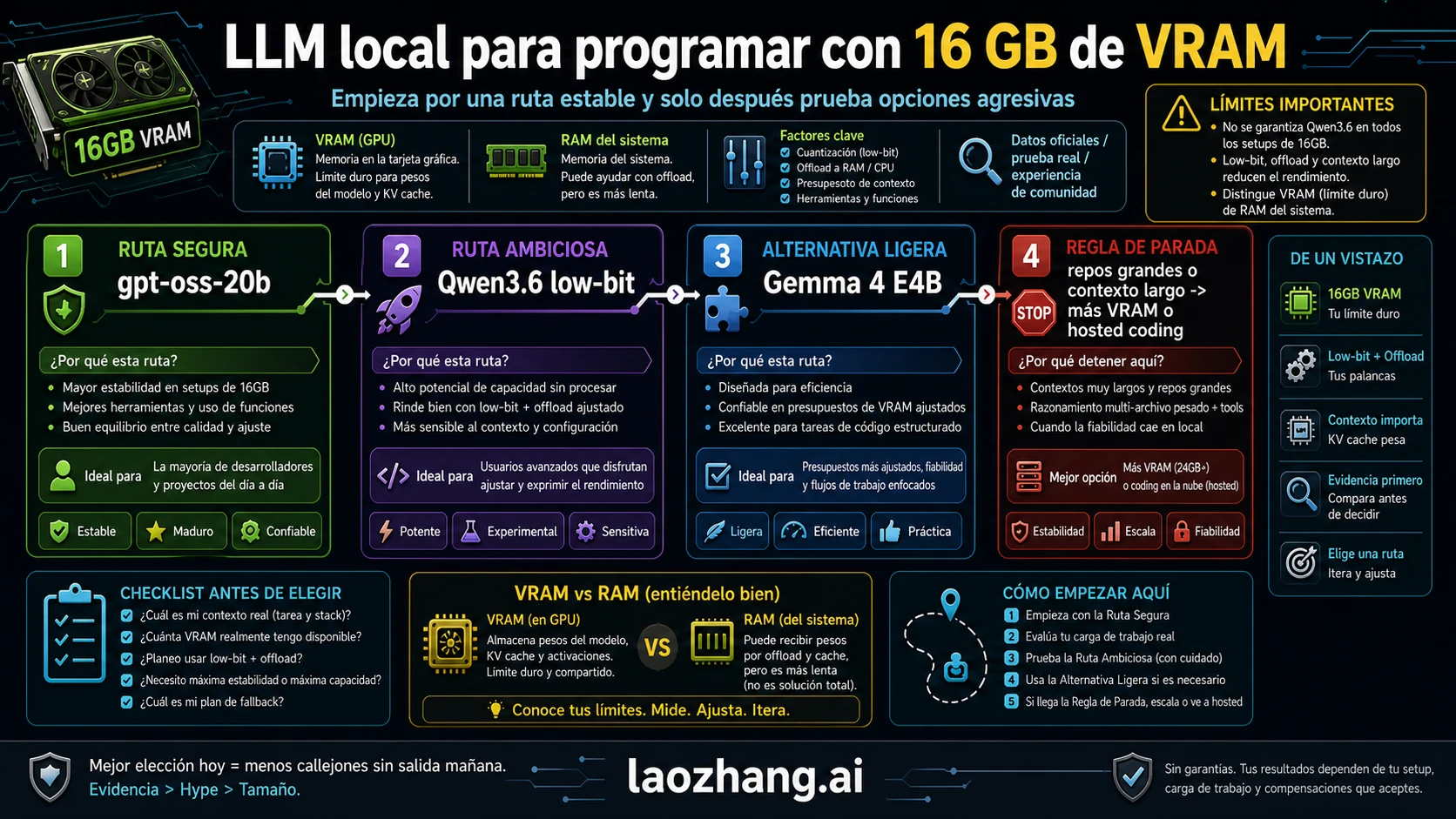
Con una GPU de 16 GB de VRAM, el mejor LLM local para programar no se elige por el nombre más grande de la lista. Conviene elegir una ruta: gpt-oss-20b como baseline defendible, Qwen3.6 35B A3B como experimento low-bit u offload, y Gemma 4 E4B o modelos pequeños de código como alternativa rápida.
Que una modelo cargue no significa que sea buen asistente de programación. En una tarea real también consumen memoria el KV cache, el contexto de archivos, los tests, el servidor local, el wrapper del editor y varias rondas de parche. Por eso 16 GB se sienten más pequeños cuando pasas de un prompt corto a un repositorio real.
Revisión fechada el 2026-07-03: las afirmaciones oficiales, las páginas de runtime y los relatos de comunidad se tratan por separado. La comunidad ayuda a descubrir candidatos; los requisitos de memoria y paquete deben venir del runtime; la decisión diaria se confirma con un smoke test en tu propio código.
La decisión práctica es: instala primero gpt-oss-20b, pídele que modifique una función real con su test cercano, mide latencia y memoria. Si falta calidad, prueba Qwen3.6 con contexto corto y cuantización explícita. Si aparecen OOM, offload lento o pérdida de contexto, cambia a un modelo menor, más VRAM o una ruta hosted.
Respuesta rápida: decide la ruta antes del modelo
En español aparecen Reddit, videos de YouTube, guías de Donweb, Javadex, Zerlo y comparativas de herramientas locales. Muchas respuestas prometen modelos de 12B a 14B con Q4, pero pocas separan carga, rendimiento y flujo real de edición.
Por eso la primera pieza debe ser una tabla de rutas, no un ranking. Ayuda a decidir qué instalar hoy, qué probar con cuidado y dónde dejar de invertir tiempo.
| Ruta | Primer modelo | Por qué encaja en la pregunta de 16 GB | Riesgo principal | Siguiente acción |
|---|---|---|---|---|
| Baseline estable | gpt-oss-20b | tiene una evidencia de memoria más limpia para la clase de 16 GB | no promete razonamiento ilimitado sobre repos completos | instalar y pasar el smoke test |
| Experimento ambicioso | Qwen3.6-35B-A3B low-bit u offload | es atractivo para agentic coding y razonamiento de repositorio | las páginas de runtime no dan una garantía simple all-GPU | fijar cuantización, contexto y offload |
| Alternativa ligera | Gemma 4 E4B-it | reduce presión de memoria y mejora la respuesta | no siempre será el agente más profundo | usarla para tareas estrechas |
| Alternativa especializada | Qwen2.5-Coder, Qwen3-Coder, DeepSeek Coder variants | las familias de código pueden rendir bien en ediciones enfocadas | el archivo exacto decide si cabe | ver paquete y contexto antes de comparar |
| Parada | más VRAM, modelo menor o hosted coding | contextos largos y tool loops pueden superar el margen de 16 GB | seguir ajustando puede costar más que la tarea | parar ante OOM, lentitud o pérdida de contexto |
Límite de evidencia: oficial, runtime y comunidad
gpt-oss-20b ocupa el inicio porque la evidencia de memoria es más defendible, no porque deba ganar todos los benchmarks de código. Cuando una ruta tiene soporte oficial y runtime más claro, reduce el riesgo de que la primera instalación se convierta en arqueología de paquetes.
Qwen3.6 35B A3B es tentador. Su posicionamiento para agentic coding y razonamiento sobre repositorios lo hace visible en discusiones actuales. Pero una compilación low-bit concreta, una página de Ollama, un perfil de LM Studio y una experiencia de Reddit no son la misma afirmación.
Gemma 4 E4B pertenece a la ruta de ajuste práctico. No hay que venderla como el agente de código más potente, sino como una opción que mantiene la máquina respirando cuando la tarea es acotada.
Los posts de Reddit, videos y guías locales sí importan. Enseñan qué GPUs usa la gente, qué modelos prueban y qué síntomas aparecen. Pero sin archivo de modelo, cuantización, longitud de contexto, GPU, driver y runtime, no son garantía reproducible.
La regla editorial es simple: lo oficial describe el modelo, el runtime describe el paquete y la memoria, la comunidad describe demanda y fallos. Mezclar todo en una frase de “mejor modelo” deja al lector sin forma de validar.

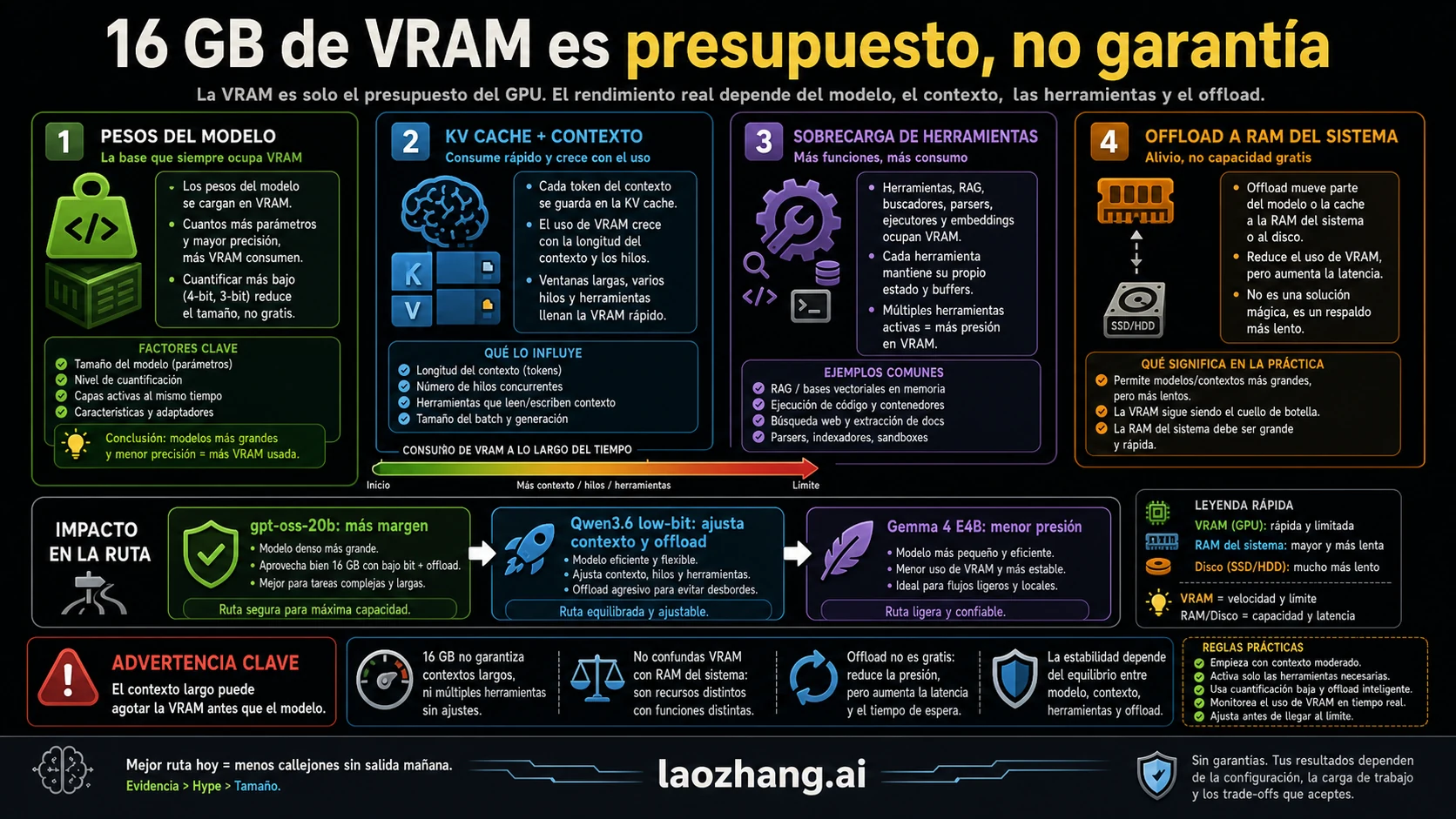
Qué compran realmente 16 GB de VRAM
VRAM es memoria dedicada de la GPU. No es RAM del sistema ni espacio en disco. En inferencia local compiten los pesos del modelo, buffers del runtime, KV cache, prompt, tokens generados y el wrapper del editor.
Programar exige más memoria contextual que chatear. El modelo debe mantener una función, un test cercano, un error, restricciones de refactor y la conversación previa. Un modelo que responde bien a un ejemplo corto puede fallar al editar un repositorio.
Offload puede evitar un OOM inmediato, pero normalmente compra viabilidad a cambio de latencia. Para un asistente de código, la latencia cambia el valor: si cada parche tarda minutos, el flujo deja de ser útil.
El valor real de 16 GB es una capa local privada y barata para tareas enfocadas. No es una promesa de agente autónomo sobre un monorepo grande.
| Presión de memoria | Qué significa al programar | Cómo tratarla con 16 GB |
|---|---|---|
| Pesos del modelo | definen si el modelo carga y con qué quant | empezar con paquete de evidencia clara |
| KV cache | el contexto largo consume el margen restante | subir contexto por pasos |
| Capa de herramientas | IDE, server, tokenizer y wrapper añaden overhead | crear baseline en CLI |
| Offload | evita OOM pero compra latencia | mantenerlo solo si sigue siendo usable |
Ruta 1: empezar con gpt-oss-20b
Usa gpt-oss-20b como baseline. Un baseline no es un campeón permanente; es una forma de comprobar si tu GPU, runtime y fragmento de repositorio pueden sostener un loop útil de programación local.
No metas todo el proyecto en el primer prompt. Usa un archivo, un test cercano y una petición concreta. Pide explicación, parche mínimo, test afectado y una declaración explícita de qué archivo falta si el contexto no alcanza.
bashollama pull gpt-oss:20b ollama run gpt-oss:20b
Si este baseline ya es lento, se queda sin memoria o olvida el contexto, no corras hacia un Qwen mayor. Primero reduce contexto, revisa runtime, apaga wrappers de IDE y prueba una alternativa más pequeña.
Si pasa, aumenta la carga en pasos: añade el test, luego un módulo vecino, luego el log de error. En cada paso registra VRAM, RAM del sistema, latencia y calidad del parche.
Ruta 2: Qwen3.6 35B A3B como experimento avanzado
Qwen3.6 35B A3B tiene sentido cuando el baseline es usable pero falta capacidad. Es una ruta avanzada, no una respuesta de instalación fácil para todo usuario con 16 GB.
Antes de probarlo fija la cuantización, runtime, capas en GPU, offload, RAM del sistema, longitud de contexto y tipo de tarea. Una explicación de una función y un flujo agentic multiarchivo son cargas distintas.
bashollama show qwen3.6:35b-a3b
Si el paquete o requisito de memoria ya supera tu zona cómoda, detente antes de descargar. Un modelo que apenas cabe puede rendir peor que uno menor que conserva contexto y responde rápido.
Esta ruta sirve si aceptas leer configuraciones, bajar contexto, cambiar quant, observar memoria y volver atrás. Si quieres un ayudante hoy, sin tocar el stack de inferencia, empieza y termina con rutas más simples.
Ruta 3: conservar Gemma 4 E4B y modelos pequeños de código
Gemma 4 E4B y los modelos pequeños de código protegen la usabilidad de una máquina de 16 GB. Responder rápido, no saturar la GPU y mantener el contexto puede valer más que el tamaño del checkpoint.
DeepSeek Coder, Qwen2.5-Coder y Qwen3-Coder pueden estar en la lista corta, pero a nivel de archivo concreto. El nombre de familia no decide si cabe, si mantiene contexto o si funciona con tu wrapper.
Un modelo pequeño sirve para explicar funciones, escribir helpers, revisar diffs cortos, proponer tests y ordenar errores. No tiene que cubrir todo el mercado de agentes para ser valioso.
Si un modelo menor entrega un parche revisable en segundos y uno mayor tarda demasiado o pierde el test, el menor gana para trabajo diario.
Runtime: Ollama, LM Studio, llama.cpp y wrappers de IDE
El runtime cambia la respuesta. Ollama es buen baseline de CLI, LM Studio ayuda con GUI y local server, llama.cpp/GGUF da control fino sobre quant y contexto, el wrapper de IDE decide qué archivos entran al prompt.
El mismo nombre de modelo puede apuntar a archivos, cuantizaciones y contextos distintos. Por eso una recomendación útil incluye ruta de ejecución, no solo nombre.
En Ollama mira tamaño del paquete y parámetros. En LM Studio lee memory requirement. En GGUF fija nombre de archivo, quant y context. En un wrapper de IDE revisa selección de archivos y endpoint.
Si el wrapper oculta la presión de memoria, vuelve a CLI. La línea de comandos ayuda a separar problema de modelo, problema de contexto y problema de integración.
Smoke test: probar el modelo con tu propio código
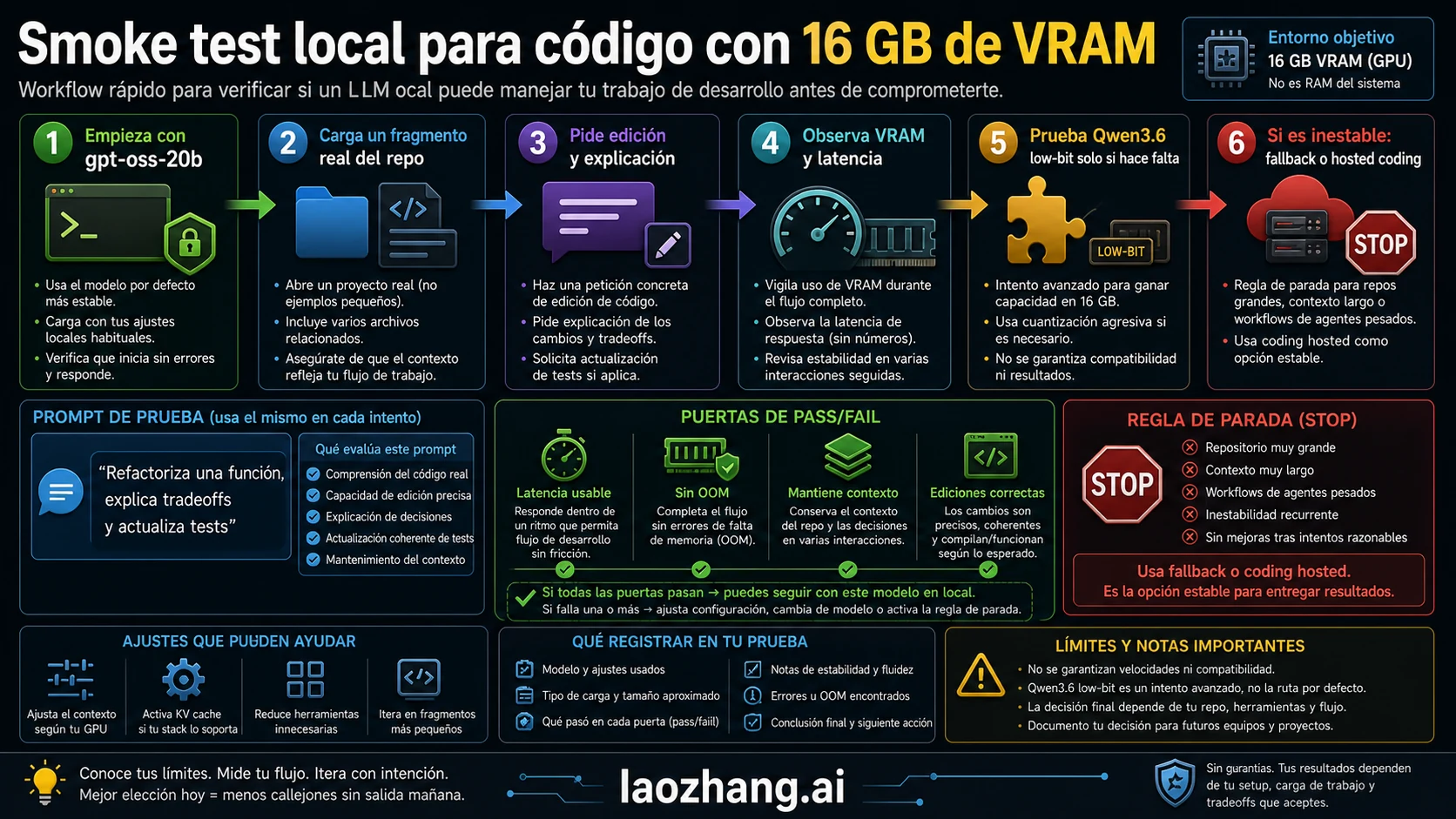
El smoke test debe usar tu código. Los puzzles y benchmarks generales no revelan si el modelo conserva restricciones, tests y forma de parche.
La prueba mínima: un archivo, un test cercano y una tarea concreta. El modelo debe explicar el comportamiento actual, proponer parche, nombrar el test y pedir un archivo específico si falta contexto.
textGiven the files below, refactor one function without changing behavior. Explain the tradeoff, show the patch, and name the test that should be updated. If the context is insufficient, say exactly what file or symbol you need next.
Pasa si la latencia es tolerable, no hay OOM ni offload descontrolado, conserva función y test, y el parche es pequeño y revisable. Falla si cualquiera de esas piezas se rompe.
Después de pasar, sube el contexto poco a poco. Solo entonces prueba Qwen low-bit. Así evitas confundir ajuste de memoria con evaluación de calidad.
Reglas de parada: cuándo dejar de forzar 16 GB
Las reglas de parada deben existir antes de empezar. El error costoso en 16 GB es seguir ajustando un modelo que carga, pero no ayuda a programar.
Si generar es muy lento, sospecha de offload caro o cuantización pesada. Si responde bien en snippets y mal en repos, sospecha de empaquetado de contexto. Si al subir contexto aparece OOM, el KV cache está dominando el presupuesto.
La salida puede ser reducir modelo, estrechar tarea, bajar contexto, pasar a 24 o 32 GB, o usar hosted coding para trabajos largos multiarchivo.
El objetivo no es demostrar que 16 GB pueden con todo. El objetivo es obtener ayuda de código fiable, rápida y revisable.
| Síntoma | Causa probable | Mejor ruta |
|---|---|---|
| Carga pero va lento | offload caro o quant pesado | modelo menor o más VRAM |
| Bien en snippets, mal en repo | context packing insuficiente | estrechar tarea |
| OOM al subir contexto | KV cache domina el presupuesto | bajar contexto o subir a 24GB+ |
| El patch loop pierde estado | workflow agentic demasiado pesado | hosted coding o GPU mayor |
Cómo documentar una prueba local
Documenta GPU, RAM del sistema, driver, runtime version, model file, quant, context length, offload, tipo de tarea, latencia, pico de memoria y razón de fallo. Sin esos campos, no puedes comparar pruebas.
Para gpt-oss-20b, mira qué tamaño de repo slice conserva de forma estable. Para Qwen3.6, mira si low-bit y offload cuestan demasiado. Para Gemma 4 E4B, mira si la velocidad compensa el menor tamaño.
No registres solo “carga”. Registra “corrige bien”. En programación importan el parche, el test y la capacidad de decir que falta contexto.
Preguntas frecuentes
¿Qué LLM local para programar debo probar primero con 16 GB de VRAM?
Empieza con gpt-oss-20b. Es el baseline más defendible para esta restricción de memoria y permite medir tu máquina antes de probar rutas más agresivas.
¿Qwen3.6 35B A3B puede funcionar con 16 GB de VRAM?
Puede funcionar en una ruta low-bit, con contexto corto u offload, pero no debe tratarse como garantía simple all-GPU. Depende de quant, runtime, RAM, contexto y tarea.
¿gpt-oss-20b es suficiente para programar?
Es útil para ediciones enfocadas, explicación de funciones, tests cortos y pequeños refactors. Para agentes multiarchivo largos necesita smoke test aparte.
¿Por qué conservar Gemma 4 E4B?
Porque reduce presión de memoria y puede responder más rápido. En tareas estrechas, esa estabilidad vale más que un modelo grande y frágil.
¿Ollama o LM Studio?
Ollama es mejor para un baseline de CLI. LM Studio es cómodo para GUI y local server. La decisión real depende del archivo, quant y requisito de memoria.
¿Una RTX 4060 Ti 16GB sirve?
Sí, como máquina de prueba de 16 GB. No significa que todo 30B o 35B vaya cómodo con contexto largo.
¿Qué hago con 8 GB de VRAM?
Usa modelos menores, contexto corto y tareas estrechas. No copies los experimentos Qwen pensados para 16 GB.
¿24 GB de VRAM resuelven el problema?
Dan más margen, sobre todo para contexto y quant, pero no eliminan la necesidad de smoke test.
¿Cuándo debo parar la ruta local?
Cuando OOM, offload lento, pérdida de contexto o fallos de patch loop se convierten en el trabajo principal.
¿Puedo decidir solo con benchmarks de Reddit?
No. Úsalos como señal de candidatos, pero valida archivo, quant, runtime, contexto y tu propio código.