
Claude Opus 4.6 が急に悪くなったように感じても、まず「Anthropic が公式に model を弱くしたのか」と考える必要はありません。2026年4月10日時点で、Anthropic の official docs と status history は universal downgrade を確認していません。むしろ先に切り分けるべきなのは、thinking mode mismatch、長い会話の文脈処理、shared usage pressure、そして claude.ai・Claude Code・Desktop・API の route difference です。
最初の一手はシンプルです。一つの surface を固定し、fresh session を開き、一回に一つの変数だけ変えます。prompt、model、thinking setting、route を同時に動かさないでください。branch-specific control test の後でも同じ task が浅い、忘れっぽい、あるいは不安定なままなら、そこで初めて repeatable issue として evidence を残す価値が出てきます。
確認メモ: Opus 4.6 関連の release notes、extended thinking help、usage and length limits help、現在の product behavior は 2026 年 4 月 10 日に再確認しました。この話題は記憶ではなく current surface behavior に依存するためです。
まず downgrade 議論ではなく、どの枝にいるかを決める
「Opus 4.6 が劣化した」という言い方は一つの症状に見えますが、実際には別の owner を持つことが多いです。
| 見えている症状 | いちばん可能性が高い枝 | 最初の一手 | 何が確認材料になるか |
|---|---|---|---|
| claude.ai で難しい task が急に浅い | thinking mode mismatch | 新しい chat で同じ task を explicit thinking で試す | thinking を固定すると quality が戻る |
| 長い thread が instructions や prior decisions を落とし始める | 文脈処理 | 短い handoff で新しい scoped session を作る | 新しい session では重要な制約が保たれる |
| heavy-use の日だけ全体に悪く感じる | shared usage pressure | usage state を見て cleaner window で同種 task を再試行する | 低 pressure では挙動が安定する |
| claude.ai、Claude Code、Desktop、API の感じが大きく違う | route differences | one route に固定して same-task を比較する | fixed route では結果が読みやすくなる |
この split が大事なのは、早く正しい first move に着けるからです。文脈の問題なのに prompt を磨き続けてもノイズが増えるだけですし、route difference なのに benchmark を眺めても diagnosis は進みません。
2026年の公式な変化で、体感が変わりやすくなった点
Anthropic の release notes によれば、Claude Opus 4.6 は 2026年2月5日に登場しました。API 側では adaptive thinking と effort が現在の reasoning control として示されています。一方で consumer chat 側では extended thinking が optional mode として扱われています。つまり API と claude.ai で、thinking の surface behavior は最初から同じではありません。
さらに Anthropic の current help pages は、extended thinking の on/off でも、新しい model version への切り替えでも新しい chat が始まると説明しています。多くの人が「同じ task を before/after 比較している」と思っていても、実際には long thread と fresh chat を比べていたり、different thinking state を比べていたりします。
文脈の扱いも同様です。Anthropic は長い conversation で earlier messages を summary 化すると説明し、API では compaction という別の mechanism を公開しています。これらは diagnosis に効く official facts ですが、それ自体は universal downgrade の証拠ではありません。
thinking mismatch は「劣化した」ように見えやすい
「最近 answer が浅い」という complaint では、最初に benchmark より thinking behavior を疑うべきです。Claude chat の extended thinking と API 側の adaptive thinking は、どちらも reasoning depth に関係しますが、同じ default でも同じ contract でもありません。
そのため、thinking を固定しない比較はすぐに misleading になります。ある session は素早く返し、別の route では深く考える。その差をそのまま「モデルが悪くなった」と読むと、route と setting の違いを model regression に誤読しやすくなります。
最も useful な control test は単純です。難しい task を一つ選び、one route を固定し、新しい session で explicit thinking 付きの比較をする。これで gap が縮むなら、diagnosis は downgrade より thinking mismatch に近いです。
長い thread の context drift は、能力低下と同じではない

二番目に多い complaint は shallow answer ではなく、「急に文脈を落とす」ことです。Anthropic の current docs は、consumer chat で earlier messages が summary 化されること、API で compaction があることを明記しています。長い session では、最初の state と同じ形で文脈が残っているとは限りません。
だから「忘れた」と「model が弱くなった」を同じ意味で扱うべきではありません。session が長くなるほど、あなたは別の context regime で比較している可能性が高くなります。重要な条件が summary の中でしか残っていないなら、同じ task でも体感は変わります。
ここでの first fix は長い mega-prompt ではなく clean handoff です。目的、守るべき条件、必要な files だけを短く渡し、新しい scoped session でやり直す。それで behavior が改善するなら、route は context-handling 側にあります。
shared usage pressure は比較条件そのものを歪める
Anthropic は claude.ai、Claude Code、Claude Desktop が同じ usage pool を共有すると説明しています。さらに headroom は model、feature、file size、conversation length に依存します。これだけで heavy-use day と light-use day の体感が変わるには十分です。
重要なのは、ここから unsupported な主張に飛ばないことです。公式 docs は「usage が高いと Opus を意図的に弱くする」とは言っていません。ただ、比較している conditions が同じでないなら、体感差をそのまま model quality difference と読むべきでない、というところまでは支えています。
だから最初にやるべきなのは usage state を見て、cleaner window で同種 task をもう一度試すことです。もし問題が heavy-use condition のときにだけ強いなら、それは diagnosis-first で扱うべきです。より broad な shared-usage の説明が欲しいならClaude の daily limit ガイド、Code 側の usage pain ならClaude Code usage limits ガイドに進む方が自然です。
claude.ai・Claude Code・Desktop・API は一つの体験ではない

多くの confusion は、複数の execution surfaces を一つの Claude story にまとめてしまうところから始まります。Claude chat は model switching、extended thinking、conversation handling の product behavior を持ちます。Claude Code は tools と repo context を持ち込みます。Desktop も consumer chat に近いですが、完全に同じではありません。API には独立した thinking controls、long-context contract、compaction surface があります。
だから same-task でも、surface をまたいだ比較は very noisy になりやすいです。Claude Code だけで悪く見える complaint は tool-heavy workflow や old session を説明しているかもしれませんし、API と chat の差は different route logic を表しているかもしれません。どちらも本物の experience ですが、自動的に universal downgrade を意味しません。
公平な比較は one fixed route でしかできません。surface と context state を固定し、それでも問題が残るなら serious issue の可能性が上がります。route をまたいだままの comparison では、結論よりノイズの方が増えます。
一番速い recovery order
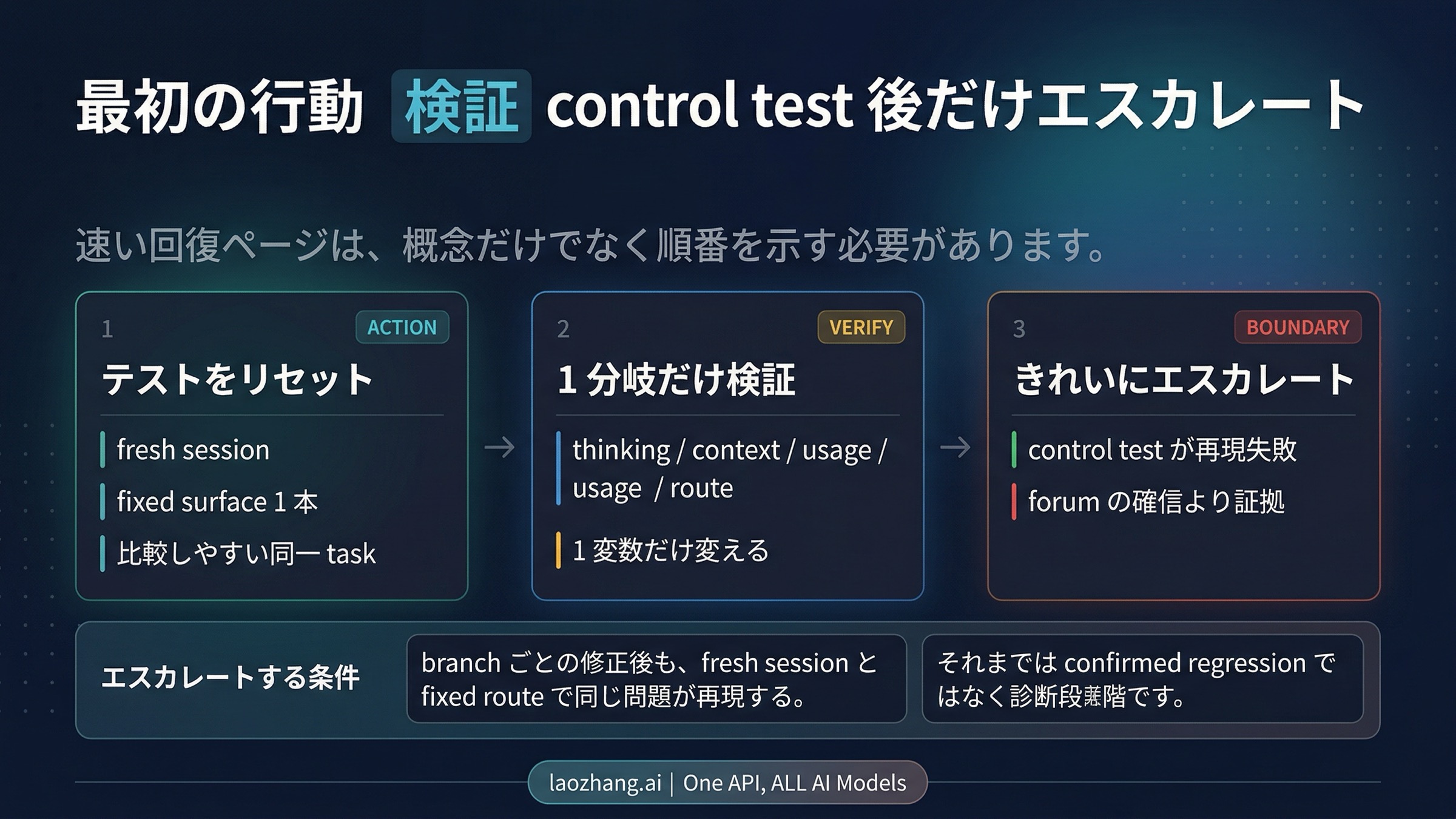
このページでいちばん重要なのは理論より順番です。
- 一つの surface を固定する。
chat、Code、Desktop、API を同時に混ぜて比べない。 - fresh session を作る。
old context は diagnosis を一気に濁らせます。 - thinking を explicit にする。
default behavior を推測しない。 - 一度に一つの変数だけ変える。
route、thread age、thinking setting を同時に動かさない。 - usage pressure を確認する。
heavy-use day なら cleaner window で再試行する。 - repeatable failure だけを escalation する。
悪い一日と再現可能な issue は別です。
route を変えるべきとき、model を変えるべきとき、escalation すべきとき
surface を変えるのは、evidence が route-specific problem を示してからです。model を変えるのは、その前ではありません。thinking mismatch や context drift を片付ける前に model switch すると、原因が隠れるだけです。
escalation が必要なのは、one fixed route で、fresh-session control test を通しても、branch-specific fix をしても、同じ task が disproportionate に失敗し続けるときです。そのときは surface、session が新規か resumed か、thinking setting、ざっくりした usage state、再現 task を一緒に残してください。
FAQ
Anthropic は Claude Opus 4.6 の official downgrade を認めていますか。
いいえ。2026年4月10日時点で official docs と status history は universal downgrade を確認していません。
長い thread で context を忘れるのは、model が弱くなった証拠ですか。
必ずしもそうではありません。consumer chat の summary 化と API の compaction という current behavior を 먼저疑う方が自然です。
Extended thinking と adaptive thinking は同じですか。
同じではありません。consumer chat と API の surface behavior は別に扱うべきです。
なぜ claude.ai と API は別の product のように見えるのですか。
そもそも route が違うからです。thinking controls も context contract も同じではありません。
いつ prompt tuning をやめて escalation に移るべきですか。
one fixed route で fresh-session control test を行い、branch-specific fix でも改善しない repeatable issue になったときです。