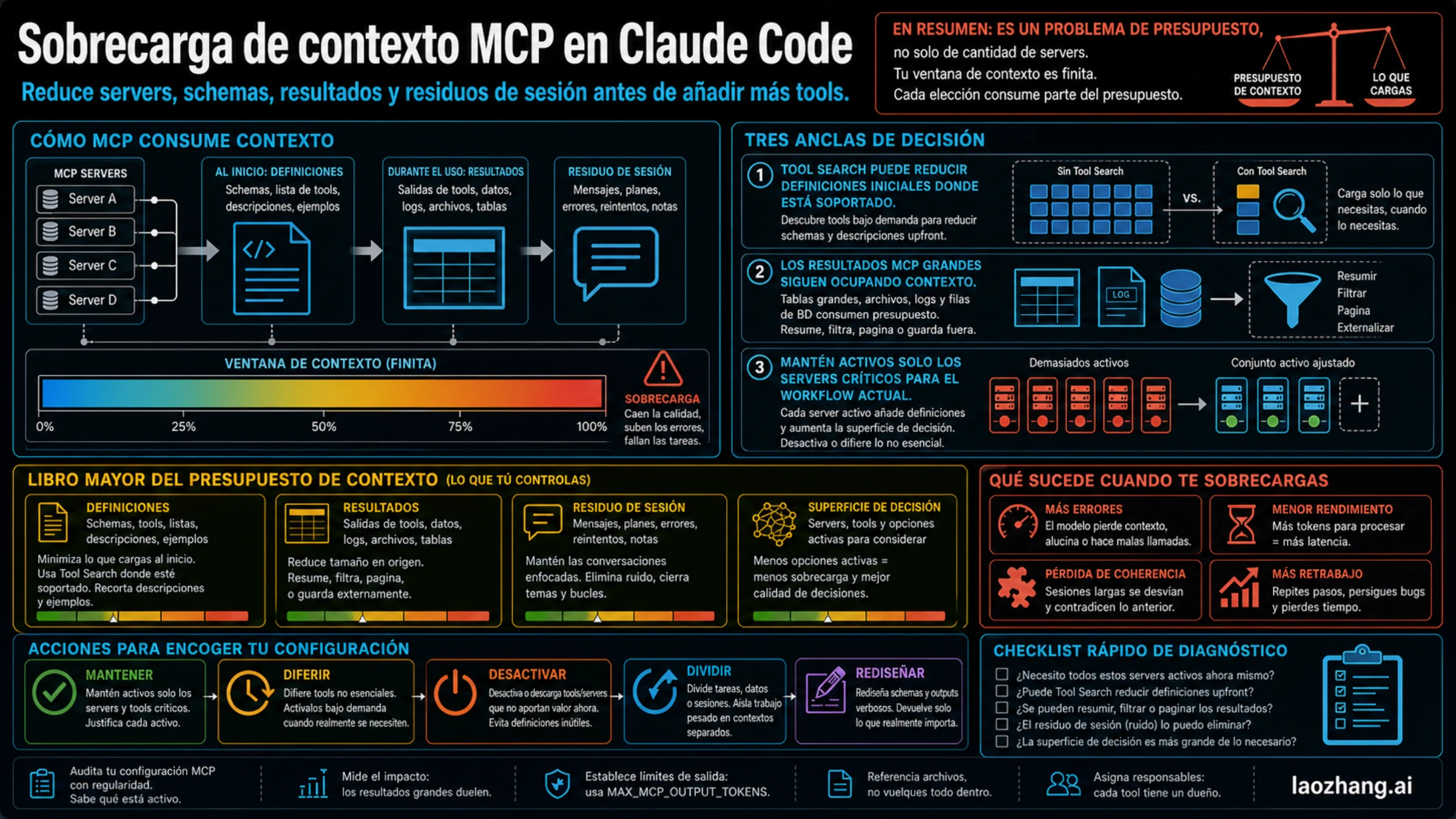
Cuando conectas demasiados servidores MCP a Claude Code, el problema suele aparecer como lentitud, compaction prematura, mala elección de herramientas o una conversación que se vuelve pesada después de leer logs, issues o datos de una base. No es solo una cuestión de cuántos servidores tienes. El contexto se consume por definiciones de herramientas, resultados devueltos, residuos de una sesión larga y una superficie de decisión con demasiadas opciones parecidas.
Vigente al 23 de mayo de 2026: Claude Code documenta controles MCP, Tool Search y avisos cuando la salida MCP supera 10.000 tokens. Tool Search puede reducir la carga inicial de definiciones donde está soportado. Pero no hace gratis los servidores irrelevantes, los resultados grandes, el historial antiguo ni las diferencias de un proxy, proveedor compatible o ruta de modelo no estándar.
Empieza con esta tabla de presupuesto, no con otro ranking de servidores:
| Coste | Cómo se ve | Primer arreglo |
|---|---|---|
| Definiciones | Antes de llamar nada, Claude ya ve muchos nombres, descripciones y schemas. | Verifica Tool Search y desactiva o aplaza servidores que no tienen dueño en la tarea actual. |
| Resultados | Después de una llamada a logs, tablas, issues o base de datos, la sesión se vuelve pesada. | Resume, filtra, pagina, limita, usa cursor o devuelve handles. |
| Residuo de sesión | Errores viejos, planes descartados y reintentos siguen dentro del hilo. | Resume la decisión actual o abre una sesión limpia. |
| Superficie de decisión | Varios servidores exponen search, read, list o fetch con funciones parecidas. | Deja un dueño por workflow; divide o rediseña servidores amplios. |
El primer paso es concreto: ejecuta /mcp, revisa los servidores activos para esta tarea y marca cada uno como keep, defer, disable, split o redesign. Si lo que falta es un método repetible, usa una skill. Si lo que falta es acceso externo o una superficie de acción, conserva solo el MCP que posee ese workflow y comprime lo que devuelve.
Empieza con un presupuesto de contexto
Un servidor MCP no es solo un nombre dentro de settings. Una herramienta MCP tiene nombre, descripción, input schema, a veces output schema y contenido devuelto. Según el cliente y el modo de carga, parte de esa definición puede volverse visible para el modelo antes de que se invoque la herramienta.
Ese es el primer coste, pero no el único. Un solo MCP de base de datos puede saturar una conversación si devuelve miles de filas, traces completas, ficheros enteros o documentos completos. En cambio, varios servidores pequeños, con dueños claros y respuestas compactas, pueden ser aceptables.
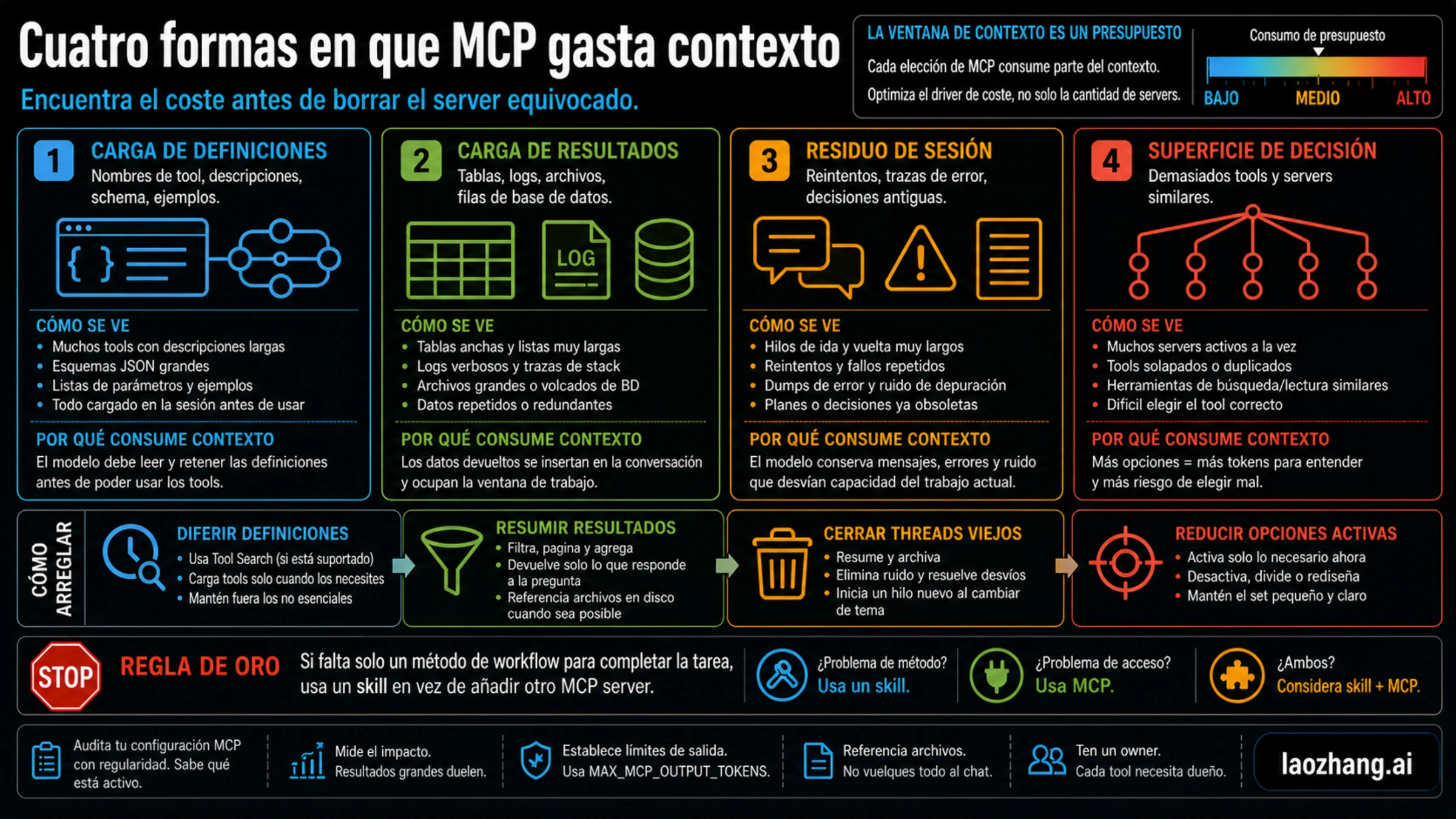
La pregunta de diagnóstico no es “cuántos servidores tengo”, sino “qué está entrando en la ventana de trabajo ahora”. Si Claude Code se vuelve lento antes de cualquier llamada, mira definiciones, nombres repetidos y descripciones largas. Si empeora después de una llamada, mira el tamaño de la salida. Si se confunde tras muchos intentos, puede que el residuo del hilo sea el problema.
| Síntoma | Coste probable | Qué inspeccionar |
|---|---|---|
| Lento antes de llamar herramientas | definiciones o superficie de decisión | /mcp, claude mcp list, nombres duplicados, descripciones vagas |
| Bien hasta una llamada y luego confuso | carga de resultados | logs, tablas, filas, ficheros, traces, payloads API |
| Peor después de muchos arreglos | residuo de sesión | errores viejos, planes abandonados, salidas repetidas |
| No sabe qué herramienta usar | superficie de decisión | varios servidores con acciones parecidas |
Este presupuesto evita la reacción extrema de apagarlo todo. El objetivo es dejar menos decisiones activas, resultados más pequeños y ownership claro para cada acceso externo.
Tool Search ayuda, pero los resultados siguen contando
Tool Search actualiza el consejo clásico sobre MCP. En rutas soportadas por Claude Code, puede diferir discovery y carga de tool definitions, reduciendo la carga inicial de schemas y descripciones.
Eso ayuda, pero no es un cheque en blanco. Cuando Claude llama una herramienta, la respuesta sigue entrando en la conversación. Una tabla grande, un log entero, una captura HTML, un fichero completo o un payload JSON siguen consumiendo context window. Tool Search controla principalmente cuándo se ven las definiciones; no decide si una herramienta devuelve veinte filas o veinte mil.
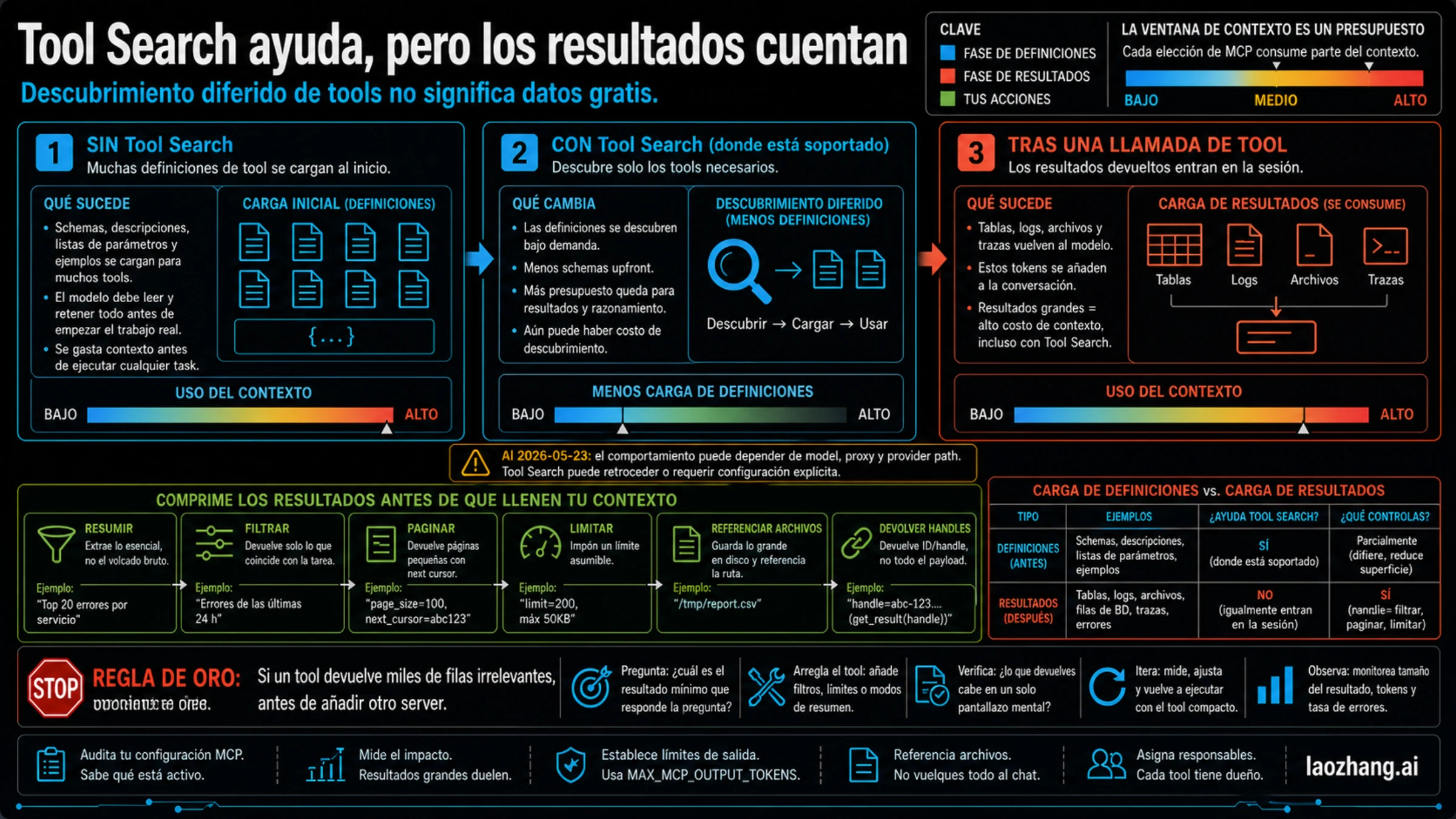
Mantén separadas estas fronteras:
| Frontera | Qué puede ayudar Tool Search | Qué no arregla |
|---|---|---|
| Definiciones iniciales | Diferir discovery y schemas en rutas soportadas. | Nombres vagos, descripciones largas, dueños duplicados. |
| Resultados de herramientas | Nada por sí solo. | Logs, tablas, traces, ficheros y payloads grandes. |
| Historial de sesión | Nada por sí solo. | Hilos largos, reintentos, errores viejos, decisiones antiguas. |
Si usas ANTHROPIC_BASE_URL, gateway compatible, proxy o ruta de modelo custom, verifica el comportamiento en tu entorno. Después de comprobar Tool Search, ejecuta un workflow real. Si el dolor aparece antes de llamar herramientas, limpia servidores y definiciones. Si aparece después, el siguiente trabajo es compresión de output.
Keep, defer, disable, split, redesign
Un buen setup MCP no tiene que ser el más pequeño posible, pero sí debe ser explicable. Cada servidor activo debe completar la frase: “En esta tarea, este MCP posee ____”. Si la respuesta es “quizá lo use luego”, no debería estar activo en el hilo principal.
| Acción | Cuándo usarla | Ejemplo |
|---|---|---|
| Keep | Posee el workflow actual y no se reemplaza con ficheros locales, memory o skill. | GitHub MCP durante review de PR; docs MCP durante migración de framework. |
| Defer | Será útil después, pero no en esta fase. | Dejar QA de navegador para cuando la UI ya esté corregida. |
| Disable | No ayuda a esta tarea o duplica otro dueño activo. | Dos docs servers responden la misma pregunta de librería. |
| Split | Un servidor custom mezcla lecturas, escrituras, deploys y métricas sin relación clara. | Separar búsqueda read-only de issues y acciones de deploy. |
| Redesign | El servidor es necesario, pero la herramienta devuelve demasiado. | Cambiar dump_database por search_errors(service, time_range, limit). |
Usa /mcp dentro de Claude Code para ver lo activo. Usa claude mcp list, claude mcp get y claude mcp remove cuando necesites revisar la configuración desde terminal. La meta no es presumir de pocos servidores, sino dejar un conjunto activo que Claude pueda razonar sin ambigüedad.
Si todavía estás eligiendo qué instalar primero, consulta Best Claude Code MCP Servers. Este artículo aborda la fase posterior: el setup ya creció demasiado y hay que devolverlo a un tamaño de trabajo.
Comprime la salida antes de meterla en la conversación
Después de Tool Search, la compresión de salida suele importar más que el número de servidores. Una sola llamada de alto volumen puede hacer más daño que varios servidores silenciosos.
El aviso de 10.000 tokens y MAX_MCP_OUTPUT_TOKENS son barandillas, no el objetivo de diseño. La mejor respuesta no es “casi bajo el límite”; es la respuesta más pequeña que todavía permite decidir el siguiente paso.
| Regla | Mala forma | Mejor forma |
|---|---|---|
| Summary first | stream completo de logs | anomalías, conteos y tres líneas de ejemplo |
| Filtrar en origen | todas las filas | filas por servicio, tiempo, estado u owner |
| Paginar | una respuesta gigante | lote inicial y next_cursor |
| Límite por defecto | resultados ilimitados | limit: 20 con override explícito |
| Devolver handles | fichero o dataset completo | path, object id, job id, stored result |
| Vista previa antes de raw | payload raw inmediato | summary primero, raw solo si se pide |
El usuario también controla el coste. En vez de “lee la base de datos”, pregunta “top 20 errores de las últimas 24 horas, agrupados por servicio, con count y una trace de ejemplo”. En vez de “mira los logs”, pregunta “solo errores después del deploy fallido, sin health checks”. Cuanto más estrecha sea la pregunta, más fácil será para la herramienta devolver poco.
Diseña servidores MCP compactos
Si controlas el servidor MCP, el mayor arreglo no es activarlo o apagarlo. Es cambiar la forma de las herramientas. Un servidor compacto expone menos herramientas, con dueños claros, nombres específicos, descripciones cortas, defaults seguros y salida acotada.
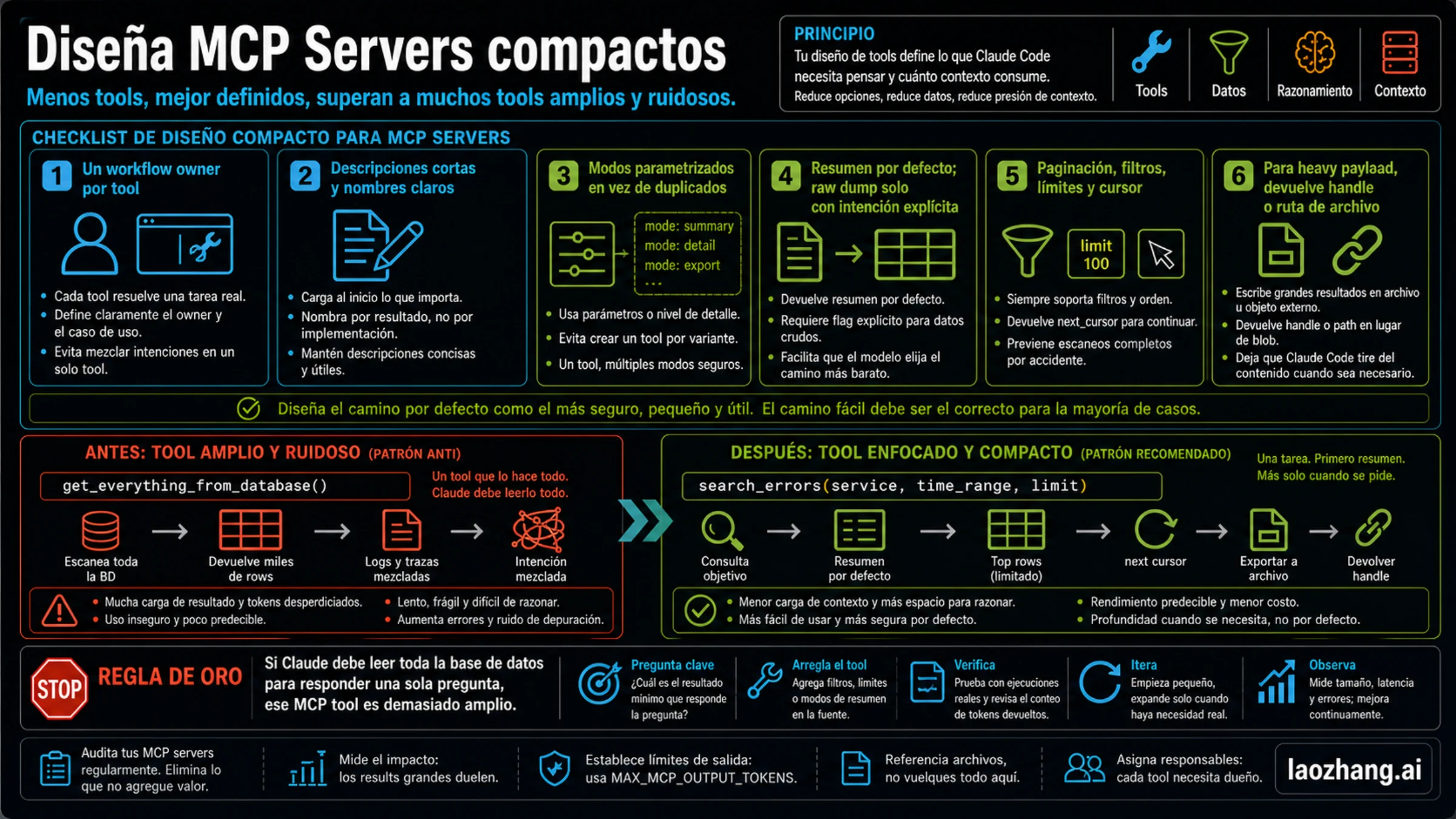
Pasa este checklist:
- Una herramienta debe tener un trabajo. No mezcles issues, logs, métricas, ficheros y deploys.
- Nombra el resultado, no la implementación. search_recent_errors es mejor que query_system.
- La descripción debe ayudar a elegir la herramienta, no documentar todo tu backend.
- Usa mode: summary/detail/export en vez de tres herramientas casi iguales.
- Summary debe ser el default. Raw output debe requerir parámetro explícito.
- Datos grandes necesitan filtros, límites, paginación o cursors.
- Si el payload es grande, devuelve paths, ids o handles.
- Separa exploración read-only de acciones write o destructivas.
Una mala herramienta es get_everything_from_database(), porque devuelve rows, logs, traces y metadata sin foco. Una buena herramienta es search_errors(service, time_range, limit), porque devuelve summary, top rows y next_cursor. La segunda no solo gasta menos tokens; también deja claro qué preguntar después.
Mueve el trabajo pesado fuera del hilo principal
A veces la respuesta correcta no es “menos MCP”, sino “menos MCP dentro del main thread”. Los subagents de Claude Code pueden investigar datos ruidosos, probar hipótesis y devolver un resumen compacto. Así el hilo principal conserva la decisión.
Pero un subagent no es una frontera automática de compresión. Si hereda demasiadas herramientas, replica el mismo problema. Dale solo los servidores necesarios y pide findings, counts, paths, risks y next actions, no dumps completos.
Skills resuelven otro problema. Si falta método, checklist, referencia o secuencia de scripts, usa una skill. Si falta acceso externo o una acción, usa MCP. Si faltan ambos, separa roles: MCP da alcance y la skill da método. Las reglas duraderas deben ir a memory, no a un transcript cada vez más largo.
Limpieza MCP de 20 minutos
Cuando Claude Code se vuelve lento, se compacta demasiado pronto o pierde señal después de añadir MCP, haz este pase:
- Ejecuta /mcp y lista los servidores activos.
- Marca cada servidor como keep, defer, disable, split o redesign.
- Apaga o aplaza todo lo que no tenga current workflow owner.
- Repite una tarea pequeña y observa si el dolor aparece antes o después del tool call.
- Antes del tool call: mira definitions, names, descriptions y soporte de Tool Search.
- Después del tool call: mira output size, summary, filters, limits, cursors y handles.
- Tras muchos reintentos: resume la decisión actual y abre un hilo limpio.
- Si falta método, escribe una skill en vez de añadir otro servidor.
La métrica útil no es el número total de servidores configurados. Importa cuántas opciones activas debe considerar Claude para esta tarea y cuánto dato devuelven las herramientas al hilo. El setup más útil suele ser pequeño, aburrido y muy claro.
Preguntas frecuentes
¿Tool Search resuelve la sobrecarga de contexto MCP?
No por completo. Puede reducir definiciones iniciales en rutas soportadas, pero no comprime resultados, no limpia historial y no arregla herramientas custom demasiado amplias.
¿Cuántos servidores MCP debería activar?
No hay número universal. Activa los que poseen el workflow actual. Un solo servidor de base de datos que devuelve dumps enormes puede ser peor que varios servidores pequeños y claros.
¿Qué hago si el output MCP es enorme?
Comprime en origen: summaries, filtros, paginación, límites, cursors, paths, ids o handles. Raw data debe ser una petición explícita.
¿Cuándo usar una skill en lugar de MCP?
Usa skill cuando falta método repetible. Usa MCP cuando Claude necesita acceso externo o una acción. Si el workflow necesita ambos, deja que MCP aporte acceso y la skill aporte disciplina.
¿Cómo diseño un servidor MCP compacto?
Con menos herramientas, dueños claros, descripciones cortas, salidas acotadas, filtros, limits, cursors, summary first y separación read/write. Evita herramientas que devuelven todo porque pueden.
¿Apagar todos los MCP es lo más seguro?
Solo como diagnóstico. La solución duradera es un active set compacto: conserva el acceso crítico, aplaza lo demás y rediseña las herramientas que devuelven demasiado.
La sobrecarga de contexto en Claude Code por MCP se arregla cuando dejas de coleccionar integraciones y empiezas a presupuestar memoria de trabajo. Conserva solo el acceso que posee el workflow actual, comprime resultados antes de meterlos en conversación, mueve el método a skills y aísla exploraciones ruidosas. El setup que Claude puede razonar mejor suele ser el más pequeño que todavía hace el trabajo.