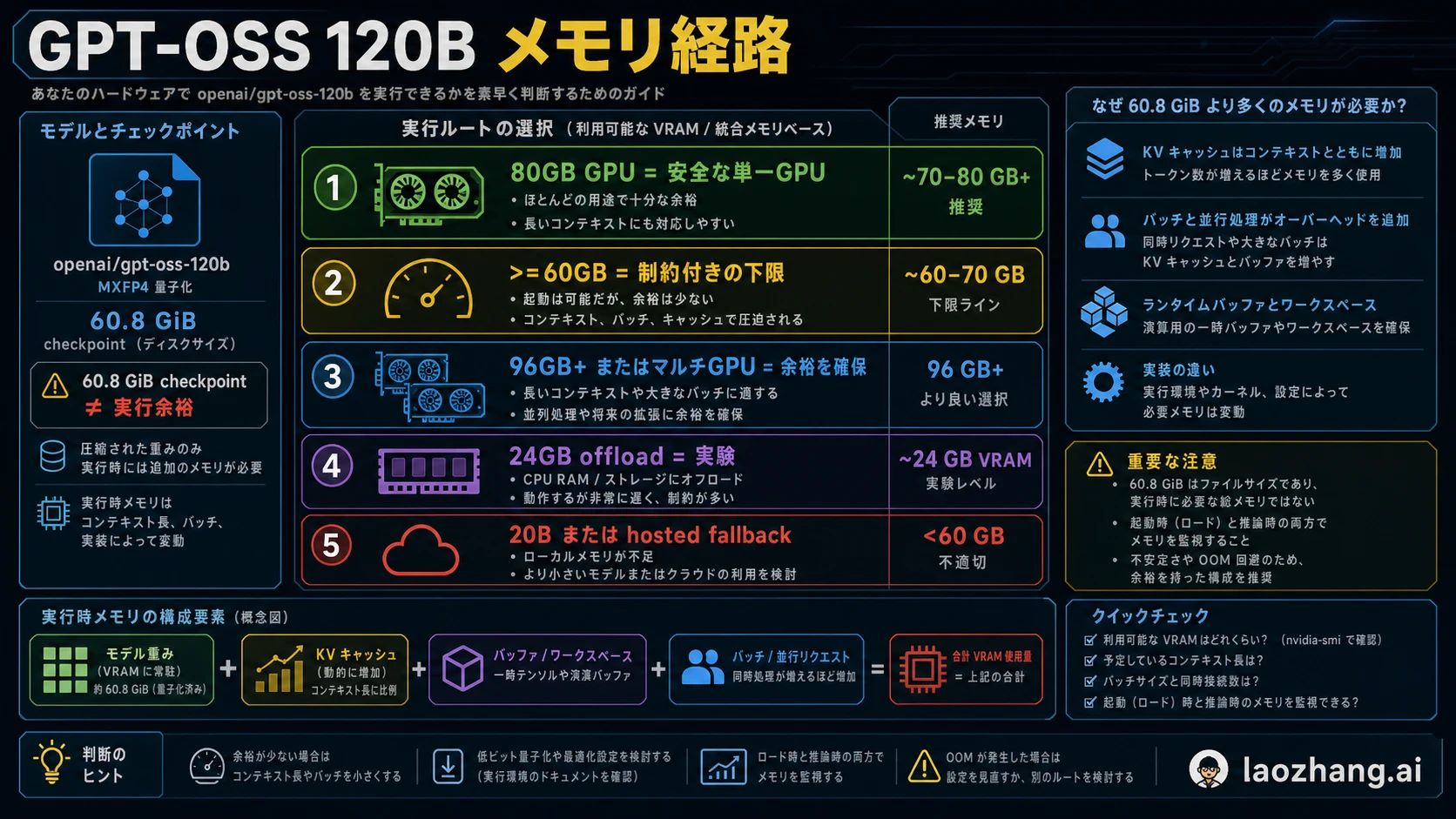
GPT-OSS 120B をローカルで安定して使うなら、まず 80GB GPU メモリ級のモデルとして考えるのが安全です。>=60GB は一部 runtime での下限に近い数字であり、60.8 GiB は checkpoint の大きさです。どちらも実行時の buffer、KV cache、長いコンテキスト、batch、並列リクエスト、CPU offload の負担までは含みません。
| ハードウェア経路 | その数字の意味 | 向いている用途 | 止めるべき合図 |
|---|---|---|---|
| 80GB GPU | 1枚で動かすためのきれいな目標 | 評価、開発、小規模な安定運用 | コンテキストと batch の余裕は別に見る |
| >=60GB VRAM または unified memory | runtime 依存の下限 | 短いコンテキストでの検証 | production headroom と呼ばない |
| 96GB+ または multi-GPU | 余裕を持つ経路 | 長いコンテキスト、throughput、OOM 回避 | sharding と KV cache を事前検証 |
| 24GB GPU と offload | 実験経路 | 読み込み検証や学習目的 | OOM または速度不足なら経路変更 |
| GPT-OSS 20B または hosted/API | fallback | 120B のローカル条件を満たさない | 早めに小型モデルか別経路へ移る |
60.8 GiB、>=60GB、80GB は同じ数字ではない
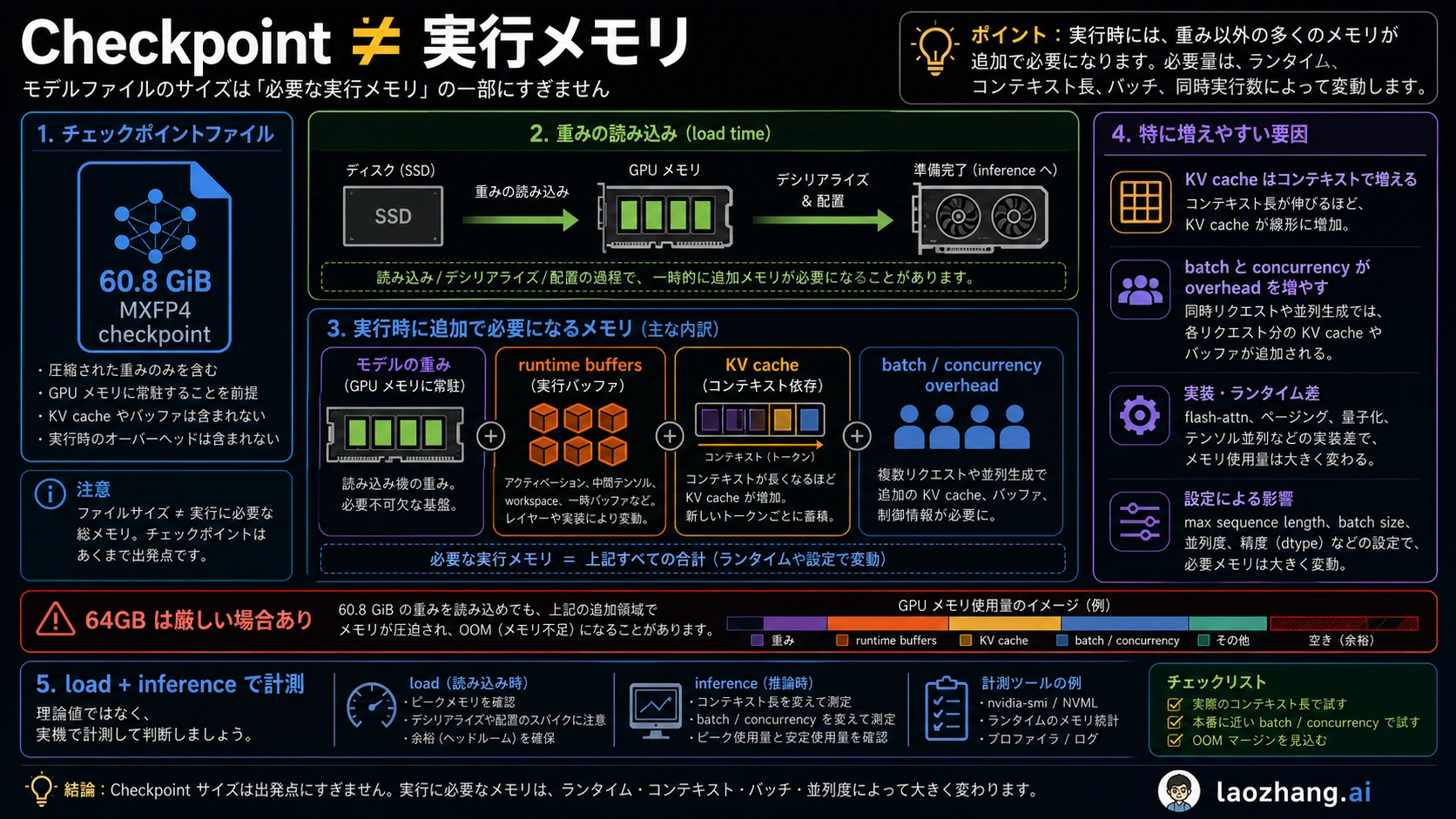
日本語のハードウェア情報では、ファイルサイズ、最低限の読み込み、実運用の余裕が同じ話として扱われがちです。最初に見るべき層は checkpoint です。OpenAI の model card では GPT-OSS 120B の MXFP4 checkpoint が約 60.8 GiB、総パラメータが 116.83B、active parameters が 5.13B とされています。これはファイルと重みの事実であり、64GB GPU が快適に動くという意味ではありません。
次の層は runtime の読み込み下限です。OpenAI Cookbook の Transformers、vLLM、Ollama の例では、>=60GB VRAM や >=60GB VRAM / unified memory という経路が出てきます。ただしこれは backend、量子化形式、context length、batch、driver、cache の条件に依存します。最低限読み込めたことと、長い prompt や複数リクエストで使えることは別です。
最後の層が実務上の目標です。OpenAI の発表では GPT-OSS 120B can run within 80GB memory とされ、Hugging Face でも H100 80GB や MI300X のような single 80GB GPU に収まるモデルとして説明されています。GPU を借りる、購入する、社内標準にする、サービス化する、という判断では 80GB が短くて安全な答えです。
この三つは矛盾ではありません。60.8 GiB は artifact、>=60GB は狭い runtime floor、80GB はより安定した計画値です。ここを分けないと、読者は 64GB や 24GB のマシンで本来は経路変更すべき作業に時間を使ってしまいます。
公式情報を基準にする
GPT-OSS 120B の必要メモリは、まず OpenAI と Hugging Face の一次情報で境界を置くべきです。Qiita、Reddit、note、PC Watch などの体験記事は実験の参考になりますが、全員に当てはまる要件ではありません。
| 事実 | 根拠の持ち主 | 判断への意味 |
|---|---|---|
| GPT-OSS 120B は 80GB memory 内で動く | OpenAI launch post | 80GB が clean single accelerator target |
| GPT-OSS 20B は 16GB memory 目標 | OpenAI launch post | 低メモリ環境の現実的 fallback |
| 60.8 GiB checkpoint | OpenAI model card | ファイルサイズであって実行余裕ではない |
| >=60GB VRAM または unified memory | OpenAI Cookbook | runtime 依存の下限がある |
| single 80GB GPU framing | Hugging Face model page と MXFP4 docs | 80GB GPU が無難な local plan |
OpenAI launch post、model card PDF、Transformers guide、Ollama guide、vLLM guide は数字の根拠です。Hugging Face の model page と MXFP4 documentation は、なぜ 120B 級の open-weight model がこの memory envelope に入るのかを説明します。コミュニティの報告は、Apple unified memory、CPU offload、複数 RTX 3090、LM Studio、Ollama などの具体例を読むために使い、公式要件の代わりにはしません。
先に runtime route を決める
メモリ要件は runtime route と切り離せません。先に経路を決めると、調整すべき対象が明確になります。
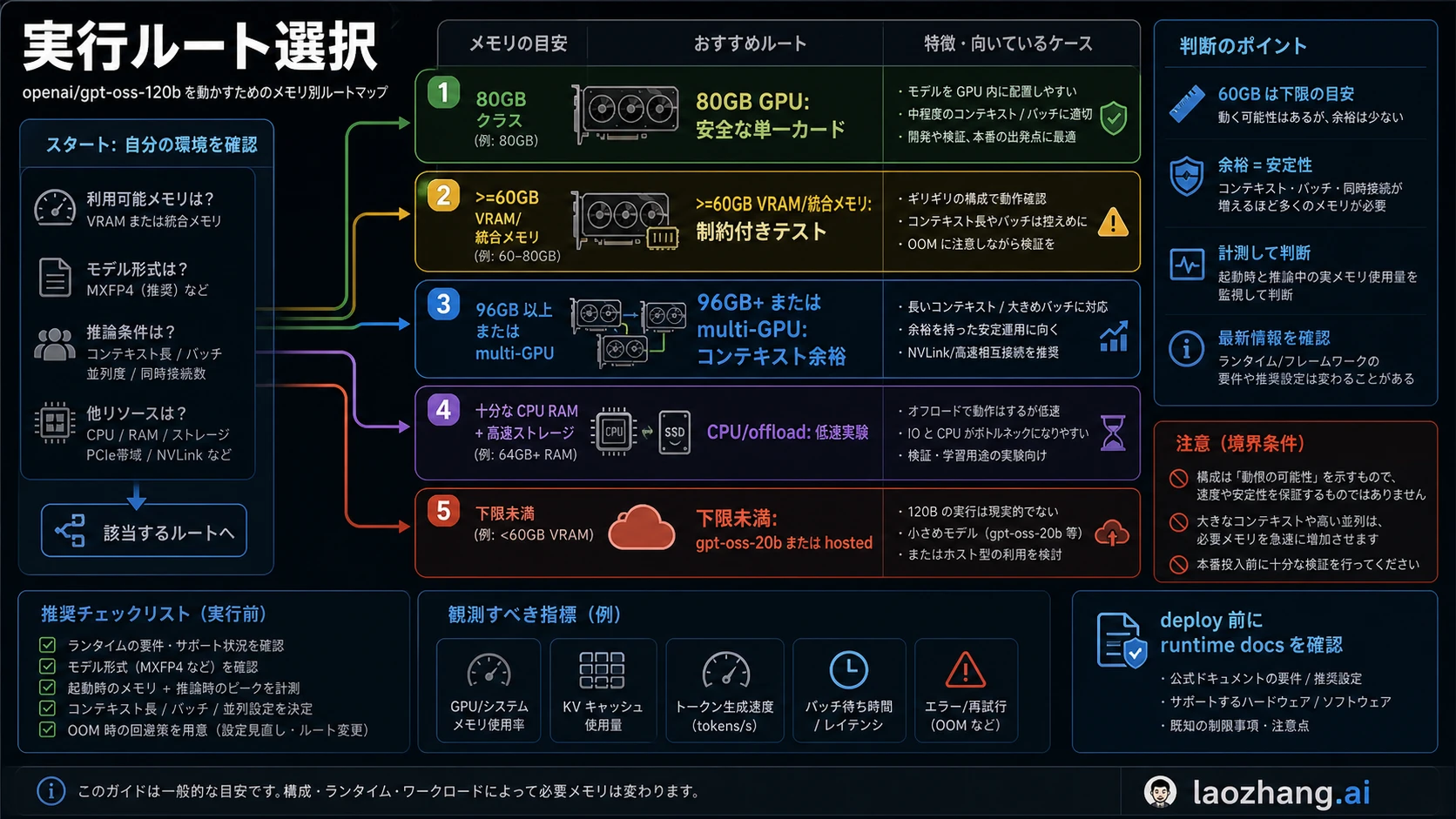
| 経路 | メモリの姿勢 | 向いている用途 | 主なリスク |
|---|---|---|---|
| 80GB GPU の Transformers | clean local route | 開発、評価、制御された検証 | context と batch の余裕が必要 |
| 80GB または multi-GPU の vLLM | serving route | throughput、API 実験、複数リクエスト | KV cache と concurrency が増える |
| Ollama と >=60GB VRAM/unified memory | low-friction local route | ワークステーションや unified memory 検証 | CPU offload で遅くなる |
| 96GB+ workstation または multi-GPU | headroom route | 長い context、安定した throughput | sharding と環境構築が難しい |
| 24GB GPU plus offload | experiment route | 学習、proof-of-load、好奇心 | 速度と文脈長が実用外になりやすい |
| GPT-OSS 20B | small fallback | 16GB から 24GB のマシン | 品質と容量は 120B と異なる |
| hosted/API | local memory を持たない | 製品組み込み、短期検証 | cost、rate limit、availability が課題になる |
モデルの品質だけを見たいなら、正しい GPU を短時間借りる方が速い場合があります。backend の挙動を学びたいなら offload 実験も価値があります。チームの運用基盤にしたいなら、最初から headroom のある経路を選ぶべきです。
VRAM、unified memory、system RAM、disk を混ぜない
VRAM は GPU 専用メモリです。H100 80GB、A100 80GB、MI300X のような話は、重み、runtime buffer、KV cache を加速器側に置けるかという問題です。速度と安定性を求めるなら、ここが最重要です。
Unified memory は CPU と GPU が共有する memory pool です。Apple Silicon や一部の workstation では大きな model を読み込む助けになりますが、帯域、backend support、offload の挙動、熱、コンテキスト長に制約があります。80GB GPU と同じ意味ではありません。
System RAM は CPU offload や hybrid inference で効きます。モデルを落とさずに動かす助けにはなりますが、多くの場合は tokens per second、loading time、安定性を犠牲にします。Disk は checkpoint、tokenizer、cache、変換済み形式を置く場所です。60.8 GiB の checkpoint は storage fact であって runtime memory fact ではありません。
KV cache と runtime buffer も忘れてはいけません。短い prompt の smoke test は通っても、長い文脈、RAG、複数ユーザー、batch serving では memory pressure が増えます。実行できることと、使い続けられることは違います。
手元のマシンをどう判定するか
80GB accelerator があるなら最も素直です。H100 80GB、A100 80GB、MI300X など、runtime が対応する 80GB 級 hardware なら GPT-OSS 120B を local evaluation や小規模 serving の候補にできます。まだ driver、CUDA/ROCm、model format、context length、batch の確認は必要ですが、最小 floor に張り付く状態ではありません。
60GB から 79GB の環境は test tier です。正しい quantized checkpoint、短い context、低い batch、特定 backend では動く可能性があります。しかし production に必要な long context、throughput、concurrency を満たすとは限りません。結果を共有するときは、GPU、runtime、model file、context、offload の有無を必ず書くべきです。
96GB+、multi-GPU、cloud GPU は headroom tier です。費用と構成難度は上がりますが、失敗コストが高い場合は余裕が必要です。長い RAG、複数ユーザー、batch evaluation、server experiments では、余分な memory は無駄ではなく保険です。
16GB から 24GB の consumer GPU は fallback または experiment tier です。GPT-OSS 20B をまず使うのが自然で、120B は offload と量子化の実験として扱います。24GB で読み込めたという話は興味深いですが、他人の購入判断には使えません。
4090、3090、5090 での stop rule
RTX 4090 や RTX 3090 は 24GB VRAM が一般的なので、GPT-OSS 120B を clean GPU-resident route として扱うには足りません。CPU offload、unified memory、短い context、特定 runtime を使えば読み込み実験はできます。しかし速度、文脈長、安定性が目的を満たさないなら、続ける意味はありません。
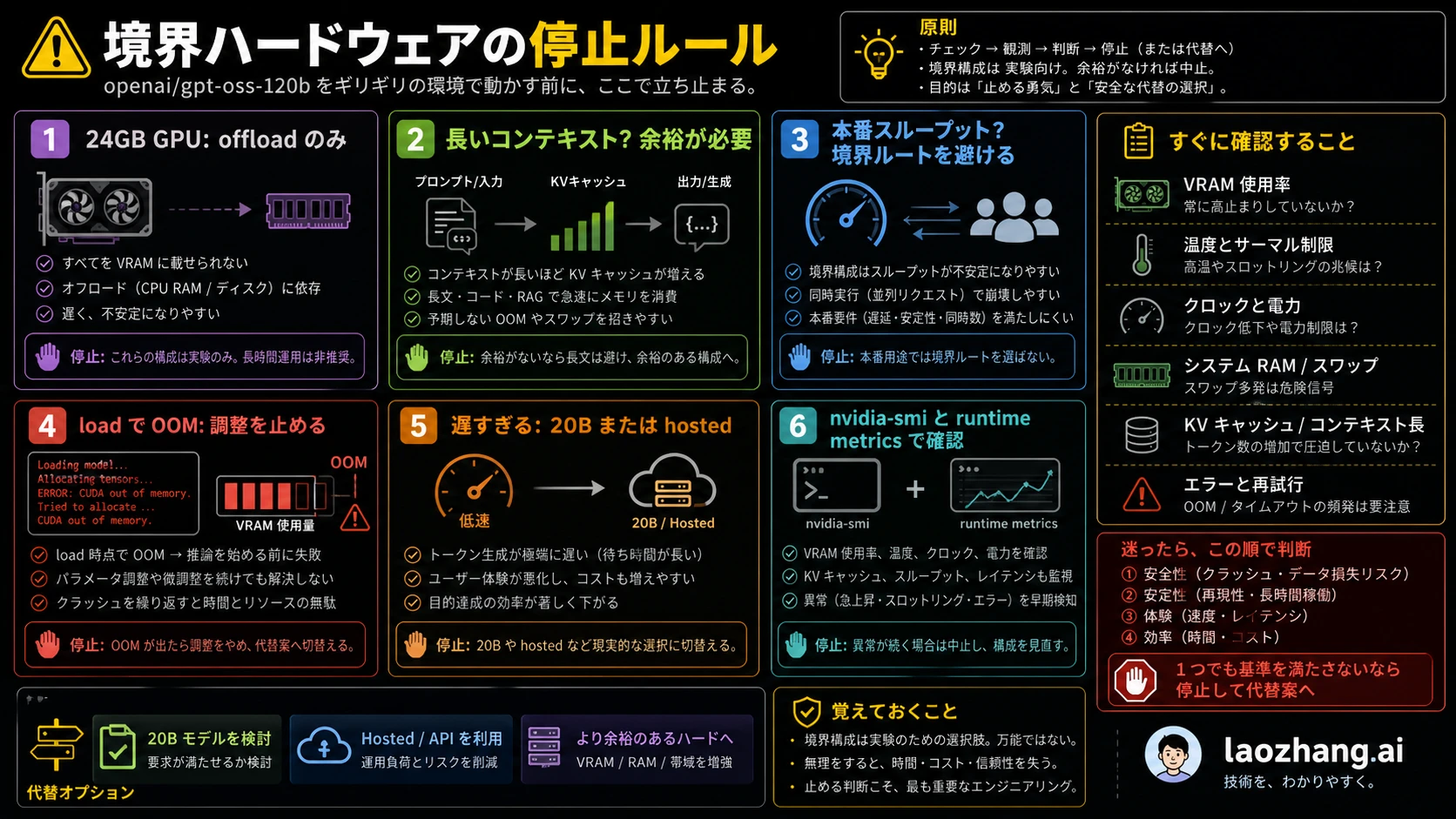
Stop rule は単純です。読み込みで OOM が続くなら経路変更。読み込めても tokens per second が実用外なら GPT-OSS 20B、cloud GPU、hosted/API へ移動。長い context が必要なら短文でしか動かない setup を採用しない。serving が必要なら heavy offload を前提にしない。好奇心だけで続けるなら、結果を experiment と明記します。
5090 でも同じです。世代が新しくても、実 VRAM が 60GB から 80GB の帯域に届かないなら clean route ではありません。compute が強くても、weights と cache を置く memory が足りなければ bottleneck は解消しません。
context length と batch が余裕を決める
十分かどうかは model load だけでは判断できません。実際に使う context length、batch size、concurrency、prompt の長さ、RAG chunk、tool call、serving framework で試す必要があります。KV cache は長い文脈ほど増え、vLLM のような serving-oriented runtime では throughput のための memory planning も必要です。
記録すべき項目は、runtime 名と version、model file、quantization、GPU、VRAM、system RAM、driver、context length、batch、concurrency、offload の有無、load 後 memory、inference peak memory、tokens per second、OOM の有無です。これがない “動いた” は体験談であって、判断材料としては弱いです。
すべての設定を最小化しないと通らないなら、それは demo route です。demo route は学習には有効ですが、社内標準、導入判断、顧客向け約束には向きません。
fallback が正しい場面
GPT-OSS 20B は低メモリ向けに存在します。OpenAI は 16GB memory 目標を示しており、laptop、consumer workstation、offline tool、quick evaluation では 20B の方が早く実用になります。能力は異なりますが、使える状態に早く到達できること自体が価値です。
Cloud GPU は 120B の品質を短時間で確かめたいときに便利です。24GB GPU で offload を何時間も詰めるより、80GB 以上の instance で本当に必要な context と speed を測る方が意思決定に向きます。Hosted/API は local hardware ownership が目的ではない場合の fallback です。ただし cost、rate limit、availability、data boundary を別途管理する必要があります。
| 本当の目的 | 向いている経路 |
|---|---|
| 自分の machine で 120B の挙動を学ぶ | constrained/offload route を experiment として試す |
| reliable local workflow を作る | 80GB+、96GB+、multi-GPU |
| 16GB から 24GB machine で使う | GPT-OSS 20B から始める |
| GPU を持たずに feature を出す | hosted/API と limit 管理 |
| 購入前に品質を比較する | 正しい GPU を短時間借りて測る |
よくある質問
GPT-OSS 120B にはどれくらい VRAM が必要ですか?
clean local answer は 80GB GPU memory です。>=60GB で動く runtime path はありますが、context、batch、backend を含めて実測する必要があります。
60.8 GiB なら 64GB GPU で十分ですか?
十分とは言えません。60.8 GiB は checkpoint size であり、runtime buffer、KV cache、context、framework overhead が別に必要です。
RTX 4090 や RTX 3090 で動きますか?
clean GPU-resident route ではありません。offload 実験は可能ですが、速度と文脈長が目的に合うかで判断します。
5090 なら動きますか?
実 VRAM と runtime support 次第です。60GB から 80GB よりかなり下なら experiment tier です。
system RAM はどれくらい必要ですか?
CPU offload や unified memory route では重要ですが、VRAM を一対一で置き換えるものではありません。実 workload で確認します。
disk space はどれくらい必要ですか?
60.8 GiB checkpoint に加え、tokenizer、cache、converted formats、作業余白を見込みます。
vLLM、Transformers、Ollama のどれを使うべきですか?
開発と評価は Transformers、serving experiment は vLLM、低摩擦な local test は Ollama が向きます。どれでも runtime と memory path を記録します。
いつ 120B を諦めるべきですか?
短い context でしか動かない、OOM 調整が続く、tokens per second が使えない、heavy offload が前提になるなら、20B、larger GPU、multi-GPU/cloud、hosted/API に移るべきです。