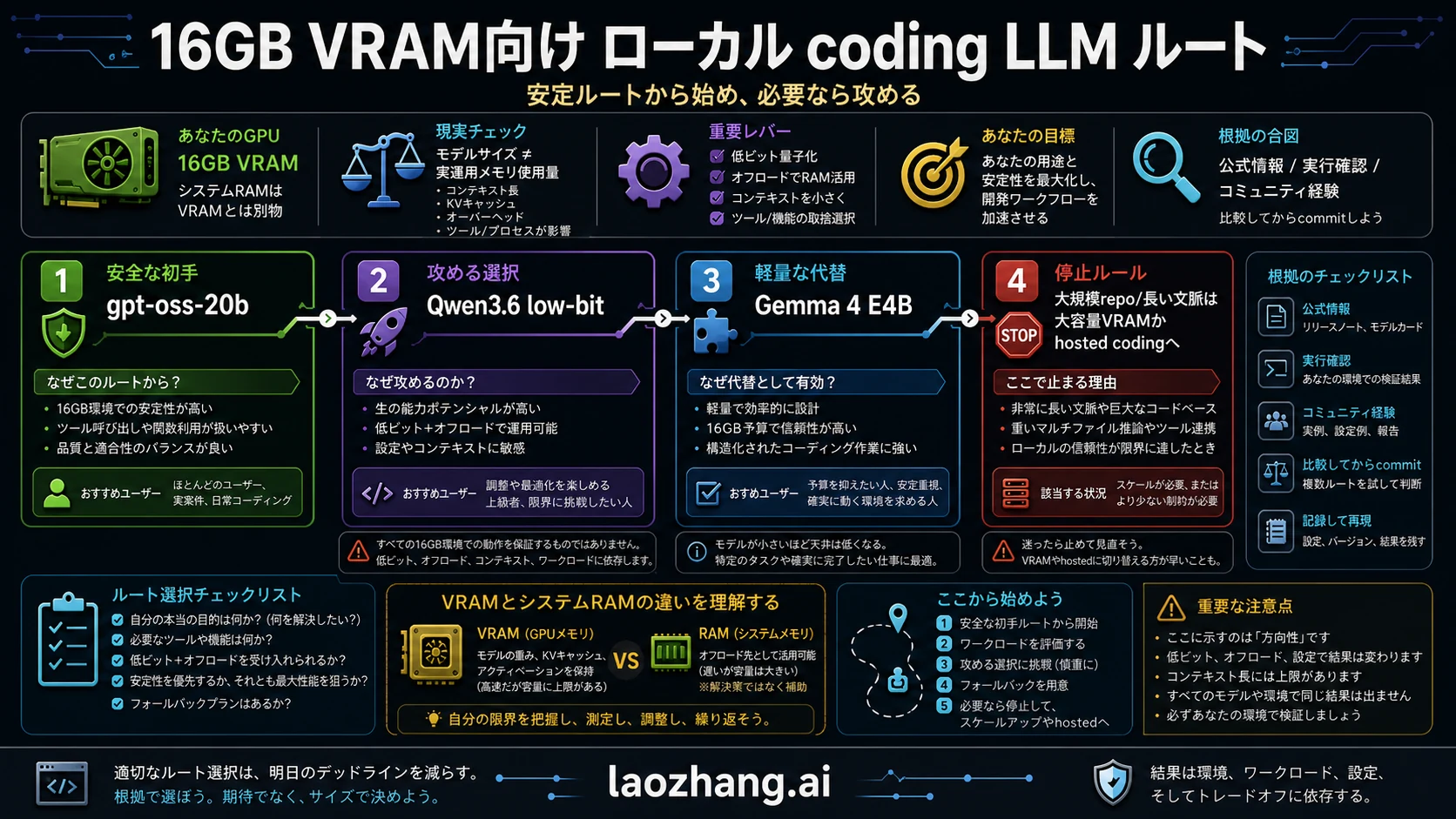
16GB VRAMでローカルCoding LLMを選ぶとき、最初に決めるべきなのは「一番強いモデル名」ではありません。日常で安定して使うならgpt-oss-20bを基準にし、能力を攻めるならQwen3.6 35B A3Bを低ビットやoffload込みの実験として扱い、応答性を優先するならGemma 4 E4Bや小型コードモデルを残します。
モデルが短いpromptで起動することと、実際のリポジトリで補丁を作れることは別です。コード支援では、モデル重みだけでなくKV cache、ファイル断片、テスト情報、エディタ連携、ローカルserver、長いcontextが同じ余白を奪います。
2026-07-03時点の判断では、公式のメモリ級、runtimeのパッケージ表示、コミュニティの実機報告を分けて扱います。Zenn、Qiita、Redditなどの公開情報は候補を知るには便利ですが、日常ルートにする前には自分のコードでsmoke testが必要です。
最短の答えはこうです。まずgpt-oss-20bを入れて、一つの関数と近いテストで補丁を出させる。品質が足りない場合だけQwen3.6の低ビットルートを短いcontextで試す。遅延、OOM、context喪失が主問題になるなら、小さいモデル、より大きいVRAM、またはhosted codingへ切り替えます。
結論:モデル名より先にルートを決める
日本語の公開情報では、Qwen2.5-CoderやDeepSeekを16GB向け候補として語る記事、Zenn、Qiita、企業技術ブログ、Reddit翻訳、ベンチマーク記事が並びます。多くは実機メモとして有用ですが、公式根拠と実行時条件を一枚の判断表にしていません。
そこで最初にルート表を置きます。ランキングではなく、今日どこから始め、どこで攻め、どこで止めるかを決めるための表です。
| ルート | 最初に試すモデル | 16GBの問いに合う理由 | 主な注意点 | 次の行動 |
|---|---|---|---|---|
| 基準ルート | gpt-oss-20b | 16GB級として説明しやすい根拠がある | 大規模repo agentを無制限には期待しない | インストールしてsmoke test |
| 攻めるルート | Qwen3.6-35B-A3Bの低ビットまたはoffload | agentic coding候補として魅力がある | 標準runtime表示は単純な16GB保証ではない | 量子化、context、offloadを記録 |
| 軽い退避先 | Gemma 4 E4B-it | メモリ圧が低く反応が安定しやすい | 深いrepo推論の主役とは限らない | 狭いタスクに使う |
| コード特化の退避先 | Qwen2.5-Coder、Qwen3-Coder、DeepSeek Coder系 | 小から中サイズなら局所修正に強い | 具体ファイルと量子化で結果が変わる | パッケージとcontextを確認 |
| 停止ライン | 大きいVRAM、小型モデル、hosted coding | 長いcontextやtool loopは16GBを越えやすい | 調整が仕事そのものになる | OOMや遅延で切り替える |
根拠の分け方:公式、実行環境、コミュニティ
gpt-oss-20bを基準にする理由は、絶対的な性能順位ではなく、16GB級の説明が最も守りやすいからです。公式と主要runtimeの説明に近いルートを先に置くことで、初回セットアップの不確実性を下げられます。
Qwen3.6 35B A3Bは魅力的です。リポジトリ推論やagentic codingを意識した候補であり、日本語圏の実機メモやコミュニティ投稿でも注目されています。ただし、OllamaやLM Studioの標準表示がそのまま16GB all-GPUの保証になるわけではありません。
Gemma 4 E4Bは、最大能力ではなく収まりやすさのために残します。関数説明、小さなhelper生成、短いdiff review、テスト観点の洗い出しでは、軽く安定するモデルが大きいモデルより役に立つことがあります。
Reddit、Zenn、Qiita、企業ブログ、個人検証は候補発見に効きます。しかし、モデルファイル名、量子化、context長、GPU、driver、runtime versionがなければ、他の環境で再現できる保証にはなりません。
公開文では、公式はモデルの位置づけ、runtimeはパッケージとメモリ、コミュニティは試行錯誤の信号として扱います。この境界を守ると、読者は見栄えのよいランキングよりも再現可能な選択を得られます。
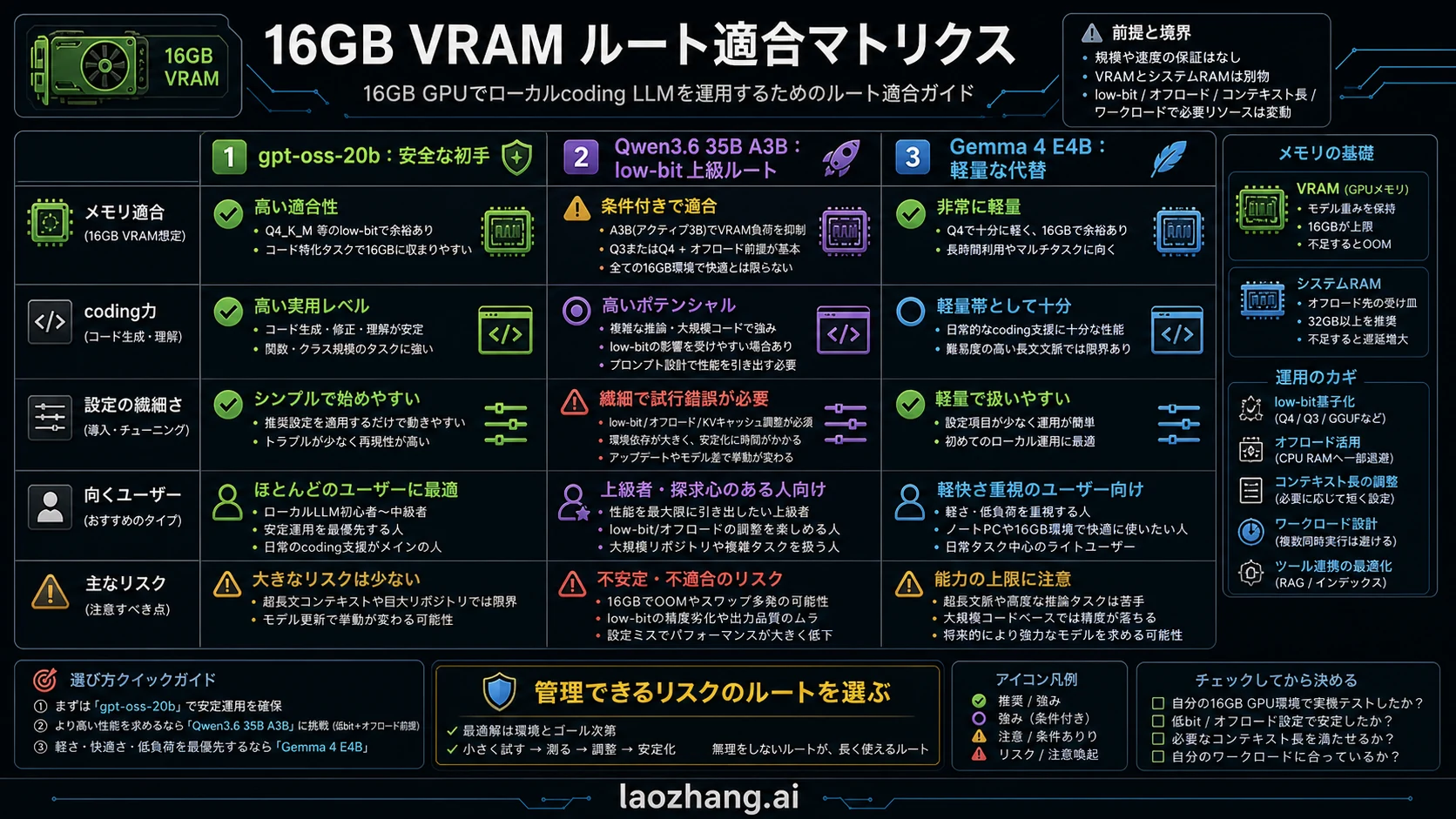
16GB VRAMで本当に使える余白
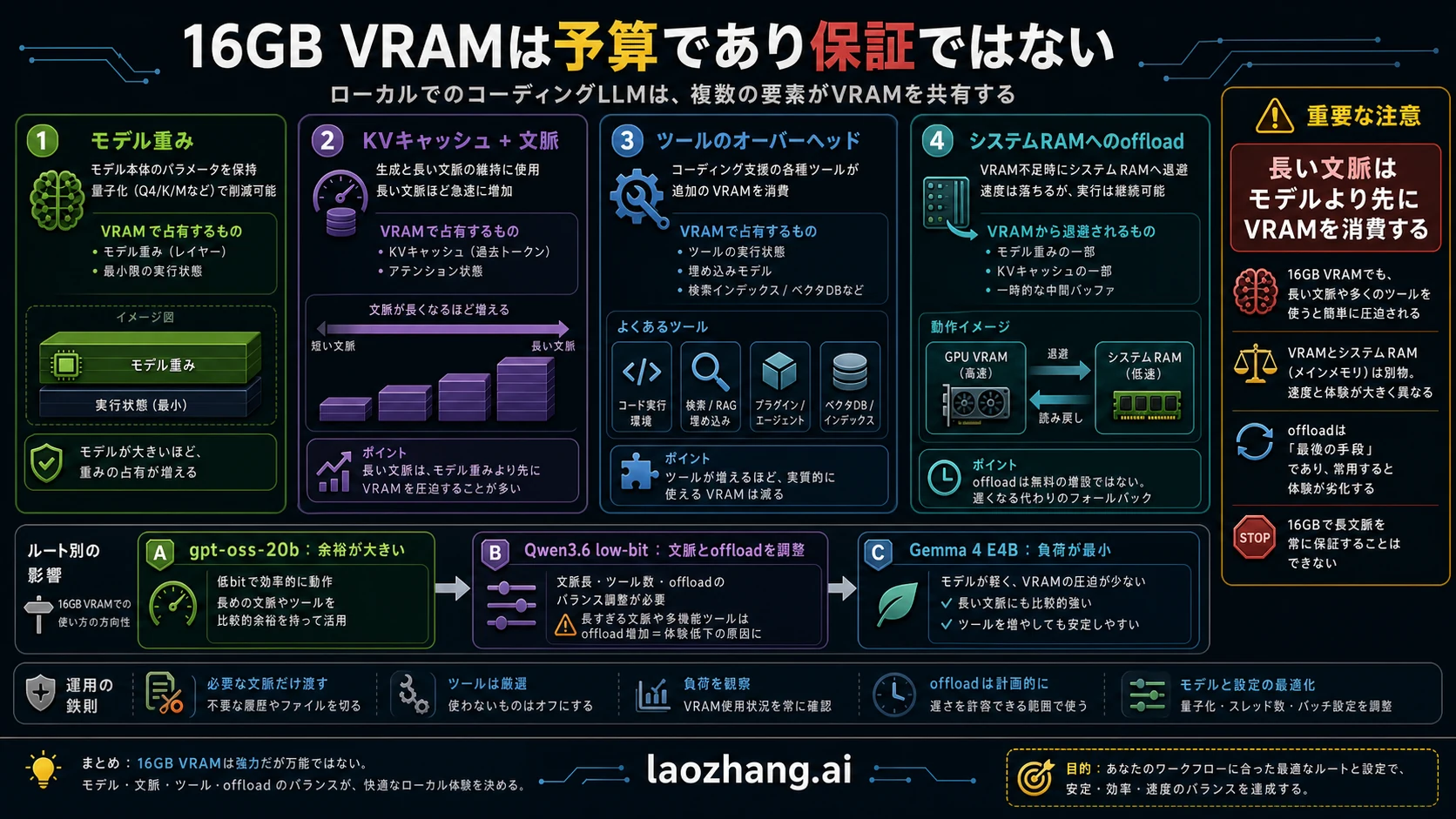
VRAMはGPU上の専用メモリです。system RAMでもdisk容量でもありません。ローカル推論では、モデル重み、runtime buffer、KV cache、prompt、生成中のtoken、エディタ連携が同じ予算を消費します。
コード支援では普通のチャットよりcontextが重くなります。関数、周辺テスト、エラー、既存制約、前回の提案を保持する必要があるためです。短い質問に答えられるモデルでも、multi-file patch loopでは急に不安定になります。
offloadはOOMを避ける助けになりますが、待ち時間を増やします。開発中の待ち時間は品質問題です。補丁のたびに長く待つなら、少し小さいモデルで速く回したほうが価値があります。
16GBの価値は、プライバシーを保った局所コード支援を安価に回せることです。大規模monorepo全体を常に把握する自動agentを約束する枠ではありません。
| 压力来源 | 对代码任务的影响 | 16GB 下的处理方式 |
|---|---|---|
| モデル重み | 起動可否と品質の土台になる | 16GB級として説明できるパッケージから始める |
| KV cache | contextを伸ばすほど残り予算を消費する | 段階的にcontextを増やす |
| ツール層 | IDE、server、tokenizer、wrapperが追加で使う | CLIで基準を作る |
| offload | OOM回避の代わりに遅延を増やす | 速度が許容範囲のときだけ残す |
ルート1:gpt-oss-20bを基準にする
gpt-oss-20bは、最初の実験を短くするための基準です。基準は勝者ではなく、あなたのGPU、runtime、repo sliceでローカルCoding LLMが実用になるかを測るものです。
最初から全リポジトリを入れないでください。一つのファイル、一つの近いテスト、一つの明確な修正要求に絞ります。現在の動作説明、最小patch、更新すべきテスト、足りないcontextを聞きます。
bashollama pull gpt-oss:20b ollama run gpt-oss:20b
この時点で遅い、OOMになる、contextを忘れるなら、さらに大きいQwenへ進む前に境界を直します。contextを減らす、runtime設定を見る、IDE wrapperを外す、小さいモデルを試すほうが先です。
基準が通ったら、テスト、隣接module、エラーログの順で負荷を増やします。各段階でVRAM、system RAM、latency、patch品質を残すと、次のモデル比較が感覚ではなくなります。
ルート2:Qwen3.6 35B A3Bは上級者向けの実験
Qwen3.6 35B A3Bは、品質を攻めたいときのルートです。ただし、16GBユーザー向けの簡単な答えではなく、低ビット、短いcontext、offload、runtime設定を含む実験として扱います。
開始前に、量子化、runtime、GPU layers、offload有無、system RAM、context長、タスク種類を固定します。単発のコード説明と、複数ファイルを跨ぐagentic codingは負荷が違います。
bashollama show qwen3.6:35b-a3b
表示されるパッケージやメモリ要件がすでに厳しいなら、ダウンロード前に止めます。かろうじて入るモデルは、実コードでは小さいモデルより悪い開発体験になることがあります。
Qwenルートは、設定を読む人には有効です。量子化を替える、contextを落とす、memory graphを見る、速度低下を受け入れる、そのうえで戻る判断ができる人向けです。
ルート3:Gemma 4 E4Bと小型コードモデルを残す
Gemma 4 E4Bや小型コードモデルは、16GBの実用性を守るためにあります。速い応答、低いメモリ圧、安定したcontext保持は、毎日の補助では大きな価値です。
DeepSeek Coder、Qwen2.5-Coder、Qwen3-Coderは候補に入りますが、family名だけでは不十分です。実際に使うファイル、量子化、context、runtime対応を見て判断します。
小型モデルは、関数説明、短いrefactor、unit testのたたき台、設定ファイルの確認、エラー文の整理に向きます。すべてのagent作業を任せる必要はありません。
15秒でreview可能なpatchを出す小型モデルは、2分待ってcontextを落とす大型モデルより開発に効くことがあります。
実行環境:Ollama、LM Studio、llama.cpp、エディタ連携
実行環境は答えを変えます。OllamaはCLI基準、LM StudioはGUIとlocal server、llama.cpp/GGUFは量子化とcontextの制御、IDE pluginはファイル選択とprompt包装を担当します。
同じモデル名でも、runtimeによって実ファイルとdefault contextが違います。推奨を書くなら、モデル名だけではなく実行経路を一緒に残します。
Ollamaではpackage sizeとparameters、LM Studioではmemory requirement、GGUFではファイル名とquant、IDE wrapperではどのファイルをendpointに送るかを確認します。
wrapperが何をしているかわからないときは、いったんCLIに戻します。CLIは地味ですが、問題がモデルなのか、contextなのか、エディタ連携なのかを分けられます。
Smoke test:自分のコードで証明する
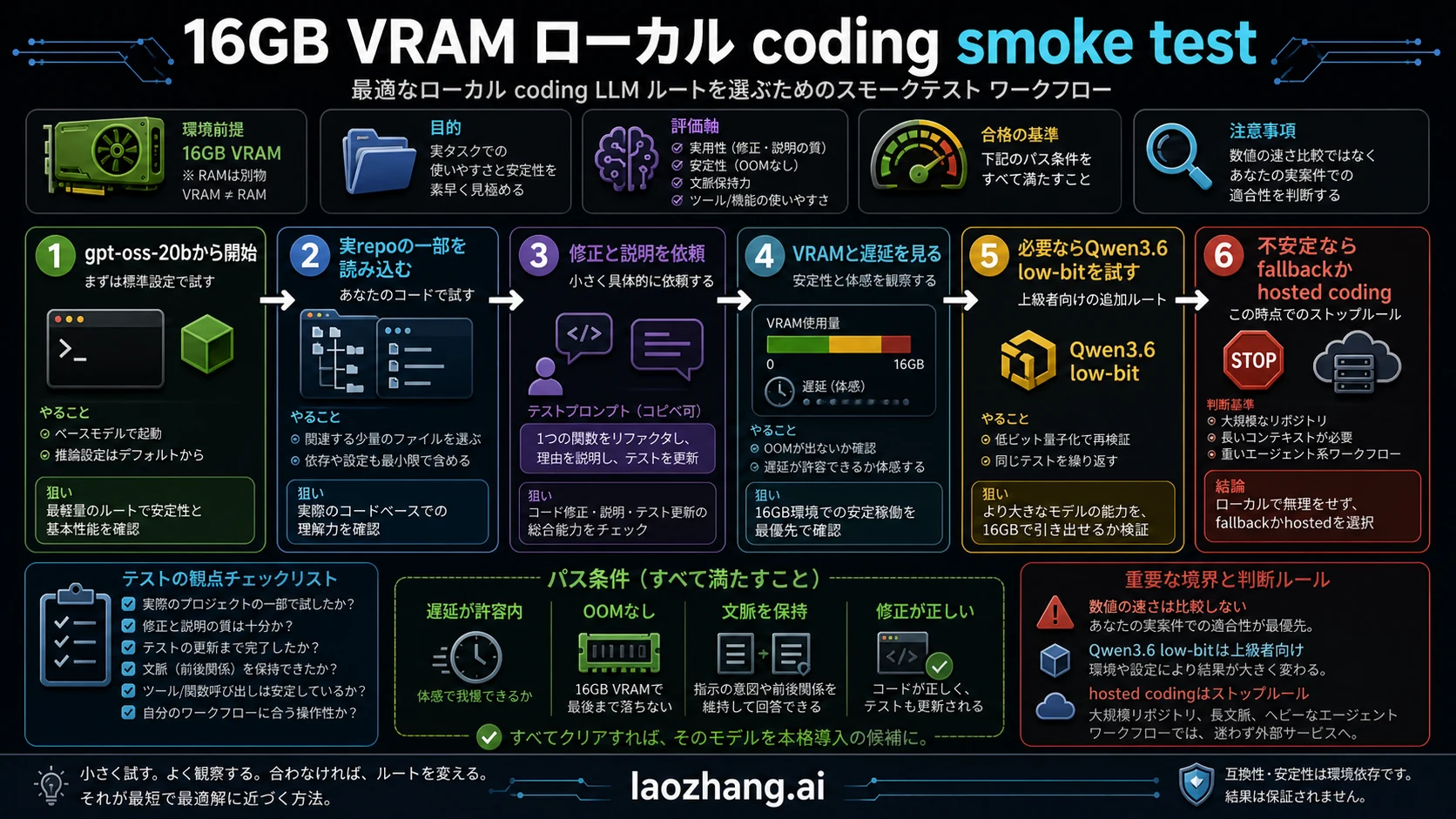
smoke testは自分のコードで行います。一般的なpuzzleやベンチマークでは、実際の関数、テスト、patch制約を保持できるかが見えません。
最小構成は、一つのファイル、一つのテスト、一つの修正要求です。モデルには現状説明、patch、テスト名、不足しているcontextを具体的に答えさせます。
textGiven the files below, refactor one function without changing behavior. Explain the tradeoff, show the patch, and name the test that should be updated. If the context is insufficient, say exactly what file or symbol you need next.
合格条件は、待ち時間が許容範囲、OOMや暴走offloadがない、関数とテストの制約を忘れない、patchが小さくreview可能であることです。
合格したらcontextを少し増やし、その後でQwen低ビットを試します。この順序なら、モデル品質と単なる調整作業を混同しにくくなります。
停止ライン:16GBに固執しない場面
停止ラインは先に決めます。16GB環境で一番時間を失うのは、起動だけはするモデルを日常用途まで無理に持ち上げようとすることです。
生成が遅すぎるならoffloadや重いquantが原因かもしれません。snippetでは良く、repoでは悪いならcontext packingが原因かもしれません。contextを上げるとOOMになるならKV cacheが予算を食っています。
解決策は一つではありません。小型モデルへ戻す、タスクを狭める、contextを下げる、24GB以上へ移る、または長いmulti-file作業だけhosted codingへ出す選択があります。
目的は16GBで全てを証明することではありません。コード作業を速く、安定して、review可能にすることです。
| 症状 | 原因の候補 | 次のルート |
|---|---|---|
| 起動後に遅い | offloadまたは重いquant | 小さいモデルか大きいVRAM |
| snippetは良いがrepoで悪い | context packing不足 | タスクを狭める |
| context増加でOOM | KV cacheが予算を食う | contextを下げる |
| patch loopで状態を失う | agent作業が重すぎる | hosted codingまたは上位GPU |
ローカル検証ログに残す項目
検証ログには、GPU、system RAM、driver、runtime version、model file、quant、context length、offload、task type、latency、memory peak、fail reasonを残します。
gpt-oss-20bでは、どの程度のrepo sliceを安定して扱えるかを見ます。Qwen3.6では、低ビットとoffloadの遅さが許容範囲かを見ます。Gemma 4 E4Bでは、速度と品質の均衡を見ます。
残すべき結論は「起動した」ではなく「正しく直せた」です。Coding LLMではpatch、テスト、context不足の申告が価値の中心です。
16GB環境の検証は、同じタスクを三段階で増やすと判断しやすくなります。最初は一つの関数と一つのテスト、次にエラーログ、最後に隣接モジュールを足します。どの段階で遅くなるか、どの段階でテスト名を忘れるかを見ると、モデルの弱点が見えます。
モデル、量子化、runtime、IDE wrapperを同時に替えると、改善の理由が分かりません。日本語の実機メモとして残すなら、タスクとpromptを固定し、変数を一つずつ変えるほうが他の読者にも使いやすい記録になります。
チームに共有する場合は「このモデルが最強」と書かず、「このGPU、このquant、このcontext、この作業では合格」と書きます。16GBでは再現条件こそが価値であり、モデル名だけの推薦はすぐ古くなります。
よくある質問
16GB VRAMで最初に試すローカルCoding LLMは?
まずgpt-oss-20bです。16GB級の根拠が比較的きれいで、baselineとして扱いやすいからです。
Qwen3.6 35B A3Bは16GBで動きますか?
低ビット、短いcontext、offloadなら動く場合があります。ただしall-GPUの簡単な保証ではありません。
gpt-oss-20bはコード用途に十分ですか?
局所修正、説明、短いテスト提案には基準として有効です。大規模agent作業は別途smoke testが必要です。
Gemma 4 E4Bはなぜ候補ですか?
軽く、速く、contextを保ちやすいからです。狭いタスクでは大きいモデルより使いやすいことがあります。
OllamaとLM Studioはどちらがよいですか?
CLI基準ならOllama、GUIやlocal serverならLM Studioです。重要なのは実ファイル、量子化、メモリ要件です。
RTX 4060 Ti 16GBで足りますか?
16GBルートの検証には使えます。ただし35B級を長いcontextで快適に使えるとは限りません。
8GB VRAMならどうしますか?
小型モデル、短いcontext、狭いタスクに絞ります。16GB向けQwen実験をそのまま移すべきではありません。
24GB VRAMにすれば十分ですか?
余裕は増えますが、contextとKV cacheの問題は残ります。smoke testは必要です。
いつローカル調整を止めるべきですか?
OOM、offload遅延、context喪失、patch loop失敗が主作業になった時点です。
コミュニティのベンチマークだけで決められますか?
候補探しには使えますが、保証にはなりません。モデルファイル、量子化、runtime、自分のコードで確認します。