
A fecha de 23 de mayo de 2026, Codex CLI no tiene un número diario universal de tokens. Antes de calcular dinero, tienes que saber si la sesión usa inicio de sesión de ChatGPT, una API key, una tarea en la nube de Codex, code review o fast mode. Solo cuando el trabajo se factura con API key tiene sentido estimar el gasto con input tokens, cached input tokens y output tokens. La estimación útil empieza por la ruta, sigue con la fórmula y termina con un límite diario antes de lanzar una tarea larga.
Estimador rápido en dos minutos
Úsalo antes de pedir a Codex que recorra un repositorio grande, haga una migración de muchos archivos, depure durante horas o produzca explicaciones largas.
- Confirma la ruta: ChatGPT sign-in, API key, CLI local, cloud task, code review o fast mode.
- Si la facturación por API key está activa, elige el modelo real y abre la tabla actual de OpenAI Platform.
- Separa tres contadores: input tokens, cached input tokens y output tokens.
- Multiplica cada contador por su precio por millón de tokens.
- Define un límite blando y un límite duro para el día.
La fórmula de API key es:
textcoste diario de API = input_tokens / 1,000,000 * input_price + cached_input_tokens / 1,000,000 * cached_input_price + output_tokens / 1,000,000 * output_price
Con los precios estándar de OpenAI revisados el 23 de mayo de 2026, un día normal con 3M input, 2M cached input y 0.4M output sale a unos 4.20 dólares en gpt-5.4-mini o 14.00 dólares en gpt-5.4. No es una promesa de factura; es un ensayo de presupuesto con supuestos visibles.
Qué medidor está activo
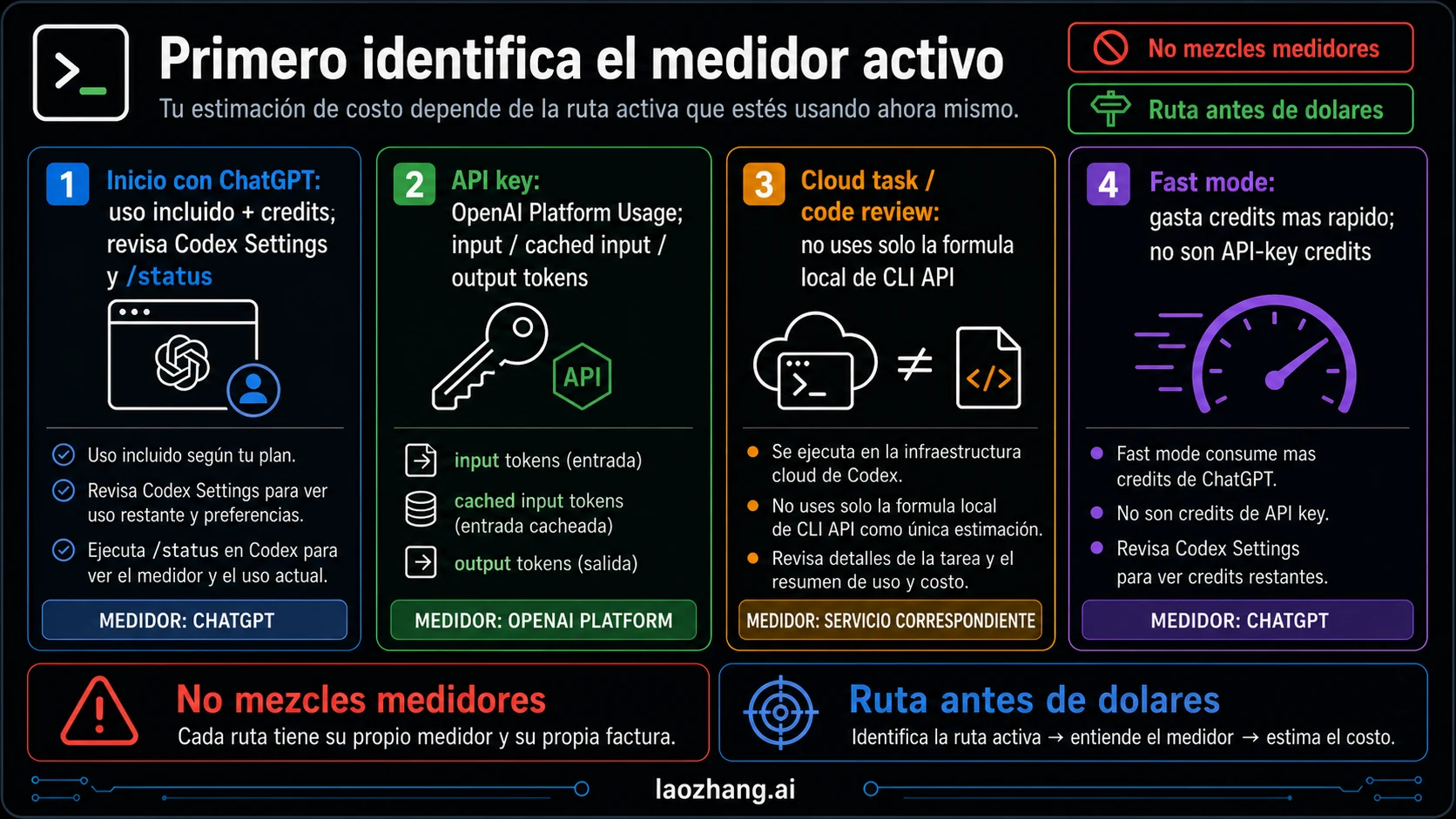
No calcules dólares hasta saber qué medidor manda. Codex puede parecer un solo producto en la terminal, pero la ruta de facturación cambia por debajo.
| Ruta activa | Qué significa | Cómo estimar | Dónde comprobar |
|---|---|---|---|
| ChatGPT sign-in | Uso de Codex ligado a un plan de ChatGPT | Included usage, credits y límites de cuenta | Codex Settings, /status |
| Facturación con API key | CLI local o automatización en OpenAI Platform | Input, cached input y output por modelo | OpenAI Platform Usage |
| Cloud task o code review | Infraestructura alojada de Codex | Detalles de tarea y Codex pricing | Task summary, Codex Settings |
| Fast mode | Trabajo más rápido en ruta ChatGPT con mayor consumo de credits | Credits y multiplicador actual | Codex Settings, speed docs |
La documentación de Codex authentication trata el inicio con API key como OpenAI Platform billing a tarifas estándar de API. La página de Codex pricing describe por separado planes de ChatGPT, credits y disponibilidad de API key. Si aún estás eligiendo ruta, usa primero Codex API Key vs Subscription: Which Route Should You Use?.
Precios actuales que debes usar
Para API key importan tres precios: input, cached input y output. Output suele dominar cuando Codex escribe explicaciones largas, archivos completos, logs de test o resúmenes repetidos.
| Modelo | Input | Cached input | Output | Uso en la estimación |
|---|---|---|---|---|
| gpt-5.4-mini | $0.75 / 1M | $0.075 / 1M | $4.50 / 1M | Base de bajo coste para tareas rutinarias |
| gpt-5.4 | $2.50 / 1M | $0.25 / 1M | $15.00 / 1M | Estimación para diagnóstico complejo y arquitectura |
| gpt-5.5 | $5.00 / 1M | $0.50 / 1M | $30.00 / 1M | Hay precio de Platform, pero no lo uses como base de Codex API-key sin verlo en Codex docs |
La nota sobre GPT-5.5 no es decorativa. En esta revisión, Codex pricing mostraba GPT-5.5 para uso de Codex en planes ChatGPT, pero no como fila base de API key. Si OpenAI cambia esa disponibilidad, actualiza primero la ruta y luego los ejemplos.
Los precios se verifican en OpenAI Platform pricing. Los límites RPM, RPD, TPM, TPD, IPM y spend limits se verifican en API rate limits. Los límites importan para automatización, pero no son el coste diario.
Escenarios diarios de coste

Los escenarios sirven para crear un techo, no para adivinar la factura exacta.
| Escenario | Input tokens | Cached input tokens | Output tokens | gpt-5.4-mini | gpt-5.4 |
|---|---|---|---|---|---|
| Día ligero | 0.6M | 0.2M | 0.08M | $0.83 | $2.75 |
| Día normal | 3M | 2M | 0.4M | $4.20 | $14.00 |
| Día pesado | 12M | 8M | 2M | $18.60 | $62.00 |
El día normal en gpt-5.4-mini:
text(3 * $0.75) + (2 * $0.075) + (0.4 * $4.50) = $4.20
La misma mezcla en gpt-5.4:
text(3 * $2.50) + (2 * $0.25) + (0.4 * $15.00) = $14.00
La diferencia muestra que el modelo y la longitud de salida pesan más que recortar unas líneas de prompt. Para documentación, cambios pequeños, tests sencillos y diagnóstico inicial, empieza por el modelo más barato que pueda completar el trabajo con seguridad.
Cómo medir tu propio día de Codex
La mejor estimación sale de un bloque real de 30 a 60 minutos. No necesitas telemetría perfecta para tomar una decisión mejor.
- Usa la misma ruta que usarás en el trabajo real.
- Ejecuta una tarea representativa, no una prueba de juguete.
- Registra modelo, tamaño del repositorio, rutas leídas, archivos tocados, tool calls y turnos.
- Si usas API key, revisa OpenAI Platform Usage.
- Si el panel separa categorías, anota input, cached input y output.
- Si solo ves gasto total, crea un rango aproximado con el precio del modelo.
- Normaliza el bloque al número de bloques esperados en el día y añade 25-50% por retries.
Si un bloque de 45 minutos cuesta 2 dólares, cuatro bloques no deben presupuestarse como exactamente 8 dólares. Los tests fallidos, archivos adicionales y explicaciones largas pueden empujar el output, así que conviene mirar un rango de 10 a 12 dólares antes de seguir.
Qué aumenta el consumo de tokens
Codex gasta más cuando tiene que leer más, recordar más, probar más o escribir más.
| Factor | Qué ocurre | Control de coste |
|---|---|---|
| Contexto grande | Más archivos entran en input | Limita rutas y excluye generated files, logs y fixtures |
| Tool calls repetidos | Cada lectura, test y log añade contexto | Da criterios de aceptación y agrupa comprobaciones |
| Output largo | Explicaciones, archivos completos y logs encarecen la sesión | Pide patches, comandos y conclusiones breves |
| Poco cache reuse | El contexto repetido no siempre obtiene precio cached | Mantén contexto estable y evita reinicios innecesarios |
| Muchos retries | Tests fallidos crean más turnos | Define stop conditions antes de empezar |
| Modelo fuerte por defecto | La tarifa alta multiplica cada categoría | Escala modelo solo cuando haga falta |
El ahorro suele ser operativo: menos alcance, salida más corta, menos reinicios, modelo base más barato y una regla de parada escrita.
Suscripción, credits o API key
La ruta correcta depende del trabajo.
| Trabajo | Ruta inicial | Motivo |
|---|---|---|
| Codificación personal interactiva | ChatGPT sign-in | Included usage y credits encajan con esa superficie |
| Automatización local con informes | API key | Platform Usage y budgets son más gobernables |
| CI, tareas programadas, SDK o backend | API key | Necesitas credenciales no interactivas y presupuesto de proyecto |
| Cloud task o code review | ChatGPT / workspace route | No se estima solo con matemáticas de CLI local |
| Included usage agotado | Credits o esperar reset | Credits pueden ampliar uso soportado, no pagar facturas API-key ordinarias |
Para límites generales de planes usa OpenAI Codex Usage Limits: Plus, Pro 5x/20x, Business Credits, and API Key Rules. Este artículo mantiene un alcance más estrecho: calcular el sobre diario cuando el trabajo local de Codex se factura por API key.
Reglas de parada para ejecuciones largas
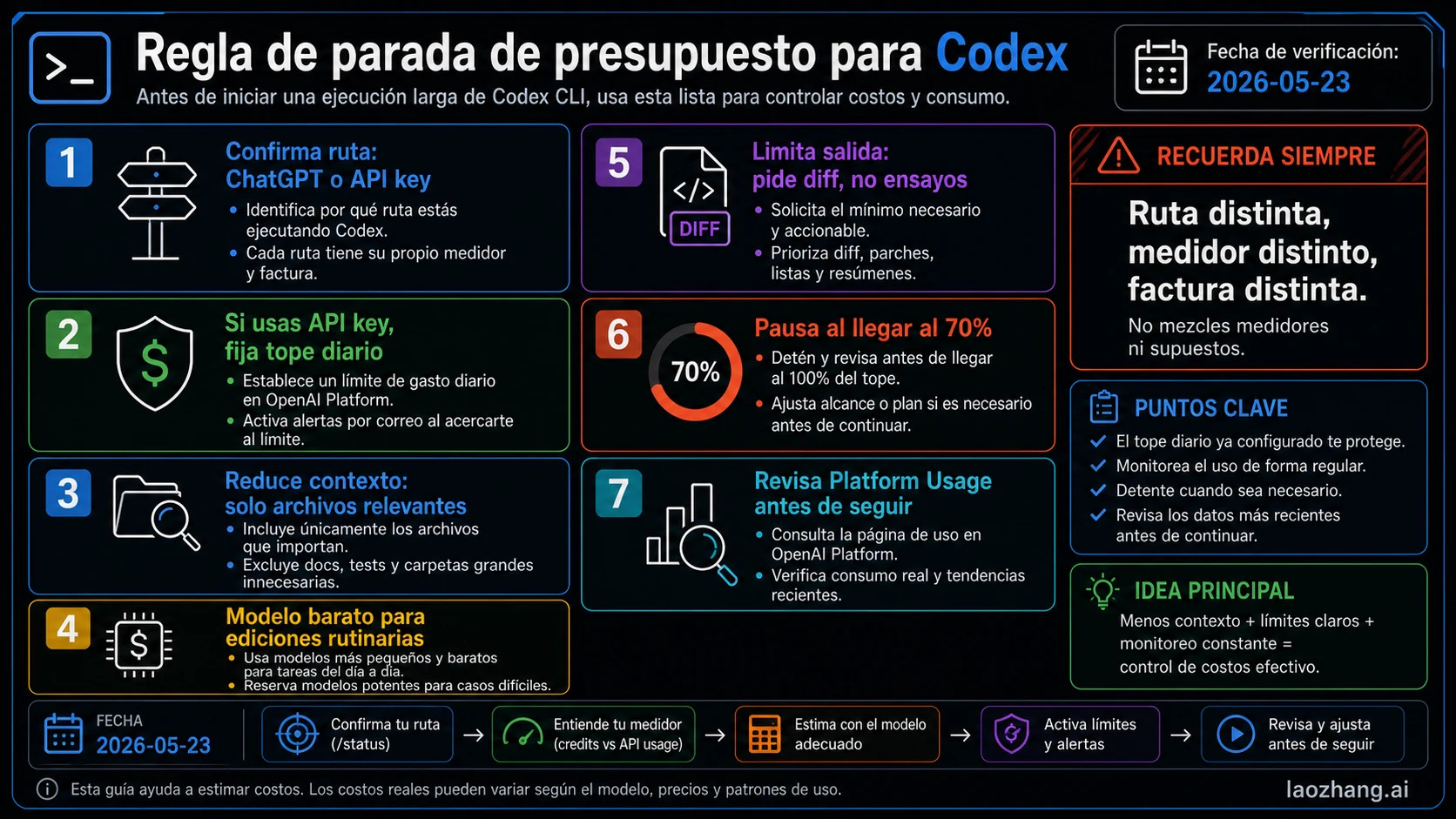
Una sesión larga necesita una regla de parada antes que más contexto.
- Límite blando: pausa al llegar al 70% del presupuesto diario.
- Límite duro: usa Platform budgets o project spend limits si hay API key.
- Límite de alcance: pausa si Codex pide leer fuera de las rutas acordadas.
- Límite de salida: pausa si la respuesta se convierte en prosa larga en vez de patches y decisiones.
- Límite de retries: pausa tras fallos repetidos y cambia de diagnóstico.
Ejemplo práctico:
textBudget: $15/day for routine Codex CLI API-key work Pause at: $10.50 estimated or observed usage Default model: gpt-5.4-mini Escalation: gpt-5.4 only for hard diagnosis or architecture change Output rule: patch and decision first
No es una cantidad universal. Es una plantilla para decidir el número, la ruta, el modelo base y la regla de escalado antes de que la sesión crezca.
Si la factura sale más alta de lo esperado
Diagnostica en este orden:
- Ruta: ¿Codex usaba API key cuando esperabas ChatGPT sign-in?
- Modelo: ¿se usó una opción más cara que la estimada?
- Output: ¿hubo explicaciones largas, archivos completos o resúmenes repetidos?
- Contexto: ¿leyó todo el repositorio en vez de las rutas objetivo?
- Retries: ¿los tests fallidos crearon muchos turnos extra?
- Automatización: ¿CI o un script ejecutó el flujo varias veces?
- Límites: ¿rate limits o spend limits provocaron fallos y reintentos?
OpenAI Platform Usage es el libro mayor para API-key spend. Codex Settings y /status son la comprobación para ChatGPT-route usage. Si no coinciden con tu expectativa, detén el siguiente trabajo largo y corrige la ruta.
Preguntas frecuentes
¿Cuántos tokens usa Codex CLI al día?
No existe un número universal. Depende de ruta, modelo, contexto del repositorio, archivos leídos, tool calls, longitud de output, retries, cache reuse y duración.
¿Cómo estimo el coste de API de Codex CLI?
Confirma primero que la facturación por API key está activa. Luego estima input tokens, cached input tokens y output tokens, multiplica cada categoría por el precio actual del modelo y suma.
¿Por qué separar cached input?
Porque tiene otra tarifa. Puede reducir el coste de contexto repetido, pero no convierte todo el input en precio cached automáticamente.
¿API key es más barata que ChatGPT Plus o Pro?
Depende. API key puede ser mejor para automatización controlada y reporting; ChatGPT sign-in puede ser mejor para trabajo personal interactivo con included usage.
¿Los credits de ChatGPT pagan facturas API-key?
No lo asumas. Credits pertenecen a la experiencia Codex en ruta ChatGPT; API-key usage pertenece a OpenAI Platform billing.
¿Cuál es la forma más segura de empezar una tarea larga?
Confirma la ruta, elige modelo base, limita contexto, pide output breve, mide un bloque representativo y pausa al 70% del presupuesto.