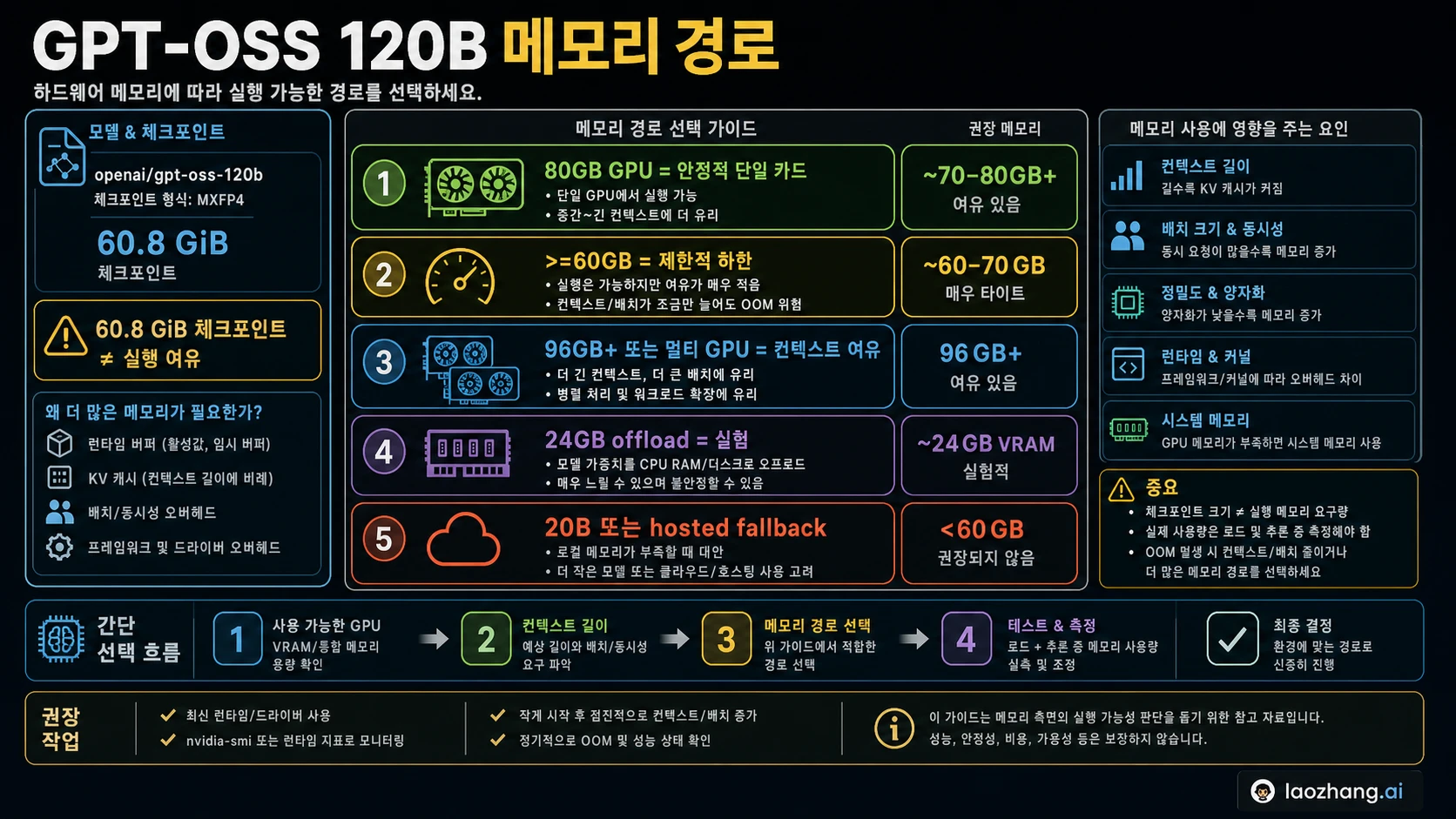
GPT-OSS 120B를 로컬에서 안정적으로 돌리려면 먼저 80GB GPU 메모리급 모델로 봐야 합니다. >=60GB는 일부 runtime에서 가능한 제한적인 로딩 하한이고, 60.8 GiB는 MXFP4 checkpoint 크기에 가까운 파일 단위 사실입니다. 두 숫자는 runtime buffer, KV cache, 긴 context, batch, concurrency, CPU offload 비용을 포함하지 않습니다.
| 하드웨어 경로 | 메모리 숫자의 의미 | 적합한 상황 | 멈춰야 할 신호 |
|---|---|---|---|
| 80GB GPU | 단일 카드 clean target | 평가, 개발, 작은 규모의 안정 실행 | context와 batch 여유는 따로 봐야 함 |
| >=60GB VRAM 또는 unified memory | runtime별 제한 하한 | 짧은 context와 낮은 batch 테스트 | production headroom으로 말하지 않기 |
| 96GB+ 또는 multi-GPU | 여유 경로 | 긴 context, 안정 throughput, OOM 감소 | sharding과 KV cache 검증 필요 |
| 24GB consumer GPU plus offload | 실험 경로 | 로딩 가능성 학습, proof-of-load | OOM 또는 속도 부족이면 경로 변경 |
| GPT-OSS 20B 또는 hosted/API | fallback | 120B 로컬 조건을 못 맞출 때 | 더 큰 모델을 억지로 밀어 넣지 않기 |
60.8 GiB, >=60GB, 80GB는 서로 다른 층위다
한국어 하드웨어 글에서는 메모리 요구 사항을 하나의 숫자로 압축하는 경우가 많습니다. 하지만 GPT-OSS 120B는 파일 크기, 로딩 하한, 안정 실행 목표를 분리해야 합니다. 첫 번째 층위는 checkpoint입니다. OpenAI model card는 GPT-OSS 120B의 MXFP4 checkpoint를 약 60.8 GiB, total parameters를 116.83B, active parameters를 5.13B로 제시합니다. 이 숫자는 모델 파일과 weight 크기를 설명하지만, 64GB GPU가 편안하게 실행된다는 뜻은 아닙니다.
두 번째 층위는 runtime 로딩 하한입니다. OpenAI Cookbook의 Transformers, vLLM, Ollama 예시는 >=60GB VRAM 또는 >=60GB VRAM / unified memory 경로를 말합니다. 이 값은 backend, quantization, context length, batch size, driver, cache 동작에 따라 달라집니다. 짧은 prompt로 로딩되는 것과 실제 작업 부하를 안정적으로 처리하는 것은 다릅니다.
세 번째 층위는 운영 목표입니다. OpenAI launch post는 GPT-OSS 120B가 80GB memory 안에서 실행될 수 있다고 설명하고, Hugging Face도 H100 80GB나 MI300X 같은 single 80GB GPU에 맞는 모델로 설명합니다. GPU를 구매하거나 대여하거나 팀 기준을 정하려는 사람에게 80GB가 가장 안전한 짧은 답입니다.

따라서 세 숫자는 충돌하지 않습니다. 60.8 GiB는 artifact 크기, >=60GB는 좁은 runtime floor, 80GB는 더 안전한 hardware planning target입니다. 이 차이를 무시하면 24GB나 64GB 환경에서 원래는 fallback을 선택해야 할 문제를 며칠씩 tuning하게 됩니다.
공식 근거를 먼저 고정한다
GPT-OSS 120B의 memory 판단은 OpenAI와 Hugging Face의 1차 자료를 기준으로 잡아야 합니다. GeekNews, Reddit, Naver Blog, YouTube, Facebook 실험은 실제 사용자의 시도를 보여 주지만 요구 사항의 소유자가 될 수는 없습니다.
| 사실 | 근거 소유자 | 실무 의미 |
|---|---|---|
| GPT-OSS 120B can run within 80GB memory | OpenAI launch post | 80GB가 clean single accelerator target |
| GPT-OSS 20B targets 16GB memory | OpenAI launch post | 20B가 낮은 메모리의 현실적 fallback |
| 60.8 GiB checkpoint | OpenAI model card | 파일 크기는 runtime 여유가 아님 |
| >=60GB VRAM 또는 unified memory | OpenAI Cookbook guides | 제한적인 runtime floor가 존재 |
| single 80GB GPU framing | Hugging Face model page와 MXFP4 docs | 80GB GPU가 더 안정적인 local plan |
OpenAI launch post, model card PDF, Transformers guide, Ollama guide, vLLM guide는 모델 사실과 runtime floor의 근거입니다. Hugging Face model page와 MXFP4 documentation은 120B급 open-weight model이 어떻게 80GB급 envelope에 들어가는지 설명합니다. 커뮤니티 사례는 AMD AI Max, RTX 3090 여러 장, 8GB VRAM plus 64GB RAM, CPU offload 같은 실험을 이해하는 데 쓰고, 공식 요구 사항의 대체물로 쓰지 않습니다.
실행 경로를 먼저 선택한다
메모리 요구 사항은 실행 경로에 따라 달라집니다. 먼저 경로를 고르면 어떤 위험을 테스트해야 하는지도 분명해집니다.
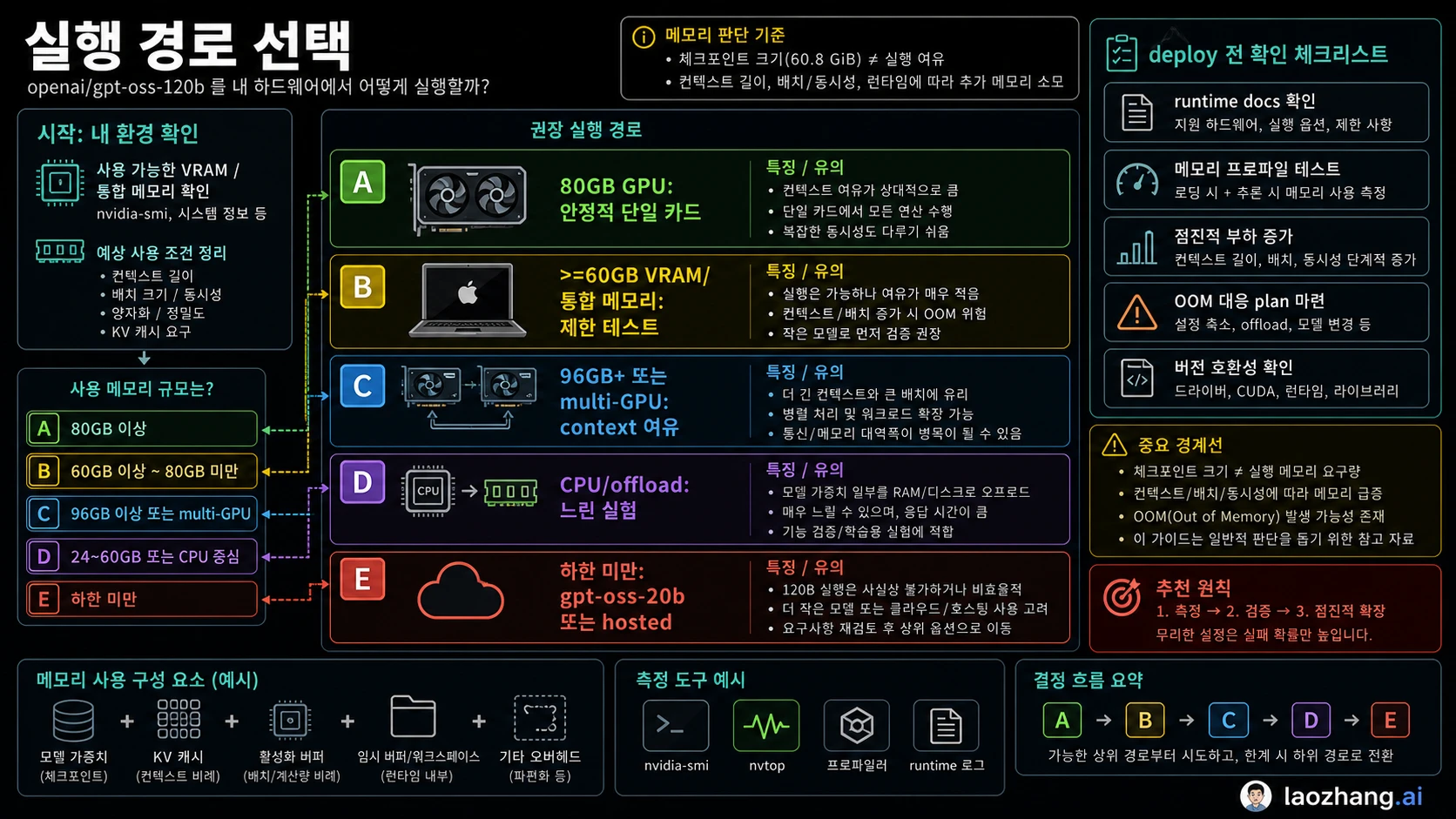
| 경로 | 메모리 관점 | 가장 적합한 용도 | 주요 위험 |
|---|---|---|---|
| 80GB GPU의 Transformers | clean local route | 개발, 평가, 통제된 실험 | context와 batch 여유 필요 |
| 80GB 또는 multi-GPU의 vLLM | serving route | throughput, API serving 실험 | KV cache와 concurrency가 메모리 상승 |
| Ollama plus >=60GB VRAM/unified memory | low-friction local route | workstation, unified memory 테스트 | CPU offload로 속도 저하 |
| 96GB+ workstation 또는 multi-GPU | headroom route | 긴 context, 안정 throughput | sharding과 backend 복잡도 |
| 24GB GPU plus offload | experiment route | 학습, proof-of-load, 호기심 | 속도와 context가 실용 밖일 수 있음 |
| GPT-OSS 20B | small fallback | 16GB에서 24GB machine | 품질과 capacity가 120B와 다름 |
| hosted/API | local memory 부담 없음 | 제품 통합, 빠른 검증 | cost, rate limit, availability 관리 필요 |
모델의 품질만 비교하려면 적절한 80GB급 GPU를 짧게 빌려 보는 편이 낫습니다. backend 동작을 배우려면 offload 실험도 가치가 있습니다. 하지만 팀 서비스나 고객 기능을 만들려면 headroom이 있는 route에서 시작해야 합니다.
VRAM, unified memory, system RAM, disk를 섞지 않는다
VRAM은 GPU 전용 메모리입니다. H100 80GB, A100 80GB, MI300X 같은 이야기는 weight, runtime buffer, KV cache를 accelerator 쪽에 둘 수 있는지를 말합니다. 속도와 안정성을 원한다면 가장 중요한 메모리입니다.
Unified memory는 CPU와 GPU가 공유하는 memory pool입니다. Apple Silicon이나 일부 workstation에서 큰 모델을 로딩할 수 있게 도와주지만, 80GB discrete GPU와 같은 의미는 아닙니다. bandwidth, backend support, offload path, thermal behavior, context length가 모두 영향을 줍니다.
System RAM은 CPU offload나 hybrid inference에서 중요합니다. 모델을 실패 없이 로딩하게 만들 수는 있지만 대부분 속도, loading time, context 안정성을 비용으로 냅니다. Disk는 checkpoint, tokenizer, converted format, cache를 저장합니다. 60.8 GiB checkpoint는 storage fact이지 runtime memory fact가 아닙니다.
마지막으로 KV cache와 runtime buffers가 있습니다. 긴 prompt, RAG chunks, multi-turn conversation, batch serving, concurrent users는 모델이 로딩된 후에도 메모리를 계속 요구합니다. 짧은 prompt 하나가 통과했다고 해서 실제 업무 부하가 통과하는 것은 아닙니다.
내 하드웨어는 어느 단계인가
80GB accelerator가 있다면 가장 단순합니다. H100 80GB, A100 80GB, MI300X급 hardware가 있고 runtime이 지원한다면 GPT-OSS 120B를 local evaluation 또는 작은 serving 후보로 둘 수 있습니다. driver, CUDA/ROCm, model format, context length, batch 확인은 여전히 필요하지만 가장 좁은 floor에 매달리는 상태는 아닙니다.
60GB에서 79GB는 test tier입니다. 올바른 quantized checkpoint, 짧은 context, 낮은 batch, 특정 backend에서는 작동할 수 있습니다. 그러나 long context, production concurrency, multi-user serving을 약속하기에는 부족합니다. 결과를 공유할 때는 GPU, runtime, model file, context, batch, offload 여부를 반드시 적어야 합니다.
96GB+, multi-GPU, cloud GPU는 headroom tier입니다. 비용과 구성 난도가 올라가지만 실패 비용이 큰 경우에는 합리적입니다. 긴 RAG, 반복 평가, server experiment, 여러 사용자, 높은 throughput은 여분의 memory를 요구합니다.
16GB에서 24GB consumer GPU는 fallback 또는 experiment tier입니다. GPT-OSS 20B를 먼저 실행하는 것이 자연스럽고, 120B는 offload와 quantization을 배우는 실험으로 취급해야 합니다. “8GB VRAM에서도 훌륭하게 구동” 같은 제목은 흥미로운 실험일 수 있지만, 다른 사람의 배포 권장 사양은 아닙니다.
4090, 3090, 5090에서의 stop rule
RTX 4090과 RTX 3090은 보통 24GB VRAM입니다. GPT-OSS 120B를 clean GPU-resident route로 실행하기에는 부족합니다. CPU offload, unified memory, smaller context, runtime-specific trick으로 로딩 실험은 가능할 수 있습니다. 하지만 속도, context 길이, 안정성이 목표를 만족하지 못하면 계속할 이유가 없습니다.
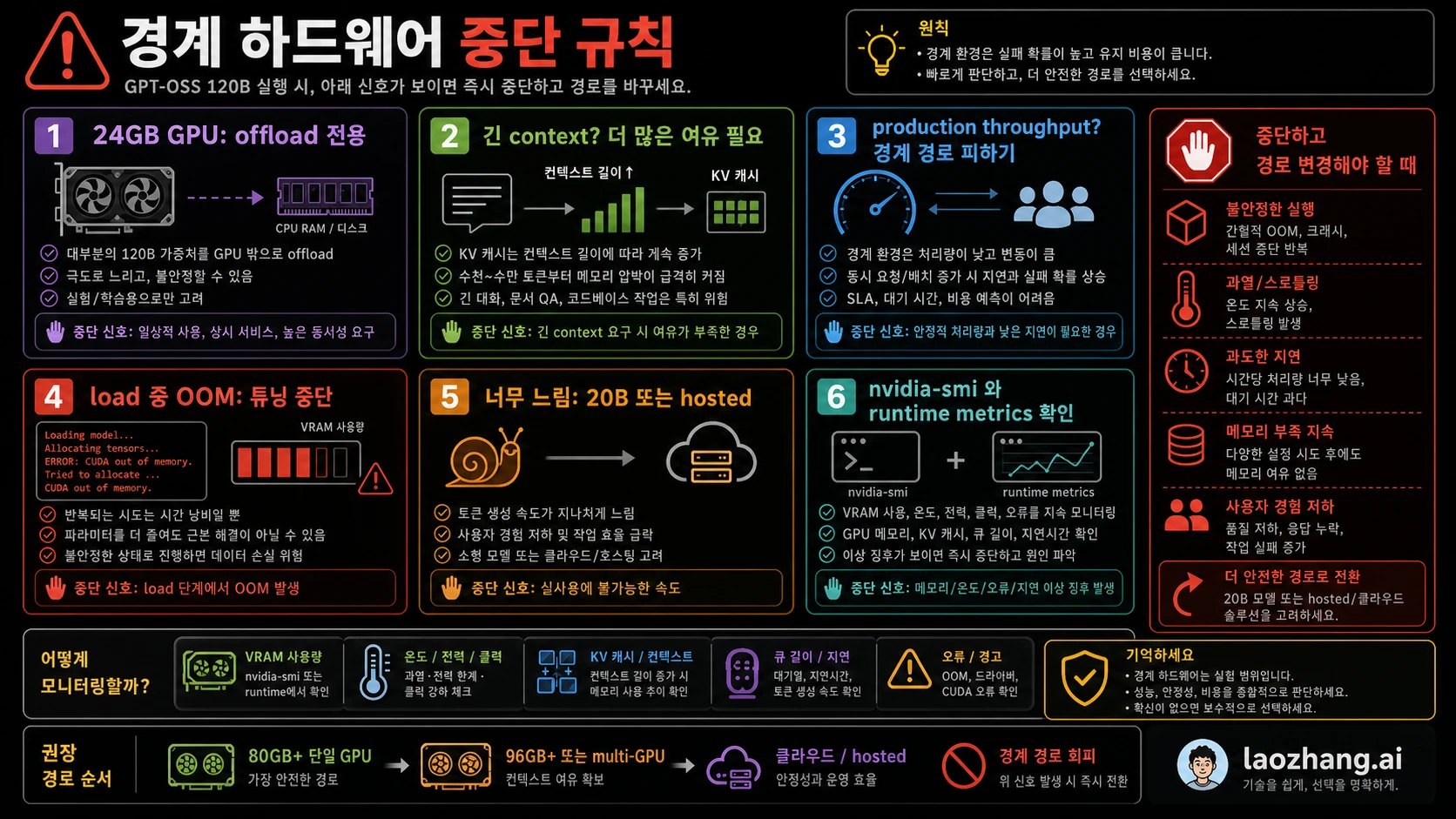
반복 OOM이 나면 tuning을 멈추고 경로를 바꿉니다. 로딩은 되지만 tokens per second가 너무 낮으면 GPT-OSS 20B, cloud GPU, hosted/API를 사용합니다. 긴 context가 필요한 작업이라면 짧은 context에서만 되는 setup을 채택하지 않습니다. serving이 필요하다면 heavy offload가 맞아야만 동작하는 구성을 피합니다. 계속 시도하는 이유가 호기심뿐이라면 결과를 experiment라고 표시합니다.
5090도 실제 VRAM이 중요합니다. 세대가 새롭다고 해서 60GB에서 80GB 구간에 도달하지 않는 memory 부족이 해결되지는 않습니다. compute가 빨라도 weights와 cache를 둘 공간이 부족하면 병목은 남습니다.
context length와 batch가 실제 여유를 결정한다
충분한지 판단하려면 model load만 보면 안 됩니다. 실제로 지원하려는 context length, batch size, concurrency, prompt shape, RAG input, tool use를 그대로 테스트해야 합니다. 긴 context는 KV cache를 키우고, serving framework는 throughput을 위해 memory planning을 추가로 요구합니다.
기록해야 할 항목은 runtime 이름과 version, model file, quantization, GPU, VRAM, system RAM, driver, context length, batch, concurrency, offload 여부, loading 후 memory, inference peak memory, tokens per second, OOM 여부입니다. 이 정보 없는 “된다”는 경험담이며, 구매나 배포 판단에는 부족합니다.
모든 값을 최소화해야만 성공한다면 그 경로는 demo route입니다. demo route는 학습에는 좋지만 팀 표준, 고객 기능, production deployment에는 맞지 않습니다.
fallback이 더 나은 순간
GPT-OSS 20B는 낮은 메모리 환경을 위해 존재합니다. OpenAI가 16GB memory target을 제시했기 때문에 laptop, consumer desktop, offline tool, quick test에서는 20B가 더 빠르게 usable state에 도달합니다. capacity는 다르지만 실제로 쓸 수 있다는 점이 중요합니다.
Cloud GPU는 120B 품질을 짧게 확인할 때 유용합니다. 24GB GPU에서 offload를 하루 종일 조정하는 것보다 80GB급 instance에서 실제 context와 speed를 측정하는 편이 의사결정에 더 낫습니다. Hosted/API는 local hardware ownership이 목적이 아닐 때 적합하지만 cost, rate limit, account state, provider boundary를 관리해야 합니다.
| 실제 목표 | 더 나은 경로 |
|---|---|
| 내 machine에서 120B 행동을 배우기 | constrained/offload route를 experiment로 시도 |
| reliable local workflow 만들기 | 80GB+, 96GB+, multi-GPU |
| 16GB에서 24GB hardware 사용 | GPT-OSS 20B부터 시작 |
| GPU 없이 feature 출시 | hosted/API와 limit 관리 |
| 구매 전 답변 품질 비교 | 적절한 GPU를 짧게 빌려 측정 |
자주 묻는 질문
GPT-OSS 120B에는 VRAM이 얼마나 필요한가요?
clean local answer는 80GB GPU memory입니다. 일부 runtime path는 >=60GB에서 로딩될 수 있지만 context, batch, backend 기준으로 반드시 테스트해야 합니다.
60.8 GiB면 64GB GPU에 충분한가요?
아닙니다. 60.8 GiB는 checkpoint size입니다. runtime buffers, KV cache, context, framework overhead가 추가로 필요합니다.
RTX 4090이나 3090에서 실행할 수 있나요?
clean GPU-resident route는 아닙니다. offload experiment는 가능할 수 있지만 속도와 context가 목적에 맞아야 의미가 있습니다.
5090이면 가능할까요?
실제 VRAM과 runtime support에 달려 있습니다. 60GB에서 80GB보다 훨씬 낮으면 여전히 experiment tier입니다.
system RAM은 얼마나 필요하나요?
CPU offload와 unified memory route에 중요하지만 VRAM을 일대일로 대체하지 않습니다. 실제 workload로 확인해야 합니다.
disk space는 얼마나 잡아야 하나요?
60.8 GiB checkpoint, tokenizer, cache, converted formats, 작업 여유 공간을 함께 잡아야 합니다.
vLLM, Transformers, Ollama 중 무엇을 써야 하나요?
개발과 평가는 Transformers, serving experiment는 vLLM, 쉬운 local test는 Ollama가 맞습니다. 어떤 경로든 runtime과 memory path를 기록합니다.
언제 120B 시도를 멈춰야 하나요?
짧은 context에서만 되고, OOM tuning이 반복되고, tokens per second가 실용 밖이고, heavy offload가 전제라면 20B, larger GPU, multi-GPU/cloud, hosted/API로 이동해야 합니다.