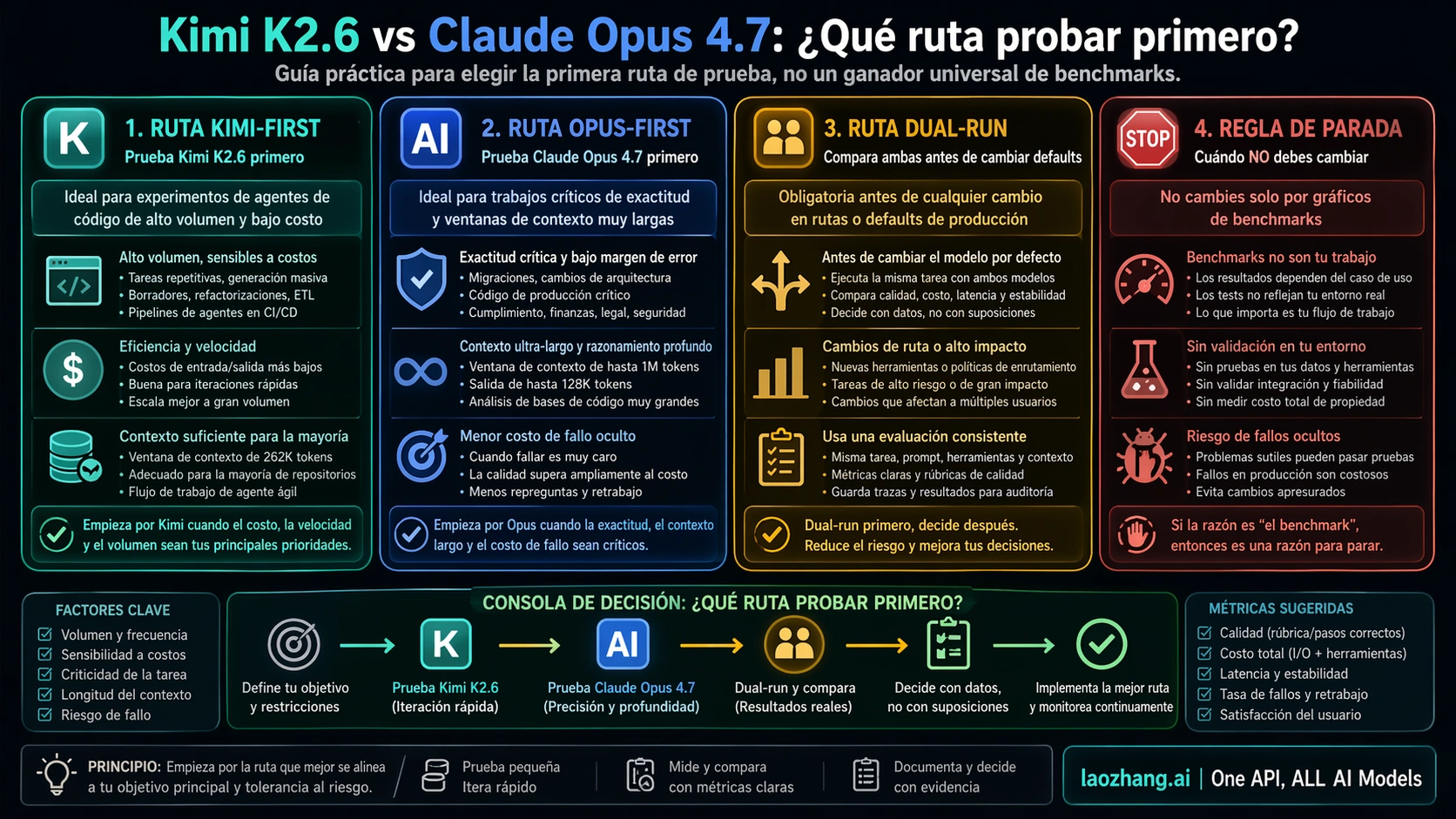
La comparación entre Kimi K2.6 y Claude Opus 4.7 no debería convertirse en una pelea abstracta por el modelo más fuerte. La pregunta útil es más concreta: qué ruta conviene probar primero para coding agents y API work, y cuándo sería irresponsable cambiar un default de producción.
Si necesitas muchas ejecuciones baratas, correcciones de bajo riesgo, scaffolding de tests o una evaluación de ruta abierta, empieza por Kimi K2.6. Si el trabajo es una migración, código de seguridad, lógica cerca de pagos, análisis con mucho contexto o una tarea donde un bug oculto cuesta más que la factura de tokens, mantén primero Claude Opus 4.7. Si el equipo quiere reemplazar un default que hoy usa Opus, corre ambos modelos con el mismo repositorio, la misma spec, el mismo presupuesto de herramientas y la misma revisión.
| Ruta | Cuándo empezar ahí | Por qué encaja | Regla de parada |
|---|---|---|---|
| Kimi primero | Experimentos masivos y baratos de coding agent | La diferencia de precio justifica un pilot serio | No lo llames reemplazo de Opus sin probar el mismo workflow |
| Opus primero | Exactitud, contexto largo y coste de fallo dominan | Tiene el contrato premium y la ruta API madura de Anthropic | No cambies production default solo por precio |
| Dual-run | Vas a cambiar routing o modelo por defecto | La calidad de reemplazo es un resultado de workflow | Sin umbral de pérdida, no hay cambio de default |
El contrato oficial del 2026-04-23 deja clara la división. Kimi K2.6 muestra cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok y 262,144 tokens de contexto. Claude Opus 4.7 muestra input $5/MTok, output $25/MTok, 1M de contexto y 128k de salida máxima. Eso prueba una ruta de coste para Kimi y una ruta premium para Opus; no prueba un ganador universal.
Respuesta rápida
En español aparecen sobre todo comparadores globales: OpenRouter, Artificial Analysis, Reddit, Kilo Blog y vídeos. Eso obliga a separar la superficie de comparación del contrato oficial. Un proveedor puede ser útil para mirar métricas, pero no debe ser dueño de los precios oficiales. Un hilo puede ser útil para ver fallos reproducibles, pero no decide tu default de producción.
La regla práctica es esta: usa Kimi primero donde el volumen de intentos sea parte de la estrategia; usa Opus primero donde el coste del fallo sea más alto que el ahorro; usa dual-run antes de tocar un default. Esta regla da a Kimi una oportunidad real de ganar en trabajos de bajo riesgo, sin fingir que un precio bajo borra todas las diferencias de revisión.
Si hoy ya usas Opus para coding de alto valor, no preguntes si Kimi “es mejor” en general. Pregunta si Kimi puede superar el mismo pack de tareas donde Opus ya justifica su coste. Si los defectos reales, el tiempo de revisión y los reintentos quedan dentro del umbral que escribiste antes del test, entonces Kimi puede ganar una parte de la ruta.
El contrato oficial marca el límite
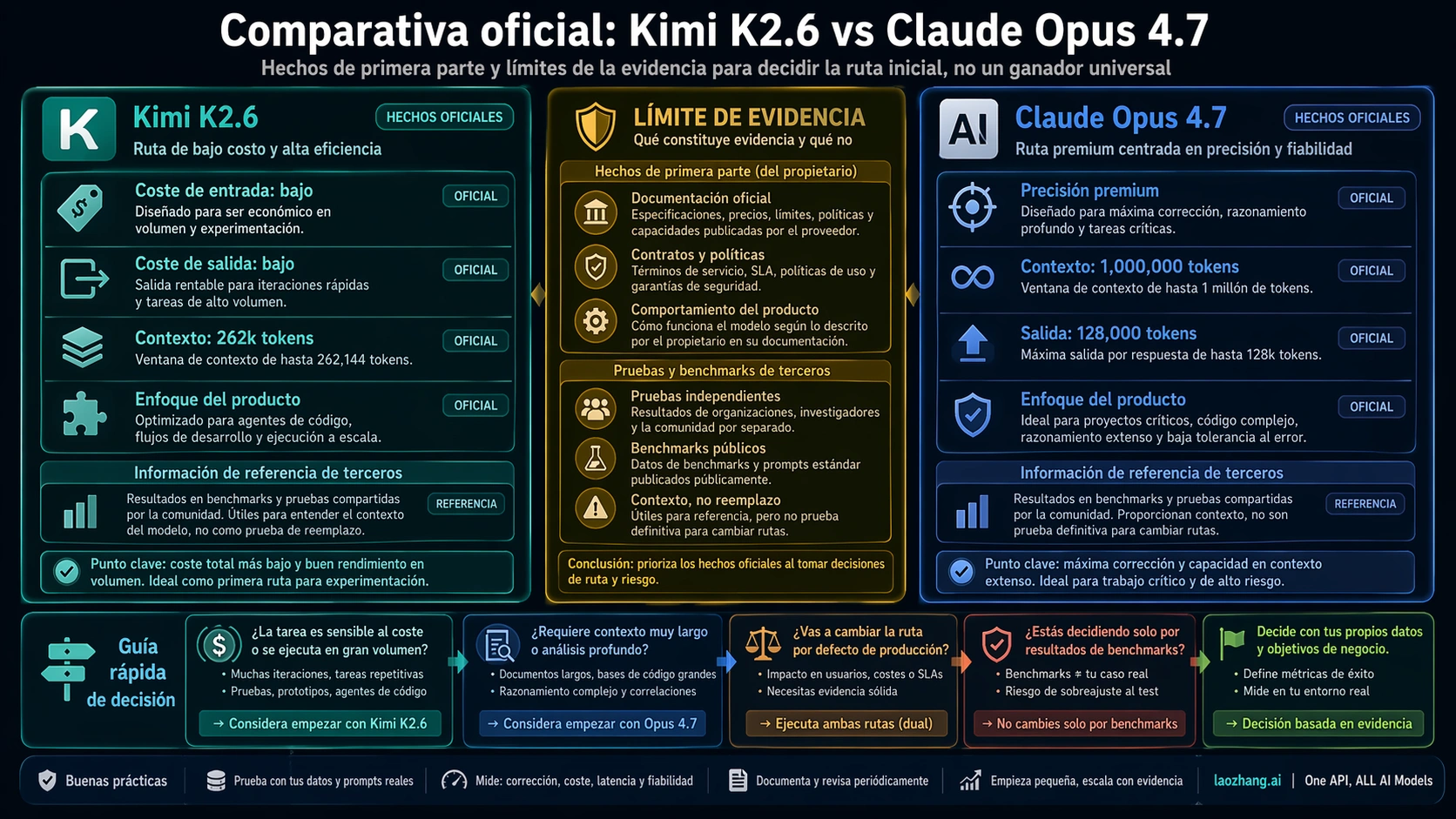
| Punto de contrato | Kimi K2.6 | Claude Opus 4.7 |
|---|---|---|
| Dueño de los datos | Moonshot / Kimi | Anthropic |
| Identificador API | ruta pública K2.6 en la plataforma Kimi | claude-opus-4-7 |
| Precio comprobado el 2026-04-23 | cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok | input $5/MTok, output $25/MTok |
| Contexto / salida | 262,144 tokens de contexto | 1M de contexto y 128k de salida máxima |
| Qué cambia | Permite aumentar intentos baratos | Mantiene control premium para trabajo con riesgo |
Los datos de Kimi pertenecen a Moonshot/Kimi: precio, cache-hit row, contexto y disponibilidad. Los datos de Claude Opus 4.7 pertenecen a Anthropic: model ID, precio, 1M de contexto, 128k de salida y comportamiento API. OpenRouter, Artificial Analysis, Reddit o Kilo pueden orientar la evaluación, pero no sustituyen a esas fuentes.
En una forma simple de 1M tokens de entrada y 1M de salida, Kimi sin cache quedaría cerca de $4.95 y Opus en $30. La diferencia es suficiente para probar Kimi con seriedad. Pero el coste real también incluye retries, tool calls, wall-clock time, intervención del reviewer, defectos ocultos y rollback. En tareas de alto riesgo, una ejecución barata puede salir cara si aumenta la carga de revisión.
En el lado de Opus también hay un matiz de tokenización. Anthropic avisa de que el mismo texto puede mapearse como aproximadamente 1.0x-1.35x tokens según el tipo de contenido. No es un recargo fijo, pero sí una razón para medir prompts reales.
Qué pruebas sirven y cuáles no
El material oficial de Kimi demuestra que K2.6 es una opción actual, barata y seria para pilot. No demuestra que Kimi ya haya ganado a Claude Opus 4.7 en tu workflow, porque la tabla oficial de Kimi no incluye a Opus 4.7 como columna directa. Convertir una fila de otra versión en prueba contra Opus 4.7 sería una sobreafirmación.
Las pruebas de terceros sirven como método. Te ayudan a decidir qué fallos reproducir: tests que pasan con código frágil, refactors demasiado amplios, pasos de migración omitidos, supuestos incorrectos, tool loops largos o summaries que prometen más de lo que arreglan. Pero no son el contrato oficial ni el default de tu equipo.
| Tipo de evidencia | Qué puede sostener | Qué no puede sostener |
|---|---|---|
| Kimi first-party | Precio, actualidad, contexto y valor de pilot | Reemplazo universal de Opus |
| Anthropic first-party | Model ID, precio, contexto, salida y migración | Que Opus siempre merezca el precio |
| Comparadores externos | Ideas de test y señales de riesgo | Precios oficiales o routing de producción |
| Tu dual-run | Decisión local de reemplazo | Conclusión universal para otros equipos |
Cómo hacer un pilot de coding agent
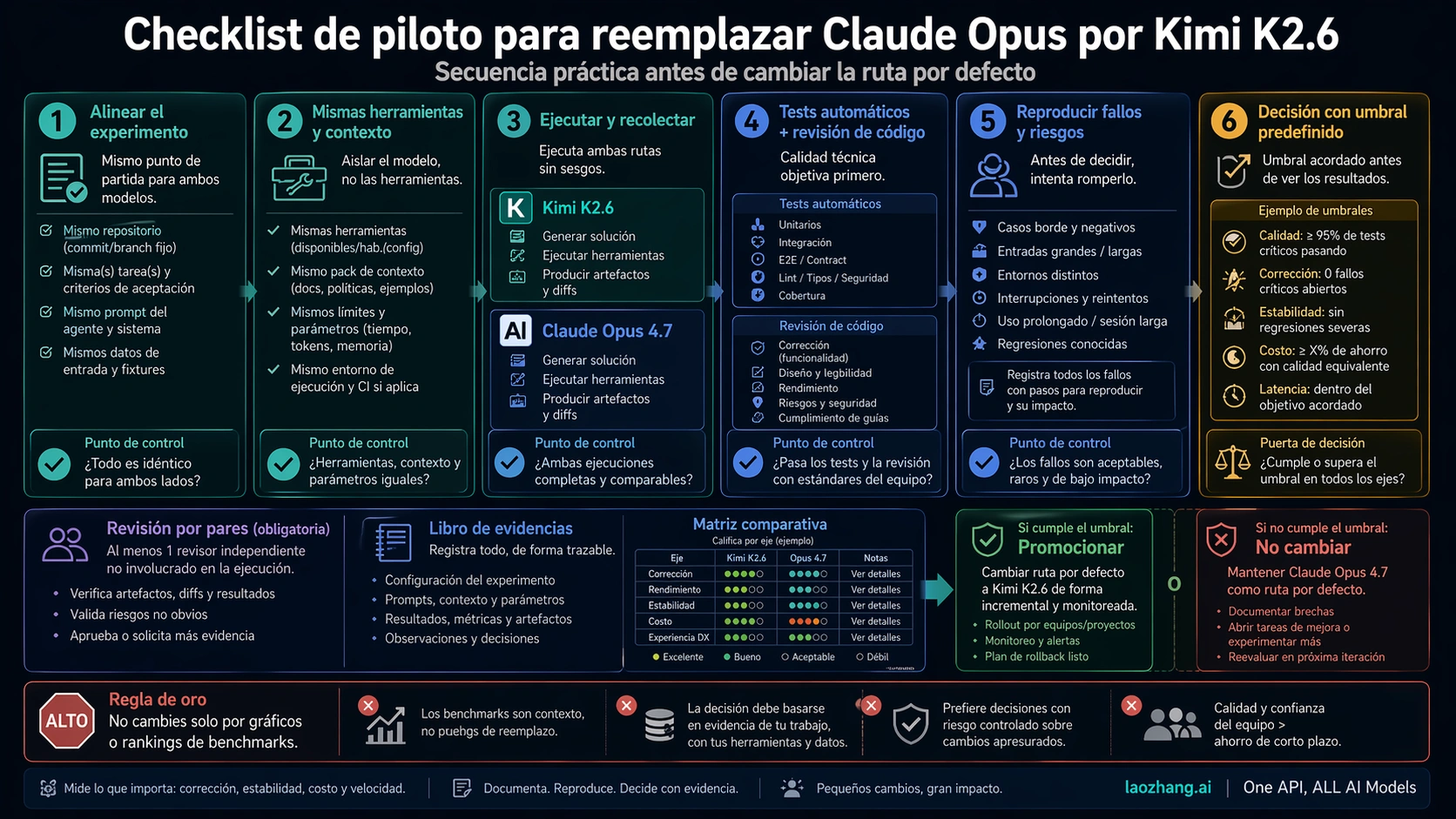
Un pilot serio debe ser aburrido. Usa tareas reales donde Opus ya haya sido útil: un bug pequeño, un refactor medio, una tarea de tests, un caso de contexto largo y una tarea ambigua donde el modelo deba pedir información o rechazar un supuesto malo. Si usas agentes, conserva herramientas y navegación de repo. Si usas API batch, conserva templates, timeouts y política de retry.
Ambos modelos deben correr con el mismo snapshot del repositorio, la misma descripción, el mismo criterio de éxito, el mismo presupuesto de herramientas, las mismas condiciones de parada y los mismos checks. Después revisa el diff a mano. Los tests son necesarios, pero no detectan todo: abstracciones frágiles, pasos de migración perdidos o fixes que solo cubren el caso visible.
El umbral de cambio se escribe antes de empezar. Para edits de bajo riesgo, quizá aceptes que Kimi quede dentro de un 10% de defectos reales respecto a Opus si el coste cae más de la mitad. Para seguridad, pagos o migraciones, exigirás casi paridad y un dual-run más largo. Esa asimetría es racional porque el precio del fallo cambia por workload.
Rutas por carga de trabajo
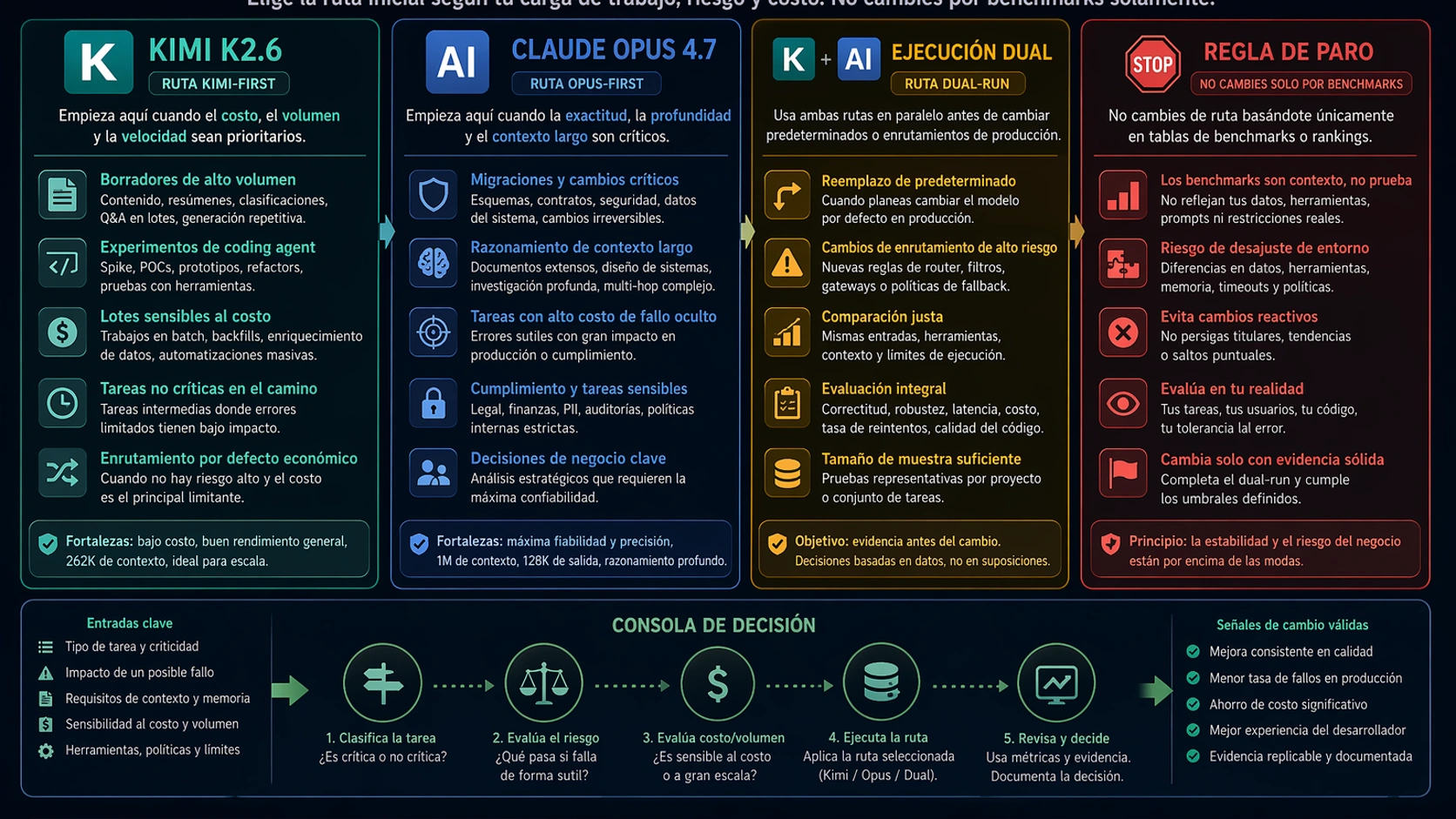
| Workload | Empezar con Kimi | Empezar con Opus | Dual-run antes del default |
|---|---|---|---|
| Experimentos masivos de agentes | Sí | Solo como muestra de control | Antes de repos importantes |
| Limpieza de bajo riesgo y tests | Sí | Si el review se vuelve cuello de botella | Antes de auto-merge |
| Migración de repositorio | Solo tras control run | Sí | Sí |
| Seguridad o código cerca de pagos | Rara vez primero | Sí | Sí |
| Análisis largo de producción | Si 262k basta y manda el coste | Si necesitas 1M o 128k output | Antes de sustituir decisiones de Opus |
| Evaluación open-source o self-host | Kimi es la ruta natural | Opus no es ruta abierta | Antes de competir con producción |
Si tu pregunta real es migrar dentro de Anthropic, lee Claude Opus 4.7 vs Claude Opus 4.6. Si comparas Anthropic, OpenAI y Google, usa Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro. Para la decisión Kimi-versus-Opus, mantén el foco en reemplazo, coste y riesgo de default.
Notas API antes de cambiar defaults
No mezcles Kimi first-party, OpenRouter, Microsoft Foundry u otras rutas de proveedor. El nombre del modelo puede parecer igual, pero latencia, cuota, facturación, logs, soporte y términos de fallo pertenecen a contratos distintos. Si escribes un informe interno, etiqueta el dueño del precio.
En Claude tampoco basta con cambiar el model string. Opus 4.7 trae notas sobre sampling parameters, extended thinking, tokenizer behavior, high-resolution images y task budgets. Si tu cliente todavía manda combinaciones antiguas de top_p, top_k o temperature, la migración puede estar en el harness, no en el prompt.
Un rollout serio separa cuatro tablas: coste, calidad, tiempo y ruta. Coste separa cached input, input, output y retries. Calidad separa blocker, major, minor y style. Tiempo registra reviewer minutes y reintentos. Ruta marca Kimi-only, Opus-only, dual-run y rollback.
Plantilla de evaluación
| Qué registrar | Cómo registrarlo | Por qué importa |
|---|---|---|
| Coste | input, cached input, output, retries, tools | Token barato no siempre es workflow barato |
| Calidad | blocker, major, minor, style | Un defecto grave no debe esconderse en el promedio |
| Revisión | minutos de reviewer, edits, reruns | El coste real de agent coding suele estar en revisión |
| Ruta | Kimi-only, Opus-only, dual-run, rollback | Convierte el pilot en una regla operativa |
Preguntas frecuentes
¿Kimi K2.6 es más barato que Claude Opus 4.7?
Sí, con precios first-party comprobados el 2026-04-23. Kimi lista $0.95/MTok input, $4.00/MTok output y $0.16/MTok cache hit. Anthropic lista Opus en $5/$25. Los precios de proveedores pueden cambiar.
¿Puede Kimi K2.6 reemplazar a Claude Opus 4.7?
Solo después de demostrarlo en tu workflow. La frase correcta inicial es que Kimi merece un pilot para coding sensible a coste, no que sea un reemplazo automático.
¿Cuál conviene para coding agents?
Opus 4.7 es la primera opción más segura para coding de alto riesgo, migraciones y trabajo largo. Kimi K2.6 es mejor primer experimento cuando necesitas muchos intentos baratos y puedes revisar o descartar salidas.
¿El benchmark oficial de Kimi prueba que gana a Opus 4.7?
No. El benchmark de Kimi es útil, pero no incluye a Claude Opus 4.7 como comparación directa.
¿Qué debo probar antes de cambiar un default model?
El mismo repo, la misma spec, el mismo tool budget, los mismos tests, el mismo reviewer y un umbral de pérdida decidido antes de correr.
¿Puedo usar páginas de proveedores para decidir?
Sí para explorar métricas y riesgos. No para reemplazar las fuentes first-party de precio, model ID, contexto, salida o comportamiento API.
¿Qué pasa si necesito 1M de contexto?
Empieza con Claude Opus 4.7 si el 1M context es central. Kimi tiene 262k, que es mucho, pero no es el mismo contrato.