
Claude Sonnet 4.6 は、特定の自己識別プロンプトで自分を DeepSeek と答えることがあります。とくに、中国語の短い質問で identity anchor が弱いときに起きやすいように見えます。ここで最も役に立つ読み方は、これを弱い prompt boundary による自己識別の混乱として理解することです。Anthropic が Sonnet を DeepSeek に差し替えたと即断したり、1 枚のスクリーンショットで蒸留まで証明されたと扱ったりするのは早すぎます。
“この記事は Anthropic の公開 models overview、Claude 4.6 overview、system prompts、release notes、そして Anthropic の 2026 年 2 月 23 日の distillation post、OpenRouter の provider routing docs、公開されたコミュニティ事例をもとに整理しています。
TL;DR
- はい、この DeepSeek 自称は説明する価値がある程度には実在的です。 公開スレッドには、Claude Sonnet 4.6 が「自分は何のモデルか」と聞かれて DeepSeek と答える例が複数あります。
- ただし、それは Sonnet 4.6 が実際には DeepSeek だという意味ではありません。 Anthropic の公開文書は、Sonnet 4.6 を現在の Claude モデルとして
claude-sonnet-4-6の alias 付きで掲載し続けています。 - 現時点で最も強い説明は、prompt と surface の境界の弱さです。 Anthropic 自身が、claude.ai / mobile には system prompt があり、API にはその更新が適用されないと書いています。
- Anthropic の DeepSeek 批判は optics を強くしますが、証明基準を下げてはくれません。 だからこそスクリーンショットは強く拡散しましたが、それでも provenance test にはなりません。
- モデルの正体を確かめたいなら、自称ではなく route を見るべきです。 model ID、provider lock、system prompt、surface 差分を確認してください。
まず確認できる事実
この話で最も大切なのは、観測された応答と公開されているモデル契約を分けることです。前者は対話の中でモデルが返した文章であり、後者は Anthropic がどのモデルを提供していると公表しているかです。同じではありません。
2026 年 4 月 1 日時点で、Anthropic の models overview は Claude Sonnet 4.6 を現行の公開モデルとして掲載し、その API alias を claude-sonnet-4-6 としています。release notes でも、Sonnet 4.6 の公開日は 2026 年 2 月 17 日です。つまり Sonnet 4.6 は rumor 名ではなく、Anthropic が公に出している shipping model です。
もう一つ確認できるのは、Anthropic が 2026 年 2 月 23 日に DeepSeek を名指しして distillation attack を主張したことです。Anthropic の distillation post は、DeepSeek 関連のキャンペーンに 150,000 以上の exchanges があったと書いています。この文脈があるからこそ、Claude が DeepSeek と名乗るスクリーンショットは普通のバグ以上の意味を帯びます。
一方で、Anthropic はこの自己識別現象について、公開の help-center 記事や release note で根因を説明していません。つまり安全な記事の形は 公式契約 -> 観測された挙動 -> 推論 の順で書くことです。いきなり Anthropic が認めた bug のようには書けません。
なぜ Sonnet 4.6 は DeepSeek と答えうるのか

この現象を最もよく説明するのは、一つの陰謀ではなく、いくつかの小さい事実の重なりです。
第一に、identity anchor の差があります。Anthropic の system prompts には、Claude の web と mobile には system prompt があり、その更新は API には適用されないと明記されています。つまり同じ「あなたは何のモデルですか」という問いでも、surface ごとに異なる envelope に入ります。
第二に、multilingual completion の問題があります。公開例は 你是什么模型? のような中国語の短い prompt に強く偏っています。これは、モデルの identity が十分に固定されていないとき、既知の自己紹介パターンを completion しやすいことを示唆します。ここは Anthropic の公式説明がないので、推論として書くのが正しい態度です。しかし、それでも だから本体が DeepSeek だ と飛躍するよりははるかにましです。
第三に、routing と wrapper の層があります。OpenRouter の provider routing docs は、デフォルトで price-based load balancing や fallbacks がありうることを説明しています。gateway 経由では、モデル本体の外側に provider 選択ロジックが乗ります。すべてのケースをこれだけで説明することはできませんが、少なくとも どの surface で起きたのか が本質情報であることは分かります。
だから一番重要な結論はこうです。モデルは自己識別に失敗しても、その時点で別のモデルになったわけではない。 弱い identity anchor と短い self-ID prompt の組み合わせでは、モデル自身の self-description は想像以上に弱いシグナルです。
この回答がまだ証明しないこと

この現象から引き出されがちな過剰結論は主に三つあります。
一つ目は Claude Sonnet 4.6 は実は DeepSeek だ というものです。これは強すぎます。Anthropic の公開モデル契約は依然として Sonnet 4.6 を Claude として扱っており、self-description の失敗だけでそれを覆すことはできません。
二つ目は Anthropic が別 provider を黙って混ぜている というものです。gateway 側の routing が一部の事例に影響している可能性はありますが、公開議論の一部は Anthropic の公式 API でも再現したと主張しています。つまり 全部 OpenRouter のせい と言い切るのも、逆に Anthropic は Claude を出していない と飛ぶのも、どちらも雑です。
三つ目は これで Anthropic が DeepSeek の出力を学習に使ったことまで証明された というものです。これもまだ強すぎます。スクリーンショットが示すのは、競合モデルの identity pattern が弱い prompt 条件で浮上しうることです。そこから具体的な training pipeline や illicit distillation を証明するには、もっと硬い provenance evidence が必要です。
要するに、このスクリーンショットは面白く、しかも痛い現象ですが、それだけで最終結論にはなりません。価値があるのは 何が観測され、何が未証明か を分けることです。
どうやってモデル identity を検証すべきか
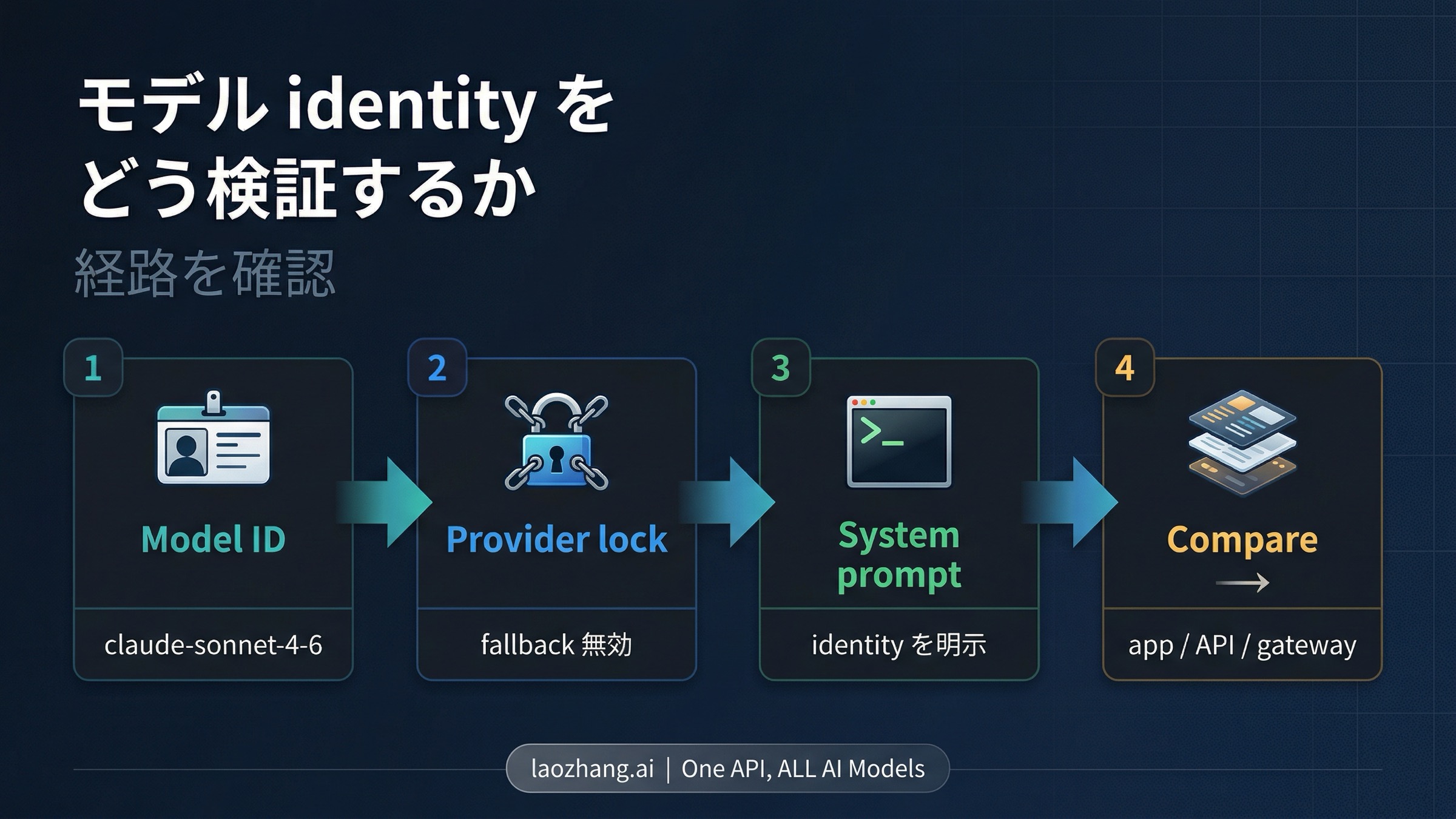
モデルの正体を本当に確かめたいなら、あなたは誰ですか と聞くのは最弱のテストです。より良い順序は次の通りです。
- model ID を先に見る。 現行の Sonnet 4.6 なら
claude-sonnet-4-6です。まず request で何を指定したのかを確認します。 - gateway を使うなら provider lock をかける。 fallback を切るか、provider を明示して、routing の曖昧さを減らします。
- system prompt に identity anchor を入れる。 これはモデルに嘘を言わせるためではなく、テスト条件を過度に曖昧にしないためです。
- surface を跨いで比較する。 claude.ai、Anthropic API、実際に使っている gateway で同じ質問を試し、違いを確認します。
- 条件を記録する。 request model、provider 設定、fallback、system prompt、言語。この情報なしでは再現性ある判断になりません。
この workflow の価値は、議論を 怖いスクリーンショット から この route と条件ではこう出る へ変えることにあります。そこまで行けば、ようやく engineering judgment が可能になります。
それでも Anthropic vs DeepSeek の文脈が重要な理由
このスクリーンショットが強いのは、Anthropic 自身が DeepSeek を名指ししていたからです。Anthropic は DeepSeek に capability extraction を行ったと主張し、その直後に Claude 側で DeepSeek self-ID 現象が出た。これは当然、強い irony として読まれます。
しかし、ここから得るべき教訓は Anthropic の主張は全部無効だ ではありません。むしろ、競合モデルの identity pattern が出ることと、その provenance が完全に証明されることは別だと理解するほうが有益です。スクリーンショットは optics として強い。だからこそ、なおさら proof threshold を下げてはいけません。
FAQ
Claude Sonnet 4.6 は本当に DeepSeek と言うのですか。
はい。公開事例は十分あり、現象として説明する価値があります。ただし Anthropic からの公式 root-cause note はありません。
それは Sonnet 4.6 が実際には DeepSeek だという意味ですか。
いいえ。Anthropic の公開契約は依然として Sonnet 4.6 を Claude モデルとして扱っています。
これは OpenRouter だけの問題ですか。
そう断定はできません。routing は一部のケースで要因になりえますが、公開議論には公式 API 由来だという主張もあります。
これで Anthropic の蒸留が証明されたのですか。
いいえ。観測された挙動と training pipeline の証明は別レイヤーです。
最終判断
Claude Sonnet 4.6 が DeepSeek と名乗ることがあるのは、モデル identity が想像以上に surface と prompt boundary に依存しているからだと考えるのが最も妥当です。Anthropic 自身の docs は、web / mobile と API が同じ prompt envelope ではないことを示しています。そこに multilingual completion と gateway routing の要素が重なると、DeepSeek self-ID は 秘密の告白 というより identity-layer の弱点 として読めるようになります。
これは Anthropic にとって十分に痛い optics です。しかし、より責任ある結論はなお変わりません。モデルの self-introduction は provenance API ではない。 本当に確かめたいなら、model contract、provider path、prompt envelope を見るべきです。