
지금 Brave Search API를 쓰려면 먼저 Search와 Answers 중 어디서 시작할지 정해야 합니다. Search는 원시 웹 결과, LLM Context를 통한 grounding, 또는 Place Search 같은 전용 endpoint를 사용하면서도 애플리케이션 로직과 모델 레이어를 계속 직접 쥐고 싶을 때 더 자연스러운 기본값입니다. Answers는 Brave가 OpenAI 호환 인터페이스를 통해 근거 있는 최종 답변까지 반환해 주길 원할 때 더 자연스럽습니다.
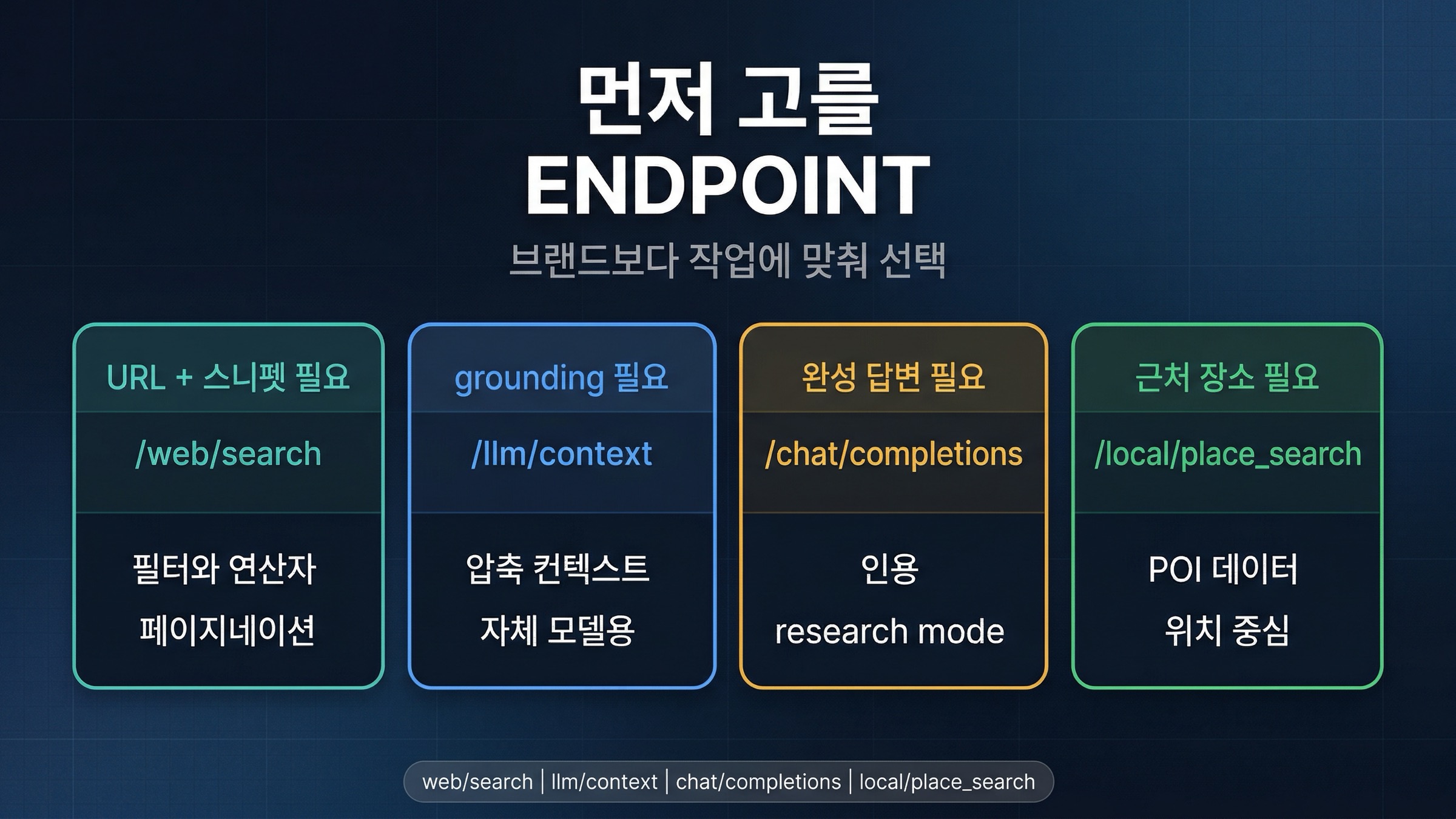
Brave Search API는 하나의 "만능 endpoint"가 아닙니다. 2026년의 Brave Search API는 작은 라우트 맵에 가깝습니다. Search는 검색 substrate, Answers는 완성된 grounded output, LLM Context는 자체 모델을 유지하면서 Brave의 grounding 레이어만 빌리고 싶을 때의 경로, Place Search는 대상이 웹페이지가 아니라 실제 장소일 때의 경로입니다.
신선도 메모: 2026년 4월 1일 기준으로 Brave의 공개 랜딩 페이지, 가격 페이지, 인증 문서, Search 문서, Answers 문서, Place Search 문서, 그리고 2026년 2월 12일의 Brave 공식 블로그 글을 다시 확인했습니다.
TL;DR
가장 짧고 안전한 결론은 아래와 같습니다.
| 당신의 실제 작업 | 여기서 시작 | 이유 | 가장 큰 주의점 |
|---|---|---|---|
| 원시 검색 결과, snippets, pagination, filters, 직접적인 검색 제어가 필요하다 | Search plan + /res/v1/web/search | 이것이 핵심 검색 substrate이기 때문 | ranking, 결과 처리, answer layer는 여전히 직접 가져가야 한다 |
| 자체 모델이나 agent에 grounding이 필요하다 | Search plan + /res/v1/llm/context | Brave가 모델 소비에 더 맞는 형태로 문맥을 압축해 준다 | 이것은 여전히 substrate이지 완성 답변 API가 아니다 |
| Brave가 grounded answer를 직접 반환하길 원한다 | Answers plan + /res/v1/chat/completions | OpenAI 호환 경로이고 citations, entities, research mode를 지원한다 | 고급 메타데이터 기능은 streaming이 필요하고 기본 throughput도 낮다 |
| 주변 상점, 랜드마크, POI가 필요하다 | Search plan + /res/v1/local/place_search | 여기서는 웹페이지가 아니라 장소가 검색 대상이다 | 기본 Web Search에 억지로 태우지 않는 편이 낫다 |
| 오래된 Summarizer 튜토리얼을 봤다 | 거기서 시작하지 말 것 | Brave는 Summarizer를 deprecated로 두고 새로운 흐름은 Answers로 옮기고 있다 | legacy Pro AI 사용자에게는 남아 있어도 신규 기본 경로는 아니다 |
가장 간단한 규칙은 하나입니다. 모델 레이어를 직접 갖고 싶다면 Search, 완성 답변까지 Brave에 맡기고 싶다면 Answers입니다.
지금의 Brave Search API는 무엇인가
가장 쉽게 헷갈리는 방식은 Brave Search API를 하나의 endpoint에 기능이 많이 붙은 제품으로 보는 것입니다. 지금의 공개 계약은 훨씬 더 명확합니다. Brave의 현재 pricing page는 가장 중요한 두 개의 주 경로를 Search와 Answers로 나눕니다.
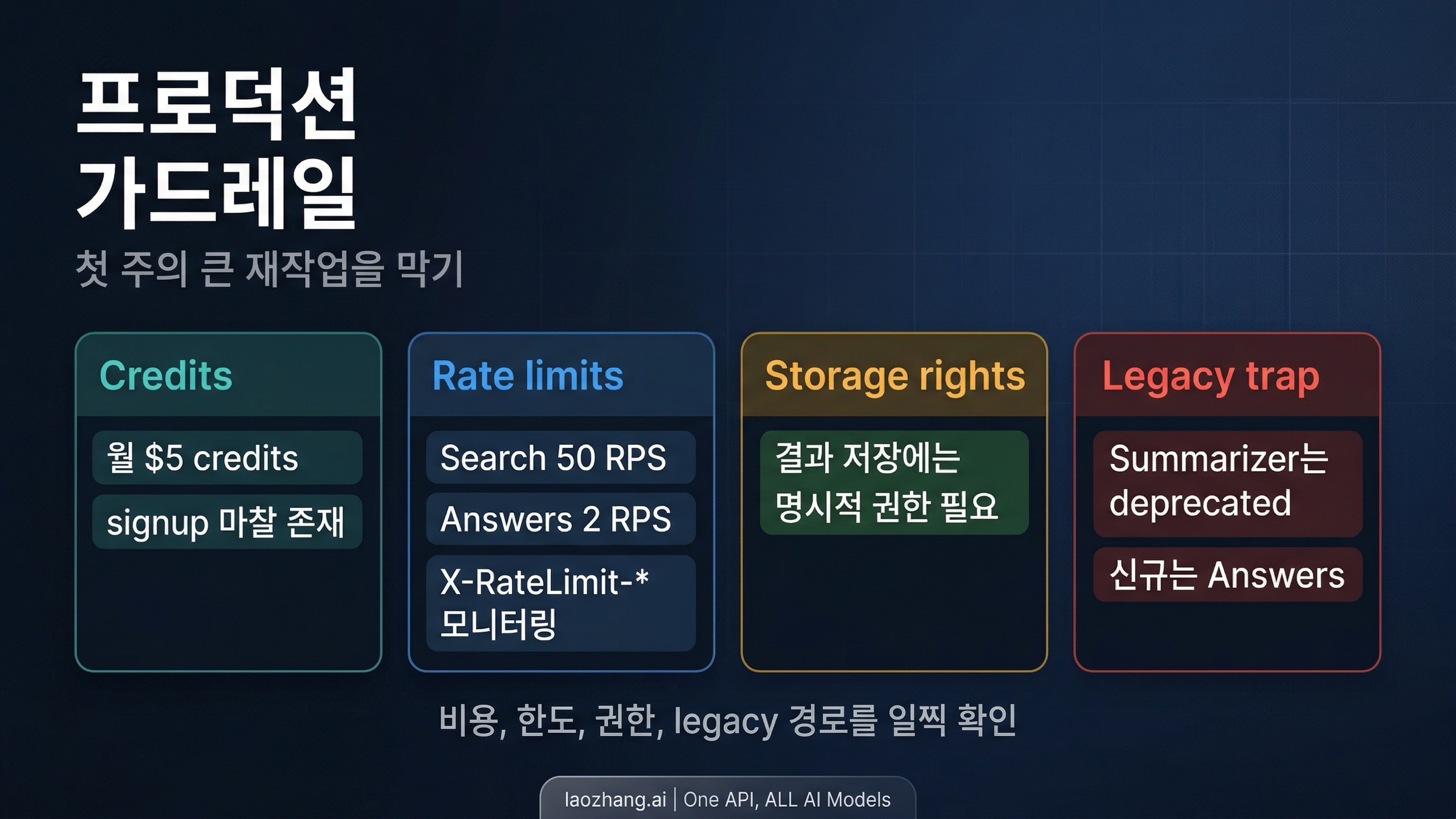
Search는 substrate plan입니다. agents, chatbots, 검색 제품, retrieval 시스템이 실제로 필요로 하는 검색 데이터를 제공합니다. Web Search, LLM Context, News Search, Video Search, Image Search, 그리고 새로 추가된 Place Search가 여기에 포함됩니다. 현재 공개 가격은 1,000 requests당 5달러, 월 5달러 credits, 기본 용량은 50 requests per second입니다. 랜딩 페이지도 이것을 "chatbots와 agents가 answers를 만들기 위해 필요한 real-time search data"로 설명합니다. 이 framing은 꽤 정확합니다. 여기서 얻는 것은 검색 레이어이지, 완성 애플리케이션이 아닙니다.
Answers는 완성 답변 plan입니다. Brave의 검색 인프라 위에서 동작하며 OpenAI 호환 인터페이스로 grounded AI answers를 반환합니다. 현재 공개 가격은 1,000 queries당 4달러에 더해 1M input tokens당 5달러, 1M output tokens당 5달러, 그리고 월 5달러 credits, 기본 용량은 2 requests per second입니다. 이 더 낮은 throughput은 우연이 아니라 Brave가 더 많은 애플리케이션 레이어 작업을 대신하기 때문입니다.
그리고 두 가지 사실은 꼭 앞쪽에 있어야 합니다. 첫째, Summarizer Search는 현재 deprecated이며 Brave는 Answers를 후속 기본 경로로 밀고 있습니다. docs에는 종료된 Pro AI plan 사용자를 위해 남아 있지만, 이는 호환성 때문이지 신규 프로젝트의 추천이 아닙니다. 둘째, Brave Search API는 Google이나 Bing 위의 scraper가 아닙니다. Brave는 이를 300억 개 이상의 페이지와 하루 1억 개 이상의 페이지 업데이트를 가진 독립 인덱스로 설명합니다. 이 제품을 진지하게 평가한다면, 이 독립 인덱스 사실이 대부분의 benchmark 문구보다 더 중요합니다.
브랜드보다 계약을 먼저 고르기
여기서 가장 중요한 판단은 처음부터 잘못된 레이어를 고르지 않는 것입니다.
고전적인 검색 substrate가 필요하다면 **/res/v1/web/search**에서 시작해야 합니다. URL, snippets, pagination, search operators, filters가 필요하고, 그 결과를 자기 시스템이 다시 처리할 계획일 때 적합합니다. 이 endpoint는 말 그대로 검색 인프라처럼 동작합니다. 검색 결과를 받고, 그다음에 무엇을 할지는 당신의 시스템이 정합니다.
자체 모델이나 agent를 위한 grounding이 필요하다면 **/res/v1/llm/context**가 더 자연스럽습니다. 2026년 2월 개편에서 Brave는 LLM Context를 문서 깊숙한 기능이 아니라 공개 1급 경로로 끌어올렸습니다. Brave는 이를 data-first ranking path라고 설명하며, 웹에서 가장 관련 있는 조각을 모델이 소비하기 쉬운 형태로 압축해 준다고 말합니다. 즉, 단순히 "이름만 다른 검색"이 아닙니다. 진짜 가치는 모델 레이어는 직접 유지하면서 retrieval output만 더 모델 친화적인 형태로 받는 데 있습니다.
완성된 grounded answer를 빠르게 받고 싶다면 Answers에서 시작하세요. answer synthesis를 직접 들고 가고 싶지 않거나, citations가 붙은 answer engine을 가장 짧은 경로로 검증하고 싶을 때 더 적합합니다. docs는 이 기능을 OpenAI 호환 /res/v1/chat/completions와 model="brave"로 노출합니다. 이미 OpenAI client libraries를 쓰는 팀이라면 이 경로는 꽤 짧습니다.
대상이 현실의 장소라면, 특별한 이유가 없는 한 일반 Web Search에 먼저 우겨 넣지 않는 편이 낫습니다. Brave의 Place Search는 businesses, landmarks, hotels, museums, nearby discovery를 위해 설계되어 있습니다. 공개 docs는 이를 2억 개 이상의 places를 가진 인덱스로 설명하며, 구조화된 POI 데이터, 위치 인식 검색, 상세 조회용 endpoint를 제공합니다. 이것은 웹페이지 ranking과는 다른 workload입니다.
판단 기준은 하나면 충분합니다. answer layer를 누가 맡을지 먼저 정하세요. 답이 "내 애플리케이션"이라면 Search 안에 머물면서 Web Search, LLM Context, Place Search 중에서 고르면 됩니다. 답이 "Brave"라면 Answers를 쓰면 됩니다.
현재 가격, rate limit, 그리고 가장 자주 오해되는 부분
가격표 자체는 단순하지만, 실제 도입 판단에는 계약 조건까지 함께 봐야 합니다.
| Plan | 현재 공개 가격 | 월간 credits | 기본 용량 | 가장 잘 맞는 작업 |
|---|---|---|---|---|
| Search | $5 / 1,000 requests | $5 | 50 requests/sec | 검색 결과, grounding context, 뉴스, 이미지, 비디오, place search |
| Answers | $4 / 1,000 queries + $5 / 1M input tokens + $5 / 1M output tokens | $5 | 2 requests/sec | OpenAI 호환 chat completions를 통한 완성형 grounded answers |
핵심은 어느 plan이 "싸다" 혹은 "비싸다"가 아닙니다. 핵심은 Answers 가격에는 Brave가 애플리케이션 레이어의 일부를 대신 수행하는 비용이 포함되어 있다는 점입니다. 이미 model stack, retrieval layer, synthesis pipeline을 갖고 있다면 Search가 더 자연스러운 default일 가능성이 큽니다. 반대로 search-to-answer 점프 자체를 Brave에 맡기고 싶다면 token 비용이 추가되더라도 Answers가 더 깔끔합니다.
실무에서 먼저 걸리는 제약 하나는 signup 계약입니다. Brave의 현재 FAQ는 여전히 free plan 구독에 credit card가 필요하다고 말하며, 이는 anti-fraud 목적이고 카드가 free plan 때문에 청구되지는 않는다고 설명합니다. 동시에 현재 pricing page는 monthly credits가 포함된 유료 plan처럼 서술합니다. 가장 안전한 운영적 해석은 이렇습니다. monthly credits는 있지만 onboarding을 no-card public sandbox처럼 생각하지는 말 것.
또 두 가지 제약이 실제 운영에 바로 영향을 줍니다. Brave의 rate-limiting docs는 제한이 1초 sliding window로 계산되며, 응답에 X-RateLimit-* headers가 포함된다고 말합니다. 진짜 운영하려는 팀이라면 첫 429가 나온 다음에야 볼 정보가 아닙니다. 그리고 Brave는 결과를 전체 또는 일부라도 저장하려면, 특히 LLM training이나 tuning에 쓰려면, 명시적인 storage rights가 포함된 plan이 필요하다고 적어 두고 있습니다. 이런 조건은 아키텍처를 확정한 뒤에 발견하고 싶지 않은 종류입니다.
엔터프라이즈 관점에서는 공개 페이지가 SOC 2 Type II와 Zero Data Retention 경로도 제시합니다. 프라이버시나 규제 대응이 구매 논리에 포함된다면 실제 차별점이 됩니다. 아직 prototype 단계라면, 이 계약이 장난감 수준만을 위한 것은 아니라는 정도를 이해하면 충분합니다.
첫 번째 작동 요청: 일반 검색인가, 모델용 컨텍스트인가
Search 쪽을 먼저 검증하고 싶다면 가장 짧은 길은 X-Subscription-Token 헤더를 넣은 기본 Web Search 요청입니다.
jsconst query = new URLSearchParams({ q: "best open source vector database for hybrid search", count: "10", country: "US", search_lang: "en", extra_snippets: "true", }); const response = await fetch( `https://api.search.brave.com/res/v1/web/search?${query}`, { headers: { Accept: "application/json", "Accept-Encoding": "gzip", "X-Subscription-Token": process.env.BRAVE_API_KEY, }, }, ); const data = await response.json(); console.log(data.web?.results?.[0]); console.log(data.query?.more_results_available);
이 기본 Web Search 요청을 보내 보면 검색 레이어가 어떤 형식으로 돌아오는지 바로 확인할 수 있습니다. 결과를 받은 뒤 더 볼 페이지가 있는지 판단하고, 계속 넘길지 아니면 현재 결과를 자기 downstream 로직으로 넘길지 결정하면 됩니다. Brave의 Web Search docs는 몇 가지 고가치 손잡이도 분명히 알려 줍니다. extra_snippets=true로 결과당 최대 5개의 추가 발췌를 받을 수 있고, search operators는 별도 파라미터가 아니라 q 안에 넣으며, pagination은 무한하지 않기 때문에 offset을 무작정 늘리기보다 more_results_available를 먼저 보는 편이 낫다는 점입니다.
만약 실제 workload가 압축된 grounding을 필요로 하는 모델이나 agent라면, Search 쪽 첫 검증으로는 LLM Context가 더 나은 default인 경우가 많습니다.
bashcurl -s --compressed \ "https://api.search.brave.com/res/v1/llm/context?q=best+open+source+vector+database+for+hybrid+search" \ -H "Accept: application/json" \ -H "Accept-Encoding: gzip" \ -H "X-Subscription-Token: $BRAVE_API_KEY"
차이는 출력 형식에 있습니다. Web Search는 검색 결과용 API라서 여전히 URL과 snippets 중심입니다. LLM Context는 grounding을 위해 설계된 응답입니다. 다음 단계가 자체 모델, coding agent, reasoning pipeline으로 넘기는 일이라면 일반 Web Search보다 더 자연스러운 출발점이 됩니다. Brave의 2026년 2월 공개 자료도 이 역할 구분에 맞춰 설명합니다.

OpenAI SDK로 Brave Answers를 시험하기
원하는 것이 retrieval substrate가 아니라 완성된 grounded answer라면, 가장 짧은 검증 경로는 OpenAI client를 통해 Answers endpoint를 호출하는 것입니다.
pythonimport asyncio from openai import AsyncOpenAI client = AsyncOpenAI( api_key="YOUR_BRAVE_SEARCH_API_KEY", base_url="https://api.search.brave.com/res/v1", ) async def main(): stream = await client.chat.completions.create( model="brave", stream=True, messages=[ { "role": "user", "content": "Compare Brave Search API Search vs Answers for an internal research assistant", } ], extra_body={ "country": "us", "language": "en", "enable_citations": True, "enable_research": False, }, ) async for chunk in stream: if chunk.choices and chunk.choices[0].delta.content: print(chunk.choices[0].delta.content, end="", flush=True) asyncio.run(main())
여기서 docs가 말하는 중요하지만 자주 놓치는 제약이 하나 있습니다. citations, entities, research mode는 모두 streaming이 필요합니다. 이것은 사소한 각주가 아닙니다. Answers는 일반 chat completion보다 더 풍부한 응답 구조를 반환할 수 있기 때문입니다. Brave docs는 <citation>, <enum_item>, <usage> 같은 특수 태그까지 설명하고 있습니다. UX를 깔끔하게 만들고 monitoring을 신뢰할 수 있게 유지하려면 실제로 이를 파싱하는 편이 좋습니다.
research mode 역시 아무 생각 없이 default로 켜면 안 됩니다. Brave는 기본 single-search mode가 속도를 위해 최적화되어 있고 보통 4.5초 이하에서 스트리밍을 시작한다고 설명합니다. 반면 research mode는 여러 번의 검색을 수행할 수 있고, 복잡한 질문에서는 몇 분까지 이어질 수 있습니다. 즉, 이것은 background task 성격의 옵션이지, 무조건 "더 좋은" 기본값이 아닙니다. interactive latency가 중요한 제품이라면, 더 비싼 비용과 더 긴 시간을 정당화할 명확한 이유가 생기기 전까지는 기본 모드에 머무는 편이 낫습니다.
Brave가 단순한 검색 wrapper보다 더 흥미로운 이유
Brave는 그저 또 하나의 search box로 볼 때보다, 내가 조종할 수 있는 search infrastructure로 볼 때 훨씬 흥미롭습니다.
첫 번째 차별점은 인덱스 자체입니다. Brave의 공개 자료는 반복해서 이것이 independent index이지 Google이나 Bing 위의 scrape-and-repackage 레이어가 아니라고 말합니다. 이 주장은 그것이 실제로 만들 수 있는 제품을 바꿀 때만 의미가 있는데, 실제로 바꿉니다. Brave는 독립 인덱스를 Goggles 같은 reranking / filtering 기능, 결과당 더 많은 문맥을 주는 extra snippets, 그리고 리뷰나 위키 같은 구조화된 객체를 다루는 schema-enriched results와 결합합니다. 이런 요소는 추상적인 마케팅 bullet이 아니라, agent나 검색 workflow가 반복적으로 같은 retrieval blind spot에 부딪힐 때 실제로 필요한 제어 장치입니다.
두 번째 차별점은 Brave가 이제 substrate layer와 answer layer를 둘 다 공개한다는 점입니다. 많은 검색 관련 제품은 둘 중 하나만 고르게 만듭니다. Brave는 raw search results, 압축된 model-ready context, finished grounded answer 중 어디까지 가져갈지 스스로 정할 수 있게 합니다. 그래서 올바른 비교 질문은 종종 "Brave가 X보다 더 나은 answer engine인가?"가 아니라, "내 시스템이 answer layer를 얼마나 직접 가져가야 하는가?"입니다.
세 번째 차별점은 ecosystem fit입니다. Brave의 공식 tools page는 MCP Server와 LangChain, LlamaIndex, Dify, Flowise, Postman 등의 통합을 이미 공개하고 있습니다. 가장 빠른 평가 경로가 "오늘 안에 agent tool에 search를 꽂아 보는 것"이라면 이건 꽤 큰 장점입니다. 나중에 Brave의 native endpoints 위에 relay / gateway 레이어를 하나 더 두고 싶어진다면, 우리 OpenClaw API 가이드가 다루는 것은 바로 그 별개의 아키텍처 결정입니다.
마지막으로 Place Search를 한 번 더 언급해야 합니다. 아직도 Brave를 "웹 검색 + AI answers" 정도로만 다루는 글이 많지만, 지금은 실제로 쓸 만한 local-discovery 경로가 있습니다. 작업이 "어떤 좌표 근처 카페", "파리의 박물관"처럼 장소 자체를 대상으로 한다면, /local/place_search는 각주가 아니라 1급 제품 결정입니다.
첫 주를 가장 많이 낭비시키는 실수
Brave Search API 초기의 좌절은 희귀한 feature가 없어서가 아니라, 처음 전제를 하나 잘못 잡아서 생기는 경우가 많습니다.
- 새 프로젝트를 Summarizer Search에서 시작하는 것. Brave는 이미 deprecated라고 명시했고, 신규 흐름은 Answers 쪽으로 보냅니다. 오래된 튜토리얼이 남아 있어도 그걸 신규 기본값으로 삼으면 안 됩니다.
- grounding substrate만 필요할 때 Answers로 바로 점프하는 것. 이미 자체 모델 레이어가 있다면 Answers는 필요 이상으로 비싸고 덜 통제되는 계약이 될 수 있습니다.
- Answers의 rich output이 streaming에 의존한다는 점을 무시하는 것. citations, entities, research mode가 필요하다면 처음부터 streaming을 정상 경로로 설계해야 합니다.
- monthly credits를 friction 없는 public sandbox로 생각하는 것. 공개 페이지는 credits가 있어도 signup/card friction이 있음을 시사합니다. 못 쓴다는 뜻이 아니라, onboarding 비용을 현실적으로 계획해야 한다는 뜻입니다.
- rate-limit과 storage-rights 점검을 뒤로 미루는 것.
X-RateLimit-*headers와 명시적 storage-rights 제약은 첫 integration checklist에 들어가야 합니다. - local discovery를 일반 Web Search에 억지로 태우는 것. 대상이 business, landmark, nearby place라면 Place Search를 먼저 의심하는 편이 더 자연스럽습니다.
가장 짧고 가장 안전한 시작법
아직 어디서 시작할지 망설인다면 이 규칙 하나만 먼저 기억하면 됩니다. 통제가 필요하면 Search, 완성 답변이 필요하면 Answers입니다.
대부분의 엔지니어링 팀에게 가장 안전한 첫 평가 경로는 Search plan 안의 Web Search 또는 LLM Context입니다. 이 두 경로는 아키텍처를 정직하게 유지해 줍니다. 먼저 retrieval layer를 보고, 그다음 Brave를 substrate에 남길지, answer layer 쪽으로 더 올릴지 결정할 수 있습니다. 반대로 제품의 본질이 애초부터 "최소한의 통합으로 grounded answer를 반환하는 것"이라면, 돌아가지 말고 Answers에서 시작하는 편이 낫습니다.
피해야 할 것은 오래된 튜토리얼이나 가격만 나열한 요약이 판단을 대신하게 두는 일입니다. Brave의 현재 공개 계약은 이제 충분히 명확합니다. 다만 그것을 하나의 endpoint 이름으로 읽지 않고, 하나의 라우트 맵으로 읽을 때만 그렇습니다.