
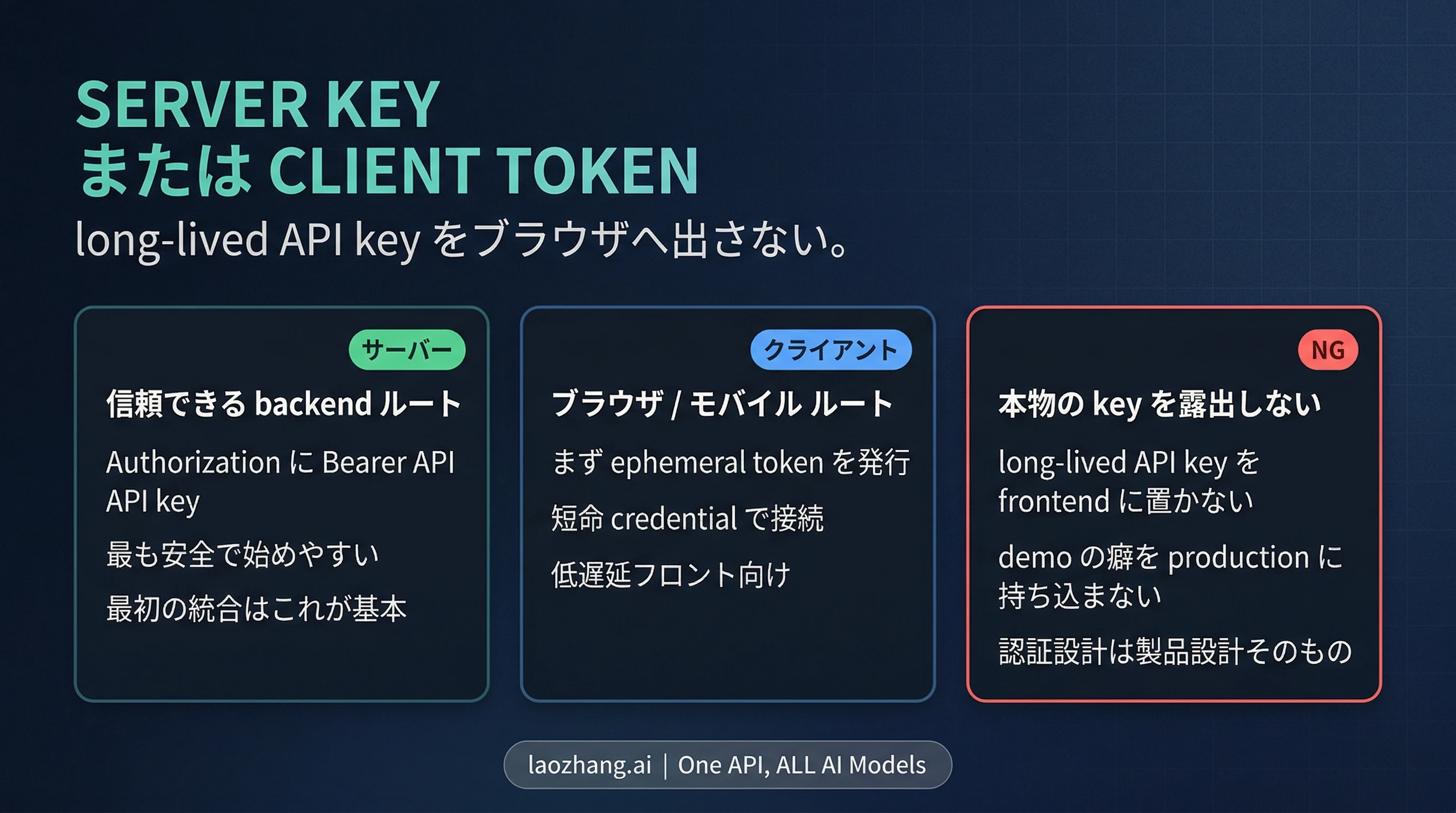
xAI の realtime voice を開発者として使いたいなら、まず押さえるべき公開入口は Grok Voice Agent API で、接続先は wss://api.x.ai/v1/realtime です。2026年4月6日 時点の公開 self-serve 情報では、$0.05 / 分、チームあたり 100 同時セッション、1 セッション 30 分までという条件が確認できます。最初に一緒に固定しておきたいのは認証の持ち方です。long-lived API key は trusted backend にだけ置き、browser や mobile は ephemeral token でつなぐ。さらに、必要なのが live conversation ではなく、最後に一度だけ音声を返すことなら、realtime loop から始めるより Text to Speech API を選ぶほうが自然です。
“本稿は 2026年4月6日 時点で、xAI の Voice Agent docs、pricing / model page、voice overview、Text to Speech docs、product page、release notes を再確認してまとめています。2026年4月20日 に STT の境界を更新しました。xAI は独立した Grok STT docs and endpoints を公開しています。
まず、どの音声ルートを使う話なのかを分ける
このテーマで一番起きやすい誤読は、Voice Agent API、TTS、STT、音声フレームワークを全部ひとつの “voice API” として読んでしまうことです。実装判断としては、まずここを分けたほうが早いです。
| いま解きたいこと | 先に選ぶべきルート |
|---|---|
| 低遅延の双方向 voice conversation を作りたい | Grok Voice Agent API |
| 最後に一度だけ音声を生成したい | Text to Speech API |
| 本当の難所が電話接続や WebRTC、media routing に移っている | 音声フレームワーク / telephony route |
| 通常の audio to text が必要 | Grok STT API |
これは言い換えの問題ではなく、そのまま設計の違いになります。turn-taking の会話、低遅延の audio 往復、会話中の tools、phone-agent 的な動作が必要なら Voice Agent API が正解です。逆に、アプリ側がすでに state を持っていて、最後に speech output を出せればよいなら TTS のほうが軽く、コストも読みやすいです。
xAI の product page には Speech to Text という言い方も出てきます。この境界は初回公開後に変わりました。2026年4月20日 時点では、xAI は独立した Grok STT route を公開しています。ファイルや audio URL は POST https://api.x.ai/v1/stt、realtime transcription は wss://api.x.ai/v1/stt です。これは Voice Agent API ではありません。STT は text を返し、Voice Agent API は live spoken session を扱います。
今の整理としては、次の三つに分けて読むのが安全です。
- Voice Agent API: live voice session 自体がプロダクト
- TTS API: 声は最後の output layer にすぎない
- Grok STT: audio to text が目的のときに使う。詳細は Grok STT API:endpoint、料金、realtime と日本語音声の確認ポイント
いま公開されている接続条件を一画面でつかむ
| 先に知っておきたいこと | 現時点の公開回答 |
|---|---|
| 公式 realtime endpoint | wss://api.x.ai/v1/realtime |
| プロダクト名 | Grok Voice Agent API |
| 公開 self-serve 料金 | $0.05 / 分($3.00 / 時間) |
| 公開されている runtime limits | チームあたり 100 同時セッション、1 セッション 30 分 |
| browser 向けの安全な認証経路 | backend が ephemeral token を発行し、client はその token で接続 |
| 最初の実装で安全な出発点 | まず backend 側で realtime session を保持する |
| 見落とされやすい費用 | tools の呼び出しは minute rate とは別課金 |
| 音声出力だけなら何を使うか | POST https://api.x.ai/v1/tts |
| self-serve の公開 region 表記 | pricing/model page は us-east-1 |
| OpenAI Realtime から来るときの読み方 | 会話の mental model は近いが、event names や細部は同じではない |
最短で動かしつつ、安全も崩さない接続順
xAI が示している最小の流れはシンプルです。
wss://api.x.ai/v1/realtimeに接続するsession.updateを送るconversation.item.createで user message を作るresponse.createで応答を要求する
trusted backend から始めるなら、最小の JavaScript は次のようになります。
jsimport WebSocket from "ws"; const ws = new WebSocket("wss://api.x.ai/v1/realtime", { headers: { Authorization: `Bearer ${process.env.XAI_API_KEY}`, }, }); ws.on("open", () => { ws.send( JSON.stringify({ type: "session.update", session: { voice: "eve", instructions: "You are a helpful assistant.", turn_detection: { type: "server_vad" }, }, }), ); ws.send( JSON.stringify({ type: "conversation.item.create", item: { type: "message", role: "user", content: [{ type: "input_text", text: "Hello!" }], }, }), ); ws.send(JSON.stringify({ type: "response.create" })); });
この始め方が強いのは、認証境界が極めて明確だからです。real key は backend にだけ置き、socket session も server 側で握る。browser audio capture や WebRTC、電話 routing、より重い orchestration は、その後に足せば十分です。
最初にやってはいけないのは、「server で動いたから同じ key を browser にも入れる」という近道です。xAI の docs は client-side apps に ephemeral token を使うよう明記しています。その public route が POST https://api.x.ai/v1/realtime/client_secrets です。backend が short-lived credential を発行し、client はそれで realtime socket を開く。browser docs では sec-websocket-protocol に xai-client-secret. の prefix を使う流れも書かれています。
ここから導ける基本ルールは次の通りです。
- まず backend から始める: 最も安全で、切り分けもしやすい
- browser / mobile から直接つなぐ: backend が ephemeral token を発行できるようになってから
早めに知っておくと助かる defaults もあります。
- turn detection の基本は
server_vad - default PCM audio は
24 kHz - supported audio formats は
audio/pcm、audio/pcmu、audio/pcma - 現在の built-in voices は
eve、ara、rex、sal、leo
これらは細かな設定一覧ではなく、この API が real voice products を想定して設計されていることを示す公開情報です。
コストの見方: minute rate は下限でしかない
公開 self-serve 情報だけを短く書けば、次のようになります。
| 項目 | 現在の公開情報 |
|---|---|
| Voice session 料金 | $0.05 / 分 |
| 時間換算 | $3.00 / 時間 |
| 同時セッション数 | チームあたり 100 |
| セッション最大長 | 30 分 |
| 公開 region | us-east-1 |
ただし、運用判断として重要なのはここから先です。xAI の voice pages で本当に大事なのは、minute rate そのものより tools の呼び出しが別課金だという点です。voice agent が function calling、web search、X search、collections、MCP-backed tools を使えば、そのコストは $0.05 / 分 には含まれません。minute rate は session floor にすぎません。
たとえば 10 分の voice session は base rate だけなら 約 $0.50 です。そこに web_search を 20 回呼び、現在の公開 price が $5 / 1,000 calls だとすると、検索だけで 約 $0.10 が追加されます。金額自体は大きく見えなくても、これで “voice app” と “audio I/O 付き retrieval agent” の economics は変わります。
公開されている tool prices には少なくとも次が含まれます。
web_search:$5 / 1,000callsx_search:$5 / 1,000callscode_execution:$5 / 1,000callscollections_search/file_search:$2.50 / 1,000calls
region の読み方も一つに潰さないほうが安全です。public pricing/model page は us-east-1 を self-serve 向けの region として示します。一方で product page は multi-region infrastructure や custom rate limits に触れます。これは同じ約束ではありません。公開の developer contract としては pricing/model page を基準にし、広い infrastructure language は enterprise 側の説明として読むべきです。
そのため最初の budgeting question は「何分しゃべるか」だけでは足りません。「平均 session が何回 tools を叩くのか、その呼び出しは毎 turn 必須なのか」まで含めて考える必要があります。

いま公開されている機能だけでも real workloads には十分届く
Voice Agent API は、見るページによって大きくも小さくも見えます。実装者にとって役に立つ読み方はもっとシンプルです。今の公開機能だけでも、かなりの real agent workloads を支えられます。
現時点の docs が明示しているのは次のような能力です。
- live two-way voice conversation over WebSocket
- built-in voices
server_vadturn handling- telephony-friendly な
μ-lawとA-lawを含む複数の audio formats web_search、x_search、file_search、remote MCP tools、custom functions- OpenAI Realtime style clients 向け compatibility entrypoint
この組み合わせだけでも、browser assistant、phone agent、support flow、retrieval-backed voice interface、operator copilot といった使い方は十分に見えてきます。ここで残したい判断は二つです。
一つ目は、tools が補助機能ではなく main route の一部だということです。
この API は「返事を声で読むだけ」の音声出力面ではありません。会話中に lookup、internal retrieval、custom function が必要な product でも、そのまま主経路として扱えるように作られています。
二つ目は、compatibility が useful でも zero-change migration ではないことです。
xAI は wss://api.x.ai/v1/realtime に base URL を変えるだけで、多くの OpenAI Realtime clients や SDKs が動くと説明しています。これは確かに強いです。ただし、同じ docs は event names の違いや unsupported events も列挙しています。わかりやすい例が response.text.delta と response.output_text.delta の違いです。
したがって移行時は次のように考えるのが実務的です。
- session 全体の mental model はかなり再利用できる
- event handling は読み替え前提で確認する
- compatibility note は入口を軽くするが、xAI 固有の差分確認をなくすわけではない
raw API ではなく、音声フレームワークを見るべきタイミング
raw API と framework を “どちらが上か” の話にするとズレます。実際には bottleneck がどこへ移ったかの話です。
いまの主な課題がまだ:
- realtime session を最小構成で通せるか
- auth boundary を安全に置けるか
- minute rate と tool cost を分けて予算化できるか
という段階なら、raw Voice Agent API のまま始めるほうがたいてい合理的です。価値検証に必要なことは、すでに十分できます。
逆に ready-made voice framework が効き始めるのは、次のようなときです。
- browser audio capture や playback pipeline そのものが重い
- phone routing、telephony、media forwarding が主問題になっている
- WebRTC や deployment topology のほうが xAI socket より難しい
xAI の voice overview は LiveKit、Twilio、WebRTC、telephony examples へ読者を導いています。これは、ボトルネックが “xAI をつなぐこと” から “media と orchestration を回すこと” へ移ったとき、framework が効いてくるというかなり明確なサインです。
実務上の分け方はこうなります。
- Voice Agent API: live conversation 自体がプロダクト
- TTS API: one-shot speech output だけが必要
- 音声フレームワーク: media plumbing、telephony、orchestration のほうが重くなった

OpenAI Realtime から来るなら、最初にここだけ確認する
xAI の compatibility note は、この API への入口をかなり軽くしてくれます。ただし、それを “drop-in compatible” の一言で済ませるのは危険です。より正確には次の四点です。
- 大きな流れは引き継げる。 stateful realtime session、streaming events、live audio、tool use という枠組みは近い。
- endpoint は変わる。 中心 contract は
wss://api.x.ai/v1/realtimeに移る。 - event names は完全には同じではない。
response.output_text.deltaとresponse.text.deltaの違いが代表例です。 - 未対応イベントもある。 xAI docs は
conversation.item.retrieveやconversation.item.truncateなどを unsupported として挙げています。
この節の価値はブランド比較ではなく、migration hygiene にあります。Realtime-oriented client architecture がすでにあるなら、xAI は確かに取り組みやすい API です。ただし、最初の production validation では socket の handshake だけでなく、event-level behavior まで見ておくべきです。
FAQ
Grok Voice Agent API の正確な endpoint は何ですか。
wss://api.x.ai/v1/realtime を使います。
公開 self-serve の料金はいくらですか。
現時点の公開情報は $0.05 / 分、時間換算で $3.00 / 時間 です。tools の呼び出しは別課金です。
browser から直接接続できますか。
可能ですが、安全な route は backend が ephemeral token を発行し、その short-lived credential で client を接続する形です。long-lived API key を browser code に置くべきではありません。
Voice Agent API と TTS API は同じものですか。
違います。Voice Agent API は live conversation 用の realtime WebSocket API、TTS API は one-shot speech generation 用の REST API です。
tools は使えますか。
使えます。xAI docs は web_search、x_search、file_search、remote MCP tools、custom functions を明示しています。
公開 self-serve の STT API はありますか。
はい。2026年4月20日時点で、xAI は Grok STT の REST route POST https://api.x.ai/v1/stt と realtime route wss://api.x.ai/v1/stt を公開しています。本稿は live spoken agent session のための Voice Agent API に絞っています。
現在の公開 limits は何ですか。
public pricing/model page は チームあたり 100 同時セッション、1 セッション 30 分までと示しています。
結論
“Grok Voice Agent API” という問いに対して役に立つ答えは、単に API が存在することではありません。もっと重要なのは、xAI が開発者向け realtime route をすでにかなり明確にしていて、今から接続を始められる一方で、最初から分けて考えるべきものもはっきりしていることです。正確な WebSocket endpoint、server key と client token の認証境界、minute rate の外側にある tool cost layer。この三つを最初に整理できるなら、live voice product の出発点として Voice Agent API は十分に使えます。単発の speech output だけなら TTS が速くて自然です。もし bottleneck がすでに media plumbing や telephony、orchestration に移っているなら、その時点で ready-made voice frameworks を検討するのがよいです。