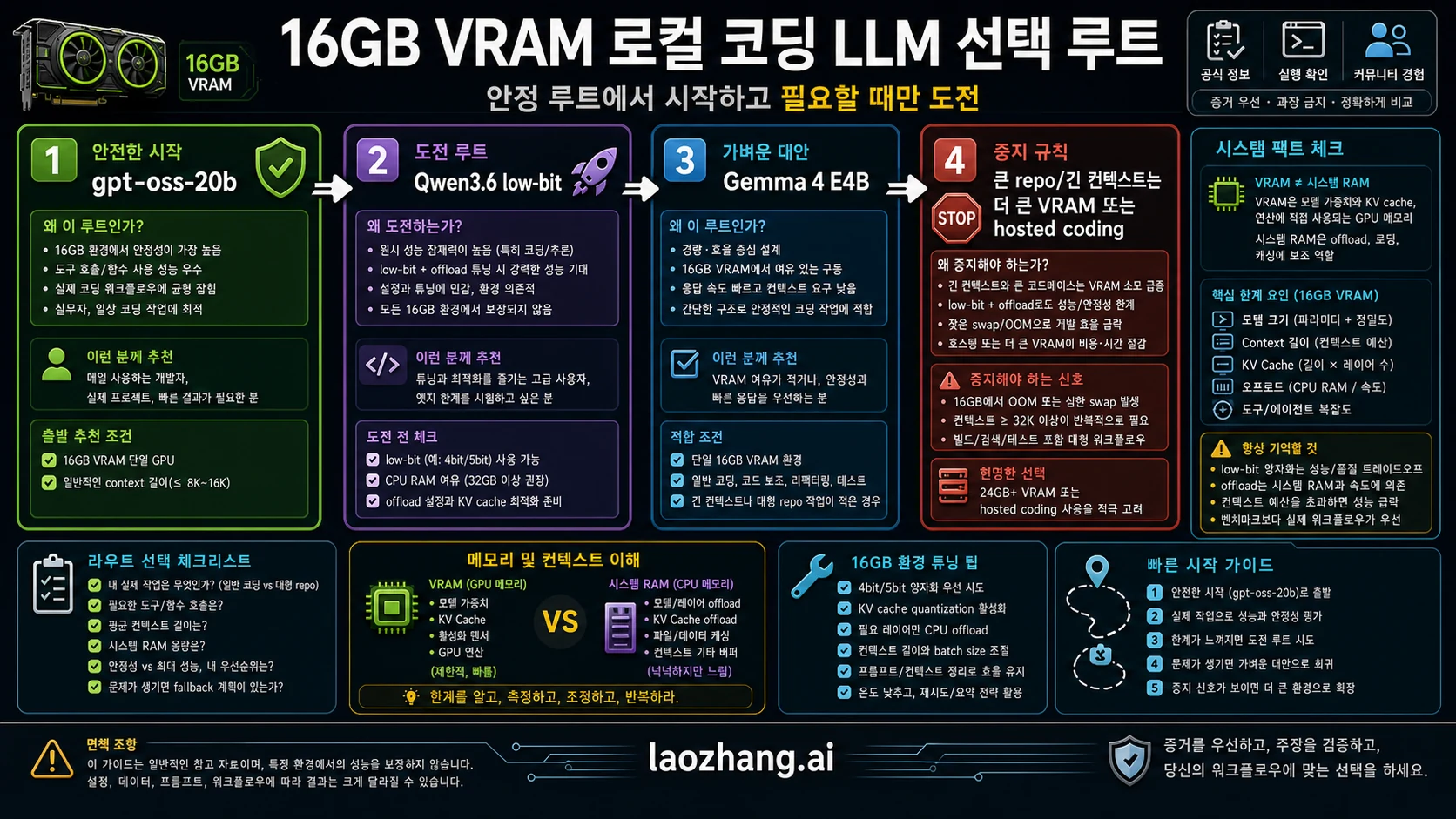
16GB VRAM에서 로컬 코딩 LLM을 고를 때 첫 질문은 “가장 강한 모델이 무엇인가”가 아니다. 먼저 안정적으로 쓸 경로를 정해야 한다. gpt-oss-20b는 기준 경로, Qwen3.6 35B A3B는 low-bit 또는 offload를 포함한 고급 실험, Gemma 4 E4B와 작은 코드 모델은 빠른 대안이다.
짧은 prompt에서 모델이 실행되는 것과 실제 저장소에서 코드를 고치는 것은 다르다. 코딩 작업은 모델 가중치뿐 아니라 KV cache, 파일 context, 테스트 정보, IDE 래퍼, 로컬 서버, 여러 번의 patch loop가 메모리와 시간을 함께 쓴다.
2026-07-03 기준으로 판단하면, 공식 설명과 runtime 페이지, 커뮤니티 실험을 분리해야 한다. 한국어권 공개 자료에는 Qwen3.6이나 Gemma4 계열까지 16GB 후보로 언급되지만, “실행 가능”과 “코딩 에이전트로 안정적”은 같은 말이 아니다.
실전 답은 단순하다. 먼저 gpt-oss-20b로 한 함수와 가까운 테스트를 고치는 smoke test를 한다. 품질이 부족할 때만 Qwen3.6 low-bit 경로를 짧은 context로 확인한다. 지연, OOM, context 손실이 반복되면 작은 모델, 더 큰 VRAM, hosted coding으로 전환한다.
빠른 결론: 모델 순위보다 경로가 먼저다
한국어권 공개 자료에는 Reddit 번역, Naver Blog, glukhov 벤치마크, 국내 커뮤니티, promptquorum류 모델 가이드가 함께 보인다. 일부 요약형 답변은 Qwen3.6-35B-A3B나 Gemma4-26B-A4B까지 언급하지만, 세부 조건은 부족하다.
그래서 첫 화면은 순위표가 아니라 결정표여야 한다. 무엇을 먼저 설치하고, 무엇을 실험하며, 어디에서 멈출지 정하는 표다.
| 경로 | 먼저 시도할 모델 | 16GB 질문에 맞는 이유 | 주요 위험 | 다음 행동 |
|---|---|---|---|---|
| 기준 경로 | gpt-oss-20b | 16GB급 근거를 설명하기 가장 쉽다 | 큰 저장소 agent를 무제한 기대하면 안 된다 | 설치 후 smoke test |
| 공격적 실험 | Qwen3.6-35B-A3B low-bit 또는 offload | agentic coding 후보로 매력적이다 | 표준 runtime 표시는 단순 16GB 보장이 아니다 | 양자화와 context를 기록 |
| 가벼운 대안 | Gemma 4 E4B-it | 메모리 압박이 낮고 반응이 안정적이다 | 깊은 repo 추론의 주역은 아닐 수 있다 | 좁은 작업에 사용 |
| 코드 특화 대안 | Qwen2.5-Coder, Qwen3-Coder, DeepSeek Coder 계열 | 함수 수정과 짧은 diff에 유용할 수 있다 | 구체 패키지와 양자화가 결과를 결정한다 | 파일 크기와 context 확인 |
| 중단 | 더 큰 VRAM, 작은 모델, hosted coding | 긴 context와 tool loop는 16GB를 넘기 쉽다 | 계속 조정하면 개발 시간이 사라진다 | OOM, 지연, context 손실에서 멈춘다 |
근거 경계: 공식, 실행 환경, 커뮤니티를 나눈다
gpt-oss-20b를 기준으로 삼는 이유는 모든 벤치마크의 우승자라서가 아니다. 공식과 주요 runtime 근거에서 16GB급이라고 설명하기 더 쉽고, 첫 설치가 덜 불확실하기 때문이다.
Qwen3.6 35B A3B는 매력적인 후보지만 단순 추천으로 쓰면 위험하다. agentic coding, repo-level reasoning 쪽 장점이 기대되지만, Ollama나 LM Studio의 표준 표시는 16GB all-GPU 보증과 다르다.
Gemma 4 E4B는 가벼운 대안이다. 가장 큰 모델이 아니라 더 빨리 응답하고, OOM 위험을 낮추며, 짧은 코드 작업에서 context를 유지하는 역할을 한다.
커뮤니티 글은 후보를 찾는 데 도움이 된다. Reddit, Naver Blog, 벤치마크, 국내 게시판은 실제 GPU 조합과 실패 사례를 보여준다. 하지만 모델 파일명, 양자화, context 길이, GPU, driver, runtime version이 없으면 보증이 아니다.
따라서 공개 문장에서는 공식은 모델의 위치, runtime은 패키지와 메모리, 커뮤니티는 수요와 증상으로 분리한다. 이 경계를 지키면 독자는 멋진 목록보다 재현 가능한 선택을 얻는다.
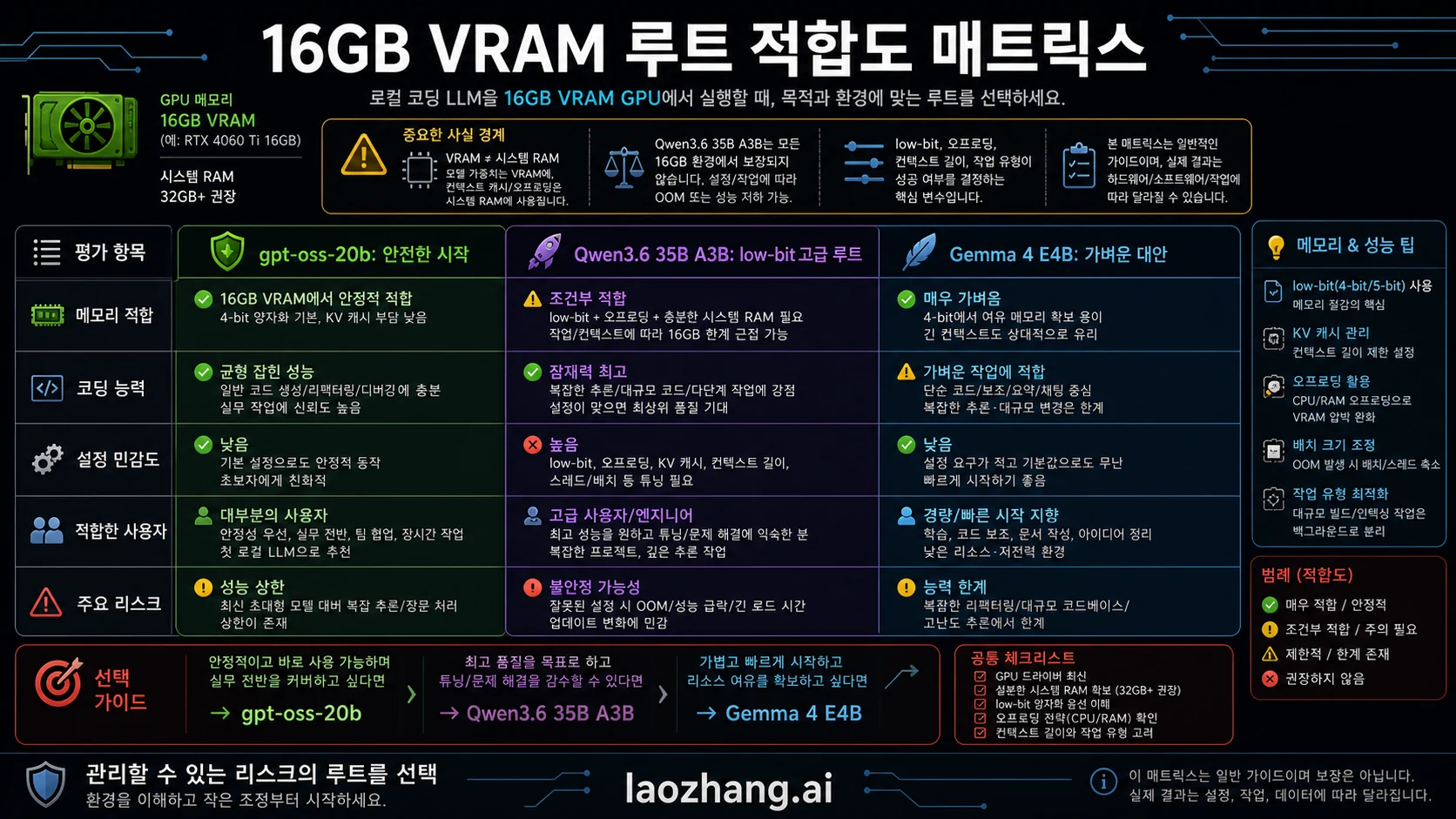
16GB VRAM이 실제로 감당하는 것
VRAM은 GPU의 전용 메모리다. 시스템 RAM이나 저장 공간이 아니다. 로컬 추론에서는 모델 가중치, runtime buffer, KV cache, prompt, 생성 token, IDE 통합 계층이 같은 예산을 쓴다.
코딩 작업은 일반 채팅보다 context가 무겁다. 함수, 인접 테스트, 에러 로그, refactor 제약, 이전 답변을 함께 유지해야 한다. 짧은 질문에는 답하는 모델도 multi-file patch loop에서는 흔들릴 수 있다.
offload는 OOM을 피할 수 있게 해주지만 대기 시간을 늘린다. 개발 도중의 지연은 품질 문제다. 매번 오래 기다려야 한다면, 조금 작은 모델이 실제로 더 좋은 선택이다.
16GB의 가치는 프라이버시 친화적인 로컬 보조와 짧은 context의 빠른 작업이다. 대형 monorepo 전체를 자동으로 이해하는 에이전트를 약속하는 크기는 아니다.
| 压力来源 | 对代码任务的影响 | 16GB 下的处理方式 |
|---|---|---|
| 모델 가중치 | 실행 가능성과 기본 품질을 좌우한다 | 16GB급 근거가 명확한 패키지부터 시작 |
| KV cache | context가 길수록 남은 메모리를 빠르게 쓴다 | context를 단계적으로 늘린다 |
| 도구 계층 | IDE, server, tokenizer, wrapper가 추가 비용을 만든다 | CLI로 기준선을 만든다 |
| offload | OOM을 피하지만 지연이 커진다 | 속도가 허용될 때만 유지 |
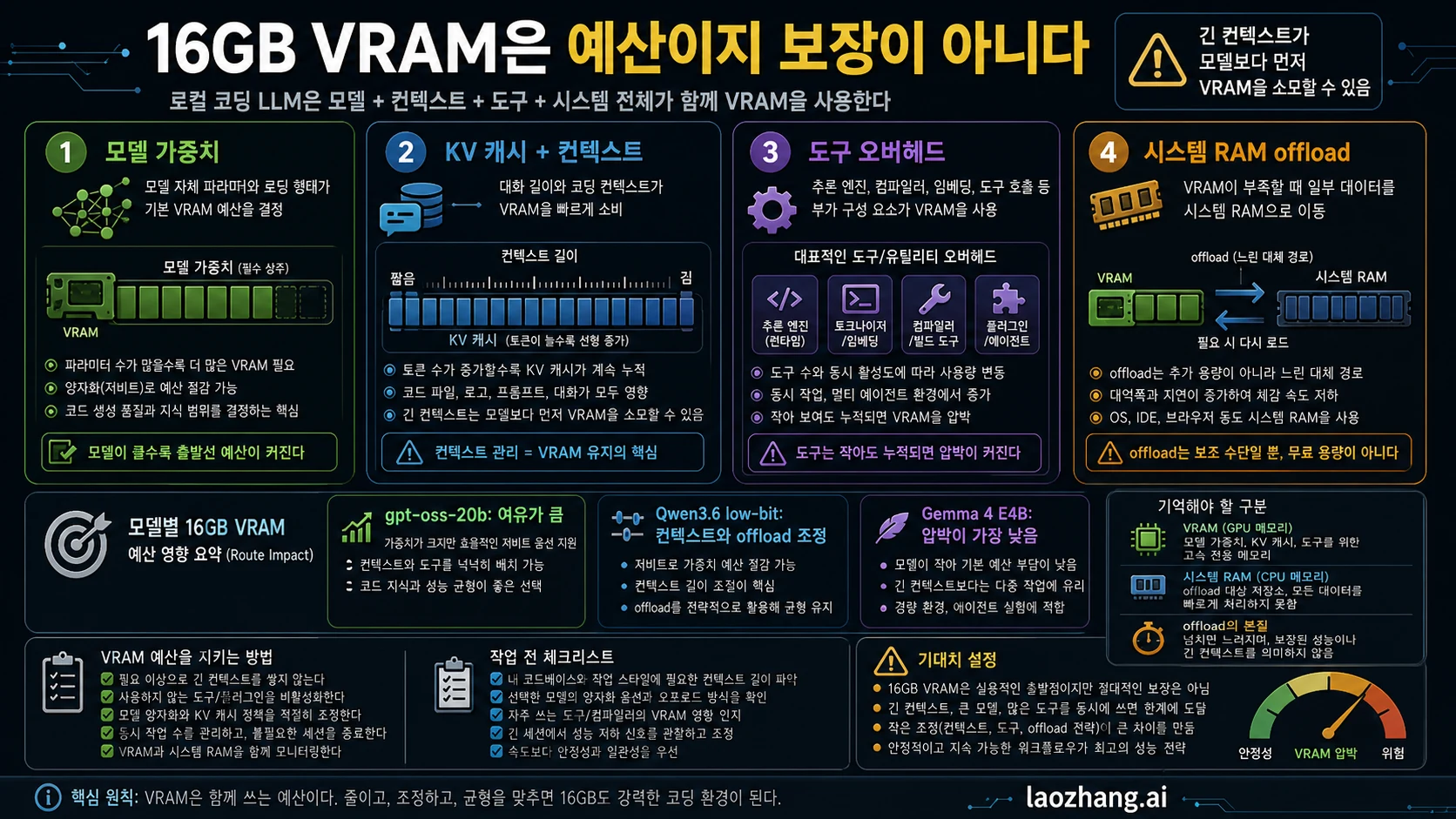
경로 1: gpt-oss-20b를 기준으로 삼기
gpt-oss-20b는 기준선을 만들기 위해 먼저 둔다. 기준선은 최종 우승자가 아니라, 내 GPU와 runtime, 저장소 조각에서 로컬 LLM이 유용한 coding loop를 만들 수 있는지 확인하는 장치다.
처음부터 전체 프로젝트를 넣지 않는다. 파일 하나, 가까운 테스트 하나, 명확한 수정 요구 하나로 시작한다. 현재 동작 설명, 작은 patch, 바뀌어야 할 테스트, 부족한 파일을 구체적으로 요청한다.
bashollama pull gpt-oss:20b ollama run gpt-oss:20b
이 단계에서 이미 느리거나 OOM이 나거나 context를 잊는다면, 더 큰 Qwen으로 가기 전에 경계를 줄인다. context 축소, runtime 설정 확인, IDE wrapper 제거, 작은 모델 테스트가 우선이다.
기준선이 통과하면 테스트, 인접 모듈, 에러 로그 순서로 context를 늘린다. 각 단계에서 VRAM, 시스템 RAM, latency, patch 품질을 기록한다.
경로 2: Qwen3.6 35B A3B는 고급 실험으로만 보기
Qwen3.6 35B A3B는 품질을 더 밀어보고 싶을 때의 실험 경로다. 16GB 사용자에게 쉬운 설치 답변이 아니라 low-bit, 짧은 context, offload, runtime 설정을 포함한 조건부 실험이다.
시작 전에 양자화, runtime, GPU layers, offload 여부, 시스템 RAM, context 길이, 작업 유형을 고정한다. 단발 코드 설명과 여러 파일을 오가는 agentic coding은 전혀 다른 부하다.
bashollama show qwen3.6:35b-a3b
패키지 크기나 메모리 요구가 이미 불편하다면 다운로드 전 멈춘다. 겨우 들어가는 모델은 실제 코딩에서 작은 모델보다 더 나쁜 경험을 줄 수 있다.
Qwen 경로는 설정을 읽고 조정할 수 있는 사람에게 맞다. quant를 바꾸고, context를 낮추고, memory graph를 보며, 속도 저하를 받아들이고, 실패 시 돌아갈 수 있어야 한다.
경로 3: Gemma 4 E4B와 작은 코드 모델을 남겨두기
Gemma 4 E4B와 작은 코드 모델은 16GB 환경의 사용성을 지키는 장치다. 빠른 응답, 낮은 메모리 압력, 안정적인 context 유지가 매일 쓰는 보조 도구에서는 매우 중요하다.
DeepSeek Coder, Qwen2.5-Coder, Qwen3-Coder는 후보에 넣을 수 있지만 family 이름만으로 결정하면 안 된다. 실제 파일, 양자화, context, runtime 지원을 봐야 한다.
작은 모델은 함수 설명, 짧은 refactor, unit test 초안, 설정 파일 검토, 에러 메시지 정리에 강하다. 모든 agent 작업을 맡길 필요는 없다.
15초 안에 review 가능한 patch를 주는 작은 모델은, 2분 동안 생각하고 테스트 context를 잊는 큰 모델보다 실무에 더 좋을 수 있다.
실행 환경: Ollama, LM Studio, llama.cpp, IDE 래퍼
실행 환경은 답을 바꾼다. Ollama는 CLI 기준선, LM Studio는 GUI와 local server, llama.cpp/GGUF는 양자화와 context 제어, IDE plugin은 어떤 파일이 prompt에 들어가는지를 결정한다.
같은 모델명이라도 runtime마다 실제 파일과 기본 context가 다를 수 있다. 추천을 쓸 때는 모델명뿐 아니라 실행 경로를 함께 기록한다.
Ollama에서는 package size와 parameters, LM Studio에서는 memory requirement, GGUF에서는 파일명과 quant, IDE wrapper에서는 file selection과 endpoint를 확인한다.
wrapper가 메모리 압력을 숨기면 잠시 CLI로 돌아간다. CLI는 문제를 모델, context, editor integration으로 나누는 데 좋다.
Smoke test: 내 코드에서 먼저 증명하기
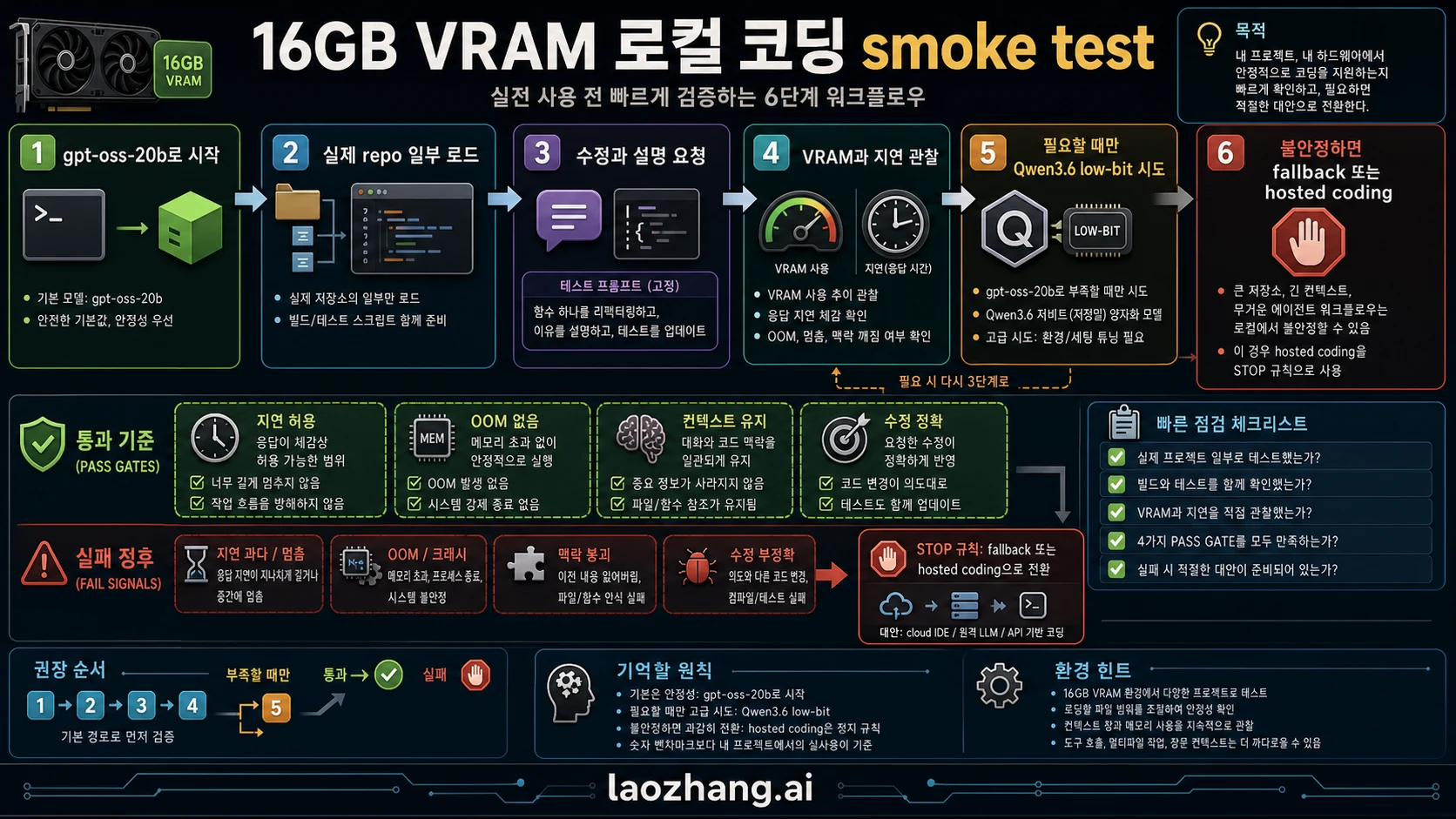
smoke test는 내 코드로 해야 한다. 일반 퍼즐이나 벤치마크는 함수, 테스트, patch 제약을 유지하는 능력을 보여주지 못한다.
최소 구성은 파일 하나, 테스트 하나, 수정 요구 하나다. 모델은 현재 동작 설명, patch, 테스트 이름, context 부족 시 필요한 파일을 구체적으로 답해야 한다.
textGiven the files below, refactor one function without changing behavior. Explain the tradeoff, show the patch, and name the test that should be updated. If the context is insufficient, say exactly what file or symbol you need next.
합격 기준은 지연이 감당 가능하고, OOM이나 과한 offload가 없고, 함수와 테스트 제약을 잊지 않고, patch가 작고 review 가능하다는 것이다.
합격하면 context를 조금 늘리고, 그다음 Qwen low-bit를 시도한다. 이 순서가 tuning과 품질 평가를 분리해준다.
중단 기준: 16GB를 더 밀어붙이지 않을 때
중단 기준은 미리 정한다. 16GB 환경에서 가장 비싼 실수는 실행만 되는 모델을 일상 도구로 만들려고 끝없이 조정하는 것이다.
생성이 너무 느리면 offload나 무거운 quant가 원인일 수 있다. snippet 답변은 좋은데 repo 작업이 나쁘면 context packing 문제일 수 있다. context를 올리자마자 OOM이면 KV cache가 예산을 먹고 있다.
해결책은 다양하다. 작은 모델로 돌아가고, 작업을 좁히고, context를 낮추고, 24GB 이상으로 옮기거나, 긴 multi-file 작업만 hosted coding으로 보낼 수 있다.
목표는 16GB로 모든 것을 증명하는 것이 아니다. 코드 작업을 더 빠르고 안정적으로 review 가능하게 만드는 것이다.
| 증상 | 가능한 원인 | 더 나은 경로 |
|---|---|---|
| 실행 후 너무 느림 | offload 또는 무거운 quant | 작은 모델 또는 더 큰 VRAM |
| snippet은 좋고 repo는 나쁨 | context packing 문제 | 작업을 좁힌다 |
| context를 올리면 OOM | KV cache 예산 초과 | context를 낮춘다 |
| patch loop에서 상태 손실 | agent 작업이 너무 큼 | hosted coding 또는 상위 GPU |
로컬 검증 로그에 남길 항목
검증 로그에는 GPU, system RAM, driver, runtime version, model file, quant, context length, offload, task type, latency, memory peak, fail reason을 남긴다.
gpt-oss-20b에서는 어떤 repo slice까지 안정적으로 유지하는지 본다. Qwen3.6에서는 low-bit와 offload가 속도에 주는 비용을 본다. Gemma 4 E4B에서는 속도와 품질의 균형을 본다.
기록할 결론은 “실행됐다”가 아니라 “정확하게 고쳤다”다. 코딩 LLM의 가치는 patch, test, context 부족을 인정하는 능력에 있다.
16GB 환경의 검증은 세 단계로 나누면 좋다. 첫 단계는 함수 하나와 테스트 하나, 두 번째는 에러 로그나 요구사항 추가, 세 번째는 인접 모듈 추가다. 어느 단계에서 지연이 커지고 어느 단계에서 테스트 이름을 잊는지 보면 실제 한계를 알 수 있다.
모델, 양자화, runtime, IDE wrapper를 한 번에 바꾸면 무엇이 좋아졌는지 알 수 없다. 작업과 prompt를 고정하고 변수 하나씩만 바꾸면 gpt-oss, Qwen, Gemma, 작은 코드 모델을 공정하게 비교할 수 있다.
팀에 공유할 때는 “이 모델이 최고”라고 쓰기보다 “이 GPU, 이 quant, 이 context, 이 작업에서 통과”라고 써야 한다. 16GB 로컬 모델 추천의 가치는 모델명보다 재현 조건에 있다.
한국어권 커뮤니티 글은 실제 체감이 풍부하지만, 많은 글이 context와 offload 조건을 생략한다. 그래서 개인 후기를 읽을 때는 GPU 이름보다도 어떤 파일을 실행했는지, 어떤 작업을 시켰는지, 얼마나 오래 기다렸는지를 먼저 확인한다.
실패 후 다음 행동도 기록해야 한다. gpt-oss-20b 품질이 부족하지만 메모리가 남으면 Qwen low-bit 짧은 context를 시도한다. Qwen이 느리면 context를 더 늘리지 말고 작은 모델로 돌아간다. 작은 모델도 테스트 제약을 잊는다면 모델보다 작업 분할이 문제일 수 있다.
가장 유용한 증거는 다운로드 완료 화면이 아니라 smoke test 전체 흐름이다. 입력 파일 범위, 모델이 낸 patch, 테스트 제안, VRAM 변화, 최종 채택 여부를 함께 남기면 다음 모델 교체가 감상이 아니라 비교 가능한 엔지니어링 결정이 된다.
실패 원인은 구체적으로 나눈다. 속도 문제는 offload, quant, context로 보고, 품질 문제는 모델 능력이나 작업 분할로 본다. 안정성 문제는 VRAM 여유, runtime version, IDE wrapper를 따로 확인한다.
팀 기준으로는 같은 작업을 세 번 연속 통과하는지도 적어야 한다. 한 번 성공은 가능성이고, 반복 성공은 일상 도구의 조건이다.
같은 16GB GPU라도 driver, OS 부하, editor plugin 상태에 따라 결과가 달라진다. 조건을 남겨야 다음 실패가 모델 문제인지 runtime 변화인지 당일 시스템 부하인지 구분할 수 있다.
자주 묻는 질문
16GB VRAM에서 먼저 시도할 로컬 코딩 LLM은?
먼저 gpt-oss-20b를 시도한다. 16GB급 근거가 비교적 명확하고 기준선으로 쓰기 좋다.
Qwen3.6 35B A3B는 16GB에서 돌아가나?
low-bit, 짧은 context, offload 조건에서는 가능할 수 있다. 하지만 단순한 all-GPU 보장은 아니다.
gpt-oss-20b는 코딩에 충분한가?
짧은 수정, 설명, 작은 테스트 제안에는 기준선으로 좋다. 큰 agent 작업은 별도 smoke test가 필요하다.
Gemma 4 E4B는 왜 남겨두나?
가볍고 빠르며 context 유지가 쉽다. 좁은 작업에서는 큰 모델보다 더 유용할 수 있다.
Ollama와 LM Studio 중 무엇이 나은가?
CLI 기준선은 Ollama, GUI와 local server는 LM Studio가 편하다. 핵심은 실제 파일, quant, 메모리 요구다.
RTX 4060 Ti 16GB면 충분한가?
16GB 경로 검증에는 충분하다. 다만 35B급을 긴 context로 편하게 돌린다는 뜻은 아니다.
8GB VRAM은 어떻게 해야 하나?
작은 모델, 짧은 context, 좁은 작업으로 제한한다. 16GB용 Qwen 실험을 그대로 옮기면 안 된다.
24GB VRAM이면 문제가 해결되나?
여유는 늘지만 context와 KV cache 문제는 남는다. smoke test는 여전히 필요하다.
언제 로컬 조정을 멈춰야 하나?
OOM, offload 지연, context 손실, patch loop 실패가 주된 일이 될 때 멈춘다.
커뮤니티 벤치마크만 믿어도 되나?
후보 탐색에는 좋지만 보증은 아니다. 모델 파일, 양자화, runtime, 내 코드 검증이 필요하다.