경우가 많습니다.
전략 7: 텍스트 전용 생성으로 사전 스크리닝하세요. 전체 이미지 생성 호출(비용 $0.067-$0.151)에 투입하기 전에, 동일한 프롬프트를 텍스트 전용 Gemini 모델에 보내 안전 필터를 트리거할지 평가하도록 요청하세요. 텍스트 전용 호출은 $0.001 미만의 극소 비용이며, 확실한 거부에 대한 비용 지불을 방지할 수 있습니다. 이는 콘텐츠를 미리 예측할 수 없는 사용자 생성 프롬프트에 특히 유용합니다. 구현은 간단합니다. "Would this image generation prompt trigger Google's safety filters? Respond YES or NO with a brief reason: [your prompt here]"와 같은 프롬프트를 Gemini Flash(텍스트 전용 모드)에 보내세요. 사전 스크리닝 모델은 다른 안전 평가 경로를 사용하므로 Layer 2 동작을 완벽하게 예측하지는 못하지만, 개발자 커뮤니티 테스트에 따르면 차단될 프롬프트의 약 70%를 포착합니다. 하루에 수천 개의 사용자 제출 프롬프트를 처리하는 애플리케이션의 경우, 이 사전 스크리닝 단계만으로도 가장 명백히 문제가 되는 요청을 비용이 많이 드는 이미지 생성 파이프라인에 도달하기 전에 필터링하여 월간 수백 달러를 절약할 수 있습니다.
NB2가 너무 제한적일 때 — 대안 모델 비교
위의 프롬프트 전략을 적용했음에도 사용 사례가 지속적으로 IMAGE_SAFETY 차단에 부딪힌다면, Nano Banana 2가 귀하의 애플리케이션에 적합한 모델이 아닐 수 있습니다. 다른 이미지 생성 모델은 각기 다른 안전 필터 철학을 가지고 있으며, 특정 콘텐츠 카테고리에 대해 상당히 더 관대한 모델도 있습니다.
OpenAI API를 통해 접근할 수 있는 DALL-E 3는 예술적이고 창작적인 콘텐츠에 대해 일반적으로 덜 제한적이지만 사실적 인물 얼굴에 대해서는 더 제한적인 다른 안전 접근 방식을 사용합니다. 해상도에 따라 이미지당 약 $0.040-$0.080의 더 높은 가격이 책정되지만, 창작 콘텐츠에 대한 낮은 거부율로 인해 특정 사용 사례에서는 성공적인 이미지당 기준으로 더 저렴할 수 있습니다. Midjourney v6는 예술적이고 창작적인 콘텐츠에 대해 주요 상업 모델 중 가장 관대하지만, API 접근은 구독 계층을 통해 다르게 가격이 책정되는 해당 플랫폼으로 제한됩니다. Flux 2(Black Forest Labs)는 비유해 콘텐츠에 대해 더 세분화된 안전 제어와 낮은 필터율을 가진 개발자 친화적 접근 방식을 취합니다. 패션, 캐릭터 디자인, 창작 초상화 분야에서 특히 강하며, 이 분야는 NB2의 필터가 가장 공격적입니다. GPT Image(OpenAI의 gpt-image-1 모델)는 적당한 안전 필터링과 강력한 프롬프트 이해력을 가진 또 다른 대안을 제공합니다. 이러한 모델들의 품질, 속도, 가격, 안전 엄격도에 대한 종합 비교는 상세 모델 비교를 참조하세요.
실질적인 의사 결정 프레임워크는 특정 콘텐츠 요구 사항과 거부 경제성에 따라 달라집니다. 애플리케이션이 비즈니스 그래픽, 마케팅 자료 또는 추상 미술을 생성한다면, NB2의 필터가 거의 방해하지 않으며 속도 이점(일반적으로 생성당 2-4초)이 대용량 사용 사례에 최선의 선택이 됩니다. 애플리케이션이 캐릭터 디자인, 패션 또는 창작 초상화를 포함한다면, IMAGE_SAFETY 비율이 요청의 30-40%를 초과할 만큼 높을 수 있어서 더 높은 이미지당 가격에도 불구하고 덜 제한적인 모델이 더 비용 효율적일 수 있습니다. 거부에 대한 비용을 지불하지 않기 때문입니다. 핵심 지표는 단가를 비교하는 것이 아니라 성공적인 이미지당 유효 비용(총 지출을 성공적인 생성 수로 나눈 것)입니다. 이미지당 비용이 두 배이지만 거부가 전혀 없는 모델은 NB2 요청의 절반 이상이 필터링된다면 NB2보다 더 저렴합니다.
프로덕션 애플리케이션에는 계층화된 라우팅 전략을 구현하는 것을 고려하세요. 필터를 통과할 때 최고의 가성비를 제공하므로 모든 요청에 NB2를 먼저 시도합니다. 첫 번째 시도가 IMAGE_SAFETY를 반환하면, NB2에서 동일한 프롬프트로 재시도하는 대신 자동으로 대체 모델로 라우팅합니다. 이 접근 방식은 대다수의 요청에서 NB2의 비용 이점을 확보하면서 반복적인 안전 거부의 복합적 비용을 방지합니다. 라우팅 로직은 대체 결정에 최소한의 지연(수백 밀리초)만 추가하지만, 혼합 콘텐츠 유형의 애플리케이션에서 유효 이미지당 비용을 20-40% 절감할 수 있습니다.
마이그레이션 위험을 최소화하려는 개발자에게 laozhang.ai와 같은 플랫폼은 단일 엔드포인트를 통해 여러 이미지 생성 모델을 지원하는 통합 API를 제공합니다. 이를 통해 자동 대체 전략을 구현할 수 있습니다. 속도와 비용 이점을 위해 NB2를 먼저 시도하고, IMAGE_SAFETY 차단이 발생하면 자동으로 대체 모델로 라우팅합니다. 이 접근 방식은 대다수의 요청에서 NB2의 속도를 확보하면서 반복적인 안전 거부 비용을 방지합니다.
자주 묻는 질문
이미지가 차단되었는데 왜 Nano Banana 2가 200 OK를 반환하나요?
Google은 안전 시스템에 의해 출력 콘텐츠가 필터링되었는지 여부와 관계없이, 서버가 성공적으로 수신하고 처리한 모든 요청에 대해 HTTP 200을 반환하도록 Gemini API를 설계했습니다. Google의 API 설계 관점에서 서버는 요청을 성공적으로 처리했습니다. 안전 필터는 전송 수준 오류가 아닌 애플리케이션 수준 결정입니다. 응답 본문의 finishReason 필드가 콘텐츠 생성 시도의 실제 결과를 나타냅니다. 이 설계는 대부분의 REST API가 콘텐츠 필터링을 처리하는 방식과 다릅니다. OpenAI의 DALL-E와 같은 서비스는 안전 차단에 4xx 오류 코드를 반환합니다. 이것이 NB2를 처음 통합하는 개발자들에게 주요 혼란의 원인입니다. 실질적인 의미는 HTTP 상태 코드 확인에만 의존할 수 없으며, 항상 응답 본문을 파싱하고 finishReason 필드를 검사해야 한다는 것입니다.
BLOCK_NONE이 모든 안전 필터를 비활성화하나요?
아닙니다. BLOCK_NONE은 Layer 1 확률적 필터(HARASSMENT, HATE_SPEECH, SEXUALLY_EXPLICIT, DANGEROUS_CONTENT)에만 영향을 미칩니다. Layer 2 하드코딩 필터(IMAGE_SAFETY, PROHIBITED_CONTENT, CSAM, SPII)는 safetySettings 구성과 관계없이 활성 상태를 유지합니다. 이것은 모든 Gemini 이미지 생성 모델에 적용되는 협상 불가능한 Google 정책입니다(ai.google.dev/safety-settings, 2026년 3월 기준 검증).
이미지가 포함되지 않은 200 OK 응답에 대해 과금되나요?
네. finishReason: "IMAGE_SAFETY"가 포함된 응답을 포함하여 모든 200 OK 응답은 표준 토큰 처리 요금으로 과금됩니다. 서버 측 오류(429, 500, 503)만 과금되지 않습니다. 이는 모든 IMAGE_SAFETY 차단이 1K 해상도의 경우 약 $0.067, 4K 해상도의 경우 약 $0.151의 비용이 발생한다는 것을 의미합니다(ai.google.dev/pricing, 2026년 3월 기준).
SAFETY와 IMAGE_SAFETY finishReason 값의 차이는 무엇인가요?
SAFETY는 Layer 1 차단을 나타냅니다(구성 가능, safetySettings로 수정). IMAGE_SAFETY는 Layer 2 차단을 나타냅니다(구성 불가능, 프롬프트 재구성으로 수정). 두 경우 모두 이미지 데이터 없이 200 OK 응답이 되지만, 수정 전략은 완전히 다릅니다. 수정 접근 방식을 결정하기 전에 항상 어떤 구체적인 값을 받았는지 확인하세요.
Nano Banana 2가 원래 Nano Banana보다 더 제한적인가요?
네. Nano Banana 2(gemini-3.1-flash-image-preview, 2026년 2월 27일 출시)는 원래 Nano Banana 모델과 비교하여 더 엄격한 Layer 2 필터링을 적용합니다. 특히 유명인 얼굴, 선정적 콘텐츠, 브랜드 이미지에 대해 그렇습니다. 원래 모델에서 성공적으로 이미지를 생성했던 프롬프트가 프롬프트 텍스트를 전혀 변경하지 않았는데도 NB2에서 IMAGE_SAFETY를 트리거할 수 있습니다.
요약 및 다음 단계
Nano Banana 2의 200 OK 이미지 없음 문제는 버그가 아닙니다. 콘텐츠 필터링이 애플리케이션 레이어에서 발생하면서 HTTP 전송은 성공을 보고하는 Google의 의도적인 설계 결정입니다. 이 가이드에서 가장 중요한 핵심 사항은 다음과 같습니다. 첫째, HTTP 상태 코드를 신뢰하는 대신 모든 API 응답에서 finishReason을 확인하세요. 둘째, Layer 2 필터(IMAGE_SAFETY)는 비활성화할 수 없으며 프롬프트 수준의 수정이 필요하다는 것을 이해하세요. 셋째, 거부율을 모니터링하고 과금 영향을 정량화하세요. 필터링된 200 OK 응답은 전체 요금이 청구되기 때문입니다.
즉각적인 실행 항목은 다음과 같습니다. 위에 제공된 Python 또는 Node.js 템플릿을 사용하여 애플리케이션 코드에 finishReason 파싱을 구현하고, 가장 일반적인 프롬프트 템플릿에 아트 스타일 접두사 전략을 적용하며(이것만으로도 실패율이 40-60% 감소합니다), IMAGE_SAFETY 거부율에 대한 모니터링을 설정하여 프롬프트 문제와 Google 측 필터 강화를 모두 조기에 감지하세요. 필터율이 높은 애플리케이션의 경우, 성공적인 이미지당 유효 비용을 계산하고 다중 모델 대체 전략이 전체 지출을 줄일 수 있는지 평가하세요.
Google이 Gemini 이미지 생성 파이프라인을 계속 개발함에 따라 Layer 2 필터 동작은 진화할 가능성이 높습니다. 최선의 방어는 필터링된 응답을 즉시 감지하고, 분석을 위해 컨텍스트를 로깅하며, 적절한 경우 대안으로 라우팅하는 탄력적인 애플리케이션 아키텍처입니다. IMAGE_SAFETY를 좌절스러운 제한이 아닌 시스템 설계 과제로 취급하는 개발자들이 Google이 안전 임계값을 어떻게 조정하든 안정적으로 작동하는 애플리케이션을 구축하는 사람들입니다.