
Si OpenAI te dice que el tipo de archivo no es compatible y te sugiere "prueba otra vez con un PDF", no conviertas todo de inmediato. ChatGPT, el OpenAI API oficial actual y Azure o los conectores todavía pueden aplicar reglas distintas, así que el primer movimiento útil no es cambiar la extensión, sino identificar dónde se produjo el rechazo.
Si el fallo aparece en ChatGPT, primero revisa si el archivo viene de Google Docs, Sheets o Slides y aún no lo has exportado. Si el error aparece en el API oficial actual, primero confirma si la vía correcta para ese trabajo es input_file o file_search. Si el rechazo ocurre en Azure o en un conector, ahí sí es posible que PDF siga siendo la salida más rápida. Después de la corrección mínima, vuelve a probar en la misma ruta. Si esa misma ruta sigue rechazando un archivo claramente soportado, no lo tomes como prueba de que OpenAI ahora solo acepta PDF; tómalo como una señal de que elegiste mal la vía o de que esa entrada todavía va por detrás.
Tabla de ruta en 30 segundos
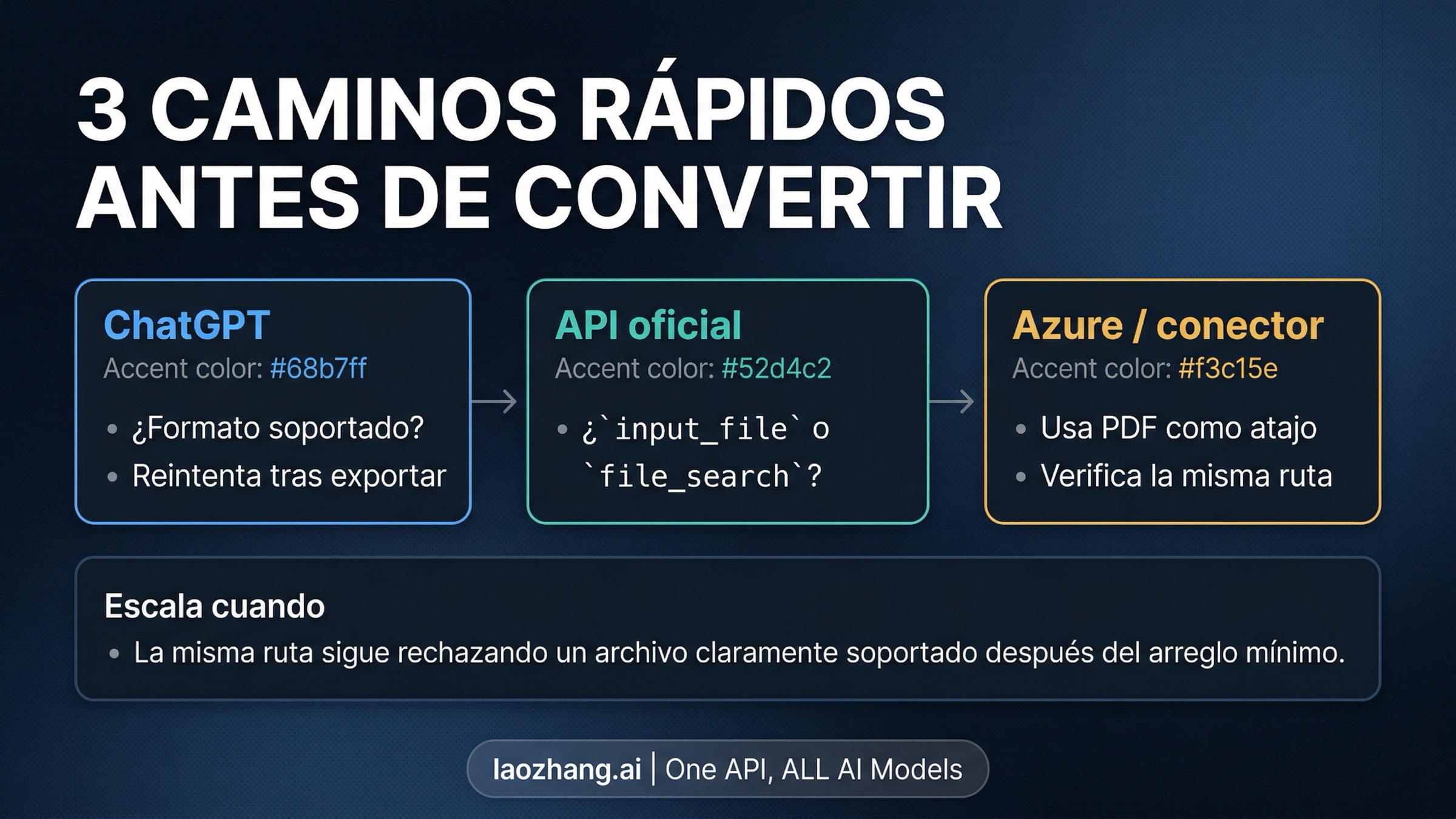
Empieza por el punto de carga que rechaza el archivo, no solo por la extensión:
| Dónde ocurre el rechazo | Problema más probable | Primer movimiento más seguro | Cómo verificar en la misma ruta | Cuándo subir el nivel del diagnóstico |
|---|---|---|---|---|
| Carga en ChatGPT | Archivo nativo de Google, formato que no se puede subir directo, o documento que en realidad necesita PDF para conservar el diseño | Primero exporta desde Google Docs, Sheets o Slides; si no, reintenta con un formato claramente soportado o con PDF cuando el diseño importe | El mismo flujo de carga en ChatGPT vuelve a aceptar el archivo | Incluso un archivo exportado y claramente soportado sigue fallando |
| OpenAI API oficial | Ruta de archivo equivocada, expectativa incorrecta sobre input_file, o trabajo que en realidad pertenece a file_search | Cambia a la vía alineada con la documentación y deja de forzar todos los trabajos de documentos por el mismo camino | La misma solicitud ahora acepta el archivo y el resultado sirve para la tarea | Incluso la vía alineada con la documentación sigue rechazando un archivo soportado |
| Azure o un conector | Una entrada que todavía se comporta como si PDF fuera obligatorio | Exporta o convierte a PDF para esa entrada, o mueve el trabajo a una ruta oficial actual de OpenAI | La misma entrada ahora acepta el archivo | Incluso el PDF falla o el comportamiento sigue sin coincidir con la documentación oficial |
Las páginas oficiales de ayuda de OpenAI y la documentación de desarrolladores usada aquí se volvieron a revisar el 8 de abril de 2026. La conclusión corta es esta: el OpenAI oficial actual no es PDF-only en todos los puntos de carga. La misma frase de error todavía aparece en algunas entradas rezagadas o vecinas, y por eso la tabla de decisión importa más que la cita por sí sola.
Si el rechazo ocurre en ChatGPT
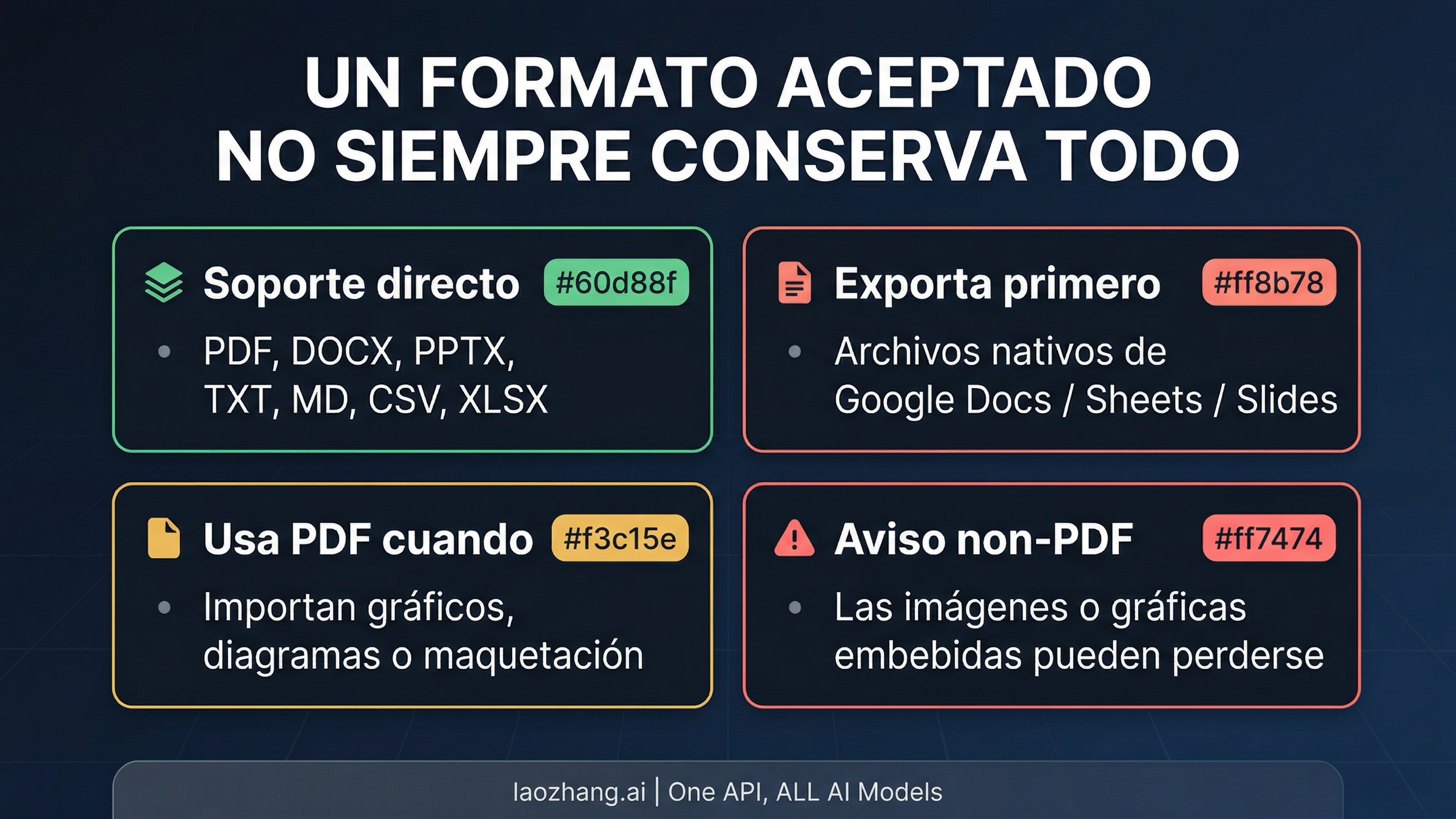
Esta rama es, ante todo, un problema de compatibilidad de carga, no de herramientas del API. Las páginas actuales de OpenAI sobre tipos de archivo soportados y el File Uploads FAQ describen varias clases de archivos soportados, no una regla general de solo PDF. Eso significa que DOCX, PPTX, TXT, MD, CSV, JSON o archivos de hoja de cálculo pueden ser cargas normales en ChatGPT aunque otra interfaz con marca OpenAI te enseñe el mensaje sobre PDF.
La excepción escondida más común aquí no es un documento de Office, sino un archivo nativo de Google como .gdoc, .gsheet o .gslides. Esos tipos no son formatos de carga directa. Si tu archivo vive en Google Docs, Sheets o Slides, primero debes exportarlo. Ese también es el punto donde PDF vuelve a ser una buena decisión por la razón correcta: no porque ChatGPT exija PDF en general, sino porque tu trabajo real puede depender más del diseño, de los gráficos o de la relación visual del documento que del texto editable.
Aquí es donde mucha gente pierde tiempo. Ven la frase exacta del error, encuentran una respuesta genérica del tipo "convierte todo a PDF" y ya no preguntan si el rechazo venía de un archivo nativo de Google, de un formato que todavía no había sido exportado, o de una tarea donde importa más el resultado renderizado que la estructura editable. El lenguaje de ayuda de OpenAI es más estrecho que ese mito. La pregunta útil no es "¿ChatGPT soporta archivos?", porque sí los soporta. La mejor pregunta es "¿estoy subiendo el formato exportado correcto para el tipo de contenido que necesito conservar?".
La verificación aquí es corta: vuelve a probar el archivo exportado en el mismo flujo de carga de ChatGPT que falló antes, no en otra app, otro wrapper o un conector distinto. Si ese mismo punto de carga sigue rechazando un archivo exportado que claramente está soportado, ya no estás en la rama simple de "faltaba exportar" y no deberías seguir tratando el PDF como cura automática.
Si al final descubres que el problema real no era el tipo de archivo sino el límite de carga, no conviertas esta página en otra guía distinta. En ese caso conviene revisar primero nuestro artículo sobre el límite de subida en ChatGPT Plus.
Si el rechazo ocurre en el OpenAI API oficial

La rama del API oficial es donde más confusión generan los consejos viejos de PDF-only. La guía actual de OpenAI sobre PDF files and other document formats dice de forma explícita que la ruta input_file del Responses API acepta no solo PDF, sino también archivos de texto, código, documentos ricos, presentaciones y hojas de cálculo. Ese contrato es más amplio de lo que sugieren muchos snippets y respuestas antiguas.
La advertencia importante no es solo si el archivo se acepta. La misma documentación también dice que las imágenes y gráficos incrustados en archivos no PDF no se extraen. Así que un DOCX o un PPTX puede ser aceptado y aun así no ser el mejor input si tu trabajo real depende de diagramas, tablas tal como se ven, diapositivas anotadas o maquetación mixta. "Archivo aceptado" y "mejor archivo para la tarea" no son la misma afirmación.
La forma más rápida de ordenar esta rama es unir la vía con el trabajo:
| Si tu trabajo real es... | Ruta más adecuada | Por qué |
|---|---|---|
| Meter un documento directamente en el contexto del prompt | input_file | El modelo puede leer el archivo en la propia solicitud sin montar otra capa de búsqueda |
| Buscar en un conjunto de documentos o citar archivos guardados después | file_search | La documentación actual de file search soporta muchos formatos no PDF y encaja mejor con recuperación |
| Conservar gráficos, diagramas, visuales incrustados o maquetación compleja | El contrato actual es más claro con PDF cuando importa la fidelidad visual |
En la práctica, cuando el API oficial rechaza el archivo, casi siempre pasa una de estas tres cosas. La ruta elegida no corresponde al trabajo. El formato se acepta, pero la tarea real necesita PDF por fidelidad visual. O la solicitud pasa por un wrapper, un conector o un ejemplo viejo que nunca se actualizó al contrato actual. Ninguna de las tres equivale a decir "OpenAI ahora solo acepta PDF".
Si la solicitud del API sigue fallando después de moverte a la vía correcta, revisa la capa de al lado y no solo la del archivo. El alcance del proyecto, el tipo de clave o el enrutado específico del wrapper todavía pueden romper una petición con el archivo correcto. Si estás en esa rama, el mejor paso siguiente es nuestra guía sobre OpenAI API Key y Organization ID, porque separa los problemas de credenciales de los problemas de alcance y selección de ruta.
Si el rechazo ocurre en Azure o en un conector
Esta es la única rama donde el consejo de usar PDF puede seguir siendo literalmente cierto para la entrada concreta en la que estás. El problema es que muchas páginas se quedan ahí y convierten ese comportamiento local en una verdad general sobre OpenAI.
La investigación de este artículo encontró evidencia actual de ese retraso específico. Un hilo reciente de Microsoft Q&A todavía muestra la queja exacta de supported format .pdf en un flujo de file search de Azure OpenAI, mientras que la documentación oficial actual de OpenAI ya describe un soporte más amplio para documentos en algunas rutas de primera parte. Las comunidades de conectores repiten el mismo patrón: el usuario ve el error real, alguien responde "convierte a PDF", y la conversación nunca separa el contrato del conector del contrato actual de la primera parte.
Esa diferencia importa en la operación. Si tienes que quedarte en esa entrada rezagada, exportar o convertir a PDF puede ser la corrección mínima adecuada. Si puedes cambiar de ruta, mover el trabajo a una vía oficial actual de OpenAI suele ser la mejor respuesta a largo plazo. Lo que no deberías hacer es tratar el comportamiento de Azure o de un módulo de automatización como si definiera la verdad de todas las cargas de OpenAI.
Aquí también conviene dejar clara la frontera de escalado. Si la misma entrada de Azure o del conector sigue fallando incluso después de un export limpio a PDF, ya no estás ante una simple elección de formato. A partir de ahí es más probable que el problema sea retraso de implementación, comportamiento del módulo o diferencia entre lo que esa entrada promete y lo que realmente acepta en producción.
Cuando PDF sigue siendo el mejor formato
PDF sigue siendo la respuesta correcta muchas veces, y por eso el consejo antiguo nunca desapareció del todo. El error no es usar PDF. El error es usarlo como explicación por defecto.
La ayuda actual de OpenAI para flujos con documentos pesados dentro de ChatGPT sigue tratando PDF como el formato más fuerte cuando necesitas conservar diagramas, visuales incrustados o maquetación con mayor estabilidad. La documentación actual del API dice lo mismo desde el lado del desarrollador: un archivo no PDF puede aceptarse, pero las imágenes y los gráficos incrustados en archivos no PDF no se extraen. La primera afirmación responde "¿sube o no sube?". La segunda responde "¿se conserva del modo que necesito?". Esta página se vuelve mucho más clara cuando no mezclas esas dos cosas.
Usa PDF cuando el documento es visualmente denso, cuando vienes de Google Docs, Sheets o Slides y necesitas el resultado renderizado en vez de la estructura editable, o cuando la misma entrada ya te demostró que sigue sesgada hacia PDF. No conviertas PDF en una respuesta mágica para todo solo porque una interfaz con marca OpenAI te haya mostrado ese mensaje alguna vez.
Un DOCX puede estar soportado y aun así ser una mala entrada para un informe lleno de gráficos. Un PPTX puede aceptarse y aun así no ser la mejor opción para una presentación donde el modelo necesita entender la relación visual entre texto y elementos gráficos. Que se acepte responde "¿la subida pasa?". Preferir PDF responde "¿el contenido sobrevive de la manera que necesito?".
Verifica la corrección y elige la ruta a largo plazo
Cuando el archivo vuelva a aceptarse, no te quedes solo con la luz verde. Verifica la corrección en la misma ruta que falló:
- Reintenta en la misma ruta después de la corrección mínima, no en otra vía que solo esconda el problema original.
- Confirma que el archivo no solo se acepta, sino que realmente sirve para la tarea: lectura, búsqueda o interpretación con fidelidad visual.
- Si el archivo venía de Google Docs, Sheets o Slides, guarda una copia exportada en el formato que de verdad funcionó.
- Si el problema desaparece solo en otra ruta de OpenAI, trata la entrada original como una rama rezagada y no como prueba de que todo OpenAI se volvió PDF-only.
La ruta a largo plazo debe seguir el trabajo que repites con más frecuencia. Si casi siempre subes documentos normales en ChatGPT, quédate con el formato exportado que las ayudas actuales ya soportan. Si repites búsquedas documentales desde código, deja de pelear con cargas de una sola vez y construye el flujo alrededor de file_search. Si tu trabajo depende de la fidelidad visual, estandariza esa rama con PDF y no redescubras el mismo problema de gráficos y maquetación cada vez.
Preguntas frecuentes
¿OpenAI ahora solo soporta PDF?
No. A fecha del 8 de abril de 2026, las páginas oficiales de ayuda y la documentación actual de OpenAI describen varios formatos soportados en las cargas de ChatGPT y en algunas rutas de primera parte del API. El mismo error tipo PDF-only todavía puede ser real en ciertos caminos de Azure o de conectores, pero eso es comportamiento específico de una entrada, no una regla general de OpenAI.
¿Qué tipos de archivo deberían funcionar en ChatGPT?
Las ayudas actuales de OpenAI describen soporte para formatos comunes de documentos, presentaciones, hojas de cálculo, texto y código. La causa oculta más común no suele ser DOCX o PPTX en sí, sino los archivos nativos de Google que primero hay que exportar.
¿Por qué DOCX o PPTX pueden funcionar en una ruta de OpenAI y fallar en otra?
Porque "OpenAI" no es un solo contrato de carga. Las subidas de ChatGPT, el API oficial actual, Azure OpenAI y los conectores de terceros todavía pueden aplicar reglas distintas o arrastrar retrasos diferentes.
¿Cuándo conviene elegir file_search en vez de input_file?
Cuando la tarea real es buscar sobre varios documentos, citar archivos guardados o volver sobre ellos después, y no simplemente meter un archivo una sola vez dentro del contexto del prompt.
¿Cuándo PDF sigue siendo la mejor respuesta?
Cuando necesitas conservar maquetación, gráficos, diagramas o visuales incrustados; cuando exportas desde Google Docs, Sheets o Slides y necesitas el resultado renderizado; o cuando la entrada concreta que usas ya te demostró que sigue inclinada hacia PDF.
La regla de trabajo
La corrección más limpia y rápida no es "convierte todo a PDF". Es esta: identifica qué entrada rechaza el archivo, aplica el cambio mínimo correcto de formato o de ruta para esa entrada, verifica en el mismo sitio y solo entonces decide si PDF debe ser tu formato por defecto a largo plazo.