
지금 당장 모델이 필요하다면 먼저 GPT-5.4를 쓰는 편이 맞습니다. Claude Mythos Preview는 Anthropic이 공개한 여러 벤치마크에서 강하게 보이지만, 현재 기준으로는 초대받은 참여자에게만 열려 있는 research preview이지, 이 글을 읽고 바로 전환할 수 있는 일반 공개 모델은 아닙니다.
2026년 4월 9일 기준으로 OpenAI는 GPT-5.4가 ChatGPT, API, Codex 전반에서 사용 가능하다고 밝히고 있습니다. 반면 Anthropic은 Mythos Preview를 Project Glasswing 파트너와 기타 초대 조직에 제한하고 있습니다. 그래서 이 글이 먼저 답해야 하는 것은 벤치마크 승패가 아니라 지금 어떤 경로를 써야 하는가입니다. 대부분의 독자에게는 지금 GPT-5.4를 계속 쓰는 것이 맞고, Mythos는 이미 preview 대상 안에 있거나 future-tier evals를 맡고 있을 때만 진지하게 계획에 넣으면 됩니다.
빠른 답
제목만 보면 흔한 "누가 더 강하냐" 비교처럼 보일 수 있지만, 실제로 유용한 답은 훨씬 더 좁습니다.
| 당신의 진짜 질문 | 지금 해야 할 일 | 이유 |
|---|---|---|
| "오늘 바로 쓸 수 있는 모델은 뭐지?" | GPT-5.4 | ChatGPT, API, Codex에서 이미 사용할 수 있습니다. |
| "Mythos Preview는 누구나 살 수 있는 공개 대안인가?" | 아니오 | Anthropic은 여전히 초대제 research preview로 설명합니다. |
| "Mythos 때문에 지금의 GPT-5.4 선택을 바꿔야 하나?" | 대체로 아니다 | 벤치마크 우위만으로 접근성 격차가 사라지지 않습니다. |
| "그럼 Mythos는 언제부터 의미가 커지나?" | 이미 초대받았거나 future-tier evals를 돌릴 때 | 그때 비로소 벤치마크 신호가 실무적 판단으로 이어집니다. |
여기서 가장 자주 틀어지는 지점은 "양쪽 모두 진짜 사실을 공개한다"는 것과 "양쪽이 같은 종류의 계약을 공개한다"는 것을 같은 말로 다루는 것입니다. Anthropic은 Mythos Preview의 participant pricing과 강한 런치 벤치마크를 실제로 공개했습니다. OpenAI도 GPT-5.4의 공개 가용성과 공개 가격을 실제로 공개했습니다. 문제는 어느 쪽이 가짜냐가 아니라, 둘이 같은 층위의 계약이 아니라는 점입니다. 한쪽은 닫힌 preview이고, 다른 한쪽은 지금 바로 쓸 수 있는 공개 경로입니다.
Claude Mythos Preview는 지금 어떤 계약인가
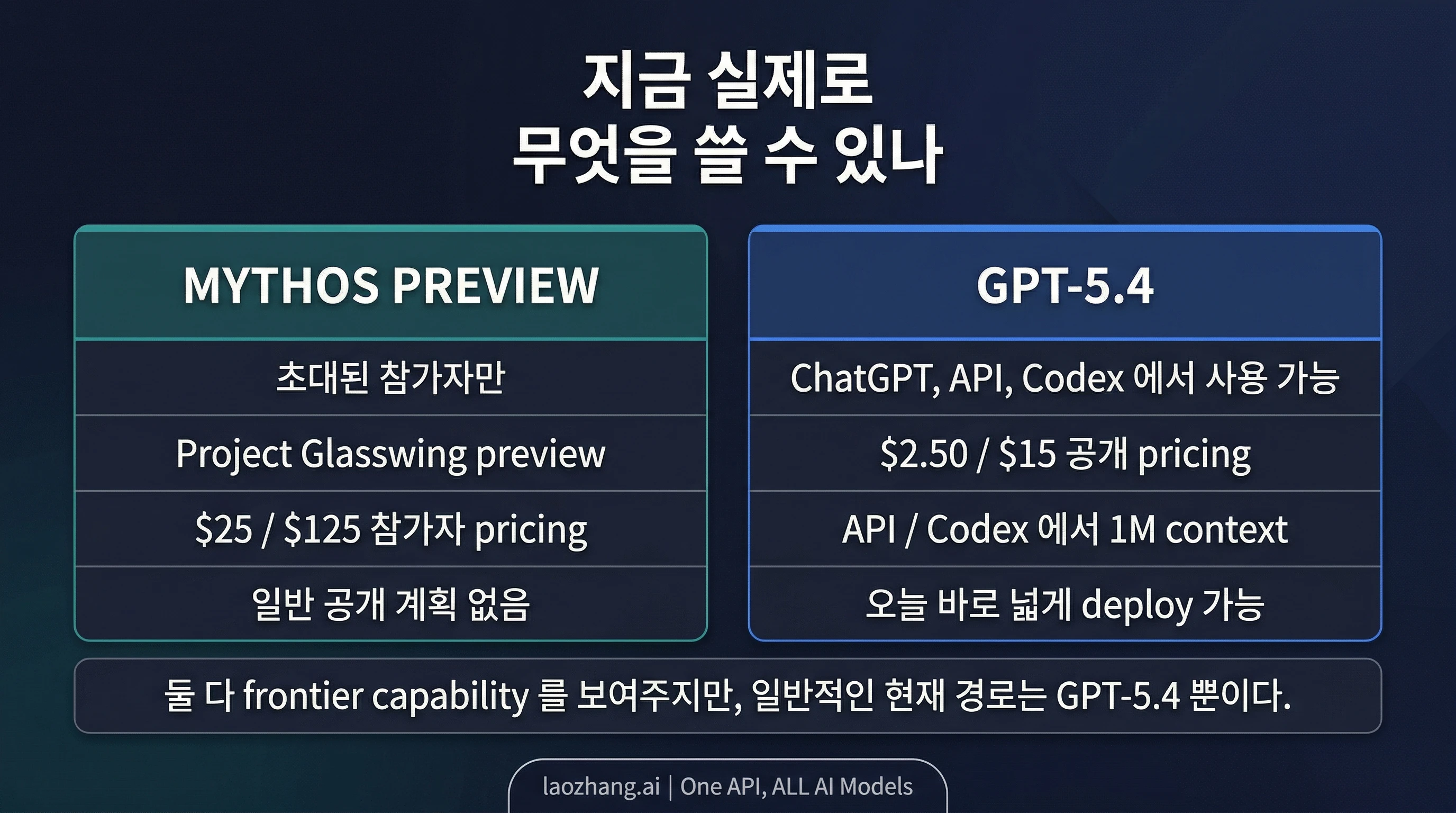
Claude Mythos Preview는 실재하지만 일반적인 공개 모델 계약은 아닙니다. Anthropic은 현재 Project Glasswing 파트너와 중요 인프라 및 보안 영역의 40개가 넘는 초대 조직에 접근을 제공한다고 설명합니다. 이 사실만으로도 Mythos를 가볍게 볼 수는 없습니다. 하지만 그렇다고 해서 대부분의 독자가 이 글을 읽고 곧바로 도입 가능한 옵션으로 다뤄도 되는 것은 아닙니다.
가격도 같은 경계를 확인해 줍니다. Anthropic은 초기 usage credits 기간 이후 입력 백만 토큰당 25달러, 출력 백만 토큰당 125달러라는 participant pricing을 제시합니다. 이 숫자는 이미 preview 대상 안에 있는 사람에게는 의미가 있습니다. 하지만 접근 권한 자체를 먼저 넘어야 하므로, GPT-5.4 API 가격처럼 오늘의 예산과 배포 판단에 바로 넣을 수 있는 공개 조달 조건과는 다릅니다.
더 중요한 점은 Anthropic이 2026년 4월 9일 기준으로 Claude Mythos Preview를 일반 공개할 계획이 현재 없다고 적고 있다는 사실입니다. 이것이 앞으로 Mythos급 공개 모델이 영원히 나오지 않는다는 뜻은 아닙니다. 다만 지금 시점의 판단에서는 Mythos Preview를 "곧 누구나 고를 수 있는 메뉴"처럼 다루면 안 된다는 뜻입니다.
그래서 가장 안정적인 해석은 이렇습니다. Mythos Preview는 frontier capability를 보여 주는 신호이지, 오늘의 기본 경로가 아닙니다. Anthropic의 상위권 능력이 더 올라갔을 수 있다는 점은 중요합니다. 하지만 그 사실만으로 오늘 실제로 배포할 모델 선택이 GPT-5.4에서 Mythos로 바뀌지는 않습니다.
GPT-5.4가 오늘 주는 것
GPT-5.4는 완전히 다른 종류의 객체입니다. OpenAI는 2026년 3월 5일 GPT-5.4를 발표했고, ChatGPT, API, Codex 전반에서 사용할 수 있다고 안내했습니다. 이 비교에서 가용성은 부수 정보가 아니라 답 자체의 일부입니다. 대부분의 독자가 정말 해결해야 하는 문제는 어떤 연구소가 더 인상적인가가 아니라, 오늘 어떤 경로를 실제 업무에 붙일 수 있는가이기 때문입니다.
가격 구조도 곧바로 의사결정에 넣기 쉬운 형태입니다. OpenAI는 입력 백만 토큰당 2.50달러, 캐시 입력 백만 토큰당 0.25달러, 출력 백만 토큰당 15달러를 제시합니다. 긴 컨텍스트 워크플로를 위해서는 API와 Codex에서 최대 1M 토큰 컨텍스트를 지원한다고 설명합니다. 즉 현재 GPT-5.4 계약은 오늘 바로 예산을 세우고, 테스트하고, 도입하고, 문서화할 수 있는 공개 경로입니다.
그래서 Anthropic의 벤치마크 이야기를 그대로 인정하더라도, GPT-5.4가 대부분의 사람에게는 여전히 실전 기본값으로 남습니다. 기본 경로란 미래감이 강한 모델이 아니라, 이번 주 실제 일을 흘려보낼 수 있는 모델입니다. 다음 질문이 GPT-5.4의 접근 경로와 비용 구조라면 GPT-5.4 free API 가이드가 더 직접적입니다. Codex 중심 자동화가 중요하다면 2026년 3월 OpenAI Codex 업데이트가 더 실무적인 다음 읽을거리입니다.
이 비교를 추상적인 "모델 품질" 이야기로만 축소하면 안 되는 이유도 여기에 있습니다. 대부분의 독자에게 실제 판단면은 "어느 연구소가 더 멋져 보이나"가 아니라, "닫힌 preview에 이미 들어가 있는 척하지 않고 오늘 쓸 수 있는 경로가 무엇인가"입니다.
공식으로 겹치는 벤치마크가 말해 주는 것과 말해 주지 않는 것
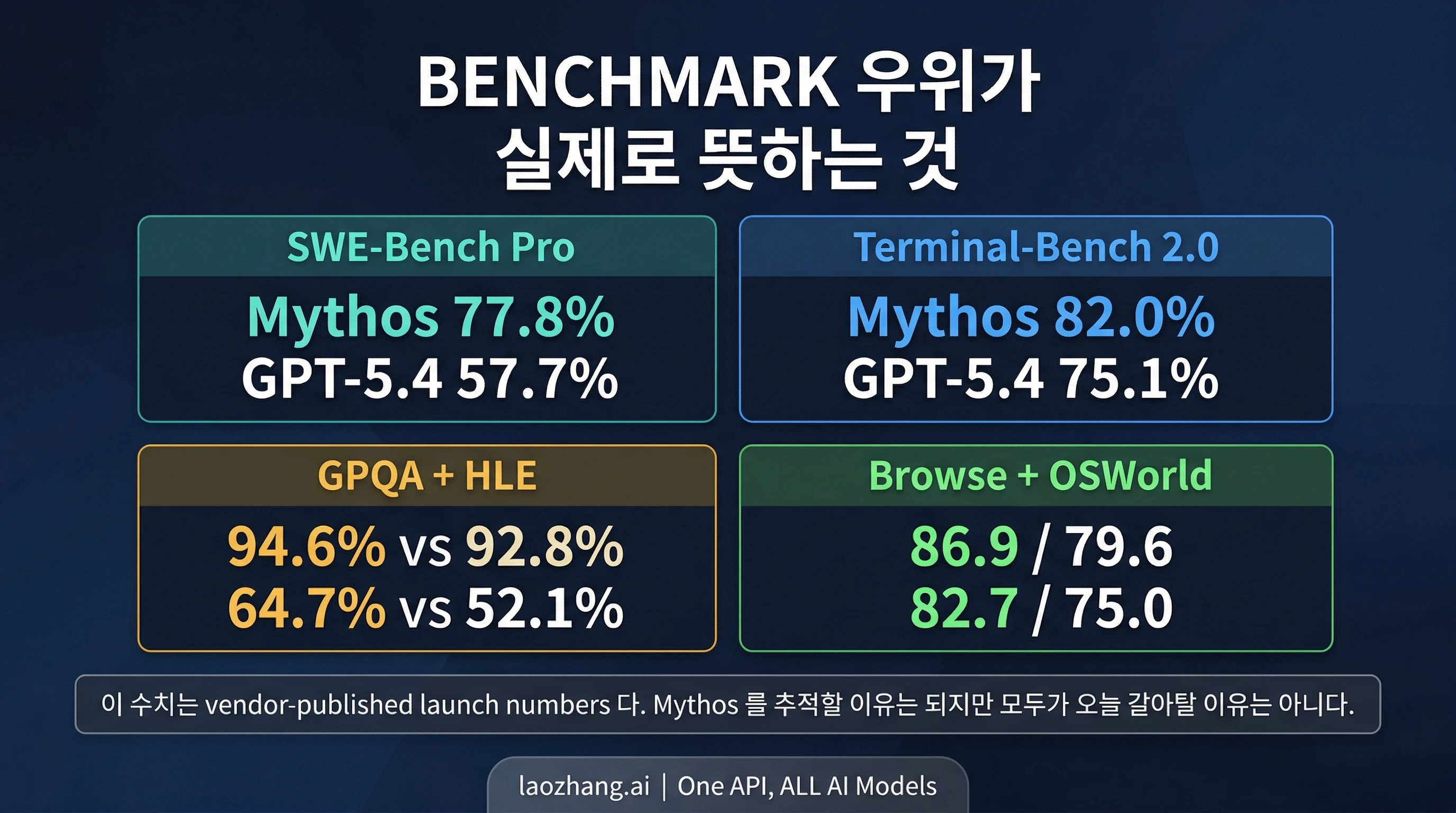
Mythos Preview가 여러 겹치는 평가 이름에서 공식적으로 앞서는 것은 사실입니다. Anthropic의 Project Glasswing 페이지에는 Mythos Preview의 SWE-Bench Pro 77.8%, Terminal-Bench 2.0 82.0%, SWE-Bench Verified 93.9%, GPQA Diamond 94.6%, Humanity's Last Exam with tools 64.7%, BrowseComp 86.9%, OSWorld-Verified 79.6%가 제시되어 있습니다. OpenAI의 GPT-5.4 런치 페이지에는 SWE-Bench Pro 57.7%, Terminal-Bench 2.0 75.1%, GPQA Diamond 92.8%, Humanity's Last Exam with tools 52.1%, BrowseComp 82.7%, OSWorld-Verified 75.0%가 제시되어 있습니다.
이 수치 덕분에 Mythos는 실제로 추적할 가치가 생깁니다. 만약 Anthropic이 눈에 띄는 공적 우위를 보여 주지 못한 닫힌 preview만 내놨다면, 실용적인 조언은 거의 달라지지 않았을 것이고 이 페이지도 이렇게까지 필요하지 않았을 것입니다. 그러니 Mythos를 단순한 유출 소문이나 hype로 치부하는 것은 맞지 않습니다.
하지만 이 표가 중립적이고 보편적인 절대 승자를 주는 것은 아닙니다. Anthropic과 OpenAI는 각각 자기 공식 런치 표면에서 숫자를 공개하고 있습니다. 겹치는 평가 이름은 참고 가치가 충분하지만, 여전히 vendor-published launch numbers이지, 동일한 설정과 도구, 예산으로 돌린 하나의 공통 점수판은 아닙니다. 따라서 올바른 해석은 "Mythos의 우위는 무시할 수 없을 만큼 실제적이다"이지, "Mythos가 GPT-5.4를 모든 현재 구매 결정에서 완전히 대체했다"가 아닙니다.
이 경계는 글쓰기용 안전장치가 아니라 실제 경로 판단을 바꾸는 핵심입니다. 벤치마크 우위는 top-tier coding, reasoning, security-adjacent evals를 추적하는 사람에게 Mythos를 watchlist에 올릴 이유를 줍니다. 그러나 그것만으로 지금 실제로 접근하고 배포할 수 있는 모델을 버려야 한다는 뜻은 아닙니다.
Mythos가 정말로 계획을 바꿔야 하는 때

대부분의 독자에게 Mythos는 현재 계획을 바꿔야 할 이유가 아닙니다. 오늘 모델이 필요하다면 답은 여전히 GPT-5.4입니다. 접근성, 가격, 배포라는 현재형 판단의 문턱을 GPT-5.4는 이미 넘었기 때문입니다. 미래형 preview 계약이 매력적으로 보인다는 이유만으로 실제 작업 경로를 대기 모드로 바꾸는 것은 보통 좋은 선택이 아닙니다.
반대로 더 이른 시점부터 Mythos가 중요해지는 독자도 있습니다. 이미 preview 대상 안에 있다면 이 비교는 더 이상 추상적이지 않습니다. 그때는 Mythos가 자신의 워크로드에서 충분한 개선을 보여 주는지, 평가 비용과 워크플로 조정, 향후 마이그레이션 준비를 감수할 가치가 있는지 실제로 따져야 합니다. frontier-model watchlist나 security 평가 체계, 상위 코딩 시스템 에스컬레이션 경로를 관리하는 사람에게도 Mythos는 단순한 뉴스가 아니라 미래 상위 티어를 준비해야 하는 신호입니다.
그 외의 많은 사람에게 Mythos는 "지금 갈 곳"이 아니라 "계속 지켜볼 대상"으로 다루는 편이 가장 안정적입니다. 지금 가능한 GPT-5.4 업무를 계속 진행하고, 비교용 기준선을 유지하며, 접근 경계가 바뀌거나 조직이 preview 권한을 받았을 때만 추가 비용을 쓰는 것이 보통 더 낫습니다.
이 페이지보다 더 넓은 질문이라면
이 페이지는 "GPT-5.4가 오늘 이미 사용 가능한 상황에서, Mythos의 벤치마크 우위가 지금의 선택을 바꿔야 하느냐"라는 좁은 질문에 가장 잘 답합니다.
만약 실제 질문이 "공개적으로 쓸 수 있는 ChatGPT와 Claude 중 무엇을 골라야 하느냐"라면, 다음으로 읽어야 할 글은 ChatGPT vs Claude입니다. 그 글은 public-vs-public 선택을 중심으로 코딩, 글쓰기, 가격, 전체 제품 차이를 더 넓게 다룹니다.
만약 실제 질문이 "Anthropic 내부에서 지금 shipping 중인 모델을 써야 하나, 아니면 preview tier를 계속 추적해야 하나"라면, Claude Capybara vs Opus 4.6가 더 맞습니다. 그 글은 Anthropic 내부 경계에 초점을 맞춘 페이지입니다.
밖으로 라우팅하는 것은 주제를 피하기 위해서가 아닙니다. 오히려 이 페이지를 유용하게 유지하기 위한 장치입니다. Mythos의 벤치마크 우위는 실제이지만, preview 안에 들어가 있지 않다면 GPT-5.4가 지금의 deployable default라는 좁은 답에 집중할수록 이 글은 더 강해집니다。
FAQ
"Claude Mythos"와 Claude Mythos Preview는 같은 뜻인가요
현재 공개 문맥에서 "Claude Mythos"는 공식 이름인 Claude Mythos Preview의 줄임말처럼 쓰이는 경우가 많습니다. 중요한 것은 줄임말이냐 정식명이냐가 아니라, Anthropic이 이를 공개 self-serve 제품이 아니라 닫힌 preview로 다룬다는 점입니다.
Mythos participant pricing이 있으면 GPT-5.4의 정상적인 대안이 되나요
아닙니다. participant pricing 자체는 실제로 존재하지만, 닫힌 preview 계약에 묶여 있습니다. GPT-5.4 가격은 오늘 바로 구매하고 배포할 수 있는 공개 경로에 묶여 있습니다. 두 조건은 같은 조달 조건이 아닙니다.
그렇다면 Mythos가 GPT-5.4를 "전반적으로 이긴다"고 말할 수 있나요
더 정확한 표현은, Mythos가 여러 겹치는 vendor-published launch benchmarks에서 앞선다는 것입니다. 그것은 모든 워크플로, 도구 조건, 지연 조건, 접근 조건에서 무조건적인 종합 승자임을 증명한 것과는 다릅니다.
공개 모델끼리의 선택이 진짜 질문이라면 Opus 쪽을 봐야 하나요
네. 실제 선택이 지금 공개적으로 쓸 수 있는 모델들 사이에서 이루어진다면, cross-platform 비교는 ChatGPT vs Claude, Anthropic 내부 비교는 Claude Capybara vs Opus 4.6를 보는 편이 더 정확합니다.
마지막으로 한 문장으로 정리하면요
Mythos의 벤치마크 우위는 충분히 추적할 가치가 있습니다. 하지만 그것만으로 대부분의 사용자가 오늘 선택해야 할 기본 경로에서 GPT-5.4를 밀어낼 정도는 아닙니다. 오늘 모델이 필요하다면 GPT-5.4를 쓰고, 이미 preview 안에 있거나 future-tier evals를 담당할 때만 Mythos를 더 좁고 현실적인 맥락에서 본격 평가하면 됩니다.