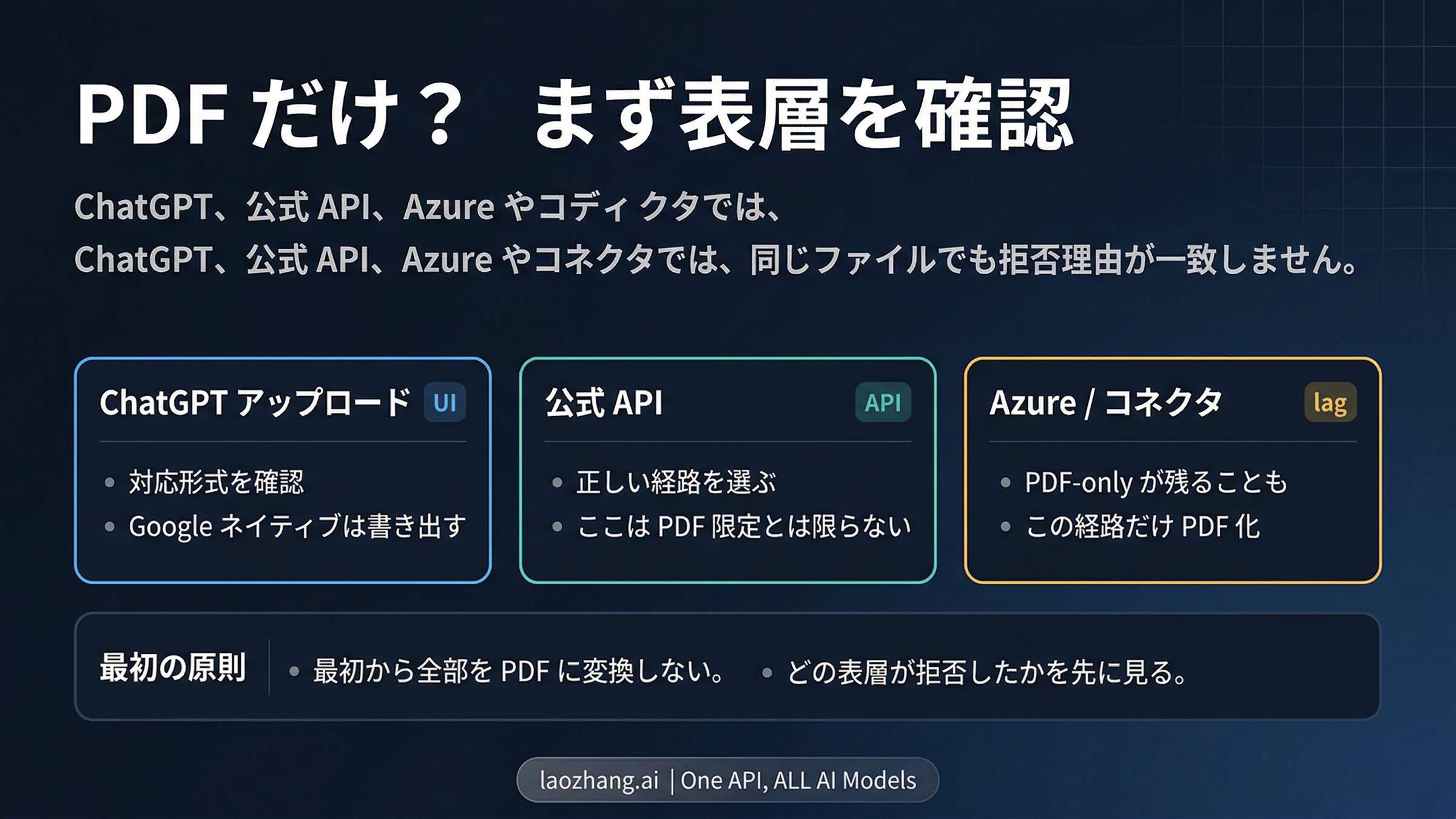
OpenAI で「ファイル形式がサポートされていません」と表示され、「PDF で再試行してください」と言われても、すぐに全部を PDF に変換しないでください。ChatGPT のアップロード、現在の公式 OpenAI API、Azure や他の connector では、まだ別々のルールでファイルを受け付けていることがあります。だから最初の正解は拡張子を変えることではなく、どの入口で拒否されたのかを見極めることです。
失敗が ChatGPT 側なら、まず Google Docs、Sheets、Slides のようなネイティブファイルを export しているかを確認します。現在の公式 API 側なら、input_file か file_search か、経路が仕事に合っているかを確認します。Azure や connector 側なら、その入口では今も PDF が最速の解決になることがあります。最小修正をしたら、同じ入口で再試行してください。同じ入口が明らかに対応しているファイルをまだ拒否するなら、それは「OpenAI は今 PDF しか受け付けない」という証拠ではなく、経路の選び方が違うか、その入口の更新が遅れていると考えるべきです。
30秒ルート表

拡張子だけで判断せず、まず拒否された入口で分けます。
| どこで拒否されたか | ありがちな原因 | 最初に取る一番安全な手 | 同じ入口での確認 | 判断を一段上げる境界 |
|---|---|---|---|---|
| ChatGPT アップロード | Google ネイティブファイル、直接アップロードできない形式、または PDF の方が版面を保ちやすい資料 | まず Google Docs / Sheets / Slides から export する。そうでなければ、明確に対応している形式か、見た目が大事なら PDF で再試行する | 同じ ChatGPT アップロード画面で再度受け付けられる | export 済みの対応ファイルでもまだ失敗する |
| 公式 OpenAI API | 経路の選び間違い、input_file への期待違い、または本当は file_search に向く仕事 | 現在のドキュメントに合う経路へ切り替え、すべての文書処理を一つの経路に押し込まない | 同じリクエスト経路で受理され、結果も仕事に合う | ドキュメントに沿った経路でも対応ファイルを拒否する |
| Azure または connector | その入口だけがまだ PDF 前提で動いている | その入口向けに PDF に export / convert するか、仕事を現在の公式 OpenAI 経路に移す | 同じ入口がファイルを受け付ける | PDF でも失敗する、または挙動が公式文書と食い違い続ける |
このページで使った OpenAI の公式 help pages と developer docs は 2026 年 4 月 8 日に再確認しました。結論は単純です。現在の公式 OpenAI は一律で PDF-only ではありません。 ただし、同じエラー文が一部の隣接入口ではまだ出るため、引用句そのものよりも分岐の見取り図の方が大事です。
ChatGPT 側で拒否される場合
この枝は API tooling の話というより、アップロード対応の話です。OpenAI の現在の supported file types と File Uploads FAQ は、PDF だけではなく複数の文書、プレゼン、表計算、テキスト、コード形式を挙げています。つまり、DOCX、PPTX、TXT、MD、CSV、JSON、XLSX といった形式は、ChatGPT 側では本来それだけで「まず PDF にすべき」とはなりません。
ここで一番多い隠れた原因は Office ファイルではなく、Google Docs、Sheets、Slides のネイティブクラウドファイルです。.gdoc、.gsheet、.gslides は直接アップロード形式ではありません。もしファイルが Google ネイティブなら、まず export してから再試行する必要があります。PDF がここでまだ有効なのも同じ理由です。ChatGPT が一律 PDF しか受けないからではなく、実際の仕事がプレーンテキストではなく、レイアウト、図、埋め込み画像、視覚関係の保持にあることが多いからです。
ここで時間を失う人は多いです。正確なエラー文を検索し、「PDF に変換すればいい」という大ざっぱな助言を見て、その拒否が Google ネイティブファイル由来なのか、対応形式へまだ export していないだけなのか、あるいは内容的にレンダリング後の見た目を保つ方が大事なのかを確認しません。OpenAI 自身の help の言い方は、その思い込みよりずっと狭いです。問うべきなのは「ChatGPT はファイルをサポートするのか」ではなく、「この仕事で必要な情報を保てる export 形式を私はアップロードしているか」です。
この枝の確認は短くて十分です。失敗したのと同じ ChatGPT アップロード画面に、export 済みファイルを戻して再試行してください。別のアプリや wrapper で成功しても、元の問題を隠しただけかもしれません。同じ ChatGPT の入口が明らかに対応している export ファイルをまだ拒否するなら、あなたはもう単純な export 不足の枝にはいません。
もし最終的に問題が unsupported file type ではなく使用量上限だと分かったら、このページを別の読者課題に広げないでください。その場合は現在のプラン制限を確認する方が筋が通っています。
公式 OpenAI API 側で拒否される場合
古い PDF-only advice の影響を最も受けやすいのは、この枝です。OpenAI の現在の PDF files and other document formats は、Responses API の input_file 経路が PDF だけでなく、text files、code files、rich documents、presentations、spreadsheets も受け付けると明記しています。これは古い snippets や forum answers が想定しているより広い契約です。
ただし、受理されることと仕事に適していることは別です。同じ文書は、non-PDF file に埋め込まれた画像や charts は抽出されないとも述べています。つまり、DOCX や PPTX は API に受け入れられても、diagram、slide の関係、annotation、mixed layout をモデルに見せたいなら最適な入力ではありません。受け入れられるファイルと、仕事に最も合うファイルは同じ主張ではありません。
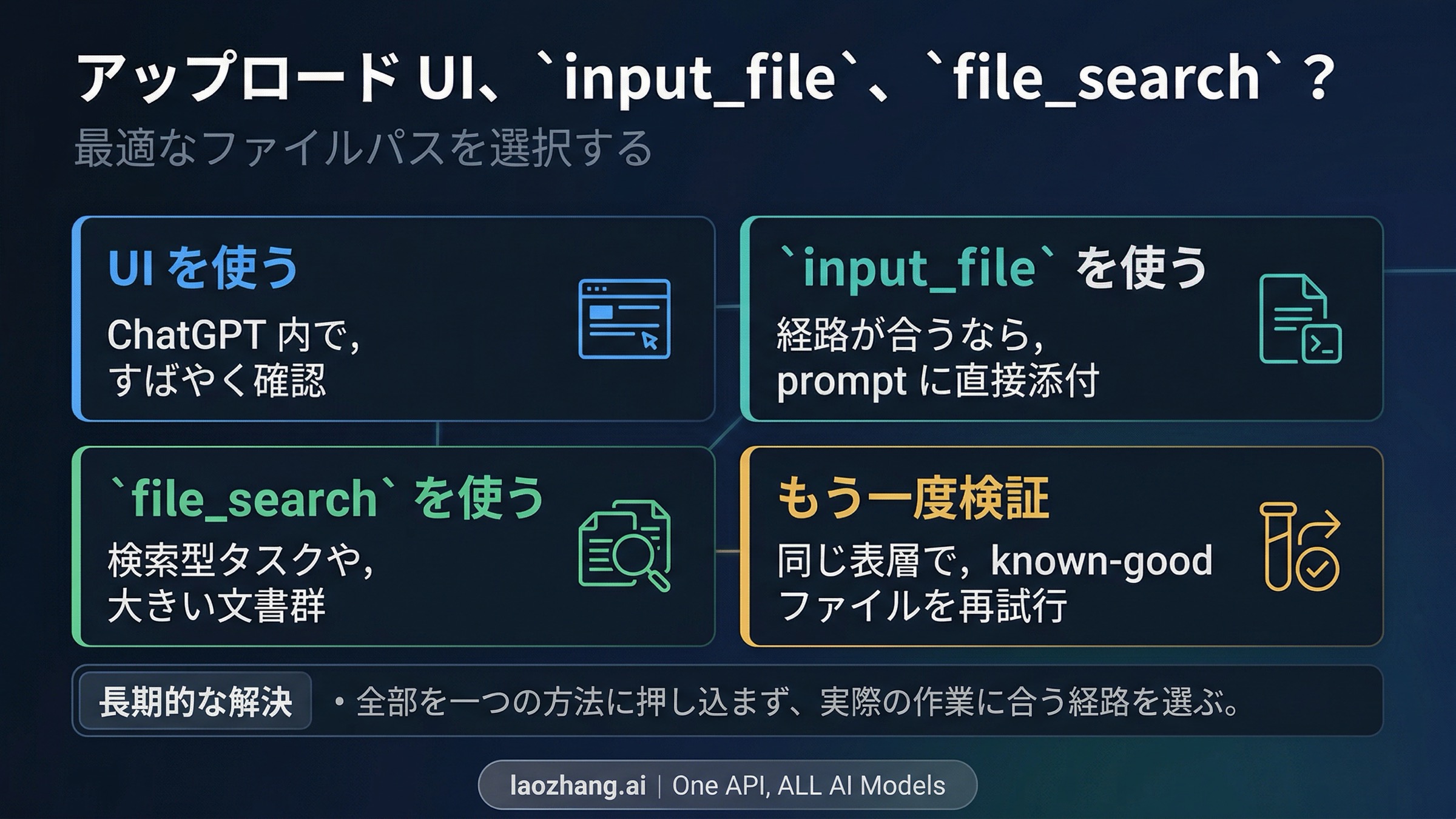
この枝を最短で整理するには、仕事に合わせて経路を選びます。
| 本当の仕事が... | 向いている経路 | 理由 |
|---|---|---|
| 1 つの文書を prompt context に直接入れること | input_file | 別の検索準備をせずに、その場で読ませられる |
| 複数文書を横断して探したり、保存済みファイルから引用したりすること | file_search | 現在の file search docs は多くの non-PDF format を扱え、検索に向く |
| charts、diagrams、埋め込み visual、複雑なレイアウトを保つこと | 見た目の保持について最も明確な現在の契約が PDF にある |
実務上、公式 API でこのエラーが出るときは、だいたい三つのどれかです。ファイル経路が仕事に合っていない。形式自体は受理されるが、本当の作業は見た目を保つために PDF を必要としている。あるいは request が wrapper や古い example を通っていて、current API contract を狭く読んでしまっている。どれも「OpenAI は今 PDF しか受けない」という話ではありません。
正しい経路に直したあとも API request が失敗するなら、次に見るべきはファイル層の外です。project scope、key type、wrapper 固有の routing が、正しいファイル形でも request を壊している可能性があります。その枝に入ったら、次は OpenAI API Key と Organization ID のガイド を読む方が役に立ちます。あちらは credential と scope selection を分けて扱うからです。
Azure または connector 側で拒否される場合
この枝だけは、「PDF を試す」がその入口に限っては文字どおり正しいことがあります。問題は、そこで止まってローカルな挙動を OpenAI 全体の真実にしてしまうページが多いことです。
今回の調査でも、そうした遅れを示す current surface-specific evidence が見つかりました。比較的新しい Microsoft Q&A のスレッド では、Azure OpenAI の file-search workflow で supported format .pdf という complaint がまだ見られます。その一方で、現在の公式 OpenAI docs は一部の first-party 経路でより広い document support を記述しています。connector コミュニティでも同じ構図で、ユーザーは本物のエラーを見ているのに、返ってくるのは「PDF に変換して」の一言で、connector 側の契約と OpenAI 本体の現在の契約が区別されません。
この違いは実務では大きいです。もし今の遅れた入口にとどまる必要があるなら、PDF への export や conversion は最小で正しい fix になり得ます。もし経路を変えられるなら、長期的には current official OpenAI path に仕事を移した方がよいことが多いです。やってはいけないのは、Azure や一つの automation module の振る舞いを、OpenAI のすべてのアップロード経路の真実として扱うことです。
同時に、切り分けをここで止めないことも大切です。同じ Azure または connector の入口が、きれいな PDF export 後でもまだ失敗するなら、それは単なる format choice ではありません。その時点では implementation lag、module behavior、あるいは案内と実際の挙動の不一致を疑うべきです。
それでも PDF がより良い形式になるとき

PDF は今でもしばしば正解です。だからこそ、古い advice は完全には消えていません。間違いは PDF を使うことではなく、PDF を何にでも当てはまる説明にしてしまうことです。
現在の OpenAI help guidance でも、document-heavy な ChatGPT workflow では、diagram、embedded visual、複雑な layout をより安定して保ちたいなら PDF が強い形式として扱われています。現在の API doc も同じことを developer 側からもっと明確に言っています。non-PDF file は accepted されることがあるが、non-PDF に埋め込まれた images と charts は抽出されない。前者は「アップロードは通るか」、後者は「必要な形で内容が残るか」を答えています。ここを分けるだけで話はかなり整理されます。
PDF を選ぶべきなのは、資料が視覚的に密であるとき、Google Docs / Sheets / Slides から export して rendered result を保持したいとき、または同じ入口がすでに PDF 寄りだと分かっているときです。OpenAI ブランドのどこか一箇所でそのエラーを見たからといって、すべての file job の default answer を PDF にしてはいけません。
修正後の確認と長期ルートの選び方
ファイルが再び受け付けられるようになっても、そこで終わりにしないでください。失敗したのと同じ入口で短い確認を行います。
- 最小修正のあと、必ず同じ入口で再試行する。他の経路に逃がして元の問題を見えなくしない。
- ファイルが受け付けられるだけでなく、読ませる、検索する、見た目を保つといった本来の仕事に本当に使えるか確認する。
- ファイルが Google Docs、Sheets、Slides 由来なら、実際に通った export 形式を保存しておく。
- 問題が別の OpenAI 経路に移した時だけ消えるなら、元の入口はその枝特有の遅れとみなし、「OpenAI は PDF-only」という話には戻さない。
長期ルートは、繰り返す仕事に合わせて決めるべきです。ChatGPT で普通の文書を上げることが多いなら、help docs がすでにサポートする export format をそのまま使えばよいです。programmatic retrieval を何度もやるなら、one-shot upload と戦わず file_search を中心に組み直した方が早いです。chart や layout の fidelity が本題なら、その枝では PDF を標準にした方が再発防止になります。
FAQ
OpenAI は今 PDF しかサポートしていませんか。
いいえ。2026 年 4 月 8 日時点で再確認した current official OpenAI help pages と developer docs では、ChatGPT uploads と一部の first-party API routes で複数の non-PDF file formats が説明されています。PDF-only のように見える error は、一部の Azure や connector path ではまだ real ですが、それはその入口特有の挙動です。
ChatGPT ではどの file types が本来サポートされますか。
現在の OpenAI help pages では、一般的な文書、プレゼンテーション、スプレッドシート、テキスト、コード形式が挙げられています。隠れた原因になりやすいのは DOCX や PPTX そのものより、まず export が必要な Google ネイティブファイルです。
なぜ DOCX や PPTX がある OpenAI 経路では通り、別の経路では失敗するのですか。
「OpenAI」は単一のアップロード契約ではないからです。ChatGPT uploads、current official API、Azure OpenAI、third-party connectors は今でも異なるルールを持ったり、更新の追いつき方が違ったりします。
input_file ではなく file_search を選ぶべきなのはいつですか。
1 つの file を一度だけ prompt に入れるのではなく、複数 document を横断検索したり、保存済み file から引用したりする retrieval job なら file_search が向いています。
それでも PDF が一番良い答えになるのはどんな時ですか。
layout、charts、diagrams、embedded visuals を保つ必要がある時、Google Docs / Sheets / Slides から export して rendered result を使いたい時、あるいはその入口が今も PDF を明らかに優先している時です。
覚えておく作業ルール
最速でクリーンな fix は「全部 PDF に変換する」ではありません。まず拒否した入口を特定し、その入口に対する最小の正しい file 変更か経路変更を行い、同じ場所で検証し、そのあとで初めて PDF を長期の標準形式にするか判断する。 これが再発を最も減らします。