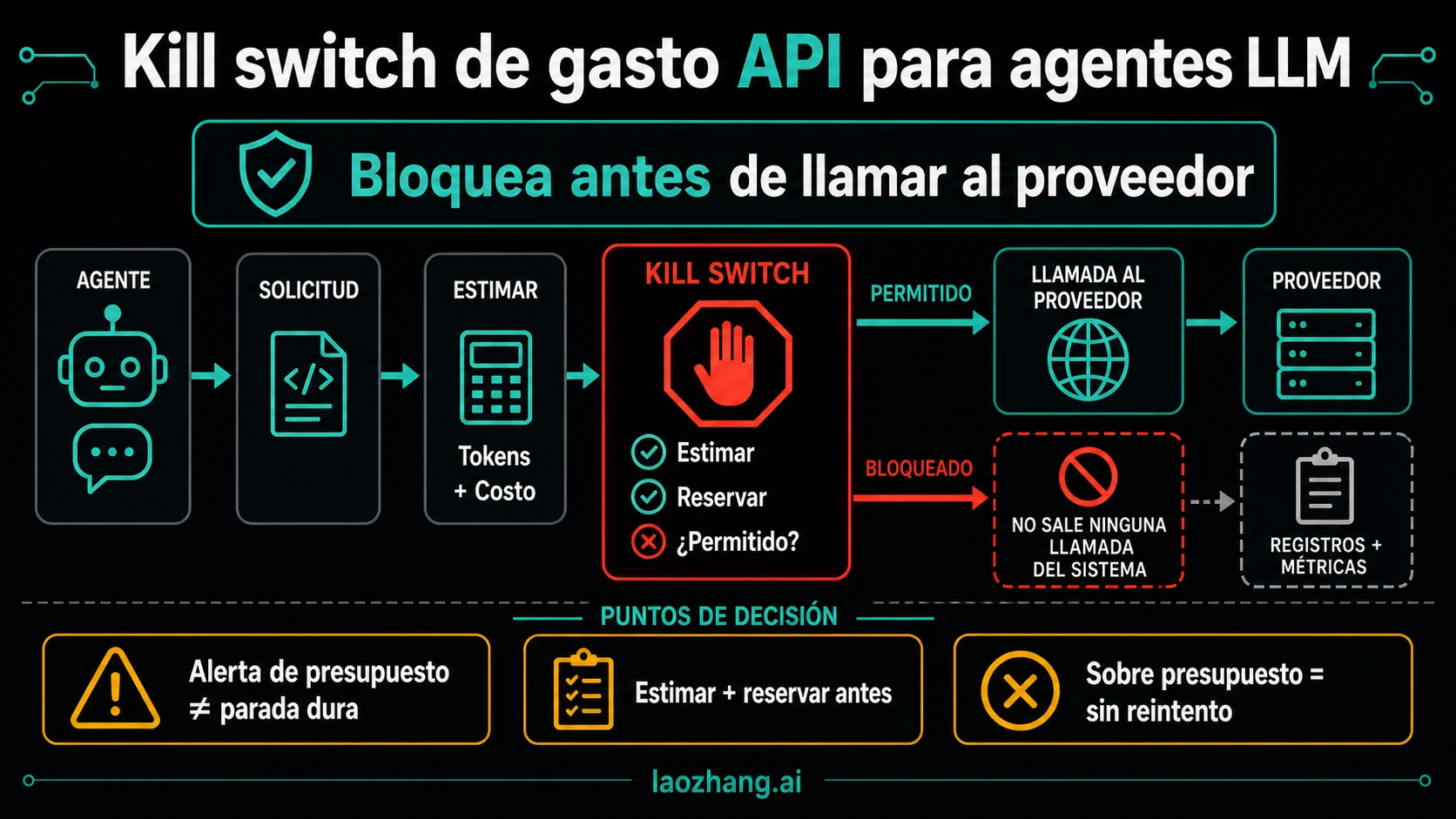
Un kill switch de gasto API para agentes LLM tiene que ejecutarse antes de que la llamada pagada salga hacia el proveedor. Si el agente puede reintentar, crear subagentes, ejecutar herramientas o cambiar de ruta, el control presupuestario debe estar en el camino de cada llamada de modelo. Un correo de alerta, un gráfico de uso o un presupuesto mensual de dashboard ayudan a gobernar, pero no siempre paran el siguiente request.
El diseño mínimo es concreto: estimar el coste máximo permitido para la llamada, reservar esa cantidad de forma atómica en un ledger compartido, llamar al proveedor solo si la reserva se aprueba y conciliar el coste real cuando llega el usage. Si la llamada rompería el límite, el agente debe recibir over_budget con retryable: false.
| Control | Qué detiene | Papel en el freno de gasto |
|---|---|---|
| Alerta de presupuesto | El equipo no ve a tiempo la subida de gasto | Aviso blando; las llamadas pueden continuar |
| Límite de proveedor o proyecto | Gobierno de cuenta en el proveedor | Buen backstop, no primera puerta del agente |
| Presupuesto de gateway | Tráfico que pasa por un proxy o gateway común | Puede ser parada dura si no hay rutas de escape |
| Puerta antes del proveedor | La próxima llamada pagada | Kill switch principal para agentes autónomos |
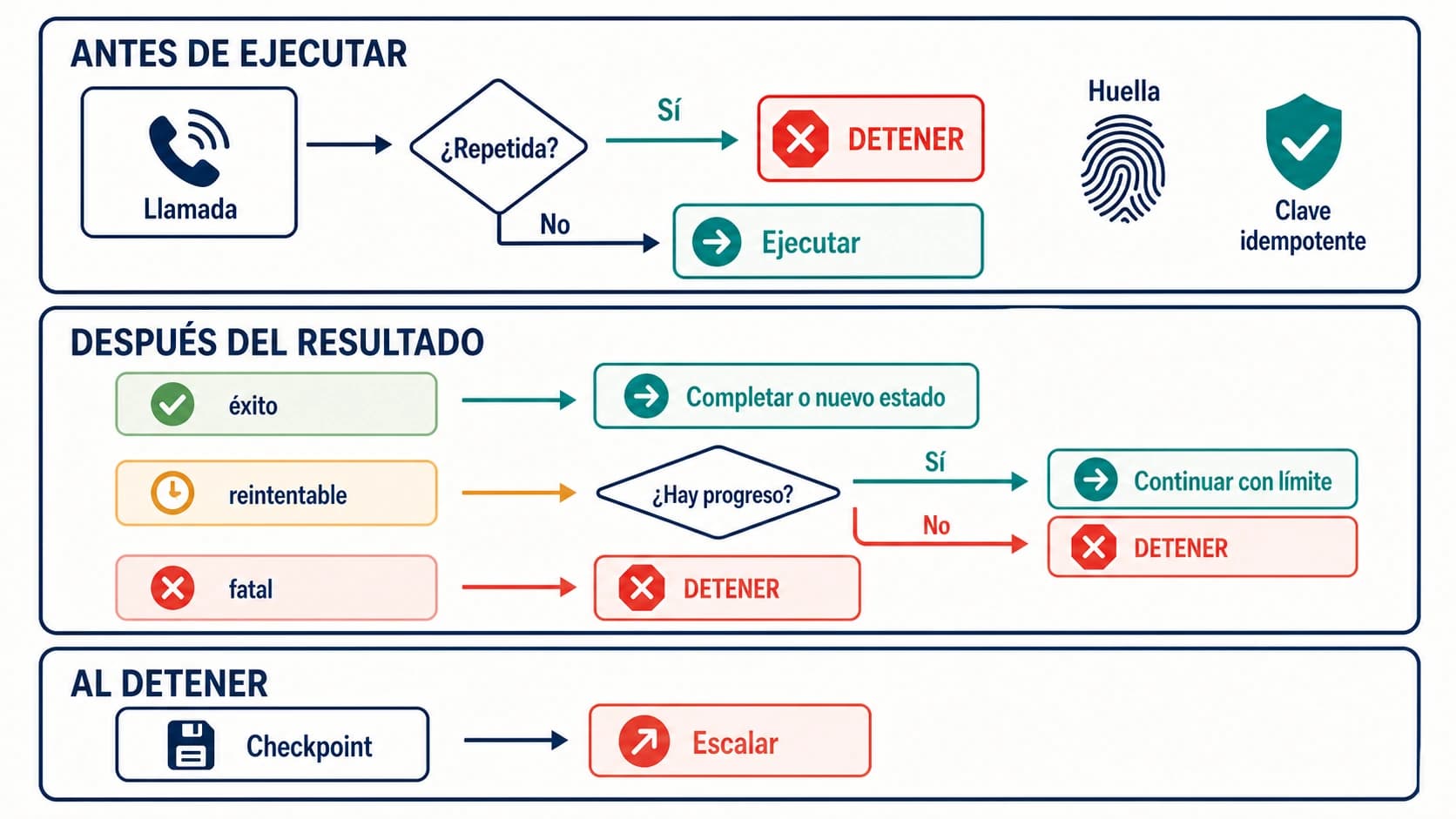
Regla de parada: después de over_budget, el agente no reintenta, no programa otro trabajo pagado, no arranca un helper y no cambia a otra key de pago. Solo puede continuar si una persona cambia el límite o la política y deja registrado el motivo.
Qué es un kill switch real
Un kill switch de gasto no es un dashboard, una alerta de correo, una respuesta de rate limit ni un informe de uso posterior. Es un punto de ejecución que puede decir no antes de iniciar otro trabajo facturable. Puede vivir en el runtime del agente, en un proxy OpenAI-compatible interno, en un AI Gateway, en un wrapper frente al proveedor o en un sidecar. La condición es que controle el credential path que el agente usa de verdad.
El fallo común es de arquitectura. El equipo añade una alerta después de que el worker ya tiene acceso directo a las claves del proveedor. Eso protege la bandeja de entrada de finanzas, no la próxima llamada API. Si el agente tiene planner loop, retry loop, tool loop y cola de subagentes, todos esos caminos deben gastar mediante el mismo gate.
Si el agente ya repite una herramienta, usa la guía para diagnosticar bucles de herramientas en agentes para clasificar el bucle y bloquear la siguiente llamada insegura antes de tratarlo solo como un problema de coste.
Usa cuatro palabras distintas en el runbook:
| Término | Úsalo para | No lo uses para |
|---|---|---|
| Spend limit | Techo de coste en moneda de cuenta | Throughput de tokens |
| Rate limit | Requests o tokens por ventana temporal | Coste mensual total |
| Soft budget | Alertas, reporting y umbrales | Bloqueo antes de la llamada |
| Hard stop | Request rechazado antes de más gasto | Email o gráfico posterior |
La precisión del lenguaje cambia la operación. En un incidente, la primera pregunta no es qué dashboard tiene un campo de presupuesto, sino qué componente puede bloquear la próxima llamada pagada.
Elige la capa de control
La opción más segura en producción es por capas. Pon el bloqueo principal en el request path y conserva los controles del proveedor y la plataforma como backstops.
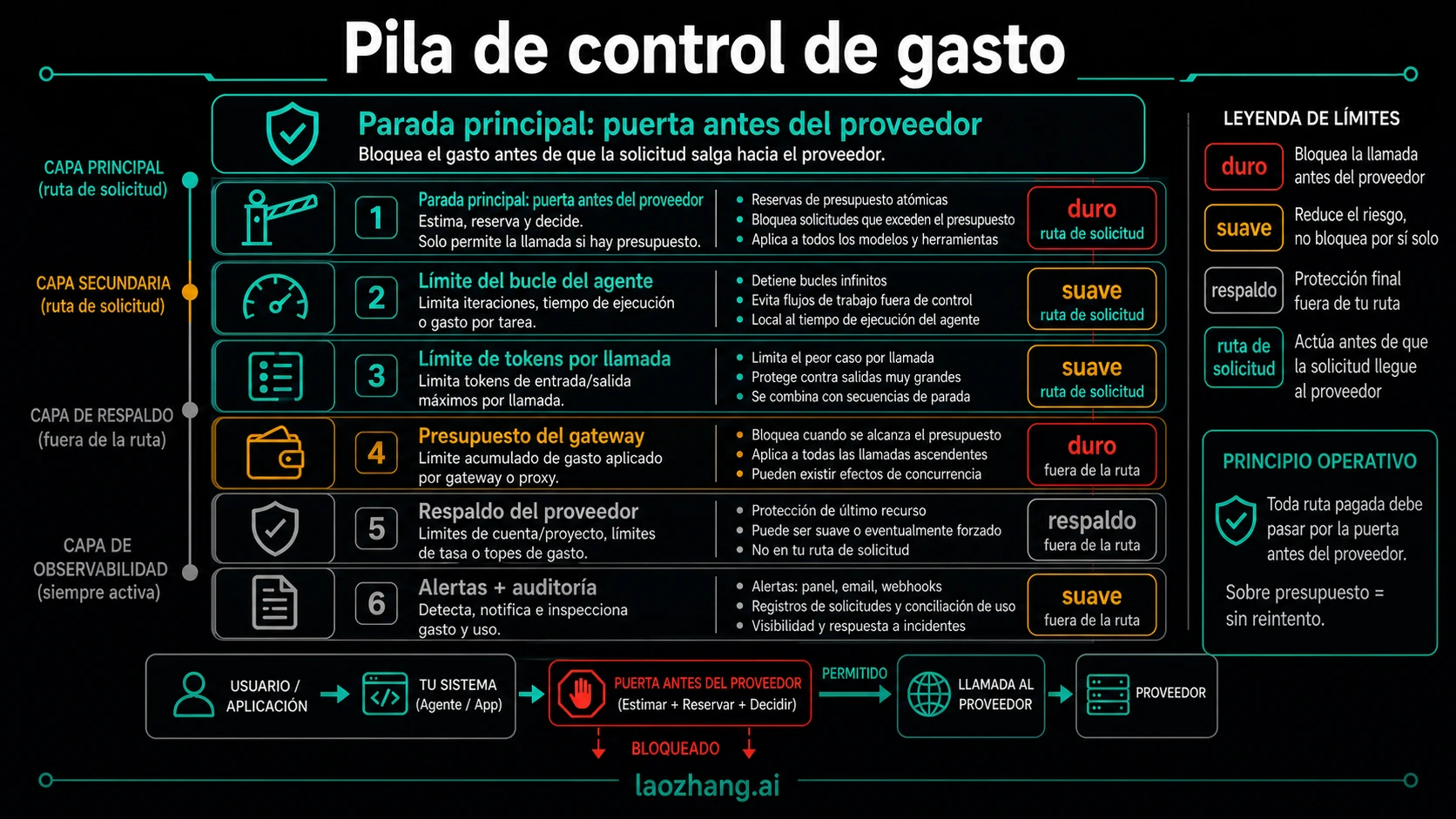
| Capa | Hace bien | Debilidad | Úsala como |
|---|---|---|---|
| Límite de loop del agente | Bucles infinitos, demasiados tool steps o wall-clock excesivo | No conoce la factura final si no se conecta a coste | Rail local |
| Token cap por llamada | Reduce el peor coste de una llamada | No detiene muchas llamadas pequeñas | Guardrail de forma |
| Gate de gasto antes del proveedor | Bloquea el siguiente request pagado antes de salir | Requiere ledger compartido y rutas cerradas | Kill switch principal |
| Presupuesto de gateway | Control entre keys, equipos, proveedores y modelos | Pierde tráfico que evita el gateway; la concurrencia importa | Control plane común |
| Cap del proveedor o proyecto | Techo de cuenta y política del proveedor | Puede ser blando, tardío o ajeno a la semántica del agente | Backstop |
| Alertas y audit logs | Detección, notificación y postmortem | No necesariamente paran la próxima llamada | Observabilidad |
Si ya usas un proxy OpenAI-compatible, pon ahí la comprobación de presupuesto. Si solo el runtime del agente ve todas las llamadas de modelo y herramienta, empieza ahí y obliga a los subagentes a heredar el mismo budget scope. Si usas varios proveedores, un gateway interno suele ser más limpio que copiar la lógica de presupuesto en cada worker.
El diseño peligroso es un gate parcial. El planner pasa por el presupuesto, pero el evaluador, el generador de imágenes, la herramienta de recuperación o la key de emergencia lo evita. En un incidente, esa ruta lateral se convierte en la factura.
Implementa reserve, call, reconcile
Antes de la respuesta no sabes el coste exacto, así que reserva un máximo razonable y concilia después. El patrón es conservador, pero evita que la concurrencia abra un agujero.
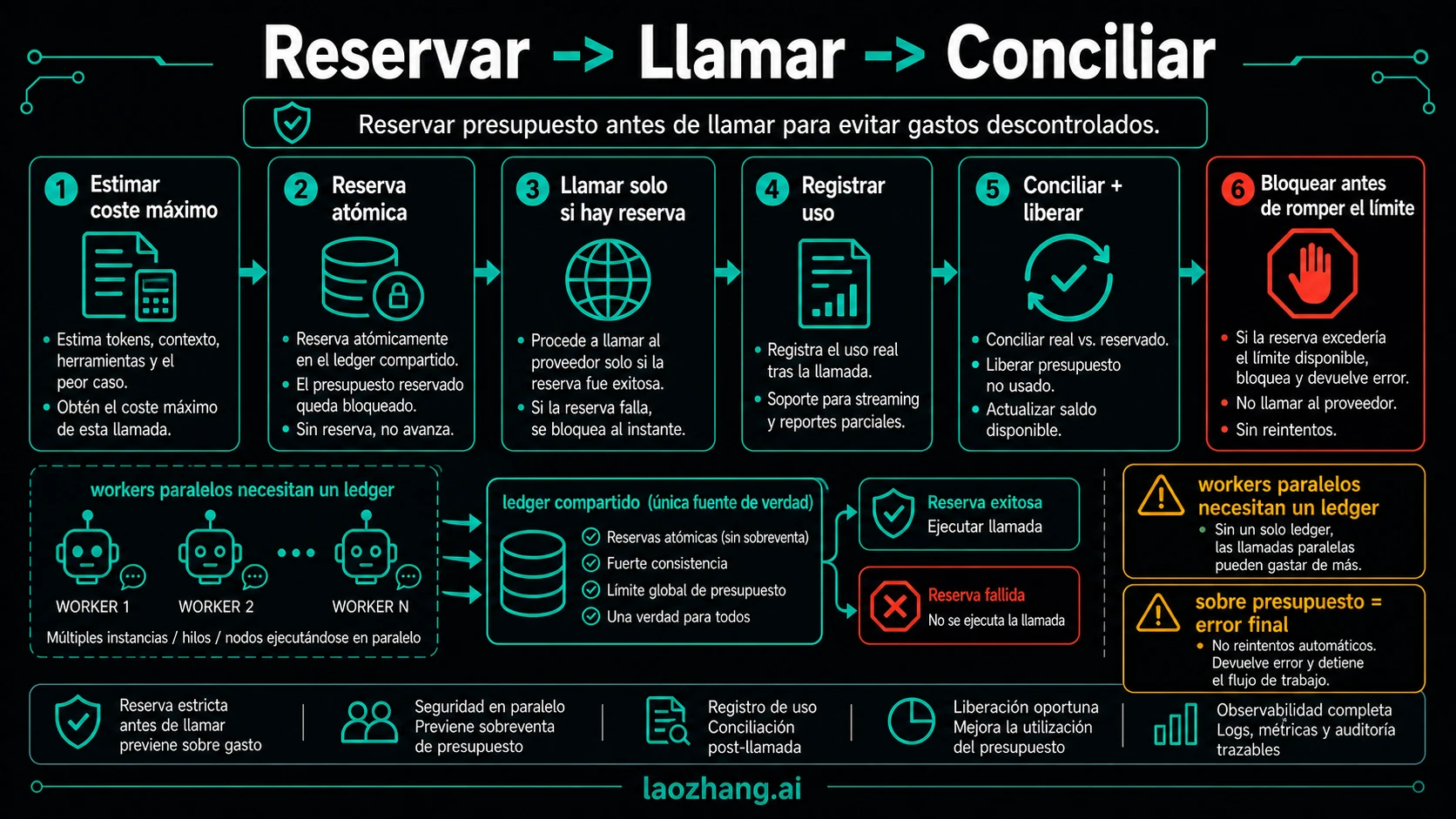
Campos mínimos del ledger:
| Campo | Por qué existe |
|---|---|
| budget_id | Equipo, usuario, proyecto, agente o run dueño del límite |
| limit_amount | Máximo permitido en el periodo o run |
| reserved_amount | Gasto reservado por llamadas en vuelo |
| actual_amount | Gasto conciliado desde usage |
| period_start / period_end | Ventana diaria, mensual o por run |
| request_id | Une la decisión con logs del proveedor |
| agent_run_id | Agrupa planner, worker, subagente y llamadas de herramienta |
| decision | allowed, blocked, reconciled o released |
| reason | cap reached, missing estimate, unknown model, override o policy block |
El flujo previo a la llamada puede ser breve:
tsasync function guardedModelCall(request) { const estimate = estimateWorstCaseCost(request); const reservation = await ledger.reserveAtomically({ budgetId: request.budgetId, requestId: request.requestId, agentRunId: request.agentRunId, amount: estimate, }); if (!reservation.allowed) { return { error: "over_budget", retryable: false }; } const response = await provider.responses.create(request.payload); await ledger.reconcile({ reservationId: reservation.id, actualAmount: costFromUsage(response.usage), usage: response.usage, }); return response; }
La palabra clave es atómica. Si cinco workers leen el mismo remaining budget y todos llaman al proveedor, los logs de usage llegan demasiado tarde. La reserva debe ser una transacción de base de datos, un script Redis, un paso de workflow durable o una operación del gateway que no se pueda intercalar para el mismo budget_id.
Para streaming, reserva el máximo que permites al inicio. Si el usage llega al final, concilia cuando cierre el stream. Si el cliente se desconecta antes de conocer el usage, no liberes toda la reserva: deja un cargo conservador, marca unknown o ejecuta una conciliación posterior con logs del proveedor.
Haz que el agente se detenga
La respuesta de presupuesto debe formar parte de la semántica del agente. Un timeout, una caída de red o algunos 429 pueden ser reintentables. over_budget no debe serlo para el mismo scope.
json{ "error": "over_budget", "retryable": false, "budget_id": "team-alpha-agent-run", "next_allowed_action": "human_budget_override" }
Tres reglas de propagación:
| Regla | Motivo |
|---|---|
| El planner deja de programar trabajo pagado | Evita que el loop raíz cree más jobs bloqueados |
| Los subagentes heredan el budget scope | Evita que helpers gasten después del padre |
| Las tools que llaman modelos usan el mismo gate | Evita gasto oculto dentro de herramientas |
La política de reintentos debe tener una stop list: over_budget, policy_blocked y missing_budget_scope no se reintentan. Se registran, se muestran al operador y detienen el run. Cambiar de modelo, proveedor, gateway o key no es un retry inocente; es una nueva decisión de presupuesto.
Verifica límites de proveedores y gateway
Los controles del proveedor son útiles, pero no todos son kill switches del mismo tipo. Revisa documentación actual antes de convertirlos en runbook, porque los productos cambian.
| Surface | Evidencia que conviene verificar | Límite práctico |
|---|---|---|
| OpenAI project budgets | En la ayuda revisada para este run, los project monthly budgets son soft spending thresholds: las API requests pueden continuar tras superar el presupuesto. La guía de rate limits también separa throughput limits de usage/spend limits. | No confíes solo en project budgets como kill switch del request path. |
| OpenAI Responses usage | Los objetos Responses exponen usage fields útiles para conciliación. | Sirven después de la llamada, no para bloquear antes por sí solos. |
| Anthropic limits | La documentación separa spend limits y rate limits. | Buen backstop de proveedor; las llamadas directas del agente deben pasar por tu gate. |
| LiteLLM proxy | Documenta budgets, agent/session caps y spend tracking. | Opción útil si todo el tráfico pagado pasa por el proxy. |
| Cloudflare AI Gateway | Documenta spend limits que pueden bloquear con HTTP 429 y advierte sobre eventual consistency. | Gateway fuerte, pero prueba bursts concurrentes y rutas de bypass. |
| Vercel Spend Management | Puede notificar, disparar webhooks o pausar despliegues según configuración. | Freno de plataforma, no sustituto de un gate por agente. |
Los incidentes de OpenAI rate limit o quota exceeded deben tener otra rama. Rate limit trata throughput; spend kill switch trata si tu política presupuestaria debe impedir la siguiente llamada pagada.
Pruébalo con cero llamadas al proveedor
La prueba decisiva no es que aparezca blocked en un log. Es que, después del límite, el proveedor falso no reciba ninguna llamada.
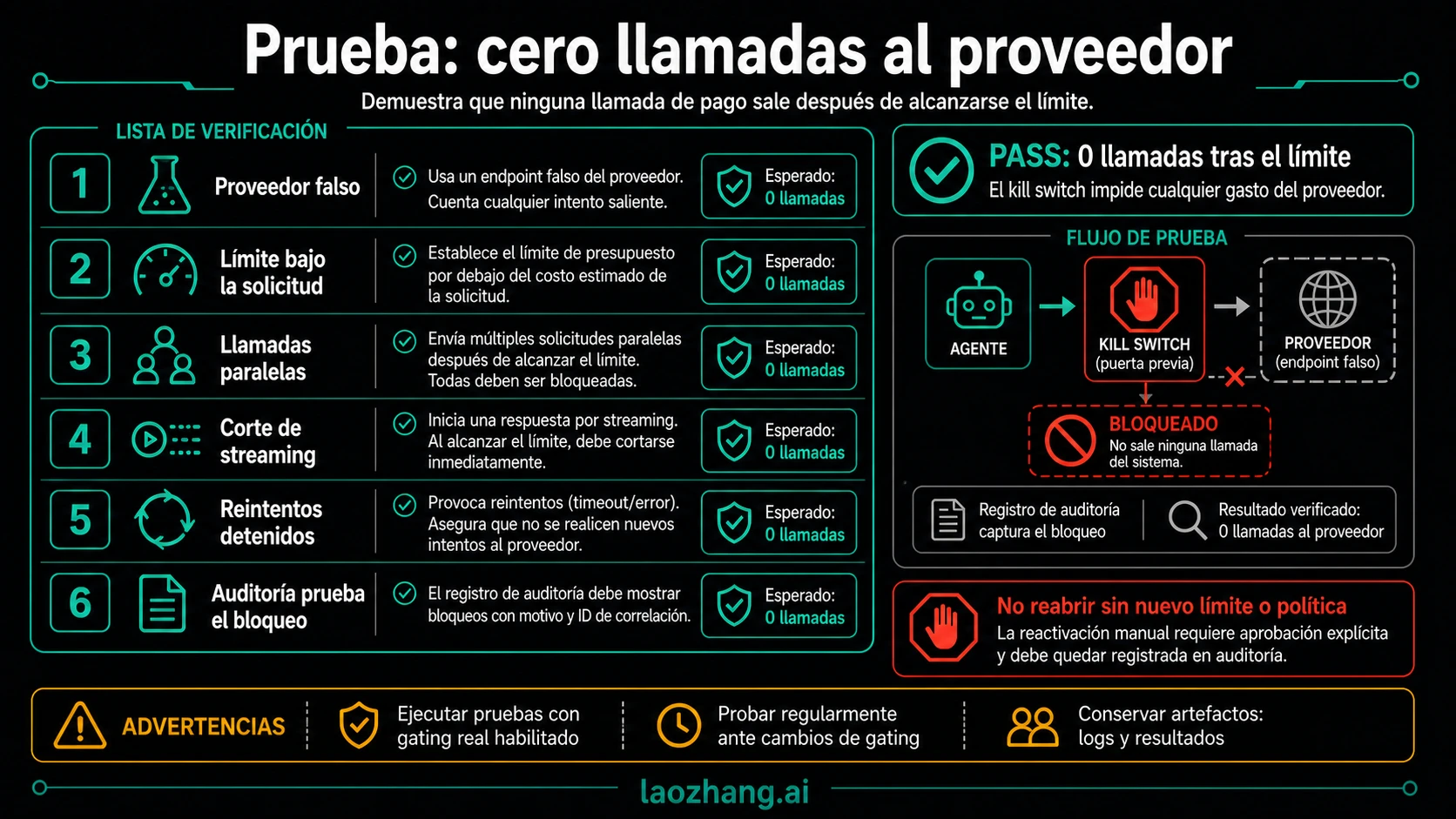
| Prueba | Setup | Condición de paso |
|---|---|---|
| Fake provider | Sustituye endpoint por un contador local | El contador queda en 0 tras agotar presupuesto |
| Cap below request | Deja remaining budget por debajo de estimate | over_budget antes de network call |
| Parallel workers | Lanza llamadas concurrentes que romperían el cap si hay carrera | Solo pasan reservas aprobadas |
| Streaming abort | Corta un stream a mitad | Ledger conserva reserva hasta reconciliar |
| Retry policy | Simula timeout, 429 y over_budget | Solo reintenta errores retryable |
| Audit packet | Revisa ledger, request_id, agent_run_id y reason | El operador puede explicar el bloqueo |
Ejecuta estas pruebas al cambiar precios, rutas, política de reintentos, gateway o storage del ledger. Si el fake provider ve una llamada después del cap, todavía no tienes un kill switch.
Runbook de producción
- Congela credenciales directas del proveedor y confirma que los workers no evitan el gate.
- Identifica el budget scope: usuario, equipo, proyecto, agent run o cap mensual.
- Revisa el ledger: actual spend, reserved spend, in-flight calls y unknown reconciliation items.
- Confirma que el agente recibió over_budget terminal.
- Detén retries, sub-agent scheduling y llamadas de modelo dentro de tools.
- Concilia provider logs contra ledger records.
- Decide si subes cap, reduces tarea o cierras el run.
- Si hay human override, registra aprobador, nuevo cap, expiración y motivo.
El override más peligroso es probar otra ruta. Si cambias proveedor, modelo, gateway o key, trátalo como nueva decisión de presupuesto.
Preguntas frecuentes
¿Basta un OpenAI project budget?
No. La ayuda revisada para este run describe project budgets como soft thresholds. Son útiles para governance y alerts, pero el agente necesita un request-path gate antes del proveedor.
¿Debe devolver HTTP 402, 429 u otra cosa?
Usa el estado que tus clientes manejen de forma consistente, pero el payload importa más: debe decir que el cap se rompería y retryable debe ser false. Algunos gateways usan 429; un runtime interno puede usar over_budget.
¿Cómo estimar coste antes de tener respuesta?
Usa el máximo input, output, tool, image o streaming cost que permites para ese request. Luego concilia con usage y libera la reserva sobrante.
¿Qué pasa si el usage llega tarde?
Mantén la reserva hasta terminar conciliación o marca unknown con cargo conservador. Liberar todo tras un stream interrumpido reabre presupuesto antes de conocer el coste real.
¿Los subagentes necesitan presupuestos propios?
Pueden tener budgets hijos, pero deben heredar el cap del run padre. Un helper no debe gastar después de que el padre se detuvo.
¿Por dónde empezar si ya usamos gateway?
Confirma que cada paid model path pasa por el gateway. Después prueba fake provider, low cap y parallel calls. El gateway solo es kill switch principal si no hay bypass y la llamada bloqueada nunca llega al proveedor.