
“Gemini 3.1 Flash Live API”라고 검색하는 개발자가 실제로 써야 하는 것은 gemini-3.1-flash-live-preview 모델이며, 접속하는 API 표면은 Gemini Live API입니다. 이 구분이 중요한 이유는 Google이 핵심 정보를 여러 문서에 흩어놓았기 때문입니다. 전체 그림을 보려면 모델 페이지, Live API 개요, capabilities guide, pricing 페이지, ephemeral tokens 안내, 그리고 2026년 3월 26일 공식 발표를 함께 봐야 합니다.
핵심 결론부터 말하면 새로운 저지연 음성 에이전트를 만든다면 Gemini 3.1 Flash Live부터 시작하는 것이 맞습니다. 하지만 gemini-2.5-flash-native-audio-preview-12-2025에서 그냥 모델 문자열만 바꾸면 끝나는 식의 업그레이드는 아닙니다. Google은 음성 품질과 대화 자연스러움, 운영 여유를 끌어올렸지만, 동시에 thinking 설정, 서버 이벤트 구조, 증분 입력 방식, tool use 동작을 바꿨습니다. 기존 2.5 스택이 async function calling, proactive audio, affective dialog에 기대고 있었다면, 무작정 갈아타는 순간 체감 품질이 먼저 나빠질 수 있습니다.
“근거 메모: 이 글은 Google의 공식 개발자 문서와 공식 발표를 2026년 3월 28일 기준으로 다시 확인한 뒤 작성했습니다. Google 공개 문서끼리 숫자나 표현이 어긋나는 부분은 억지로 하나로 맞추지 않고 그대로 표시합니다.
TL;DR
| 먼저 알아야 할 것 | 현재 답 |
|---|---|
| 정확한 모델 ID | gemini-3.1-flash-live-preview |
| 정확한 API 표면 | 상태 유지형 WebSocket 기반 Gemini Live API |
| 출시일 | 2026년 3월 26일 |
| 가장 잘 맞는 시작 용도 | 저지연, 멀티모달 인지, 더 자연스러운 음성 대화가 필요한 실시간 음성 에이전트 |
| 기본 권장안 | 새 프로젝트는 3.1부터 시작 |
| 아직 2.5에 남아야 하는 주된 이유 | async tool calling, proactive audio, affective dialog가 꼭 필요할 때 |
| 큰 마이그레이션 변화 | thinkingBudget가 thinkingLevel로 바뀌고, 하나의 서버 이벤트에 여러 part가 들어올 수 있으며, 실시간 갱신은 send_realtime_input으로 보내야 하고, tool 호출은 현재 동기만 지원 |
| 가격 형태 | text input $0.75 / 1M tokens, audio input $3 / 1M tokens 또는 $0.005 / 분, image/video input $1 / 1M tokens 또는 $0.002 / 분, text output $4.50 / 1M tokens, audio output $12 / 1M tokens 또는 $0.018 / 분 |
| 브라우저에서 안전하게 붙는 방법 | 백엔드에서 ephemeral token을 발급한 뒤 클라이언트를 연결 |
| 숨어 있는 비용 포인트 | 기본 turn coverage가 모든 video frame을 포함 |
Google이 2026년 3월 26일에 실제로 내놓은 것
공식 발표는 Gemini 3.1 Flash Live를 Google의 최신 실시간 오디오 모델로 소개하며, 개발자는 Google AI Studio에서 Gemini Live API를 통해 preview로 사용할 수 있다고 설명합니다. 모델 페이지는 이를 더 구체적으로 풀어줍니다. 모델 코드는 gemini-3.1-flash-live-preview, 입력은 text, images, audio, video, 핵심 목적은 낮은 지연으로 동작하는 실시간 대화이며 acoustic nuance detection, numeric precision, multimodal awareness를 강조합니다.
이 점에서 흔한 오해를 먼저 정리해야 합니다. “Gemini 3.1 Flash Live API”라는 별도의 제품이 따로 있는 것이 아닙니다. Gemini Live API가 실시간 스트리밍 인터페이스이고, Gemini 3.1 Flash Live는 그 위에서 실행되는 모델입니다. Live API 자체는 상태를 가지는 WebSocket 세션이기 때문에, 끊김 없는 스트리밍 입력, 인터럽트, 멀티모달 turn 처리에 맞춰 설계되었습니다. 일반적인 generateContent 요청처럼 한 번 보내고 한 번 받는 식으로 생각하면 구조를 잘못 잡기 쉽습니다.
또 하나 중요한 점은 이것이 단순한 TTS 모델이 아니라는 사실입니다. 공식 문서는 function calling과 Google Search grounding을 지원한다고 적고 있으므로, 단순히 텍스트를 읽어주는 모델이 아니라 “듣고, 보고, 판단하고, 필요하면 도구를 부르고, 그 자리에서 응답하는” voice-ready agent용 모델로 보는 편이 맞습니다. 같은 모델 페이지에는 knowledge cutoff가 2025년 1월이라고 적혀 있으므로, 최신 정보가 필요한 제품이라면 grounding이나 자체 retrieval 계층을 함께 설계해야 합니다.
다만 구현 단계에서 눈여겨볼 모순도 있습니다. 모델 페이지는 text와 audio output을 모두 말하지만, capabilities guide는 native audio models가 AUDIO response modality만 지원한다고 설명합니다. 그래서 실무적으로는, 읽을 수 있는 텍스트가 필요하다면 그것을 “일반 텍스트 응답”이 아니라 output audio transcription으로 다루는 편이 안전합니다. 또 공식 발표는 생성된 모든 오디오가 SynthID watermark를 포함한다고 밝히고 있어, 사용자에게 배포되는 음성 경험이라면 이 역시 계약 조건의 일부로 봐야 합니다.
새 프로젝트라면 3.1로 가야 하나, 아니면 2.5를 유지해야 하나
새로 만드는 프로젝트라면 3.1이 기본 선택지입니다. Google이 최신·최상위 실시간 음성 모델로 포지셔닝하고 있고, 마이그레이션 문서도 2.5에서 3.1로의 이동을 전제로 써두었습니다. 하지만 이것이 2.5의 완전한 상위 호환이라는 뜻은 아닙니다.
실제로 중요한 질문은 지금의 2.5 시스템이 3.1에 아직 없는 능력에 의존하고 있는지 여부입니다. 그래서 발표 기사보다 아래 비교표가 더 중요합니다.
| 실무 차이 | Gemini 3.1 Flash Live | Gemini 2.5 Flash Live |
|---|---|---|
| 모델 ID | gemini-3.1-flash-live-preview | gemini-2.5-flash-native-audio-preview-12-2025 |
| 출시 / 최근 업데이트 | 2026년 3월 26일 출시 | 2025년 9월 업데이트 |
| 출력 token 한도 | 65,536 | 8,192 |
| thinking 제어 | thinkingLevel | thinkingBudget |
| 서버 이벤트 구조 | 하나의 이벤트에 여러 part 가능 | 이벤트당 part 하나 |
| 실시간 텍스트 입력 | send_realtime_input 중심 | 대화 중에도 send_client_content 사용 가능 |
| 기본 turn coverage | TURN_INCLUDES_AUDIO_ACTIVITY_AND_ALL_VIDEO | TURN_INCLUDES_ONLY_ACTIVITY |
| Async function calling | 미지원 | 지원 |
| Proactive audio | 미지원 | 지원 |
| Affective dialog | 미지원 | 지원 |
| 지금 잘 맞는 곳 | 새 음성 에이전트 | 2.5 고유 기능에 기대는 기존 운영계 |
이 표에서 바로 읽어야 할 핵심은 두 가지입니다.
첫째, 실시간 음성 대화 품질이라는 본류에서는 3.1이 실제로 전진했습니다.
Google은 음색 이해, 복잡한 작업 수행, 자연스러운 대화 흐름의 개선을 강조하고 있고, output token 한도 역시 8,192에서 65,536으로 크게 늘었습니다. 새 프로젝트의 기본 출발점으로 삼기 충분한 이유입니다.
둘째, 기존 2.5 시스템을 가진 팀에게는 3.1이 무조건 이득이 아닙니다.
예를 들어 2.5에서 behavior: NON_BLOCKING 같은 비동기 tool 흐름을 전제로 설계해 두었다면, 3.1으로 옮기는 순간 대화 설계 자체를 다시 해야 할 수 있습니다. Google 문서가 3.1의 function calling을 동기 전용이라고 분명히 적고 있기 때문입니다. proactive audio와 affective dialog도 같은 맥락입니다. 2.5 시절의 UX를 구성하던 요소가 3.1에 그대로 옮겨오지 않습니다.
따라서 판단 규칙은 간단합니다.
- 제로에서 시작한다면 3.1
- 이미 2.5를 운영 중이라면 동기 tool loop와 기능 공백을 받아들일 수 있는지 확인한 뒤 이동

가격은 token보다 minute로 읽어야 운영 판단이 쉬워진다
이번 가격 페이지가 유용한 이유는 token 단가만이 아니라 minute 단가도 제공한다는 점입니다. 실시간 음성 제품에서는 이쪽이 훨씬 직관적입니다.
| 항목 | 현재 가격 |
|---|---|
| Text input | $0.75 / 1M tokens |
| Audio input | $3.00 / 1M tokens 또는 $0.005 / 분 |
| Image/video input | $1.00 / 1M tokens 또는 $0.002 / 분 |
| Text output | $4.50 / 1M tokens |
| Audio output | $12.00 / 1M tokens 또는 $0.018 / 분 |
| Google Search grounding | Gemini 3 공유 월 5,000 prompts 무료, 이후 $14 / 1,000 query |
이 수치로 바로 현실적인 계산이 가능합니다. 양방향으로 오디오가 흐르는 통화라면, audio input과 audio output의 분당 가격을 합쳐 분당 약 $0.023 입니다. 10분 통화면 오디오만으로 약 $0.23 입니다. 이는 Google이 문장으로 직접 적은 값이 아니라, 공개된 $0.005 / 분과 $0.018 / 분에서 바로 계산한 값입니다.
Search grounding도 생각보다 의미가 있습니다. 무료 공유 구간을 넘기면 query 하나가 약 $0.014 입니다. 세션 안에서 5번 검색을 쓰면 약 $0.07 이 추가됩니다.
더 위험한 것은 video입니다. 3.1 마이그레이션 노트는 기본 turn coverage가 all video를 포함한다고 밝힙니다. 즉, 실제로는 음성이 중심인데 카메라 프레임을 계속 밀어 넣는 설계라면 3.1에서는 비용이 조용히 커집니다.
또 한 가지는 쿼터입니다. Google은 Gemini 3.1 Flash Live의 정확한 RPM / RPD를 공개 페이지에 고정해 두지 않고, AI Studio에서 active rate limits를 확인하라고 안내합니다. 따라서 문서에서 비용 구조를 이해하고, 실제 배포 용량은 AI Studio의 현재 값을 보는 것이 맞습니다.
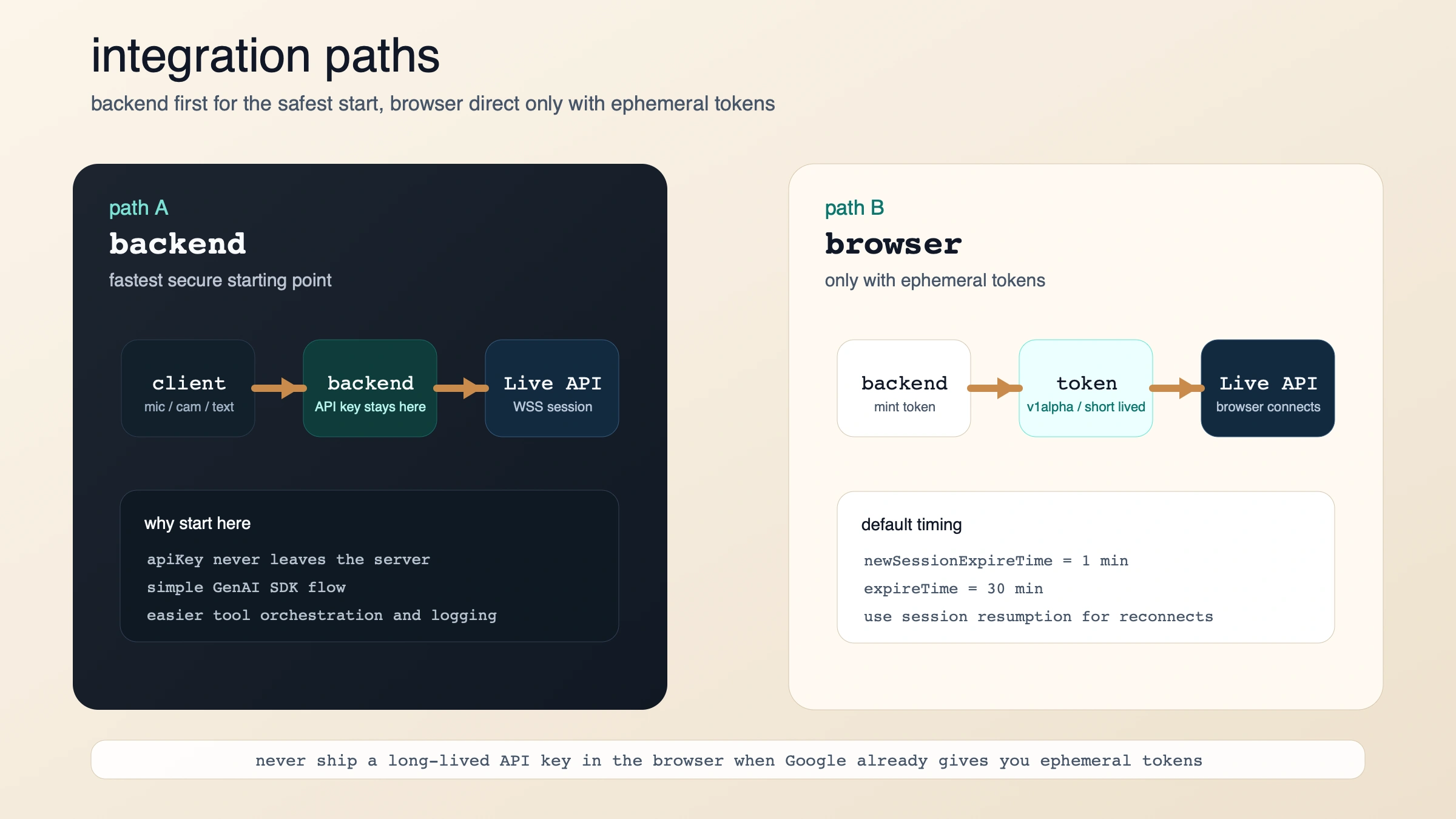
가장 빨리 동작시키는 방법: backend first, browser direct는 그 다음
빨리 성공하는 것이 목표라면 server-to-server가 가장 안정적입니다. Live API overview도 이 구조를 기본으로 설명하고, capabilities guide의 예제 역시 Live 연결을 열고 AUDIO를 선언한 뒤 send_realtime_input으로 데이터를 보내는 형태입니다.
pythonimport asyncio from google import genai client = genai.Client() MODEL = "gemini-3.1-flash-live-preview" async def main(): config = {"response_modalities": ["AUDIO"]} async with client.aio.live.connect(model=MODEL, config=config) as session: await session.send_realtime_input( text="Say hello and introduce yourself in one sentence." ) async for response in session.receive(): if response.server_content and response.server_content.model_turn: for part in response.server_content.model_turn.parts: if part.inline_data: audio_bytes = part.inline_data.data # 여기서 audio_bytes를 재생하거나 전달 if response.text: print(response.text) if response.server_content and response.server_content.turn_complete: break asyncio.run(main())
실제 음성 스트림으로 가면 포맷 조건도 중요합니다. Google 문서에 따르면 입력은 16-bit PCM / 16kHz / little-endian, MIME type은 audio/pcm;rate=16000 형태입니다. 출력은 24kHz PCM입니다. 또 오디오만 쓰는 세션은 15분, 오디오 + 비디오는 2분 제한이 있으므로, 더 긴 세션이 필요하면 session management / resumption을 설계해야 합니다.
브라우저 직접 연결이 필요한 경우, Google이 제시하는 답은 ephemeral tokens입니다. 목적은 분명합니다. 장기 API key를 프론트엔드에 두지 않으면서도 낮은 지연을 얻는 것입니다. 공식 가이드의 기본값은:
- 신규 세션 시작까지 보통 1분
- 연결 후 메시지 전송 가능 시간은 보통 30분
- 클라이언트는 이 token을 API key처럼 사용
- 재연결은 session resumption으로 처리
결국 설계 규칙은 이렇게 정리됩니다.
- backend only: 가장 단순하고 안전한 시작점
- browser direct: 백엔드가 ephemeral token을 안전하게 발급할 수 있을 때만
첫날 가장 많이 시간을 잡아먹는 마이그레이션 실수
2.5에서 3.1로 갈 때 위험한 것은 전체 실패보다 “대충은 돌아가는데 묘하게 이상한 상태”입니다.
1. thinkingBudget를 계속 보내지 말 것.
3.1은 thinkingLevel을 씁니다. 게다가 기본값은 지연 최소화를 위한 minimal입니다.
2. 서버 이벤트의 모든 part를 읽을 것.
3.1에서는 오디오 chunk와 transcript가 같은 이벤트에 함께 들어올 수 있습니다. 이전 파서 가정이 남아 있으면 조용히 데이터를 잃습니다.
3. 실시간 업데이트는 send_realtime_input으로 보낼 것.
2.5 감각대로 send_client_content를 대화 중 계속 쓰는 것은 3.1에서 맞지 않습니다.
4. tool 호출은 동기 흐름으로 설계할 것.
3.1은 tool response를 받을 때까지 다음 반응을 시작하지 않습니다. 기존 2.5의 비동기 tool loop를 그대로 옮기는 것은 위험합니다.
5. proactive audio / affective dialog 설정을 남겨두지 말 것.
현재 3.1에서는 미지원입니다.
6. video는 정말 필요할 때만 보낼 것.
all video가 기본이므로, 카메라를 계속 보내는 설계는 곧 비용 설계가 됩니다.
7. 텍스트는 transcription 관점에서 다룰 것.
모델 페이지와 capability 문서의 표현 차이를 메우는 가장 안전한 방식입니다.
Gemini 3.1 Flash Live가 아닌 다른 선택이 더 나은 경우
실시간 음성이 핵심이 아니라면 Live API는 과합니다.
WebSocket, PCM, 인터럽트, ephemeral token은 voice-first 제품일 때만 가치가 큽니다.
현재 2.5 시스템이 async tools에 크게 의존한다면 3.1은 아직 이르다.
음성 품질 향상이 전체 사용자 경험 개선과 같은 뜻은 아닙니다.
ephemeral token을 안전하게 발급할 수 없다면 브라우저 직결을 서두르지 말 것.
그 경우 Live 세션을 백엔드에 두는 편이 훨씬 낫습니다.
필요한 것이 단순 TTS라면 대화형 Live 모델은 과하다.
Gemini 3.1 Flash Live는 대화, 도구, 인터럽트, 멀티모달 입력을 위한 모델입니다.

FAQ
정확한 모델 ID는?
gemini-3.1-flash-live-preview 입니다.
이미 GA인가?
아닙니다. 2026년 3월 기준 preview입니다.
Tools와 Google Search를 지원하나?
지원합니다. 다만 function calling은 현재 동기 방식만 가능합니다.
브라우저에서 직접 연결 가능한가?
가능합니다. 다만 백엔드에서 ephemeral token을 발급한 뒤 연결하는 것이 권장 경로입니다.
세션은 얼마나 오래 유지되나?
오디오 전용은 15분, 오디오 + 비디오는 2분입니다. 더 길게 쓰려면 session management를 추가해야 합니다.
응답은 텍스트도 주나, 오디오만 주나?
공개 문서의 표현은 조금 갈리지만, 구현 기준으로는 AUDIO response modality를 기본으로 두고, 읽을 텍스트는 transcription으로 처리하는 것이 가장 안전합니다.
생성된 오디오에 워터마크가 들어가나?
들어갑니다. 공식 발표는 SynthID watermark를 명시합니다.
마이그레이션 규칙을 한 문장으로 요약하면?
새 음성 에이전트는 3.1부터 시작하되, 기존 2.5 시스템이 async tools, proactive audio, affective dialog에 의존한다면 먼저 그 비용을 계산한 뒤 옮기면 됩니다.