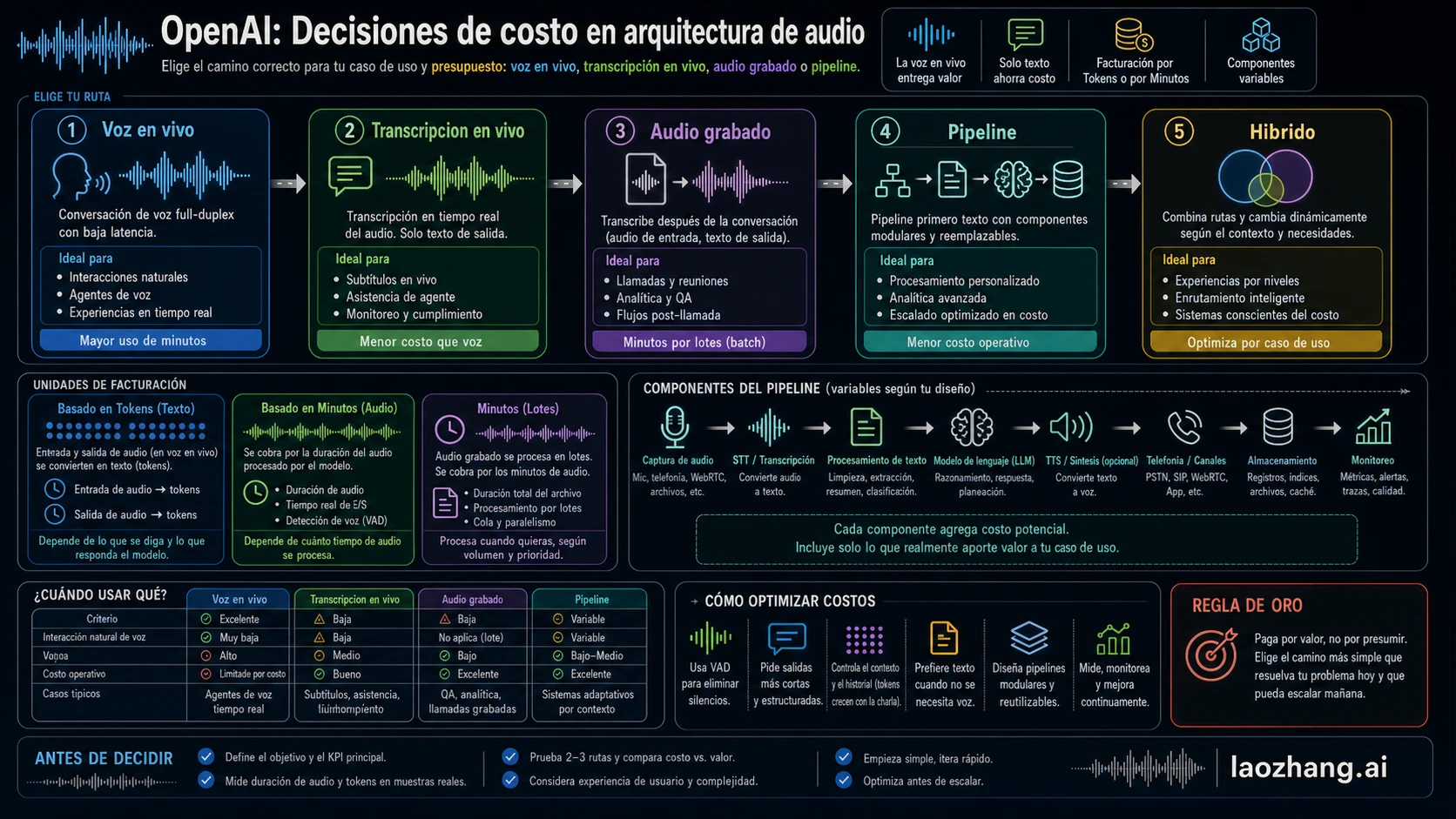
No empieces preguntando si Realtime API es más barato o más caro que un pipeline de transcripción. Empieza preguntando si el producto debe entender al usuario mientras habla, aceptar interrupciones, llamar herramientas y responder con voz en el mismo momento. Si esa interacción hablada es el valor del producto, gpt-realtime-2 puede justificar un medidor más alto. Si el producto necesita transcript, resumen, archivo, QA, cumplimiento o analytics, empieza con una ruta de transcripción.
La ruta va antes de la tabla de precios:
- Asistente de voz en directo: usa
gpt-realtime-2cuando la calidad de voz, la baja latencia, la interrupción y el uso de herramientas durante la llamada crean valor. - Solo transcripción en directo: usa
gpt-realtime-whispercuando el producto necesita texto en streaming mientras alguien habla, pero no necesita que el asistente hable. - Audio acotado a texto: usa
gpt-4o-transcribeogpt-4o-mini-transcribecuando el audio se puede subir, grabar o procesar como request. - Pipeline propio: combina STT, un modelo de texto, TTS opcional, telefonía, almacenamiento, monitorización y QA solo cuando esos componentes sean necesarios.
- Híbrido: reserva Realtime para los momentos live de alto valor y usa procesamiento basado en transcripción para archivo, revisión y resúmenes.
A 14 de junio de 2026, OpenAI lista gpt-realtime-whisper a $0.017/minute, gpt-4o-transcribe como estimated $0.006/minute y gpt-4o-mini-transcribe como estimated $0.003/minute. La conversión directa da $1.02/hour, $0.36/hour y $0.18/hour para transcripción facturada por duración. Las sesiones con gpt-realtime-2 tienen otra forma: audio input y audio output se facturan por tokens, y una hora contada de audio del usuario más una hora generada de audio del asistente crea un media-token floor de $5.76/hour antes de text tokens, herramientas, historial repetido, optional input transcription, telefonía y componentes del pipeline.
La regla de parada es simple: no pagues salida hablada del asistente cuando el texto basta. El resto de la página da la hoja de cálculo para decidir cuándo la voz de baja latencia merece el coste adicional, cómo crece el coste de Realtime y qué partes del pipeline deben seguir siendo variables hasta verificarlas en tu stack.
Elige primero por el trabajo del producto
La decisión no es “Realtime API versus pipeline de transcripción” en abstracto. Es primero el trabajo del producto, después la ruta de OpenAI y finalmente la unidad de facturación. Si saltas directo al precio por minuto, puedes comparar un asistente hablado completo con una fila de STT y tomar una decisión falsa.
| Trabajo del producto | Primera ruta a presupuestar | Unidad de coste | Cuándo usarla | Regla de parada |
|---|---|---|---|---|
| Asistente de voz en directo | gpt-realtime-2 | tokens de audio y texto por Response | El usuario necesita interrupción, turn-taking, herramientas y salida hablada durante la sesión | Si basta salida de texto, no empieces aquí |
| Solo transcripción en directo | gpt-realtime-whisper | minutos de audio live | El producto necesita texto mientras alguien habla | Si el audio puede esperar, mira transcripción acotada |
| Audio acotado a texto | gpt-4o-transcribe o gpt-4o-mini-transcribe | minutos de audio enviado | Archivos, grabaciones, revisión post-llamada, resúmenes, QA o compliance | Si necesitas deltas live, usa transcripción realtime |
| Pipeline propio | STT -> modelo de texto -> TTS opcional -> capa operativa | medidores separados | Se necesita control, mezcla de proveedores, telefonía, auditoría u optimización por componente | No añadas TTS, telefonía o modelo de texto sin necesidad real |
| Híbrido | Realtime para el live moment, transcripción para back office | medidores combinados | La ayuda live crea valor, pero archivo y analytics no requieren voz | Mide dónde termina la sesión live y empieza el back office |
La tabla evita el error más común: creer que dos productos de audio compran lo mismo. Un asistente de voz compra un interactive spoken loop. Un pipeline de transcripción compra texto y procesamiento posterior. Ambos pueden empezar por audio, pero no entregan el mismo resultado.
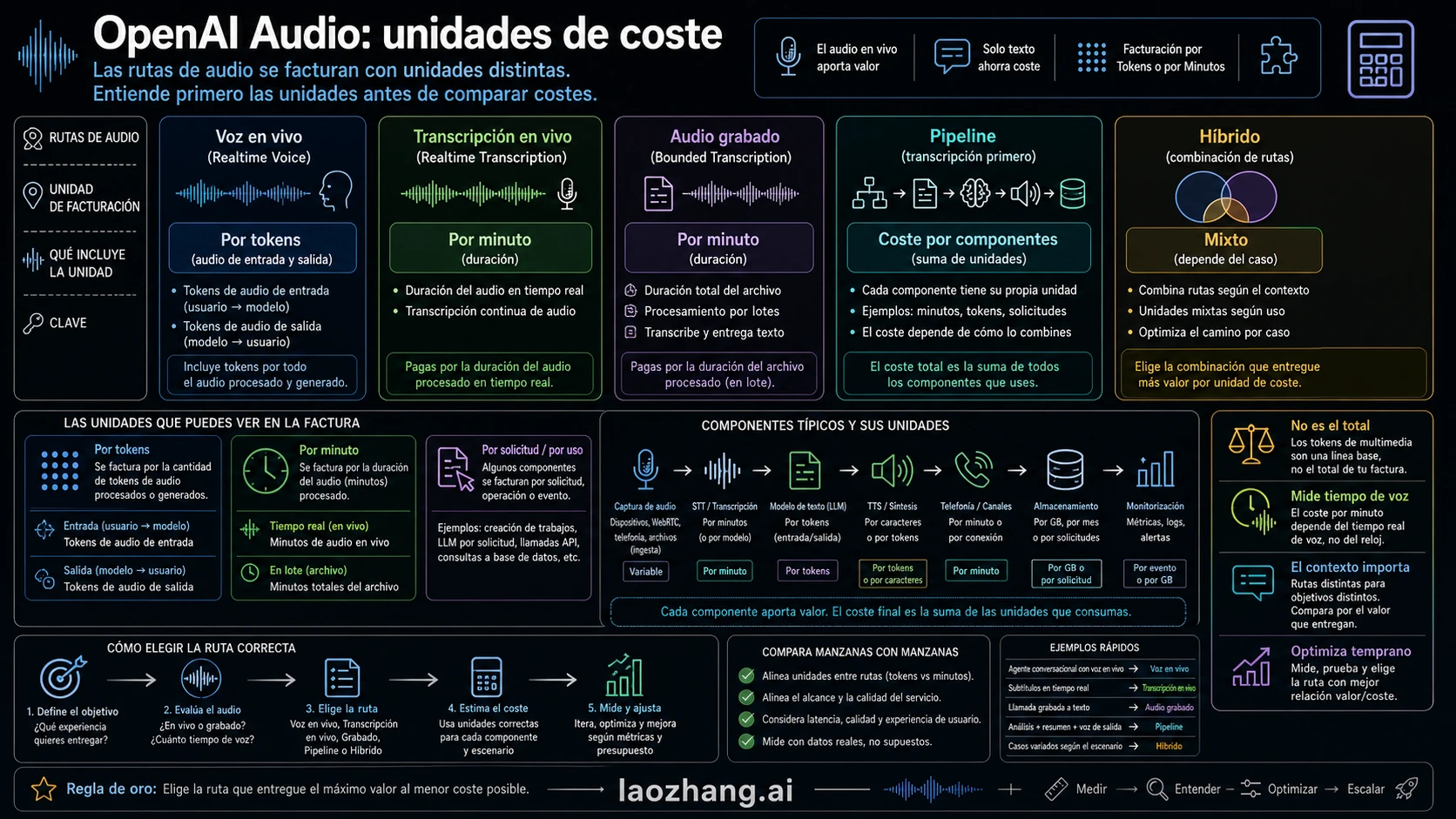
Precios actuales de OpenAI que importan
Usa las filas actuales de OpenAI como anclas y después añade tu carga real medida. Revisado el 14 de junio de 2026, la OpenAI pricing page lista estas filas para las rutas de esta decisión:
| Ruta | Fila actual de precio OpenAI | Intuición por hora | Qué no incluye |
|---|---|---|---|
gpt-realtime-whisper | $0.017/minute | $1.02/hour por conversión directa | trabajo de modelo de texto, storage, monitorización, telefonía y componentes no OpenAI |
gpt-4o-transcribe | estimated $0.006/minute | $0.36/hour por conversión directa | post-procesado, resúmenes, clasificación, storage y orquestación |
gpt-4o-mini-transcribe | estimated $0.003/minute | $0.18/hour por conversión directa | revisión de exactitud, vocabulario de dominio, retries y trabajo operativo |
gpt-realtime-2 audio input | $32.00/1M audio input tokens | $1.152/hour para una hora contada de audio de usuario a 1 token por 100 ms | audio del asistente, texto, tools, historial, transcripción opcional y pipeline |
gpt-realtime-2 audio output | $64.00/1M audio output tokens | $4.608/hour para una hora generada de audio del asistente a 1 token por 50 ms | audio del usuario, texto, tools, historial, transcripción opcional y pipeline |
La transcripción por duración se convierte directamente:
textgpt-realtime-whisper: 60 minutes * $0.017 = $1.02/hour gpt-4o-transcribe: 60 minutes * $0.006 = $0.36/hour gpt-4o-mini-transcribe: 60 minutes * $0.003 = $0.18/hour
El media-token floor de gpt-realtime-2 también se puede calcular, pero sigue siendo solo un floor:
textUser audio input: 36,000 tokens/hour * $32 / 1,000,000 = $1.152/hour Assistant audio output: 72,000 tokens/hour * $64 / 1,000,000 = $4.608/hour Media-token floor: $1.152 + $4.608 = $5.76/hour
Usa $5.76/hour como etiqueta de advertencia, no como presupuesto final. Asume una hora de audio de usuario y una hora de audio de asistente, pero excluye text tokens, context repetido, herramientas, input transcription opcional, tokens especiales, telefonía, storage, monitorización y cualquier parte del pipeline fuera de Realtime.
Por qué crece el coste de un agente de voz Realtime
La Realtime cost guide explica por qué una sesión de voice-agent no se presupuesta como un simple archivo de audio. El coste aparece cuando se crea un Response y depende de input/output tokens. Si input transcription está activado, se factura con un modelo de transcripción separado. OpenAI también indica que connections y network bandwidth no se cobran actualmente, pero eso no convierte una sesión abierta en gratuita cuando genera Responses.
Los drivers prácticos son:
- User audio: contado a 1 token por 100 ms.
- Assistant audio: contado a 1 token por 50 ms; respuestas largas suelen dominar el floor.
- Response count: cada Response es un nuevo evento de generación.
- Conversation history: el contenido anterior vuelve al contexto y los turnos tardíos pueden encarecerse.
- Empty audio control: VAD puede filtrar silencio si el client no lo añade manualmente.
- Text and tool work: instructions, tool schemas, tool results y text output también cuentan.
- Optional input transcription: si quieres transcript dentro de la sesión, aparece una transcripción aparte.

Por eso “Realtime cuesta X dólares por hora” suele ser una respuesta débil para launch planning. Una llamada de soporte de 60 minutos con respuestas cortas del asistente puede costar menos que una sesión de tutoría de 20 minutos donde el asistente habla mucho, usa tools y mantiene un context largo a través de muchos Responses.
Puedes reducir desperdicio sin cambiar de ruta. Mantén VAD configurado para que el silencio no entre como input. Termina o resume sesiones largas cuando el historial viejo ya no mejore la siguiente respuesta. Mantén tool schemas e instrucciones del sistema compactas. Evita monólogos del asistente cuando basta una frase corta. Activa input transcription solo si el producto necesita transcript dentro de la sesión. Antes de fijar margen público, mide Response count real y duración del audio del asistente.
La ventaja de Realtime también es real. gpt-realtime-2 compra un loop hablado nativo: low latency, interruption handling, calidad de voz y herramientas durante la conversación. Si esas propiedades mejoran conversion, containment, accessibility o completion rate, el coste extra es valor de producto.
Modelo de coste de un pipeline de transcripción
Un pipeline de transcripción empieza más barato porque el primer paso pagado puede ser speech-to-text. Para files y bounded audio, la Speech to text guide apunta a gpt-4o-transcribe, gpt-4o-mini-transcribe y gpt-4o-transcribe-diarize; los uploads tienen cap de 25 MB y no tienen la misma forma que live deltas. Para live text sin asistente hablado, la Realtime transcription guide encaja con gpt-realtime-whisper.
No cierres la hoja de costes en STT si el producto hace más que producir texto. Cuenta todo el stack:
| Componente | Cómo contarlo | Tratamiento de precio |
|---|---|---|
| Audio capture and transport | app, browser, WebRTC, telefonía o recording infrastructure | variable según stack y región |
| STT | gpt-realtime-whisper, gpt-4o-transcribe o gpt-4o-mini-transcribe | las minute rows de OpenAI anclan el estimate |
| Text model | resumen, extracción, routing, QA, coaching, moderación o agent logic | variable por modelo, tokens, cache y retries |
| Optional TTS | salida de voz después del procesamiento de texto | variable hasta verificar la ruta de lanzamiento |
| Telephony | PSTN, SIP, grabación, números, funciones de compliance | variable por proveedor y región |
| Storage and retrieval | audio, transcripts, embeddings, logs, retention policy | variable por privacidad y retención |
| Monitoring and QA | revisión humana, auditorías, métricas, failure replay, alertas | variable y a veces mayor que STT en workflows regulados |
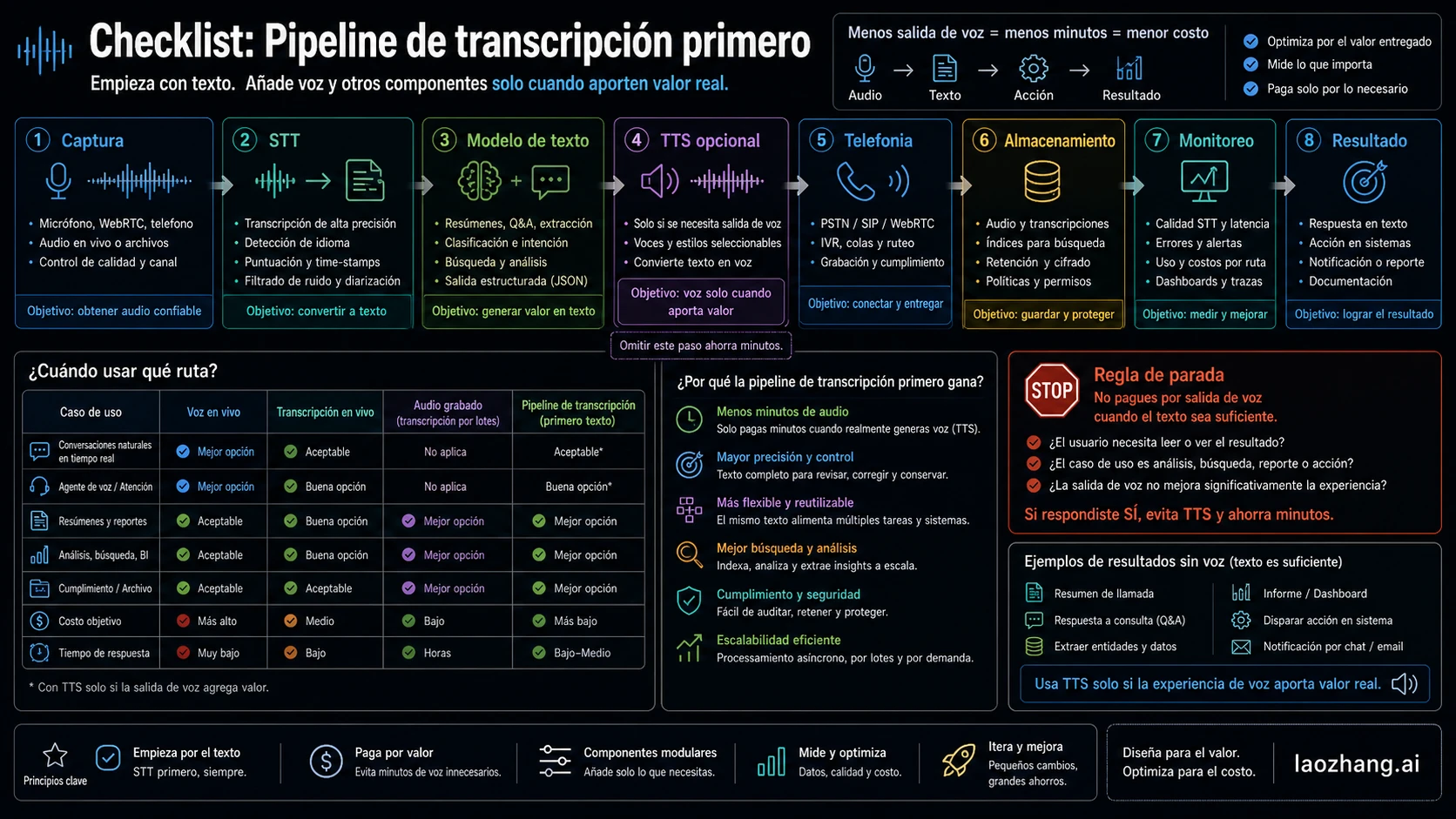
El pipeline puede ser más barato y predecible que una sesión de voice-agent, sobre todo cuando el producto no necesita spoken output. También es más fácil de depurar porque cada component deja un artifact: audio, transcript, output del modelo de texto, summary, classification o audit log.
El tradeoff es latency e integración. Un diseño STT -> text model -> TTS puede hacerse streaming, pero no se convierte en una sesión hablada nativa. Elígelo porque el workflow está centrado en texto o porque necesitas control de componentes, no porque una fila STT parezca universalmente barata.
Cuándo merece la pena pagar por voz en directo
Paga por gpt-realtime-2 cuando la interacción hablada cambia el comportamiento del usuario durante la sesión. Buenos candidatos: llamadas de sales u onboarding, tutoring o coaching donde la interrupción importa, accessibility flows, voice agents que llaman tools mientras el usuario sigue presente, consumer voice experiences, y soporte donde resolver por voz evita escalación humana.
La pregunta del piloto no es “¿Realtime es más caro que STT?”. Es “¿live speech produce suficiente valor para justificar el medidor adicional?”. Mide:
| Métrica | Por qué importa |
|---|---|
| real user talk time | impulsa el user audio contado |
| assistant speech time | impulsa audio output y suele dominar el media-token floor |
| Responses per session | controla cuántas veces genera el modelo |
| average history size by turn | revela crecimiento de coste en turnos tardíos |
| tool calls per session | captura texto oculto y contexto de herramientas |
| completion or containment lift | muestra si el voice loop se paga solo |
| human fallback rate | detecta casos donde una ruta de transcripción habría bastado |
Si esas métricas muestran mejora de negocio o de experiencia, Realtime puede ser el gasto correcto aunque una ruta de transcripción tenga una fila horaria más baja. Si no muestran mejora, no escales Realtime por inercia a todos los workflows de audio.
Cuándo gana una ruta de transcripción
Empieza por transcripción cuando el artifact final es texto. Casos típicos: meeting summaries, call QA, compliance review, searchable archives, support analytics, coaching notes, borradores médicos o legales que requieren revisión, notas de voz asíncronas y post-call classification.
Las reglas de parada son prácticas. Si el usuario no necesita que el asistente responda con voz, no pagues assistant audio output. Si el transcript puede llegar cuando termina el audio, compara bounded transcription antes de live transcription. Si necesitas live captions pero no asistente hablado, presupuesta gpt-realtime-whisper antes que gpt-realtime-2. Si summaries y classifications corren después del capture, son trabajo de modelo de texto fuera de la fila STT. Si el workflow necesita compliance trail, los artifacts del pipeline suelen ser más inspeccionables que un live spoken loop por sí solo.
Esta ruta también da más control de calidad. Puedes guardar el audio original, rerun transcription, comparar model outputs, revisar prompt changes, batch non-urgent work y mandar solo muestras de riesgo a revisión humana. Para equipos operativos, ese control puede valer más que reducir unos segundos de latency.
Patrón híbrido: Realtime solo donde la voz crea valor
Hybrid suele ser la mejor forma de producción. Usa Realtime para el segmento live donde speech cambia el resultado y usa transcription-first processing para las partes que no requieren spoken output.
Una secuencia simple:
- Inicia una sesión
gpt-realtime-2solo para la interacción live que necesita interruption, turn-taking y speech. - Captura metadata: duración de audio de usuario, duración de audio de asistente, Response count, tool calls y si input transcription estaba activada.
- Guarda o exporta transcript solo si el producto y la política de privacidad lo necesitan.
- Ejecuta post-call summaries, QA, compliance classification, analytics y search indexing por rutas de texto o transcripción.
- Revisa sesiones de muestra cada semana hasta estabilizar el límite live y el límite de back office.
Así la ruta más cara queda atada a la parte del producto que realmente la necesita. Un agente de onboarding puede usar Realtime durante la llamada y después usar post-processing más barato para CRM notes y QA. Un monitor de call center puede usar live transcription para visibilidad del supervisor sin hacer que un voice agent hable todo el tiempo. Una app de notas de voz puede evitar Realtime por completo si solo necesita texto exacto y un resumen limpio después de grabar.
La clave es definir dónde termina el valor live. Cada paso posterior debe demostrar de nuevo por qué necesita realtime speech y no una ruta text-centered más barata.
Hoja de presupuesto
Haz tres estimates: transcription-only, Realtime media floor y full pipeline. Después reemplaza placeholders con datos del piloto.
| Línea de worksheet | Fórmula |
|---|---|
| Live transcript-only cost | live_audio_minutes * $0.017 para gpt-realtime-whisper |
| Bounded high-accuracy transcription cost | audio_minutes * $0.006 para gpt-4o-transcribe |
| Bounded low-cost transcription cost | audio_minutes * $0.003 para gpt-4o-mini-transcribe |
| Realtime user-audio floor | user_audio_hours * $1.152 para gpt-realtime-2 audio input |
| Realtime assistant-audio floor | assistant_audio_hours * $4.608 para gpt-realtime-2 audio output |
| Realtime media-token floor | user_audio_floor + assistant_audio_floor |
| Realtime session estimate | media floor + text tokens + tool tokens + history growth + optional input transcription |
| Pipeline estimate | STT + text model + optional TTS + telephony + storage + monitoring + QA |
Corre la hoja con low, typical y high usage. En Realtime, cambia primero assistant speech time y Response count antes que user talk time; ahí suele aparecer el riesgo de margen. En transcription-first, cambia audio duration, text-model output length, retry rate, storage retention y human-review load.
Antes del lanzamiento, captura evidencia de sesiones reales: median y p95 de user audio duration, median y p95 de assistant audio duration, Response count, average history size en turnos tardíos, input transcription usage and model, text tokens usados por tools y follow-up processing, failed or retried sessions, minutos de revisión humana por transcript, y filas de precio OpenAI vigentes en la fecha de lanzamiento.
Revisa precios el día de deploy. Model IDs, availability, minute rows, token rows y acceso por cuenta pueden cambiar, y los calculators antiguos envejecen rápido.
Preguntas frecuentes
¿Realtime API siempre es más caro que un pipeline de transcripción?
No siempre. Las sesiones de Realtime voice-agent suelen tener un floor más alto que plain transcription, pero la pregunta correcta es si la interacción hablada crea valor. Si necesitas interruption, low latency, tool use durante la llamada y spoken output, Realtime puede merecer la pena. Si necesitas text artifacts, transcription-first suele empezar más barato y ser más fácil de presupuestar.
¿gpt-realtime-whisper es lo mismo que gpt-realtime-2?
No. gpt-realtime-whisper sirve para workflows de live transcription-only que necesitan transcript deltas sin salida hablada. gpt-realtime-2 es la ruta Realtime voice-agent para sesiones de asistente hablado en directo. Mezclarlos como una sola fila de Realtime rompe la comparación.
¿Por qué no llamar $5.76/hour precio horario de Realtime?
Porque es solo el media-token floor para una hora contada de user audio y una hora generada de assistant audio con las filas actuales de gpt-realtime-2. Excluye text tokens, repeated history, tools, optional input transcription, special tokens, telephony y pipeline components.
¿Qué ruta usar para live captions?
Empieza por realtime transcription-only. La ruta OpenAI a presupuestar es gpt-realtime-whisper cuando el producto necesita live transcript deltas pero no asistente hablado. Si el audio puede esperar hasta terminar la grabación, compara gpt-4o-transcribe y gpt-4o-mini-transcribe.
¿Un pipeline STT -> LLM -> TTS siempre gana a Realtime?
No. Un pipeline puede ser más barato para trabajos centrados en texto y más controlable para compliance, telephony, debugging y vendor mix. También añade integración y latencia por componente. Si la experiencia depende de interrupción natural y calidad de respuesta hablada, una sesión Realtime nativa puede ser la mejor ruta.
¿Cuál es la regla de producción más segura?
Elige primero la ruta, usa filas oficiales actuales de OpenAI para las partes que OpenAI cobra directamente, etiqueta todo lo demás como variable y valida con sesiones reales. No pagues spoken assistant output cuando el texto basta y no llames factura final a un media-token floor.