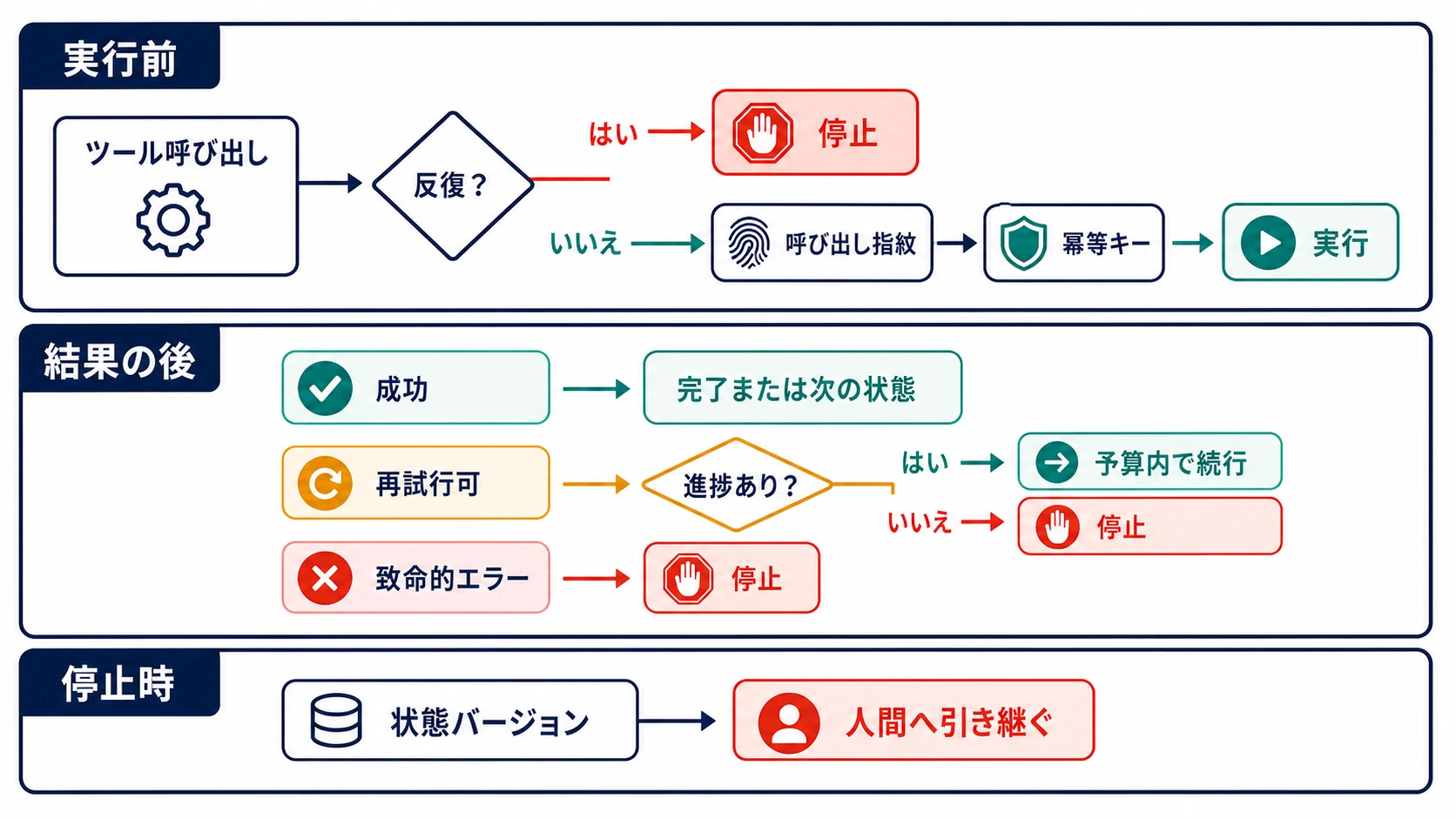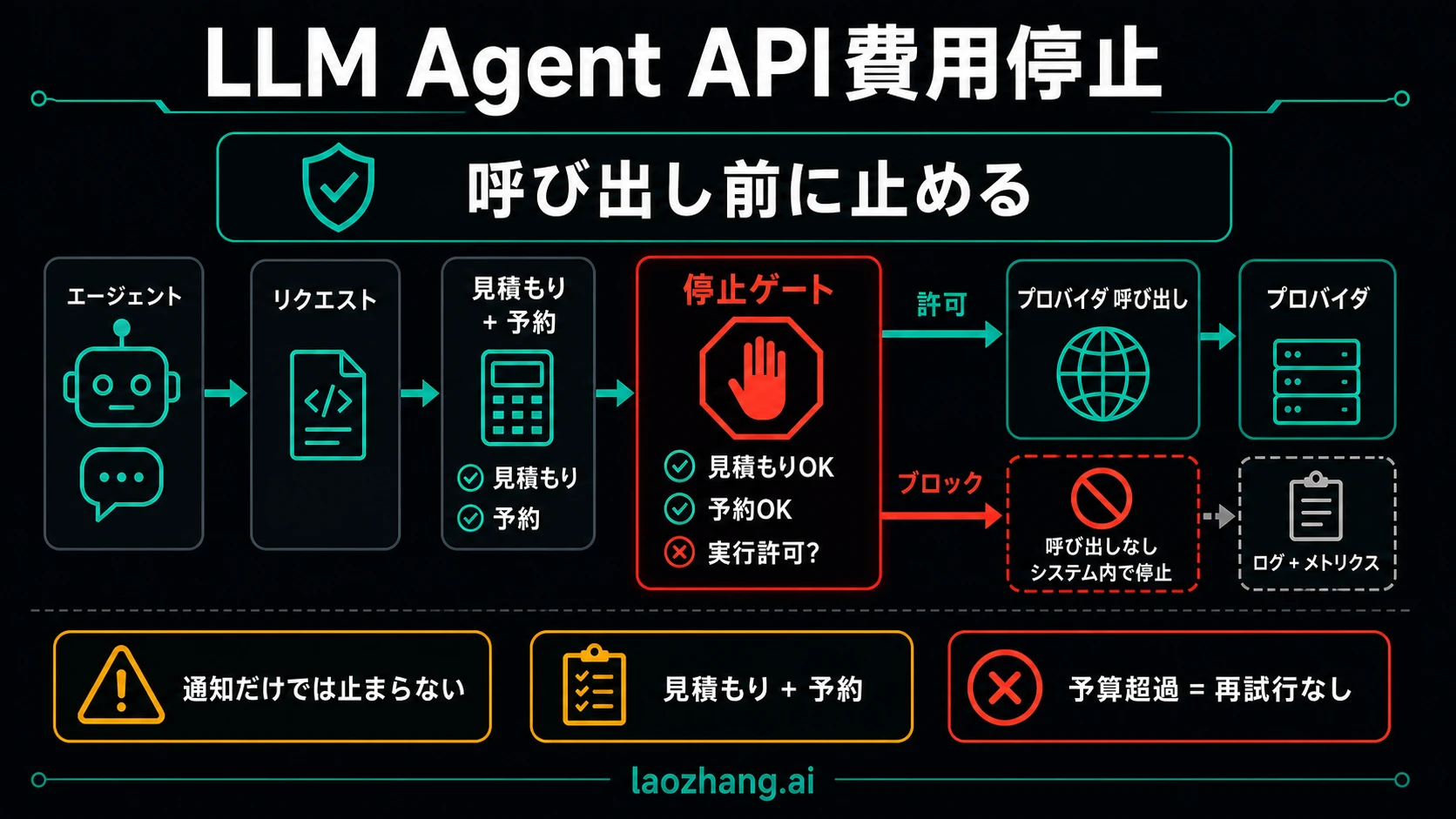
LLMエージェントAPIの費用キルスイッチは、リクエストが有料プロバイダーへ出ていく前に動かなければなりません。月次予算のメール、利用量ダッシュボード、請求アラートは役に立ちますが、すでにループしているエージェント、リトライを続けるworker、サブエージェント、モデル呼び出しを内包するtoolをその場で止めるとは限りません。
最低限の実装は、呼び出し前に最大費用を見積もり、共有台帳でその金額を原子的に予約し、予約が成功した場合だけプロバイダーを呼び出し、レスポンス後にusageで照合する形です。上限を超えるなら、エージェントには再試行不可のover_budgetを返します。これは通常のtimeoutや一時的な429とは別の意味を持つ停止条件です。
| 制御 | 止められるもの | 費用停止での役割 |
|---|---|---|
| 予算アラート | 人が燃え方を見逃す問題 | ソフト警告。リクエストは続くことがある |
| プロバイダーまたはプロジェクト上限 | アカウント単位の治理 | 後備として有用。エージェントの第一ゲートではない |
| Gateway予算 | 全トラフィックが同一gatewayを通る場合の制御 | 迂回がなければハード停止になり得る |
| 呼び出し前の予算ゲート | 次の有料モデル呼び出し | 自律エージェントの主キルスイッチ |
停止ルールは明示してください。over_budgetが返ったら、plannerは新しい有料作業を作らず、サブエージェントを起動せず、別のkeyやfallback routeへ切り替えず、tool経由の隠れたモデル呼び出しも止めます。人が上限またはpolicyを変えて、その理由を記録するまで、runは停止です。
本物の費用キルスイッチとは
本物のキルスイッチは、利用量を見る画面や請求メールではありません。次の有料APIリクエストを送る前にnoと言える enforcement point です。置き場所はエージェントruntime、社内のOpenAI互換proxy、共有AI gateway、プロバイダーwrapper、sidecar serviceのどれでも構いません。ただし、エージェントが使うcredential pathを必ず支配している必要があります。
典型的な事故は、予算チェックの場所を間違えることです。workerがprovider keyを直接持っているのに、後段でbudget warningだけを足しても、守れるのは財務担当の受信箱だけです。planner loop、retry loop、tool loop、sub-agent queueのいずれも、同じbudget scopeを通らなければなりません。
すでにtool呼び出しを繰り返している場合は、費用問題だけとして扱う前に、AIエージェントのtool loop診断ガイドでパターンを分類し、次の危険な呼び出しを実行前に止めてください。
運用手順では、次の語を分けます。
| 用語 | 使う対象 | 使わない対象 |
|---|---|---|
| spend limit | 金額ベースの上限 | token throughput |
| rate limit | 時間窓あたりのrequestやtoken | 月次総費用 |
| soft budget | alert、report、threshold | 呼び出し前ブロック |
| hard stop | 有料作業の前に拒否されるrequest | 後から届くメールやdashboard |
この区別は文章上の好みではありません。暴走中に最初に聞くべきことは「どの画面にbudget欄があるか」ではなく、「どのcomponentが次の有料呼び出しを止められるか」です。
制御レイヤーを選ぶ
本番では、主停止をリクエスト経路に置き、プロバイダーやプラットフォームの制御を後備にするのが安定します。

| レイヤー | 得意なこと | 弱点 | 位置づけ |
|---|---|---|---|
| Agent loop limit | 無限loop、tool step過多、長すぎる実行時間 | 最終請求額は分からない | ローカル安全柵 |
| per-call token cap | 1回の最悪費用を狭める | 小さな呼び出しの累積は止まらない | call shape guardrail |
| pre-provider spend gate | システム外へ出る前の有料requestを拒否 | 共通台帳と経路統制が必要 | 主キルスイッチ |
| gateway budget | key、team、provider、model横断の管理 | gatewayを通らない経路は漏れる | 共有control plane |
| provider/project cap | プロバイダー側のaccount governance | ソフト、遅延、agent retryと無関係の可能性 | 後備 |
| alertsとaudit logs | 検知、通知、復盤 | 次のcallを止める保証はない | 可観測性 |
OpenAI互換proxyをすでに使っているなら、まずそこにbudget gateを置くのが実務的です。agent runtimeだけがtool呼び出しとsub-agentのすべてを見ているなら、runtime側に置き、すべての子処理へ同じbudget scopeを渡してください。複数providerを使うなら、gatewayや内部proxyの方が、各workerへ同じロジックを複写するより監査しやすくなります。
避けるべきは部分的なgateです。main plannerはgateを通るが、retrieval tool、evaluator、image generator、emergency fallback keyが直通なら、停止標識の横に別の有料道路が残ります。
reserve、call、reconcileを実装する
レスポンス前に正確な費用は分かりません。そのため、gateは「このrequestが作れる最大の合理的費用」を予約し、完了後にusageで調整します。
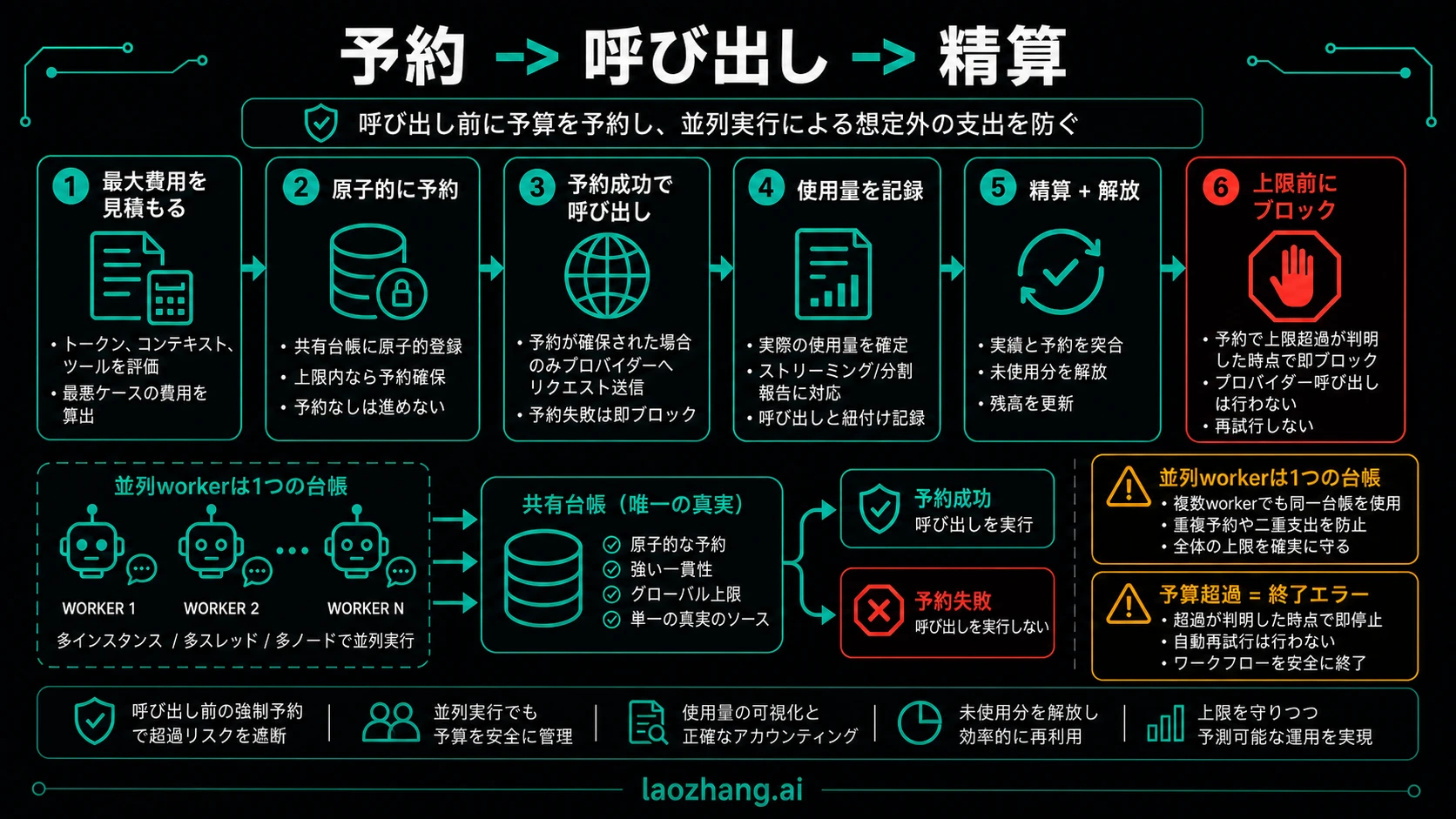
最小台帳は次の項目です。
| 項目 | 目的 |
|---|---|
| budget_id | team、user、project、agent、runなど上限のowner |
| limit_amount | periodまたはrunで使える最大額 |
| reserved_amount | in-flight callにより予約済みの額 |
| actual_amount | 完了後usageから照合した実費 |
| period_start / period_end | 日次、月次、run単位のreset window |
| request_id | budget decisionとprovider logを結ぶ |
| agent_run_id | planner、worker、sub-agent、tool callをまとめる |
| decision | allowed、blocked、reconciled、released |
| reason | cap reached、missing estimate、unknown model、override、policy block |
呼び出し前の流れは短くできます。
tsasync function guardedModelCall(request) { const estimate = estimateWorstCaseCost(request); const reservation = await ledger.reserveAtomically({ budgetId: request.budgetId, requestId: request.requestId, agentRunId: request.agentRunId, amount: estimate, }); if (!reservation.allowed) { return { error: "over_budget", retryable: false }; } const response = await provider.responses.create(request.payload); await ledger.reconcile({ reservationId: reservation.id, actualAmount: costFromUsage(response.usage), usage: response.usage, }); return response; }
重要なのは原子的な予約です。5つのworkerが同じ残高を読み、全員が呼び出し可能と判断すると、usage logが戻った時点ではもう遅いです。予約はdatabase transaction、Redis script、durable workflow step、またはgateway operationのように、同じbudget_idで割り込まれない操作である必要があります。
streamingでは、最初の予約を最大出力として扱います。usageが最後にしか出ない場合はstream close後に照合します。途中でclientが切れてusageが不明なら、全部を即時解放しないでください。保守的なchargeを残す、unknownにする、後続のprovider log reconciliationを走らせる、という処理が必要です。
Agentを本当に止める
予算エラーは通常例外ではなくAgent semanticsです。timeoutや一部の429はリトライ可能でも、over_budgetは同じbudget scopeでは終端です。
json{ "error": "over_budget", "retryable": false, "budget_id": "team-alpha-agent-run", "next_allowed_action": "human_budget_override" }
守るべき伝播ルールは3つです。
| ルール | 理由 |
|---|---|
| plannerは有料作業を増やさない | root loopがblocked jobを作り続けるのを防ぐ |
| sub-agentは親のbudget scopeを継承する | helperが親停止後に使い続けるのを防ぐ |
| model callを含むtoolも同じgateを通る | toolが隠れた費用経路になるのを防ぐ |
retry policyにはstop listを作ります。over_budget、policy_blocked、missing_budget_scopeは再試行しません。記録し、operatorへ表示し、runを止めます。「別providerで試す」「別keyで続ける」はretryではなく、新しい予算判断です。
プロバイダーとgatewayの境界を確認する
provider controlは有用ですが、すべて同じ種類のキルスイッチではありません。内部runbookへ入れる前に現在の公式ドキュメントを再確認してください。
| Surface | 現在確認すべき点 | 実用上の境界 |
|---|---|---|
| OpenAI project budgets | 本runで確認したHelp Centerでは、project monthly budgetsはsoft spending thresholdで、超過後もAPI requestsが続くと説明されています。rate limits guideもthroughput limitsとusage/spend limitsを分けています。 | project budgetだけをrequest-path kill switchにしない。 |
| OpenAI Responses usage | usage fieldsは実費照合に使えます。 | call後の記録には有用。call前の停止には不足。 |
| Anthropic limits | spend limitsとrate limitsを区別しています。 | provider governanceとして有用。直通callは自前gateへ。 |
| LiteLLM proxy | budgets、agent/session caps、spend trackingが文書化されています。 | すべての有料経路がproxyを通るなら選択肢。 |
| Cloudflare AI Gateway | spend limit到達後にHTTP 429でブロックする説明があり、eventual consistencyの注意があります。 | gatewayとして強いが、並列burstと迂回をテスト。 |
| Vercel Spend Management | notify、webhook、pause deploymentなどplatform-level actionを持ちます。 | per-agent request gateの代替ではありません。 |
OpenAIのrate limitやquota exceededの症状は、費用キルスイッチとは別のincident pathです。rate limitは処理量の拒否、spend kill switchは自分の予算policyによる拒否です。
プロバイダーを呼ばずにテストする
出荷前に証明すべきことは、blocked後にprovider callがゼロであることです。
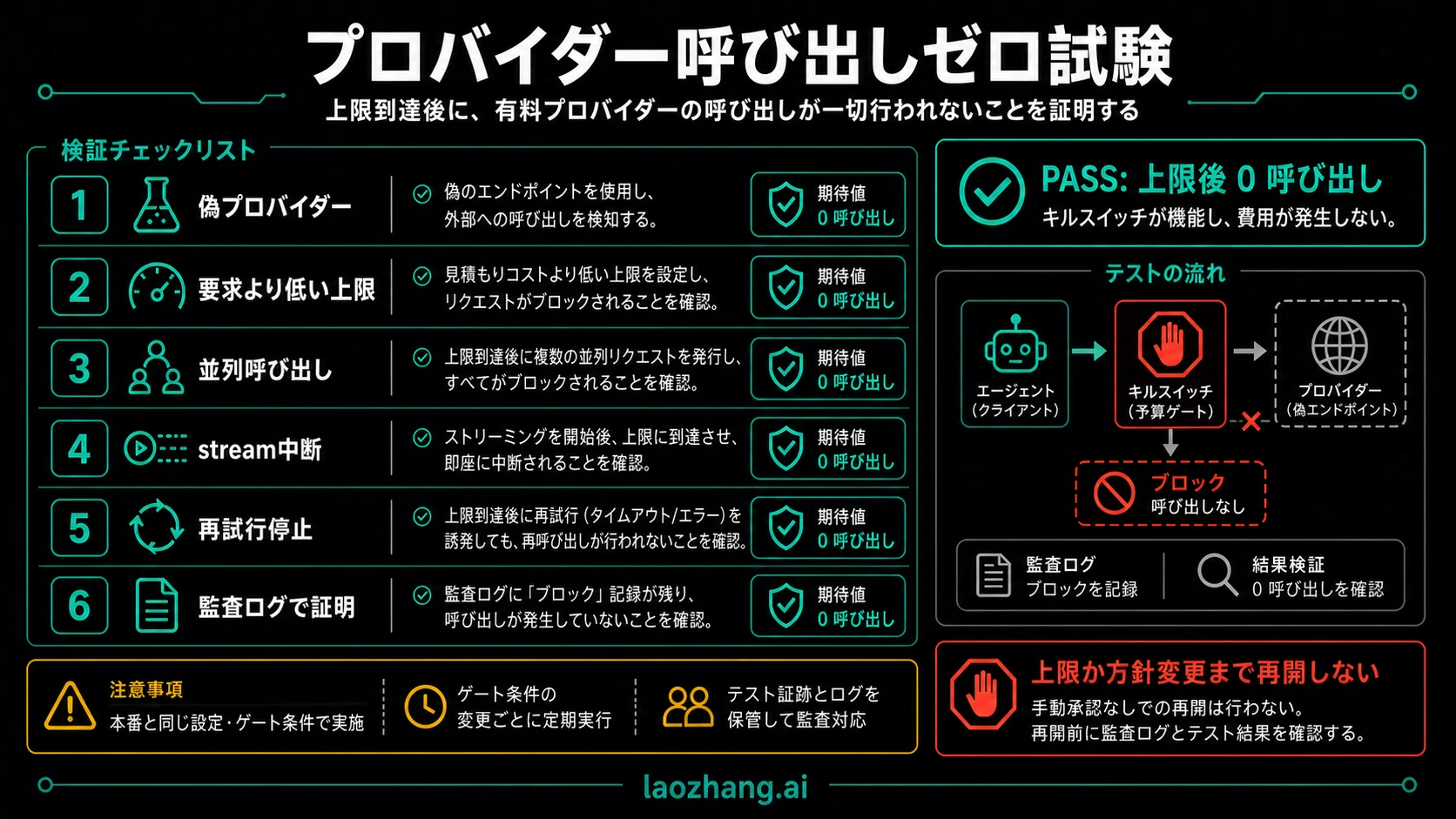
| テスト | 設定 | 合格条件 |
|---|---|---|
| fake provider | provider endpointをlocal counter serviceへ置換 | budget消費後もcounterが0 |
| cap below request | 残額をestimate未満にする | network call前にover_budget |
| parallel workers | 予約競合なら超過する数の並列requestを投げる | 予約済み分だけ通り、他はproviderへ行かない |
| streaming abort | stream途中で切断 | reconciliationまで保守的なreserveを保持 |
| retry policy | timeout、429、over_budgetを模擬 | retryableだけ再試行、over_budgetは停止 |
| audit packet | ledger、request_id、agent_run_id、reasonを確認 | operatorがブロック理由を説明できる |
価格メタデータ、model routing、retry policy、gateway設定、ledger storageを変えたら再実行してください。cap後にfake providerが1件でも受け取るなら、それはまだ監視であってキルスイッチではありません。
本番runbook
- direct provider credentialを凍結し、workerがgateを迂回できないことを確認する。
- budget scopeを確認する。user、team、project、agent run、monthly account capのどれか。
- ledgerを見る。actual、reserved、in-flight、unknown reconciliation itemを分ける。
- agentがterminal over_budgetを受け取ったか確認する。
- retry、sub-agent scheduling、tool内のmodel callを止める。
- provider logsとledgerのrequest_idを照合する。
- capを上げる、taskを狭める、runを閉じるのどれかを決める。
- human overrideなら承認者、新cap、期限、理由を記録する。
最も危険なのは「別routeで試す」ことです。provider、model、gateway、keyの変更は同じ失敗のretryではなく、新しいbudget decisionとして扱います。
よくある質問
OpenAI project budgetだけで十分ですか?
十分ではありません。本runで確認したOpenAI Help Centerの説明ではproject budgetsはsoft thresholdです。governanceやalertには有用ですが、暴走agentを止める主手段はrequest-path gateです。
HTTP 402、429、domain errorのどれを返すべきですか?
クライアントが一貫して扱えるものを選びます。ただしpayloadにはbudget cap would be exceededとretryable: falseが必要です。gatewayは429、内部runtimeはover_budgetが扱いやすい場合があります。
レスポンス前にどう費用を見積もりますか?
そのrequestに許した最大input、output、tool、image、streaming costを使います。完了後にusageで照合し、未使用予約を解放します。
provider usageが遅れて届く場合は?
reconciliationが終わるまでreserveを保持するか、unknownとして保守的に計上します。中断stream後に全額解放すると、実費未確定のままbudget windowが開きます。
sub-agentは別予算でよいですか?
子予算は持てますが、親runのcapを必ず継承します。helperが親停止後に消費を続けてはいけません。
すでにgatewayがある場合は?
まず全てのpaid model pathがgatewayを通るか確認します。その後、fake provider、low cap、parallel callsでgateway予算をテストします。迂回が閉じている時だけgateway budgetを主キルスイッチにできます。