
「Gemini 3.1 Flash Live API」と言われたとき、開発者が実際に使うべきものは gemini-3.1-flash-live-preview というモデルで、接続先の API 面は Gemini Live API です。ここを最初に正しておかないと、名前だけ似ている別のレイヤーを追いかけて時間を失います。Google は有用な情報を複数ページに分散していて、モデルページ、Live API overview、capabilities guide、pricing、ephemeral tokens guide、そして 2026年3月26日の公式発表 を見ないと全体像が揃いません。
結論を先に書くと、今から新しく低遅延の音声エージェントを作るなら、Gemini 3.1 Flash Live から始めるのが基本です。 ただし、gemini-2.5-flash-native-audio-preview-12-2025 のそのまま置き換えではありません。Google は音声品質、会話の自然さ、運用上の余裕を押し上げた一方で、thinking の制御、サーバーイベントの構造、増分入力の送り方、tool use の挙動を変えています。2.5 側で async function calling、proactive audio、affective dialog に寄せた設計をしていたなら、移行判断は雑に済ませないほうがいいです。
“根拠メモ: 本稿は Google の公式ドキュメントと公式発表記事を 2026年3月28日 時点で再確認した内容に基づいています。Google 自身の公開ページどうしで数値や表現が揃っていない箇所は、その不一致を残したまま扱います。
TL;DR
| まず押さえるべきこと | 現在の答え |
|---|---|
| 正しいモデル ID | gemini-3.1-flash-live-preview |
| 正しい API 面 | 状態付き WebSocket の Gemini Live API |
| リリース日 | 2026年3月26日 |
| 最初に向く用途 | 低遅延・マルチモーダル・より自然な音声対話が必要なリアルタイム音声エージェント |
| 基本方針 | 新規構築なら 3.1 から始める |
| まだ 2.5 に残る主理由 | async tool calling、proactive audio、affective dialog が必要 |
| 大きな移行差分 | thinkingBudget は thinkingLevel に変わる、1イベントに複数 part が来る、リアルタイム更新は send_realtime_input へ、tool 呼び出しは同期のみ |
| 料金の形 | text input $0.75 / 1M tokens、audio input $3 / 1M tokens または $0.005 / 分、image/video input $1 / 1M tokens または $0.002 / 分、text output $4.50 / 1M tokens、audio output $12 / 1M tokens または $0.018 / 分 |
| ブラウザ向け安全策 | バックエンドで ephemeral token を発行してからクライアントを接続 |
| 隠れたコスト注意点 | 3.1 の既定 turn coverage は全 video frame を含む |
2026年3月26日に Google が出したものは何か
Google の発表記事は Gemini 3.1 Flash Live を最新のリアルタイム音声モデルとして紹介し、開発者向けには Gemini Live API 経由で preview 提供すると書いています。モデルページはさらに具体的で、モデルコードは gemini-3.1-flash-live-preview、入力は text、images、audio、video、そして目的は低遅延のリアルタイム対話、acoustic nuance detection、numeric precision、multimodal awareness にあると明記しています。
ここで大事なのは、これは独立した “Flash Live API” 製品ではないということです。Gemini Live API がリアルタイム用の API 面であり、Gemini 3.1 Flash Live はその上で動くモデルです。Live API 自体は有状態の WebSocket セッションで、割り込み、連続ストリーム、音声と映像を含む turn 管理を前提にしています。generateContent のような通常の一問一答 API と同じ感覚では扱えません。
また、これは単なる TTS モデルではありません。Google のドキュメントでは function calling と Google Search grounding がサポート対象になっているため、想定されているのは「喋るだけの音声モデル」ではなく、「聞いて、考えて、必要なら道具や検索を使い、その場で返す音声エージェント」です。モデルページには knowledge cutoff が 2025年1月 とあるので、最新情報が必要な製品なら grounding や独自 retrieval を前提にした方が安全です。
もう一つ見落としやすい点があります。モデルページには text and audio output とありますが、capabilities guide は native audio models について AUDIO response modality しか使えないと説明しています。したがって、可読なテキストが必要な場合は output audio transcription を前提に設計した方が無難です。さらに公式発表では 生成音声に SynthID watermark が埋め込まれる と書かれていて、これも配布系プロダクトでは契約条件の一部として見ておくべきです。
新規なら 3.1 でよいのか、それとも 2.5 を維持すべきか
新規開発なら 3.1 を起点にするのが妥当です。Google 自身が最新・最高品質のリアルタイム音声モデルとして位置付けており、移行ノートも 2.5 から 3.1 への移動を前提に書かれています。ただし、3.1 は 2.5 の完全上位互換ではありません。
実務的に重要なのは、いまの 2.5 システムが 3.1 にまだ存在しない性質に依存していないかどうかです。その意味で、発表文より次の比較表の方が価値があります。
| 実務差分 | Gemini 3.1 Flash Live | Gemini 2.5 Flash Live |
|---|---|---|
| モデル ID | gemini-3.1-flash-live-preview | gemini-2.5-flash-native-audio-preview-12-2025 |
| リリース / 最終更新 | 2026年3月26日リリース | 2025年9月更新 |
| 出力 token 上限 | 65,536 | 8,192 |
| thinking 制御 | thinkingLevel | thinkingBudget |
| サーバーイベント | 1 イベントに複数 part が同居可能 | 1 イベント 1 part |
| テキストの増分投入 | リアルタイムでは send_realtime_input | 会話途中でも send_client_content を使える |
| 既定 turn coverage | TURN_INCLUDES_AUDIO_ACTIVITY_AND_ALL_VIDEO | TURN_INCLUDES_ONLY_ACTIVITY |
| Async function calling | 未対応 | 対応 |
| Proactive audio | 未対応 | 対応 |
| Affective dialog | 未対応 | 対応 |
| 現時点の向き先 | 新規の voice agent | 2.5 の特性に依存する既存系 |
この比較から読み取るべきことは二つあります。
第一に、3.1 はライブ音声対話の本筋では確かに前進しています。
Google は音色理解、複雑タスク、自然な会話の改善を強調しており、output token 上限も 8,192 から 65,536 へ大きく伸びています。新規プロジェクトの起点として 3.1 を推す理由は十分あります。
第二に、既存 2.5 系の移行は“良くなるはず”で決めるべきではありません。
もし 2.5 で behavior: NON_BLOCKING のような非同期 tool 呼び出しを前提に会話を設計していたなら、3.1 にそのまま持ち込むと UX は悪化します。Google は 3.1 について 同期 tool 呼び出しのみ と明記しています。proactive audio や affective dialog も同様で、2.5 にはあった体験差を自動で引き継げるわけではありません。
整理すると:
- ゼロから作るなら 3.1
- 2.5 の本番系を持っているなら、同期化と機能欠落を受け入れられるか確認してから移る

料金は token より minute で見ると判断しやすい
今回の価格ページが役に立つのは、token 単価だけでなく minute 単価も出していることです。リアルタイム音声プロダクトではこちらの方が運用コストのイメージを作りやすいです。
| 項目 | 現在の料金 |
|---|---|
| Text input | $0.75 / 1M tokens |
| Audio input | $3.00 / 1M tokens または $0.005 / 分 |
| Image/video input | $1.00 / 1M tokens または $0.002 / 分 |
| Text output | $4.50 / 1M tokens |
| Audio output | $12.00 / 1M tokens または $0.018 / 分 |
| Google Search grounding | Gemini 3 共有で月 5,000 prompts 無料、その後 $14 / 1,000 query |
ここからすぐに現実的な試算ができます。双方向で音声が流れる会話なら、audio input と audio output の minute 料金を足して 1 分あたり約 $0.023 です。10 分の通話なら音声だけで 約 $0.23。これは Google の文面そのままではなく、公開されている $0.005 / 分 と $0.018 / 分 からの直接計算です。
Search grounding も無視しない方がいいです。無料共有枠を超えると 1 query あたり 約 $0.014。1 セッション中に 5 回検索すれば 約 $0.07 上乗せされます。
そして一番見落としやすいのが video です。3.1 の移行ノートでは、既定 turn coverage が all video を含むようになったと説明されています。つまり、音声が主で video は補助なのに、旧コードの癖で映像を流しっぱなしにすると、3.1 ではコストが膨らみやすいです。
なお、Google は Gemini 3.1 Flash Live の正確な RPM / RPD を公開ドキュメント上に固定していません。rate limits ページは AI Studio で active rate limits を確認するよう案内しています。ここは無理に“見た目の良い数字”を記事に書かず、料金は公開ページ、容量は AI Studio の実値で見るのが正解です。
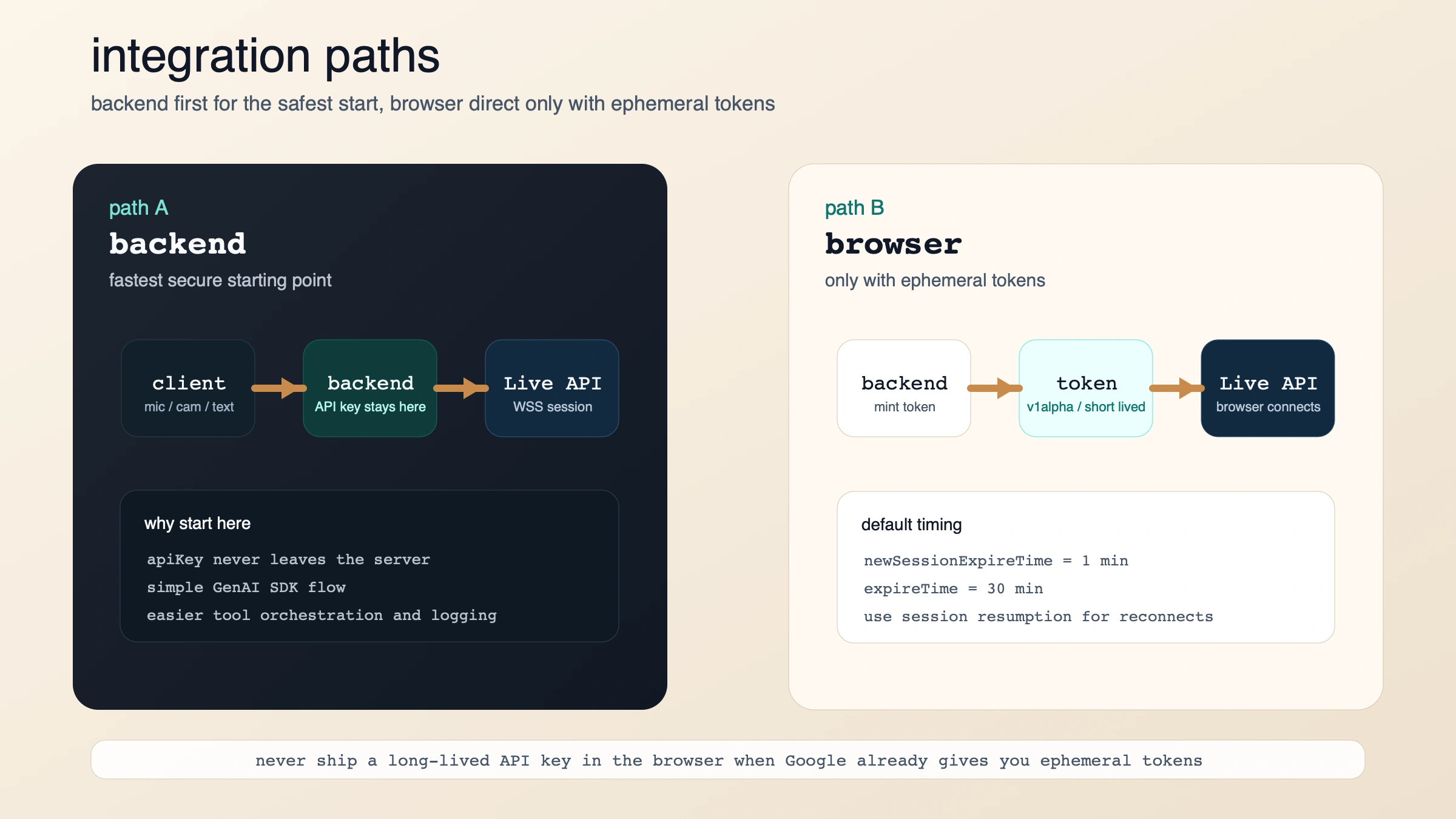
最短で動かすなら backend first、browser direct はその後
最初に成功させるだけなら、server-to-server が一番簡単です。Live API overview もこの形を基本としていて、capabilities guide のサンプルも Live 接続 → AUDIO 指定 → send_realtime_input という流れです。
pythonimport asyncio from google import genai client = genai.Client() MODEL = "gemini-3.1-flash-live-preview" async def main(): config = {"response_modalities": ["AUDIO"]} async with client.aio.live.connect(model=MODEL, config=config) as session: await session.send_realtime_input( text="Say hello and introduce yourself in one sentence." ) async for response in session.receive(): if response.server_content and response.server_content.model_turn: for part in response.server_content.model_turn.parts: if part.inline_data: audio_bytes = part.inline_data.data # audio_bytes を再生または転送 if response.text: print(response.text) if response.server_content and response.server_content.turn_complete: break asyncio.run(main())
本番に近づける段階では、音声形式も要注意です。Google の説明では入力は 16-bit PCM / 16kHz / little-endian、MIME type は audio/pcm;rate=16000 のような形です。出力音声は 24kHz PCM。さらに音声のみのセッションは 15 分、音声 + 動画は 2 分 という制限があるので、長時間対話にするなら session management / resumption を追加します。
ブラウザ直結が必要な場合、Google の答えは ephemeral tokens です。これは “API key をフロントに置かずに低遅延を取る” ための仕組みです。デフォルトでは:
- 1 分 以内に新規セッションを開始
- 開始後は通常 30 分 メッセージ送信可能
- クライアントはその token を API key のように 使う
- 再接続には session resumption を使う
したがって実装判断はこうなります。
- backend only: 最も安全で速い
- browser direct: バックエンドで ephemeral token を発行できるときだけ使う
最初の一日を無駄にしがちな移行ミス
2.5 から 3.1 への移行で厄介なのは、全部が大きく壊れるわけではなく、“なんとなく動くが正しくない” 状態が多いことです。
1. thinkingBudget を送らない。
3.1 は thinkingLevel です。しかも既定値は minimal で、低遅延を優先します。
2. 1 イベントのすべての part を読む。
3.1 では音声チャンクと transcript が同時に入ることがあります。古いパーサーのままだと静かに情報を落とします。
3. リアルタイム更新は send_realtime_input に寄せる。
2.5 の感覚で send_client_content を会話途中に使い続けると、挙動が噛み合わなくなります。
4. tool 呼び出しは同期前提で設計する。
3.1 では model が tool response を待ってから続行します。2.5 の非同期 tool loop をそのまま持ってくるのは危険です。
5. proactive audio / affective dialog の設定を残さない。
未対応機能の設定を残すと、デバッグ対象が増えるだけです。
6. video は必要時だけ送る。
all video が既定なので、映像を常時送る設計はそのままコスト設計になります。
7. テキストは transcript として扱う。
モデルページと capability ページの表現差を埋めるなら、この理解がいちばん安全です。
Gemini 3.1 Flash Live を選ばない方がいいケース
そもそもリアルタイム音声が主役でないなら、Live API は重いです。
WebSocket、PCM、割り込み、ephemeral token は、voice-first でこそ意味があります。
現行 2.5 で async tools が効いているなら、3.1 はまだ早い可能性があります。
音声品質の向上が、そのまま製品価値の向上に直結するとは限りません。
ephemeral token を安全に出せないなら、ブラウザ直結を急がない。
その場合は Live セッションをバックエンドに置く方が素直です。
必要なのが TTS だけなら、会話型 Live モデルは過剰です。
Gemini 3.1 Flash Live は対話とツール利用を含む厚い契約のモデルです。

FAQ
正しいモデル ID は?
gemini-3.1-flash-live-preview です。
もう GA ですか?
いいえ。2026年3月時点では preview です。
Tools と Google Search は使えますか?
使えます。ただし tool 呼び出しは 同期のみ です。
ブラウザから直接つなげますか?
はい。ただし本番ではバックエンドで ephemeral token を発行してから接続するのが推奨です。
セッション時間の上限は?
音声のみで 15 分、音声 + 動画で 2 分。より長くしたいなら session management を入れます。
返ってくるのは音声だけですか?
Google の公開ページには揺れがありますが、実装上は AUDIO response modality を前提にし、必要なテキストは transcription として扱う のが安全です。
生成音声には watermark がありますか?
あります。公式発表では SynthID watermark が入るとされています。
移行判断を一文で言うと?
新規の音声エージェントなら 3.1、ただし既存 2.5 系で async tools / proactive audio / affective dialog が重要なら、先に移行コストを精査してからです。